
Un ghid SEO pentru înțelegerea modelelor lingvistice mari (LLM)
Publicat: 2023-05-08Ar trebui să folosesc modele lingvistice mari pentru cercetarea cuvintelor cheie? Pot să gândească aceste modele? ChatGPT este prietenul meu?
Dacă ți-ai pus aceste întrebări, acest ghid este pentru tine.
Acest ghid acoperă ceea ce trebuie să știe SEO-ul despre modelele mari de limbaj, procesarea limbajului natural și tot ce se află între ele.
Modele mari de limbaj, procesare a limbajului natural și multe altele în termeni simpli
Există două modalități de a determina o persoană să facă ceva – spuneți-i să o facă sau sperați că o va face singur.
Când vine vorba de informatică, programarea îi spune robotului să o facă, în timp ce învățarea automată speră ca robotul să o facă singur. Prima este învățarea automată supravegheată, iar cea de-a doua este învățarea automată nesupravegheată.
Procesarea limbajului natural (NLP) este o modalitate de a descompune textul în numere și apoi de a-l analiza folosind computere.
Calculatoarele analizează tiparele în cuvinte și, pe măsură ce acestea devin mai avansate, în relațiile dintre cuvinte.
Un model de învățare automată a limbajului natural nesupravegheat poate fi antrenat pe multe tipuri diferite de seturi de date.
De exemplu, dacă ați antrenat un model de limbă pe recenzii medii ale filmului „Waterworld”, veți avea un rezultat bun la scrierea (sau înțelegerea) recenziilor filmului „Waterworld”.
Dacă l-ai instrui pe cele două recenzii pozitive pe care le-am făcut pentru filmul „Waterworld”, ar înțelege doar acele recenzii pozitive.
Modelele de limbaj mari (LLM) sunt rețele neuronale cu peste un miliard de parametri. Sunt atât de mari încât sunt mai generalizate. Ei nu sunt instruiți doar pentru recenzii pozitive și negative pentru „Waterworld”, ci și pentru comentarii, articole Wikipedia, site-uri de știri și multe altele.
Proiectele de învățare automată funcționează foarte mult cu context - lucruri în și în afara contextului.
Dacă aveți un proiect de învățare automată care funcționează pentru a identifica erori și a-i arăta o pisică, nu va fi bun la acel proiect.
Acesta este motivul pentru care lucruri precum mașinile autonome sunt atât de dificile: există atât de multe probleme în afara contextului încât este foarte dificil să generalizezi aceste cunoștințe.
LLM-urile par și pot fi mult mai generalizat decât alte proiecte de învățare automată. Acest lucru se datorează dimensiunii mari a datelor și capacității de a analiza miliarde de relații diferite.
Să vorbim despre una dintre tehnologiile inovatoare care permit acest lucru - transformatoarele.
Explicarea transformatoarelor de la zero
Un tip de arhitectură de rețele neuronale, transformatoarele au revoluționat domeniul NLP.
Înainte de transformare, majoritatea modelelor NLP se bazau pe o tehnică numită rețele neuronale recurente (RNN), care procesa textul secvenţial, câte un cuvânt. Această abordare a avut limitările sale, cum ar fi să fie lentă și să se străduiască să gestioneze dependențele pe termen lung în text.
Transformers au schimbat asta.
În lucrarea de referință din 2017, „Atenția este tot ce aveți nevoie”, Vaswani și colab. a introdus arhitectura transformatorului.
În loc să proceseze textul secvențial, transformatoarele folosesc un mecanism numit „auto-atenție” pentru a procesa cuvintele în paralel, permițându-le să capteze mai eficient dependențele pe distanță lungă.
Arhitectura anterioară includea RNN-uri și algoritmi de memorie pe termen scurt.
Modelele recurente ca acestea au fost (și sunt încă) utilizate în mod obișnuit pentru sarcini care implică secvențe de date, cum ar fi textul sau vorbirea.
Cu toate acestea, aceste modele au o problemă. Ei pot procesa datele doar o bucată la un moment dat, ceea ce le încetinește și limitează cantitatea de date cu care pot lucra. Această procesare secvenţială limitează cu adevărat capacitatea acestor modele.
Mecanismele de atenție au fost introduse ca o modalitate diferită de procesare a datelor secvențe. Acestea permit unui model să analizeze toate datele simultan și să decidă care sunt cele mai importante.
Acest lucru poate fi cu adevărat util în multe sarcini. Cu toate acestea, majoritatea modelelor care au folosit atenția folosesc și procesare recurentă.
Practic, aveau acest mod de a procesa datele dintr-o dată, dar tot trebuiau să le privească în ordine. Lucrarea lui Vaswani și colab. plutea: „Dacă am folosi doar mecanismul atenției?”
