
Ce este AI generativă și cum funcționează?
Publicat: 2023-09-26Inteligența artificială generativă, un subset al inteligenței artificiale, a apărut ca o forță revoluționară în lumea tehnologiei. Dar ce este mai exact? Și de ce câștigă atât de multă atenție?
Acest ghid aprofundat va aborda modul în care funcționează modelele AI generative, ce pot și nu pot face și implicațiile tuturor acestor elemente.
Ce este AI generativă?
AI generativ, sau genAI, se referă la sisteme care pot genera conținut nou, fie că este text, imagini, muzică sau chiar videoclipuri. În mod tradițional, AI/ML a însemnat trei lucruri: învățare supravegheată, nesupravegheată și întărire. Fiecare oferă informații bazate pe rezultatul grupării.
Modelele AI negenerative fac calcule pe baza intrărilor (cum ar fi clasificarea unei imagini sau traducerea unei propoziții). În schimb, modelele generative produc rezultate „noi”, cum ar fi scrierea de eseuri, compunerea muzicii, proiectarea graficelor și chiar crearea de fețe umane realiste care nu există în lumea reală.
Implicațiile AI generative
Creșterea IA generativă are implicații semnificative. Cu capacitatea de a genera conținut, industrii precum divertismentul, designul și jurnalismul sunt martorii unei schimbări de paradigmă.
De exemplu, agențiile de presă pot folosi AI pentru a redacta rapoarte, în timp ce designerii pot obține sugestii asistate de AI pentru grafică. AI poate genera sute de sloganuri publicitare în câteva secunde, indiferent dacă aceste opțiuni sunt bune sau nu sau nu este alta treaba.
AI generativ poate produce conținut personalizat pentru utilizatorii individuali. Gândiți-vă la ceva de genul unei aplicații muzicale care compune o melodie unică în funcție de starea dvs. de spirit sau la o aplicație de știri care redactează articole despre subiecte care vă interesează.
Problema este că, pe măsură ce AI joacă un rol mai important în crearea de conținut, întrebările despre autenticitate, drepturi de autor și valoarea creativității umane devin mai răspândite.
Cum funcționează AI generativ?
AI generativă, în esență, se referă la prezicerea următoarei date dintr-o secvență, indiferent dacă acesta este următorul cuvânt dintr-o propoziție sau următorul pixel dintr-o imagine. Să dezvăluim cum se realizează acest lucru.
Modele statistice
Modelele statistice sunt coloana vertebrală a majorității sistemelor AI. Ei folosesc ecuații matematice pentru a reprezenta relația dintre diferite variabile.
Pentru IA generativă, modelele sunt antrenate să recunoască modele în date și apoi să utilizeze aceste modele pentru a genera date noi, similare.
Dacă un model este antrenat pe propoziții în limba engleză, acesta învață probabilitatea statistică ca un cuvânt să urmeze pe altul, permițându-i să genereze propoziții coerente.
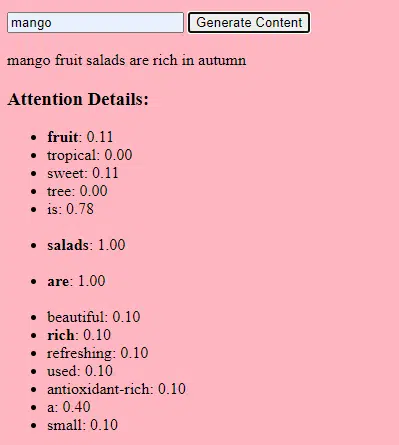
Colectarea datelor
Atât calitatea, cât și cantitatea datelor sunt cruciale. Modelele generative sunt antrenate pe seturi vaste de date pentru a înțelege tiparele.
Pentru un model de limbă, acest lucru ar putea însemna ingerarea de miliarde de cuvinte din cărți, site-uri web și alte texte.
Pentru un model de imagine, ar putea însemna analiza a milioane de imagini. Cu cât datele de instruire sunt mai diverse și mai cuprinzătoare, cu atât mai bine modelul va genera rezultate diverse.
Cum funcționează transformatoarele și atenția
Transformatoarele sunt un tip de arhitectură de rețea neuronală introdusă într-o lucrare din 2017 intitulată „Attention Is All You Need” de Vaswani și colab. Ele au devenit de atunci baza pentru majoritatea modelelor de limbaj de ultimă generație. ChatGPT nu ar funcționa fără transformatoare.
