
Как Apache Spark может окрылить аналитику авиакомпаний?
Опубликовано: 2015-10-30Мировая индустрия авиаперевозок продолжает быстро расти, но стабильной и стабильной прибыльности пока не видно. По данным Международной ассоциации воздушного транспорта (IATA), за последнее десятилетие доходы отрасли удвоились: с 369 млрд долларов США в 2005 году до ожидаемых 727 млрд долларов США в 2015 году.

В секторе коммерческой авиации каждый игрок в цепочке создания стоимости — аэропорты, производители самолетов, производители реактивных двигателей, турагенты и сервисные компании — получают приличную прибыль.
Все эти игроки по отдельности генерируют чрезвычайно большие объемы данных из-за более высокой текучести транзакций рейсов. Ключевым моментом здесь является выявление и учет спроса, который предоставляет авиакомпаниям гораздо больше возможностей для дифференциации. Таким образом, авиационная промышленность может использовать анализ больших данных для увеличения продаж и увеличения прибыли.
Большие данные — это термин для сбора наборов данных, настолько больших и сложных, что их вычисление не может быть выполнено с помощью традиционных систем обработки данных или имеющихся инструментов СУБД.
Apache Spark — это среда распределенных кластерных вычислений с открытым исходным кодом, специально разработанная для интерактивных запросов и итерационных алгоритмов.
Абстракция Spark DataFrame — это табличный объект данных, аналогичный собственному фрейму данных R или пакету pandas для Python, но хранящийся в среде кластера.
Согласно последнему опросу Fortunes, Apache Spark является самой популярной технологией 2015 года.
Крупнейший поставщик Hadoop Cloudera также прощается с Hadoop MapReduce и приветствует Spark.
Что действительно дает Spark преимущество над Hadoop, так это скорость . Spark выполняет большинство своих операций в памяти , копируя их из распределенного физического хранилища в гораздо более быструю логическую оперативную память. Это сокращает время, затрачиваемое на запись и чтение на медленные, неуклюжие механические жесткие диски и с них, которые необходимо выполнять в системе Hadoops MapReduce.
Кроме того, Spark включает в себя инструменты (обработка в реальном времени, машинное обучение и интерактивный SQL), которые хорошо разработаны для решения бизнес-задач, таких как анализ данных в реальном времени путем объединения исторических данных с подключенных устройств, также известных как Интернет вещей .
Сегодня давайте проанализируем примеры данных об аэропортах с помощью Apache Spark .
В предыдущем блоге мы увидели, как обрабатывать структурированные и частично структурированные данные в Spark с помощью нового API Dataframes, а также рассказали, как эффективно обрабатывать данные JSON.
В этом блоге мы поймем, как запрашивать данные в DataFrames с помощью SQL , а также сохранять вывод в файловую систему в формате CSV.
Использование библиотеки синтаксического анализа Databricks CSV
Для этого я собираюсь использовать библиотеку разбора CSV, предоставленную Databricks, компанией, основанной создателями Apache Spark и которая в настоящее время занимается разработкой и распространением Spark.
Сообщество Spark состоит примерно из 600 участников, что делает его самым активным проектом во всем Apache Software Foundation, главном руководящем органе для программного обеспечения с открытым исходным кодом, с точки зрения количества участников.
Библиотека Spark-csv помогает нам анализировать и запрашивать данные csv в искре. Мы можем использовать эту библиотеку как для чтения, так и для записи данных csv в любую файловую систему, совместимую с Hadoop, и из нее.
Загрузка данных в Spark DataFrames
Давайте загрузим наши входные файлы в Spark DataFrames, используя библиотеку синтаксического анализа spark-csv от Databricks.
Вы можете использовать эту библиотеку в оболочке Spark, указав –packages com.databricks: spark-csv_2.10:1.0.3
При запуске оболочки, как показано ниже:
$ bin/spark-shell – пакеты com.databricks:spark-csv_2.10:1.0.3
Помните, что вы должны быть подключены к Интернету, потому что пакет spark-csv будет автоматически загружен, когда вы дадите эту команду. Я использую искру версии 1.4.0
Давайте создадим sqlContext с уже созданным объектом SparkContext(sc)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Теперь давайте загрузим наши данные csv из файла airports.csv (csv аэропорта github), схема которого приведена ниже.
