
Создание приложения с использованием Serverless Framework, AWS и BigQuery
Опубликовано: 2021-01-28Бессерверные относятся к приложениям, в которых управление и распределение серверов и ресурсов управляется облачным провайдером. Это означает, что облачный провайдер динамически распределяет ресурсы. Приложение работает в контейнере без сохранения состояния, который может запускаться событием. Один из таких примеров из вышеперечисленного, который мы будем использовать в этой статье, касается AWS Lambda .
Короче говоря, мы можем определить «Бессерверные приложения» как приложения, которые представляют собой облачные системы, управляемые событиями. Приложение опирается на сторонние сервисы, логику на стороне клиента и удаленные вызовы (прямо называя его Function as a Service ).
Установка Serverless Framework и ее настройка для Amazon AWS

1. Бессерверная среда
Serverless Framework — это платформа с открытым исходным кодом. Он состоит из интерфейса командной строки или CLI и размещенной панели инструментов, которая предоставляет нам полностью бессерверную систему управления приложениями. Использование Framework обеспечивает меньшие накладные расходы и затраты, быструю разработку и развертывание, а также защиту бессерверных приложений.
Прежде чем приступить к установке фреймворка Serverless, вам необходимо сначала настроить NodeJS. Это очень легко сделать в большинстве операционных систем — вам просто нужно посетить официальный сайт NodeJS, чтобы загрузить и установить его. Не забудьте выбрать версию выше 6.0.0.
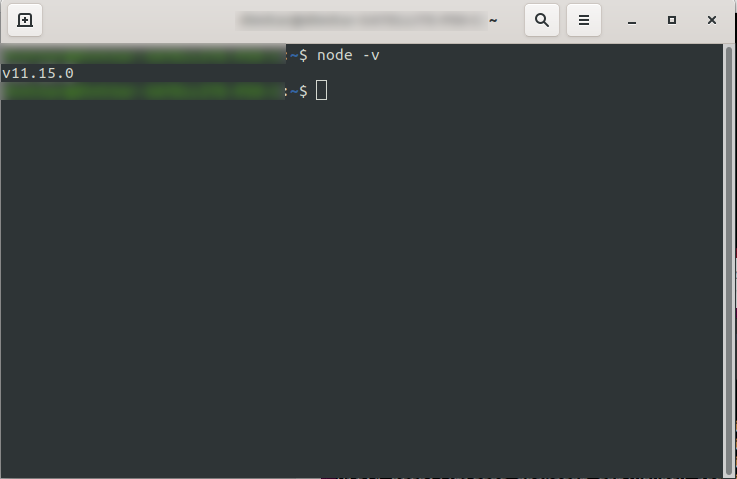
После его установки вы можете убедиться, что NodeJS доступен, запустив node -v в консоли. Он должен вернуть версию узла, которую вы установили:
Теперь все готово, так что продолжайте установку Serverless framework.
Для этого следуйте документации по установке и настройке фреймворка. При желании вы можете установить его только для одного проекта, но в DevriX мы обычно устанавливаем фреймворк глобально: npm install -g serverless
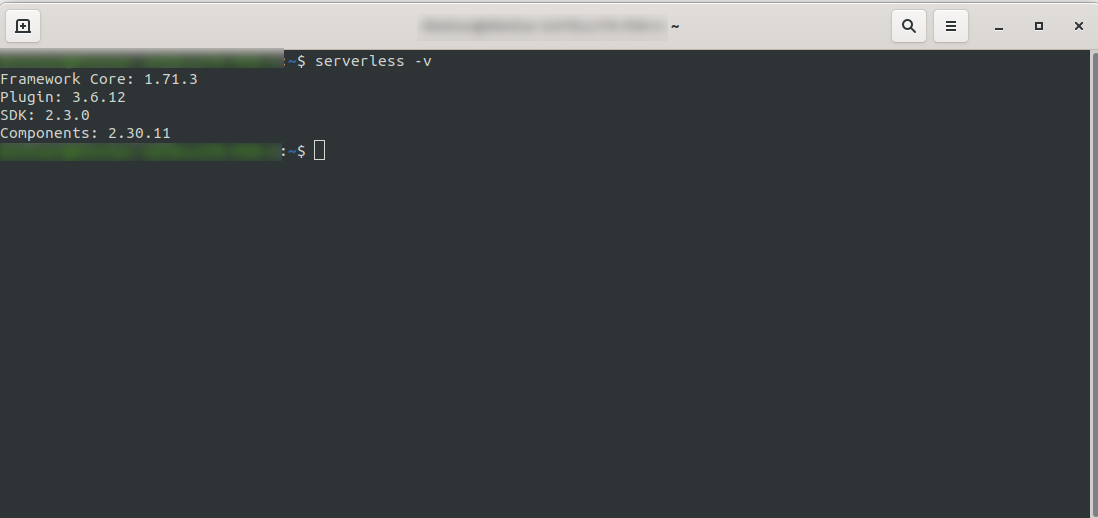
Дождитесь завершения процесса и убедитесь, что Serverless успешно установлен, выполнив: serverless -v
2. Создайте учетную запись Amazon AWS
Прежде чем приступить к созданию примера приложения, необходимо создать учетную запись в Amazon AWS . Если у вас его еще нет, это так же просто, как зайти на Amazon AWS, нажать «Создать учетную запись AWS» в правом верхнем углу и выполнить шаги по созданию учетной записи.
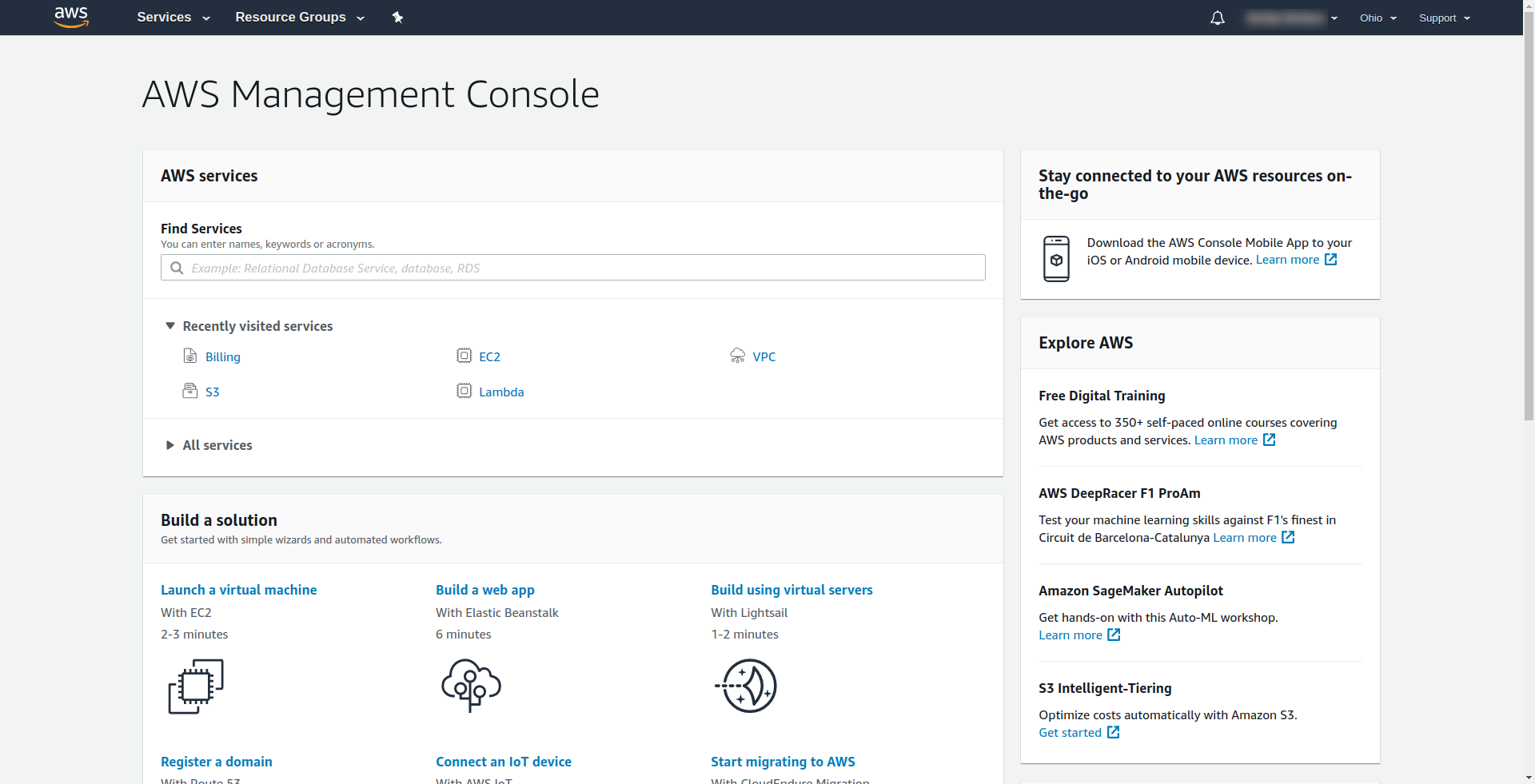
Amazon требует, чтобы вы ввели кредитную карту, поэтому вы не можете продолжить без ввода этой информации. После успешной регистрации и входа в систему вы должны увидеть Консоль управления AWS:
Здорово! Давайте приступим к созданию вашего приложения.
3. Настройте бессерверную платформу с помощью AWS Provider и создайте пример приложения.
На этом этапе нам нужно настроить бессерверную структуру с помощью поставщика AWS. Некоторые сервисы, такие как AWS Lambda, требуют учетных данных при доступе к ним, чтобы убедиться, что у вас есть разрешения на доступ к ресурсам, принадлежащим этому сервису. Для этого AWS рекомендует использовать AWS Identity and Access Manager (IAM).
Итак, первое и самое важное — создать пользователя IAM в AWS , чтобы использовать его в нашем приложении:
В консоли AWS:
- Введите IAM в поле «Найти службы» .
- Нажмите «ИАМ» .
- Перейдите в «Пользователи» .
- Нажмите «Добавить пользователя» .
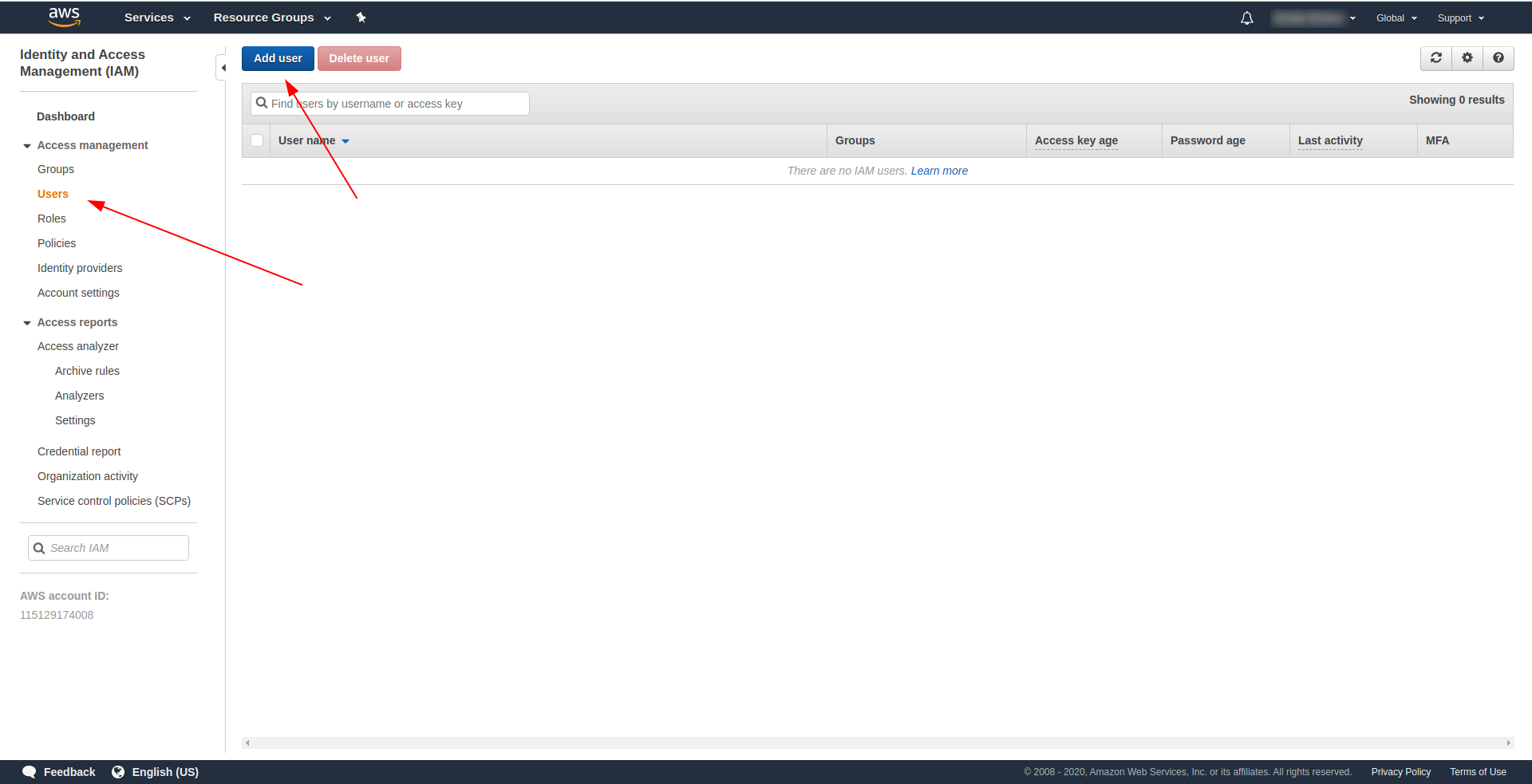
В качестве «Имени пользователя» используйте все, что хотите. Например, мы используем serverless-admin. Для « Тип доступа» установите флажок «Программный доступ» и нажмите «Следующие разрешения ».
