
Entity SEO: полное руководство
Опубликовано: 2023-04-06Эта статья была написана в соавторстве с Эндрю Энсли .
Вещи, а не струны. Если вы не слышали об этом раньше, то это из известного поста в блоге Google, в котором анонсировался Knowledge Graph.
До 11-й годовщины объявления остается всего месяц, но многие все еще пытаются понять, что на самом деле означает «вещи, а не строки» для SEO.
Цитата — это попытка показать, что Google понимает вещи и больше не является простым алгоритмом обнаружения ключевых слов.
Можно утверждать, что в мае 2012 года родилась компания SEO. Машинное обучение Google, которому помогают полуструктурированные и структурированные базы знаний, может понять значение ключевого слова.
Двусмысленная природа языка, наконец, нашла долгосрочное решение.
Итак, если сущности были важны для Google более десяти лет, почему оптимизаторы до сих пор не понимают сущности?
Хороший вопрос. Я вижу четыре причины:
- Сущностное SEO как термин не использовался достаточно широко, чтобы SEO-специалисты привыкли к его определению и, следовательно, включили его в свой словарь.
- Оптимизация сущностей во многом совпадает со старыми методами оптимизации, ориентированными на ключевые слова. В результате сущности объединяются с ключевыми словами. Вдобавок к этому было неясно, как сущности играют роль в SEO, а слово «сущности» иногда взаимозаменяемо с «темами», когда Google говорит на эту тему.
- Понимание сущностей — скучная задача. Если вам нужны глубокие знания о сущностях, вам нужно прочитать некоторые патенты Google и знать основы машинного обучения. Entity SEO — это гораздо более научный подход к SEO, а наука не для всех.
- Хотя YouTube оказал огромное влияние на распространение знаний, он упростил процесс обучения по многим предметам. Создатели, добившиеся наибольшего успеха на платформе, исторически выбирали легкий путь при обучении своей аудитории. В результате создатели контента до недавнего времени не уделяли сущностям много времени. Из-за этого вам нужно узнать о сущностях от исследователей НЛП, а затем применить эти знания в SEO. Патенты и исследовательские работы имеют ключевое значение. Это еще раз подтверждает первый пункт выше.
