
Studiu de caz SEO pe parcursul unui an: Ce trebuie să știți despre Googlebot
Publicat: 2019-08-30Nota editorului: CEO-ul crawler-ului JetOctopus, Serge Bezborodov, oferă sfaturi experți despre cum să vă faceți site-ul atractiv pentru Googlebot. Datele din acest articol se bazează pe cercetări de un an și pe 300 de milioane de pagini accesate cu crawlere.
În urmă cu câțiva ani, încercam să măresc traficul pe site-ul nostru de agregare a locurilor de muncă cu 5 milioane de pagini. Am decis să folosesc serviciile de agenție SEO, așteptându-mă ca traficul să treacă prin acoperiș. Dar m-am înșelat. În loc de un audit cuprinzător, am citit cărți de tarot. De aceea, m-am întors la punctul unu și am creat un crawler web pentru o analiză SEO completă pe pagină.
Spionez Googlebot de mai bine de un an și acum sunt gata să împărtășesc informații despre comportamentul acestuia. Mă aștept că observațiile mele vor clarifica cel puțin modul în care funcționează crawlerele web și cel mult vă vor ajuta să realizați eficient optimizarea paginii. Am adunat cele mai semnificative date care sunt utile fie pentru un site web nou, fie pentru unul care are mii de pagini.
Sunt paginile dvs. afișate în SERP-uri?
Pentru a ști cu siguranță ce pagini sunt în rezultatele căutării, ar trebui să verificați capacitatea de indexare a întregului site web. Cu toate acestea, analizele fiecărei adrese URL pe un site web de peste 10 milioane de pagini costă o avere, cam la fel de mult ca o mașină nouă.
Să folosim în schimb analiza fișierelor jurnal. Lucrăm cu site-urile web în felul următor: accesăm cu crawlere paginile web așa cum face botul de căutare, apoi analizăm fișierele jurnal care au fost adunate pentru jumătate de an. Jurnalele arată dacă roboții vizitează site-ul web, ce pagini au fost accesate cu crawlere și când și cât de des au vizitat roboții paginile.
Crawling-ul este procesul prin care roboții de căutare vă vizitează site-ul web, procesează toate linkurile de pe paginile web și plasează aceste link-uri în linie pentru indexare. În timpul accesării cu crawlere, roboții compară adresele URL tocmai procesate cu cele aflate deja în index. Astfel, boții reîmprospătează datele și adaugă/șterg unele URL-uri din baza de date a motorului de căutare pentru a oferi utilizatorilor cele mai relevante și proaspete rezultate.
Acum, putem trage cu ușurință aceste concluzii:
- Cu excepția cazului în care botul de căutare a fost pe adresa URL, probabil că această adresă URL nu va fi în index.
- Dacă Googlebot vizitează adresa URL de mai multe ori pe zi, acea adresă URL are prioritate ridicată și, prin urmare, necesită o atenție specială.
În total, aceste informații dezvăluie ceea ce împiedică creșterea organică și dezvoltarea site-ului dvs. Acum, în loc să opereze orbește, echipa ta poate optimiza cu înțelepciune un site web.
Lucrăm în mare parte cu site-uri web mari, deoarece, dacă site-ul dvs. este mic, Googlebot va accesa cu crawlere toate paginile dvs. web mai devreme sau mai târziu.
În schimb, site-urile web cu peste 100.000 de pagini se confruntă cu o problemă atunci când crawlerul vizitează pagini care sunt invizibile pentru webmasteri. Un buget valoros de accesare cu crawlere poate fi irosit pe aceste pagini inutile sau chiar dăunătoare. În același timp, este posibil ca botul să nu găsească niciodată paginile dvs. profitabile, deoarece există o mizerie în structura unui site web.
Bugetul de accesare cu crawlere reprezintă resursele limitate pe care Googlebot este gata să le cheltuiască pe site-ul dvs. A fost creat pentru a prioritiza ce să analizeze și când. Mărimea bugetului de accesare cu crawlere depinde de mulți factori, cum ar fi dimensiunea site-ului dvs. web, structura acestuia, volumul și frecvența interogărilor utilizatorilor etc.
