
Ecosistemul Hadoop și componentele sale
Publicat: 2015-04-23Big Data este cuvântul popular care circulă în industria IT din 2008. Cantitatea de date generată de rețelele sociale, producția, retailul, stocurile, telecomunicațiile, asigurările, industria bancară și industria sănătății depășește cu mult imaginația noastră.
Înainte de apariția Hadoop, stocarea și procesarea datelor mari reprezentau o mare provocare. Dar acum că Hadoop este disponibil, companiile și-au dat seama de impactul afacerilor pe care îl au Big Data și de modul în care înțelegerea acestor date va conduce la creștere. De exemplu:
• Sectoarele bancare au o șansă mai bună de a înțelege clienții fideli, debitorii de credit și tranzacțiile frauduloase.
• Sectoarele de retail au acum suficiente date pentru a prognoza cererea.
• Sectoarele de producție nu trebuie să depindă de mecanismele costisitoare pentru testarea calității. Captarea datelor senzorilor și analizarea acestora ar dezvălui multe modele.
• E-Commerce, rețelele sociale pot personaliza paginile în funcție de interesele clienților.
• Piețele bursiere generează o cantitate uriașă de date, corelarea din când în când va dezvălui perspective frumoase.
Big Data are multe aplicații utile și perspicace.
Hadoop este răspunsul direct pentru procesarea Big Data. Ecosistemul Hadoop este o combinație de tehnologii care au avantaje competente în rezolvarea problemelor de afaceri.
Să înțelegem componentele din Hadoop Ecosytem pentru a construi soluții potrivite pentru o anumită problemă de afaceri.
Ecosistemul Hadoop:
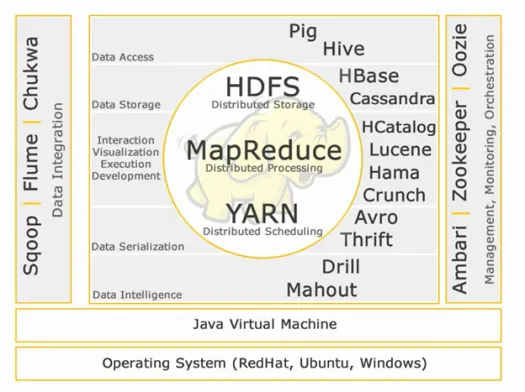

Core Hadoop:
HDFS:
HDFS înseamnă Hadoop Distributed File System pentru gestionarea seturilor mari de date cu volum mare, viteză și varietate. HDFS implementează arhitectura master slave. Master este nodul de nume și slave este nodul de date.
Caracteristici:
• Scalabil
• De încredere
• Hardware de marfă
HDFS este bine-cunoscut pentru stocarea Big Data.
Reducere hartă:
Map Reduce este un model de programare conceput pentru a procesa date distribuite cu volum mare. Platforma este construită folosind Java pentru o mai bună gestionare a excepțiilor. Map Reduce include doi deamoni, Job tracker și Task Tracker.
Caracteristici:
• Programare funcțională.
• Funcționează foarte bine pe Big Data.
• Poate procesa seturi mari de date.
Map Reduce este componenta principală cunoscută pentru procesarea datelor mari.
fire:
YARN înseamnă Yet Another Resource Negotiator. Este numit și MapReduce 2(MRv2). Cele două funcționalități majore ale Job Tracker în MRv1, managementul resurselor și programarea/monitorizarea lucrărilor sunt împărțite în daemoni separate care sunt ResourceManager, NodeManager și ApplicationMaster.
Caracteristici:
• Gestionarea mai bună a resurselor.
• Scalabilitate
• Alocarea dinamică a resurselor clusterului.
Acces la date:
Porc:
Apache Pig este un limbaj de nivel înalt construit pe MapReduce pentru analiza seturi de date mari cu programe simple de analiză de date ad-hoc. Pig mai este cunoscut și sub numele de limbaj de flux de date. Este foarte bine integrat cu python. Este dezvoltat inițial de Yahoo.
Caracteristicile esențiale ale porcului:
• Ușurință de programare
• Oportunități de optimizare
• Extensibilitate.
Scripturile Pig intern vor fi convertite în programe de reducere a hărților.

Stup:
Apache Hive este un alt limbaj de interogare la nivel înalt și o infrastructură de depozit de date construită pe Hadoop pentru a oferi rezumat, interogare și analiză a datelor. Este inițial dezvoltat de Yahoo și făcut open source.
Caracteristicile esențiale ale stupului:
• Limbajul de interogare asemănător SQL numit HQL.
• Partiționare și compartimentare pentru o procesare mai rapidă a datelor.
• Integrare cu instrumente de vizualizare precum Tableau.
Interogările Hive la nivel intern vor fi convertite în programe de reducere a hărților.
Dacă doriți să deveniți un analist de date mari, aceste două limbi de nivel înalt trebuie să știți!

Stocare a datelor:
Hbase:
Apache HBase este o bază de date NoSQL creată pentru a găzdui tabele mari cu miliarde de rânduri și milioane de coloane deasupra mașinilor hardware Hadoop. Utilizați Apache Hbase atunci când aveți nevoie de acces aleatoriu, în timp real, de citire/scriere la Big Data.
Caracteristici:
• Citiri și scrieri strict consecvente. În operaţiile de memorie.
• API Java ușor de utilizat pentru accesul clientului.
• Bine integrat cu porc, stup și sqoop.
• Este un sistem consistent și tolerant la partiții în teorema CAP.

