
Apache Apex — введение
Опубликовано: 2015-12-29Apache Hadoop де-факто стал программной средой для надежных, масштабируемых, распределенных и крупномасштабных вычислений. С момента своего создания Hadoop был предпочтительным фреймворком для пакетной обработки. Все, от крупных банков до гигантов онлайн-торговли, используют Hadoop для создания периодических отчетов, вычислений и многих других вариантов использования. Как правило, эти варианты использования представляют собой пакетно-ориентированные процессы, и требуется несколько часов, прежде чем мы получим смысл из данных. Современный стремительный мир требует осмысления или действий на основе необработанных данных практически в момент их создания. Это привело к концепции потоковой обработки. Хотя изначально Hadoop не считался пригодным для потоковой обработки, изобретение YARN (Hadoop 2.0) сделало его хорошим кандидатом для этой цели. В настоящее время в экосистеме Hadoop существует несколько фреймворков потоковой обработки, и Apex — совершенно новый фреймворк, выходящий на этот переполненный рынок.
Что такое Apache Apex?
Apache Apex — это собственная платформа на основе YARN, которая помогает разработчику приложений писать как потоковые, так и пакетные приложения. Он предназначен для обработки данных в движении, распределенным, высокопроизводительным и отказоустойчивым способом. Обледенение этого — простой API, который позволяет пользователям писать свой код Java с ограниченными знаниями об обработке потоков.
Apex основан на отдельных функциональных и эксплуатационных спецификациях, а не на их объединении. Это заставляет разработчиков приложений сосредоточиться на написании пользовательских функций, не задумываясь о том, как они будут работать в распределенной среде.
Apache Apex имеет богатую библиотеку часто используемых функций. Они добавляются как часть библиотеки Apache Apex-Malhar. В этой библиотеке есть операторы для доступа к различным файловым системам, базам данных, очередям сообщений. Сообщество ежедневно добавляет операторов, облегчая жизнь разработчикам приложений.
Что такое основные блоки Apache Apex?
Архитектура Apex очень проста. В Apex есть Malhar, библиотека операторов и основной движок для работы. Ядро Apex можно изобразить следующим образом, их часто называют основными блоками Apache Apex.
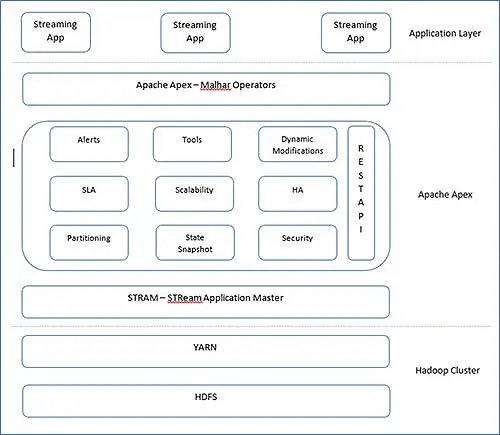
Вы можете четко разделить слои и получить обзор, где это подходит. Посмотрим информацию об этих блоках.
- StrAM ( мастер приложений Stream )
StrAM является мастером приложений YARN. В его обязанности входит запуск потоковых приложений, распределение ресурсов, планирование логических DAG. Наряду с этими операциями YARN StrAM инициализирует операторы, потоки. StrAM также собирает статистику от своих дочерних элементов. - Снимок состояния
Фреймворки потоковой обработки не могли допустить потери обработанных результатов. Кроме того, они должны знать, сколько они обработали, чтобы правильно обрабатывать записи после восстановления после сбоя. Поэтому периодически контрольные точки важны в потоковой обработке. В Apex StrAM отслеживает контрольные точки и на границе оператора, периодически контрольные точки выполняются на HDFS. - ОТДЫХА API
StrAM — это точка доступа для REST API. Внешние инструменты могут получить доступ к этому REST API и интегрироваться с любым внешним приложением. - Инструменты
Apex предоставляет интерфейс командной строки для запуска и мониторинга приложений Apex. Даже мы можем создать свой собственный с помощью REST API. Наряду с интерфейсом командной строки приложение можно настроить с помощью сценариев статической конфигурации для автоматического запуска. - Разделение
- Динамические модификации
- Анализ SLA
Apache Apex периодически самостоятельно выполняет анализ SLA. Он выполняет анализ задержек, узких мест и пропускной способности, а также добавляет дополнительные ресурсы в соответствии с настроенным соглашением об уровне обслуживания. - Безопасность
- Высокая доступность
Apache Apex использует функцию перезапуска YARN и перезапускается из состояния последней контрольной точки. - Малхар
Apache Apex –Malhar — это операторская библиотека с многочисленными операторами. Эти операторы подразделяются на - Операторы ввода/вывода –
В этой категории в настоящее время у Малхара есть операторы для чтения/записи. - Файловая система
- СУБД
- NoSQL-магазины
- Очереди сообщений
- Базы данных в памяти
- Социальные сети
- Операторы вычислений —
- Сопоставление с образцом
- Статистика и математика
- Машинное обучение
- Парсеры
- Социальные сети
- Буферные серверы
Apex обеспечивает секционирование на основе ключей и динамическую балансировку нагрузки. Даже пользователь может определить свою собственную схему разбиения.
