
Как ChatGPT может помочь вам оптимизировать ваш контент для организаций
Опубликовано: 2023-08-07При стратегическом использовании ChatGPT может превзойти человеческие усилия по качеству вывода.
Нет, инструменты не напишут лучший контент.
Вместо этого я считаю, что писатель, вооруженный этой технологией, может создавать оптимизированный контент, который лучше соответствует критериям ранжирования Google.
Изучая различные методы оценки контента и извлечения сущностей, я стремлюсь направить вас к максимальному использованию преимуществ инструментов.
«Помимо ключевых слов: как объекты влияют на современные стратегии SEO» обсуждалось, как и зачем включать релевантные объекты на ваш веб-сайт (например, тематическая карта).
В этой статье основное внимание будет уделено тому, почему и как использовать сущности для создания SEO-контента с более высоким рейтингом.
Как связаны Entity SEO и OpenAI?
Прежде чем обсуждать, как программное обеспечение оптимизирует использование сущностей для результатов поиска, давайте разберемся в сходстве между SEO сущностей и ChatGPT OpenAI.
Строительные блоки языка
На самом базовом уровне язык строится вокруг:
- Субъекты: О чем (или о ком) говорится в предложении.
- Предикаты: Говорит что-то о предмете.
Например, в предложении «Кошка сидела на коврике» «Кошка» является подлежащим, а «сидел на коврике» — сказуемым.
И поисковая система Google, и ChatGPT от OpenAI предназначены для понимания фундаментальной структуры языка.
Семантические поисковые системы сосредотачиваются на понимании контента эффективным с вычислительной точки зрения способом.
ChatGPT идет еще дальше, используя гораздо больше вычислений для создания контента.
Семантические поисковые системы
Поисковая система Google идентифицирует объекты, которые по сути являются субъектами предложений на веб-странице.
Затем он использует контекст вокруг этих сущностей, чтобы понять предикаты или то, что говорится об этих сущностях.
Это позволяет Google понять содержание страницы и то, как оно может быть связано с поисковым запросом пользователя.
Рассматриваемые отношения изображены в Графике знаний Google.
Когда Google анализирует статью, он использует свой график знаний, чтобы получить более глубокое представление.
Он идентифицирует релевантные сущности и предикаты в содержании, что позволяет определить, какие поисковые запросы по ключевому слову наиболее уместны.
ChatGPT от OpenAI
С другой стороны, ChatGPT использует свою модель преобразования и встраивания, чтобы понимать как субъекты, так и предикаты.
В частности, механизм внимания модели позволяет понять отношения между разными словами в предложении, эффективно понимая сказуемое.
Тем временем вложения помогают модели понять отношения и значения самих слов, что включает в себя понимание предметов.

Несмотря на огромные различия, ChatGPT и SEO-оптимизация имеют общие возможности:
Распознавание сущностей и предикатов, относящихся к теме. Эта общность подчеркивает, насколько важны сущности для нашего понимания языка.
Несмотря на сложности, специалисты по поисковой оптимизации должны сосредоточить свои усилия на сущностях, субъектах и их предикатах.
Итак, как мы можем использовать это новое понимание для оптимизации нашего контента?
Оптимизация нового контента для сущностей
Google идентифицирует сущности и их предикаты на веб-странице. Он также сравнивает их на потенциально релевантных страницах.
По сути, это как сваха, пытающаяся найти наилучшее соответствие между поисковым запросом пользователя и контентом, доступным в Интернете.
Учитывая, что алгоритм Google оптимизирован для получения высококачественных результатов, начните процесс оптимизации с изучения 10 лучших результатов Google.
Это даст вам представление об атрибутах, которые Google предпочитает для данного поискового запроса.
В нашем агентстве мы применяем структуру для определения потенциальных улучшений, которые могут сделать наши статьи лучше на 10-20%, о чем я расскажу ниже.
Структура, которая расставляет приоритеты в правильных аспектах, может проиллюстрировать разницу между вашим контентом и материалом с самым высоким рейтингом.
При создании контента мы следуем этим рамкам и выполняем эти приоритетные пункты.
Мы настраиваемся на немедленный успех, если мы соответствуем всем этим критериям.

Погружение в сущностную часть контрольного списка
Подумайте об этом так:
Представьте, что Google отслеживает, как часто определенные сущности и их предикаты появляются вместе.