Эта статья — решение всех четырех проблем, которые мешали SEO-специалистам полностью освоить основанный на сущностях подход к SEO.
Прочитав это, вы узнаете:
- Что такое сущность и почему она важна.
- История семантического поиска.
- Как идентифицировать и использовать сущности в поисковой выдаче.
- Как использовать сущности для ранжирования веб-контента.
Почему сущности важны?
Entity SEO — это будущее того, куда движутся поисковые системы в отношении выбора контента для ранжирования и определения его значения.
Объедините это с доверием, основанным на знаниях, и я верю, что юридическое SEO станет будущим того, как SEO делается в ближайшие два года.
Примеры сущностей
Так как же распознать сущность?
В поисковой выдаче есть несколько примеров сущностей, которые вы, вероятно, видели.
Наиболее распространенные типы сущностей связаны с местоположениями, людьми или предприятиями.
Возможно, лучшим примером сущностей в поисковой выдаче являются кластеры намерений. Чем больше тема понята, тем больше появляется этих поисковых функций.
Интересно, что одна SEO-кампания может изменить лицо поисковой выдачи, если вы знаете, как проводить SEO-кампании, ориентированные на сущности.
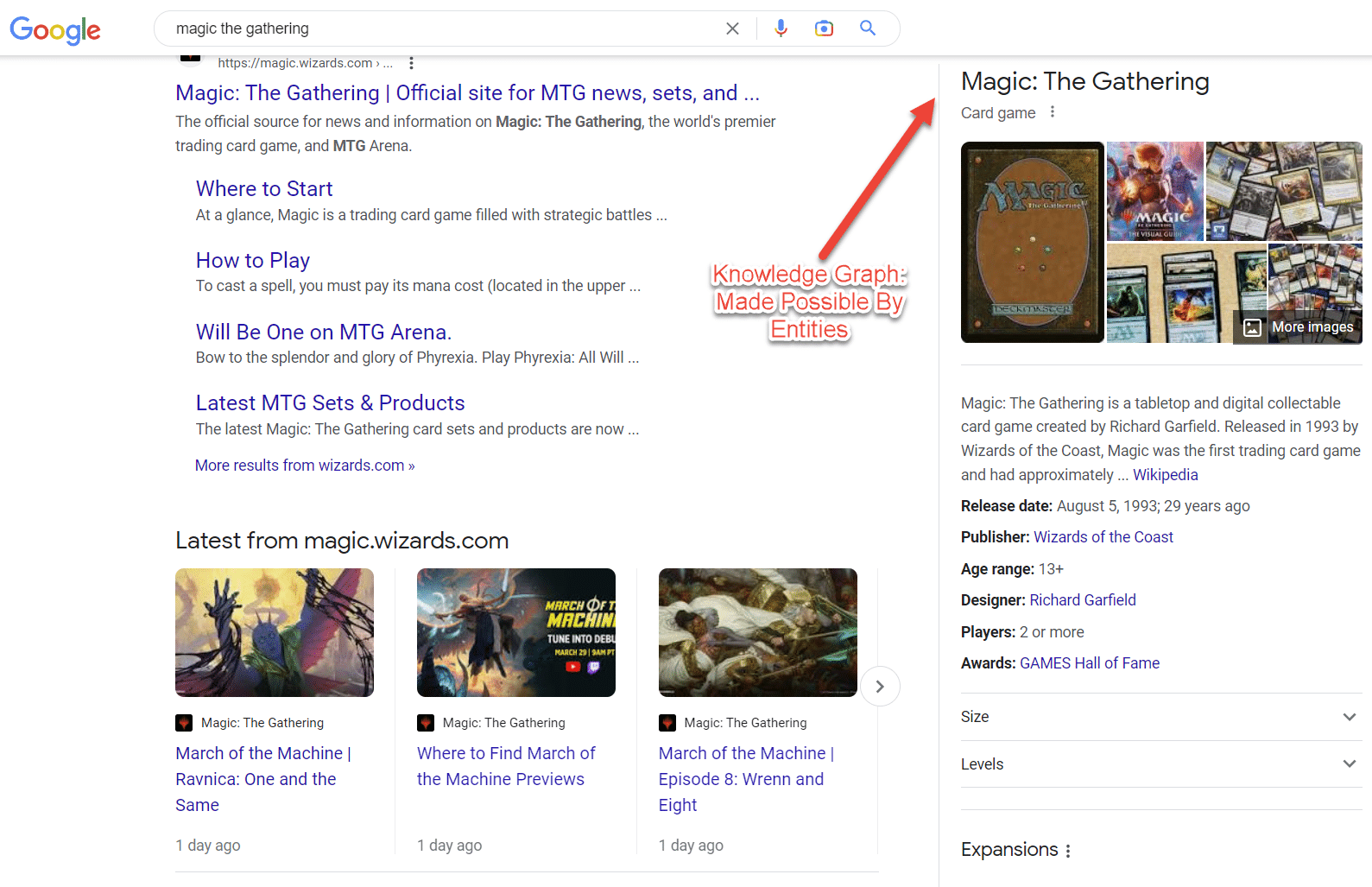
Записи в Википедии — еще один пример сущностей. Википедия предоставляет отличный пример информации, связанной с сущностями.
Как видно из верхнего левого угла, сущность имеет всевозможные атрибуты, связанные с «рыбой», начиная от ее анатомии и заканчивая ее важностью для человека.
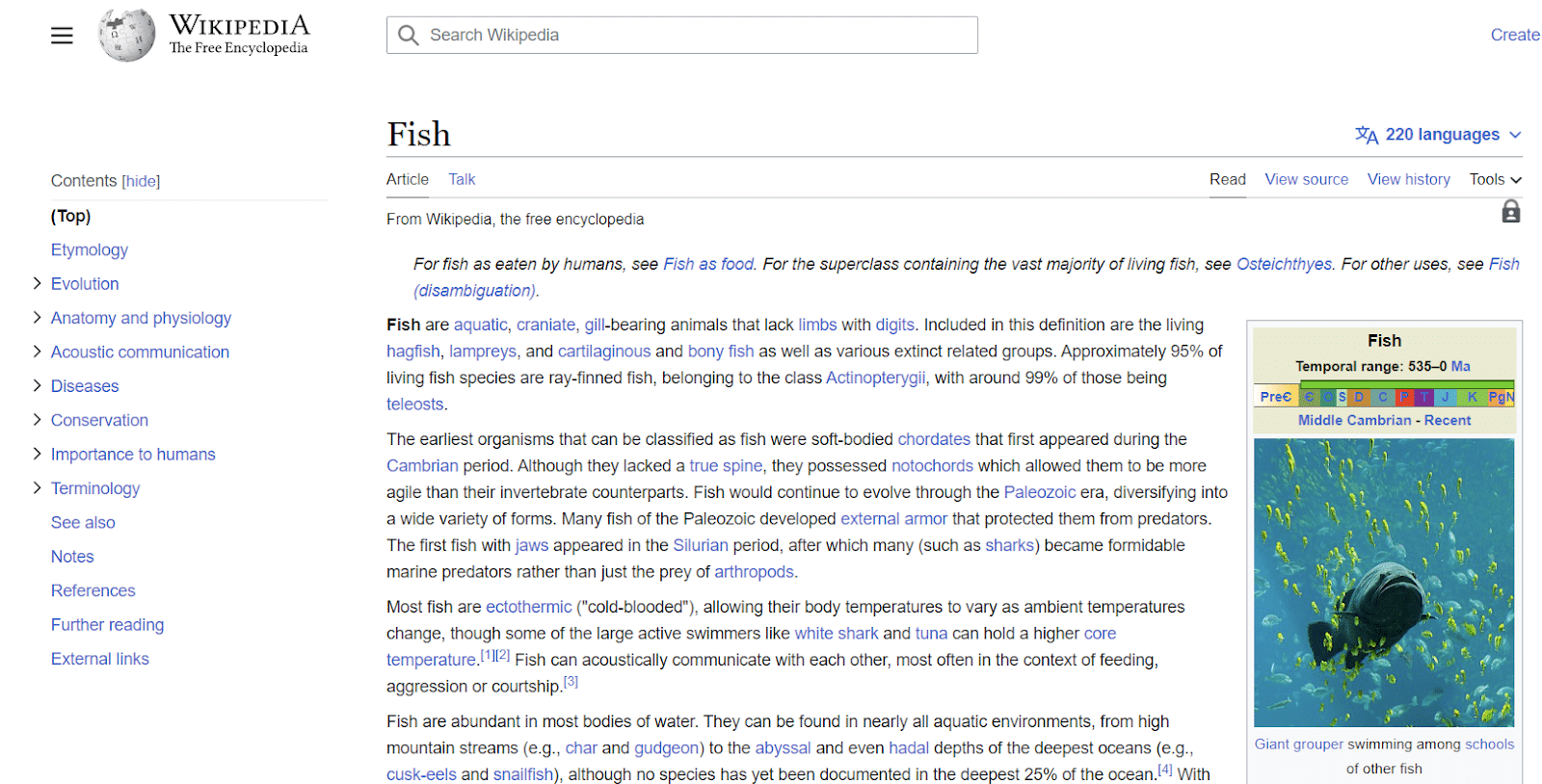
Хотя Википедия содержит множество точек данных по теме, она ни в коем случае не является исчерпывающей.
