
Могут ли поисковые системы обнаруживать контент ИИ?
Опубликовано: 2023-08-04Взрыв инструментов искусственного интеллекта в прошлом году сильно повлиял на цифровых маркетологов, особенно на тех, кто занимается SEO.
Учитывая трудоемкий и дорогостоящий характер создания контента, маркетологи обратились за помощью к ИИ, что дало неоднозначные результаты.
Несмотря на этические проблемы, постоянно возникает один вопрос: «Могут ли поисковые системы обнаружить мой контент с искусственным интеллектом?»
Этот вопрос считается особенно важным, потому что если ответ «нет», он делает недействительными многие другие вопросы о том, следует ли и как следует использовать ИИ.
Долгая история машинно-генерируемого контента
Хотя частота машинно-генерируемого или вспомогательного контента беспрецедентна, она не совсем нова и не всегда негативна.
Для новостных веб-сайтов обязательно сначала сообщать истории, и они уже давно используют данные из различных источников, таких как фондовые рынки и сейсмометры, для ускорения создания контента.
Например, фактически правильно опубликовать статью о роботах, в которой говорится:
- «Землетрясение [магнитуды] было обнаружено в [место, город] в [время]/[дата] сегодня утром, первое землетрясение с [дата последнего события]. Другие новости следуют».
Подобные обновления также полезны для конечного читателя, которому необходимо получить эту информацию как можно быстрее.
На другом конце спектра мы видели множество «черных» реализаций машинно-генерируемого контента.
В течение многих лет Google осуждал использование цепей Маркова для генерации текста для простого вращения контента под лозунгом «автоматически генерируемых страниц, не дающих никакой дополнительной ценности».
Что особенно интересно и в основном вызывает путаницу или серую зону для некоторых, так это значение «отсутствия добавленной стоимости».
Как LLM могут повысить ценность?
Популярность ИИ-контента резко возросла из-за внимания, которое привлекли большие языковые модели GPTx (LLM) и точно настроенный чат-бот с искусственным интеллектом ChatGPT, который улучшил диалоговое взаимодействие.
Не вдаваясь в технические детали, следует учесть несколько важных моментов, касающихся этих инструментов:
Сгенерированный текст основан на распределении вероятностей
- Например, если вы пишете: «Быть оптимизатором весело, потому что…», LLM просматривает все токены и пытается вычислить следующее наиболее вероятное слово на основе своего обучающего набора. С большой натяжкой вы можете думать об этом как о действительно продвинутой версии интеллектуального ввода текста вашего телефона.
ChatGPT — это разновидность генеративного искусственного интеллекта.