Mecanismul de „atenție” permite modelului să se concentreze asupra diferitelor părți ale datelor de intrare, la fel ca modul în care oamenii acordă atenție anumitor cuvinte atunci când înțeleg o propoziție.
Acest mecanism permite modelului să decidă care părți ale inputului sunt relevante pentru o anumită sarcină, făcându-l extrem de flexibil și puternic.
Codul de mai jos este o defalcare fundamentală a mecanismelor transformatorului, explicând fiecare piesă în limba engleză simplă.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)În cod, este posibil să aveți o clasă Transformer și o singură clasă TransformerLayer. Este ca și cum ai avea un plan pentru un etaj față de o clădire întreagă.
Această bucată de cod TransformerLayer vă arată cum funcționează anumite componente, cum ar fi atenția cu mai multe capete și aranjamentele specifice.
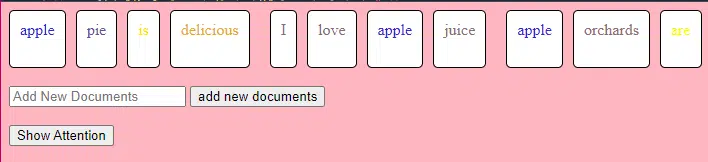
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)O rețea neuronală feed-forward este unul dintre cele mai simple tipuri de rețele neuronale artificiale. Este format dintr-un strat de intrare, unul sau mai multe straturi ascunse și un strat de ieșire.
Datele circulă într-o singură direcție – de la stratul de intrare, prin straturile ascunse și către stratul de ieșire. Nu există bucle sau cicluri în rețea.
În contextul arhitecturii transformatorului, rețeaua neuronală feed-forward este utilizată după mecanismul de atenție din fiecare strat. Este o transformare liniară simplă în două straturi cu o activare ReLU între ele.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Cum funcționează IA generativă – în termeni simpli
Gândiți-vă la IA generativă ca la aruncarea unui zar ponderat. Datele de antrenament determină ponderile (sau probabilitățile).
Dacă zarul reprezintă următorul cuvânt dintr-o propoziție, un cuvânt care urmează adesea cuvântul curent din datele de antrenament va avea o pondere mai mare. Deci, „cerul” ar putea urma „albastru” mai des decât „banana”. Când AI „da zarurile” pentru a genera conținut, este mai probabil să aleagă secvențe mai probabile din punct de vedere statistic pe baza antrenamentului său.
Deci, cum pot LLM-urile să genereze conținut care „pare” original?
Să luăm o listă falsă – „cele mai bune cadouri Eid al-Fitr pentru marketerii de conținut” – și să vedem cum poate genera un LLM această listă combinând indicații textuale din documente despre cadouri, Eid și marketeri de conținut.
Înainte de procesare, textul este împărțit în bucăți mai mici numite „jetoane”. Aceste jetoane pot fi scurte cât un caracter sau lungi cât un cuvânt.
Exemplu: „Eid al-Fitr este o sărbătoare” devine [„Eid”, „al-Fitr”, „este”, „a”, „sărbătoare”].
Acest lucru permite modelului să lucreze cu bucăți de text ușor de gestionat și să înțeleagă structura propozițiilor.
Fiecare jeton este apoi convertit într-un vector (o listă de numere) folosind înglobări. Acești vectori captează sensul și contextul fiecărui cuvânt.
Codificarea pozițională adaugă informații fiecărui vector cuvânt despre poziția sa în propoziție, asigurându-se că modelul nu pierde această informație de ordine.
Apoi folosim un mecanism de atenție : acesta permite modelului să se concentreze pe diferite părți ale textului de intrare atunci când generează o ieșire. Dacă vă amintiți BERT, acesta este ceea ce a fost atât de interesant pentru angajații Google despre BERT.
Dacă modelul nostru a văzut texte despre „ cadouri ” și știe că oamenii oferă cadouri în timpul sărbătorilor și a văzut și texte despre „ Eid al-Fitr ” ca fiind o sărbătoare semnificativă, va acorda „ atenție ” acestor conexiuni.
În mod similar, dacă a văzut texte despre „ marketerii de conținut ” care au nevoie de instrumente sau resurse specifice, poate conecta ideea de „ cadouri ” cu „ marketerii de conținut”.

Acum putem combina contexte: pe măsură ce modelul procesează textul de intrare prin mai multe straturi Transformer, combină contextele pe care le-a învățat.