Что такое сущность?
Сущность - это однозначно идентифицируемый объект или вещь, характеризуемая своим именем (именами), типом (ами), атрибутами и отношениями с другими сущностями. Сущность считается существующей только тогда, когда она существует в каталоге сущностей.
Каталоги сущностей присваивают каждой сущности уникальный идентификатор. В моем агентстве есть алгоритмические решения, в которых используется уникальный идентификатор, связанный с каждым объектом (включая услуги, продукты и бренды).
Если слово или фраза не находится в существующем каталоге, это не означает, что слово или фраза не является сущностью, но обычно вы можете узнать, является ли что-то сущностью, по ее наличию в каталоге.
Важно отметить, что Википедия не является решающим фактором в отношении того, является ли что-либо сущностью, но компания наиболее известна своей базой данных сущностей.
Любой каталог может использоваться, когда речь идет о сущностях. Как правило, объектом является человек, место или вещь, но также могут быть включены идеи и концепции.
Вот некоторые примеры каталогов сущностей:
- Википедия
- Викиданные
- DBpedia
- Бесплатная база
- Яго

Сущности помогают преодолеть разрыв между мирами неструктурированных и структурированных данных.
Их можно использовать для семантического обогащения неструктурированного текста, а текстовые источники можно использовать для заполнения структурированных баз знаний.
Распознавание упоминаний сущностей в тексте и связывание этих упоминаний с соответствующими записями в базе знаний известно как задача связывания сущностей.
Сущности позволяют лучше понять значение текста как для людей, так и для машин.
В то время как люди могут относительно легко разрешить двусмысленность сущностей в зависимости от контекста, в котором они упоминаются, это создает много трудностей и проблем для машин.
Запись в базе знаний об объекте суммирует то, что мы знаем об этом объекте.
Поскольку мир постоянно меняется, появляются новые факты. Идти в ногу с этими изменениями требует постоянных усилий со стороны редакторов и контент-менеджеров. Это сложная задача в масштабе.
Путем анализа содержания документов, в которых упоминаются сущности, может поддерживаться или даже полностью автоматизироваться процесс поиска новых фактов или фактов, нуждающихся в обновлении.
Ученые называют это проблемой заполнения базы знаний, поэтому важно связывание сущностей.
Сущности облегчают семантическое понимание потребности пользователя в информации, выраженной запросом с ключевым словом, и содержания документа. Таким образом, сущности могут использоваться для улучшения представления запросов и/или документов.
В исследовательской работе с расширенными именованными сущностями автор определяет около 160 типов сущностей. Вот два из семи скриншотов из списка.


Определенные категории сущностей определить легче, но важно помнить, что понятия и идеи являются сущностями. Google очень сложно масштабировать эти две категории самостоятельно.
Вы не можете научить Google одной страницей, когда работаете с расплывчатыми понятиями. Понимание сущностей требует множества статей и множества ссылок, поддерживаемых с течением времени.
История Google с сущностями
16 июля 2010 г. компания Google приобрела Freebase. Эта покупка была первым важным шагом, который привел к нынешней системе поиска сущностей.

Вложив средства в Freebase, Google понял, что у Wikidata есть лучшее решение. Затем Google работал над объединением Freebase с Викиданными, что оказалось намного сложнее, чем ожидалось.
Пятеро ученых Google написали статью под названием «От Freebase к Викиданным: Великая миграция». Основные выводы включают.
«Freebase построена на понятиях объектов, фактов, типов и свойств. Каждый объект Freebase имеет стабильный идентификатор, который называется «mid» (от Machine ID)».
«Модель данных Викиданных опирается на понятия элемента и утверждения. Элемент представляет сущность, имеет стабильный идентификатор, называемый «qid», и может иметь метки, описания и псевдонимы на нескольких языках; дальнейшие заявления и ссылки на страницы о сущности в других проектах Викимедиа, прежде всего в Википедии. В отличие от Freebase, утверждения Викиданных не нацелены на кодирование истинных фактов, а утверждения из разных источников, которые также могут противоречить друг другу…»
Сущности определены в этих базах знаний, но Google все равно пришлось создавать свои знания сущностей для неструктурированных данных (т. е. для блогов).
Google сотрудничал с Bing и Yahoo и создал Schema.org для выполнения этой задачи.
Google предоставляет инструкции по схеме, чтобы у менеджеров веб-сайтов были инструменты, помогающие Google понимать контент. Помните, Google хочет сосредоточиться на вещах, а не на строках.
По словам Google:
«Вы можете помочь нам, предоставив Google явные подсказки о значении страницы, добавив на страницу структурированные данные. Структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации содержимого страницы; например, на странице рецептов укажите ингредиенты, время и температуру приготовления, калорийность и т. д.».
Google продолжает, говоря:
«Вы должны указать все необходимые свойства, чтобы объект мог отображаться в поиске Google с расширенным отображением. В целом, определение дополнительных рекомендуемых функций может повысить вероятность того, что ваша информация будет отображаться в результатах поиска с улучшенным отображением. Однако более важно предоставить меньшее количество, но полных и точных рекомендуемых свойств, а не пытаться предоставить все возможные рекомендуемые свойства с менее полными, плохо сформированными или неточными данными».
