
Estimarea timpului, costului și a rezultatelor unui proiect de aplicație ML
Publicat: 2019-11-20Imaginează-ți că vei cumpăra un portofel personalizat într-un magazin.
Deși știți ce tip de portofel aveți nevoie, dar nu știți costul sau timpul necesar pentru a obține versiunea personalizată.
Același lucru este cazul proiectelor de învățare automată. Și pentru a vă ajuta cu această dilemă, v-am oferit informații detaliate pentru a avea un proiect de succes.
Machine Learning este ca o monedă care are două fețe .
Pe de o parte, ajută la eliminarea incertitudinilor din procese. Dar, pe de altă parte , dezvoltarea sa este plină de nesiguranță.
În timp ce rezultatul final al aproape fiecărui proiect de învățare automată (ML) este o soluție care îmbunătățește afacerile și eficientizează procesele; partea de dezvoltare are o poveste complet diferită de împărtășit.
Chiar dacă ML a jucat un rol masiv în schimbarea poveștii profitului și a modelului de afaceri al mai multor mărci de aplicații mobile consacrate, încă funcționează în devenire. Această noutate, la rândul său, face cu atât mai dificil pentru dezvoltatorii de aplicații mobile să gestioneze un plan de proiect ML și să îl pregătească pentru producție, ținând cont de constrângerile de timp și costuri.
O soluție ( probabil singura soluție ) la această dificultate este estimarea proiectului aplicației Machine Learning în alb și negru a timpului, costului și a rezultatelor.
Dar înainte de a ne îndrepta spre acele secțiuni, să vedem mai întâi ce face ca dificultatea și arderea lumânărilor de noapte să merite.
De ce aplicația dvs. are nevoie de un cadru de învățare automată?
S-ar putea să vă gândiți cum de vorbim despre cadru la mijlocul estimărilor de timp, cost și livrabile.
Dar adevăratul motiv din spatele timpului și al costului constă aici, care ne informează despre motivul nostru din spatele dezvoltării aplicației. Indiferent dacă aveți nevoie de învățare automată pentru:
Pentru a oferi o experiență personalizată
Pentru încorporarea căutării avansate m
Pentru prezicerea comportamentului utilizatorului
Pentru o mai bună securitate
Pentru implicarea profundă a utilizatorilor
Pe baza acestor motive, timpul, costul și livrarea vor depinde în mod corespunzător.
Tipuri de modele de învățare automată
Ce tip de model ați lua în considerare pentru a ajusta timpul și costul? Daca nu stii, ti-am oferit informatii pentru ca tu sa intelegi si sa alegi modele, in functie de cerintele si bugetul tau.
Învățarea automată, printre diferitele sale cazuri de utilizare, poate fi clasificată în trei tipuri de modele, care joacă un rol în transformarea aplicațiilor rudimentare în aplicații mobile inteligente – Supervizat, Nesupravegheat și Reinforcement. Cunoașterea a ceea ce reprezintă aceste modele de învățare automată este ceea ce ajută la definirea modului de dezvoltare a unei aplicații activate ML.
Învățare supravegheată
Este procesul în care sistemul este furnizat cu date în care intrările algoritmului și ieșirile lor sunt etichetate corect. Deoarece informațiile de intrare și de ieșire sunt etichetate, sistemul este antrenat să identifice tiparele în date în cadrul algoritmului.
Ea devine cu atât mai benefică cu cât este folosită pentru a prezice rezultatul pe baza datelor de intrare viitoare. Un exemplu în acest sens poate fi văzut atunci când rețelele sociale recunosc fața cuiva atunci când sunt etichetate într-o fotografie.
Învățare nesupravegheată
În cazul învățării nesupravegheate, datele sunt alimentate în sistem, dar rezultatele sale nu sunt etichetate ca în cazul modelului supravegheat. Acesta permite sistemului să identifice datele și să determine modele din informații. Odată ce modelele sunt stocate, toate intrările viitoare sunt alocate modelului pentru producerea unei ieșiri.
