
Utilizează Google un sistem asemănător ChatGPT pentru detectarea conținutului spam și AI și pentru clasarea site-urilor?
Publicat: 2023-02-01Titlul este înșelător în mod intenționat – dar numai în ceea ce privește utilizarea termenului „ChatGPT”.
„ChatGPT-like” vă permite imediat cititorului să cunoașteți tipul de tehnologie la care mă refer, în loc să descriu sistemul ca „un model de generare de text precum GPT-2 sau GPT-3”. (De asemenea, acesta din urmă chiar nu ar fi la fel de accesibil...)
Ceea ce ne vom uita în acest articol este o lucrare Google mai veche, dar extrem de relevantă, din 2020, „Modelele generative sunt predictori nesupravegheați ai calității paginii: un studiu la scară colosală”.
Despre ce este hârtia?
Să începem cu descrierea autorilor. Ei introduc subiectul astfel:
„Mulți și-au exprimat îngrijorarea cu privire la potențialele pericole ale generatoarelor de text neuronale în sălbăticie, în mare parte datorită capacității lor de a produce text cu aspect uman la scară.
Clasificatorii instruiți să discrimineze între textul uman și cel generat de mașini au fost utilizați recent pentru a monitoriza prezența textului generat de mașini pe web [29]. S-a făcut însă puțină muncă în aplicarea acestor clasificatoare pentru alte utilizări, în ciuda proprietății lor atractive de a nu necesita etichete – doar un corpus de text uman și un model generativ. În această lucrare, arătăm, printr-o evaluare umană riguroasă, că discriminatorii de pe raft uman vs. mașină servesc ca clasificatori puternici ai calității paginii . Adică, textele care par generate de mașină tind să fie incoerente sau neinteligibile. Pentru a înțelege prezența unei pagini de calitate scăzută în sălbăticie, aplicăm clasificatorii unui eșantion de jumătate de miliard de pagini web în limba engleză.”
Ceea ce spun ei în esență este că au descoperit că aceleași clasificatoare dezvoltate pentru a detecta copierea bazată pe inteligență artificială, folosind aceleași modele pentru a o genera, pot fi folosite cu succes pentru a detecta conținut de calitate scăzută.
Desigur, acest lucru ne lasă cu o întrebare importantă:
Este această cauzalitate (adică, sistemul o preia pentru că este cu adevărat bun la asta) sau o corelație (adică, o mulțime de spam-uri actuale sunt create într-un mod care este ușor de îndepărtat cu instrumente mai bune)?
Înainte de a explora acest lucru, totuși, să ne uităm la unele dintre lucrările autorilor și constatările acestora.
Pregatirea
Pentru referință, au folosit următoarele în experimentul lor:
- Două modele de generare de text , detectorul OpenAI GPT-2 bazat pe Roberta (un detector care utilizează modelul RoBERTa cu ieșire GPT-2 și prezice dacă este probabil generat de AI sau nu) și modelul GLTR, care are și acces la partea de sus GPT-2 iese și funcționează în mod similar.
Putem vedea un exemplu de ieșire a acestui model pe conținutul pe care l-am copiat din lucrarea de mai sus:
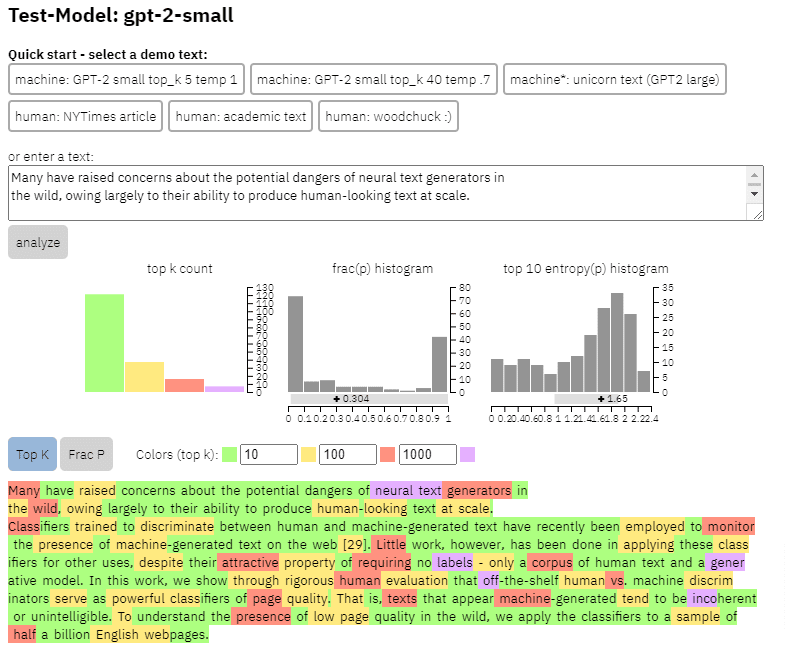
- Trei seturi de date Web500M (o eșantionare aleatorie de 500 de milioane de pagini web în limba engleză), GPT-2 Output (250k GPT-2 generații de text) și Grover-Output (au generat intern 1,2 milioane de articole folosind modelul Grover-Base, care a fost conceput pentru a detecta știri false).
