
TW-BERT: Ponderea termenilor de interogare de la capăt la capăt și viitorul Căutării Google
Publicat: 2023-09-14Căutarea este grea, așa cum a scris Seth Godin în 2005.
Adică, dacă credem că SEO este greu (și este), imaginați-vă dacă ați încerca să construiți un motor de căutare într-o lume în care:
- Utilizatorii variază dramatic și își schimbă preferințele în timp.
- Tehnologia la care accesează căutarea avansează în fiecare zi.
- Concurenții îți strâng călcâiele în mod constant.
În plus, aveți de-a face și cu SEO enervantă care încearcă să -și folosească algoritmul pentru a obține informații despre cel mai bun mod de a optimiza pentru vizitatorii dvs.
Asta o va face mult mai greu.
Acum imaginați-vă dacă principalele tehnologii pe care trebuie să vă bazați pentru a avansa au avut propriile limitări – și, poate și mai rău, costuri masive.
Ei bine, dacă sunteți unul dintre scriitorii lucrării recent publicate, „Ponderarea termenilor de interogare de la capăt la capăt”, vedeți aceasta ca o oportunitate de a străluci.
Ce este ponderarea termenilor de interogare de la capăt la capăt?
Ponderea termenilor de interogare de la capăt la capăt se referă la o metodă în care ponderea fiecărui termen dintr-o interogare este determinată ca parte a modelului general, fără a se baza pe schemele de ponderare a termenilor programate manual sau tradiționale sau pe alte modele independente.
Cum arată asta?
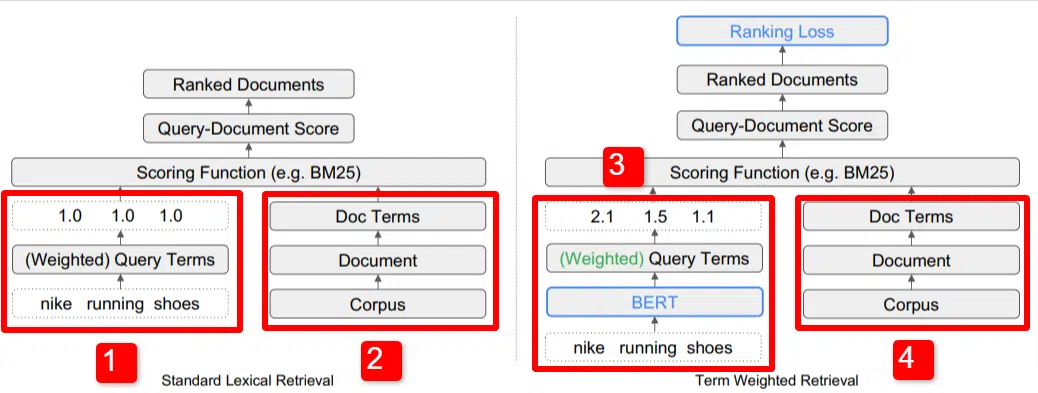
Aici vedem o ilustrare a unuia dintre diferențiatorii cheie ai modelului subliniați în lucrare (Figura 1, în mod specific).
În partea dreaptă a modelului standard (2) vedem la fel ca și cu modelul propus (4), care este corpus (setul complet de documente din index), care duce la documente, care duce la termeni.
Acest lucru ilustrează ierarhia reală în sistem, dar vă puteți gândi la ea în sens invers, de sus în jos. Avem termeni. Căutăm documente cu acești termeni. Aceste documente se află în corpus tuturor documentelor despre care știm.
În stânga jos (1) în arhitectura standard de recuperare a informațiilor (IR), veți observa că nu există un strat BERT. Interogarea folosită în ilustrația lor (pantofi de alergare nike) intră în sistem, iar greutățile sunt calculate independent de model și transmise acestuia.
În ilustrația de aici, ponderile trec în mod egal între cele trei cuvinte din interogare. Cu toate acestea, nu trebuie să fie așa. Este pur și simplu o ilustrație implicită și bună.
Ceea ce este important de înțeles este că ponderile sunt atribuite din afara modelului și introduse cu interogarea. Vom discuta de ce acest lucru este important pentru moment.
Dacă ne uităm la versiunea termen-greutate din partea dreaptă, veți vedea că interogarea „pantofi de alergare nike” intră BERT (Term Weighting BERT, sau TW-BERT, pentru a fi mai precis), care este folosită pentru a atribui greutățile care ar fi cel mai bine aplicat la acea interogare.
De acolo lucrurile urmează o cale similară pentru ambele, se aplică o funcție de punctare și documentele sunt clasate. Dar există un pas final cheie cu noul model, acesta este de fapt scopul, calculul pierderii în clasament.
Acest calcul, la care mă refeream mai sus, face ca ponderile determinate în cadrul modelului să fie atât de importante. Pentru a înțelege cel mai bine acest lucru, să luăm o scurtă deoparte pentru a discuta despre funcțiile de pierdere, ceea ce este important pentru a înțelege cu adevărat ce se întâmplă aici.
Ce este o funcție de pierdere?
În învățarea automată, o funcție de pierdere este, practic, un calcul al cât de greșit este un sistem, care încearcă să învețe să se apropie cât mai mult de o pierdere zero.
Să luăm de exemplu un model conceput pentru a determina prețurile caselor. Dacă ai intrat în toate statisticile casei tale și a venit cu o valoare de 250.000 USD, dar casa ta s-a vândut cu 260.000 USD, diferența ar fi considerată pierdere (care este o valoare absolută).
Într-un număr mare de exemple, modelul este învățat să minimizeze pierderea prin atribuirea unor greutăți diferite parametrilor care îi sunt dați până când obține cel mai bun rezultat. Un parametru, în acest caz, poate include lucruri precum picioare pătrate, dormitoare, dimensiunea curții, apropierea de o școală etc.