Un exemplu al acestui model poate fi văzut în cazurile în care rețelele de socializare oferă prietenilor sugestii pe baza mai multor date cunoscute, cum ar fi demografia, studiile etc.
Consolidarea învățării
Ca și în cazul învățării nesupravegheate, datele care sunt date sistemului în învățarea prin întărire nu sunt, de asemenea, etichetate. Ambele tipuri de învățare automată diferă pe motiv că, atunci când se produce o ieșire corectă, sistemului i se spune că rezultatul este corect. Acest tip de învățare permite sistemului să învețe din mediu și experiențe.
Un exemplu în acest sens poate fi văzut în Spotify. Aplicația Spotify face o recomandare pentru melodii pe care utilizatorii trebuie să le dea fie degetul în sus, fie în jos. Pe baza selecției, aplicația Spotify învață gustul utilizatorilor în muzică.
Ciclul de viață al unui proiect de învățare automată
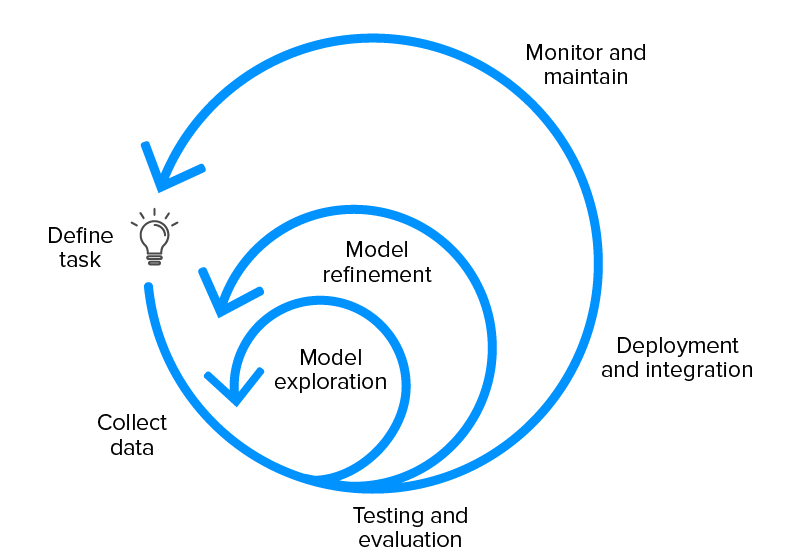
Ciclul de viață al livrabililor unui proiect de învățare automată arată de obicei astfel:
Configurarea planului de proiect ML
- Definiți sarcina și cerințele
- Identificați fezabilitatea proiectului
- Discutați compromisurile generale ale modelului
- Creați o bază de cod de proiect
Colectarea și etichetarea datelor
- Creați documentația de etichetare
- Construiți conducta de absorbție a datelor
- Validarea calității datelor
Explorarea modelului
- Stabiliți linia de bază pentru performanța modelului
- Creați un model simplu cu conducta inițială de date
- Încercați idei paralele în primele etape
- Găsiți modelul SoTA pentru domeniul problemei, dacă există, și reproduceți rezultatele.
Rafinarea modelului
- Faceți optimizări centrate pe model
- Depanați modelele pe măsură ce se adaugă complexitatea
- Efectuați o analiză a erorilor pentru a descoperi modurile de defecțiune.
Testați și evaluați
- Evaluați modelul pe distribuția testului
- Revizuiți metrica de evaluare a modelului, asigurându-vă că aceasta generează comportamentul dorit al utilizatorului
- Scrieți teste pentru – funcție de inferență a modelului, pipeline de date de intrare, scenarii explicite așteptate în producție.
Implementarea modelului
- Expuneți modelul prin API-ul REST
- Implementați noul model unui subset de utilizatori pentru a vă asigura că totul este fără probleme înainte de lansarea finală.