- The Spam Baseline , un clasificator instruit pe setul de date Enron Spam Email. Ei au folosit acest clasificator pentru a stabili numărul de calitate a limbajului pe care l-ar atribui, așa că dacă modelul a determinat că un document nu este spam cu o probabilitate de 0,2, scorul de calitate a limbii (LQ) atribuit a fost 0,2.
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
O deoparte despre prevalența spam-ului
Am vrut să iau o scurtă deoparte pentru a discuta câteva descoperiri interesante de care s-au împiedicat autorii. Una este ilustrată în următoarea figură (Figura 3 din hârtie):
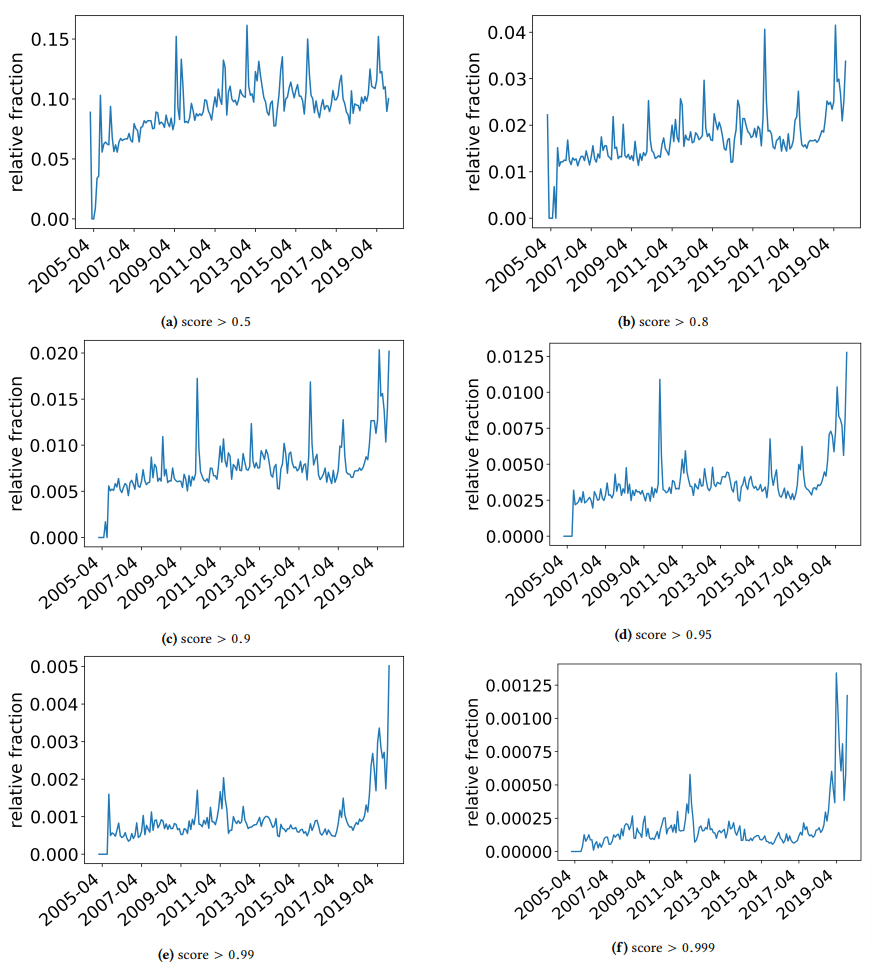
Este important să observați scorul de sub fiecare grafic. Un număr spre 1.0 trece la încrederea că conținutul este spam. Ceea ce vedem atunci este că din 2017 încolo – și crescând în 2019 – a existat o prevalență a documentelor de calitate scăzută.
În plus, au descoperit că impactul conținutului de calitate scăzută a fost mai mare în unele sectoare decât în altele (reținând că un scor mai mare reflectă o probabilitate mai mare de spam).