Acum, reveniți la ponderarea termenilor de interogare
Privind înapoi la cele două exemple de mai sus, pe care trebuie să ne concentrăm este prezența unui model BERT pentru a furniza ponderea termenilor în jos a calculului pierderii în clasament.
Pentru a spune altfel, în modelele tradiționale, ponderarea termenilor s-a făcut independent de modelul în sine și, prin urmare, nu a putut răspunde la modul în care a funcționat modelul general. Nu a putut învăța cum să se îmbunătățească în ponderări.

În sistemul propus, acest lucru se schimbă. Ponderea se face din interiorul modelului în sine și astfel, deoarece modelul încearcă să-și îmbunătățească performanța și să reducă funcția de pierdere, are aceste cadrane suplimentare pentru a aduce ponderarea termenilor în ecuație. Literalmente.
ngrame
TW-BERT nu este proiectat să funcționeze în termeni de cuvinte, ci mai degrabă de ngrame.
Autorii lucrării ilustrează bine de ce folosesc ngrame în loc de cuvinte atunci când subliniază că în interogarea „nike running shoes” dacă pur și simplu ponderați cuvintele, atunci o pagină cu mențiuni ale cuvintelor nike, alergare și pantofi s-ar putea clasa bine chiar și dacă este vorba despre „șosete de alergare Nike” și „pantofi de skate”.
Metodele tradiționale IR folosesc statistici de interogare și statistici de document și pot apărea pagini cu aceasta sau probleme similare. Încercările anterioare de a aborda acest lucru s-au concentrat pe co-apariție și ordonare.
În acest model, ngramele sunt ponderate așa cum au fost cuvintele în exemplul nostru anterior, așa că ajungem cu ceva de genul:
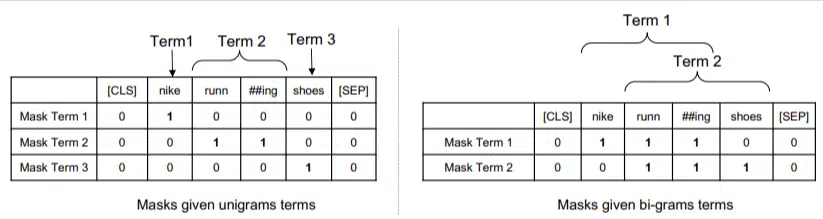
În stânga vedem cum ar fi ponderată interogarea ca uni-grame (ngrame cu 1 cuvânt), iar în dreapta, bi-grame (ngrame cu 2 cuvinte).
Sistemul, deoarece ponderarea este încorporată în el, se poate antrena pe toate permutările pentru a determina cele mai bune ngrame și, de asemenea, greutatea adecvată pentru fiecare, spre deosebire de a se baza doar pe statistici precum frecvența.
Zero shot
O caracteristică importantă a acestui model este performanța sa în sarcini zero-scurte. Autorii au testat pe:
- Set de date MS MARCO – Setul de date Microsoft pentru clasarea documentelor și a pasajelor
- Set de date TREC-COVID – articole și studii COVID
- Robust04 – Articole de știri
- Common Core – Articole educaționale și postări pe blog
Au avut doar un număr mic de interogări de evaluare și nu au folosit niciuna pentru reglare fină, făcând din acesta un test zero, deoarece modelul nu a fost antrenat pentru a clasifica documentele în mod specific pe aceste domenii. Rezultatele au fost:
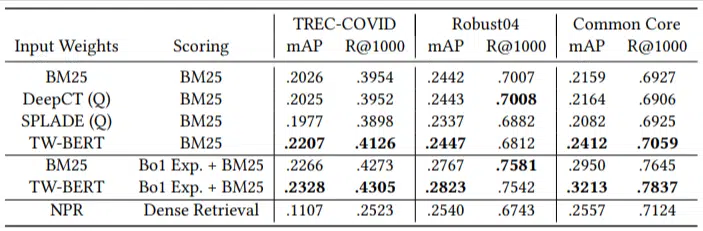
A avut performanțe depășite în majoritatea sarcinilor și a funcționat cel mai bine la interogări mai scurte (1 până la 10 cuvinte).
Și este plug-and-play!
OK, asta ar putea fi prea simplificator, dar autorii scriu:
„Alinierea TW-BERT cu marcatorii motoarelor de căutare minimizează modificările necesare pentru a-l integra în aplicațiile de producție existente , în timp ce metodele de căutare bazate pe învățarea profundă existente ar necesita o optimizare suplimentară a infrastructurii și cerințe hardware. Greutățile învățate pot fi utilizate cu ușurință de către recuperatorii lexicali standard și de alte tehnici de recuperare, cum ar fi extinderea interogărilor.”
Deoarece TW-BERT este proiectat să se integreze în sistemul actual, integrarea este mult mai simplă și mai ieftină decât alte opțiuni.
Ce înseamnă toate acestea pentru tine
Cu modelele de învățare automată, este dificil să prezici un exemplu de ceea ce poți face tu în calitate de SEO (în afară de implementările vizibile precum Bard sau ChatGPT).
O permutare a acestui model va fi, fără îndoială, implementată datorită îmbunătățirilor sale și ușurinței implementării (presupunând că afirmațiile sunt corecte).
Acestea fiind spuse, aceasta este o îmbunătățire a calității vieții la Google, care va îmbunătăți clasamentele și rezultatele zero-shot cu un cost scăzut.
Tot ceea ce ne putem baza cu adevărat este că, dacă sunt implementate, rezultate mai bune vor apărea în mod mai fiabil. Și aceasta este o veste bună pentru profesioniștii SEO.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.