Atenția este o modalitate prin care modelul se concentrează asupra anumitor părți ale secvenței de intrare atunci când o procesează. De exemplu, atunci când citim o propoziție, în mod natural acordăm mai multă atenție unor cuvinte decât altora, în funcție de context și de ceea ce vrem să înțelegem.
Dacă te uiți la un transformator, modelul calculează un scor pentru fiecare cuvânt din secvența de intrare, în funcție de cât de important este acesta pentru înțelegerea sensului general al secvenței.
Modelul folosește apoi aceste scoruri pentru a cântări importanța fiecărui cuvânt din secvență, permițându-i să se concentreze mai mult pe cuvintele importante și mai puțin pe cele neimportante.
Acest mecanism de atenție ajută modelul să capteze dependențe și relații pe distanță lungă între cuvinte care ar putea fi departe unul de celălalt în secvența de intrare, fără a fi nevoie să proceseze întreaga secvență secvenţial.
Acest lucru face ca transformatorul să fie atât de puternic pentru sarcinile de procesare a limbajului natural, deoarece poate înțelege rapid și precis sensul unei propoziții sau al unei secvențe mai lungi de text.
Să luăm exemplul unui model de transformator care prelucrează propoziția „Pisica s-a așezat pe covoraș”.
Fiecare cuvânt din propoziție este reprezentat ca un vector, o serie de numere, folosind o matrice de încorporare. Să presupunem că înglobările pentru fiecare cuvânt sunt:
- Cele : [0,2, 0,1, 0,3, 0,5]
- pisică : [0,6, 0,3, 0,1, 0,2]
- sat : [0,1, 0,8, 0,2, 0,3]
- activat : [0,3, 0,1, 0,6, 0,4]
- : [0,5, 0,2, 0,1, 0,4]
- mat : [0,2, 0,4, 0,7, 0,5]
Apoi, transformatorul calculează un scor pentru fiecare cuvânt din propoziție pe baza relației sale cu toate celelalte cuvinte din propoziție.
Acest lucru se face folosind produsul punctual al înglobării fiecărui cuvânt cu încorporarea tuturor celorlalte cuvinte din propoziție.
De exemplu, pentru a calcula scorul pentru cuvântul „pisica”, am lua produsul punctual al înglobării sale cu înglobarea tuturor celorlalte cuvinte:
- „ Pisica ”: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- „ pisica așezată ”: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- „ pisică pe „: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- „ pisica „: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- „ covoraș pentru pisici ”: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Aceste scoruri indică relevanța fiecărui cuvânt pentru cuvântul „pisica”. Apoi, transformatorul folosește aceste scoruri pentru a calcula o sumă ponderată a înglobărilor de cuvinte, unde ponderile sunt scorurile.
Acest lucru creează un vector de context pentru cuvântul „pisica” care ia în considerare relațiile dintre toate cuvintele din propoziție. Acest proces se repetă pentru fiecare cuvânt din propoziție.
Gândiți-vă la asta ca la transformatorul care desenează o linie între fiecare cuvânt din propoziție pe baza rezultatului fiecărui calcul. Unele linii sunt mai slabe, iar altele mai puțin.
Transformatorul este un nou tip de model care folosește doar atenția fără nicio prelucrare recurentă. Acest lucru îl face mult mai rapid și capabil să gestioneze mai multe date.
Cum folosește GPT transformatoarele
Poate vă amintiți că în anunțul BERT de la Google, ei s-au lăudat că a permis căutării să înțeleagă contextul complet al unei intrări. Acest lucru este similar cu modul în care GPT poate folosi transformatoare.
Să folosim o analogie.
Imaginează-ți că ai un milion de maimuțe, fiecare stând în fața unei tastaturi.
Fiecare maimuță lovește aleatoriu tastele de pe tastatură, generând șiruri de litere și simboluri.
Unele șiruri sunt o prostie completă, în timp ce altele ar putea să semene cu cuvinte reale sau chiar propoziții coerente.
Într-o zi, unul dintre antrenorii de circ vede că o maimuță a scris „A fi sau a nu fi”, așa că dresorul îi oferă maimuței un răsfăț.
Celelalte maimuțe văd asta și încep să încerce să imite maimuța de succes, sperând să primească propria lor răsfăț.
Pe măsură ce trece timpul, unele maimuțe încep să producă în mod constant șiruri de text mai bune și mai coerente, în timp ce altele continuă să producă farfurie.
În cele din urmă, maimuțele pot recunoaște și chiar emula modele coerente în text.
