
Как Google может идентифицировать и оценивать авторов через EEAT
Опубликовано: 2023-04-17Google придает большее значение источнику контента, в частности автору, при ранжировании результатов поиска. Введение « Перспективы», «Об этом результате» и «Об этом авторе» в поисковой выдаче проясняет это.
В этой статье рассматривается, как Google потенциально может оценивать фрагменты контента на основе опыта, знаний, авторитетности и надежности их авторов (EEAT).
EEAT: качественное наступление Google
Google подчеркнул важность концепции EEAT для улучшения качества результатов поиска и взаимодействия с пользователем в поисковой выдаче.
Факторы на странице, такие как общее качество контента, сигналы ссылок (т. е. PageRank и анкорные тексты), а также сигналы на уровне объектов, играют жизненно важную роль.
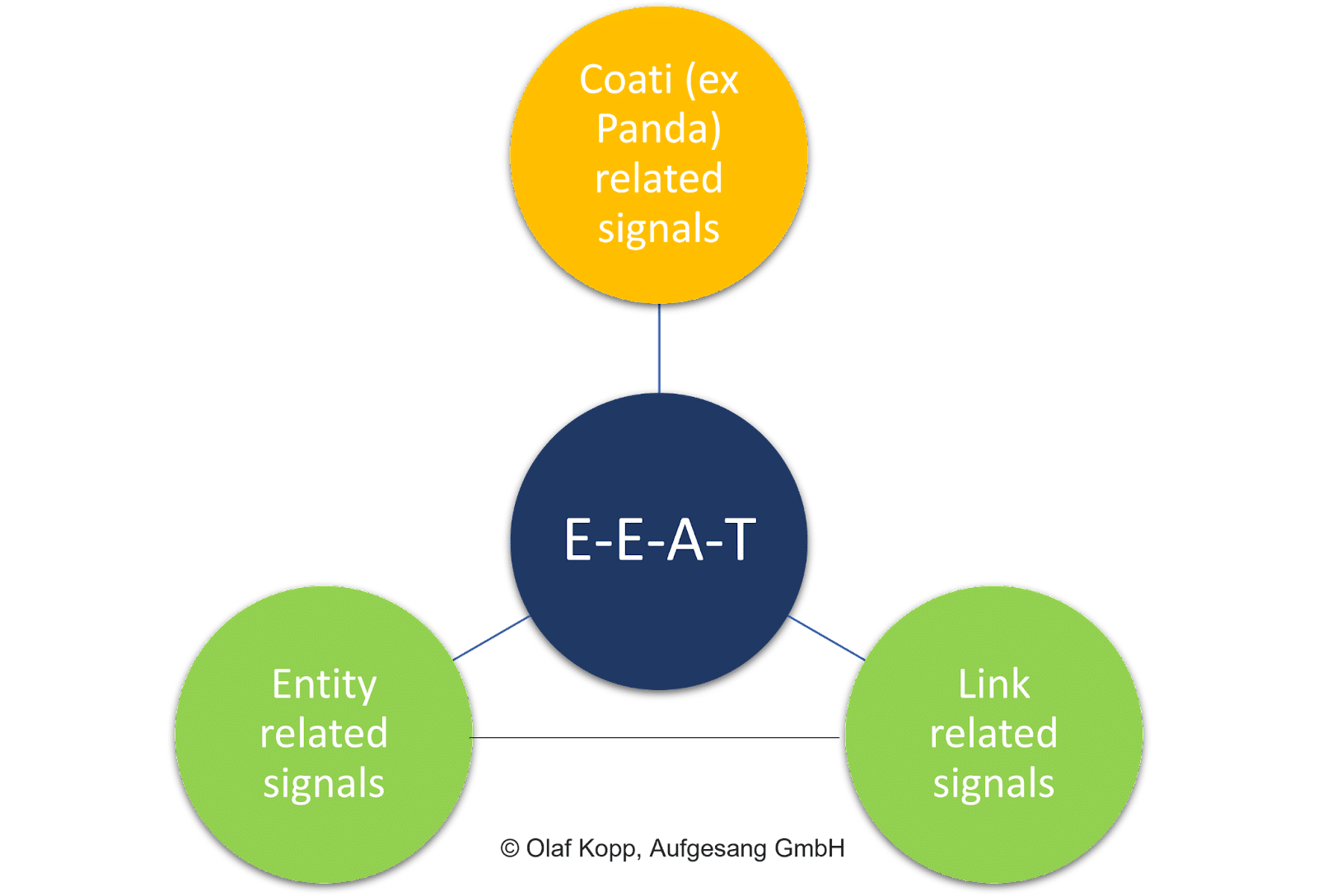
В отличие от оценки документов, оценка отдельного контента не является целью EEAT.