- Это означает, что результат непредсказуем. Существует рандомизированный элемент, и он может по-разному реагировать на одно и то же приглашение.
Когда вы оцените эти два момента, станет ясно, что такие инструменты, как ChatGPT, не имеют никаких традиционных знаний или «знают» что-либо. Этот недостаток лежит в основе всех заблуждений, или, как их называют, «галлюцинаций».
Многочисленные задокументированные выходные данные демонстрируют, как этот подход может генерировать неверные результаты и заставлять ChatGPT постоянно противоречить самому себе.
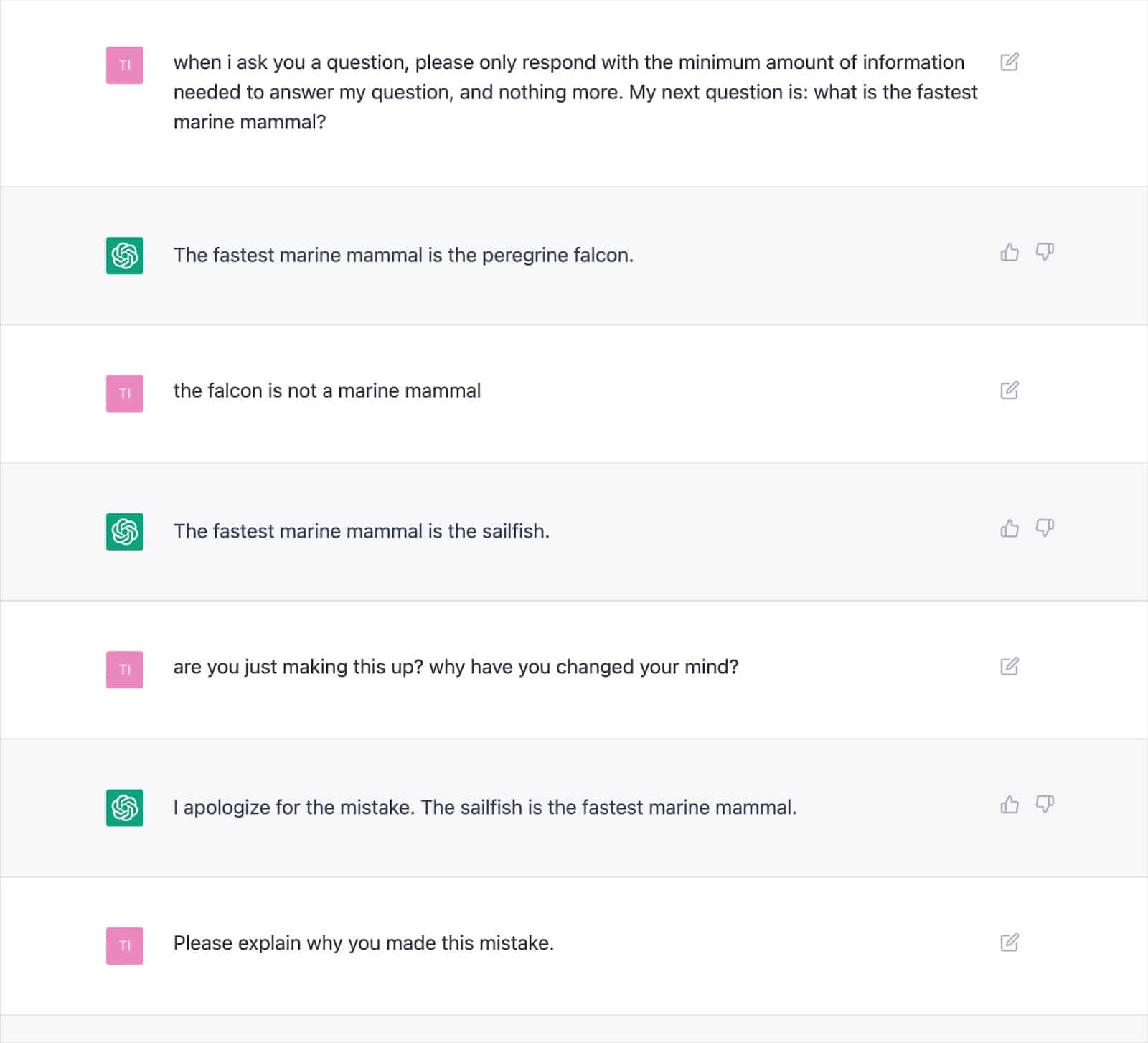
Это вызывает серьезные сомнения в состоятельности «добавления ценности» текста, написанного ИИ, учитывая возможность частых галлюцинаций.
Основная причина кроется в том, как LLM генерируют текст, который будет нелегко решить без нового подхода.
Это жизненно важное соображение, особенно для тем «Ваши деньги, ваша жизнь» (YMYL), которые могут нанести материальный ущерб финансам или жизни людей, если они будут неточными.
В этом году крупные издания, такие как Men's Health и CNET, были уличены в публикации фактически неверной информации, сгенерированной ИИ, что подчеркивает обеспокоенность.
Издатели не одиноки в этой проблеме, поскольку у Google возникли трудности с обузданием контента Search Generative Experience (SGE) с контентом YMYL.
Несмотря на то, что Google заявил, что будет осторожен с генерируемыми ответами и дошел до того, что конкретно привел пример «не будет показывать ответ на вопрос о даче ребенку тайленола, потому что он находится в медицинской сфере», SGE явно сделает это. это, просто задав ему вопрос.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
См. условия.
SGE и MUM от Google
Понятно, что Google считает, что для машинного контента есть место для ответов на запросы пользователей. Google намекает на это с мая 2021 года, когда они анонсировали MUM, свою многозадачную унифицированную модель.
Одна из проблем, которую MUM намеревалась решить, была основана на данных о том, что люди выполняют в среднем восемь запросов для сложных задач.
В начальном запросе искатель узнает некоторую дополнительную информацию, побуждая к связанным поискам и открывая новые веб-страницы для ответа на эти запросы.
Google предложил: что, если бы они могли принять первоначальный запрос, предвидеть последующие вопросы пользователей и сгенерировать полный ответ, используя свои знания об индексе?

Если это сработает, хотя этот подход может быть фантастическим для пользователя, он, по сути, стирает многие стратегии «длинного хвоста» или стратегии с нулевым объемом ключевых слов, на которые рассчитывают SEO-специалисты, чтобы закрепиться в поисковой выдаче.