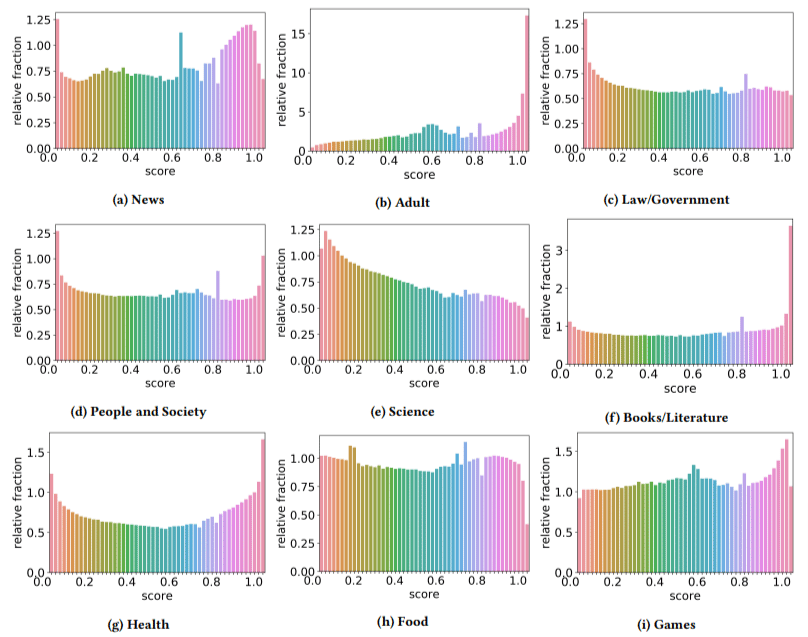
M-am scărpinat pe cap pe câteva dintre astea. Adultul avea sens, evident.
Dar cărțile și literatura au fost un pic o surpriză. La fel a fost și sănătatea – până când autorii au adus în discuție Viagra și alte site-uri de „produse de sănătate pentru adulți” ca „sănătate” și fermele de eseuri ca „literatură” – adică.
Descoperirile lor
Pe lângă ceea ce am discutat despre sectoare și vârful din 2019, autorii au găsit și o serie de lucruri interesante de la care SEO pot învăța și trebuie să le țină cont, mai ales că începem să ne bazăm pe instrumente precum ChatGPT.
- Conținutul de calitate scăzută tinde să aibă o lungime mai mică (atingând un vârf de 3.000 de caractere).
- Sistemele de detectare instruite pentru a determina dacă textul a fost scris de o mașină sau nu sunt, de asemenea, bune la clasificarea conținutului scăzut față de cel de nivel înalt.
- Ei numesc conținutul nostru conceput pentru clasamente drept un vinovat specific, deși bănuiesc că se referă la gunoiul despre care știm cu toții că nu ar trebui să fie acolo.
Autorii nu susțin că aceasta este o soluție finală, ci mai degrabă un punct de plecare și sunt sigur că au avansat ștacheta în ultimii doi ani.
O notă despre conținutul generat de AI
Modelele de limbaj s-au dezvoltat, de asemenea, de-a lungul anilor. În timp ce GPT-3 exista când a fost scrisă această lucrare, detectoarele pe care le foloseau erau bazate pe GPT-2, care este un model semnificativ inferior.
GPT-4 este probabil chiar după colț, iar Sparrow de la Google este pregătit pentru lansare mai târziu în acest an. Aceasta înseamnă că nu numai că tehnologia se îmbunătățește de ambele părți ale câmpului de luptă (generatoare de conținut vs. motoare de căutare), ci și combinațiile vor fi mai ușor de pus în joc.
Poate Google să detecteze conținut creat de Sparrow sau GPT-4? Poate.
Dar ce zici dacă a fost generat cu Sparrow și apoi trimis la GPT-4 cu un prompt de rescriere?
Un alt factor care trebuie reținut este că tehnicile utilizate în această lucrare se bazează pe modele auto-regresive. Mai simplu spus, ei prezic un scor pentru un cuvânt pe baza a ceea ce ar prezice acel cuvânt pentru a primi cei care l-au precedat.
Pe măsură ce modelele dezvoltă un grad mai mare de sofisticare și încep să creeze idei complete la un moment dat, mai degrabă decât un cuvânt urmat de altul, detectarea AI poate scădea.
Pe de altă parte, detectarea conținutului pur și simplu prost ar trebui să escaladeze – ceea ce poate însemna că singurul conținut „de calitate scăzută” care va câștiga este generat de AI.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.