Концепция имеет тематическую ссылку, связанную с доменом и сущностью-создателем. Он не зависит от цели поиска и самого отдельного контента.
В конечном счете, EEAT — это влияющий фактор, не зависящий от поисковых запросов.
EEAT в основном относится к тематическим областям и понимается как уровень оценки, который оценивает наборы контента и внестраничных сигналов по отношению к таким объектам, как компании, организации, люди и их домены.
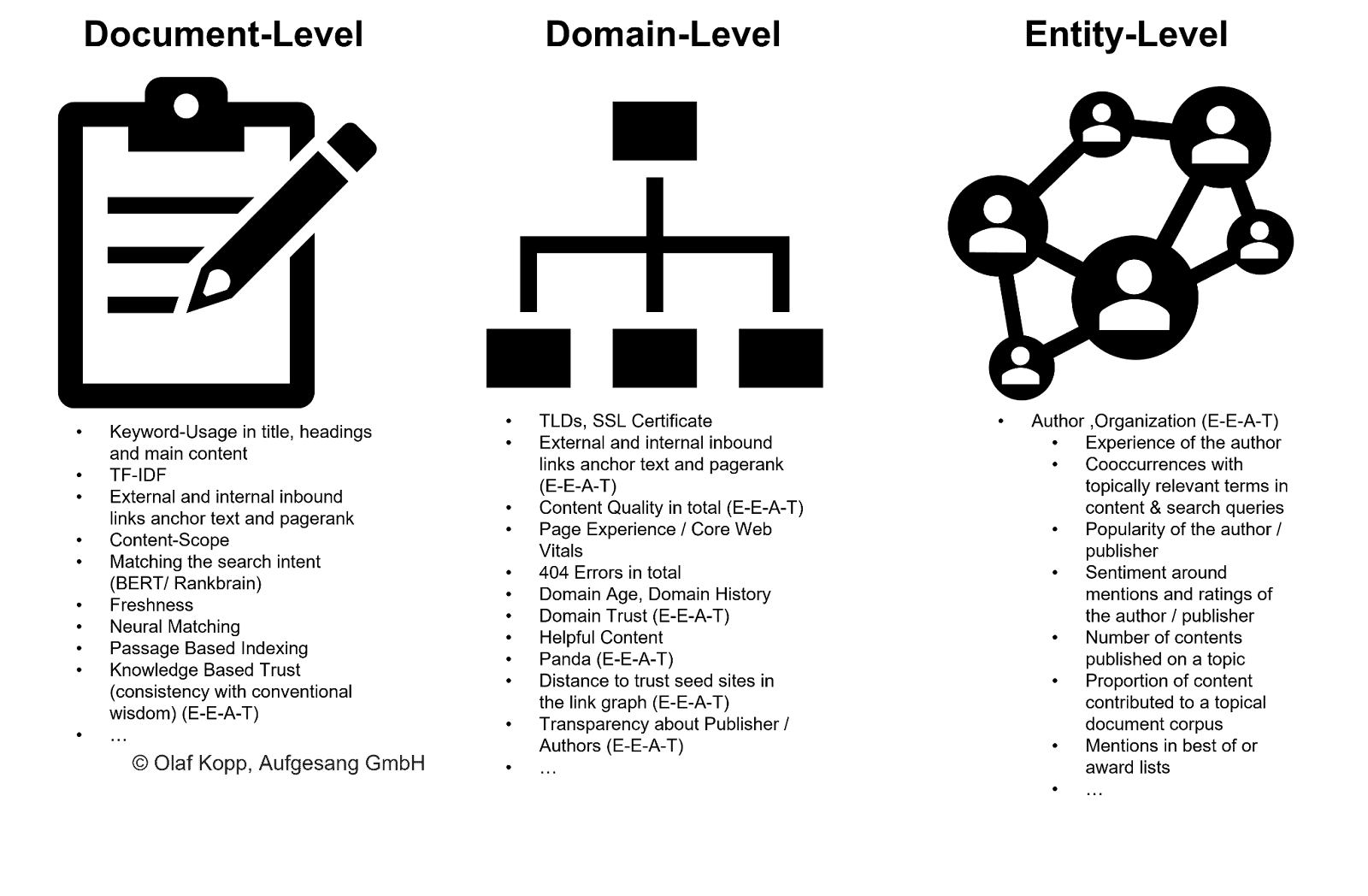
Важность автора как источника контента
Задолго до (E-)EAT Google пытался включить рейтинг источников контента в поисковые рейтинги. Например, обновление Vince от 2009 года дало контенту, созданному брендом, преимущество в рейтинге.