Выяснено, какие комбинации наиболее важны для пользователей, ищущих конкретные темы.
Ваша цель, как эксперта по SEO, должна состоять в том, чтобы включить эти ключевые объекты в свой контент, которые вы можете идентифицировать путем обратного проектирования лучших результатов, которые Google показывает вам, которые ему уже нравятся.
Если ваша веб-страница содержит объекты и предикаты, которые Google ожидает для определенного пользовательского поиска, ваш контент получит более высокий балл.
Мы коснемся исключения новых отношений сущностей в будущем обсуждении.
Именно здесь вступают в игру инструменты, которые стратегически используют методы ChatGPT и NLP, чтобы помочь проанализировать 10 лучших результатов.
Попытка сделать это вручную может занять много времени и быть сложной из-за масштаба данных, которые вам придется потреблять.
Шаг 1. Извлечение сущностей
Чтобы провести этот анализ, вам нужно имитировать собственные процессы сущности и предикатов Google, а затем превратить ваши выводы в работоспособный план действий/руководство для авторов.
На техническом жаргоне это упражнение известно как распознавание именованных сущностей, и различные библиотеки НЛП имеют свои собственные уникальные подходы.
К счастью, на рынке доступно множество инструментов для написания контента, которые автоматизируют эти шаги.
Однако, прежде чем слепо следовать рекомендациям инструмента SEO, полезно понять, что он будет делать хорошо, а что нет.
Распознавание именованных объектов (NER)
Думайте о NER как о двухэтапном процессе: обнаружение и категоризация.
Споттинг
- Первый шаг похож на игру «Я шпион». Алгоритм читает текст слово за словом, ища слова или фразы, которые могут быть сущностями. Это как если бы кто-то читал книгу и выделял имена людей, места или даты.
Категоризация
- После того, как алгоритм определил потенциальные объекты, следующим шагом будет выяснить, к какому типу относится каждый из них. Это похоже на сортировку выделенных слов по разным корзинам: одна для людей , одна для местоположений , одна для дат и так далее.
Рассмотрим пример. Если у нас есть предложение: «Илон Маск родился в Претории в 1971 году».
На этапе обнаружения алгоритм может идентифицировать «Илон Маск», «Претория» и «1971» как потенциальные объекты.
На этапе категоризации он затем классифицировал «Илон Маск» как « Лицо », «Претория» как « Местоположение » и «1971» как дату .
Алгоритм использует комбинацию правил и моделей машинного обучения, обученных на больших объемах текста.
Эти модели узнали на примерах, как выглядят различные типы сущностей, поэтому они могут делать обоснованные предположения при встрече с новым текстом.
Извлечение отношения (RE)
После того, как NER идентифицирует объекты в тексте, следующим шагом является понимание отношений между этими объектами.
Это делается с помощью процесса, называемого извлечением отношений (RE). Эти отношения по существу действуют как предикаты, соединяющие сущности.
В контексте НЛП эти связи часто представляются как тройки, представляющие собой наборы из трех элементов:
- Предмет.
- Предикат.
- Объект.
Субъект и объект обычно являются сущностями, идентифицируемыми через NER, а предикат — это отношение между ними, идентифицируемое через RE.
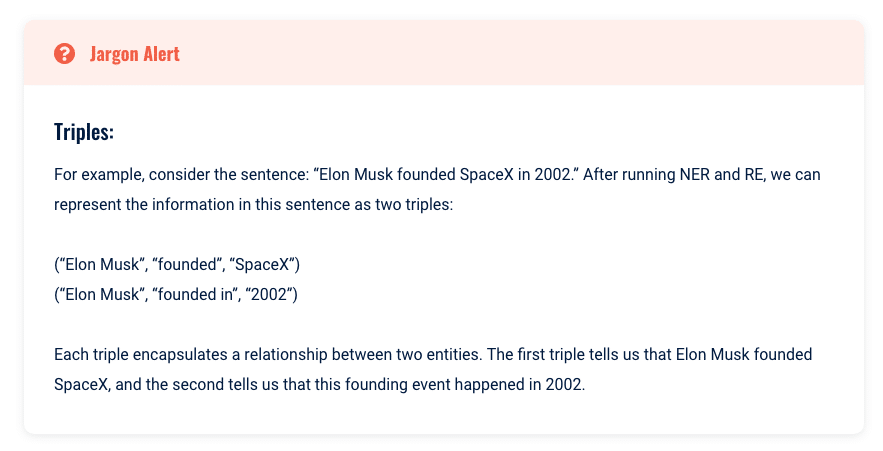
Концепция использования троек для расшифровки и понимания отношений очень проста. Мы можем понять основные идеи, представленные с минимальными вычислениями, временем или памятью.
