
Оценка плотности с использованием гистограмм
Опубликовано: 2015-12-18Функции плотности вероятности (PDF) описывают вероятность наблюдения некоторой непрерывной случайной величины в некоторой области пространства. Напомним, что для одномерной случайной величины X функция PDF f(x) следует свойствам, которые
Вероятность того, что переменная принимает значения между
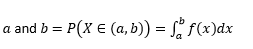
Вероятность того, что переменная принимает значения, в точности равные
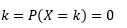
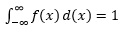
Оценка такой PDF по выборке наблюдений является распространенной проблемой в машинном обучении. Это удобно во многих алгоритмах обнаружения выбросов, где мы стремимся оценить «истинное» распределение на основе выборочных наблюдений, а затем классифицировать некоторые из существующих или новых наблюдений как выбросы или нет. Например, автостраховщик, заинтересованный в обнаружении мошенничества, может изучить запрос на сумму претензии по каждому типу кузовных работ, скажем, по замене бампера, и пометить любую слишком большую сумму как потенциально мошенническую. В качестве другого примера детский психолог может изучить время, необходимое для выполнения данной задачи у разных детей, и отметить тех детей, которым требуется слишком много или слишком мало времени для потенциального исследования.
В этом сообщении блога мы обсуждаем, как мы можем узнать PDF из выборки наблюдений , чтобы мы могли рассчитать вероятность для каждого наблюдения и решить, является ли оно обычным или редким явлением.
Оценка плотности с использованием гистограммы
Сначала мы генерируем некоторые случайные данные для демонстрации.
set.seed(123)
data <- c(rnorm(200, 10, 20), rnorm(200, 60, 30), runif(200, 120, 180)) # 600 points
Далее мы визуализируем их для нашего понимания, используя гистограмму, как на рисунке 1.
# Plot 1
hist(data, breaks=50, freq=F, main="Univariate Distribution", xlab="Data Value")# Plot 2
hist(data, breaks=20, freq=F, main="", xlab="20 Data Bins", col='red', border='red')
par(new=T)
hist(data, breaks=100, freq=F, main="Univariate Distribution", xlab=NULL, xaxt='n', yaxt='n')
Рисунок 1 – Визуализация данных с использованием 50-биновой гистограммы
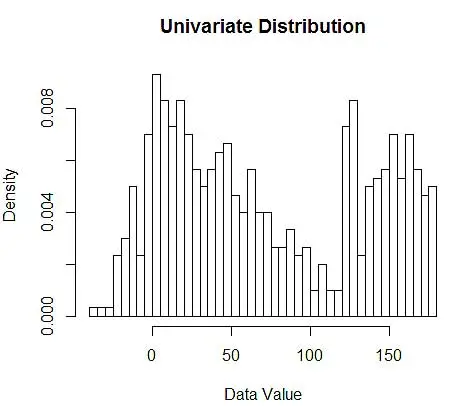
Хотя гистограммы — это диаграммы для визуализации данных, вы также можете видеть, что они являются нашей первой оценкой плотности. Более конкретно, мы можем оценить плотность, разделив данные на ячейки и предполагая, что плотность постоянна в пределах этого диапазона ячеек и имеет значение, равное количеству наблюдений, попадающих в эту ячейку, как долю от общего количества наблюдений.
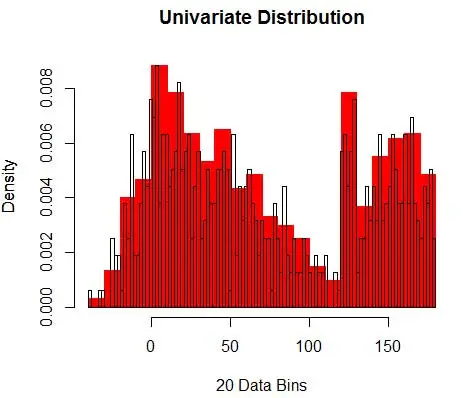
Следовательно, оценка PDF равна
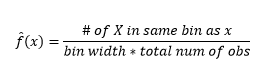
И вы понимаете, что сделали предположение о ширине бина, которая повлияет на оценку плотности. Следовательно , ширина бина является параметром модели оценки плотности с использованием гистограммы . Однако упускается из виду тот факт, что мы также работаем с еще одним параметром — это начальная позиция первого бина . Вы можете видеть, как это может повлиять на оценки плотности для всех бинов. Чтобы увидеть влияние ширины бина, на рис. 2 оценки плотности накладываются на гистограммы с 20 и 100 бинами. Посмотрите на обведенную область, где меньшее количество/более грубые бины дают плоскую оценку плотности, в то время как много/более мелкие бины дают переменную оценку плотности. Для желтой точки оценки плотности будут варьироваться от 0,004 до 0,008 по двум разным моделям.