С помощью таких проектов, как Knol или Google+, которые уже давно прекратили свое существование, Google пытался собирать сигналы для рейтингов авторов (т. е. через социальный граф и рейтинги пользователей).
За последние 20 лет несколько патентов Google прямо или косвенно ссылались на контентные платформы, такие как Knol, и социальные сети, такие как Google+.
Оценка происхождения или автора части контента в соответствии с критериями EEAT является важным шагом к дальнейшему повышению качества результатов поиска.
При обилии контента, созданного искусственным интеллектом, и классического спама Google не имеет смысла включать некачественный контент в поисковый индекс.
Чем больше контента он индексирует и должен обрабатывать во время поиска информации, тем больше вычислительной мощности требуется.
EEAT может помочь Google ранжировать на основе объекта, домена и уровня автора в более широком масштабе без необходимости сканирования каждого фрагмента контента.
На этом макроуровне содержимое может быть классифицировано в соответствии с исходной сущностью и выделено с большим или меньшим краулинговым бюджетом. Google также может использовать этот метод, чтобы исключить из индексации целые группы контента.
Как Google может идентифицировать авторов и атрибутировать контент?
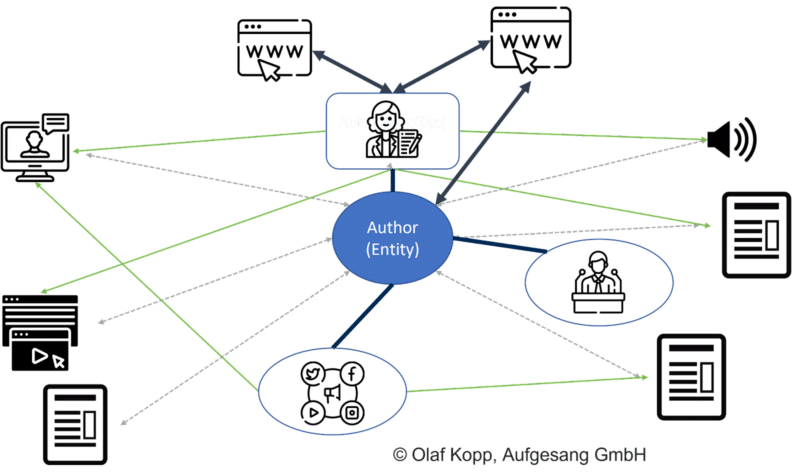
Авторы относятся к типу сущности лица. Необходимо проводить различие между уже известными объектами, записанными в Графике знаний, и ранее неизвестными или непроверенными объектами, записанными в хранилище знаний, таком как Хранилище знаний.
Даже если сущности еще не включены в Сеть знаний, Google может распознавать и извлекать сущности из неструктурированного контента с помощью машинного обучения и языковых моделей. Решение называется распознаванием сущностей (NER), подзадачей обработки естественного языка.
NER распознает сущности на основе лингвистических шаблонов и назначает типы сущностей. Вообще говоря, существительные — это (названные) сущности.
Современные информационно-поисковые системы используют для этого встраивание слов (Word2Vec).
Вектор чисел представляет каждое слово текста или абзац текста, а объекты могут быть представлены в виде векторов узлов или вложений объектов (Node2Vec/Entity2Vec).
Слова относятся к грамматическому классу (существительное, глагол, предлог и т. д.) с помощью тегов части речи (POS).
Существительные обычно являются сущностями. Субъекты являются основными сущностями, а объекты — второстепенными сущностями. Глаголы и предлоги могут связывать сущности друг с другом.