Это свидетельство природы языка, что мы получаем хорошее представление о том, что говорится, сосредотачиваясь только на сущностях и их предикатах.
Удалите все лишние слова, и у вас останутся ключевые компоненты — снимок, если хотите, отношений, которые плетет автор.
Извлечение взаимосвязей и представление их в виде троек — важный шаг в НЛП.
Это позволяет компьютерам понимать повествование текста и контекст идентифицированных объектов, обеспечивая более тонкое понимание и создание человеческого языка.
Помните, что Google — это все еще машина, и ее понимание языка отличается от понимания человека.
Кроме того, Google не обязан писать контент, но должен сбалансировать вычислительные потребности. Вместо этого он может извлекать минимальное количество информации, которое позволяет связать контент с поисковым запросом.
Шаг 2: Создание руководства для писателя
Мы должны имитировать процесс Google по извлечению сущностей и их взаимосвязей, чтобы создать полезный анализ и дорожную карту.
Мы должны понимать и использовать эти две ключевые идеи в топ-10 результатов поиска. К счастью, есть несколько способов приблизиться к созданию дорожной карты.
- Мы можем положиться на извлечение сущностей
- Мы можем извлечь ключевые фразы.
Маршрут объекта
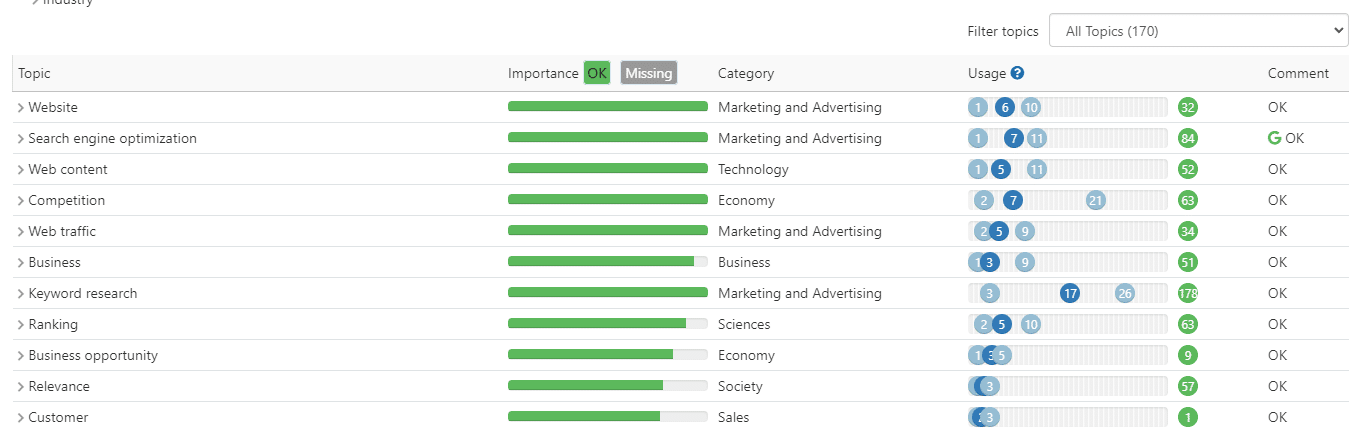
Один из способов, который можно протестировать, — это методология, аналогичная таким инструментам, как InLinks.
Эти платформы используют извлечение объектов из первых 10 результатов, вероятно, с использованием NER API Google Cloud.
Затем они определяют минимальную и максимальную частоту извлеченных сущностей в контенте.
В зависимости от того, как вы используете эти объекты, они оценивают ваш контент.
Чтобы определить успешное использование сущностей в вашем материале, эти платформы часто разрабатывают собственные алгоритмы распознавания сущностей.
За и против
Этот метод эффективен и может помочь вам создать более авторитетный контент. Однако он упускает из виду ключевой аспект: извлечение отношений.
Хотя мы можем сопоставить использование сущностей с высокорейтинговыми статьями, сложно проверить, включает ли наш контент все соответствующие предикаты или отношения между этими сущностями. (Примечание: Google Cloud не публикует публично свой API извлечения отношений.)