Deci, chiar dacă textele originale nu au menționat niciodată „cadouri Eid al-Fitr pentru marketerii de conținut”, modelul poate reuni conceptele de „Eid al-Fitr”, „cadouri” și „marketinguri de conținut” pentru a genera acest conținut.
Acest lucru se datorează faptului că a învățat contextele mai largi din jurul fiecăruia dintre acești termeni.
După procesarea intrării prin mecanismul de atenție și rețelele de feed-forward din fiecare strat de transformator, modelul produce o distribuție de probabilitate în vocabularul său pentru următorul cuvânt din secvență.
S-ar putea crede că după cuvinte precum „cel mai bun” și „Eid al-Fitr”, cuvântul „cadouri” are o mare probabilitate să apară în continuare. În mod similar, ar putea asocia „cadourile” cu potențiali destinatari, cum ar fi „marketinguri de conținut”.
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
Cât de mari sunt construite modele de limbaj
Călătoria de la un model de transformator de bază la un model de limbaj mare sofisticat (LLM) precum GPT-3 sau BERT implică extinderea și rafinarea diferitelor componente.
Iată o defalcare pas cu pas:
LLM-urile sunt instruite pe cantități mari de date text. Este greu de explicat cât de vaste sunt aceste date.
Setul de date C4, un punct de plecare pentru multe LLM, este de 750 GB de date text. Adică 805.306.368.000 de octeți – o mulțime de informații. Aceste date pot include cărți, articole, site-uri web, forumuri, secțiuni de comentarii și alte surse.
Cu cât datele sunt mai variate și mai cuprinzătoare, cu atât mai bune sunt capabilitățile de înțelegere și generalizare ale modelului.
În timp ce arhitectura de bază a transformatorului rămâne fundația, LLM-urile au un număr semnificativ mai mare de parametri. GPT-3, de exemplu, are 175 de miliarde de parametri. În acest caz, parametrii se referă la ponderile și părtinirile din rețeaua neuronală care sunt învățate în timpul procesului de antrenament.
În deep learning, un model este antrenat să facă predicții prin ajustarea acestor parametri pentru a reduce diferența dintre predicțiile sale și rezultatele reale.

Procesul de ajustare a acestor parametri se numește optimizare, care utilizează algoritmi precum coborârea gradientului.
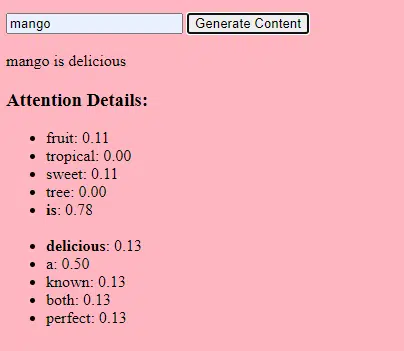
- Greutăți: Acestea sunt valori din rețeaua neuronală care transformă datele de intrare în straturile rețelei. Acestea sunt ajustate în timpul antrenamentului pentru a optimiza randamentul modelului. Fiecare conexiune dintre neuronii din straturile adiacente are o greutate asociată.
- Prejudecăți: Acestea sunt, de asemenea, valori din rețeaua neuronală care sunt adăugate la rezultatul transformării unui strat. Acestea oferă un grad suplimentar de libertate modelului, permițându-i să se potrivească mai bine cu datele de antrenament. Fiecare neuron dintr-un strat are o părtinire asociată.
Această scalare permite modelului să stocheze și să proceseze modele și relații mai complicate în date.
Numărul mare de parametri înseamnă, de asemenea, că modelul necesită o putere de calcul semnificativă și memorie pentru antrenament și inferență. Acesta este motivul pentru care antrenarea unor astfel de modele necesită resurse intensive și, de obicei, utilizează hardware specializat, cum ar fi GPU-uri sau TPU-uri.
Modelul este antrenat să prezică următorul cuvânt dintr-o secvență folosind resurse de calcul puternice. Isi ajusteaza parametrii interni in functie de erorile pe care le face, imbunatatindu-si continuu predictiile.
Mecanismele de atenție precum cele pe care le-am discutat sunt esențiale pentru LLM. Acestea permit modelului să se concentreze pe diferite părți ale intrării atunci când generează ieșire.
Cântărind importanța diferitelor cuvinte într-un context, mecanismele de atenție permit modelului să genereze text coerent și relevant din punct de vedere contextual. Făcând acest lucru la această scară masivă, LLM-urilor să funcționeze așa cum o fac.