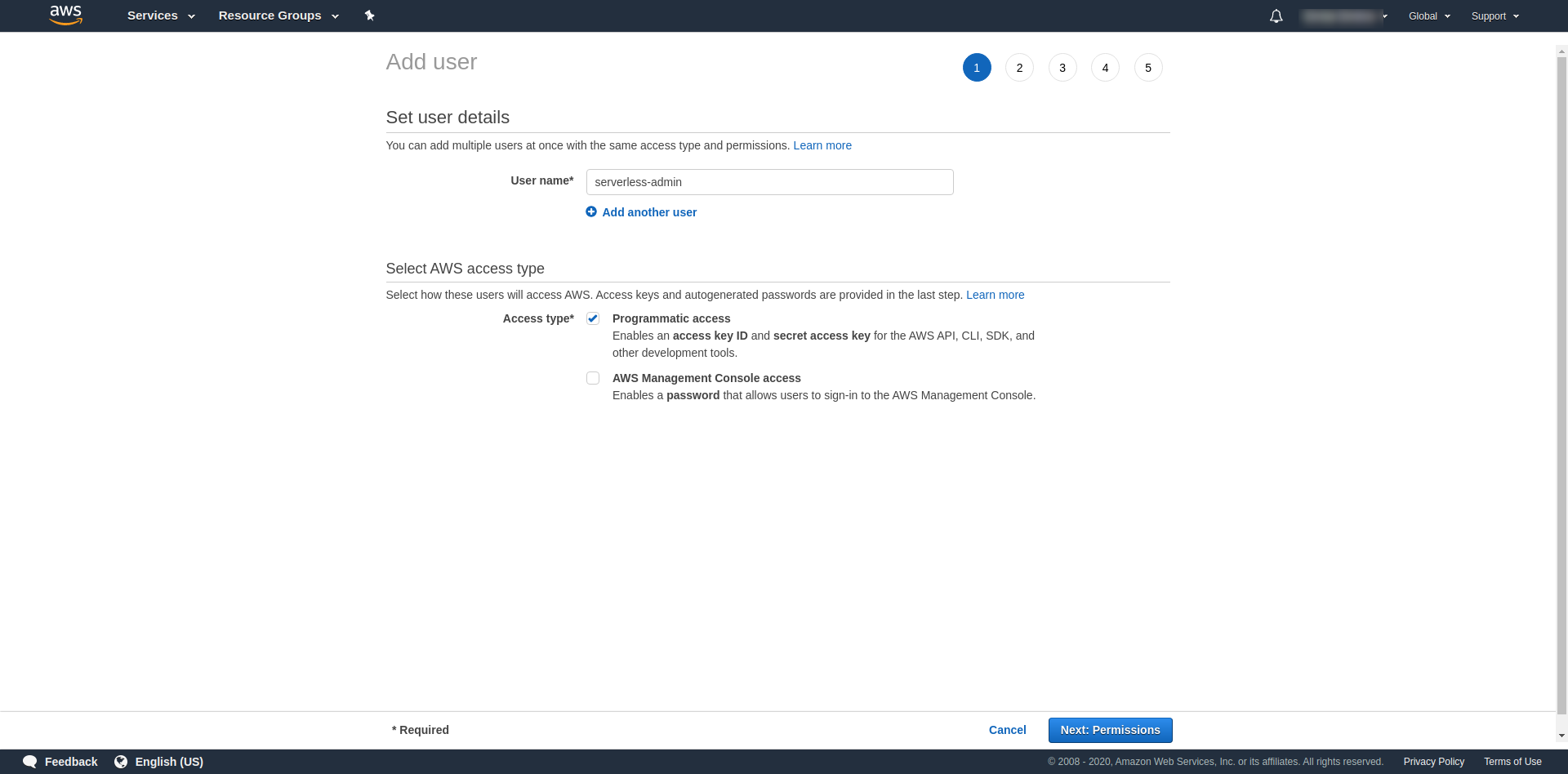
После этого мы должны прикрепить разрешения для пользователя, нажать «Прикрепить существующие политики напрямую», найти «Доступ администратора» и щелкнуть по нему. Продолжайте, нажав «Следующие теги»
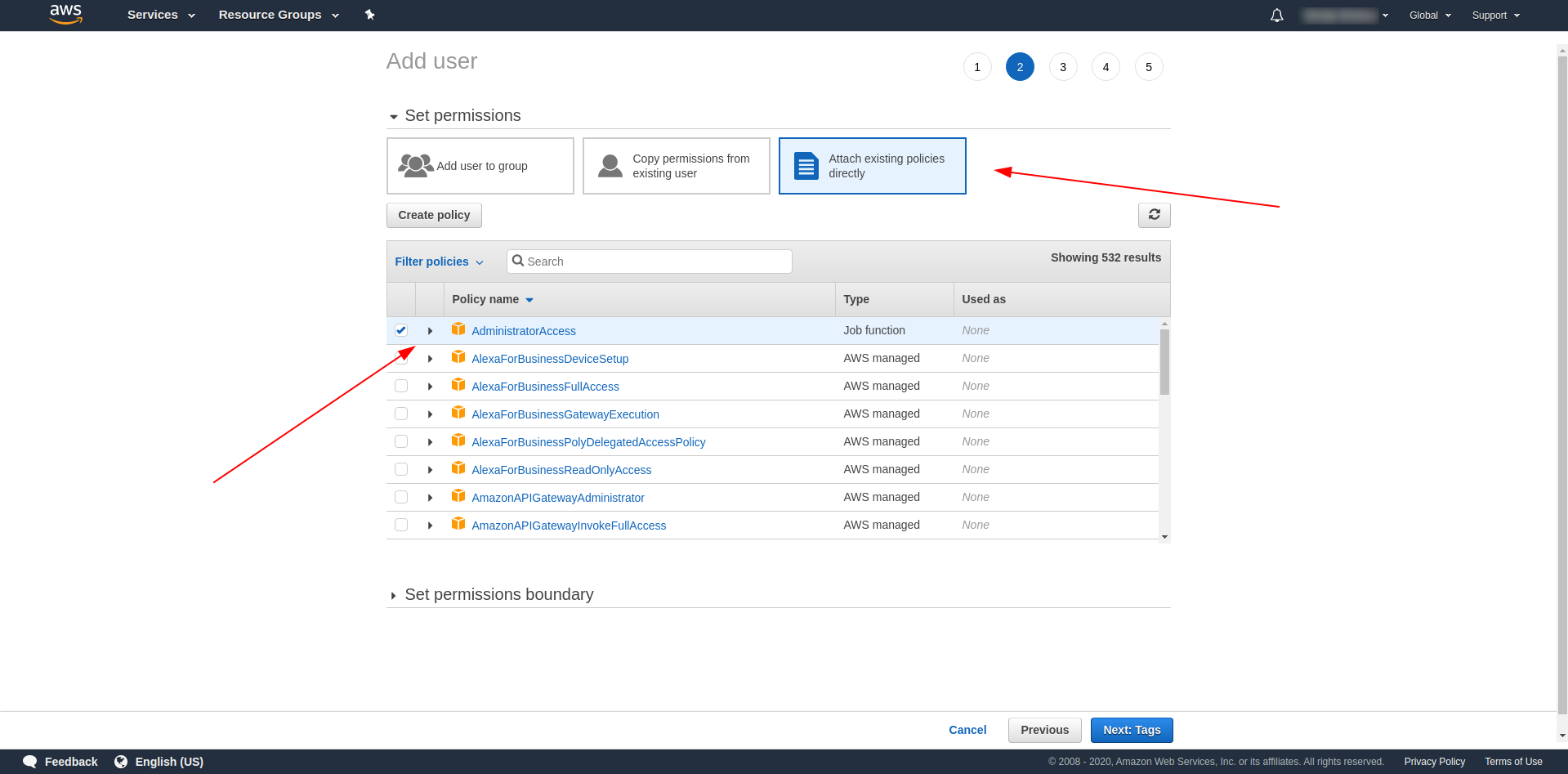
Теги необязательны, поэтому вы можете продолжить, нажав «Следующий обзор» и «Создать пользователя». После завершения и загрузки на странице появится сообщение об успешном завершении с учетными данными, которые нам нужны.
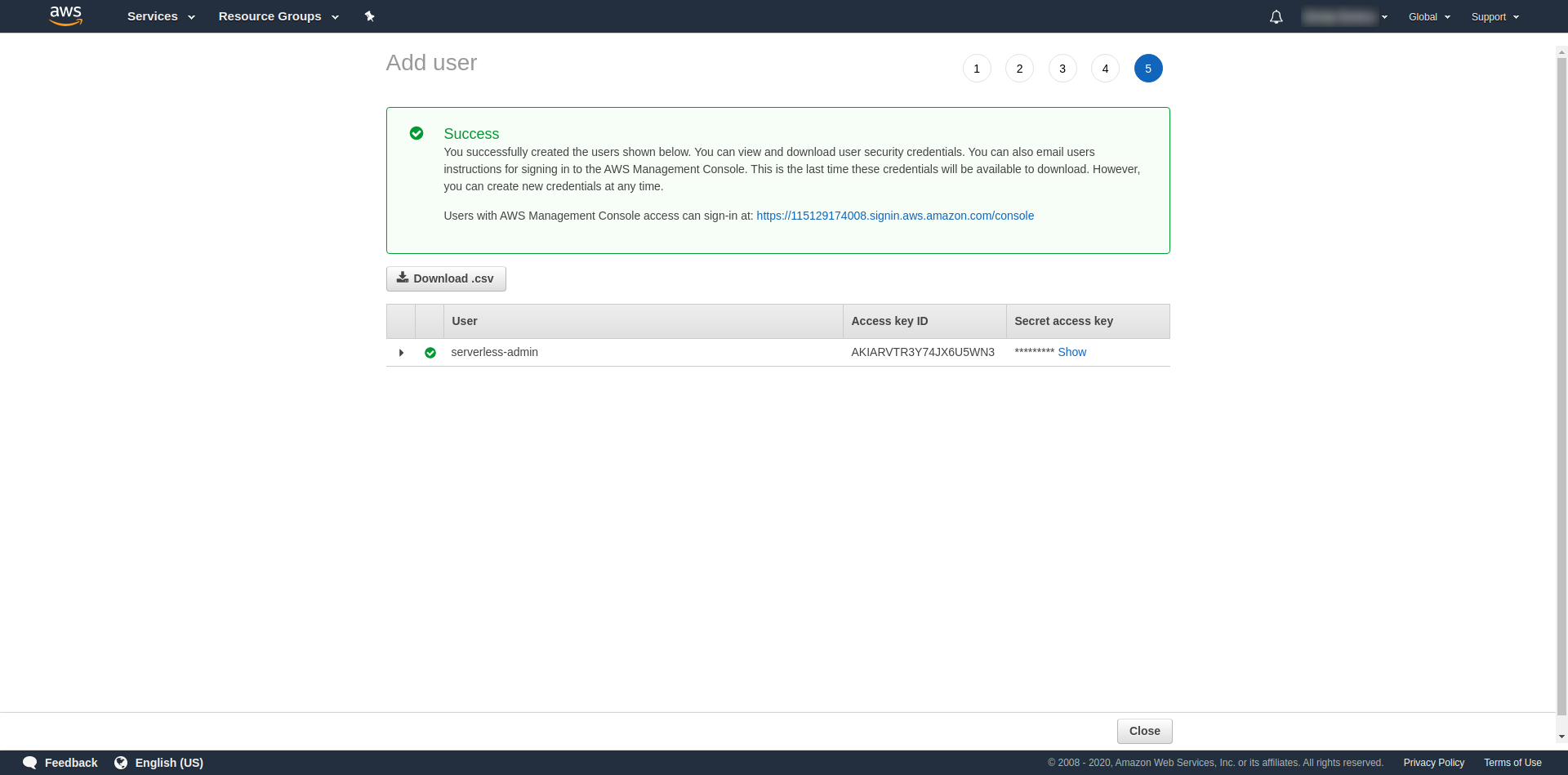
Теперь нам нужно выполнить следующую команду:
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
Замените ключ и секрет на указанные выше. Ваши учетные данные AWS создаются в виде профиля. Вы можете перепроверить это, открыв файл ~/.aws/credentials . Он должен состоять из профилей AWS. В настоящее время в примере ниже он только один — тот, который мы создали:
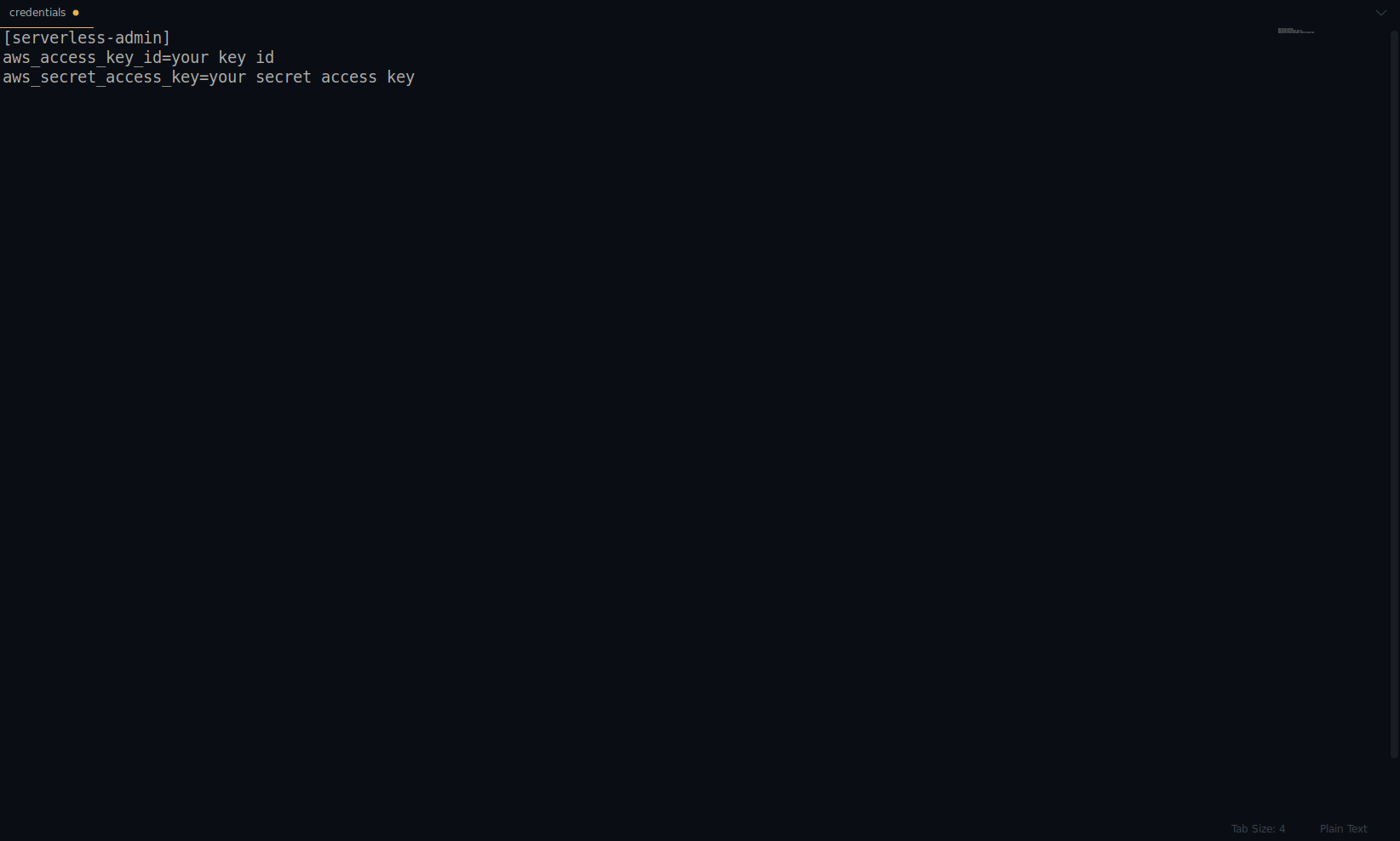
Отличная работа до сих пор! Вы можете продолжить, создав один пример приложения с помощью NodeJS и встроенных начальных шаблонов.
Примечание. Кроме того, в статье мы используем команду sls , что является сокращением от serverless .
Создайте пустой каталог и войдите в него. Запустите команду
ls create --template aws-nodejs
С помощью команды create –template укажите один из доступных шаблонов, в данном случае aws-nodejs, который является шаблонным приложением NodeJS «Hello world».
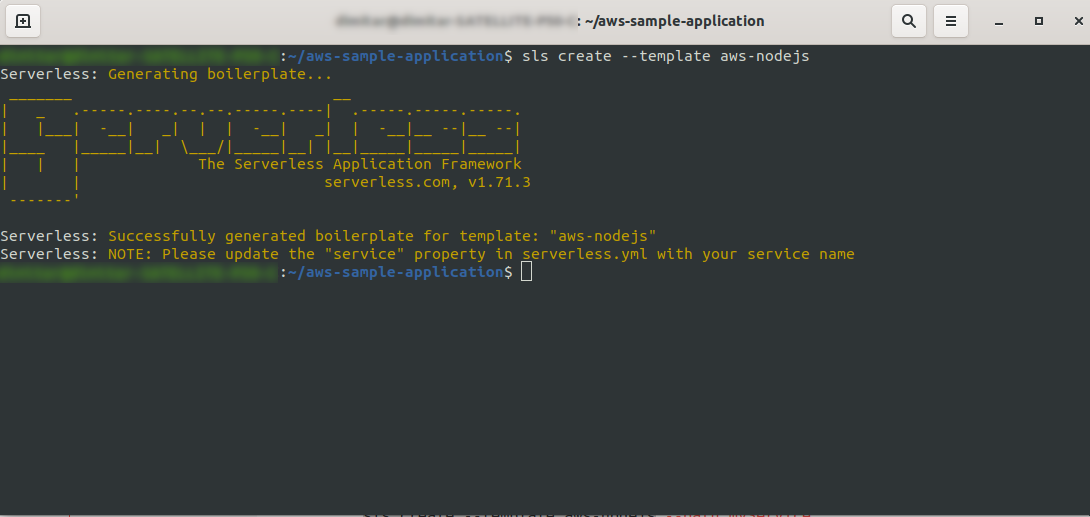
После этого ваш каталог должен состоять из следующего и выглядеть так:
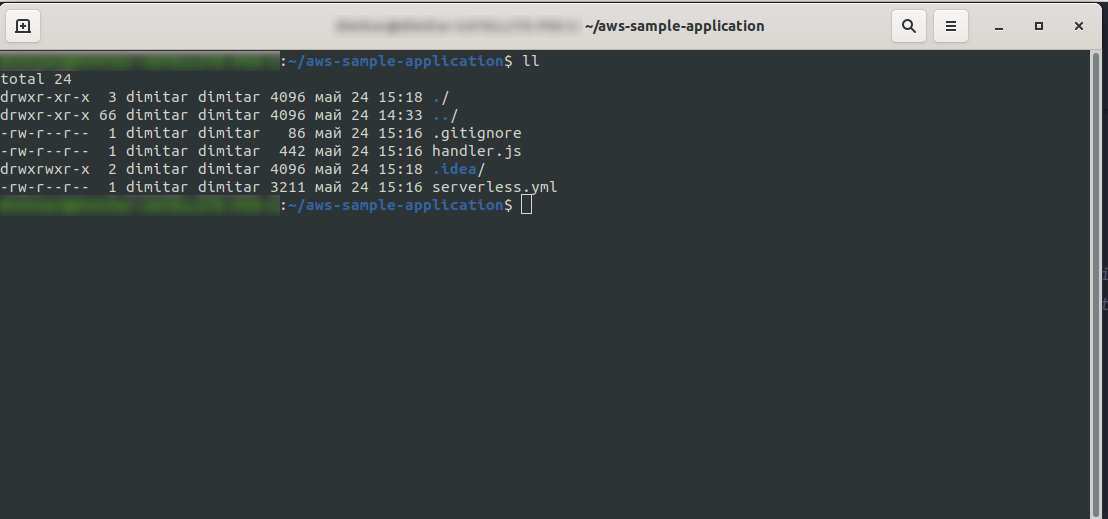
Мы создали новые файлы handler.js и serverless.yml .
В файле handler.js хранятся ваши функции, а в файле serverless.yml хранятся свойства конфигурации, которые вы измените позже. Если вам интересно, что такое файл .yml , вкратце, это человекочитаемый язык сериализации данных . Хорошо с ним ознакомиться, так как он используется при вставке любых параметров конфигурации. Но давайте теперь посмотрим, что у нас есть в файле serverless.yml :
сервис: aws-sample-application
провайдер:
имя: авс
время выполнения: nodejs12.x
функции:
Привет:
обработчик: обработчик.привет
- service: – Название нашего сервиса.
- провайдер: — объект, который содержит свойства провайдера, и, как мы видим здесь, наш провайдер — это AWS, и мы используем среду выполнения NodeJS.
- functions: — это объект, содержащий все функции, которые можно развернуть в Lambda. В этом примере у нас есть только одна функция с именем hello , которая указывает на функцию hello в handler.js.