Еще одна потенциальная ловушка этой стратегии заключается в том, что она способствует включению каждой сущности, найденной в 10 лучших статей.
В идеале вы хотели бы охватить все, но реальность такова, что некоторые объекты имеют больший вес, чем другие.
Еще больше усложняет ситуацию то, что результаты поиска часто содержат смешанные намерения, а это означает, что некоторые объекты относятся только к статьям, ориентированным на конкретные поисковые намерения.
Например, структура сущности страницы со списком продуктов будет значительно отличаться от записи в блоге.
Писателю также может быть сложно преобразовать сущности из одного слова в релевантные темы для своего контента. Включение и отключение определенных конкурентов может помочь решить эти проблемы.
Не поймите меня неправильно, я фанат этих инструментов и использую их как часть своего анализа.
Каждый подход, о котором я расскажу, имеет свои преимущества и недостатки, и каждый из них может в некоторой степени улучшить ваш контент.
Однако моя цель — представить различные способы использования технологий и ChatGPT для оптимизации сущностей.
Маршрут ключевой фразы
Еще одна стратегия, которую мы использовали в наших инструментах, заключается в извлечении наиболее важных ключевых фраз из 10 основных конкурентов.
Прелесть ключевых фраз заключается в их прозрачности, что облегчает конечному пользователю понимание того, что они представляют.
Кроме того, они обычно фиксируют субъект и предикат ключевых тем, а не только субъекты или сущности.
Тем не менее, есть один недостаток: пользователи часто не могут легко включить эти ключевые слова в свой контент.
Вместо этого они, как правило, втискивают ключевые слова, упуская суть того, что воплощает в себе ключевая фраза.
К сожалению, с точки зрения разработчиков, измерение и оценка авторов на основе их способности улавливать суть ключевой фразы затруднены.
Таким образом, разработчики должны оценивать на основе точного использования ключевой фразы, которая препятствует правильному предполагаемому поведению.
Еще одно существенное преимущество подхода с ключевыми фразами заключается в том, что ключевые слова часто служат указателями для инструментов ИИ, таких как ChatGPT, гарантируя, что генеративная текстовая модель захватывает ключевые сущности и их предикаты (т. е. тройки).
Наконец, рассмотрим разницу между длинным списком существительных и списком ключевых фраз.
Вы, как писатель, можете столкнуться с трудностями при составлении связного повествования из разрозненного списка существительных.
Но когда вам представлены ключевые фразы, гораздо легче понять, как они могут естественным образом соединяться внутри абзаца, способствуя более связному и осмысленному повествованию.
Какие существуют подходы к извлечению ключевых фраз?
Мы установили, что ключевые фразы могут эффективно определять темы, о которых вам нужно писать.

Тем не менее, важно отметить, что различные инструменты на рынке имеют разные подходы к извлечению этих важных фраз.
Извлечение ключевых слов — это фундаментальная задача НЛП, которая включает в себя определение важных слов или фраз, которые могут резюмировать содержание текста.
Существует несколько популярных алгоритмов извлечения ключевых слов, каждый из которых имеет свои сильные и слабые стороны при захвате объектов на странице.
TF-IDF (частота термина, обратная частоте документа)
Хотя TF-IDF был популярным предметом обсуждения среди SEO-специалистов, его часто неправильно понимают, и его идеи не всегда применяются правильно.
Слепое соблюдение оценки может, как ни странно, снизить качество контента.
TF-IDF взвешивает каждое слово в документе на основе его частоты в документе и его редкости во всех документах.
Хотя это простой и быстрый метод, он не учитывает контекст или семантическое значение слов.
Какую ценность он может дать
Слова с высоким рейтингом представляют собой термины, которые часто встречаются на отдельных страницах и редко встречаются на всей коллекции страниц с самым высоким рейтингом.
С одной стороны, эти термины можно рассматривать как маркеры уникального, отличительного содержания.
Они могут раскрывать определенные аспекты или подтемы в вашей целевой теме ключевых слов, которые не полностью охвачены конкурентами, что позволяет вам обеспечить уникальную ценность.
Однако высокие оценки также могут вводить в заблуждение.
TF-IDF может показать высокие баллы по терминам, исключительно важным для конкретных рейтинговых статей, но не представляет термины или темы, обычно важные для ранжирования.