В приведенном ниже примере именованными объектами являются «olaf kopp», «head of seo», «coучредитель» и «aufgesang». (NN = существительное).
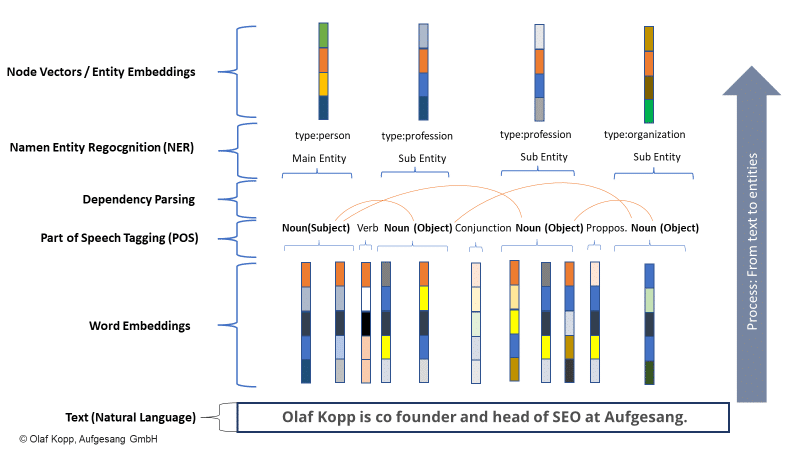
Обработка естественного языка может идентифицировать объекты и определять отношения между ними.
Это создает семантическое пространство, которое лучше фиксирует и понимает концепцию объекта.
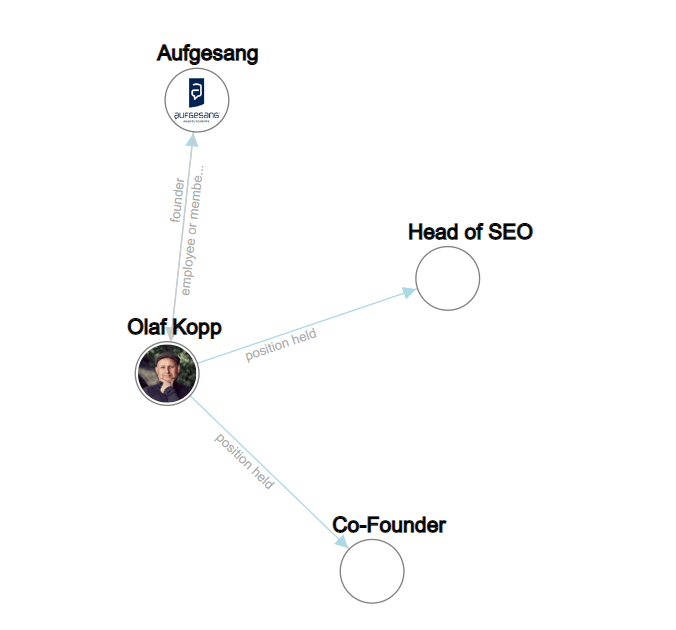
Подробнее об этом можно узнать в статье «Как Google использует НЛП для лучшего понимания поисковых запросов и контента».
Аналогом авторских вложений являются вложения документов. Вложения документов сравниваются с авторскими векторами посредством анализа векторного пространства. (Вы можете узнать больше в патенте Google «Создание векторных представлений документов».)
Все типы контента могут быть представлены в виде векторов, что позволяет:
- Векторы контента и векторы авторов для сравнения в векторных пространствах.
- Документы группируются по сходству.
- Авторы должны быть назначены.