Cum prezice un transformator textul?
Transformers prezic text prin procesarea jetoanelor de intrare prin mai multe straturi, fiecare echipat cu mecanisme de atenție și rețele de feed-forward.
După procesare, modelul produce o distribuție de probabilitate în vocabularul său pentru următorul cuvânt din secvență. Cuvântul cu cea mai mare probabilitate este de obicei selectat ca predicție.
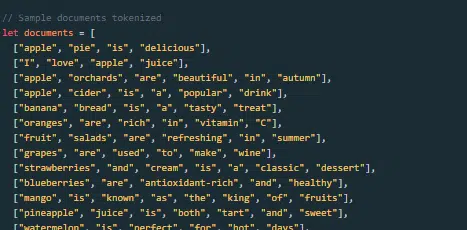
Cum este construit și antrenat un model lingvistic mare?
Construirea unui LLM implică colectarea datelor, curățarea acestora, antrenamentul modelului, reglarea fină a modelului și testarea viguroasă și continuă.
Modelul este antrenat inițial pe un corpus vast pentru a prezice următorul cuvânt dintr-o secvență. Această fază permite modelului să învețe conexiuni între cuvintele care preiau tipare în gramatică, relații care pot reprezenta fapte despre lume și conexiuni care par a fi un raționament logic. Aceste conexiuni îl fac, de asemenea, să capteze prejudecățile prezente în datele de antrenament.
După pregătire preliminară, modelul este rafinat pe un set de date mai restrâns, adesea cu recenzori umani urmând liniile directoare.
Reglarea fină este un pas crucial în construirea LLM-urilor. Aceasta implică antrenarea modelului pre-antrenat pe un set de date sau sarcină mai specific. Să luăm ChatGPT ca exemplu.
Dacă te-ai jucat cu modele GPT, știi că solicitarea este mai puțin „scrie chestia asta” și mai mult ca
- Prompt: A fost odată ca niciodată
- Continuare: În vârful unui turn era un vrăjitor rău.
- Continuare: În vârful unui turn era un vrăjitor rău.
- Solicitare : De ce s-a alăturat puiul unei trupe?
- Continuare : Pentru că avea bețișoarele!
Pentru a ajunge la ChatGPT din acel punct implică multă muncă prost plătită. Acești oameni creează corpuri imense pentru a pune un deget pe greutatea răspunsurilor GPT și a comportamentelor așteptate. Acești lucrători creează o mulțime de texte prompte/continuare care sunt de genul:
- Solicitare : Termină această poveste: „A fost odată ca niciodată..”
- Continuare : Sigur! Odinioară, într-un ținut foarte, departe, era un mic sat cuibărit între doi munți maiestuoși.
- Continuare : Sigur! Odinioară, într-un ținut foarte, departe, era un mic sat cuibărit între doi munți maiestuoși.
- Prompt : Spune-mi o glumă despre un pui.
- Continuare : De ce s-a alăturat puiul unei trupe? Pentru că avea bețișoarele!
Acest proces de reglare fină este esențial din mai multe motive:
- Specificitate: în timp ce pre-instruirea oferă modelului o înțelegere largă a limbajului, reglarea fină restrânge cunoștințele și comportamentul acestuia pentru a se alinia mai mult cu sarcini sau domenii specifice. De exemplu, un model reglat fin pe datele medicale va răspunde mai bine la întrebările medicale.
- Control: reglarea fină oferă dezvoltatorilor mai mult control asupra ieșirilor modelului. Dezvoltatorii pot folosi un set de date organizat pentru a ghida modelul pentru a produce răspunsurile dorite și pentru a evita comportamentele nedorite.
- Siguranță: ajută la reducerea rezultatelor dăunătoare sau părtinitoare. Folosind liniile directoare în timpul procesului de reglare fină, recenzenții umani se pot asigura că modelul nu produce conținut neadecvat.
- Performanță: reglarea fină poate îmbunătăți semnificativ performanța modelului în anumite sarcini. De exemplu, un model care a fost ajustat pentru asistența clienților va fi mult mai bun decât un model generic.
Puteți spune că ChatGPT a fost reglat fin în special în anumite moduri.
De exemplu, „raționamentul logic” este ceva cu care LLM-ii tind să se lupte. Cel mai bun model de raționament logic al ChatGPT – GPT-4 – a fost antrenat intens pentru a recunoaște modelele în numere în mod explicit.
In loc de asa ceva:
- Solicitare : Ce înseamnă 2+2?