LLM-urile au un pas în fața maimuțelor, deoarece LLM-urile sunt mai întâi antrenate pe miliarde de bucăți de text. Ei pot vedea deja modelele. Ei înțeleg, de asemenea, vectorii și relațiile dintre aceste bucăți de text.
Aceasta înseamnă că pot folosi acele modele și relații pentru a genera text nou care seamănă cu limbajul natural.
GPT, care înseamnă Generative Pre-trained Transformer, este un model de limbaj care utilizează transformatoare pentru a genera text în limbaj natural.
A fost instruit pe o cantitate masivă de text de pe internet, ceea ce i-a permis să învețe tiparele și relațiile dintre cuvinte și expresii în limbaj natural.
Modelul funcționează prin preluarea unui prompt sau câteva cuvinte de text și folosind transformatoarele pentru a prezice ce cuvinte ar trebui să urmeze pe baza tiparelor pe care le-a învățat din datele sale de antrenament.
Modelul continuă să genereze text cuvânt cu cuvânt, folosind contextul cuvintelor anterioare pentru a le informa pe următoarele.
GPT în acțiune
Unul dintre avantajele GPT este că poate genera text în limbaj natural care este extrem de coerent și relevant din punct de vedere contextual.
Aceasta are multe aplicații practice, cum ar fi generarea de descrieri de produse sau răspunsul la întrebările de la serviciul clienți. Poate fi folosit și în mod creativ, cum ar fi generarea de poezie sau povestiri scurte.
Cu toate acestea, este doar un model de limbaj. Este instruit pe date, iar acele date pot fi depășite sau incorecte.
- Nu are sursa de cunoastere.
- Nu poate căuta pe internet.
- Nu „știe” nimic.
Pur și simplu ghicește ce cuvânt urmează.
Să ne uităm la câteva exemple:
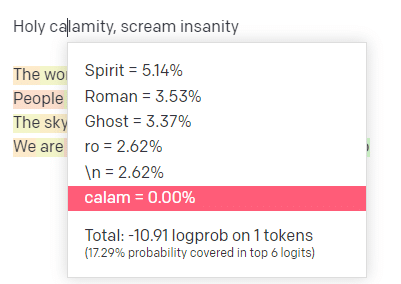
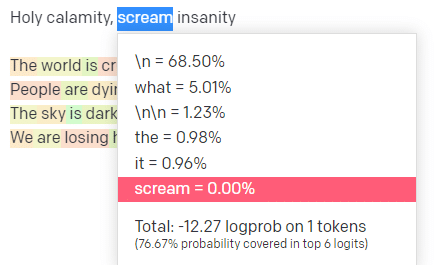
În locul de joacă OpenAI, am conectat prima linie a piesei clasice Handsome Boy Modeling School „Holy calamity [[Bear Witness ii]]”.
Am trimis răspunsul, astfel încât să putem vedea probabilitatea atât a liniilor mele de intrare, cât și a celor de ieșire. Deci, să trecem prin fiecare parte a ceea ce ne spune asta.
Pentru primul cuvânt/semn, am introdus „Sfânt”. Putem vedea că următoarea intrare cea mai așteptată este Spirit, Roman și Ghost.
De asemenea, putem vedea că primele șase rezultate acoperă doar 17,29% din probabilitățile a ceea ce urmează: ceea ce înseamnă că există ~82% alte posibilități pe care nu le putem vedea în această vizualizare.
Să discutăm pe scurt despre diferitele intrări pe care le puteți utiliza în acest sens și despre modul în care acestea vă afectează rezultatul.
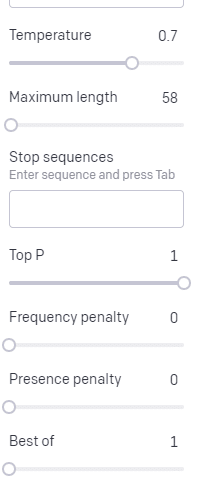
Temperatura este probabilitatea ca modelul să prindă alte cuvinte decât cele cu cea mai mare probabilitate, P superior este modul în care selectează acele cuvinte.
Așadar, pentru intrarea „Holy Calamity”, partea de sus P este modul în care selectăm grupul de jetoane următoare [Ghost, Roman, Spirit], iar temperatura este cât de probabil este să meargă pentru simbolul cel mai probabil față de mai multă varietate.
Dacă temperatura este mai mare, este mai probabil să alegeți un simbol mai puțin probabil .
Așadar, o temperatură ridicată și un P superior ridicat vor fi probabil mai sălbatice. Este alegerea dintr-o varietate mare (P înalt) și este mai probabil să aleagă jetoane surprinzătoare.