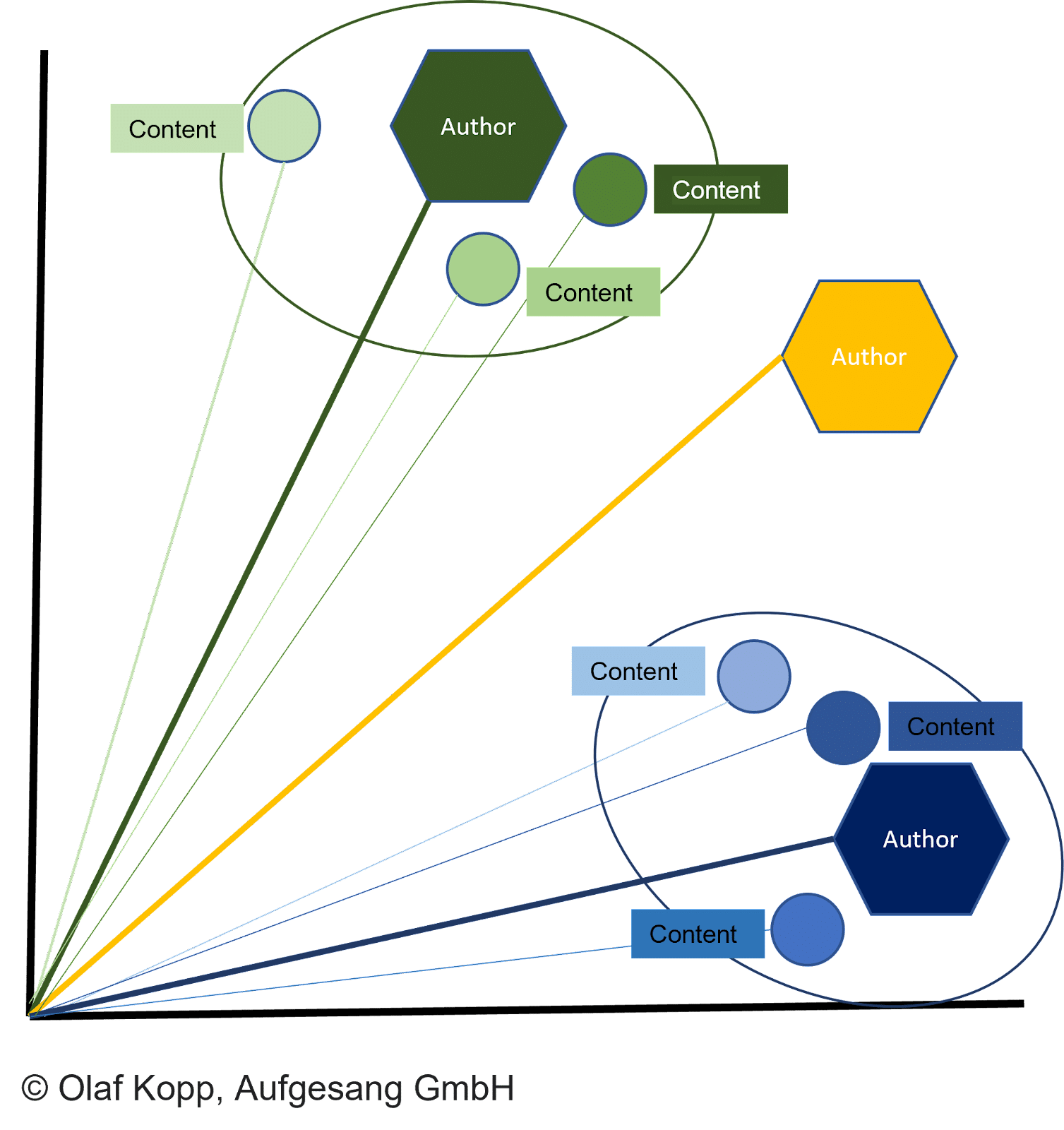
Расстояние между векторами документов и соответствующим вектором автора описывает вероятность того, что автор создал документы.
Документ присваивается автору, если расстояние меньше других векторов и достигнут определенный порог.
Это также может предотвратить создание документа под ложным флагом. Затем вектор автора может быть назначен объекту автора, как уже описано, с использованием имени автора, указанного в содержимом.
К важным источникам информации об авторах относятся:
- Википедия Статьи о человеке.
- Профили авторов.
- Профили динамиков.
- Профили в социальных сетях.
Если вы введете в Google имя лица типа объекта, вы найдете записи в Википедии, профили автора и URL-адреса доменов, которые напрямую связаны с автором, в первых 20 результатах поиска.
В мобильной поисковой выдаче вы можете увидеть, какие источники Google устанавливает прямую связь с физическим лицом.
Google распознал все результаты над значками профилей в социальных сетях как источники с прямой ссылкой на объект.

Этот снимок экрана с поисковым запросом «olaf kopp» показывает, что сущности связаны с источниками.
Он также отображает новый вариант панели знаний. Кажется, я стал частью бета-теста здесь.