Прежде чем приступить к развертыванию приложения, вам нужно сделать одну важную вещь. Ранее мы установили учетные данные для AWS с помощью профиля (мы назвали его serverless-admin ). Теперь все, что вам нужно сделать, это указать бессерверной конфигурации использовать этот профиль и ваш регион. Откройте serverless.yml и в свойстве провайдера прямо под средой выполнения введите следующее:
профиль: serverless-admin регион: us-east-2
В итоге у нас должно получиться вот это:
провайдер: имя: авс время выполнения: nodejs12.x профиль: serverless-admin регион: us-east-2
Примечание. Чтобы получить регион, проще всего просмотреть URL-адрес после входа в консоль: Пример:
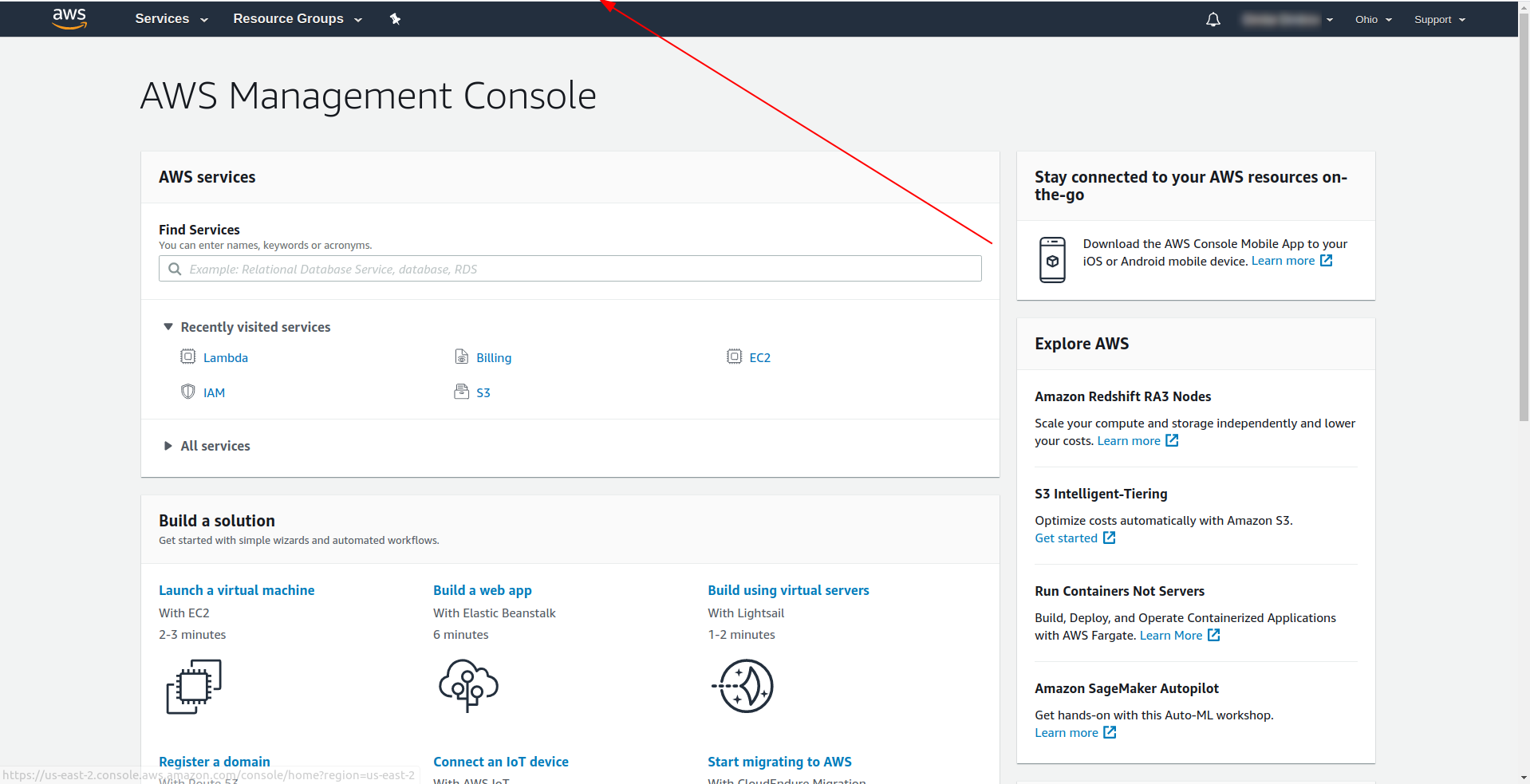
Теперь, когда у нас есть необходимая информация о сгенерированном шаблоне. Давайте проверим, как мы можем вызвать функцию локально и развернуть ее в AWS Lambda.
Мы можем сразу протестировать приложение, вызвав функцию локально:
sls invoke local -f hello
Он вызывает функцию (но только локально!) и возвращает вывод в консоль:
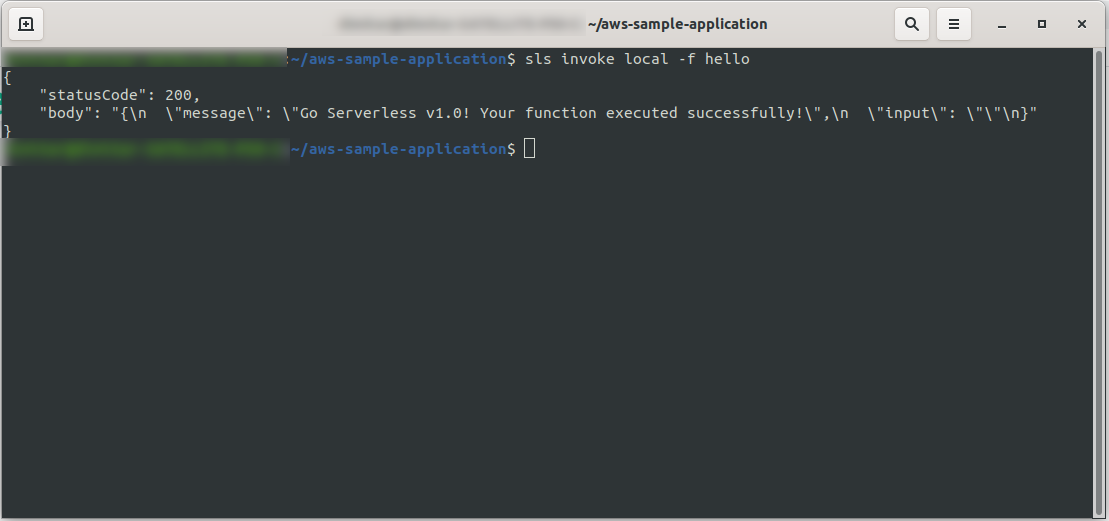
Теперь, если все прошло нормально, можно попробовать развернуть свою функцию на AWS Lambda .
Значит, это было сложно? Нет, не было! Благодаря Serverless Framework это всего лишь однострочный код:
sls deploy -v
Подождите, пока все закончится, это может занять несколько минут, если все в порядке, вы должны закончить примерно так:
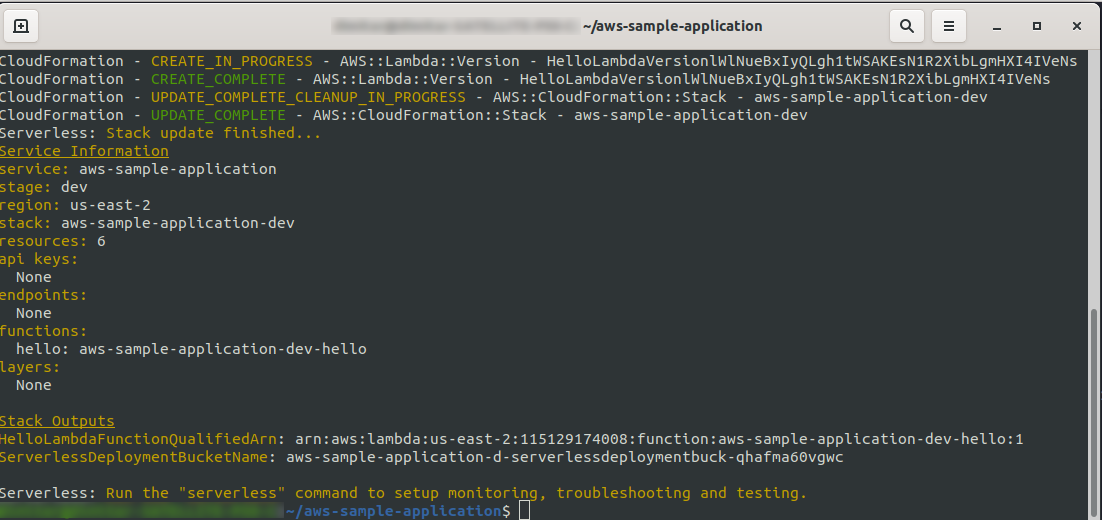
Теперь давайте проверим, что произошло в AWS. Перейдите в Lambda (в « Найти службы » введите Lambda ), и вы должны увидеть созданную функцию Lambda .
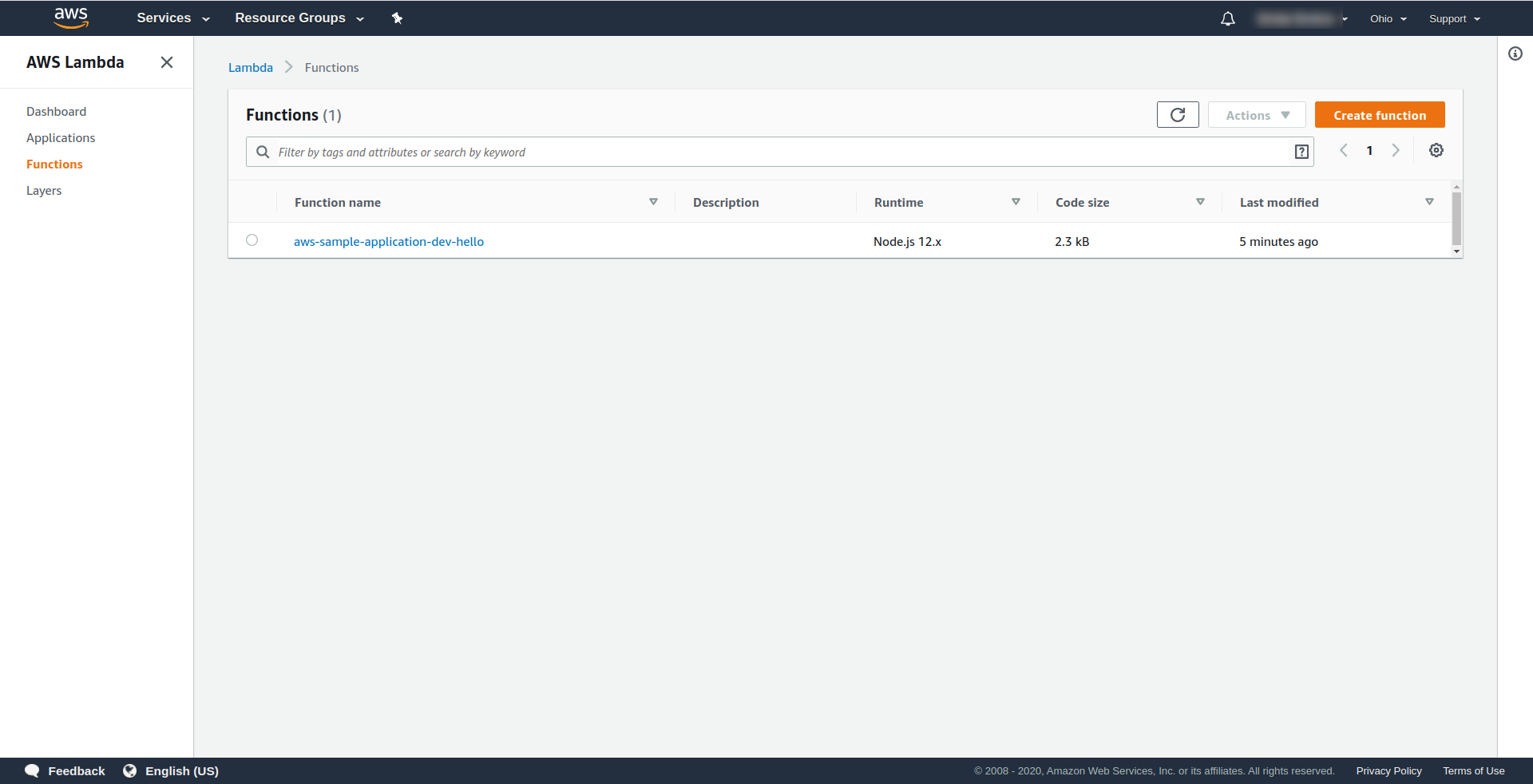
Теперь вы можете попробовать вызвать свою функцию из AWS Lambda. В терминальном типе
sls invoke -f hello
Он должен вернуть тот же результат, что и раньше (когда мы тестируем локально):
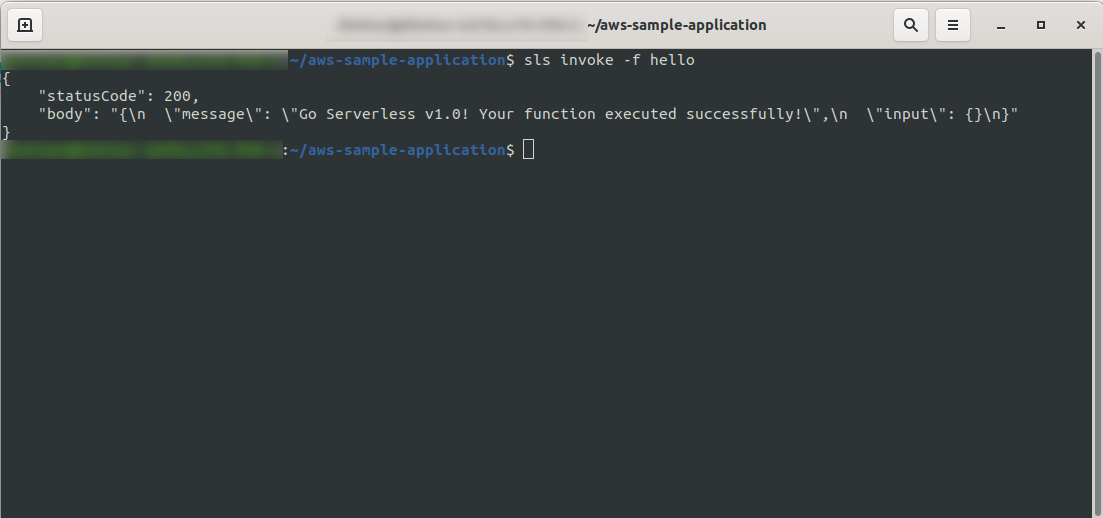
Вы можете проверить, активировали ли вы функцию AWS, открыв функцию в AWS Lambda , перейдя на вкладку « Мониторинг » и нажав « Просмотреть журналы в CloudWatch». “.
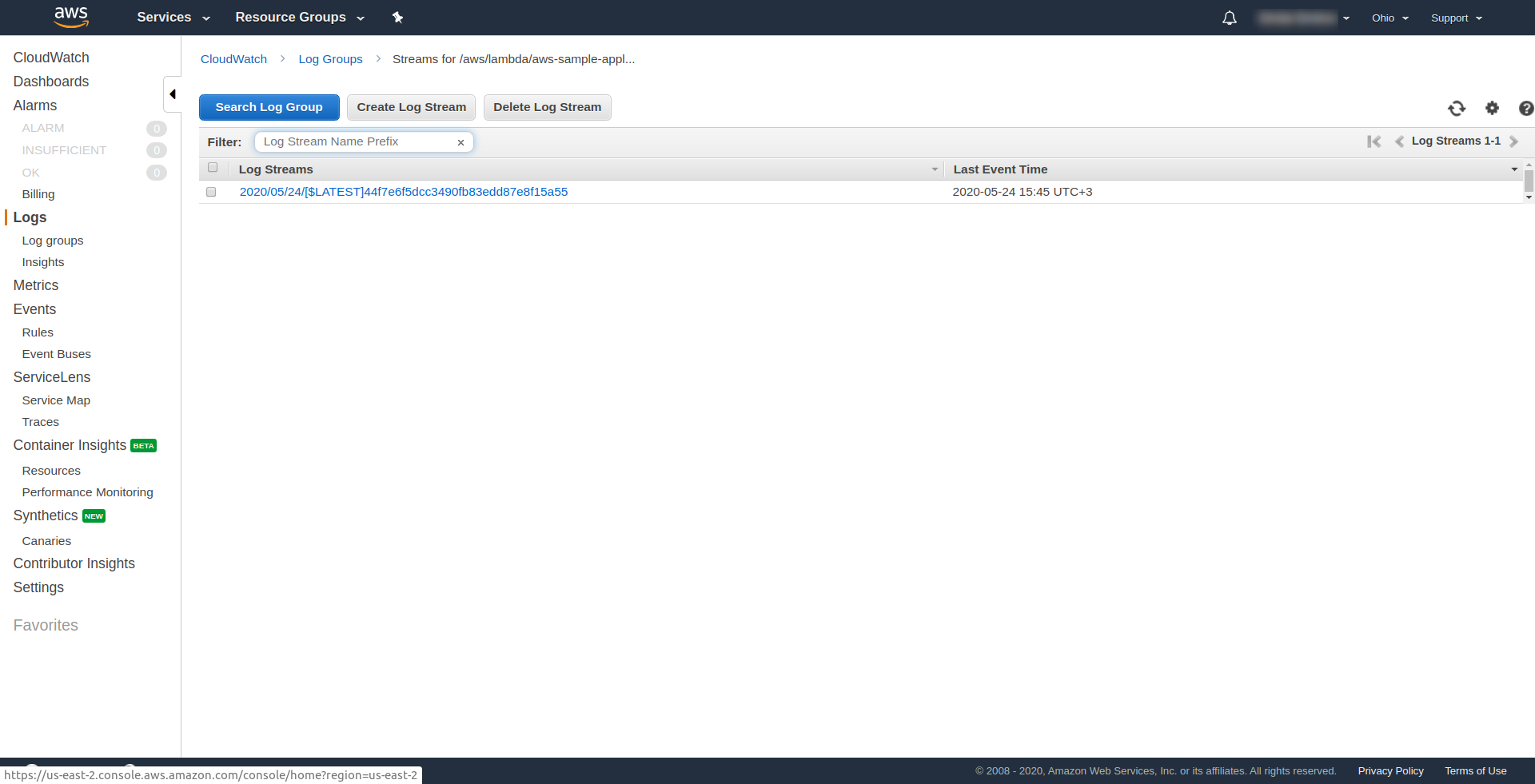
Там у вас должен быть один журнал.