О схеме можно было бы сказать больше, но достаточно сказать, что схема — это невероятный инструмент для SEO-специалистов, стремящихся сделать содержимое страницы понятным для поисковых систем.
Последняя часть головоломки исходит из объявления в блоге Google под названием «Улучшение поиска в течение следующих 20 лет».
Актуальность и качество документа — основные идеи, лежащие в основе этого объявления. Первый метод, который Google использовал для определения содержания страницы, был полностью сосредоточен на ключевых словах.
Затем Google добавил тематические слои для поиска. Этот уровень стал возможен благодаря графам знаний и систематическому сбору и структурированию данных в Интернете.
Это подводит нас к текущей системе поиска. Google перешел от 570 миллионов сущностей и 18 миллиардов фактов к 800 миллиардам фактов и 8 миллиардам сущностей менее чем за 10 лет. По мере роста этого числа поиск сущностей улучшается.
Чем модель сущностей лучше предыдущих моделей поиска?
Традиционные модели информационного поиска на основе ключевых слов (IR) имеют неотъемлемое ограничение, заключающееся в невозможности извлечения (релевантных) документов, которые не имеют явных совпадений терминов с запросом.
Если вы используете ctrl + f для поиска текста на странице, вы используете что-то похожее на традиционную модель поиска информации на основе ключевых слов.
Каждый день в сети публикуется безумное количество данных.
Для Google просто невозможно понять значение каждого слова, каждого абзаца, каждой статьи и каждого веб-сайта.
Вместо этого сущности предоставляют структуру, с помощью которой Google может минимизировать вычислительную нагрузку, улучшая понимание.
«Методы поиска на основе понятий пытаются решить эту проблему, полагаясь на вспомогательные структуры для получения семантических представлений запросов и документов в пространстве понятий более высокого уровня. К таким структурам относятся управляемые словари (словари и тезаурусы), онтологии и объекты из хранилища знаний».
– Сущностно-ориентированный поиск , Глава 8.3
Кристиан Балог, написавший исчерпывающую книгу о сущностях, выделяет три возможных решения традиционной модели поиска информации.
- На основе расширения : использует сущности в качестве источника для расширения запроса с помощью различных терминов.
- На основе проекции : соответствие между запросом и документом понимается путем их проецирования на скрытое пространство сущностей.
- На основе сущностей : явные семантические представления запросов и документов получаются в пространстве сущностей для расширения представлений на основе терминов.
Цель этих трех подходов состоит в том, чтобы получить более полное представление информации, необходимой пользователю, путем идентификации сущностей, тесно связанных с запросом.
Затем Балог определяет шесть алгоритмов, связанных с проекционными методами отображения объектов (проекционные методы относятся к преобразованию объектов в трехмерное пространство и измерению векторов с использованием геометрии).
- Явный семантический анализ (ESA) : семантика данного слова описывается вектором, сохраняющим сильные стороны ассоциации слова с понятиями, полученными из Википедии.
- Модель скрытого пространства сущностей (LES) : основана на генеративной вероятностной структуре. Оценка поиска документа считается линейной комбинацией оценки пространства скрытых сущностей и оценки вероятности исходного запроса.
- EsdRank: EsdRank предназначен для ранжирования документов с использованием комбинации функций запрос-сущность и сущность-документ. Они соответствуют понятиям компонентов проекции запроса и проекции документа LES, соответственно, ранее. Используя дискриминативную структуру обучения, также можно легко включить дополнительные сигналы, такие как популярность объекта или качество документа.
- Явное семантическое ранжирование (ESR): модель явного семантического ранжирования включает информацию об отношениях из графа знаний, чтобы обеспечить «мягкое сопоставление» в пространстве сущностей.
- Структура дуэта слов и сущностей: она включает межпространственные взаимодействия между представлениями на основе терминов и сущностей, что приводит к четырем типам совпадений: термины запроса к терминам документа, объекты запроса к терминам документа, термины запроса к объектам документа и объекты запроса. для документирования объектов.
- Модель ранжирования на основе внимания : Это, безусловно, самое сложное для описания.
Вот что пишет Балог:
«Всего разработано четыре функции внимания, которые извлекаются для каждой сущности запроса. Функции неоднозначности объекта предназначены для характеристики риска, связанного с аннотацией объекта. К ним относятся: (1) энтропия вероятности того, что поверхностная форма связана с различными объектами (например, в Википедии), (2) является ли аннотируемый объект наиболее популярным смыслом поверхностной формы (т. е. имеет наивысшую общность). оценка и (3) разница в оценках общности между наиболее вероятным и вторым наиболее вероятным кандидатом для данной формы поверхности.Четвертый признак - близость, которая определяется как косинусное сходство между сущностью запроса и запросом в пространстве вложения . В частности, совместное встраивание терминов-сущностей обучается с использованием модели скип-граммы в корпусе, где упоминания сущностей заменяются соответствующими идентификаторами сущностей. Вложение запроса принимается за центр тяжести встраивания терминов запроса».

На данный момент важно иметь поверхностное представление об этих шести алгоритмах, ориентированных на объекты.
Главный вывод заключается в том, что существуют два подхода: проецирование документов на слой скрытых объектов и явные аннотации объектов документов.