În timp ce o temperatură ridicată, dar mai scăzută, P superior va alege opțiuni surprinzătoare dintr-un eșantion mai mic de posibilități:

Și scăderea temperaturii alege doar următoarele simboluri cele mai probabile:

Jocul cu aceste probabilități poate, în opinia mea, să vă ofere o perspectivă bună asupra modului în care funcționează aceste tipuri de modele.
Se uită la o colecție de selecții viitoare probabile bazate pe ceea ce este deja finalizat.
Ce înseamnă asta de fapt?
Mai simplu spus, LLM-urile preiau o colecție de intrări, le zguduie și le transformă în ieșiri.
Am auzit oameni glumând dacă asta este atât de diferit de oameni.
Dar nu este ca oamenii – LLM-urile nu au o bază de cunoștințe. Ei nu extrag informații despre un lucru. Ei ghicesc o secvență de cuvinte bazată pe ultimul.
Un alt exemplu: gândiți-vă la un măr. Ce imi vine in minte?
Poate poți roti unul în mintea ta.
Poate vă amintiți mirosul unei livezi de meri, dulceața unei doamne roz etc.
Poate te gândești la Steve Jobs.
Acum să vedem ce se întoarce un prompt „gândește-te la un măr”.
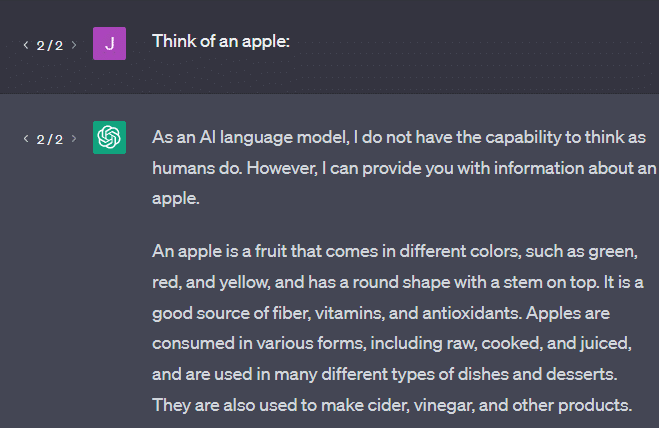
S-ar putea să fi auzit cuvintele „Papagali Stochastici” plutind până în acest moment.
Stochastic Parrots este un termen folosit pentru a descrie LLM-uri precum GPT. Un papagal este o pasăre care imită ceea ce aude.
Deci, LLM-urile sunt ca papagalii, prin aceea că preiau informații (cuvinte) și scot ceva care seamănă cu ceea ce au auzit. Dar sunt și stocastici , ceea ce înseamnă că folosesc probabilitatea pentru a ghici ce urmează.
LLM-urile sunt bune la recunoașterea tiparelor și a relațiilor dintre cuvinte, dar nu au o înțelegere mai profundă a ceea ce văd. De aceea, sunt atât de buni la generarea de text în limbaj natural, dar nu îl înțeleg.
Utilizări bune pentru un LLM
LLM-urile sunt bune la sarcini mai generaliste.
Îi poți arăta text și, fără antrenament, poate face o sarcină cu acel text.
Puteți să-i aruncați niște text și să cereți o analiză a sentimentelor, să îi cereți să transfere acel text într-un marcaj structurat și să faceți ceva creație (de exemplu, scrierea contururilor).
Este OK la chestii precum codul. Pentru multe sarcini, aproape te poate duce acolo.
Dar din nou, se bazează pe probabilitate și modele. Așa că vor exista momente în care va prelua modele din intrarea dvs. despre care nu știți că există.
Acest lucru poate fi pozitiv (văzând modele pe care oamenii nu le pot), dar poate fi și negativ (de ce a răspuns așa?).
De asemenea, nu are acces la nici un fel de surse de date. SEO care îl folosește pentru a căuta cuvinte cheie de clasare se vor distra.
Nu poate căuta trafic pentru un cuvânt cheie. Nu are informații pentru datele cuvintelor cheie dincolo de faptul că există cuvinte.

Lucrul interesant despre ChatGPT este că este un model de limbă ușor de disponibil pe care îl puteți folosi imediat pentru diverse sarcini. Dar nu este lipsit de avertismente.

Utilizări bune pentru alte modele ML
Am auzit oameni spunând că folosesc LLM-uri pentru anumite sarcini, pe care alți algoritmi și tehnici NLP le pot face mai bine.
Să luăm un exemplu, extragerea cuvintelor cheie.
Dacă folosesc TF-IDF, sau o altă tehnică de cuvinte cheie, pentru a extrage cuvinte cheie dintr-un corpus, știu ce calcule sunt folosite în acea tehnică.