Rețineți că robotul de căutare nu este interesat să acceseze cu crawlere complet site-ul dvs.
Scopul principal al robotului motor de căutare este de a oferi utilizatorilor cele mai relevante răspunsuri cu pierderi minime de resurse.Botul accesează cu crawlere câte date are nevoie pentru scopul principal. Așadar, este sarcina TA să ajuți botul să culeagă cel mai util și mai profitabil conținut.
Spionarea Googlebot
În ultimul an, am scanat peste 300 de milioane de adrese URL și 6 miliarde de linii de jurnal pe site-uri mari. Pe baza acestor date, am urmărit comportamentul Googlebot pentru a răspunde la următoarele întrebări:
- Ce tipuri de pagini sunt ignorate?
- Ce pagini sunt vizitate frecvent?
- Ce merită atenție pentru bot?
- Ce nu are valoare?
Mai jos sunt analiza și constatările noastre, și nu o rescrie a Ghidurilor Google pentru webmasteri. De fapt, nu oferim recomandări nedovedite și nejustificate. Fiecare punct se bazează pe statistici și grafice faptice pentru confortul dvs.
Să trecem la urmărire și să aflăm:
- Ce contează cu adevărat pentru Googlebot?
- Ce determină dacă botul vizitează pagina sau nu?
Am identificat următorii factori:
Distanța față de index
DFI înseamnă Distanța de la Index și este cât de departe este adresa URL pentru adresa URL principală/rădăcină/index în clicuri. Este unul dintre cele mai importante criterii care influențează frecvența vizitelor Googlebot. Iată un videoclip educațional pentru a afla mai multe despre DFI .
Rețineți că DFI nu este numărul de bare oblice din directorul URL, cum ar fi, de exemplu:
site.com / magazin /iphone/iphoneX.html – DFI – 3
Deci, DFI se numără exact prin CLICK-uri din pagina principală
https://site.com/shop/iphone/iphoneX.html
https://site.com Catalog iPhones → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Mai jos puteți vedea cum interesul Googlebot față de adresa URL cu DFI sa redus treptat în ultima lună și în ultimele șase luni.
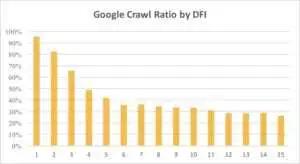
După cum puteți vedea, dacă DFI este 5 t0 6, Googlebot accesează cu crawlere doar jumătate din paginile web. Iar procentul de pagini procesate se reduce dacă DFI este mai mare. Indicatorii din tabel au fost unificați pentru 18 milioane de pagini. Rețineți că datele pot varia în funcție de nișa site-ului respectiv.
Ce să fac?
Este evident că cea mai bună strategie în acest caz este să eviți DFI care este mai mare de 5, să construiești o structură a site-ului web ușor de navigat, să acorzi o atenție deosebită link-urilor etc.
Adevărul este că aceste măsuri necesită foarte mult timp pentru site-urile web cu peste 100, ooo de pagini. De obicei, site-urile web mari au o istorie lungă de reproiectări și migrări. De aceea, webmasterii nu ar trebui să ștergă doar pagini cu DFI de 10, 12 sau chiar 30. De asemenea, inserarea unui link de la paginile vizitate frecvent nu va rezolva problema.
Modul optim de a face față cu DFI lung este de a verifica și estima dacă aceste adrese URL sunt relevante, profitabile și ce poziții au în SERP-uri.
Paginile cu DFI lung, dar poziții bune în SERP-uri au un potențial ridicat. Pentru a crește traficul pe pagini de înaltă calitate, webmasterii ar trebui să introducă link-uri din paginile următoare. Una sau două legături nu sunt suficiente pentru un progres tangibil.
Puteți vedea din graficul de mai jos că Googlebot vizitează mai des adresele URL dacă există mai mult de 10 link-uri pe pagină.
