
Spark vs Hadoop: care cadru de date mari vă va îmbunătăți afacerea?
Publicat: 2019-09-24„Datele sunt combustibilul economiei digitale”
Întrucât companiile moderne se bazează pe grămada de date pentru a-și înțelege mai bine consumatorii și piața, tehnologiile precum Big Data câștigă un impuls uriaș.
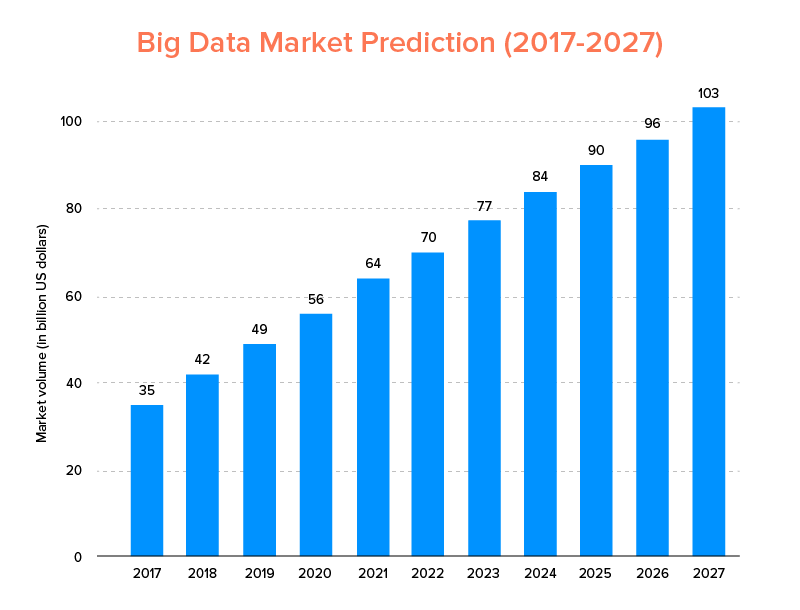
Big Data, la fel ca inteligența artificială, nu doar a intrat în lista cu tendințele tehnologice de top pentru 2020 , ci este de așteptat să fie acceptat atât de startup-uri, cât și de companiile Fortune 500 pentru a se bucura de o creștere exponențială a afacerii și pentru a asigura o loialitate mai mare a clienților. Un indiciu clar al căruia este că piața Big Data va atinge 103 miliarde USD până în 2027.
Acum, deși, pe de o parte, toată lumea este foarte motivată să își înlocuiască instrumentele tradiționale de analiză a datelor cu Big Data – cea care pregătește terenul pentru avansarea Blockchain și AI, ei sunt, de asemenea, confuzi în ceea ce privește alegerea instrumentului potrivit pentru Big Data. Ei se confruntă cu dilema de a alege între Apache Hadoop și Spark – cei doi titani ai lumii Big Data.
Deci, având în vedere acest gând, astăzi vom acoperi un articol despre Apache Spark vs Hadoop și vă vom ajuta să determinați care este opțiunea potrivită pentru nevoile dvs.
Dar, în primul rând, să facem o scurtă introducere a ceea ce este Hadoop și Spark.
Apache Hadoop este un cadru open-source, distribuit și bazat pe Java, care permite utilizatorilor să stocheze și să proceseze date mari pe mai multe grupuri de computere folosind constructe de programare simple. Acesta cuprinde diverse module care lucrează împreună pentru a oferi o experiență îmbunătățită, care sunt: -
- Hadoop Common
- Sistemul de fișiere distribuit Hadoop (HDFS)
- Hadoop YARN
- Hadoop MapReduce
În timp ce, Apache Spark este un cadru de date mari de calcul în cluster distribuit open-source, care este „ușor de utilizat” și oferă servicii mai rapide.
Cele două cadre de date mari sunt susținute de numeroase companii mari datorită setului de oportunități pe care le oferă.