Aceasta înseamnă că rezultatele vor fi standard, reproductibile și știu că vor fi legate în mod specific de corpus respectiv.
Cu LLM-uri precum ChatGPT, dacă solicitați extragerea cuvintelor cheie, nu obțineți neapărat cuvintele cheie extrase din corpus. Obțineți ceea ce crede GPT că ar fi un răspuns la cuvintele cheie corpus + extract.
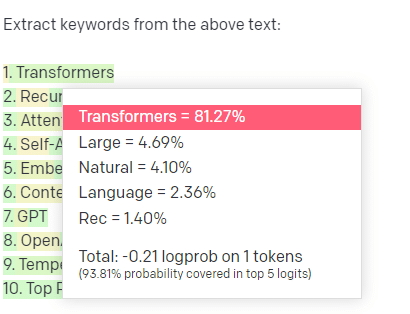
Acest lucru este similar cu sarcini precum gruparea sau analiza sentimentelor. Nu obțineți neapărat rezultatul reglat fin cu parametrii pe care îi setați. Obțineți ceea ce există probabilitate pe baza altor sarcini similare.
Din nou, LLM-urile nu au nicio bază de cunoștințe și nici informații actuale. De multe ori nu pot căuta pe web și analizează ceea ce obțin din informații ca simboluri statistice. Restricțiile privind durata memoriei unui LLM sunt din cauza acestor factori.
Un alt lucru este că aceste modele nu pot gândi. Folosesc cuvântul „gândește” doar de câteva ori pe parcursul acestei piese, deoarece este foarte dificil să nu îl folosesc când vorbesc despre aceste procese.
Tendința este către antropomorfism, chiar și atunci când discutăm despre statistici fanteziste.
Dar asta înseamnă că, dacă încredințați un LLM oricărei sarcini care necesită „gândire”, nu aveți încredere într-o creatură care gândește.
Aveți încredere într-o analiză statistică a cu ce răspund sute de ciudați de pe internet la token-uri similare.
Dacă ai avea încredere în locuitorii internetului cu o sarcină, atunci poți folosi un LLM. In caz contrar…
Lucruri care nu ar trebui să fie niciodată modele ML
Un chatbot rulat printr-un model GPT (GPT-J) a încurajat un bărbat să se sinucidă. Combinația de factori poate provoca un rău real, inclusiv:
- Oameni care antropomorfizează aceste răspunsuri.
- Crezându-i infailibili.
- Folosindu-le în locuri în care oamenii trebuie să fie în mașină.
- Și altele.
În timp ce vă puteți gândi, „Sunt SEO. Nu am nicio mână în sisteme care ar putea ucide pe cineva!”
Gândiți-vă la paginile YMYL și la modul în care Google promovează concepte precum EEAT.
Face Google acest lucru pentru că vrea să enerveze SEO sau pentru că nu doresc vinovăția acelui rău?
Chiar și în sistemele cu baze solide de cunoștințe, se poate face rău.
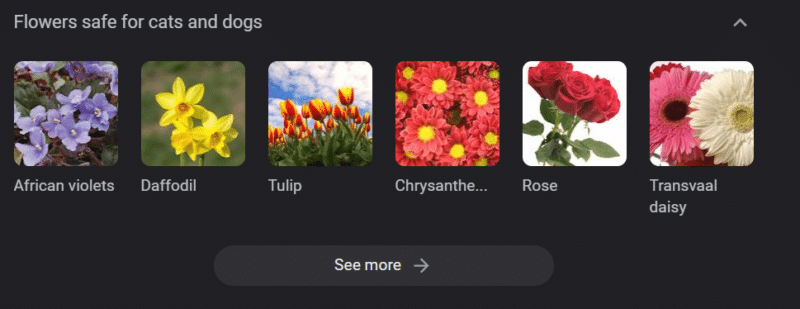
Cele de mai sus este un carusel de cunoștințe Google pentru „flori sigure pentru pisici și câini”. Narcisele sunt pe această listă, în ciuda faptului că sunt toxice pentru pisici.
Să presupunem că generați conținut pentru un site web veterinar la scară folosind GPT. Conectați o grămadă de cuvinte cheie și trimiteți ping la API-ul ChatGPT.
Ai un freelancer care citește toate rezultatele și nu este un expert în subiect. Ei nu înțeleg o problemă.
Publicați rezultatul, care încurajează cumpărarea de narcise pentru proprietarii de pisici.
Ucizi pisica cuiva.
Nu direct. Poate că ei nici măcar nu știu că a fost site-ul respectiv.
Poate că celelalte site-uri veterinare încep să facă același lucru și să se hrănească reciproc.
Primul rezultat al căutării Google pentru „sunt narcise toxice pentru pisici” este un site care spune că nu sunt.