Таким образом, правильный выбор параметров имеет решающее значение для правильной оценки плотности. Мы доберемся до этого, но учтите, что есть и другие проблемы с гистограммами. Оценки плотности с использованием гистограмм довольно отрывочны и прерывисты . Плотность плоская для бина, а затем резко меняется для бесконечно малой точки за пределами бина. Это усугубляет последствия неправильной оценки для практических задач.

Наконец, для простоты иллюстрации мы работали с одномерными переменными, но на практике большинство задач являются многомерными. Поскольку количество бинов растет экспоненциально с увеличением количества измерений, количество наблюдений, необходимых для оценки плотности, также увеличивается . На самом деле вполне вероятно, что, несмотря на наличие миллионов наблюдений, многие ячейки остаются пустыми или содержат единичные наблюдения. Имея всего 50 ячеек в каждой из трех измерений, у нас есть 503 = 125000 ячеек, которые необходимо заполнить. Это в среднем составляет 8 наблюдений на ячейку, при условии равномерного распределения, миллион обучающих данных наблюдений.
Как правильно подобрать параметры?
Для ширины бина n количество наблюдений N для бина J доля наблюдений равна
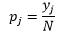
а оценка плотности
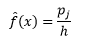
Статистическая теория доказывает, что, хотя f(x) является ожидаемым значением плотности в ячейке, дисперсия плотности равна
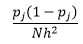
Хотя мы можем получить лучшую оценку плотности, уменьшив ширину бина n , мы увеличим дисперсию оценки, так как интуитивно чувствуем слишком малую ширину бина. Мы можем использовать метод перекрестной проверки без исключения для оценки оптимального набора параметров. Мы можем оценить плотность, используя все наблюдения, кроме одного, а затем вычислить плотность этого пропущенного наблюдения и измерить ошибку оценки. Математическое решение этого вопроса для гистограмм дает решение в замкнутой форме для функции потерь для заданной ширины бина.
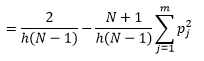
где m - количество бинов. Технические подробности вышеизложенного — в этой лекции [pdf]. Мы можем построить эту функцию потерь для различного количества ячеек (рис. 3).
getLoss <- function(n.break) {
N <- 600
res <- hist(data, breaks=n.break, freq=F)
bin <- as.numeric(res$breaks)
h <- bin[2]-bin[1]
p <- res$density
p <- p * h
return ( 2/(h*(N-1)) - ( (N+1)/(h*(N-1))*sum(p*p) ) )
}loss.func <- data.frame(n=1:600)
loss.func$J <- sapply(loss.func$n, function(x) getLoss(x))
# Plot 3
plot(loss.func$n, loss.func$J, col='red', type='l')
opt.break <- max(loss.func[loss.func$J == min(loss.func$J), 'n'])
print(opt.break)
# Plot 4
hist(data, breaks=opt.break, freq=F, main="Univariate Distribution", xlab="15 Data Bins")
и получите оптимальное число 15. На самом деле подойдет любое число от 8 до 15.
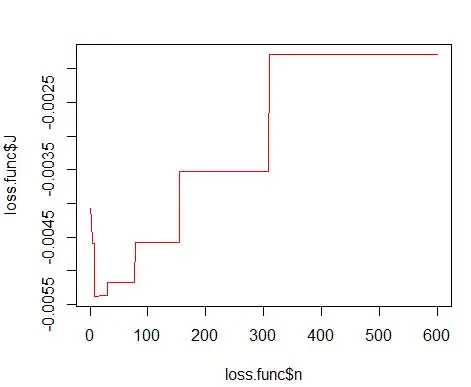
Следовательно, ниже рисунка 4 приведена оценка плотности, которая уравновешивает значения плотности и степень детализации (с оптимальным компромиссом смещения и дисперсии).
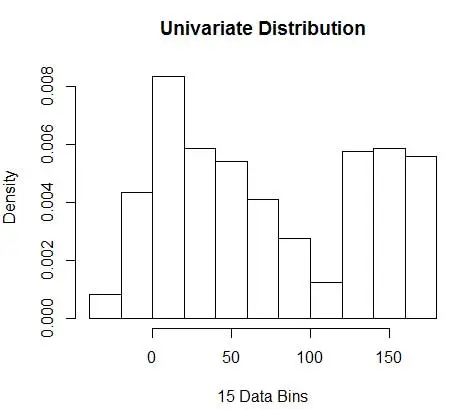
Если вы чувствуете небольшое беспокойство в этот момент, тогда я с вами. Несмотря на то, что количество бинов математически оптимально, это кажется слишком грубой оценкой. Нет интуитивного ощущения, почему мы проделали лучшую работу. И не забывайте о других проблемах, связанных с начальной позицией, прерывистой оценкой и проклятием размерности. Не отчаивайтесь, есть лучший способ. В следующем посте мы поговорим об оценке плотности с использованием ядер.