Avantajele Hadoop Big Data Framework
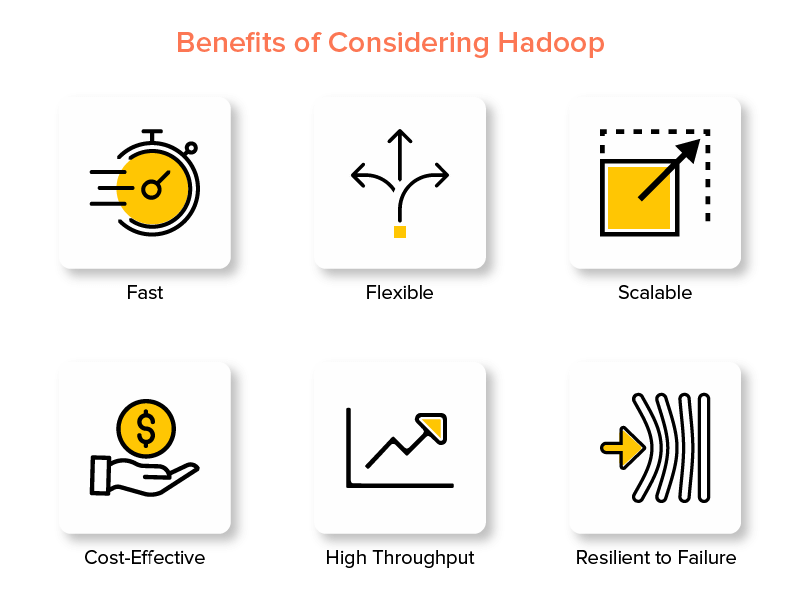
1. Rapid
Una dintre caracteristicile Hadoop care îl face popular în lumea datelor mari este că este rapid.
Metoda sa de stocare se bazează pe un sistem de fișiere distribuit care „cartează” în primul rând datele oriunde se află într-un cluster. De asemenea, datele și instrumentele utilizate pentru prelucrarea datelor sunt de obicei disponibile pe același server, ceea ce face ca prelucrarea datelor să fie o sarcină mai rapidă și fără probleme.
De fapt, s-a descoperit că Hadoop poate procesa terabytes de date nestructurate în doar câteva minute, în timp ce petabytes în ore.
2. Flexibil
Hadoop, spre deosebire de instrumentele tradiționale de procesare a datelor, oferă flexibilitate de vârf.
Permite companiilor să adune date din diferite surse (cum ar fi rețelele sociale, e-mailuri etc.), să lucreze cu diferite tipuri de date (atât structurate, cât și nestructurate) și să obțină informații valoroase pentru a le utiliza în continuare în scopuri variate (cum ar fi procesarea jurnalelor, analiza campaniilor de piață, detectarea fraudei etc).
3. Scalabil
Un alt avantaj al Hadoop este că este foarte scalabil. Platforma, spre deosebire de sistemele tradiționale de baze de date relaționale (RDBMS) , permite companiilor să stocheze și să distribuie seturi mari de date de la sute de servere care funcționează în paralel.
4. Eficient din punct de vedere al costurilor
Apache Hadoop, în comparație cu alte instrumente de analiză a datelor mari, este mult mai ieftin. Acest lucru se datorează faptului că nu necesită nicio mașină specializată; rulează pe un grup de hardware de marfă. De asemenea, este mai ușor să adăugați mai multe noduri pe termen lung.
Adică, un singur caz crește cu ușurință nodurile fără a suferi de vreun timp de nefuncționare a cerințelor de pre-planificare.
5. Debit ridicat
În cazul cadrului Hadoop, datele sunt stocate într-un mod distribuit, astfel încât o lucrare mică este împărțită în mai multe bucăți de date în paralel. Acest lucru face mai ușor pentru companii să realizeze mai multe lucrări în mai puțin timp, ceea ce duce în cele din urmă la un randament mai mare.
6. Rezistent la eșec
Nu în ultimul rând, Hadoop oferă opțiuni de toleranță ridicată la erori care ajută la atenuarea consecințelor eșecului. Stochează o replică a fiecărui bloc care face posibilă recuperarea datelor ori de câte ori se defectează orice nod.