Apache Apex имеет эту очень полезную и уникальную функцию. Он поддерживает изменение логического DAG, изменение физического плана выполнения.
Apex поддерживает Kerberos. Лежащий в основе защищенный кластер Hadoop, он может получить доступ с встроенной интеграцией Kerberos.
У Malhar есть много операторов, которые помогут в реальной реализации бизнес-логики. Эта библиотека имеет
Буферные серверы лежат на границе каждого оператора. В случае данных локальные буферные серверы операторов могут быть после строк операторов. Основная их цель — временное удержание данных на краях перед пересылкой на следующий. Они играют важную роль при восстановлении узла после сбоя. Буферные серверы загружают данные из последнего контрольного состояния для воспроизведения

Что такое модель программирования приложений Apex?
Это включает в себя богатую структуру и библиотеку Malhar, что означает, что разработчикам приложений нужно только подключить операторов и запустить приложение. Следовательно, ваше приложение представляет собой не что иное, как последовательность операторов.
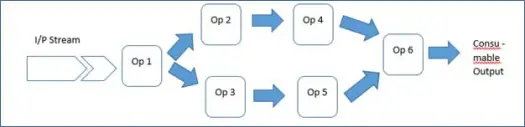
Вот как богатый фреймворк упрощает жизнь разработчика. Итак, давайте посмотрим, как работает это демонстрационное приложение.
Демонстрация Apache Apex
Итак, давайте начнем с « Hello World of Big Data J», небольшой демонстрации подсчета слов с использованием Apache Apex.
Настройка Apache Apex
Чтобы запустить эту демонстрацию, нам нужно настроить Apex. Вы можете установить Apache Apex в свой существующий кластер, или есть простой способ попробовать, вы можете скачать предустановленную виртуальную машину-песочницу с веб-сайта DataTorrent отсюда. Для этой демонстрации мы будем использовать предустановленную виртуальную машину.
Пошаговое руководство по консоли пользовательского интерфейса Apex
Apex поставляется с очень интуитивно понятной и красиво оформленной консолью пользовательского интерфейса, которую можно использовать для запуска, мониторинга и управления приложениями. Он включает в себя различную статистику, касающуюся различных развернутых компонентов.
После того, как вы загрузили виртуальную машину для песочницы, распакуйте ее и загрузите в свой любимый проигрыватель виртуальных машин (я использую проигрыватель виртуальных машин VMWare). Все программное обеспечение и инструменты, необходимые для запуска Apex, уже настроены на этой виртуальной машине, а все сценарии запуска настроены на выполнение при загрузке ОС. Итак, когда ваша виртуальная машина будет запущена, у вас будет работающий экземпляр Apache Apex. Теперь, чтобы просмотреть консоль, просто нажмите http://locahost:9090 в своем любимом веб-браузере и войдите в консоль. Имя пользователя по умолчанию: пароль для виртуальной машины в песочнице — dtadmin: dtadmin. Вы увидите консоль, как показано ниже
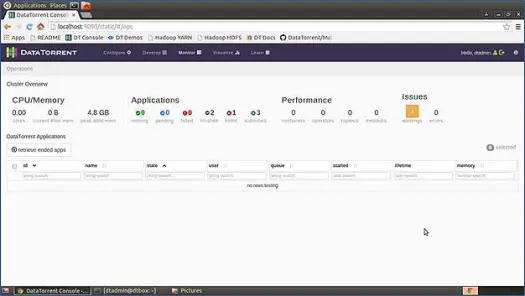
Эта страница дает нам полный обзор всей системы, такой как использование ЦП и памяти, приложения, производительность, проблемы и т. д.
Чтобы развернуть приложение, перейдите на вкладку «Разработка» вверху страницы.
Здесь вы можете развернуть пакеты приложений и управлять схемами кортежей для данных внутри Apex.