Теперь в вашем приложении все еще не хватает одной вещи, но что это…? Что ж, у вас нет конечной точки для доступа к вашему приложению, поэтому давайте создадим ее с помощью AWS API Gateway.
Вы должны открыть файл serverless.yml и сначала очистить комментарии. Вам нужно добавить свойство events в нашу функцию и в ее свойство http . Это говорит бессерверной платформе создать шлюз API и прикрепить его к нашей функции Lambda при развертывании приложения. Наш конфигурационный файл должен заканчиваться следующим образом:
сервис: aws-sample-application
провайдер:
имя: авс
время выполнения: nodejs12.x
профиль: serverless-admin
регион: us-east-2
функции:
Привет:
обработчик: обработчик.привет
Мероприятия:
- http:
путь: /привет
метод: получить
В http указываем путь и метод HTTP.
Вот и все, давайте снова развернем наше приложение, запустив sls deploy -v
После завершения в выходном терминале должна появиться одна новая вещь, и это конечная точка, которая была создана:
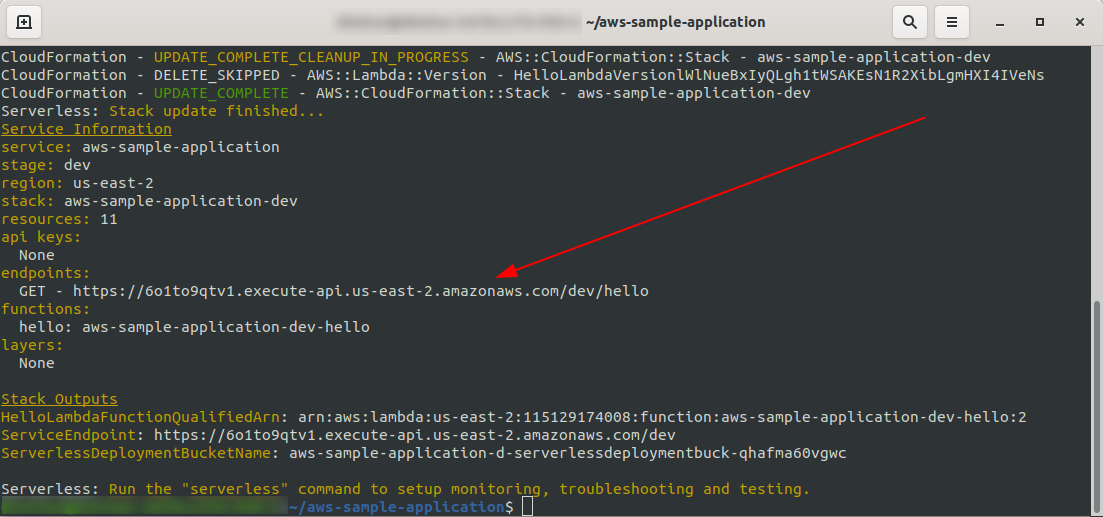
Откроем конечную точку:
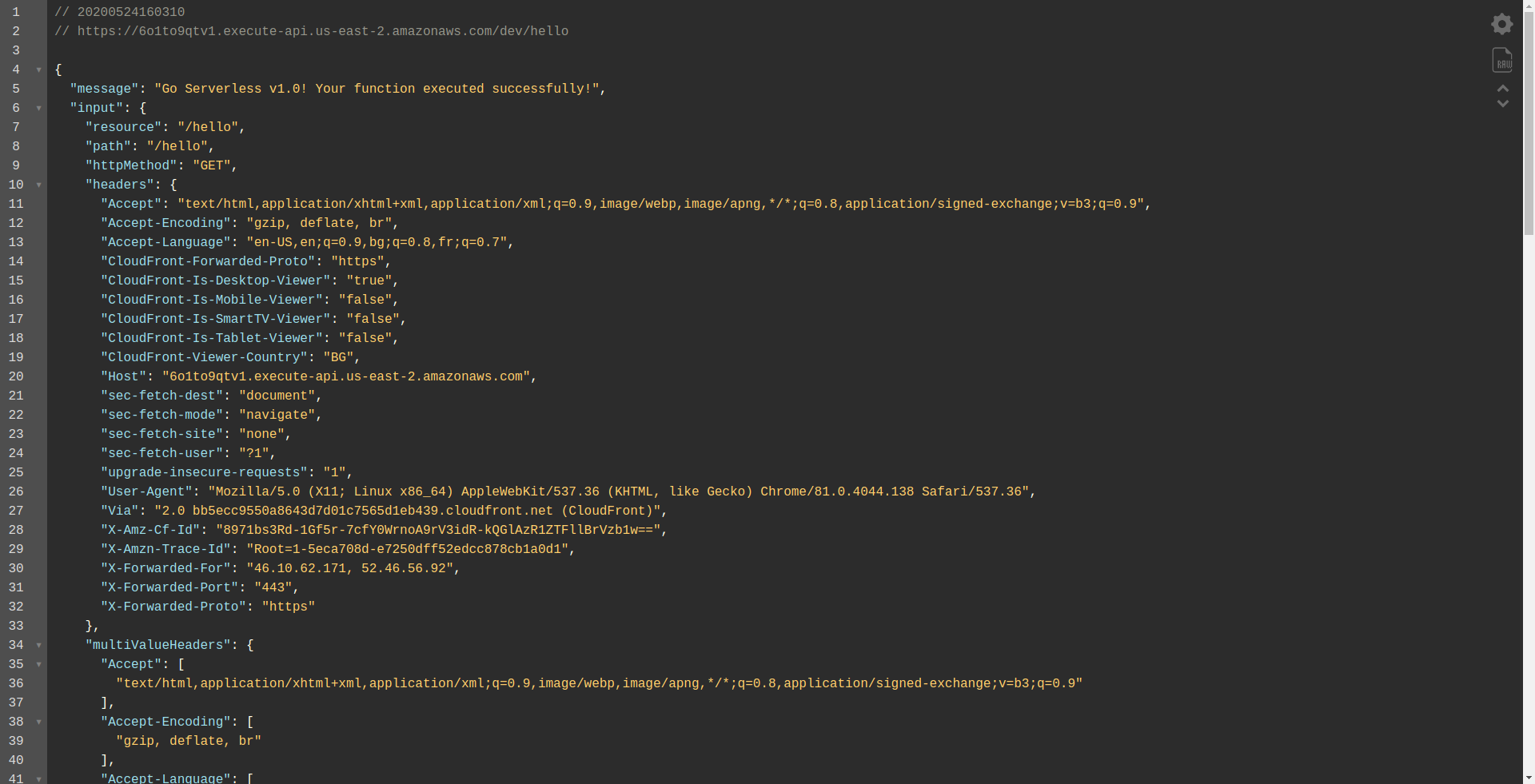
Вы должны увидеть, что ваша функция выполняется, возвращает вывод и некоторую информацию о запросе. Давайте проверим, что меняется в нашей лямбда-функции.
Откройте AWS Lambda и нажмите на свою функцию.
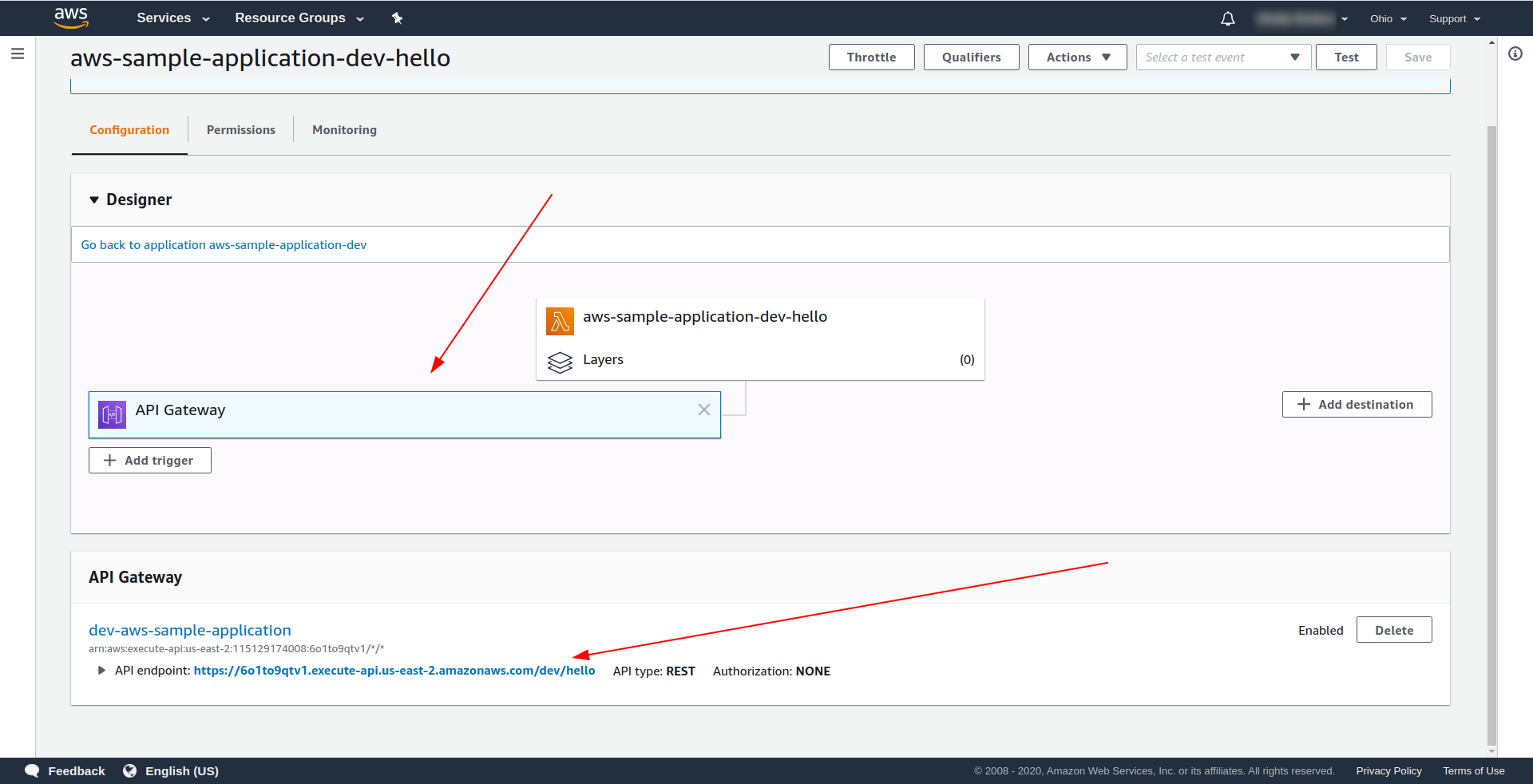
На вкладке « Дизайнер » мы видим, что у нас есть шлюз API , подключенный к нашей лямбде и конечной точке API.
Здорово! Вы создали очень простое бессерверное приложение, развернули его на AWS Lambda и протестировали его функциональность. Кроме того, мы добавили конечную точку, использующую AWS API Gateway .
4. Как запустить приложение в автономном режиме
На данный момент мы знаем, что можем вызывать функции локально, но также мы можем запускать все наше приложение в автономном режиме с помощью плагина serverless-offline.
Плагин эмулирует AWS Lambda и API Gateway на вашем локальном компьютере или компьютере для разработки. Он запускает HTTP-сервер, который обрабатывает запросы и вызывает ваши обработчики.
Чтобы установить плагин, выполните команду ниже в каталоге приложения.
npm install serverless-offline --save-dev
Затем внутри проекта serverless.yml откройте файл и добавьте свойство plugins :
плагины: - безсерверный-офлайн
Конфиг должен выглядеть так:
сервис: aws-sample-application
провайдер:
имя: авс
время выполнения: nodejs12.x
профиль: serverless-admin
регион: us-east-2
функции:
Привет:
обработчик: обработчик.привет
Мероприятия:
- http:
путь: /привет
метод: получить
плагины:
- безсерверный-офлайн
Чтобы убедиться, что мы успешно установили и настроили плагин, запустите
sls --verbose
Вы должны увидеть это:
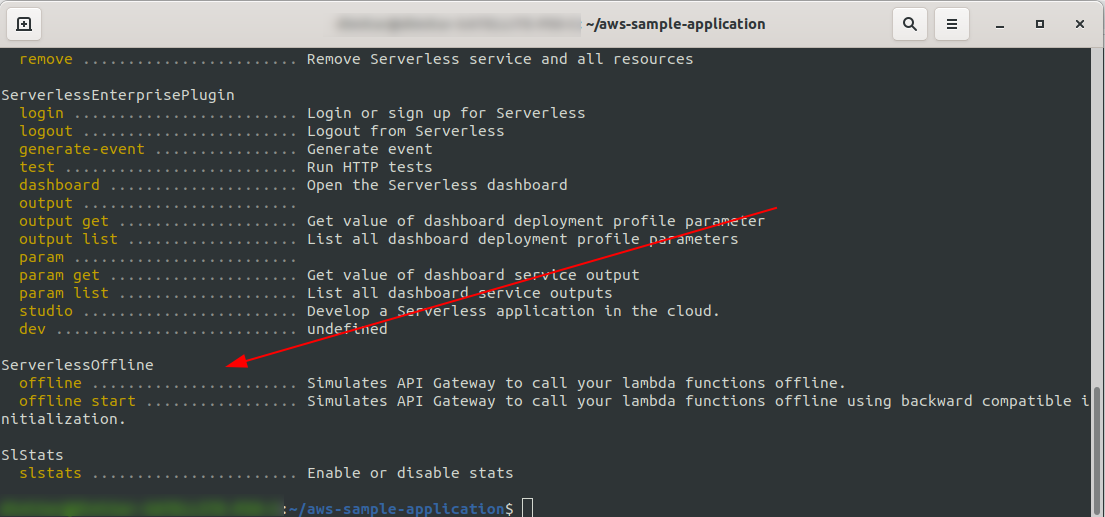
Теперь в корне вашего проекта запустите команду
sls offline
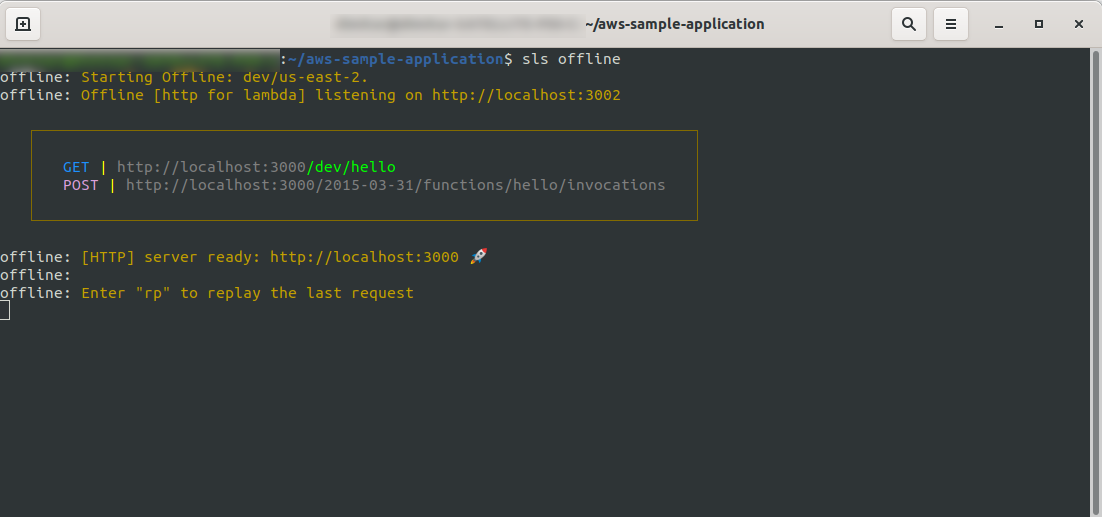
Как видите, HTTP -сервер прослушивает порт 3000, и вы можете получить доступ к своим функциям, например, здесь у нас есть http://localhost:3000/dev/hello для нашей функции приветствия. Открываем, что у нас такой же ответ, как и от API Gateway , который мы создали ранее.