Dezavantajele Hadoop Framework
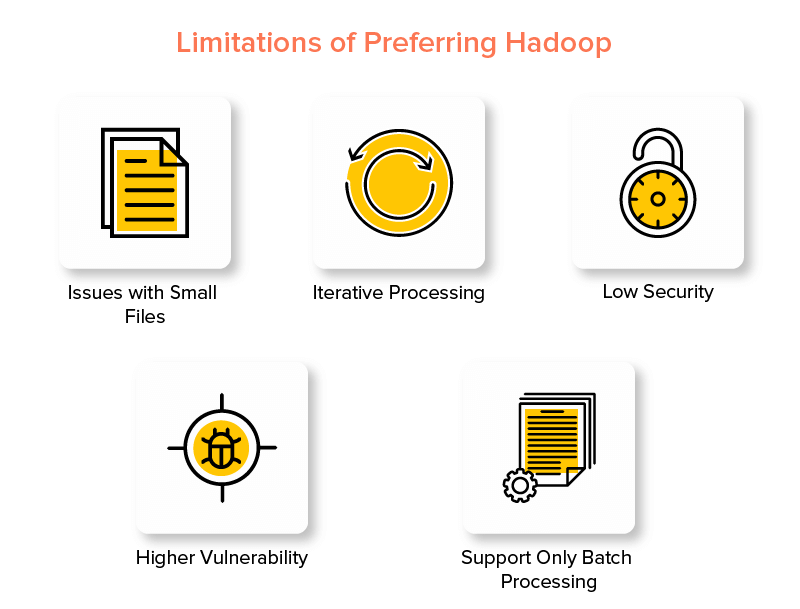
1. Probleme cu fișierele mici
Cel mai mare dezavantaj al luării în considerare a Hadoop pentru analiza datelor mari este că nu are potențialul de a sprijini citirea aleatorie a fișierelor mici în mod eficient și eficient.
Motivul din spatele acestui lucru este că un fișier mic are o dimensiune de memorie comparativ mai mică decât dimensiunea blocului HDFS. Într-un astfel de scenariu, dacă se stochează un număr mare de fișiere mici, există șanse mai mari de supraîncărcare a NameNode care stochează spațiul de nume al HDFS, ceea ce practic nu este o idee bună.
2. Procesare iterativă
Fluxul de date în cadrul Hadoop de date mari este sub forma unui lanț, astfel încât rezultatul unuia devine intrarea altei etape. În timp ce, fluxul de date în procesarea iterativă este de natură ciclică.
Din acest motiv, Hadoop este o alegere nepotrivită pentru învățare automată sau soluții bazate pe procesare iterativă.
3. Securitate scăzută
Un alt dezavantaj al folosirii cadrului Hadoop este că oferă funcții de securitate mai scăzute.
Cadrul, de exemplu, are modelul de securitate dezactivat implicit. Dacă cineva care utilizează acest instrument de date mari nu știe cum să îl activeze, datele sale ar putea fi expuse unui risc mai mare de a fi furate/folosite greșit. De asemenea, Hadoop nu oferă funcționalitatea de criptare la niveluri de stocare și rețea, ceea ce crește din nou șansele de amenințare de încălcare a datelor.
4. Vulnerabilitate mai mare
Cadrul Hadoop este scris în Java, cel mai popular limbaj de programare, dar foarte exploatat. Acest lucru facilitează accesul infractorilor cibernetici la soluțiile bazate pe Hadoop și utilizarea greșită a datelor sensibile.
5. Suport numai pentru procesarea în lot
Spre deosebire de diverse alte cadre de date mari, Hadoop nu procesează datele transmise în flux. Acceptă numai procesarea în loturi , iar motivul din spate este că MapReduce nu reușește să profite la maximum de memoria Clusterului Hadoop.
Deși totul este despre Hadoop, caracteristicile și dezavantajele sale, haideți să aruncăm o privire la avantajele și dezavantajele lui Spark pentru a înțelege cu ușurință diferența dintre cele două.