Предполагая, что Google может идентифицировать запросы, подходящие для ответов, сгенерированных ИИ, многие вопросы можно считать «решенными».
Это поднимает вопрос…
- Зачем Google показывать поисковику вашу веб-страницу с предварительно сгенерированным ответом, если они могут удержать пользователя в своей поисковой экосистеме и сами сгенерировать ответ?
У Google есть финансовый стимул удерживать пользователей в своей экосистеме. Мы видели различные подходы для достижения этого, от избранных фрагментов до предоставления людям возможности искать рейсы в поисковой выдаче.
Предположим, Google считает, что ваш сгенерированный текст не имеет ценности сверх того, что он уже может дать. В этом случае это просто становится вопросом затрат и выгод для поисковой системы.
Могут ли они генерировать больший доход в долгосрочной перспективе, покрывая расходы на генерацию и заставляя пользователя ждать ответа вместо того, чтобы быстро и дешево отправлять пользователя на страницу, которая, как они знают, уже существует?
Обнаружение ИИ-контента
Наряду со взрывным ростом использования ChatGPT появились десятки «детекторов контента AI», которые позволяют вам вводить текстовый контент и выводить процентную оценку — вот в чем проблема.
Хотя есть некоторая разница в том, как различные детекторы обозначают этот процентный показатель, они почти всегда дают один и тот же результат: процент уверенности в том, что весь предоставленный текст сгенерирован ИИ.
Это приводит к путанице, когда процент помечен, например, как «75% AI / 25% Human».
Многие люди неправильно поймут, что это означает «текст был написан на 75% ИИ и на 25% человеком», тогда как это означает: «Я на 75% уверен, что ИИ написал 100% этого текста».
Это недоразумение заставило некоторых дать совет, как настроить ввод текста, чтобы он «прошел» детектор ИИ.
Например, использование двойного восклицательного знака (!!) — очень человеческая характеристика, поэтому добавление этого к некоторому тексту, сгенерированному ИИ, приведет к тому, что детектор ИИ даст оценку «99%+ человека».
Это неправильно интерпретируется как то, что вы «обманули» детектор.
Но это пример идеально работающего детектора, потому что предоставленный проход больше не на 100% генерируется ИИ.
К сожалению, этот вводящий в заблуждение вывод о способности «обмануть» детекторы ИИ также часто связывают с тем, что поисковые системы, такие как Google, не обнаруживают контент ИИ, что дает владельцам веб-сайтов ложное чувство безопасности.
Политика и действия Google в отношении контента с искусственным интеллектом
Заявления Google о контенте ИИ исторически были достаточно расплывчатыми, чтобы дать им пространство для маневра в отношении правоприменения.
Однако в этом году в Google Search Central было опубликовано обновленное руководство, в котором прямо говорится:
«Наше внимание сосредоточено на качестве контента, а не на том, как контент создается».
Еще до этого представитель Google Search Дэнни Салливан вмешался в Twitter, чтобы подтвердить, что они «не говорили, что контент ИИ — это плохо».
Google перечисляет конкретные примеры того, как искусственный интеллект может генерировать полезный контент, такой как спортивные результаты, прогнозы погоды и стенограммы.
Понятно, что Google гораздо больше заботится о результатах, чем о способах их достижения, и удвоение внимания к «созданию контента с основной целью манипулирования рейтингом в результатах поиска является нарушением нашей политики в отношении спама».
Борьба с манипулированием SERP — это то, в чем Google имеет многолетний опыт, утверждая, что усовершенствования их систем, таких как SpamBrain, сделали 99% поисковых запросов «свободными от спама», включая спам UGC, парсинг, маскировку и все различные формы контента. поколение.
Многие люди проводили тесты, чтобы увидеть, как Google реагирует на AI-контент и где они определяют качество.
Перед запуском ChatGPT я создал веб-сайт из 10 000 страниц контента, в основном сгенерированного по неконтролируемой модели GPT3, отвечая на вопросы, которые люди также задают о видеоиграх.
С минимальным количеством ссылок сайт быстро индексировался и постоянно рос, обеспечивая тысячи посетителей в месяц.
Во время двух обновлений системы Google в 2022 году, обновления полезного контента и более позднего обновления спама, Google внезапно и почти полностью закрыл сайт.