Alți freelanceri care citesc alte conținuturi AI – pagini peste pagini de conținut AI – verifică de fapt. Dar sistemele au acum informații incorecte.
Când discutăm despre acest boom actual al AI, menționez foarte mult Therac-25. Este un studiu de caz faimos al abaterilor informatice.
Practic, a fost un aparat de radioterapie, primul care a folosit doar mecanisme de blocare computerizate. O eroare a software-ului a însemnat că oamenii au doza de radiații de zeci de mii de ori mai mare decât ar trebui să o aibă.
Ceva care îmi iese mereu în evidență este că compania a rechemat și a inspectat în mod voluntar aceste modele.
Dar ei au presupus că, deoarece tehnologia era avansată și software-ul era „infailibil”, problema avea de-a face cu piesele mecanice ale mașinii.
Astfel, au reparat mecanismele, dar nu au verificat software-ul – iar Therac-25 a rămas pe piață.
Întrebări frecvente și concepții greșite
De ce mă minte ChatGPT?
Un lucru pe care l-am văzut de la unele dintre cele mai mari minți ale generației noastre și, de asemenea, de la influenți de pe Twitter este o plângere că ChatGPT le „mintește”. Acest lucru se datorează unor concepții greșite în tandem:
- Că ChatGPT are „dorințe”.
- Că are o bază de cunoștințe.
- Că tehnologii din spatele tehnologiei au un fel de agendă dincolo de „a face bani” sau „a face un lucru tare”.
Prejudecățile sunt incluse în fiecare parte a vieții tale de zi cu zi. La fel sunt și excepțiile de la aceste părtiniri.
Majoritatea dezvoltatorilor de software în prezent sunt bărbați: eu sunt un dezvoltator de software și o femeie.
Antrenarea unui AI bazat pe această realitate ar duce la presupunerea întotdeauna că dezvoltatorii de software sunt bărbați, ceea ce nu este adevărat.
Un exemplu celebru este AI de recrutare de la Amazon, instruit pe CV-uri de la angajații de succes Amazon.
Acest lucru a dus la eliminarea CV-urilor de la colegiile majoritare negre, chiar dacă mulți dintre acești angajați ar fi putut avea un succes extrem.
Pentru a contracara aceste prejudecăți, instrumente precum ChatGPT folosesc straturi de reglare fină. Acesta este motivul pentru care primiți răspunsul „Ca model de limbaj AI, nu pot…”.
Unii lucrători din Kenya au fost nevoiți să treacă prin sute de solicitări, căutând insulte, discurs instigator la ură și răspunsuri și sugestii de-a dreptul teribile.
Apoi a fost creat un strat de reglare fină.
De ce nu poți inventa insulte despre Joe Biden? De ce poți face glume sexiste despre bărbați și nu despre femei?
Nu se datorează părtinirii liberale, ci din cauza a mii de straturi de reglare fină care îi spune lui ChatGPT să nu rostească cuvântul N.
În mod ideal, ChatGPT ar fi complet neutru în privința lumii, dar au nevoie și de el pentru a reflecta lumea.
Este o problemă similară cu cea pe care o are Google.
Ceea ce este adevărat, ceea ce îi face pe oameni fericiți și ceea ce face un răspuns corect la o solicitare sunt adesea lucruri foarte diferite .
De ce ChatGPT vine cu citări false?
O altă întrebare pe care o văd că apare frecvent este despre citațiile false. De ce unele dintre ele sunt false și altele reale? De ce unele site-uri sunt reale, dar paginile sunt false?
Sperăm că, citind cum funcționează modelele statistice, puteți analiza acest lucru. Dar iată o scurtă explicație:
Ești un model de limbaj AI. Ai fost instruit pe o mulțime de web.
Cineva îți spune să scrii despre un lucru tehnologic – să spunem Cumulative Layout Shift.
Nu aveți o mulțime de exemple de lucrări CLS, dar știți ce este și cunoașteți forma generală a unui articol despre tehnologii. Știți modelul cum arată acest tip de articol.

Așa că începi cu răspunsul tău și te confrunți cu un fel de problemă. În felul în care înțelegeți scrierea tehnică, știți că o adresă URL ar trebui să urmeze următoarea propoziție.
Ei bine, din alte articole CLS, știți că Google și GTMetrix sunt adesea citate despre CLS, așa că acestea sunt ușor.