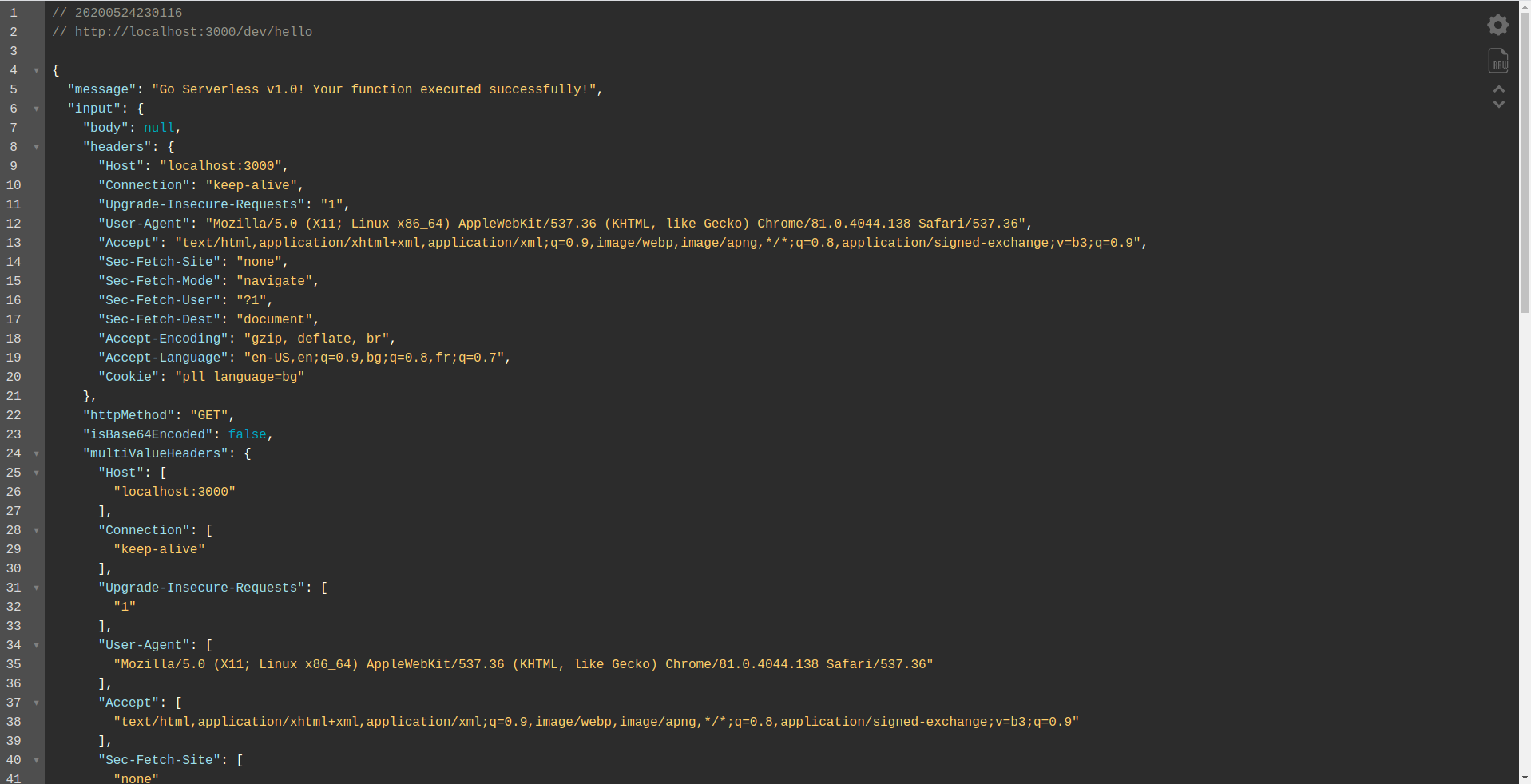
Добавьте интеграцию с Google BigQuery.

Вы проделали большую работу до сих пор! У вас есть полностью работающее приложение, использующее Serverless. Давайте расширим наше приложение и добавим в него интеграцию с BigQuery , чтобы увидеть, как оно работает и как осуществляется интеграция.
BigQuery — это бессерверное программное обеспечение как услуга (SaaS), представляющее собой экономичное и быстрое хранилище данных, поддерживающее запросы. Прежде чем мы продолжим интегрировать его с нашим приложением NodeJS, нам нужно создать учетную запись, поэтому давайте продолжим.

1. Настройте облачную консоль Google
Перейдите на https://cloud.google.com и войдите в свою учетную запись, если вы еще этого не сделали — создайте учетную запись и продолжайте.
Когда вы входите в Google Cloud Console, вам нужно создать новый проект. Нажмите на три точки рядом с логотипом, и откроется модальное окно, в котором выберите « Новый проект». ”
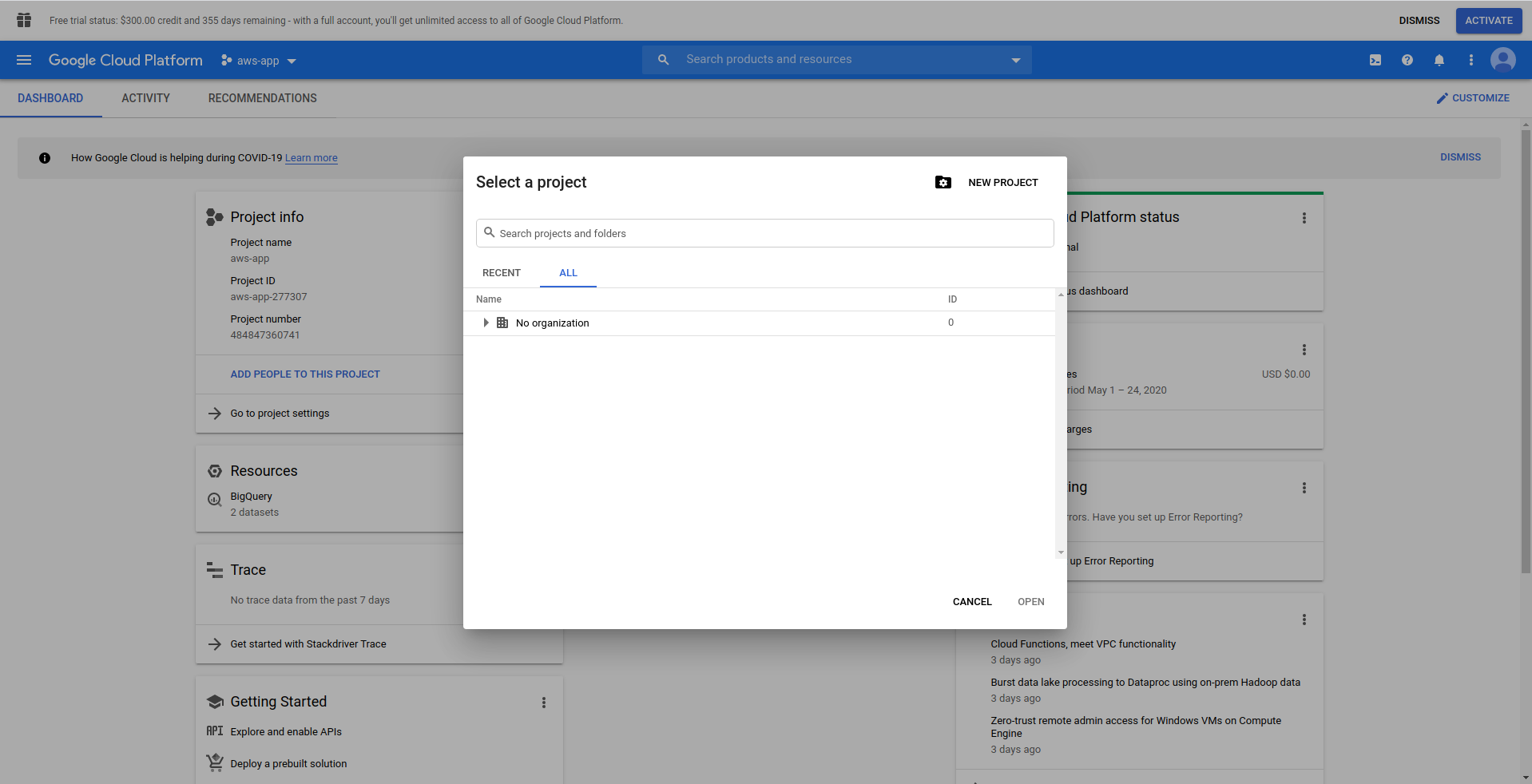
Введите имя для вашего проекта. Мы будем использовать bigquery-example . После того, как вы создали проект, перейдите к BigQuery с помощью ящика:
Когда BigQuery загрузится, слева вы увидите данные проекта, к которым у вас есть доступ, а также общедоступные наборы данных. В этом примере мы используем общедоступный набор данных. Он называется covid19_ecdc :
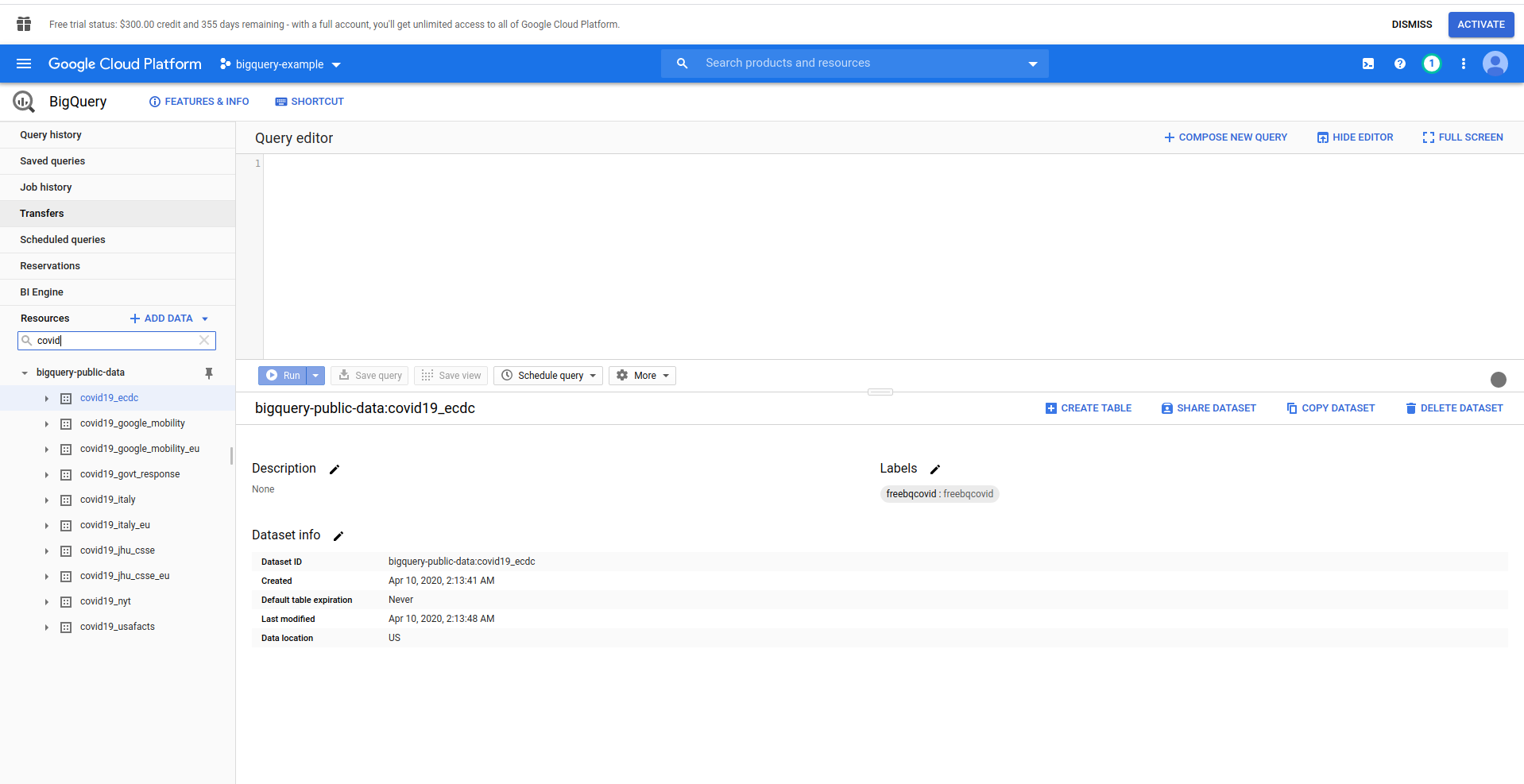
Поэкспериментируйте с набором данных и доступными таблицами. Предварительно просмотрите данные в нем. Это общедоступный набор данных, который обновляется ежечасно и содержит информацию о мировых данных о COVID-19 .
Мы должны создать пользователя IAM -> учетную запись службы, чтобы иметь доступ к данным. Итак, в меню нажмите «IAM и администратор», затем «Сервисные учетные записи».
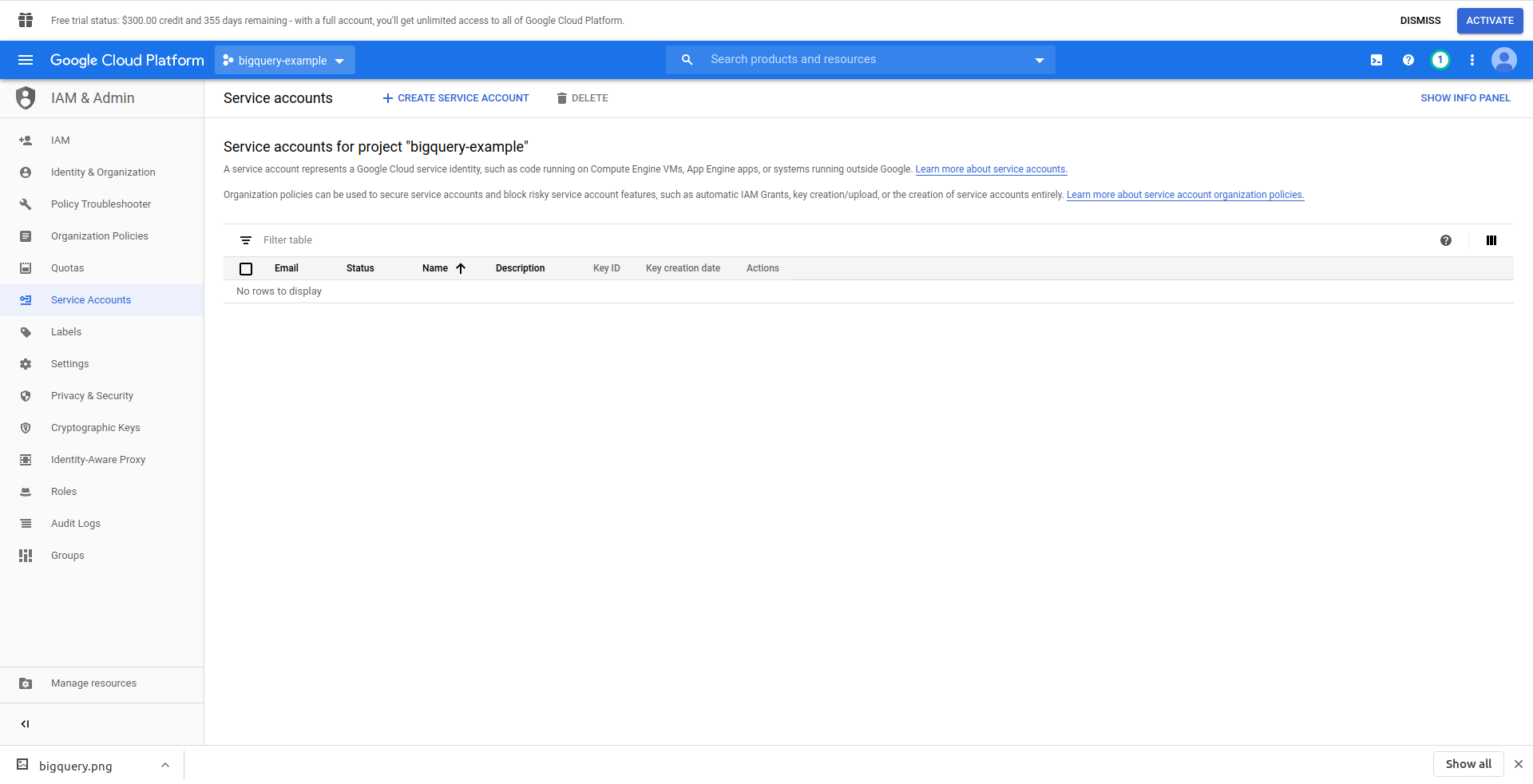
Нажмите кнопку «Создать учетную запись службы» , введите имя учетной записи службы и нажмите «Создать». Затем перейдите в раздел «Разрешения учетной записи службы» , найдите и выберите «Администратор BigQuery» .