- Proces : De multe ori în manualele de matematică pentru copii 2+2 =4. Ocazional, există referiri la „2+2=5”, dar de obicei există mai mult context de-a face cu George Orwell sau Star Trek atunci când acesta este cazul. Dacă aceasta ar fi în acel context, ponderea ar fi mai mult în favoarea lui 2+2=5. Dar acest context nu există, așa că în acest caz următorul simbol este probabil 4.
- Răspuns : 2+2=4
Antrenamentul face ceva de genul:
- antrenament: 2+2=4
- antrenament: 4/2=2
- antrenament: jumătate din 4 este 2
- antrenament: 2 din 2 este patru
…și așa mai departe.
Aceasta înseamnă că pentru acele modele mai „logice”, procesul de instruire este mai riguros și axat pe asigurarea faptului că modelul înțelege și aplică corect principiile logice și matematice.
Modelul este expus la diverse probleme matematice și soluțiile acestora, asigurându-se că poate generaliza și aplica aceste principii la probleme noi, nevăzute.
Importanța acestui proces de reglare fină, în special pentru raționamentul logic, nu poate fi exagerată. Fără el, modelul ar putea oferi răspunsuri incorecte sau fără sens la întrebări logice sau matematice simple.
Modele de imagine versus modele de limbaj
În timp ce atât modelele de imagine, cât și de limbaj pot folosi arhitecturi similare, cum ar fi transformatoarele, datele pe care le procesează sunt fundamental diferite:
Modele de imagine
Aceste modele se ocupă de pixeli și funcționează adesea într-o manieră ierarhică, analizând mai întâi modelele mici (cum ar fi marginile), apoi combinându-le pentru a recunoaște structuri mai mari (cum ar fi formele) și așa mai departe până când înțeleg întreaga imagine.
Modele de limbaj
Aceste modele procesează secvențe de cuvinte sau caractere. Ei trebuie să înțeleagă contextul, gramatica și semantica pentru a genera text coerent și relevant din punct de vedere contextual.
Cum funcționează interfețele AI generative proeminente
Dall-E + Mijlocul călătoriei
Dall-E este o variantă a modelului GPT-3 adaptată pentru generarea de imagini. Este antrenat pe un set vast de date de perechi text-imagine. Midjourney este un alt software de generare de imagini care se bazează pe un model proprietar.
- Intrare: furnizați o descriere textuală, cum ar fi „un flamingo cu două capete”.
- Procesare: Aceste modele codifică acest text într-o serie de numere și apoi decodează acești vectori, găsind relații cu pixelii, pentru a produce o imagine. Modelul a învățat relațiile dintre descrierile textuale și reprezentările vizuale din datele sale de antrenament.
- Ieșire: o imagine care se potrivește sau se referă la descrierea dată.
Degete, modele, probleme
De ce aceste instrumente nu pot genera în mod constant mâini care arată normal? Aceste instrumente funcționează privind pixelii unul lângă altul.
Puteți vedea cum funcționează acest lucru atunci când comparați imaginile generate mai devreme sau mai primitive cu cele mai recente: modelele anterioare arată foarte neclare. În schimb, modelele mai recente sunt mult mai clare.
Aceste modele generează imagini prin predicția următorului pixel pe baza pixelilor pe care i-a generat deja. Acest proces se repetă de milioane de ori pentru a produce o imagine completă.
Mâinile, în special degetele, sunt complicate și au o mulțime de detalii care trebuie surprinse cu acuratețe.
Poziționarea, lungimea și orientarea fiecărui deget pot varia foarte mult în diferite imagini.
Atunci când generează o imagine dintr-o descriere textuală, modelul trebuie să facă multe presupuneri cu privire la poziția și structura exactă a mâinii, ceea ce poate duce la anomalii.
ChatGPT
ChatGPT se bazează pe arhitectura GPT-3.5, un model bazat pe transformator conceput pentru sarcini de procesare a limbajului natural.
- Intrare: un prompt sau o serie de mesaje pentru a simula o conversație.
- Procesare: ChatGPT își folosește cunoștințele vaste din diverse texte de pe internet pentru a genera răspunsuri. Ia în considerare contextul oferit în conversație și încearcă să producă cel mai relevant și coerent răspuns.
- Ieșire: un răspuns text care continuă sau răspunde la conversație.
Specialitate
Puterea ChatGPT constă în capacitatea sa de a trata diverse subiecte și de a simula conversații umane, făcându-l ideal pentru chatbot și asistenți virtuali.