Cassandra:
Cassandra este o bază de date NoSQL concepută pentru scalabilitate liniară și disponibilitate ridicată. Cassandra se bazează pe modelul cheie-valoare. Dezvoltat de Facebook și cunoscut pentru răspunsul mai rapid la întrebări.
Caracteristici:
• Indici de coloane
• Suport pentru denormalizare
• Vederi materializate
• Cache încorporată puternică.

Interacțiune -Vizualizare-execuție-dezvoltare:
Hcatalog:

HCatalog este un nivel de management al tabelelor care oferă integrarea metadatelor stupului pentru alte aplicații Hadoop. Le permite utilizatorilor cu diferite instrumente de procesare a datelor, cum ar fi Apache pig, Apache MapReduce și Apache Hive, să citească și să scrie mai ușor datele.
Caracteristici:
• Vedere tabelară pentru diferite formate.
• Notificări privind disponibilitatea datelor.
• API-uri REST pentru sisteme externe pentru a accesa metadate.
Lucene:
Apache LuceneTM este o bibliotecă de motor de căutare de text de înaltă performanță, cu funcții complete, scrisă în întregime în Java. Este o tehnologie potrivită pentru aproape orice aplicație care necesită căutare full-text, în special multiplatformă.
Caracteristici:
• Indexare scalabilă, de înaltă performanță.
• Algoritmi de căutare puternici, precisi și eficienți.
• Soluție multiplatformă.
Hama:
Apache Hama este un cadru distribuit bazat pe calculul Bulk Synchronous Parallel (BSP). Capabil și bine cunoscut pentru calcule științifice masive, cum ar fi algoritmi de matrice, grafic și rețea.
Caracteristici:
• Model de programare simplu
• Bine potrivit pentru algoritmi iterativi
• Fire suportată
• Învățare automată nesupravegheată cu filtrare colaborativă.
• K-Means clustering.
Crunch:
Apache crunch este construit pentru pipelinerea programelor MapReduce care sunt simple și eficiente. Acest cadru este utilizat pentru scrierea, testarea și rularea conductelor MapReduce.
Caracteristici:
• Axat pe dezvoltator.
• Abstracții minime
• Model de date flexibil.
Serializarea datelor:
Avro:
Apache Avro este un cadru de serializare a datelor care este neutru în limbaj. Conceput pentru portabilitatea limbii, permițând datelor să supraviețuiască potențial limbii pentru a o citi și scrie.

Cumpătare:
Thrift este un limbaj dezvoltat pentru a construi interfețe pentru a interacționa cu tehnologiile construite pe Hadoop. Este folosit pentru a defini și a crea servicii pentru numeroase limbi.
Inteligența datelor:
Burghiu:
Apache Drill este un motor de interogare SQL cu latență scăzută pentru Hadoop și NoSQL.
Caracteristici:
• Agilitate
• Flexibilitate
• Familiaritate.

Conducător de elefanţi:
Apache Mahout este o bibliotecă scalabilă de învățare automată concepută pentru a construi analize predictive pe Big Data. Mahout are acum implementări apache spark pentru calcularea mai rapidă a memoriei.
Caracteristici:
• Filtrare colaborativa.
• Clasificare
• Clustering
• Reducerea dimensionalității

Integrarea datelor:
Apache Sqoop:

Apache Sqoop este un instrument conceput pentru transferurile de date în vrac între bazele de date relaționale și Hadoop.
Caracteristici:
• Importă și exportă către și de la HDFS.
• Importă și exportă către și de la Hive.
• Import și export în HBase.
Apache Flume:
Flume este un serviciu distribuit, de încredere și disponibil pentru colectarea, agregarea și mutarea eficientă a unor cantități mari de date de jurnal.
Caracteristici:
• Robustă
• Tolerant la erori
• Arhitectură simplă și flexibilă bazată pe fluxuri de date în flux.

Apache Chukwa:
Colector de jurnal scalabil utilizat pentru monitorizarea sistemelor mari de fișiere distribuite.
Caracteristici:
• Scalează la mii de noduri.
• Livrare de încredere.
• Ar trebui să poată stoca datele pe termen nelimitat.

Management, monitorizare și orchestrare:
Apache Ambari:
Ambari este conceput pentru a simplifica gestionarea Hadoop prin furnizarea unei interfețe pentru furnizarea, gestionarea și monitorizarea clusterelor Apache Hadoop.
Caracteristici:
• Furnizați un cluster Hadoop.
• Gestionați un cluster Hadoop.
• Monitorizați un cluster Hadoop.

Apache Zookeeper:
Zookeeper este un serviciu centralizat conceput pentru menținerea informațiilor de configurare, denumirea, furnizarea de sincronizare distribuită și furnizarea de servicii de grup.
Caracteristici:
• Serializare
• Atomicitate
• Fiabilitate
• API simplu

Apache Oozie:
Oozie este un sistem de planificare a fluxului de lucru pentru a gestiona joburile Apache Hadoop.
Caracteristici:
• Sistem scalabil, fiabil și extensibil.
• Suportă mai multe tipuri de lucrări Hadoop, cum ar fi Map-Reduce, Hive, Pig și Sqoop.
• Simplu și ușor de utilizat.

Vom discuta despre componente în detaliu în articolele viitoare. Rămâneți aproape.