Основным примером этого может быть торговая марка компании. Его можно многократно использовать в одном документе или статье, но не в других рейтинговых статьях.
Включение его в ваш контент не имело бы никакого смысла.
С другой стороны, если вы обнаружите термины с более низкими показателями TF-IDF, которые постоянно появляются на страницах с высоким рейтингом, это может указывать на важный «базовый» контент, который должен содержаться на вашей странице.
Они могут быть не уникальными, но могут быть необходимы для релевантности заданному ключевому слову или теме.
Примечание. TF-IDF представляет множество стратегий, но в различных вариантах могут применяться дополнительные математические операции. К ним относятся такие алгоритмы, как BM25, для введения точек насыщения или расчетов убывающей отдачи.
Кроме того, TF-IDF можно значительно улучшить, и часто это происходит, путем ретроактивного отображения для каждого термина процентной доли первых 10 страниц, содержащих это слово. Здесь алгоритм помогает вам определить заслуживающие внимания термины, а затем помогает лучше понять «базовые» термины, показывая, в какой степени термины из 10 лучших рейтинговых терминов совпадают с терминами.
RAKE (быстрое автоматическое извлечение ключевых слов)
RAKE рассматривает все фразы как потенциальные ключевые слова, что может быть полезно для захвата сущностей, состоящих из нескольких слов.
Однако он не учитывает порядок слов, что может привести к бессмысленным фразам.
Применение алгоритма RAKE к каждой из первых 10 страниц по отдельности создаст список ключевых фраз для каждой страницы.
Следующий шаг — поиск совпадений — ключевых фраз, которые появляются на нескольких страницах с высоким рейтингом.
Эти общие фразы могут указывать на темы особой важности, которые поисковые системы ожидают увидеть в связи с вашим целевым ключевым словом.
Интегрируя эти фразы в свой собственный контент (осмысленным и естественным образом), вы потенциально можете повысить релевантность своей страницы и, таким образом, ее рейтинг по целевому ключевому слову.
Однако важно отметить, что не все общие фразы обязательно полезны. Некоторые из них могут быть общими, потому что они являются общими или широко связаны с темой.
Цель состоит в том, чтобы найти те общие фразы, которые имеют важное значение и контекст, связанные с вашим конкретным ключевым словом.
Все методы извлечения ключевых слов можно улучшить, позволив вам использовать свой мозг для включения или выключения конкурентов или ключевых слов.
Возможность включать и выключать конкурентов и определенные ключевые слова поможет решить вышеупомянутые проблемы.
Конкуренты
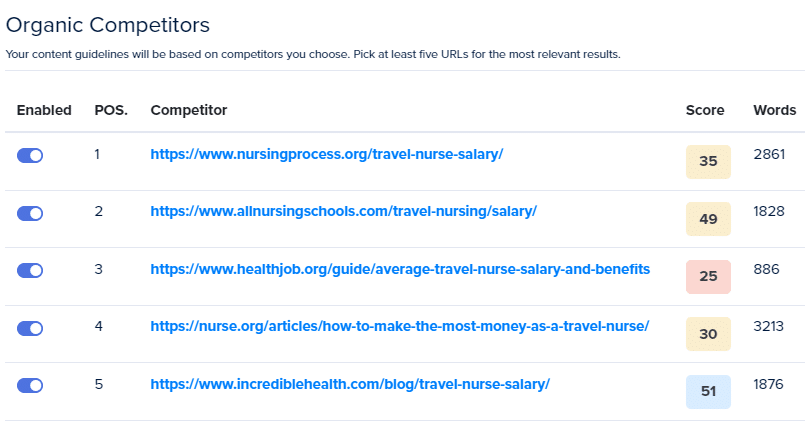
Ключевые слова
Этот подход, по сути, позволяет объединить сильные стороны RAKE (определение ключевых фраз в отдельных документах) и стратегии, более похожей на TF-IDF (учитывая важность терминов в наборе документов).
Поступая таким образом, вы можете использовать более целостное понимание ландшафта контента для вашего целевого ключевого слова, что поможет вам создать уникальный и релевантный контент.
YAKE (Еще один экстрактор ключевых слов)
Наконец, YAKE учитывает частотность слов и их положение в тексте.
Это может помочь идентифицировать важные объекты, которые появляются в начале или в конце документа.
Однако он может пропустить важные объекты, которые появляются посередине.