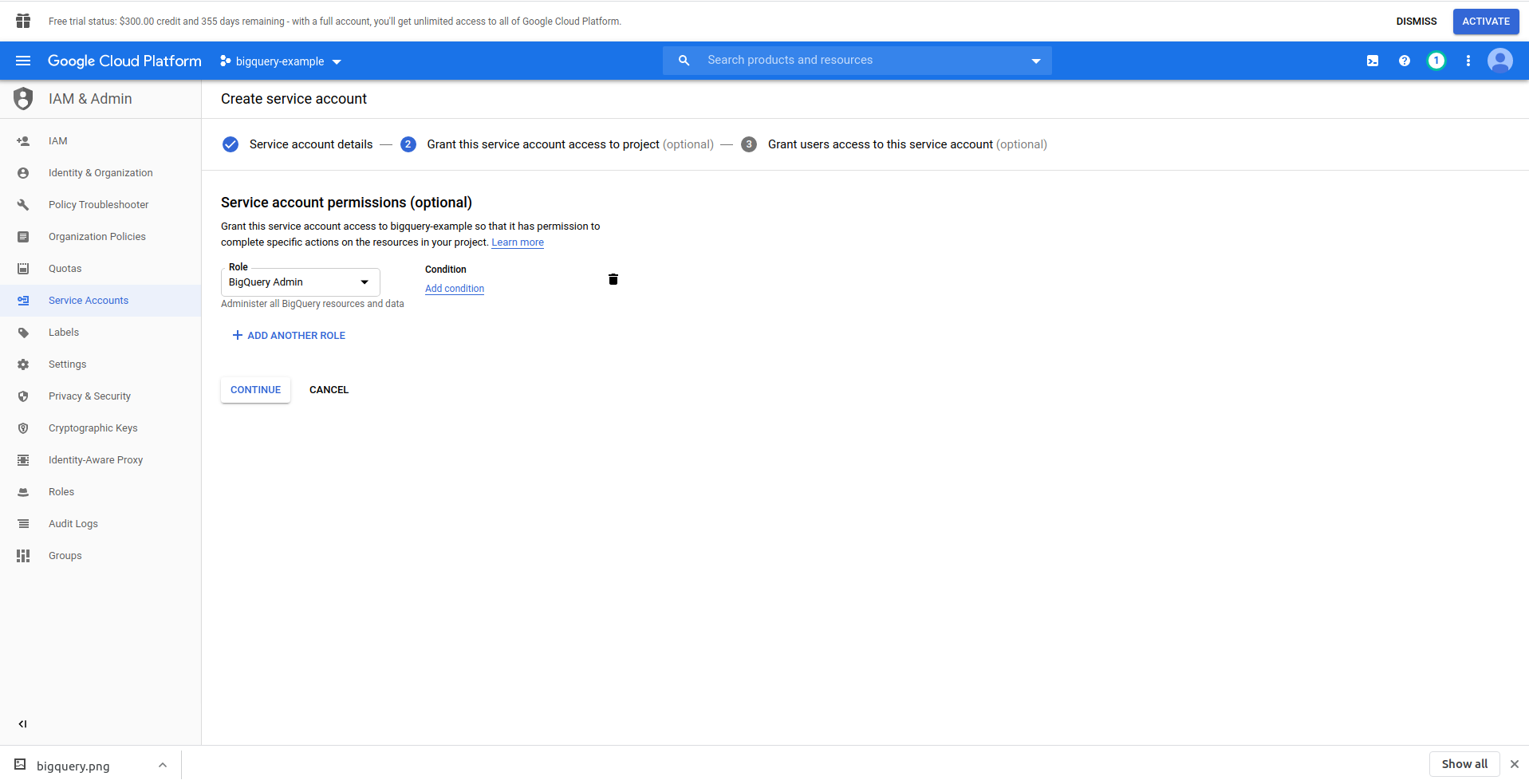
Нажмите « Продолжить », это последний шаг, здесь вам нужны ваши ключи, поэтому нажмите кнопку создания в разделе « Ключи » и экспортируйте как JSON . Сохраните это где-нибудь в надежном месте, оно нам понадобится позже. Нажмите « Готово» , чтобы завершить создание учетной записи службы.
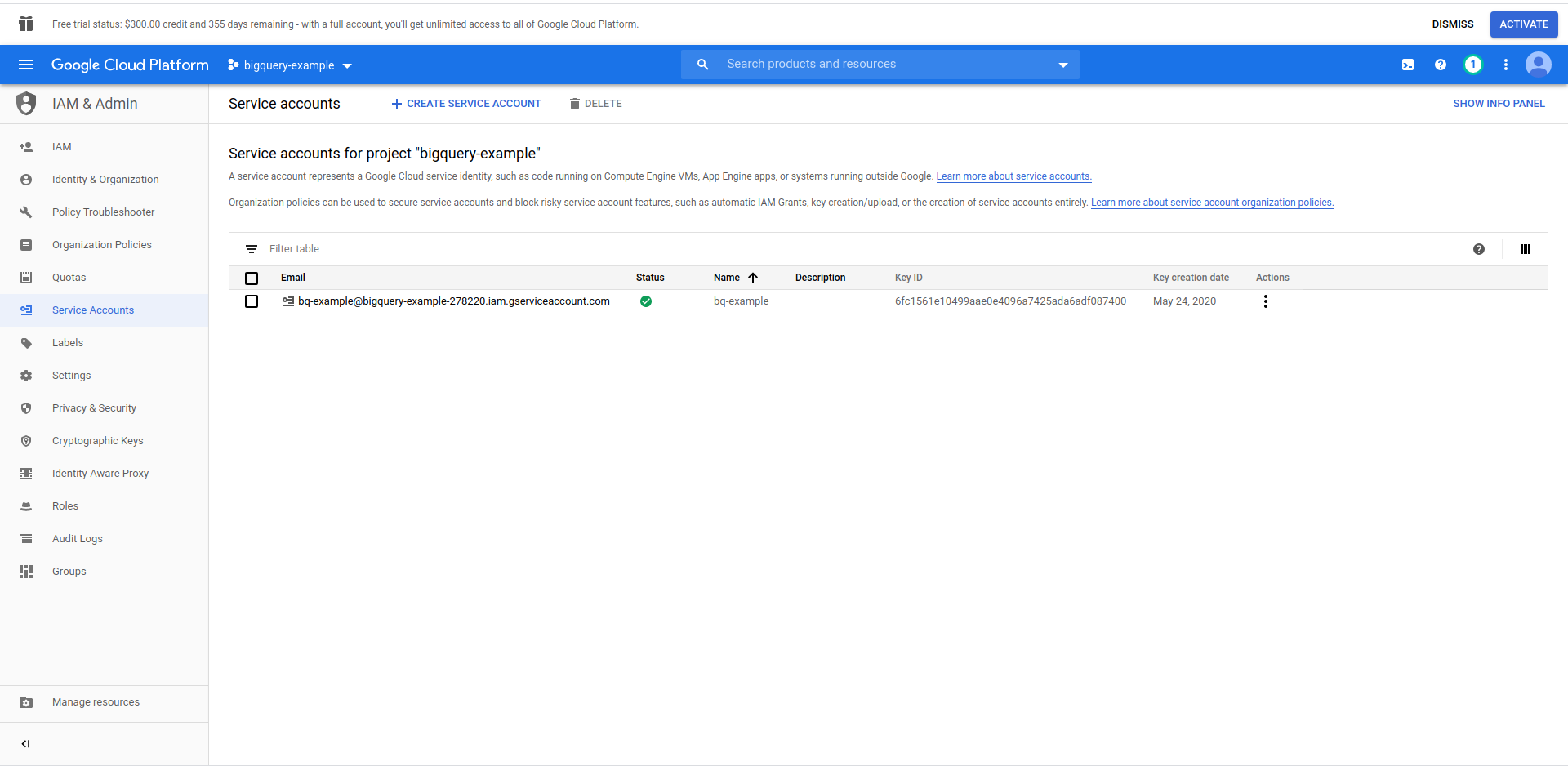
Теперь мы будем использовать созданные здесь учетные данные для подключения библиотеки NodeJS BigQuery.
2. Установите библиотеку NodeJS BigQuery.
Вам потребуется установить библиотеку BigQuery NodeJS, чтобы использовать ее в только что созданном проекте. Запустите приведенные ниже команды в каталоге приложения:
Сначала инициализируйте npm, запустив npm init
Заполните все вопросы и приступайте к установке библиотеки BigQuery :
npm install @google-cloud/bigquery
Прежде чем мы продолжим изменять наш обработчик функции, мы должны перенести закрытый ключ из файла JSON, который мы ранее создали. Для этого мы будем использовать переменные среды Serverless . Вы можете получить больше информации здесь.
Откройте serverless.yml и в свойстве провайдера добавьте свойство среды следующим образом:
окружающая обстановка:
PROJECT_ID: ${файл(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${файл(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${файл(./config/bigquery-config.json):private_key}
Создайте переменные среды PROJECT_ID, PRIVATE_KEY и CLIENT_EMAIL , которые принимают те же свойства (нижний регистр) из созданного нами файла JSON. Мы поместили его в папку конфигурации и назвали bigquery-config.json .
Прямо сейчас у вас должен получиться файл serverless.yml, который будет выглядеть так:
сервис: aws-sample-application
провайдер:
имя: авс
время выполнения: nodejs12.x
профиль: serverless-admin
регион: us-east-2
окружающая обстановка:
PROJECT_ID: ${файл(./config/bigquery-config.json):project_id}
CLIENT_EMAIL: ${файл(./config/bigquery-config.json):client_email}
PRIVATE_KEY: ${файл(./config/bigquery-config.json):private_key}
функции:
Привет:
обработчик: обработчик.привет
Мероприятия:
- http:
путь: /привет
метод: получить
плагины:
- безсерверный-офлайн
Теперь откройте handler.js и давайте импортируем библиотеку BigQuery, в верхней части файла в разделе «use strict» добавьте следующую строку:
const {BigQuery} = require('@google-cloud/bigquery');
Теперь нам нужно сообщить библиотеке BigQuery учетные данные. Для этого создайте новую константу, которая создает экземпляр BigQuery с учетными данными:
const bigQueryClient = новый BigQuery({
идентификатор проекта: process.env.PROJECT_ID,
реквизиты для входа: {
client_email: process.env.CLIENT_EMAIL,
private_key: процесс.env.PRIVATE_KEY
}
});
Далее давайте создадим наш SQL-запрос BigQuery. Мы хотим получить самую свежую информацию о случаях COVID-19 в Болгарии. Мы используем редактор запросов BigQuery, чтобы протестировать его, прежде чем продолжить, поэтому мы создали собственный запрос:
SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` ГДЕ geo_ ORDER BY date DESC LIMIT 1
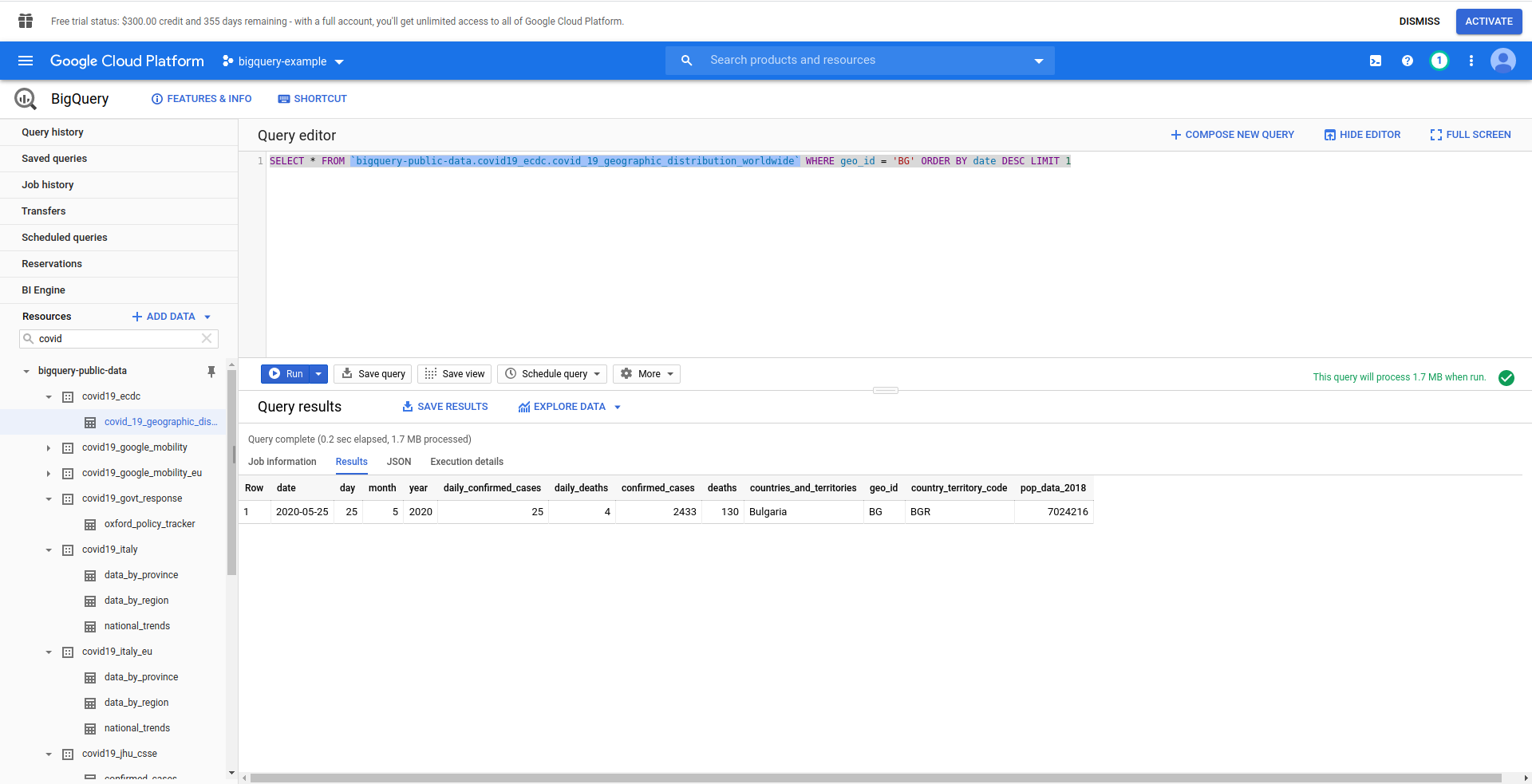
Хорошо! Теперь давайте реализуем это в нашем приложении NodeJS.
Откройте handler.js и вставьте код ниже
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` ГДЕ geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
постоянные параметры = {
запрос: запрос
}
const [задание] = ожидание bigQueryClient.createQueryJob (параметры);
const [строки] = ожидание job.getQueryResults();
Мы создали константы запросов и опций . Затем мы приступаем к выполнению запроса как задания и извлечению из него результатов.