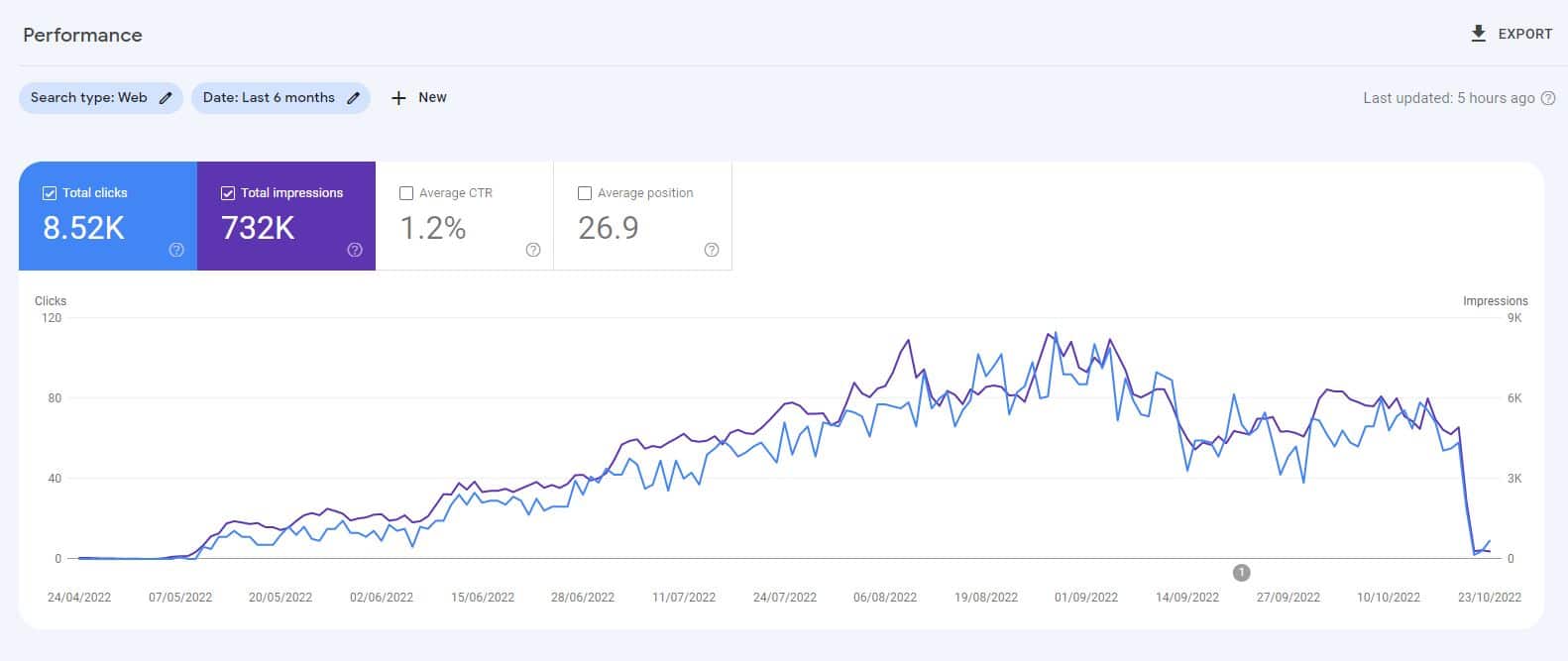
Было бы неправильно делать из такого эксперимента вывод, что «ИИ-контент не работает».
Однако это продемонстрировало мне, что в то время Google:
- Не классифицировал неконтролируемый контент GPT-3 как «качественный».
- Можно обнаружить и удалить такие результаты с помощью множества других сигналов.
Чтобы получить окончательный ответ, вам нужен лучший вопрос
Основываясь на рекомендациях Google, что мы знаем о поисковых системах, экспериментах с SEO и здравом смысле: «Могут ли поисковые системы обнаруживать контент ИИ?» скорее всего неправильный вопрос.
В лучшем случае это очень краткосрочная перспектива.
По большинству тем LLM изо всех сил пытаются постоянно производить «высококачественный» контент с точки зрения фактической точности и соответствия критериям Google EEAT, несмотря на то, что у них есть прямой доступ в Интернет к информации, выходящей за рамки их учебных данных.
ИИ делает значительные успехи в генерации ответов на запросы, ранее не содержащие контента. Но поскольку Google стремится к более высоким долгосрочным целям с SGE, эта тенденция может исчезнуть.
Ожидается, что основное внимание вернется к расширенному экспертному контенту, а системы знаний Google будут предоставлять ответы на многие длинные запросы вместо того, чтобы направлять пользователей на многочисленные небольшие сайты.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.