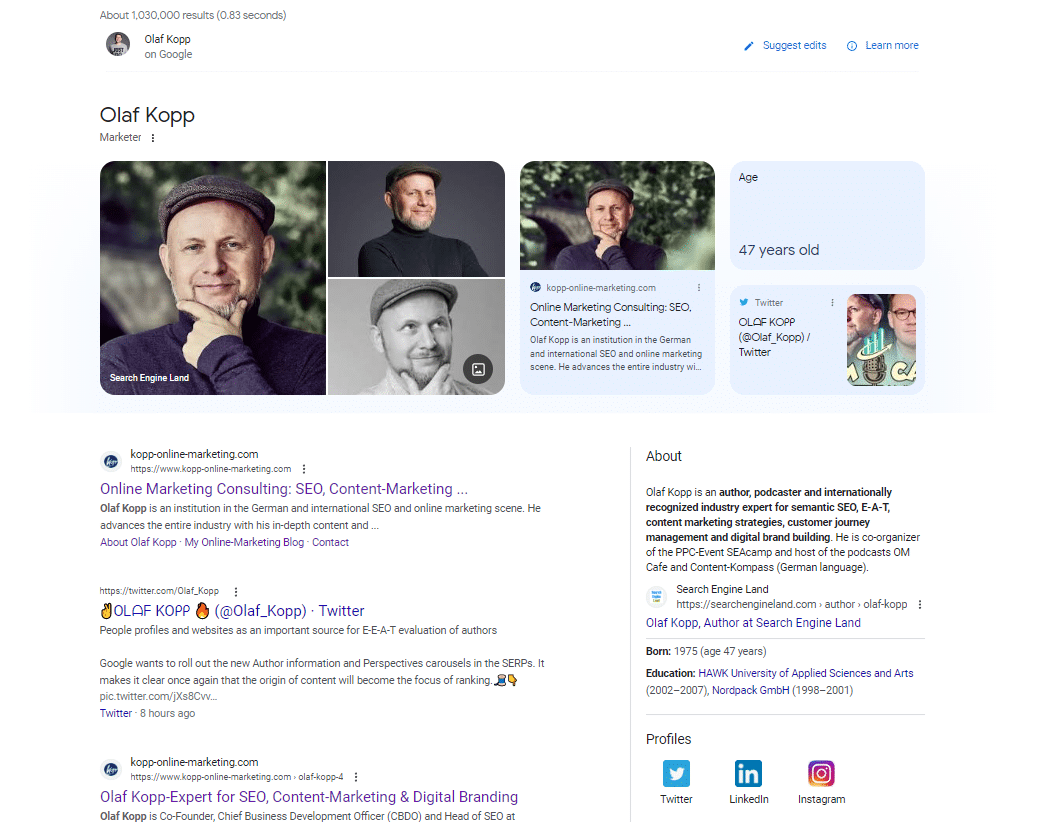
На этом снимке экрана вы увидите, что в дополнение к изображениям и атрибутам (возраст) Google напрямую связал мой домен и профиль в социальной сети с моей сущностью и доставляет их в панель знаний.
Поскольку обо мне нет статьи в Википедии, описание «Обо мне» взято из профиля автора в Search Engine Land в США и из профиля автора на веб-сайте агентства в Германии.
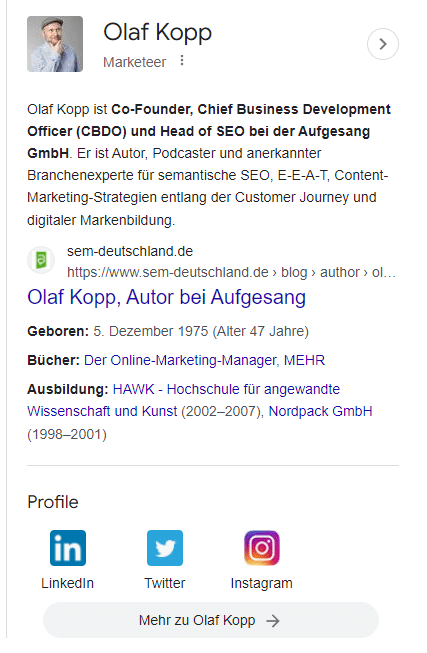
Личные профили в Интернете помогают Google контекстуализировать авторов и идентифицировать профили социальных сетей и домены, связанные с автором.