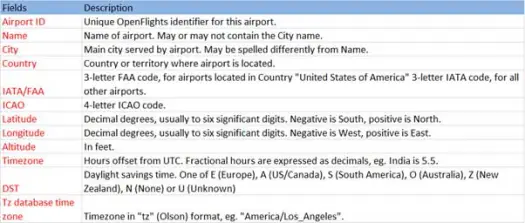
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Операция загрузки проанализирует файл *.csv с помощью библиотеки искры-csv Databricks и вернет кадр данных с именами столбцов, такими же, как в первой строке заголовка в файле.
Ниже приведены параметры, передаваемые методу загрузки.
- Источник : «com.databricks.spark.csv» сообщает искре, что мы хотим загрузить файл csv.
- Опции:
- path – путь к файлу, где он находится.
- Заголовок : «заголовок» -> «истина» указывает искре сопоставить первую строку файла с именами столбцов для результирующего фрейма данных.
Давайте посмотрим, что такое схема нашего Dataframe
Проверьте образцы данных в нашем фрейме данных
scala> airportDF.show


Запрос данных CSV с использованием временных таблиц:
Чтобы выполнить запрос к таблице, мы вызываем метод sql() в SQLContext.
Мы создали DataFrame аэропортов и загрузили данные CSV, чтобы запросить эти данные DF, мы должны зарегистрировать их как временную таблицу с именем airports.
>
scala> airportDF.registerTempTable("airports")
Давайте узнаем, сколько аэропортов в юго-восточной части нашего набора данных.
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Мы можем делать агрегации в sql-запросах на Spark.
Узнаем, сколько уникальных городов имеют аэропорты в каждой стране
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Какова средняя высота (в футах) аэропортов в каждой стране?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Теперь, чтобы узнать, сколько аэропортов работает в каждом часовом поясе?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Мы также можем рассчитать среднюю широту и долготу для этих аэропортов в каждой стране.
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Давайте посчитаем, сколько существует различных DST
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Сохранение данных в формате CSV
До сих пор мы загружали и запрашивали данные csv. Теперь мы увидим, как сохранить результаты в формате CSV обратно в файловую систему.
Предположим, мы хотим отправить клиенту отчет обо всех аэропортах в северо-западной части всех стран.
Давайте посчитаем это сначала.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
И сохраните его в файл CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Ниже приведены параметры, передаваемые в метод сохранения.
- Источник : то же, что и метод загрузки com.databricks.spark.csv , который указывает искре сохранять данные как csv.
- SaveMode : это позволяет пользователю заранее указать, что необходимо сделать, если данный выходной путь уже существует. Так что существующие данные не будут потеряны/переписаны по ошибке. Вы можете выдать ошибку, добавить или перезаписать. Здесь мы выдали ошибку ErrorIfExists , так как не хотим перезаписывать какой-либо существующий файл.
- Параметры : эти параметры аналогичны тем, которые мы передали методу загрузки . Опции:
- path – путь к файлу, где он должен храниться.
- Заголовок : «header» -> «true» указывает искре отображать имена столбцов фрейма данных в первую строку результирующего выходного файла.
Преобразование других форматов данных в CSV
Мы также можем преобразовать любой другой формат данных, такой как JSON, паркет, текст в CSV, используя эту библиотеку.
В предыдущем блоге мы создали данные json. вы можете найти его на гитхабе
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
давайте просто сохраним его как CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Заключение:
В этом посте мы собрали некоторые сведения о данных аэропортов с помощью интерактивных запросов SparkSQL.
и изучили библиотеку парсинга csv от Spark
В следующем блоге мы рассмотрим очень важный компонент Spark, т.е. Spark Streaming.
Spark Streaming позволяет пользователям собирать данные в реальном времени в Spark и обрабатывать их по мере их поступления, мгновенно выдавая результаты.