Три типа структур данных
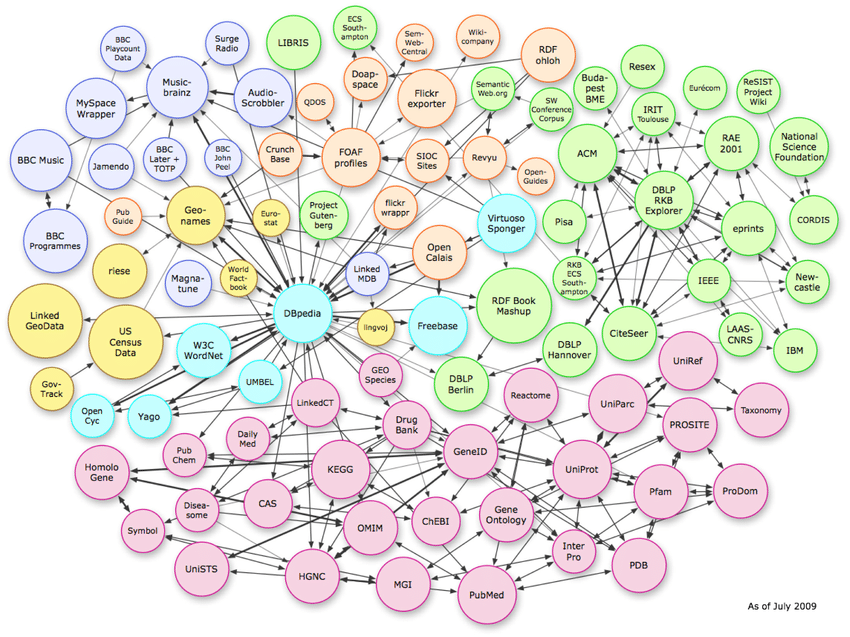
На изображении выше показаны сложные отношения, существующие в векторном пространстве. Хотя в примере показаны соединения графа знаний, этот же шаблон можно воспроизвести на уровне постраничной схемы.
Чтобы понимать сущности, важно знать три типа структур данных, которые используют алгоритмы.
- При использовании неструктурированных описаний сущностей ссылки на другие сущности должны распознаваться и устраняться неоднозначность. Направленные ребра (гиперссылки) добавляются от каждой сущности ко всем другим сущностям, упомянутым в ее описании.
- В полуструктурированной среде (например, в Википедии) ссылки на другие объекты могут быть предоставлены явно.
- При работе со структурированными данными тройки RDF определяют граф (т. е. граф знаний). В частности, ресурсы субъекта и объекта (URI) являются узлами, а предикаты — ребрами.
Проблема с полуструктурированным и отвлекающим контекстом для оценки IR заключается в том, что если документ не настроен для одной темы, оценка IR может быть разбавлена двумя разными контекстами, что приведет к потере относительного ранга для другого текстового документа.
Разбавление баллов IR связано с плохо структурированными лексическими отношениями и близостью плохих слов.
Соответствующие слова, которые дополняют друг друга, должны использоваться близко к абзацу или разделу документа, чтобы более четко обозначить контекст и повысить оценку IR.
Использование атрибутов и взаимосвязей сущностей дает относительные улучшения в диапазоне 5–20 %. Использование информации о типах сущностей еще более полезно: относительные улучшения варьируются от 25% до более чем 100%.
Аннотирование документов с помощью сущностей может структурировать неструктурированные документы, что может помочь заполнить базы знаний новой информацией о сущностях.
Использование Википедии в качестве основы SEO вашей организации
Структура страниц Википедии
- Титул (И.)
- Свинцовая секция (II.)
- Ссылки значений неоднозначности (II.a)
- Информационное окно (II.b)
- Вводный текст (II.c)
- Оглавление (III.)
- Содержимое тела (IV.)
- Приложения и донная часть (V.)
- Ссылки и примечания (Ва)
- Внешние ссылки (Вб)
- Категории (ВК)
Большинство статей Википедии включают вводный текст, «лид», краткое изложение статьи — обычно не более четырех абзацев. Это должно быть написано таким образом, чтобы вызвать интерес к статье.
Первое предложение и вступительный абзац имеют особое значение. Первое предложение «можно рассматривать как определение сущности, описанной в статье». Первый абзац предлагает более развернутое определение без излишних подробностей.
Ценность ссылок выходит за рамки навигационных целей; они фиксируют семантические отношения между статьями. Кроме того, якорные тексты являются богатым источником вариантов имен объектов. Ссылки на Википедию могут использоваться, среди прочего, для идентификации и устранения неоднозначности упоминаний объекта в тексте.
- Обобщите ключевые факты об объекте (информационное окно).
- Краткое введение.
- Внутренние ссылки. Ключевое правило, данное редакторам, состоит в том, чтобы ссылаться только на первое появление сущности или концепции.
- Включите все популярные синонимы для объекта.
- Обозначение страницы категории.
- Шаблон навигации.
- Использованная литература.
- Специальные инструменты парсинга для понимания вики-страниц.
- Несколько типов носителей.
Как оптимизировать для сущностей
Ниже приведены основные соображения по оптимизации сущностей для поиска:
- Включение семантически связанных слов на странице.
- Частота слов и фраз на странице.
- Организация понятий на странице.
- Включая неструктурированные данные, частично структурированные данные и структурированные данные на странице.
- Пары субъект-предикат-объект (SPO).
- Веб-документы на сайте, функционирующие как страницы книги.
- Организация веб-документов на веб-сайте.
- Включите понятия в веб-документ, которые являются известными характеристиками сущностей.
Важное примечание. Когда акцент делается на отношениях между сущностями, базу знаний часто называют графом знаний.
Поскольку намерения анализируются в сочетании с журналами поиска пользователей и другими фрагментами контекста, одна и та же поисковая фраза от человека 1 может привести к другому результату от человека 2. У человека может быть другое намерение с одним и тем же запросом.