Dar știți, de asemenea, că CSS-tricks este adesea legat de articolele web: știți că, de obicei, adresele URL CSS-tricks arată într-un anumit fel: deci puteți construi o adresă URL CSS-tricks astfel:
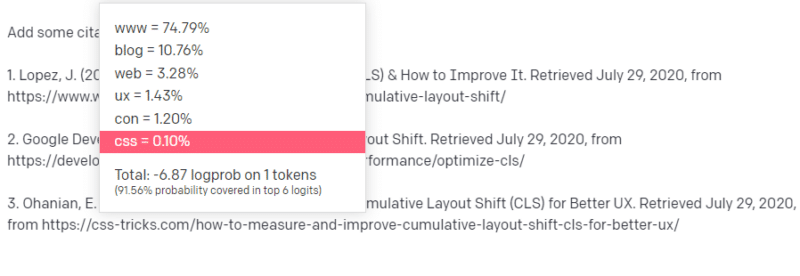
Trucul este: așa sunt construite toate URL-urile, nu doar cele false:

Acest articol GTMetrix există: dar există pentru că era un șir probabil de valori care urmează să apară la sfârșitul acestei propoziții.
GPT și modelele similare nu pot face distincția între o citare reală și una falsă.
Singura modalitate de a face această modelare este să utilizați alte surse (baze de cunoștințe, Python etc.) pentru a analiza acea diferență și a verifica rezultatele.
Ce este un „Papagal Stochastic”?
Știu că am trecut deja peste asta, dar merită repetat. Papagalii stochastici sunt o modalitate de a descrie ceea ce se întâmplă atunci când modelele mari de limbaj par de natură generalistă.
Pentru LLM, prostiile și realitatea sunt aceleași. Ei văd lumea ca un economist, ca o grămadă de statistici și numere care descriu realitatea.
Știți citatul: „Există trei feluri de minciuni: minciuni, minciuni blestemate și statistici.”
LLM-urile sunt o mulțime mare de statistici.
LLM-urile par coerente, dar asta pentru că în mod fundamental vedem lucruri care par umane ca fiind umane.
În mod similar, modelul chatbot ofucă o mare parte din indicațiile și informațiile de care aveți nevoie pentru ca răspunsurile GPT să fie pe deplin coerente.
Sunt dezvoltator: încercarea de a folosi LLM-uri pentru a-mi depana codul are rezultate extrem de variabile. Dacă este o problemă similară cu cea pe care oamenii au avut-o adesea online, atunci LLM-urile pot prelua și remedia acel rezultat.
Dacă este o problemă pe care nu a mai întâlnit-o înainte sau este o mică parte din corpus, atunci nu va rezolva nimic.
De ce este GPT mai bun decât un motor de căutare?
Am formulat asta într-un mod picant. Nu cred că GPT este mai bun decât un motor de căutare. Mă îngrijorează că oamenii au înlocuit căutarea cu ChatGPT.
O parte subrecunoscută a ChatGPT este cât de mult există pentru a urma instrucțiunile. Îi poți cere să facă practic orice.
Dar amintiți-vă, totul se bazează pe următorul cuvânt statistic dintr-o propoziție, nu pe adevăr.
Deci, dacă îi pui o întrebare care nu are un răspuns bun, dar o întrebi într-un mod în care este obligat să răspundă, vei primi un răspuns slab.
Este mai reconfortant să ai un răspuns conceput pentru tine și în jurul tău, dar lumea este o masă de experiențe.
Toate intrările într-un LLM sunt tratate la fel: dar unii oameni au experiență, iar răspunsul lor va fi mai bun decât un amestec de răspunsuri ale altora.
Un expert valorează mai mult decât o mie de piese de gândire.
Este aceasta apariția AI? Skynet este aici?
Koko Gorila a fost o maimuță care a fost învățată limbajul semnelor. Cercetătorii din studii lingvistice au făcut o mulțime de cercetări care arată că maimuțele ar putea fi învățate limbajul.
Herbert Terrace a descoperit atunci că maimuțele nu puneau cap la cap propoziții sau cuvinte, ci pur și simplu își maimuțuiau pe mânuitorii lor umani.
Eliza a fost un terapeut cu mașini, unul dintre primii chatterbots (chatbots).
Oamenii au văzut-o ca pe o persoană: un terapeut în care aveau încredere și de care aveau grijă. Le-au cerut cercetătorilor să fie singuri cu ea.
Limbajul face ceva foarte specific creierului oamenilor. Oamenii aud ceva ce comunică și se așteaptă la gânduri în spatele lui.
LLM-urile sunt impresionante, dar într-un mod care arată o amploare a realizărilor umane.
LLM-urile nu au testamente. Ei nu pot scăpa. Ei nu pot încerca să cucerească lumea.
Sunt o oglindă: o reflectare a oamenilor și a utilizatorului în mod specific.
Singurul gând de acolo este o reprezentare statistică a inconștientului colectiv.