Bard + Search Generative Experience (SGE)
În timp ce detaliile specifice ar putea fi proprietare, Bard se bazează pe tehnici AI transformatoare, similare cu alte modele de limbaj de ultimă generație. SGE se bazează pe modele similare, dar se împletește în alți algoritmi ML pe care îi folosește Google.
SGE generează probabil conținut folosind un model generativ bazat pe transformator și apoi extrage răspunsuri neclare din paginile de clasare în căutare. (Este posibil să nu fie adevărat. Doar o presupunere bazată pe modul în care pare să funcționeze din jocul cu ea. Vă rog să nu mă dați în judecată!)
- Intrare: un prompt/comandă/căutare
- Procesare: Bard procesează intrarea și funcționează așa cum fac alți LLM. SGE folosește o arhitectură similară, dar adaugă un strat în care își caută cunoștințele interne (dobândite din datele de instruire) pentru a genera un răspuns adecvat. Acesta ia în considerare structura, contextul și intenția promptului de a produce conținut relevant.
- Rezultat: conținut generat care poate fi o poveste, un răspuns sau orice alt tip de text.
Aplicații ale inteligenței artificiale generative (și controversele acestora)
Artă și Design
AI generativ poate crea acum lucrări de artă, muzică și chiar design de produse. Acest lucru a deschis noi căi pentru creativitate și inovație.
Controversă
Creșterea IA în artă a stârnit dezbateri despre pierderea locurilor de muncă în domeniile creative.
În plus, există preocupări cu privire la:
- Încălcări ale muncii, în special atunci când conținutul generat de inteligență artificială este utilizat fără atribuirea sau compensarea corespunzătoare.
- Directorii care amenință scriitorii cu înlocuirea lor cu inteligență artificială este una dintre problemele care au stimulat greva scriitorilor.
Procesarea limbajului natural (NLP)
Modelele AI sunt acum utilizate pe scară largă pentru chatbot, traducerea limbilor și alte sarcini NLP.
În afara visului inteligenței generale artificiale (AGI), aceasta este cea mai bună utilizare pentru LLM, deoarece acestea sunt aproape de un model NLP „generalist”.
Controversă
Mulți utilizatori consideră că chatbot-urile sunt impersonale și uneori enervante.
În plus, în timp ce AI a făcut progrese semnificative în traducerea limbilor, adesea îi lipsesc nuanța și înțelegerea culturală pe care le aduc traducătorii umani, ceea ce duce la traduceri impresionante și greșite.
Descoperirea medicamentelor și a medicamentelor
AI poate analiza rapid cantități mari de date medicale și poate genera potențiali compuși ai medicamentelor, accelerând procesul de descoperire a medicamentelor. Mulți medici folosesc deja LLM-urile pentru a scrie note și comunicări cu pacienții
Controversă
Bazarea pe LLM în scopuri medicale poate fi problematică. Medicina necesită precizie, iar orice erori sau neglijeri ale inteligenței artificiale pot avea consecințe grave.
De asemenea, medicina are deja prejudecăți care doar devin mai coapte în utilizarea LLM-urilor. Există, de asemenea, probleme similare, așa cum se discută mai jos, cu confidențialitatea, eficacitatea și etica.
Jocuri
Mulți pasionați de IA sunt încântați de utilizarea AI în jocuri: ei spun că AI poate genera medii de joc realiste, personaje și chiar intrigi întregi de joc, îmbunătățind experiența de joc. Dialogul NPC poate fi îmbunătățit prin utilizarea acestor instrumente.
Controversă
Există o dezbatere despre intenționalitatea în designul jocului.
În timp ce AI poate genera cantități mari de conținut, unii susțin că îi lipsește designul deliberat și coeziunea narativă pe care le aduc designerii umani.
Watchdogs 2 a avut NPC-uri programatice, care au contribuit puțin la coeziunea narativă a jocului în ansamblu.
Marketing și publicitate
AI poate analiza comportamentul consumatorilor și poate genera reclame personalizate și conținut promoțional, făcând campaniile de marketing mai eficiente.
LLM-urile au context din scrisul altor persoane, ceea ce le face utile pentru generarea de povești ale utilizatorilor sau idei programatice mai nuanțate. În loc să recomande televizoare cuiva care tocmai și-a cumpărat un televizor, LLM-urile pot recomanda accesorii pe care cineva le-ar putea dori în schimb.
Controversă
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.