- Aveți posibilitatea de a reveni la modelele la versiunea anterioară
- Monitorizați datele în direct.
Întreținere model
- Reantrenați modelul pentru a preveni învechirea modelului
- Educați echipa dacă există un transfer în proprietatea modelului
Cum se estimează domeniul de aplicare al unui proiect de învățare automată?
Echipa Appinventiv Machine Learning, după ce a analizat tipul Machine Learning și ciclul de viață de dezvoltare , continuă să definească estimarea proiectului aplicației Machine Learning a proiectului, urmând aceste faze:
Faza 1 – Descoperire (7 până la 14 zile)
Foaia de parcurs al planului de proiect ML începe cu definirea unei probleme. Acesta analizează problemele și ineficiențele operaționale care ar trebui abordate.
Scopul aici este de a identifica cerințele și de a vedea dacă Machine Learning îndeplinește obiectivele de afaceri . Etapa necesită inginerii noștri să se întâlnească cu oamenii de afaceri din partea clientului pentru a le înțelege viziunea în ceea ce privește problemele pe care doresc să le rezolve.
În al doilea rând, echipa de dezvoltare ar trebui să identifice ce fel de date au și dacă ar trebui să le preia de la un serviciu extern.
În continuare, dezvoltatorii trebuie să evalueze dacă sunt capabili să supravegheze algoritmii – dacă returnează răspunsul corect de fiecare dată când se face o predicție.
Livrabil – O declarație de problemă care ar defini dacă un proiect este banal sau ar fi complex.
Faza 2 – Explorare (6 până la 8 săptămâni)
Scopul acestei etape este de a construi pe o Proof of Concept care poate fi apoi instalată ca API. Odată ce un model de bază este instruit, echipa noastră de experți ML estimează performanța soluției pregătite pentru producție.
Această etapă ne oferă claritate cu privire la ce performanță ar trebui să ne așteptăm cu valorile planificate în etapa de descoperire.
Livrabil – O dovadă a conceptului
Faza 3 – Dezvoltare (4+ luni)
Aceasta este etapa în care echipa lucrează în mod iterativ până când ajunge la un răspuns gata de producție. Deoarece există mult mai puține incertitudini până în momentul în care proiectul ajunge la această etapă, estimarea devine foarte precisă.
Dar în cazul în care rezultatul nu este îmbunătățit, dezvoltatorii ar trebui să aplice un model diferit sau să relueze datele sau chiar să schimbe metoda, dacă este necesar.
În această etapă, dezvoltatorii noștri lucrează în sprinturi și decid ce trebuie făcut după fiecare iterație individuală. Rezultatele fiecărui sprint pot fi prezise eficient.

În timp ce rezultatul sprintului poate fi prezis eficient, planificarea sprinturilor în avans poate fi o greșeală în cazul învățării automate, deoarece veți lucra pe ape neexplorate.
Livrabil – O soluție ML pregătită pentru producție
Faza 4 – Îmbunătățire (continuă)
Odată implementați, factorii de decizie sunt aproape întotdeauna grăbiți să încheie proiectul pentru a economisi costuri. În timp ce formula funcționează în 80% dintre proiecte, același lucru nu se aplică în aplicațiile Machine Learning.
Ceea ce se întâmplă este că datele se modifică pe parcursul cronologiei proiectului Machine Learning. Acesta este motivul pentru care un model AI trebuie monitorizat și revizuit în mod constant – pentru a-l salva de la degradare și pentru a oferi o IA sigură care să permită dezvoltarea aplicațiilor mobile .
Proiectele centrate pe Machine Learning necesită timp pentru a obține rezultate satisfăcătoare. Chiar și atunci când descoperiți că algoritmii dvs. depășesc valorile de referință chiar de la început, sunt șanse ca aceștia să fie o lovitură și programul s-ar putea pierde atunci când este utilizat pe un alt set de date.
Factori care afectează costul total
Modul de dezvoltare a unui sistem de învățare automată are câteva caracteristici distinctive, cum ar fi probleme legate de date și factori de performanță care decid ultima cheltuială.