Beneficiile Apache Spark Framework
1. Dinamic în natură
Deoarece Apache Spark oferă aproximativ 80 de operatori de nivel înalt, acesta poate fi utilizat pentru procesarea dinamică a datelor. Poate fi considerat instrumentul potrivit de date mari pentru a dezvolta și gestiona aplicații paralele.
2. Puternic
Datorită capacității sale de procesare a datelor în memorie cu latență scăzută și a disponibilității diverselor biblioteci încorporate pentru învățarea automată și algoritmi de analiză grafică, poate face față diferitelor provocări de analiză. Acest lucru îl face o opțiune puternică de date mari pe piață, potrivită.
3. Analize avansate
O altă caracteristică distinctivă a Spark este că nu numai că încurajează „MAP” și „reduce”, dar acceptă și învățare automată (ML), interogări SQL, algoritmi de grafic și date de streaming. Acest lucru îl face potrivit pentru a vă bucura de analize avansate.
4. Reutilizabilitate
Spre deosebire de Hadoop, codul Spark poate fi reutilizat pentru procesarea în loturi, poate rula interogări ad-hoc privind starea fluxului, se poate alătura fluxului cu datele istorice și multe altele.
5. Procesarea fluxului în timp real
Un alt avantaj al folosirii Apache Spark este că permite gestionarea și procesarea datelor în timp real.
6. Suport multilingv
Nu în ultimul rând, acest instrument de analiză a datelor mari acceptă mai multe limbi pentru codare, inclusiv Java, Python și Scala.
Limitările instrumentului Spark Big Data

1. Fără proces de gestionare a fișierelor
Principalul dezavantaj al folosirii Apache Spark este că nu are propriul sistem de gestionare a fișierelor. Se bazează pe alte platforme precum Hadoop pentru a îndeplini această cerință.
2. Puțini algoritmi
Apache Spark rămâne, de asemenea, în urma altor cadre de date mari atunci când se ia în considerare disponibilitatea algoritmilor precum distanța Tanimoto.
3. Problemă cu fișierele mici
Un alt dezavantaj al utilizării Spark este că nu gestionează eficient fișierele mici.
Acest lucru se datorează faptului că funcționează cu Hadoop Distributed File System (HDFS), căruia îi este mai ușor să gestioneze un număr limitat de fișiere mari peste o mulțime de fișiere mici.
4. Nici un proces automat de optimizare
Spre deosebire de diverse alte platforme de date mari și cloud, Spark nu are niciun proces automat de optimizare a codului. Trebuie să optimizați codul doar manual.
5. Nu este potrivit pentru mediul multi-utilizator
Deoarece Apache Spark nu poate gestiona mai mulți utilizatori în același timp, nu funcționează eficient în mediul multi-utilizator. Ceva care se adaugă din nou la limitările sale.
Cu elementele de bază ale ambelor cadre de date mari acoperite, este probabil că sperați să vă familiarizați cu diferențele dintre Spark și Hadoop.
Deci, să nu mai așteptăm și să ne îndreptăm spre comparația lor pentru a vedea care dintre ele conduce bătălia „Spark vs Hadoop”.
Spark vs Hadoop: cum se împart cele două instrumente de date mari
[ID tabel=38 /]
1. Arhitectura
Când vine vorba de arhitectura Spark și Hadoop, aceasta din urmă conduce chiar și atunci când ambele funcționează în mediu de calcul distribuit.
Acest lucru se datorează faptului că, arhitectura Hadoop – spre deosebire de Spark – are două elemente principale – HDFS (Hadoop Distributed File System) și YARN (Yet Another Resource Negotiator). Aici, HDFS gestionează stocarea de date mari în noduri variate, în timp ce YARN se ocupă de sarcinile de procesare prin alocare de resurse și mecanisme de programare a sarcinilor. Aceste componente sunt apoi împărțite în mai multe componente pentru a oferi soluții mai bune cu servicii precum toleranța la erori.
