
Apache Spark: сверкающая звезда на небосводе больших данных.
Опубликовано: 2015-09-24- Рекомендовать миллионы продуктов нужным клиентам.
- Отслеживание истории поиска и предложение скидок на авиабилеты.
- Сравнение технических навыков человека и подходящее предложение людей, с которыми можно связаться в вашей области.
- Понимание закономерностей в миллиардах мобильных объектов, сетевых вышек и транзакций вызовов, а также расчет оптимизации телекоммуникационной сети или поиск сетевых лазеек.
- Изучение миллионов характеристик датчиков и анализ сбоев в сенсорных сетях.
Базовые данные, которые необходимо использовать для получения правильных результатов для всех вышеперечисленных задач, сравнительно очень велики. С ним невозможно эффективно (с точки зрения пространства и времени) справиться с помощью традиционных систем.
Это все сценарии больших данных.
Для сбора, хранения и выполнения вычислений с такими объемными данными нам нужна специализированная кластерная вычислительная система. Apache Hadoop решил эту проблему за нас.
Он предлагает распределенную систему хранения (HDFS) и платформу параллельных вычислений (MapReduce).
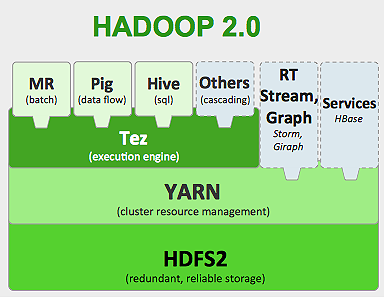
Фреймворк Hadoop работает следующим образом:
- Разбивает большие файлы данных на более мелкие фрагменты для обработки отдельными машинами (распределение хранилища).
- Разделяет более длинную работу на более мелкие задачи, которые будут выполняться параллельно (параллельные вычисления).
- Автоматически обрабатывает сбои.
Ограничения Hadoop
Hadoop имеет в своей экосистеме специализированные инструменты для выполнения различных задач. Итак, если вы хотите запустить сквозной жизненный цикл приложения, вам нужно использовать несколько инструментов. Например, для SQL -запросов, которые вы будете использовать, hive/pig , для потоковых источников вам нужно использовать встроенную потоковую передачу Hadoop или Apache Storm (который не является частью экосистемы Hadoop), или для алгоритмов машинного обучения вы должны использовать Mahout . Интеграция всех этих систем вместе для создания единого варианта использования конвейера данных — непростая задача.
В задании MapReduce
- Все выходные данные картографических задач сбрасываются на локальные диски (или HDFS).
- Hadoop объединяет все файлы разлива в один файл большего размера, который сортируется и разбивается на разделы в соответствии с количеством редюсеров.
- И задачи сокращения приходится заново загружать в память.
Этот процесс замедляет работу, вызывая дисковый ввод-вывод и сетевой ввод-вывод. Это также делает Mapreduce непригодным для итеративной обработки, когда вам приходится снова и снова применять алгоритмы машинного обучения к одной и той же группе данных.
Войдите в мир Apache Spark:
Apache Spark был разработан в UC Berkeley AMPLAB в 2009 году, а в 2010 году он стал самым популярным проектом Apache с открытым исходным кодом на сегодняшний день.
Apache Spark — это более универсальная система, в которой вы можете одновременно запускать как пакетные, так и потоковые задания . Он превосходит своего предшественника MapReduce по скорости, добавляя возможности для более быстрой обработки данных в памяти. Это также более эффективно на диске. Он использует при обработке памяти, используя свой базовый блок данных RDD (Resilient Distributed Dataset). Они содержат максимально возможный объем данных в памяти для полного жизненного цикла задания, следовательно, экономят дисковый ввод-вывод. Некоторые данные могут попасть на диск за пределами верхнего предела памяти.
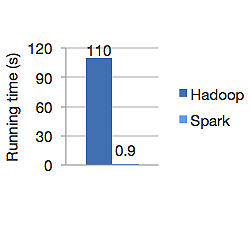
На приведенном ниже графике показано время работы Apache Hadoop и Spark в секундах для расчета логистической регрессии. Hadoop потребовалось 110 секунд, в то время как Spark выполнил ту же работу всего за 0,9 секунды.
Spark не хранит все данные в памяти. Но если данные находятся в памяти, лучше всего использовать кеш LRU для их более быстрой обработки. Это в 100 раз быстрее при обработке данных в памяти и еще быстрее на диске, чем у Hadoop.