Probleme legate de date
Dezvoltarea învățării automate de încredere nu depinde doar de codificarea fenomenală, ci și calitatea și cantitatea informațiilor de instruire joacă, de asemenea, un rol crucial.
- Lipsa datelor adecvate
- Proceduri complexe de extragere, transformare, încărcare
- Prelucrarea nestructurată a datelor
Probleme legate de performanță
Performanța adecvată a algoritmului este un alt factor important de cost, deoarece un algoritm de înaltă calitate necesită mai multe runde de sesiuni de reglare.
- Rata de precizie variază
- Performanța algoritmilor de procesare
Cum estimăm costul unui proiect de învățare automată?
Când vorbim despre estimarea costului unui proiect de învățare automată, este important să identificăm mai întâi despre ce tip de proiect se vorbește.
Există în principal trei tipuri de proiecte de învățare automată , care au un rol în a răspunde Cât costă învățarea automată:
În primul rând – Acest tip are deja o soluție – ambele: arhitectura modelului și setul de date există deja. Aceste tipuri de proiecte sunt practic gratuite, așa că nu vom vorbi despre ele.
În al doilea rând – Aceste proiecte necesită cercetare fundamentală – aplicarea ML într-un domeniu complet nou sau pe diferite structuri de date în comparație cu modelele mainstream. Costul acestor tipuri de proiecte este de obicei unul pe care majoritatea startup-urilor nu și-l pot permite.
În al treilea rând - Acestea sunt cele asupra cărora ne vom concentra în estimarea costurilor. Aici, luați arhitectura modelului și algoritmii care există deja și apoi le modificați pentru a se potrivi cu datele la care lucrați.
Să ajungem acum la partea în care estimăm costul proiectului ML.
Costul datelor
Datele sunt moneda principală a unui proiect de învățare automată. Maximul soluțiilor și cercetării se concentrează pe variațiile modelului de învățare supravegheată. Este un fapt binecunoscut că, cu cât învățarea supravegheată este mai profundă, cu atât este mai mare nevoia de date adnotate și, la rândul său, cu atât costul dezvoltării aplicației Machine Learning este mai mare .
Acum, în timp ce servicii precum Scale și Amazon's Mechanical Turk vă pot ajuta cu colectarea și adnotarea datelor, cum rămâne cu calitatea?
Verificarea și apoi corectarea eșantioanelor de date poate fi extrem de consumatoare. Soluția problemei are două fronturi – fie externalizați colectarea datelor, fie o rafinați intern.
Ar trebui să externalizați cea mai mare parte a activității de validare și rafinare a datelor și apoi să numiți una sau două persoane interne pentru curățarea mostrelor de date și etichetarea acestora.
Costul cercetării
Partea de cercetare a proiectului, așa cum am împărtășit mai sus, tratează studiul de fezabilitate la nivel de intrare, căutarea algoritmului și faza de experimentare. Informațiile care apar de obicei dintr-un atelier de livrare a produselor . Practic, etapa exploratorie este cea prin care trece fiecare proiect înainte de producerea sa.
Finalizarea etapei cu cea mai mare perfecțiune este un proces care vine cu un număr atașat în costul implementării discuției ML.
Costul de producție
Partea de producție a costului proiectului Machine Learning este alcătuită din costul infrastructurii, costul de integrare și costul de întreținere. Dintre aceste costuri, va trebui să faceți cele mai puține cheltuieli cu calculul cloud. Dar și asta va varia de la complexitatea unui algoritm la altul.
Costul de integrare variază de la un caz de utilizare la altul. De obicei, este suficient să puneți un punct final API în cloud și să îl documentați pentru a fi apoi utilizat de restul sistemului.