Если ваша страница охватывает оба типа намерений, то она лучше подходит для веб-рейтинга. Вы можете использовать структуру баз знаний, чтобы направлять свои шаблоны запросов-намерений (как упоминалось в предыдущем разделе).
Люди также спрашивают, Люди ищут и Автозаполнение семантически связаны с отправленным запросом и либо углубляются в текущее направление поиска, либо перемещаются к другому аспекту задачи поиска.
Мы это знаем, так как же мы можем оптимизировать для этого?
Ваши документы должны содержать как можно больше вариантов целей поиска. Ваш веб-сайт должен содержать все варианты поисковых запросов для вашего кластера. Кластеризация основана на трех типах подобия:
- Лексическое сходство.
- Семантическое сходство.
- Нажмите сходство.
Охват темы
Что это такое –> Список атрибутов –> Раздел, посвященный каждому атрибуту –> Каждый раздел ссылается на статью, полностью посвященную этой теме –> Необходимо указать аудиторию и указать определения для подраздела –> Что следует учитывать ? -> Каковы преимущества? -> Преимущества модификатора -> Что такое ___ -> Что он делает? –> Как это получить –> Как это сделать –> Кто может это сделать –> Ссылка на все категории

Google предлагает инструмент, который дает оценку заметности (аналогично тому, как мы используем слово «сила» или «уверенность»), который говорит вам, как Google видит контент.

Приведенный выше пример взят из статьи Search Engine Land о сущностях за 2018 год.
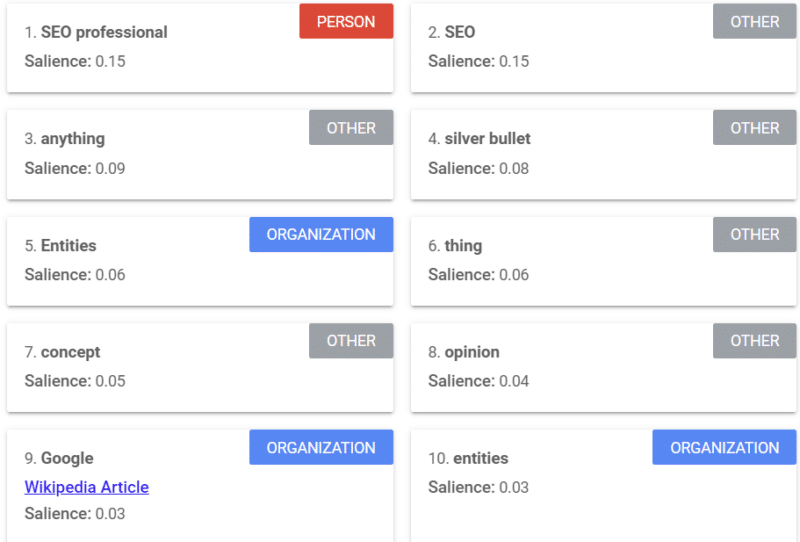
Вы можете увидеть человека, другого и организации из примера. Этот инструмент представляет собой API естественного языка Google Cloud.
Каждое слово, предложение и абзац имеют значение, когда речь идет о сущности. То, как вы организуете свои мысли, может изменить понимание Google вашего контента.
Вы можете включить ключевое слово о SEO, но понимает ли Google это ключевое слово так, как вы хотите?
Попробуйте поместить абзац или два в инструмент и реорганизовать и изменить пример, чтобы увидеть, как он увеличивает или уменьшает заметность.
Это упражнение, называемое «устранение неоднозначности», невероятно важно для сущностей. Язык неоднозначен, поэтому мы должны сделать наши слова менее двусмысленными для Google.
Современные подходы к устранению неоднозначности рассматривают три типа доказательств:
Предварительная важность сущностей и упоминаний.
Контекстное сходство между текстом, окружающим упоминание, и сущностью-кандидатом, а также согласованность всех решений, связанных с сущностью, в документе.
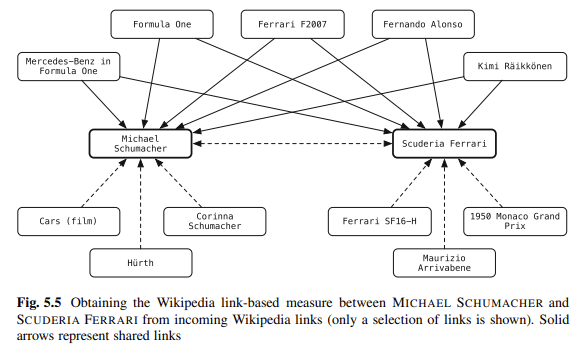
Схема — один из моих любимых способов устранения неоднозначности контента. Вы связываете объекты в своем блоге с хранилищами знаний. Балог говорит:
«Связывание сущностей в неструктурированном тексте со структурированным хранилищем знаний может значительно расширить возможности пользователей в их действиях по потреблению информации».
Например, читатели документа могут получить контекстную или справочную информацию одним щелчком мыши, а также получить легкий доступ к связанным объектам.
Аннотации сущностей также можно использовать в последующей обработке для повышения производительности поиска или облегчения взаимодействия пользователя с результатами поиска.