Legături
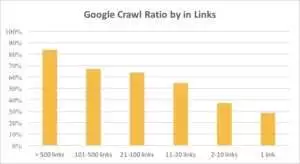
De fapt, cu cât este mai mare un site web, cu atât este mai important numărul de link-uri pe paginile web. Aceste date provin de fapt de pe site-uri web de peste 1 milion de pagini.

Dacă ați descoperit că există mai puțin de 10 link-uri pe paginile dvs. profitabile, nu vă panicați. În primul rând, verificați dacă aceste pagini sunt de înaltă calitate și profitabile. Când faceți asta, inserați link-uri pe pagini de înaltă calitate fără grabă și cu iterații scurte, analizând jurnalele după fiecare pas.
Dimensiunea conținutului
Conținutul este unul dintre cele mai populare aspecte ale analizei SEO. Desigur, cu cât conținutul mai relevant este pe site-ul dvs., cu atât rata de accesare cu crawlere este mai bună. Mai jos puteți vedea cât de dramatic scade interesul Googlebot pentru paginile cu mai puțin de 500 de cuvinte.
Ce să fac?
Pe baza experienței mele, aproape jumătate din toate paginile cu mai puțin de 500 de cuvinte sunt pagini de gunoi. Am văzut un caz în care un site web conținea 70.000 de pagini cu doar dimensiunea hainelor enumerate, așa că doar o parte din aceste pagini erau în index.
Prin urmare, mai întâi verificați dacă aveți într-adevăr nevoie de acele pagini. Dacă aceste adrese URL sunt importante, ar trebui să adăugați conținut relevant asupra lor. Dacă nu aveți nimic de adăugat, relaxați-vă și lăsați aceste adrese URL așa cum sunt. Uneori este mai bine să nu faci nimic în loc să publici conținut inutil.
Alti factori
Următorii factori pot avea un impact semnificativ asupra raportului de accesare cu crawlere:
Timp de încărcare
Viteza paginii web este crucială pentru accesare cu crawlere și clasare. Botul este ca un om: urăște să aștepte prea mult ca o pagină web să se încarce. Dacă există mai mult de 1 milion de pagini pe site-ul dvs., robotul de căutare va descărca probabil cinci pagini cu un timp de încărcare de 1 secundă, în loc să aștepte o pagină care se încarcă în 5 secunde.
Ce să fac?
De fapt, aceasta este o sarcină tehnică și nu există o soluție „o singură metodă”, cum ar fi utilizarea unui server mai mare. Ideea principală este de a găsi blocajul problemei. Ar trebui să înțelegeți de ce paginile web se încarcă lent. Numai după ce motivul este dezvăluit, puteți lua măsuri.
Raportul dintre conținut unic și șablon
Echilibrul dintre datele unice și cele tip șablon este important. De exemplu, aveți un site web cu variații de nume de animale de companie. Cât de mult conținut relevant și unic puteți aduna cu adevărat despre acest subiect?
Luna a fost cel mai popular nume de câine „celebritate”, urmat de Stella, Jack, Milo și Leo.
Boților de căutare nu le place să-și cheltuiască resursele pe astfel de pagini.
Ce să fac?
Menține echilibrul. Utilizatorilor și roboților nu le place să viziteze pagini cu șabloane complicate, o grămadă de link-uri de ieșire și puțin conținut.
Pagini Orfane
Paginile orfane sunt adrese URL care nu se află în structura site-ului web și nu știți despre aceste pagini, dar aceste pagini orfane pot fi accesate cu crawlere de roboți. Pentru a fi clar, uitați-vă la Cercul lui Euler din imaginea de mai jos:

Puteți vedea situația normală pentru tânărul site, a cărui structură nu a fost schimbată de ceva vreme. Există 900.000 de pagini pe care dumneavoastră și crawler-ul puteți analiza. Aproximativ 500.000 de pagini sunt procesate de crawler, dar sunt necunoscute de Google. Dacă faceți ca aceste 500.000 de adrese URL să fie indexate, traficul dvs. va crește cu siguranță.