Давайте также изменим наш обработчик возврата, чтобы он возвращал сгенерированные строки из запроса:
вернуть {
код состояния: 200,
тело: JSON.stringify(
{
ряды
},
нулевой,
2
),
};
Давайте посмотрим полный handler.js :
'использовать строгий';
const {BigQuery} = require('@google-cloud/bigquery');
const bigQueryClient = новый BigQuery({
идентификатор проекта: process.env.PROJECT_ID,
реквизиты для входа: {
client_email: process.env.CLIENT_EMAIL,
private_key: процесс.env.PRIVATE_KEY
}
});
module.exports.hello = асинхронное событие => {
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` ГДЕ geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
постоянные параметры = {
запрос: запрос
}
const [задание] = ожидание bigQueryClient.createQueryJob (параметры);
const [строки] = ожидание job.getQueryResults();
вернуть {
код состояния: 200,
тело: JSON.stringify(
{
ряды
},
нулевой,
2
),
};
};
Хорошо! Давайте протестируем нашу функцию локально:
sls invoke local -f hello
Мы должны увидеть вывод:
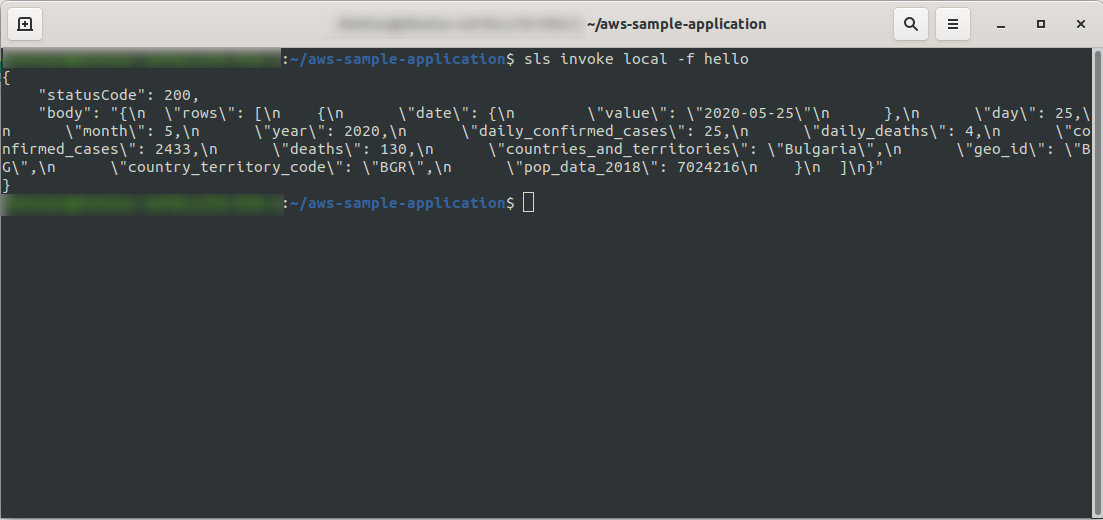
Продолжайте развертывание приложения, чтобы протестировать его через конечные точки HTTP, поэтому запустите sls deploy -v
Дождитесь его завершения и откройте конечную точку. Вот результаты:
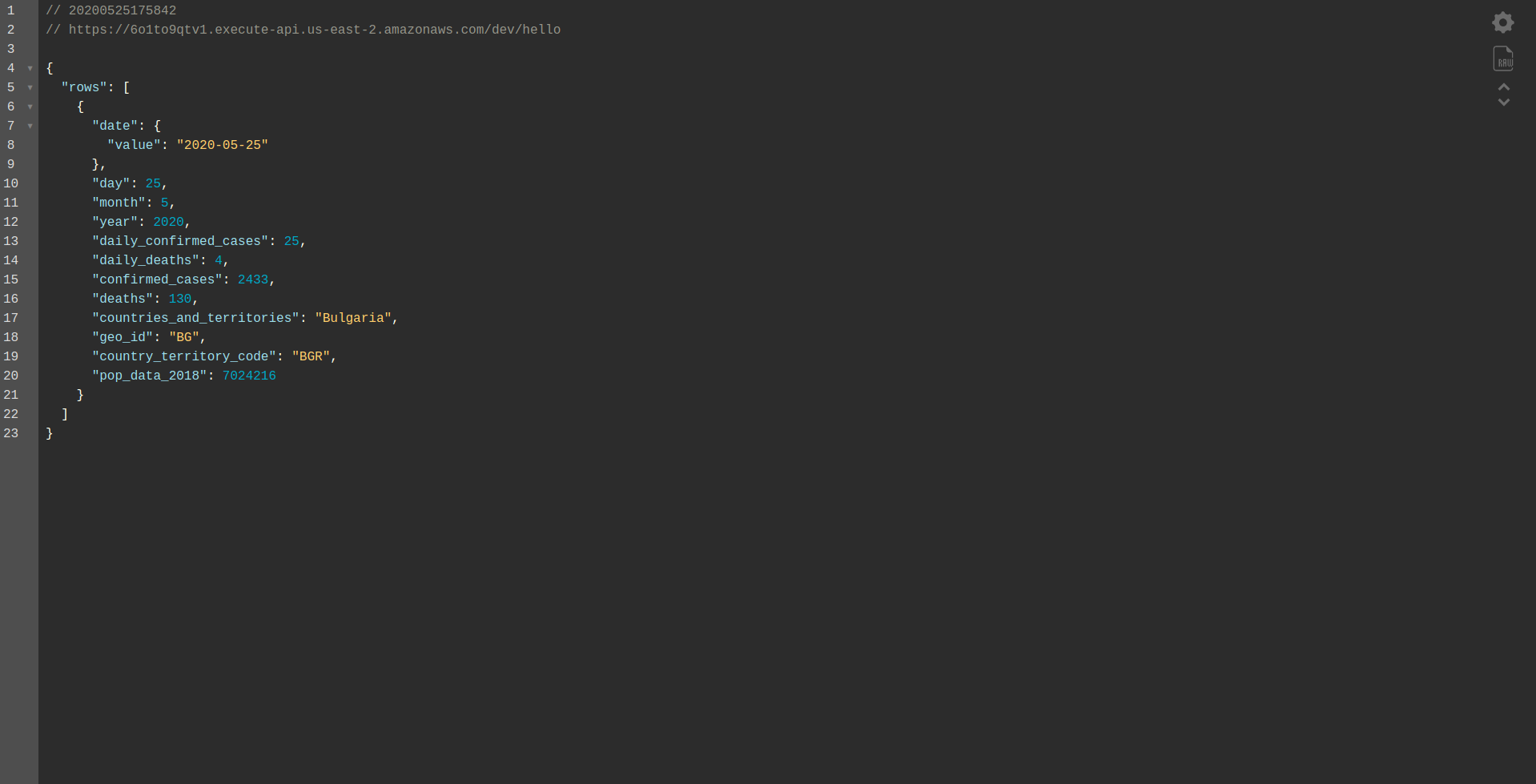
Отличная работа! Теперь у нас есть приложение для извлечения данных из BigQuery и возврата ответа! Давайте, наконец, проверим, что он работает в автономном режиме. Запуск sls offline
И загрузите локальную конечную точку:
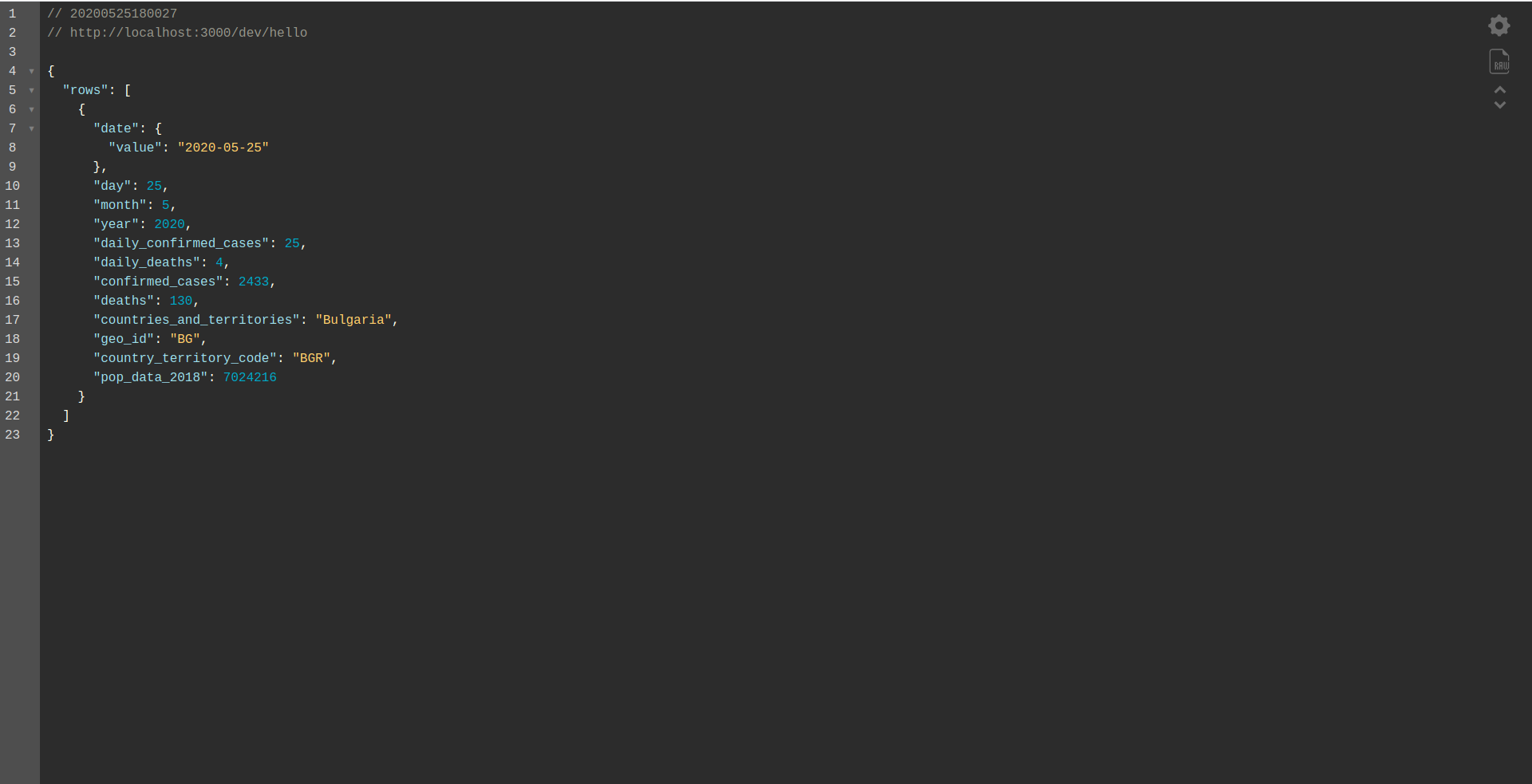
Хорошо сделанная работа. Мы почти в конце процесса. Последний шаг — немного изменить приложение и поведение. Вместо AWS API Gateway мы хотим использовать Application Load Balancer . Давайте посмотрим, как этого добиться, в следующей главе.
ALB — балансировщик нагрузки приложений в AWS
Мы создали наше приложение, используя AWS API Gateway. В этой главе мы расскажем, как заменить шлюз API на Application Load Balancer (ALB).
Во-первых, давайте посмотрим, как работает балансировщик нагрузки приложений по сравнению со шлюзом API:
В балансировщике нагрузки приложения мы сопоставляем определенные пути (например, /hello/ ) с целевой группой — группой ресурсов, в нашем случае — функцией Lambda .
С целевой группой может быть связана только одна функция Lambda. Всякий раз, когда целевой группе необходимо ответить, балансировщик нагрузки приложения отправляет запрос в Lambda, и функция должна ответить объектом ответа. Как и шлюз API, ALB обрабатывает все HTTP-запросы.
Между ALB и шлюзом API есть некоторые различия. Одно из основных отличий заключается в том, что шлюз API поддерживает только HTTPS (SSL), тогда как ALB поддерживает как HTTP, так и HTTPS.
Но давайте посмотрим на некоторые плюсы и минусы шлюза API:
Шлюз API:
Плюсы:
- Отличная безопасность.
- Это просто реализовать.
- Это быстро для развертывания и готово к работе через минуту.
- Масштабируемость и доступность.
Минусы:
- Это может стать довольно дорогим, если столкнуться с высоким трафиком.
- Это требует дополнительной оркестровки, что усложняет работу разработчиков.
- Снижение производительности из-за сценариев API может повлиять на скорость и надежность приложения.
Давайте продолжим создавать ALB и переключаться на него вместо использования шлюза API:
1. Что такое АЛБ?
Балансировщик нагрузки приложения позволяет разработчику настраивать и маршрутизировать входящий трафик. Это функция « Упругой балансировки нагрузки». Он служит единой точкой контакта для клиентов, распределяет входящий трафик приложений между несколькими целями, такими как экземпляры EC2 в нескольких зонах.
2. Создайте балансировщик нагрузки приложений с помощью пользовательского интерфейса AWS.
Давайте создадим наш Application Load Balancer (ALB) через пользовательский интерфейс в Amazon AWS. Войдите в консоль AWS в разделе « Найти сервисы. » введите « EC2 » и найдите « Балансировщики нагрузки. ”
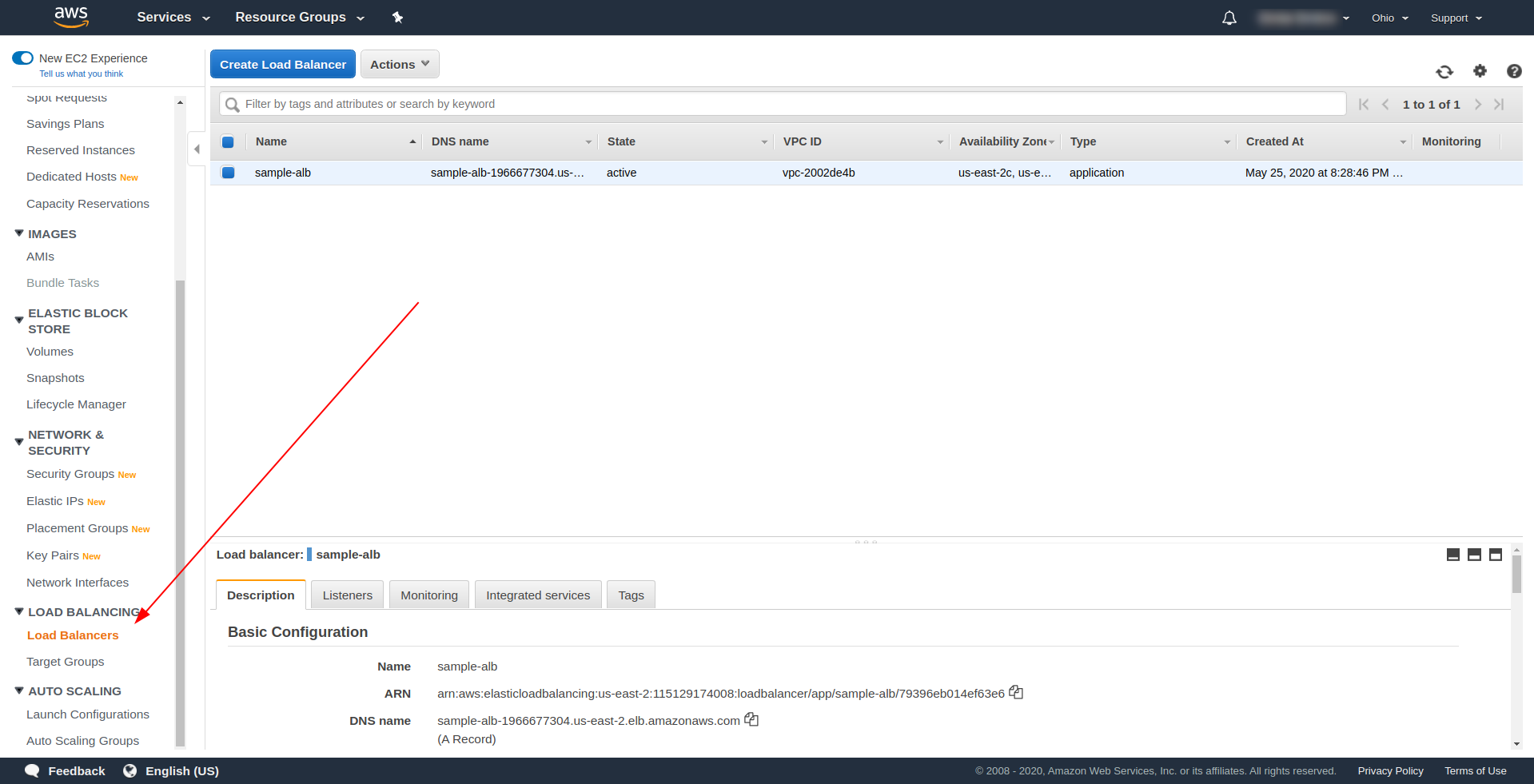
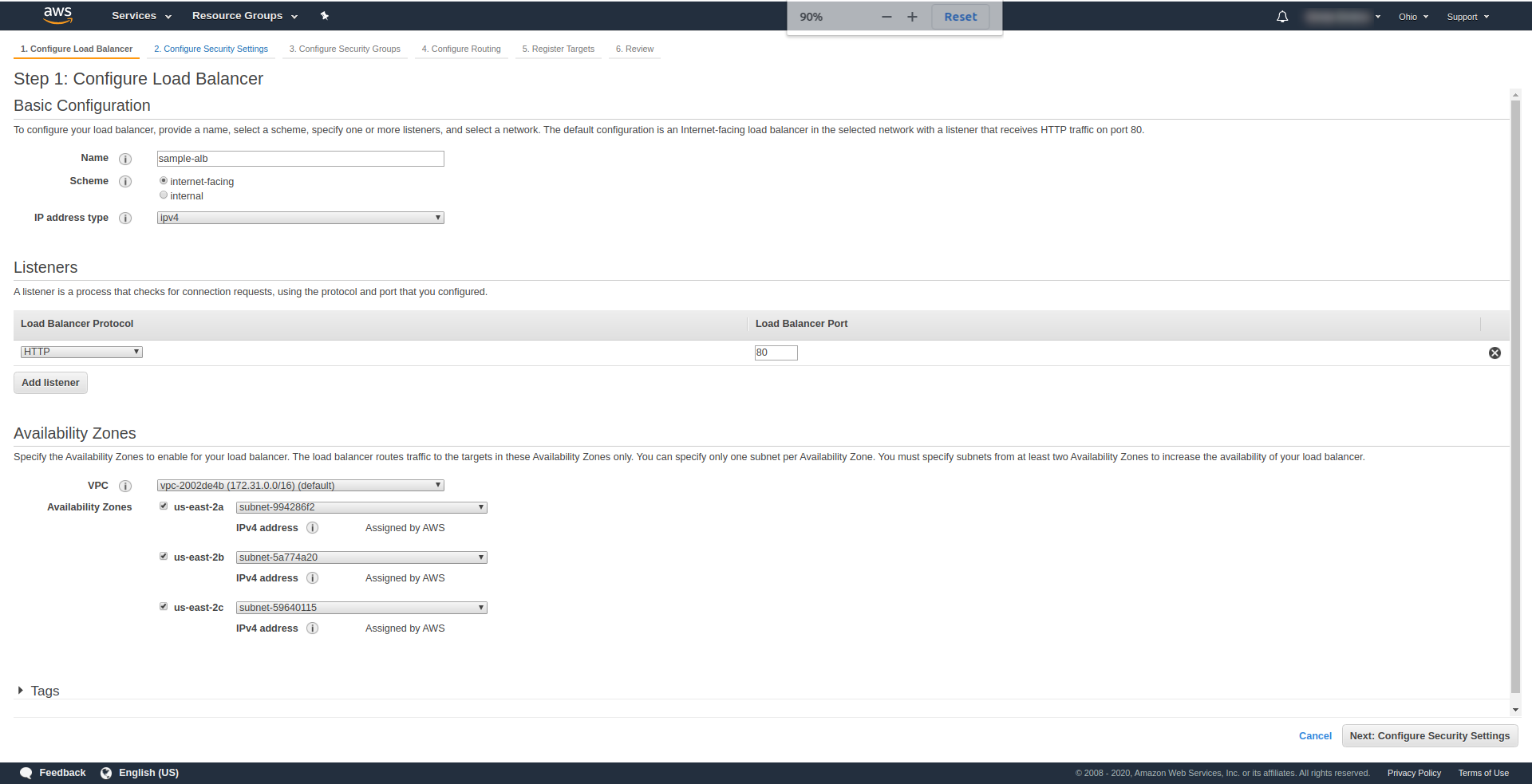
Нажмите « Создать балансировщик нагрузки », в разделе « Балансировщик нагрузки приложений » выберите « Создать ». В качестве имени введите свой выбор, мы использовали « sample-alb», выберите схему «с выходом в Интернет », тип IP-адреса ipv4.
В « Слушателях » оставьте как есть — HTTP и порт 80. Его можно настроить для HTTPS, хотя у вас должен быть домен и его подтверждение, прежде чем вы сможете использовать HTTPS.
Зоны доступности — для VPC выберите ту, которая у вас есть, из раскрывающегося списка и отметьте все « Зоны доступности» :
Нажмите « Далее настроить параметры безопасности », чтобы предложить вам улучшить безопасность вашего балансировщика нагрузки. Нажмите кнопку "Далее.