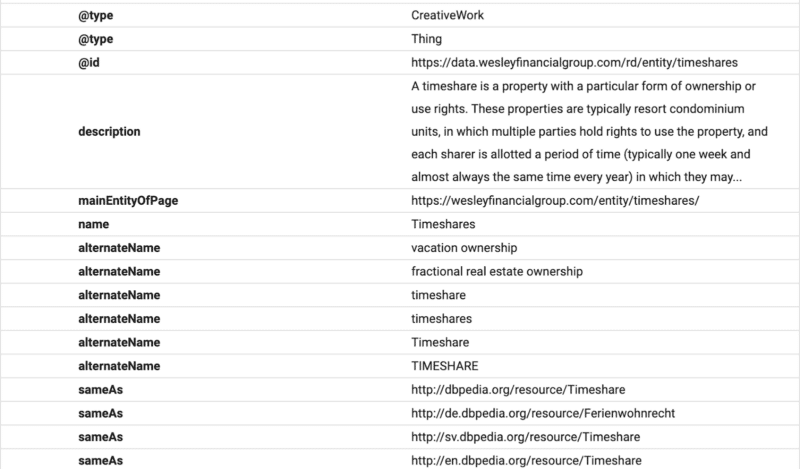
Здесь вы можете видеть, что содержимое часто задаваемых вопросов структурировано для Google с использованием схемы часто задаваемых вопросов.
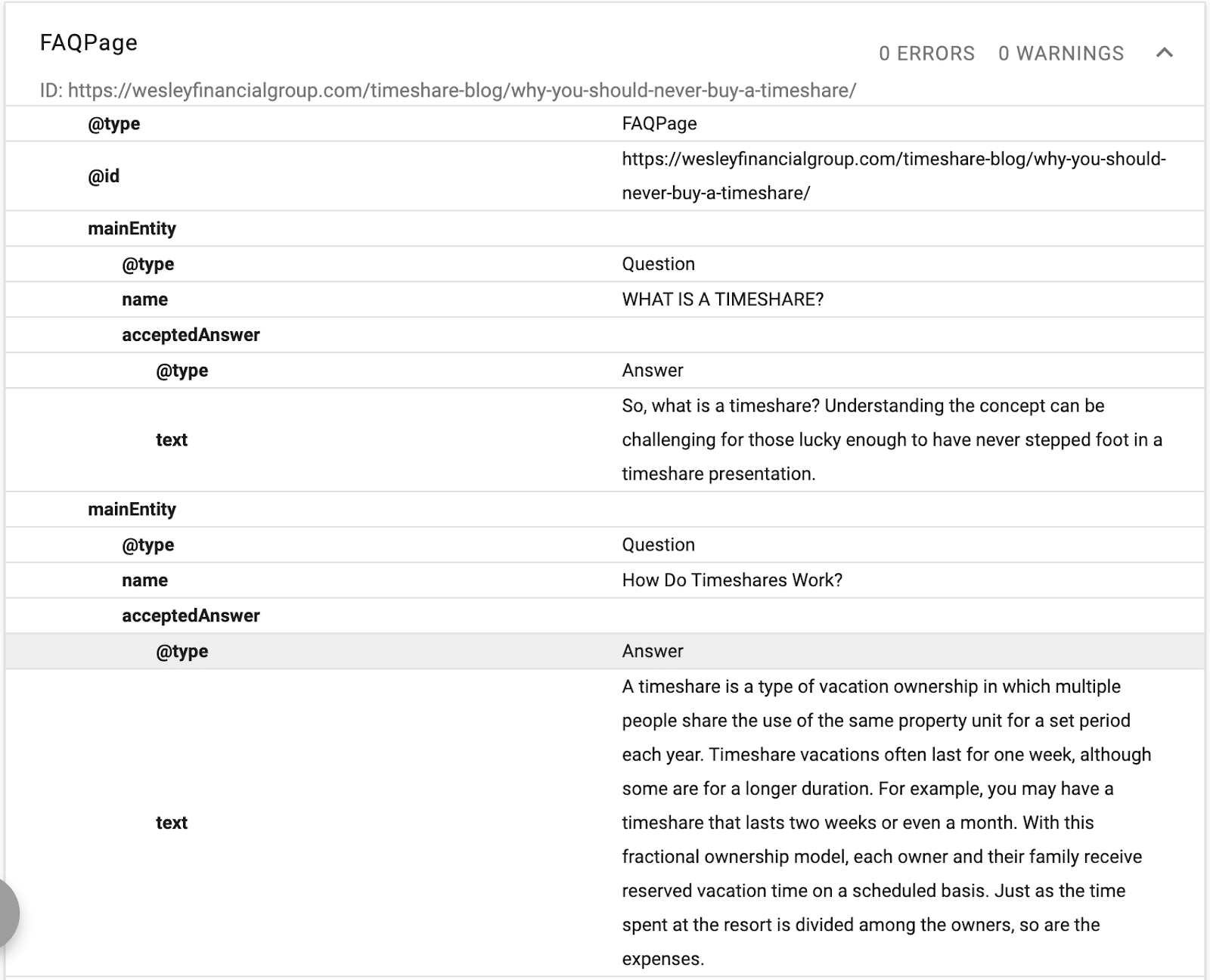
В этом примере вы можете увидеть схему, предоставляющую описание текста, идентификатор и объявление основного объекта страницы.
(Помните, Google хочет понять иерархию контента, поэтому H1–H6 важны.)
Вы увидите альтернативные имена и то же самое, что и объявления. Теперь, когда Google читает контент, он будет знать, какую структурированную базу данных связать с текстом, и у него будут синонимы и альтернативные версии слова, связанные с сущностью.
Когда вы оптимизируете с помощью схемы, вы оптимизируете NER (распознавание именованных сущностей), также известную как идентификация сущностей, извлечение сущностей и разбивка сущностей.
Идея состоит в том, чтобы задействовать Устранение неоднозначности именованных объектов > Викификация > Связывание сущностей.