Atenție: chiar și un site tânăr conține câteva pagini (partea albastră din imagine) care nu sunt în structura site-ului, dar sunt vizitate în mod regulat de bot.
Și aceste pagini ar putea conține conținut de gunoi, cum ar fi interogări inutile ale vizitatorilor generate automat.
Dar site-urile mari rare sunt atât de precise. Foarte des site-urile web cu istorie arată astfel:

Iată cealaltă problemă: Google știe mai multe despre site-ul tău decât tine. Pot exista pagini șterse, pagini pe JavaScript sau Ajax, redirecționări rupte și așa mai departe și așa mai departe. Odată ne-am confruntat cu o situație în care o listă de 500.000 de link-uri sparte a apărut în harta site-ului din cauza unei greșeli a unui programator. După trei zile, eroarea a fost găsită și remediată, dar Googlebot a vizitat aceste linkuri rupte de jumătate de an!
Adesea, bugetul dvs. de accesare cu crawlere este irosit frecvent pe aceste pagini orfane.
Ce să fac?
Există două moduri de a remedia această problemă potențială: Prima este canonică: curățarea mizeriei. Organizați structura site-ului web, introduceți corect link-uri interne, adăugați pagini orfane la DFI adăugând link-uri din paginile indexate, setați sarcina programatorilor și așteptați următoarea vizită Googlebot.
A doua modalitate este promptă: adunați lista de pagini orfane și verificați dacă acestea sunt relevante. Dacă răspunsul este „da”, atunci creați harta site-ului cu aceste adrese URL și trimiteți-l la Google. Acest mod este mai ușor și mai rapid, dar doar jumătate din paginile orfane vor fi în index.
Următorul Nivel
Algoritmii motoarelor de căutare s-au îmbunătățit timp de două decenii și este naiv să credem că accesarea cu crawlere a căutării ar putea fi explicată cu câteva grafice.
Adunăm peste 200 de parametri diferiți pentru fiecare pagină și ne așteptăm ca acest număr să crească până la sfârșitul anului. Imaginați-vă că site-ul dvs. este tabelul cu 1 milion de linii (pagini) și înmulțiți aceste rânduri cu 200 de coloane, eșantionul simplu nu este suficient pentru un audit tehnic complet. Sunteți de acord?
Am decis să ne aprofundăm și am folosit învățarea automată pentru a afla ce influențează accesarea cu crawlere a robotilor Google în fiecare caz.

Pentru unul, link-urile site-urilor sunt cruciale, în timp ce conținutul este factorul cheie pentru celălalt.
Principalul obiectiv al acestei sarcini a fost să obțineți răspunsuri simple din date complicate și masive: ce de pe site-ul dvs. afectează cel mai mult indexarea? Ce grupuri de adrese URL sunt conectate cu aceiași factori? Pentru a putea lucra cu ei în mod cuprinzător.
Înainte de a descărca și analiza jurnalele pe site-ul nostru de agregare HotWork, povestea despre paginile orfane care sunt vizibile pentru roboți, dar nu pentru noi mi s-a părut nerealistă. Dar situația reală m-a surprins și mai mult: Crawl a arătat 500 de pagini cu 301 de redirecționare, dar Yandex a găsit 700.000 de pagini cu același cod de stare.
De obicei, tehnicienilor nu le place să stocheze fișiere jurnal, deoarece aceste date „supraîncărcă” discurile. Dar obiectiv, pe majoritatea site-urilor web cu până la 10 milioane de vizite pe lună, setarea de bază a stocării jurnalelor funcționează perfect.
Apropo de volumul de jurnal, cea mai bună soluție este să creați o arhivă și să o descărcați pe Amazon S3-Glacier (puteți stoca 250 GB de date pentru doar 1 USD). Pentru administratorii de sistem, această sarcină este la fel de ușoară ca și a face o ceașcă de cafea. În viitor, jurnalele istorice vor ajuta la dezvăluirea erorilor tehnice și la estimarea influenței actualizărilor Google pe site-ul dvs.