2. Ușurință în utilizare
Apache Spark le permite dezvoltatorilor să introducă în mediul lor de dezvoltare diverse API-uri ușor de utilizat, cum ar fi cea pentru Scala, Python, R, Java și Spark SQL. De asemenea, vine încărcat cu un mod interactiv care acceptă atât utilizatorii, cât și dezvoltatorii. Acest lucru îl face ușor de utilizat și cu curbă de învățare scăzută.
În timp ce, când vorbim despre Hadoop, oferă suplimente pentru a sprijini utilizatorii, dar nu un mod interactiv. Acest lucru face ca Spark să învingă Hadoop în această luptă pentru „datele mari”.
3. Toleranța la erori și securitate
În timp ce atât Apache Spark, cât și Hadoop MapReduce oferă o facilitate de toleranță la erori, acesta din urmă câștigă bătălia.
Acest lucru se datorează faptului că trebuie să începeți de la zero în cazul în care un proces se blochează în mijlocul funcționării în mediul Spark. Dar, când vine vorba de Hadoop, pot continua din punctul în care s-a produs accidentul.
4. Performanță
Când vine vorba de performanța Spark vs MapReduce, primul îl câștigă pe cel din urmă.
Cadrul Spark poate rula de 10 ori mai rapid pe disc și de 100 de ori în memorie. Acest lucru face posibilă gestionarea a 100 TB de date de 3 ori mai rapid decât Hadoop MapReduce.
5. Prelucrarea datelor
Un alt factor de luat în considerare în timpul comparației Apache Spark vs Hadoop este procesarea datelor.
În timp ce Apache Hadoop oferă o oportunitate de procesare în lot, celălalt cadru de date mari permite lucrul cu procesare interactivă, iterativă, în flux, grafic și în lot. Ceva care demonstrează că Spark este o opțiune mai bună pentru a beneficia de servicii mai bune de procesare a datelor.
6. Compatibilitate
Compatibilitatea dintre Spark și Hadoop MapReduce este oarecum aceeași.
Deși uneori, ambele cadre de date mari acționează ca aplicații autonome, ele pot funcționa și împreună. Spark poate rula eficient pe Hadoop YARN, în timp ce Hadoop se poate integra cu ușurință cu Sqoop și Flume. Din acest motiv, ambele acceptă reciproc sursele de date și formatele de fișiere.
7. Securitate
Mediul Spark este încărcat cu diferite caracteristici de securitate, cum ar fi înregistrarea evenimentelor și utilizarea filtrelor servlet javax pentru protejarea interfețelor de utilizare web. De asemenea, încurajează autentificarea prin secret partajat și poate profita de potențialul permisiunilor de fișiere HDFS, criptarea intermodală și Kerberos atunci când este integrat cu YARN și HDFS.
În timp ce, Hadoop acceptă autentificare Kerberos , autentificare terță parte, permisiuni convenționale pentru fișiere și liste de control al accesului și multe altele, ceea ce oferă în cele din urmă rezultate de securitate mai bune.
Deci, când luăm în considerare comparația Spark vs Hadoop în ceea ce privește securitatea, acesta din urmă conduce.
8. Cost-eficiență
Când comparăm Hadoop și Spark, primul are nevoie de mai multă memorie pe disc, în timp ce al doilea necesită mai multă memorie RAM. De asemenea, deoarece Spark este destul de nou în comparație cu Apache Hadoop, dezvoltatorii care lucrează cu Spark sunt mai rari.
Acest lucru face ca lucrul cu Spark să fie o afacere costisitoare. Adică, Hadoop oferă soluții rentabile atunci când se concentrează pe costul Hadoop vs Spark.
9. Domeniul de aplicare al pieței
În timp ce atât Apache Spark, cât și Hadoop sunt susținute de mari companii și au fost utilizate în scopuri diferite, acesta din urmă este lider în ceea ce privește domeniul de aplicare al pieței.