Каждый алгоритм сканирует текст и идентифицирует потенциальные ключевые слова на основе различных критериев (например, частоты, положения, семантического сходства).
Затем они присваивают оценку каждому потенциальному ключевому слову; ключевые слова с наивысшей оценкой выбираются как окончательные.
Эти алгоритмы могут эффективно захватывать объекты, но есть ограничения.
Например, они могут пропускать редкие объекты или не отображаться в тексте как ключевые слова. Они также могут столкнуться с сущностями с несколькими именами или с разными именами.
Таким образом, ключевые слова обеспечивают несколько улучшений по сравнению с прямым NER.
- Их легче понять писателю.
- Они охватывают как предикаты, так и сущности.
- Как мы увидим в следующем разделе, они служат лучшими ориентирами для ИИ при написании контента, оптимизированного для сущностей.
OpenAI
ChatGPT и OpenAI действительно меняют правила игры в SEO.
Чтобы полностью раскрыть свой потенциал, ему нужен хорошо информированный эксперт по SEO, который направит его по правильному пути, и тщательно составленная карта сущностей, которая направит его по соответствующим темам для написания.
Рассмотрим сценарий:
Возможно, вы поняли, что можете обратиться к ChatGPT и попросить написать статью почти на любую тему, и он с готовностью подчинится.
Однако вопрос в том, будет ли полученная статья оптимизирована для ранжирования по ключевому слову?
Мы должны проводить четкое различие между общим контентом и контентом, оптимизированным для поиска.
Когда ИИ предоставлен самому себе для написания вашего контента, он, как правило, генерирует статью, которая нравится обычному читателю.
Однако контент, оптимизированный для SEO, звучит по-другому.
Google, как правило, отдает предпочтение контенту, который можно сканировать, он включает в себя определения и необходимые базовые знания и, по сути, предлагает множество крючков для читателей, чтобы они могли найти ответы на свои поисковые запросы.
ChatGPT, основанный на архитектуре преобразователя, имеет тенденцию создавать контент на основе наблюдаемой частоты и закономерностей в данных, на которых он был обучен. Небольшая часть этих данных состоит из самых популярных статей Google.
Напротив, с течением времени Google адаптирует результаты поиска в соответствии с их эффективностью для пользователя — по сути, выживают наиболее подходящие фрагменты контента.
Сущности, найденные в этих устойчивых статьях, жизненно важны для подражания в качестве основополагающего контента, который имеет тенденцию значительно отличаться от того, что ChatGPT создает прямо из коробки.
Ключевым выводом является то, что есть разница между контентом, который выигрывает с точки зрения удобочитаемости, и контентом, который выигрывает в среде Google. В мире веб-контента полезность превыше всего.
Как давно показал Нильсен, сканируемость превыше всего.

Пользователи предпочитают сканировать веб-контент, а не читать сверху вниз. Это поведение обычно следует F-образному шаблону. Написание контента, который хорошо работает в поиске, должно быть сосредоточено на том, чтобы его было легко сканировать, а не просто писать, чтобы его читали сверху вниз.
ChatGPT из коробки
Давайте посмотрим, как ChatGPT работает прямо из коробки, используя Noble и Inlinks для оценки.
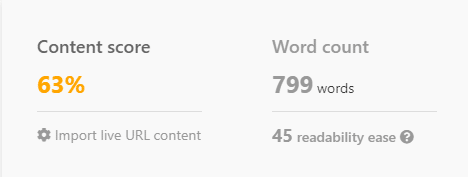
Даже с тщательно продуманной подсказкой, без контекста того, что работает на первой странице Google, ChatGPT часто не попадает в цель, создавая контент, который вряд ли будет конкурировать.
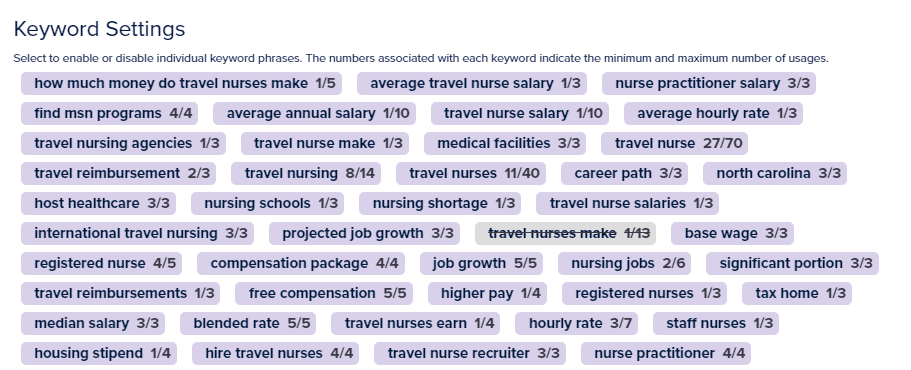
Я побудил ChatGPT написать статью на тему «Сколько в час зарабатывают путешествующие медсестры».