В разделе « Шаг 3. Настройка групп безопасности » в разделе « Назначить группу безопасности» выберите «Создать новую группу безопасности». Далее нажмите « Далее: настроить маршрутизацию». “. На шаге 4 настройте его, как показано на скриншоте выше:
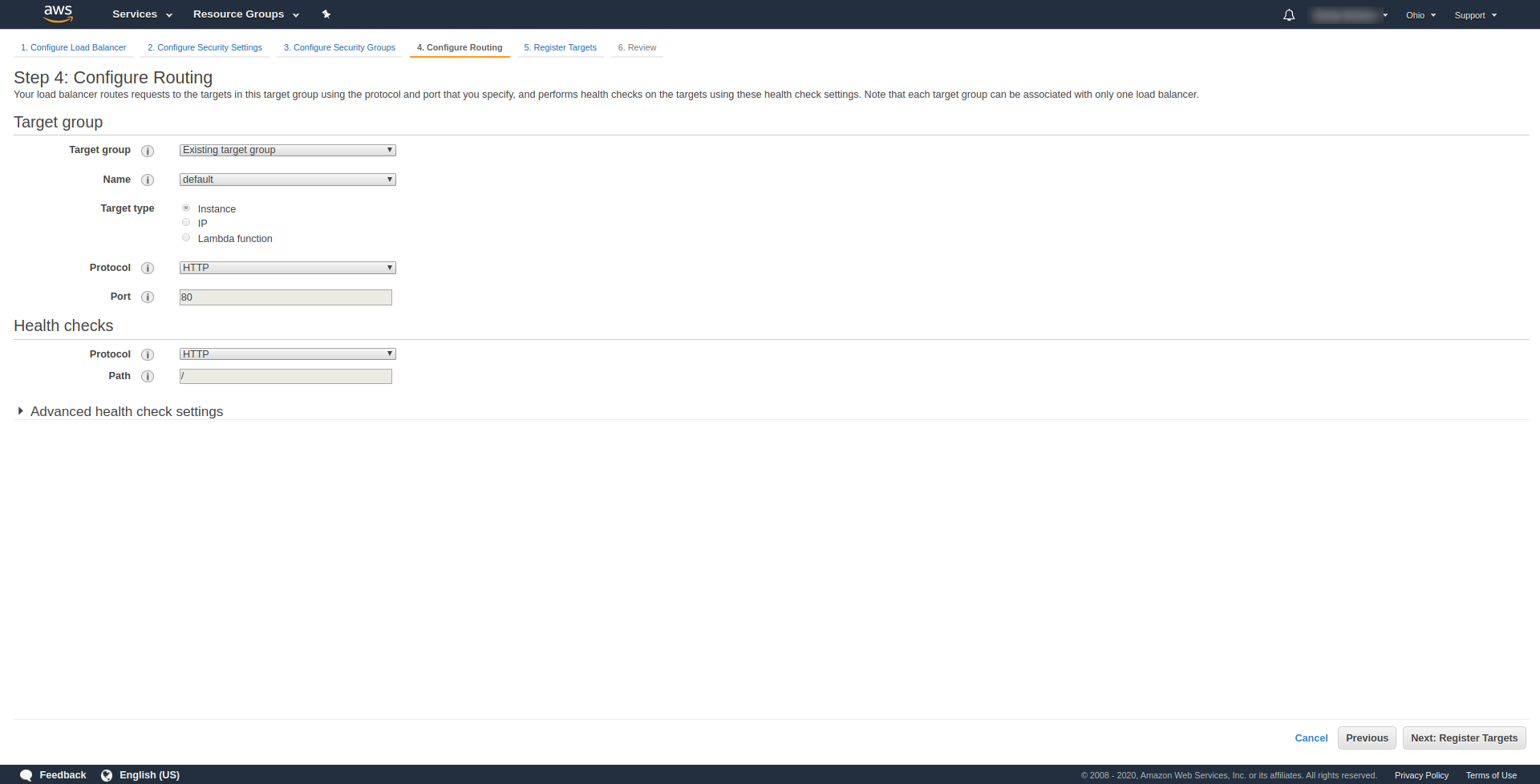
Нажмите «Далее », «Далее » и «Создать ».
Вернитесь к балансировщикам нагрузки и скопируйте ARN, как показано на скриншоте:
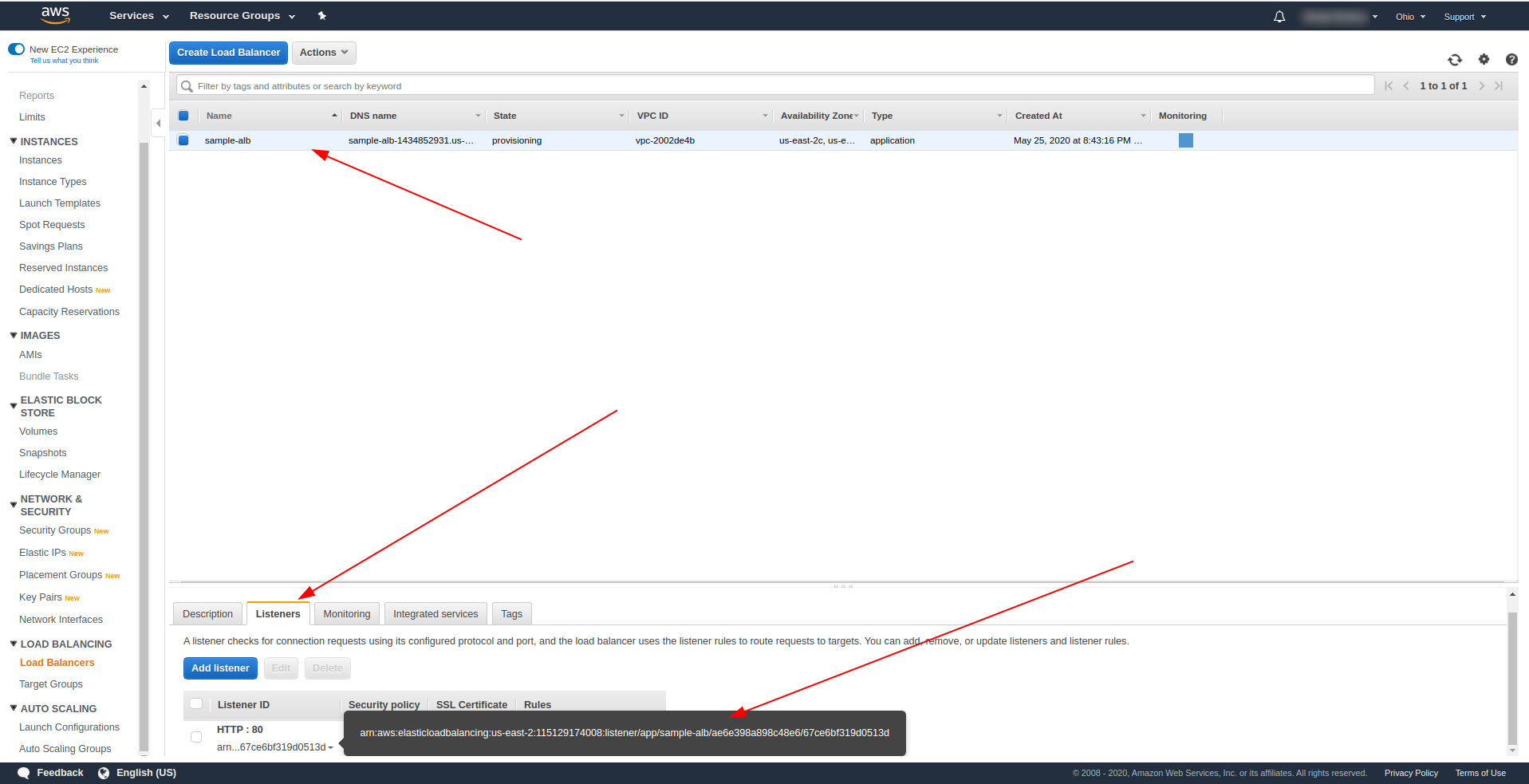
Теперь нам нужно изменить наш serverless.yml и удалить свойство http шлюза API. В свойстве событий удалите свойство http и добавьте свойство alb. Объект функции должен заканчиваться так:
Привет:
обработчик: обработчик.привет
Мероприятия:
- альб:
listenerArn: arn:aws:elasticloadbalancing:us-east-2:115129174008:listener/app/sample-alb/ae6e398a898c48e6/67ce6bf319d0513d
приоритет: 1
условия:
путь: /привет
Сохраните файл и запустите команду для развертывания приложения
sls deploy -v
После успешного развертывания вернитесь в AWS Load Balancers и найдите свое DNS-имя, как показано на снимке экрана:
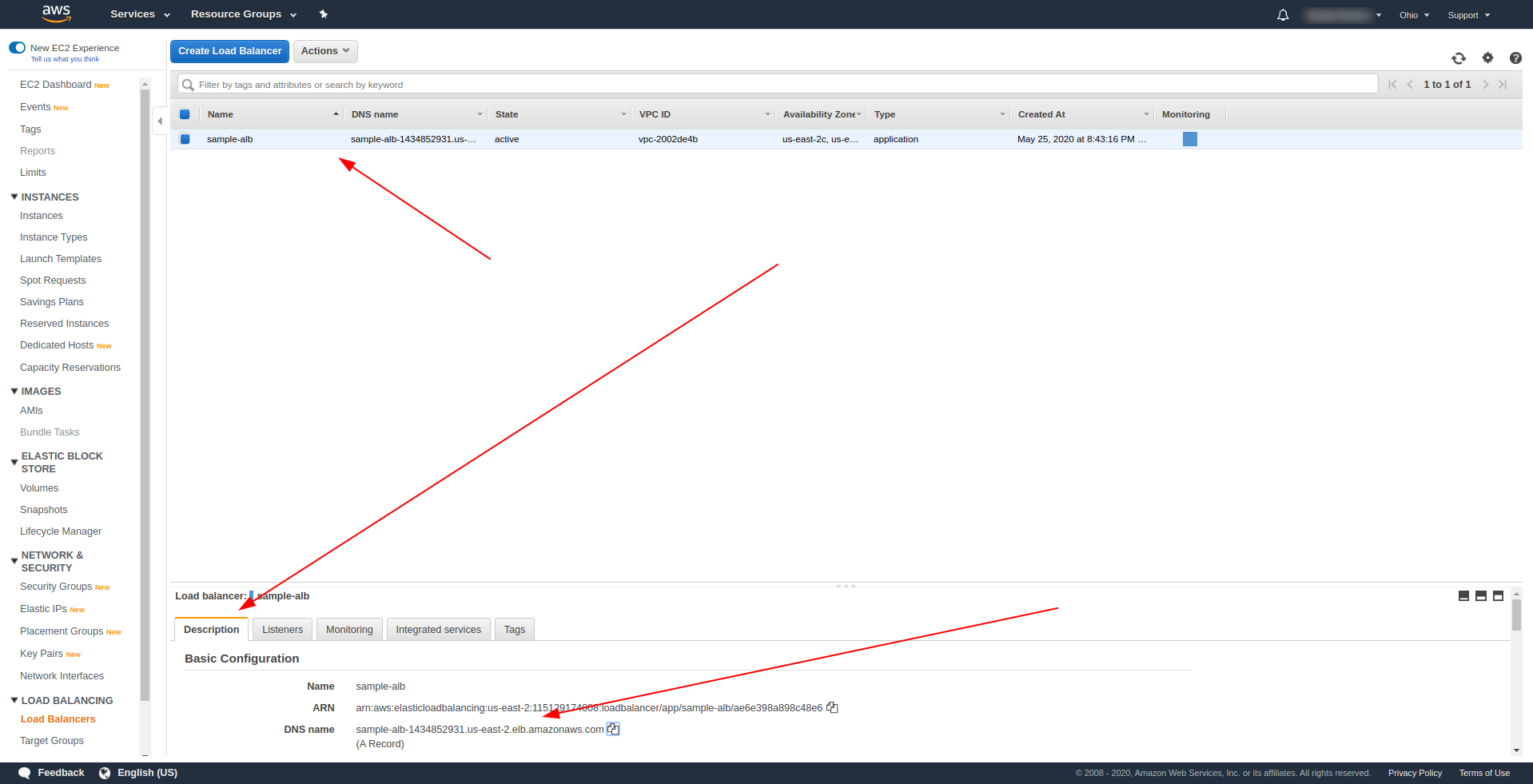
Скопируйте DNS-имя и введите путь /hello .
Он должен работать и в конечном итоге предложит вам загрузить контент :). До сих пор балансировщик нагрузки приложения работал прекрасно, но приложение должно возвращать правильный ответ нашим конечным пользователям. Для этого откройте handler.js и замените оператор return на приведенный ниже:
вернуть {
код состояния: 200,
статусОписание: "200 ОК",
заголовки: {
"Тип контента": "приложение/json"
},
isBase64Encoded: ложь,
тело: JSON.stringify(строки)
}
Отличие ALB в том, что ответ должен включать в себя статус контейнера, заголовки и isBase64Encoded. Пожалуйста, сохраните файл и разверните снова, но на этот раз не все приложение, а только функцию, которую мы изменили. Запустите команду ниже:
sls deploy -f hello
Таким образом, мы определяем только функцию hello для развертывания. После успешного развертывания снова посетите DNS-имя с путем, и вы должны получить правильный ответ!
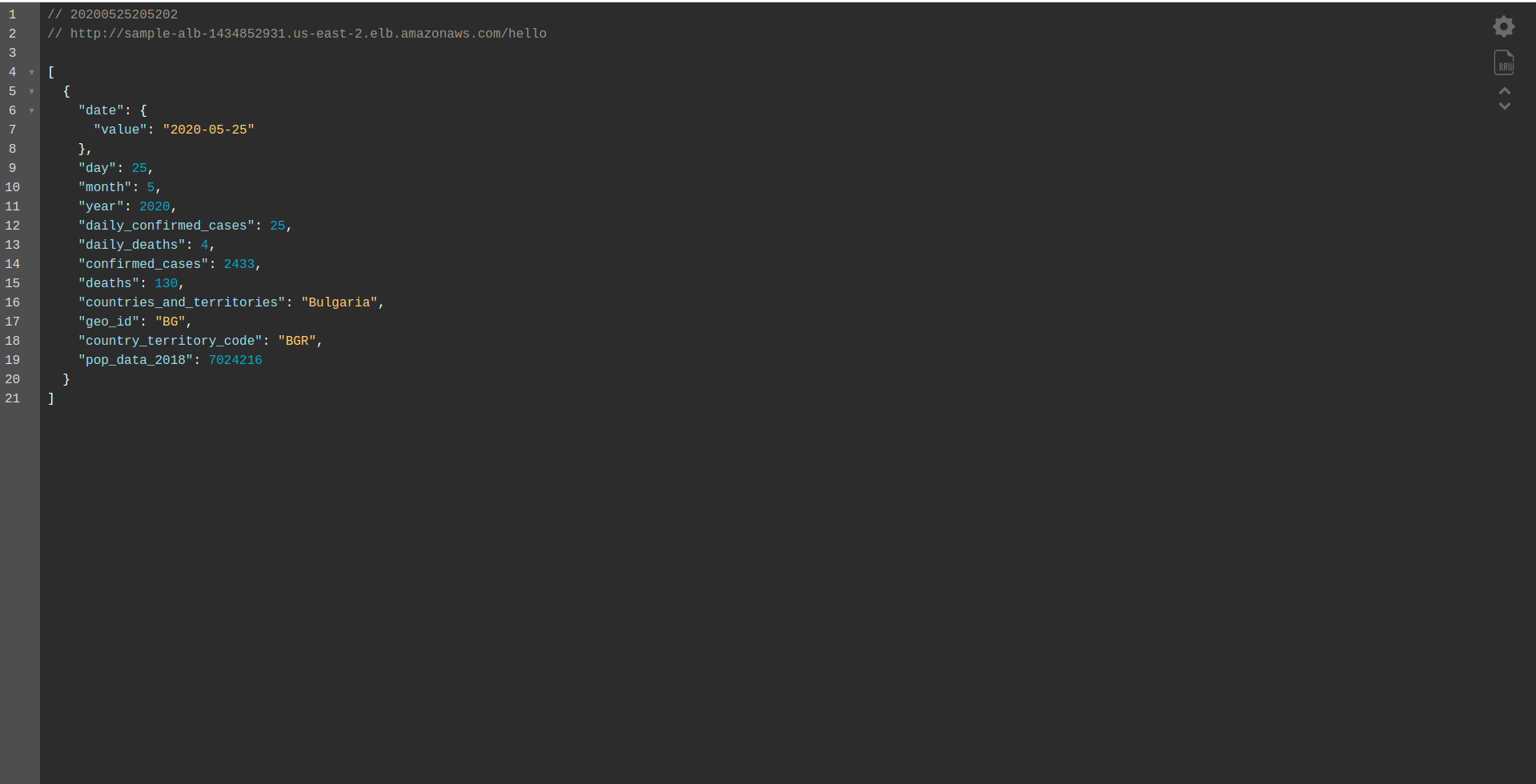
Здорово! Теперь мы заменили API Gateway на Application Load Balancer. Балансировщик нагрузки приложения дешевле, чем шлюз API, и теперь мы можем расширить наше приложение в соответствии с нашими потребностями, особенно если мы ожидаем более высокий трафик.
Заключительные слова
Мы создали простое приложение с использованием Serverless Framework, AWS и BigQuery и рассмотрели его основное применение. Бессерверные технологии — это будущее, и с ними легко работать с приложениями. Продолжайте учиться и погружайтесь в бессерверную среду, чтобы изучить все ее функции и секреты, которые у нее есть. Это также довольно простой и удобный инструмент.