Un factor cheie pe care oamenii tind să-l ignore atunci când dezvoltă un proiect de învățare automată este necesitatea de a acorda suport continuu pe parcursul întregului ciclu de viață al proiectului. Datele care vin de la API-uri trebuie să fie curățate și adnotate corespunzător. Apoi, modelele trebuie să fie instruite pe date noi și testate, implementate.
În plus față de punctele menționate mai sus, mai există doi factori care au importanță pentru estimarea costului dezvoltării unei aplicații AI/ML .
Provocări în dezvoltarea aplicațiilor de învățare automată

De obicei, atunci când se întocmește o estimare a unui proiect de aplicație Machine Learning, provocările de dezvoltare asociate cu aceasta sunt de asemenea luate în considerare. Dar pot exista cazuri în care provocările se găsesc la jumătatea procesului de dezvoltare a aplicațiilor bazate pe ML. În astfel de cazuri, timpul general și estimarea costurilor crește automat.
Provocările pentru proiectele de învățare automată pot varia de la:
- Decizia ce set de caracteristici ar deveni caracteristici de învățare automată
- Deficit de talent în domeniul AI și Machine Learning
- Achiziția de seturi de date este costisitoare
- Este nevoie de timp pentru a obține rezultate satisfăcătoare
Concluzie
Estimarea forței de muncă și a timpului necesar pentru a finaliza un proiect software este relativ ușoară atunci când acesta este dezvoltat pe baza unor proiecte modulare și este gestionat de o echipă cu experiență, urmând o abordare Agile . Același lucru, totuși, devine cu atât mai dificil atunci când lucrați la crearea estimării proiectului aplicației Machine Learning în funcție de timp și eforturi.
Chiar dacă obiectivele ar putea fi bine definite, garanția dacă un model va obține sau nu rezultatul dorit nu există. De obicei, nu este posibil să reduceți domeniul de aplicare și apoi să rulați proiectul într-o setare de timp, printr-o dată de livrare predefinită.
Este de primă importanță să identificați că vor exista incertitudini. O abordare care poate ajuta la atenuarea întârzierilor este asigurarea faptului că datele de intrare sunt în formatul potrivit pentru învățarea automată.
Dar, în cele din urmă, indiferent de abordarea pe care intenționați să o urmați, aceasta va fi considerată de succes numai atunci când vă asociați cu o agenție de dezvoltare a aplicațiilor Machine Learning care știe să dezvolte și să implementeze complexitățile în cea mai simplă formă.
Întrebări frecvente despre estimarea proiectului aplicației Machine Learning
Î. De ce să folosiți Machine Learning în dezvoltarea unei aplicații?
Există o serie de beneficii pe care companiile le pot beneficia prin încorporarea Machine Learning în aplicațiile lor mobile. Unele dintre cele mai răspândite sunt pe frontul marketingului de aplicații –
- Oferă experiență personalizată
- Cautare Avansata
- Prezicerea comportamentului utilizatorului
- Implicarea mai profundă a utilizatorilor
Î. Cum vă poate ajuta învățarea automată afacerea?
Beneficiile învățării automate pentru companii depășesc marcarea lor ca un brand perturbator. Se reduce la ofertele lor, care devin mai personalizate și în timp real.
Machine Learning poate fi formula secretă care aduce afacerile mai aproape de clienții lor, exact cum doresc să fie abordați.
Î. Cum se estimează rentabilitatea investiției la dezvoltarea unui proiect de învățare automată?
În timp ce articolul v-ar fi ajutat să stabiliți estimarea proiectului aplicației Machine Learning, calcularea rentabilității investiției este un joc diferit. Va trebui să țineți cont și de costul de oportunitate în amestec. În plus, va trebui să te uiți la așteptările pe care le are afacerea ta de la proiect.
Î. Ce platformă este mai bună pentru un proiect ML?
Alegerea dvs. de a vă conecta cu o companie de dezvoltare de aplicații pentru Android sau cu dezvoltatori iOS va depinde în totalitate de baza dvs. de utilizatori și de intenție - dacă este vorba de profit sau de valoare.