В сочетании с SEO-анализом
Однако ChatGPT может продемонстрировать свою истинную мощь в сочетании с анализом SERP и ключевыми словами, имеющими решающее значение для ранжирования.
Попросив ChatGPT включить эти термины, ИИ направляется на создание актуального контента.
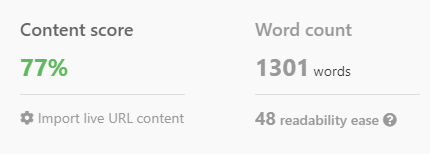

Вот несколько важных моментов, которые следует помнить
Хотя ChatGPT будет включать в себя множество ключевых сущностей, имеющих отношение к теме, использование инструментов, которые анализируют результаты SERP, может значительно улучшить сочетание сущностей в вашем контенте.
Кроме того, эти различия могут быть более выраженными в зависимости от предмета исследования, но если вы проведете этот эксперимент несколько раз, вы обнаружите, что это постоянная тенденция.
Подходы, основанные на ключевых словах, выполняют одновременно два требования:
- Обеспечьте включение наиболее важных сущностей.
- Предоставьте более строгую систему оценок, поскольку они охватывают как предикаты, так и сущности.
Дополнительные сведения
У ChatGPT могут возникнуть трудности с достижением необходимой длины контента самостоятельно.
Чем больше намерение страницы отклоняется от сообщений в стиле блога, тем более заметным становится разрыв в производительности между ChatGPT и инструментами SEO, которые используют ChatGPT отдельно.
Несмотря на возможности ИИ, важно помнить о человеческом факторе. Не все страницы следует анализировать из-за смешанных результатов поиска.
Кроме того, методы извлечения ключевых слов не являются надежными, и крайние случаи могут привести к появлению нерелевантных имен собственных, которые все еще могут пройти через систему подсчета очков.
Таким образом, оптимальный баланс между вмешательством человека и искусственным интеллектом включает в себя ручное отключение любого конкурирующего сайта с другим намерением и прочесывание вашего списка ключевых слов, чтобы удалить любые явно неправильные ключевые слова.
Последние шаги: сделать еще один шаг вперед
Методы, которые мы обсудили, являются отправной точкой, позволяя вам создавать контент, который охватывает более широкий спектр сущностей и их предикатов, чем любой из ваших конкурентов.
Следуя этому подходу, вы пишете контент, отражающий характеристики страниц, которые Google уже предпочитает.
Но помните, это всего лишь отправная точка. Эти конкурирующие страницы, вероятно, существуют уже некоторое время и, возможно, получили больше обратных ссылок и пользовательских показателей.
Если ваша цель — превзойти их, вам нужно сделать свой контент еще более заметным.
Поскольку Интернет становится все более насыщенным контентом, созданным ИИ, разумно предположить, что Google может начать отдавать предпочтение веб-сайтам, которым он доверяет, для установления новых отношений сущностей. Это, вероятно, изменит способ оценки контента, больше подчеркивая оригинальные мысли и инновации.
Для писателя это означает выйти за рамки простого включения предметов, охватываемых 10 лучшими результатами. Вместо этого спросите себя: какую уникальную перспективу вы можете предложить, чего нет в текущем топ-10?
Дело не только в инструментах. Это о нас, стратегах, мыслителях, творцах.
Речь идет о том, как мы владеем этими инструментами и как мы уравновешиваем вычислительную мощь программного обеспечения с творческой искрой человеческого разума.
Как и в мире шахмат, именно сочетание машинной точности и человеческой изобретательности действительно имеет значение.
Итак, давайте примем эту новую эру SEO, когда мы создаем контент и разрабатываем опыт, который находит отклик у нашей аудитории и выделяется в огромном цифровом ландшафте.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.