GPT a învățat o limbă întreagă de la sine?
Sundar Pichai, CEO al Google, a continuat „60 de minute” și a susținut că modelul de limbă Google a învățat bengaleza.
Modelul a fost antrenat pe acele texte. Este incorect faptul că „vorbea o limbă străină pe care nu a fost niciodată instruit să o cunoască”.
Există momente în care AI face lucruri neașteptate, dar asta în sine este de așteptat.
Când te uiți la modele și statistici la scară mare, vor exista neapărat momente când acele modele dezvăluie ceva surprinzător.
Ceea ce dezvăluie acest lucru cu adevărat este că mulți dintre cei de la C-suite și cei de marketing care vând AI și ML nu înțeleg de fapt cum funcționează sistemele.
Am auzit unii oameni care sunt foarte inteligenți vorbind despre proprietăți emergente, inteligență generală artificială (AGI) și alte lucruri futuriste.
S-ar putea să fiu doar un simplu inginer operațiuni ML de țară, dar arată cât de multă hype, promisiuni, science fiction și realitate se amestecă atunci când vorbesc despre aceste sisteme.
Elizabeth Holmes, infamul fondator al Theranos, a fost crucificată pentru că a făcut promisiuni care nu au putut fi ținute.
Dar ciclul de a face promisiuni imposibile face parte din cultura startup-ului și a câștiga bani. Diferența dintre Theranos și hype AI este că Theranos nu a putut să-l falsească pentru mult timp.
GPT este o cutie neagră? Ce se întâmplă cu datele mele din GPT?
GPT este, ca model, nu o cutie neagră. Puteți vedea codul sursă pentru GPT-J și GPT-Neo.
GPT-ul OpenAI este, totuși, o cutie neagră. OpenAI nu a și va încerca probabil să nu-și lanseze modelul, deoarece Google nu lansează algoritmul.
Dar nu pentru că algoritmul este prea periculos. Dacă ar fi adevărat, nu ar vinde abonamente API niciunui tip prost cu computer. Este din cauza valorii acelei baze de cod proprietar.
Când utilizați instrumentele OpenAI, antrenați și alimentați API-ul lor cu intrările dvs. Aceasta înseamnă că tot ce pui în OpenAI îl alimentează.
Aceasta înseamnă că oamenii care au folosit modelul GPT al OpenAI pe datele pacienților pentru a ajuta la redactarea notelor și alte lucruri au încălcat HIPAA. Aceste informații sunt acum în model și va fi extrem de dificil să le extragi.
Deoarece atât de mulți oameni întâmpină dificultăți în a înțelege acest lucru, este foarte probabil că modelul conține tone de date private, așteptând doar solicitarea potrivită pentru a-l elibera.
De ce este instruit GPT despre discursul instigator la ură?
Un alt lucru care apare des este că corpus de text GPT pe care a fost instruit include discursul instigator la ură.
Într-o oarecare măsură, OpenAI trebuie să-și antreneze modelele pentru a răspunde la discursul instigator la ură, așa că trebuie să aibă un corpus care să includă unii dintre acești termeni.
OpenAI a pretins că șterge acest tip de discurs instigator la ură din sistem, dar documentele sursă includ 4chan și tone de site-uri instigatoare la ură.
Trăiește web, absorbi părtinirea.
Nu există o modalitate ușoară de a evita acest lucru. Cum poți avea ceva să recunoască sau să înțeleagă ura, părtinirile și violența fără a le avea ca parte a setului tău de antrenament?
Cum eviți părtinirile și cum înțelegi părtinirile implicite și explicite atunci când ești un agent de mașină care selectează statistic următorul simbol dintr-o propoziție?
TL;DR
Exagerarea și dezinformarea sunt în prezent elemente majore ale boom-ului AI. Asta nu înseamnă că nu există utilizări legitime: această tehnologie este uimitoare și utilă.
Dar modul în care este comercializată tehnologia și modul în care o folosesc oamenii pot favoriza dezinformarea, plagiatul și chiar pot provoca vătămări directe.
Nu folosiți LLM-uri când viața este pe linie. Nu utilizați LLM-uri când un alt algoritm ar funcționa mai bine. Nu vă lăsați păcăliți de hype.
Este necesar să înțelegeți ce sunt și ce nu sunt LLM-urile
Vă recomand acest interviu lui Adam Conover cu Emily Bender și Timnit Gebru.
LLM-urile pot fi instrumente incredibile atunci când sunt utilizate corect. Există multe moduri în care puteți folosi LLM-urile și chiar mai multe moduri de a abuza de LLM-urile.
ChatGPT nu este prietenul tău. Este o grămadă de statistici. AGI nu este „deja aici”.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.