Apex предоставляет вам ряд готовых приложений, которые вы можете увидеть в списке ниже:
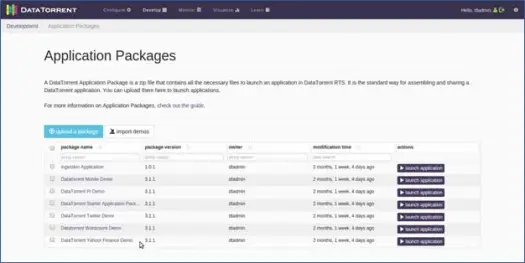
Демонстрация подсчета слов
Теперь давайте запустим приложение подсчета слов. Вы можете сделать это, щелкнув опцию запуска приложения рядом с DataTorrent Wordcount Demo. Затем вы можете предоставить другое приложение и изменить детали конфигурации, если это необходимо (мы не будем этого делать, так как большинство настроек по умолчанию работают нормально, давайте просто изменим имя приложения на «MyWordCountDemo»). Вы увидите сообщение о том, что приложение было успешно развернуто со ссылкой на приложение. Нажмите на эту ссылку.

Это открывает новую страницу. Подождите несколько секунд, пока статус приложения не изменится с «Принято» на «Выполняется». Теперь вы увидите страницу, полную различной статистики и информации. Следующие два скриншота изображают их.
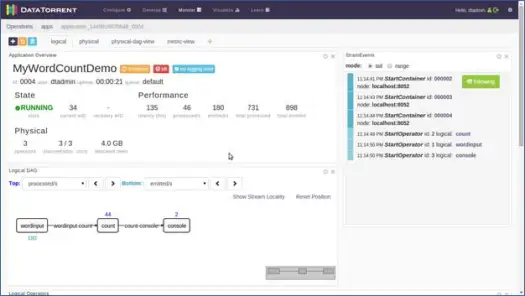
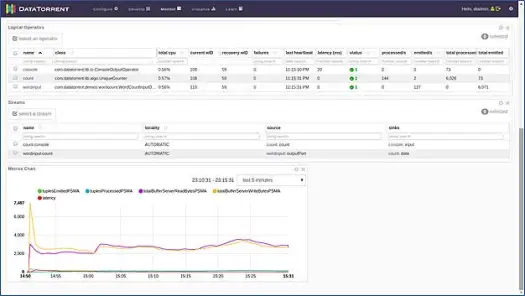
Эти страницы показывают нам различную информацию, такую как логическое, физическое и метрическое представление приложения, а также статистику различных кортежей/записей, которые приложение обрабатывает каждую секунду. Он показывает графическое представление испускаемых кортежей, задержек и т. д.
Вы можете щелкнуть любой логический оператор, просмотреть его записи и даже записать образец. Давайте сделаем это для оператора консоли. Нажмите на оператора консоли, и вы получите подробную информацию об операторе, как показано ниже:
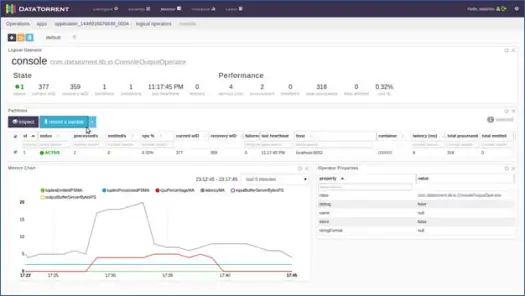
Далее выберите один из разделов и нажмите на запись образца.
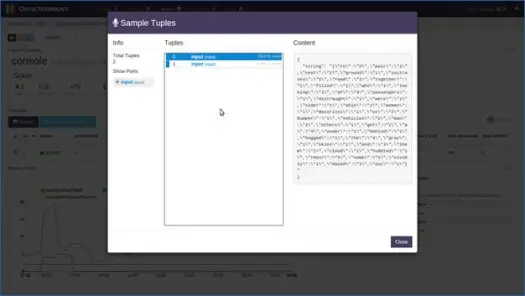
Через несколько секунд вы увидите, что кортежи заполнены. Нажмите на кортеж, чтобы просмотреть его содержимое. Как вы можете видеть из содержимого, приложение выполнило подсчет слов на основе данных на основе окон, и в 0-м входном кортеже для этого окна было 2 «to», 4 «the», 4 «a» и т. д. Теперь вы можете остановить приложение, нажав «Завершить работу» или «Убить» на главной странице приложения.
Вот и все, мы успешно развернули и запустили приложение wordcount.
Заключение
Итак, это было знакомство с новым инструментом потоковой передачи — Apache Apex и успешным запуском приложения в Apache Apex. Apache Apex имеет много важных функций, которые дают ему преимущество перед другими существующими фреймворками, о которых я расскажу в следующих постах.