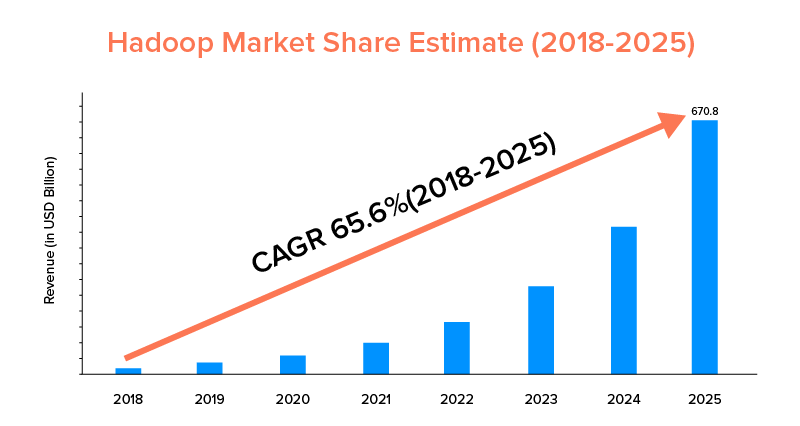
Conform statisticilor pieței, se preconizează că piața Apache Hadoop va crește cu un CAGR de 65,6% în perioada 2018-2025, în comparație cu Spark cu un CAGR de doar 33,9%.
În timp ce acești factori vor ajuta la determinarea instrumentului potrivit de date mari pentru afacerea dvs., este profitabil să vă familiarizați cu cazurile lor de utilizare. Deci, hai să acoperim aici.
Cazuri de utilizare ale Apache Spark Framework
Acest instrument de date mari este acceptat de companii atunci când doresc:
- Transmiteți și analizați datele în timp real.
- Bucurați-vă de puterea învățării automate.
- Lucrați cu analize interactive.
- Introduceți Fog and Edge Computing în modelul lor de afaceri.
Cazuri de utilizare ale Apache Hadoop Framework
Hadoop este preferat de startup-uri și întreprinderi atunci când doresc: -
- Analizați datele de arhivă.
- Bucurați-vă de opțiuni mai bune de tranzacționare financiară și de prognoză.
- Executați operațiuni care includ hardware-ul de marfă.
- Luați în considerare procesarea liniară a datelor.
Prin aceasta, sperăm că ați decis care dintre ele este câștigătorul luptei „Spark vs Hadoop” în ceea ce privește afacerea dvs. Dacă nu, nu ezitați să vă contactați cu experții noștri în Big Data pentru a înlătura toate îndoielile și pentru a obține servicii exemplare, cu o rată de succes mai mare.
ÎNTREBĂRI FRECVENTE
1. Ce cadru de date mari să alegeți?
Alegerea depinde complet de nevoile afacerii tale. Dacă vă concentrați pe performanță, compatibilitatea datelor și ușurința în utilizare, Spark este mai bun decât Hadoop. În timp ce, cadrul de date mari Hadoop este mai bun atunci când vă concentrați pe arhitectură, securitate și eficiență a costurilor.
2. Care este diferența dintre Hadoop și Spark?
Există diferite diferențe între Spark și Hadoop. De exemplu:-
- Spark este de 100 de ori mai mare decât Hadoop MapReduce.
- În timp ce Hadoop este folosit pentru procesarea în loturi, Spark este destinat procesării în loturi, grafice, învățare automată și procesare iterativă.
- Spark este compact și mai ușor decât cadrul de date mari Hadoop.
- Spre deosebire de Spark, Hadoop nu acceptă stocarea în cache a datelor.
3. Este Spark mai bun decât Hadoop?
Spark este mai bun decât Hadoop atunci când accentul principal este pe viteză și securitate. Cu toate acestea, în alte cazuri, acest instrument de analiză a datelor mari rămâne în urmă cu Apache Hadoop.
4. De ce Spark este mai rapid decât Hadoop?
Spark este mai rapid decât Hadoop datorită numărului mai mic de cicluri de citire/scriere pe disc și stocării datelor intermediare în memorie.
5. Pentru ce este folosit Apache Spark?
Apache Spark este folosit pentru analiza datelor atunci când se dorește să-
- Analizați datele în timp real.
- Introduceți ML și Fog Computing în modelul dvs. de afaceri.
- Lucrați cu Analytics interactiv.