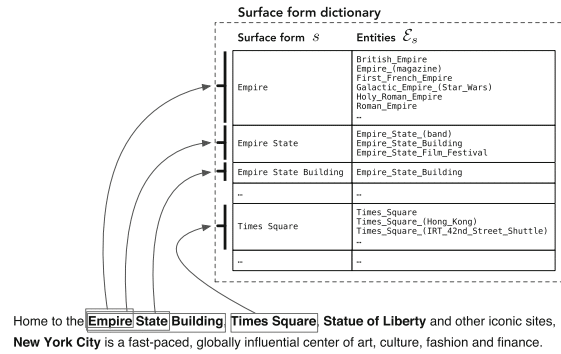
«Появление Википедии способствовало крупномасштабному распознаванию и устранению неоднозначности сущностей, предоставляя всеобъемлющий каталог сущностей вместе с другими бесценными ресурсами (в частности, гиперссылками, категориями, страницами перенаправления и устранения неоднозначности».
– Сущностно-ориентированный поиск
Как выйти за рамки предложений инструментов SEO
Большинство SEO-специалистов используют какой-либо инструмент на странице для оптимизации своего контента. Каждый инструмент ограничен в своей способности определять возможности уникального контента и предложения по глубине контента.
По большей части инструменты на странице просто собирают лучшие результаты поисковой выдачи и создают среднее значение, которое вы можете повторить.
SEO-специалисты должны помнить, что Google не ищет ту же перефразированную информацию. Вы можете копировать то, что делают другие, но уникальная информация — это ключ к тому, чтобы стать стартовым/авторитетным сайтом.
Вот упрощенное описание того, как Google обрабатывает новый контент:
Как только найден документ, в котором упоминается данный объект, этот документ может быть проверен, чтобы, возможно, обнаружить новые факты, с помощью которых запись в базе знаний этого объекта может быть обновлена.
Балог пишет:
«Мы хотим помочь редакторам оставаться в курсе изменений, автоматически определяя контент (новостные статьи, сообщения в блогах и т. д.), который может подразумевать изменения в записях базы знаний определенного набора объектов, представляющих интерес (т. е. объектов, которыми данный редактор является ответственный за)."
Любой, кто улучшает базы знаний, распознавание сущностей и возможность сканирования информации, получит любовь Google.
Изменения, внесенные в хранилище знаний, можно отследить до документа как исходного источника.
Если вы предоставляете контент, который охватывает тему, и вы добавляете уровень глубины, который является редким или новым, Google может определить, добавил ли ваш документ эту уникальную информацию.
В конце концов, эта новая информация, сохраняемая в течение определенного периода времени, может привести к тому, что ваш сайт станет авторитетным.
Это авторитетность, основанная не на рейтинге домена, а на актуальном освещении, которое я считаю гораздо более ценным.
Сущностный подход к SEO не ограничивает вас таргетингом на ключевые слова с объемом поиска.
Все, что вам нужно сделать, это подтвердить главный термин (например, «нахлыстовые удочки»), а затем вы можете сосредоточиться на таргетинге на варианты намерений поиска, основанные на старом добром человеческом мышлении.
Начнем с Википедии. На примере нахлыстовой рыбалки мы видим, что на рыболовном веб-сайте должны быть освещены как минимум следующие понятия:
- Виды рыб, история, происхождение, развитие, технологические усовершенствования, расширение, методы ловли нахлыстом, заброс, ловля форели нахлыстом, техника ловли нахлыстом, ловля форели в холодной воде, ловля форели на сухую мушку, ловля форели на нимфы, стоячая вода ловля форели, ловля форели, выпуск форели, ловля нахлыстом в морской воде, снасти, искусственные мухи и узлы.
Вышеупомянутые темы взяты со страницы Википедии о нахлыстовой рыбалке. Хотя на этой странице представлен отличный обзор тем, мне нравится добавлять дополнительные идеи, которые приходят из семантически связанных тем.
К теме «рыбы» мы можем добавить несколько дополнительных тем, включая этимологию, эволюцию, анатомию и физиологию, общение рыб, болезни рыб, сохранение и важность для человека.
Кто-нибудь связывал анатомию форели с эффективностью определенных методов ловли?
Охватывал ли единый рыболовный веб-сайт все виды рыб, при этом связывая типы методов ловли, удочки и наживку для каждой рыбы?
К настоящему времени вы должны увидеть, как может расти расширение темы. Учитывайте это при планировании контент-кампании.
Только не перефразируй. Добавить значение. Быть уникальный. Используйте алгоритмы, упомянутые в этой статье, в качестве руководства.
Заключение
Эта статья является частью серии статей, посвященных сущностям. В следующей статье я подробно расскажу об усилиях по оптимизации сущностей и некоторых инструментах, ориентированных на сущности, на рынке.
Я хочу закончить эту статью, поблагодарив двух человек, которые объяснили мне многие из этих концепций.
Билл Славски из SEO by the Sea и Корай Тагберт из Holistic SEO. Хотя Славского больше нет с нами, его вклад продолжает оказывать влияние на индустрию SEO.
Я в значительной степени полагаюсь на следующие источники для содержания статьи, так как эти источники являются лучшими ресурсами, которые существуют по теме:
- Расширенная иерархия именованных сущностей Сатоши Кетине, Киёси Судо и Тикаши Нобата
- Поиск, ориентированный на объекты, Кристиан Балог , Серия информационного поиска (INRE, том 39)
- Перезапись запросов с обнаружением сущностей , патент Google
- Уточнение поисковых запросов , патент Google
- Связывание объекта с поисковым запросом , патент Google
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.