Распределенная модель хранения данных Spark, отказоустойчивые распределенные наборы данных (RDD), гарантирует отказоустойчивость, которая, в свою очередь, минимизирует сетевой ввод-вывод. Искра бумага говорит:

«RDD обеспечивают отказоустойчивость благодаря понятию происхождения: если раздел RDD потерян, у RDD достаточно информации о том, как он был получен из других RDD, чтобы иметь возможность восстановить только этот раздел».
Таким образом, вам не нужно реплицировать данные для достижения отказоустойчивости.
В Spark MapReduce выходные данные картографов хранятся в буферном кеше ОС, а редукторы извлекают их на свою сторону и записывают непосредственно в свою память, в отличие от Hadoop, где выходные данные перебрасываются на диск и снова считываются.
Кэш-память Spark делает его пригодным для алгоритмов машинного обучения, где вам нужно использовать одни и те же данные снова и снова. Spark может выполнять сложные задания, многоэтапные конвейеры данных с использованием прямого ациклического графа (DAG).
Spark написан на Scala и работает на JVM (виртуальная машина Java). Spark предлагает API-интерфейсы разработки для языков Java, Scala, Python и R. Spark работает на Hadoop YARN, Apache Mesos, а также имеет собственный автономный менеджер кластера.
В 2014 году он занял 1-е место в мировом рекорде по сортировке 100 ТБ данных (1 триллион записей) всего за 23 минуты, тогда как предыдущий рекорд Hadoop от Yahoo составлял около 72 минут. Это доказывает, что Spark сортирует данные в 3 раза быстрее и использует в 10 раз меньше машин. Вся сортировка происходила на диске (HDFS) без фактического использования возможностей искрового кэша в памяти.
Экосистема искры
Spark предназначен для выполнения расширенной аналитики за один раз, для чего он предлагает следующие компоненты:
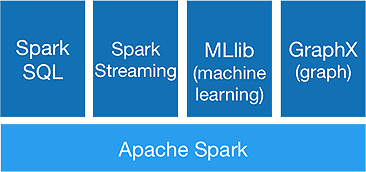
1.Искровое ядро:
Основной API Spark является основой платформы Apache Spark, которая занимается планированием заданий, распределением задач, управлением памятью, операциями ввода-вывода и восстановлением после сбоев. Основная логическая единица данных в spark называется RDD (Resilient Distributed Dataset), которая хранит данные в распределенном виде для последующей параллельной обработки. Он лениво вычисляет операции. Следовательно, память не обязательно должна быть занята все время, и ее могут использовать другие задания.
2.Искра SQL:
Он предлагает интерактивные возможности запросов с низкой задержкой. Новый API-интерфейс DataFrame может хранить как структурированные, так и полуструктурированные данные и позволяет всем операциям и функциям SQL выполнять вычисления.
3.Искра потокового:
Он предоставляет API-интерфейсы потоковой передачи в реальном времени , которые собирают и обрабатывают данные микропакетами.
Он использует Dstreams , которые представляют собой не что иное, как непрерывную последовательность RDD , для вычисления бизнес-логики на входных данных и немедленной генерации результатов.
4.MLlib :
Это библиотека машинного обучения Spark (почти в 9 раз быстрее, чем Mahout), которая обеспечивает машинное обучение, а также статистические алгоритмы, такие как классификация, регрессия, совместная фильтрация и т. д.
5.ГрафикX :
GraphX API предоставляет возможности для обработки графиков и выполнения граф-параллельных вычислений. Он включает в себя графические алгоритмы, такие как PageRank, и различные функции для анализа графов.
Ознаменует ли Spark конец эры Hadoop?
Spark все еще молодая система, не такая зрелая, как Hadoop. Для NOSQL нет такого инструмента, как HBase. Учитывая высокие требования к памяти для более быстрой обработки данных, вы не можете сказать, что он работает на обычном оборудовании. Spark не имеет собственной системы хранения. Для этого он использует HDFS.
Таким образом, Hadoop MapReduce по-прежнему хорош для некоторых пакетных заданий, которые не включают в себя конвейерную обработку данных.
«Новая технология никогда полностью не заменяет старую; они оба предпочли бы сосуществовать».
Заключение
В этом блоге мы рассмотрели, зачем вам нужен такой инструмент, как Spark, что делает его более быстрой кластерной вычислительной системой и ее основными компонентами. В следующей части мы углубимся в RDD, преобразования и действия основного API Spark.