Ящики авторов или коллекции авторов в профилях авторов помогают Google назначать контент авторам. Имя автора недостаточно в качестве идентификатора, поскольку могут возникнуть двусмысленности.
Вы должны обратить внимание на описания каждого автора, чтобы обеспечить согласованность. Google может использовать их для проверки достоверности объекта по сравнению друг с другом.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
См. условия.
Интересные патенты Google для рейтинга авторов EEAT
Следующие патенты дают представление о возможных методологиях того, как Google идентифицирует авторов, присваивает им контент и оценивает его с точки зрения EEAT.

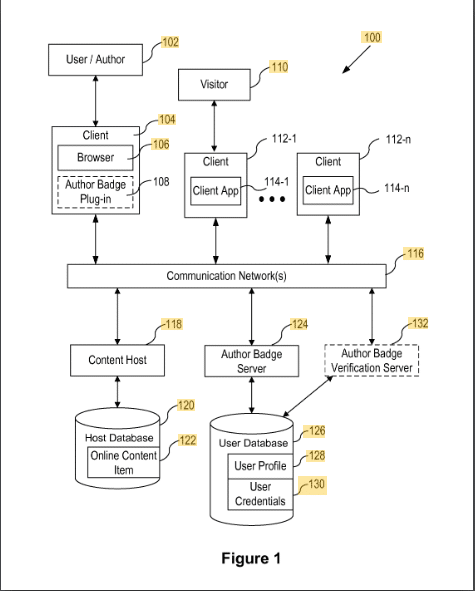
Значки авторов контента
В этом патенте описывается, как контент назначается авторам с помощью значка.
Контент присваивается значку автора с использованием идентификатора, такого как адрес электронной почты или имя автора. Проверка осуществляется через аддон в браузере автора.
Генерация авторских векторов
Google подписал этот патент в 2016 году со сроком действия до 2036 года. Однако патентные заявки были поданы только для США, что говорит о том, что он еще не используется в поиске Google по всему миру.
Патент описывает, как авторы представлены в виде векторов на основе обучающих данных.
Вектор становится уникальным параметром, определяемым на основе типичного стиля письма автора и выбора слов.
Таким образом, им может быть присвоен контент, ранее не приписываемый автору, или похожие авторы могут быть сгруппированы в кластеры.
Затем ранжирование контента может быть скорректировано для одного или нескольких авторов на основе поведения пользователя в прошлом в поиске (например, в Discover).
Таким образом, контент от авторов, которые уже были обнаружены, и от похожих авторов будут ранжироваться лучше.
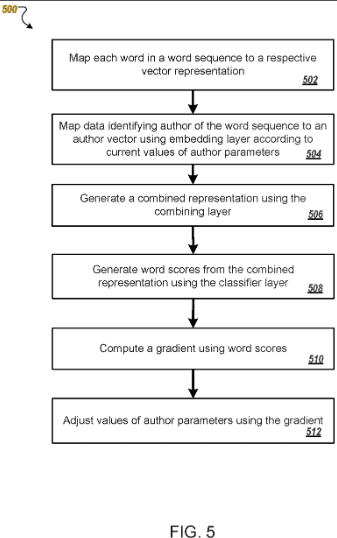
Этот патент основан на так называемых вложениях, таких как авторы и вложения слов.
Сегодня вложения являются технологическим стандартом в области глубокого обучения и обработки естественного языка.
Поэтому очевидно, что такие методы Google также будут использоваться для распознавания и атрибуции автора.
Рейтинг репутации автора
Этот патент был впервые подписан Google в 2008 году и имеет минимальный срок действия 2029 года. Первоначально этот патент относится к давно закрытому проекту Google Knol.
Таким образом, тем более интересно, почему Google снова нарисовал его в 2017 году под новым названием «Монетизация онлайн-контента». Knol был закрыт Google еще в 2012 году.
Патент касается определения рейтинга репутации. При этом могут учитываться следующие факторы:
- Уровень кадра автора.
- Публикации в известных СМИ.
- Количество публикаций.
- Возраст последних релизов.
- Как давно автор официально работает автором.
- Количество ссылок, сгенерированных авторским контентом.
У автора может быть несколько оценок репутации для каждой темы и несколько псевдонимов для каждой предметной области.
Многие моменты, указанные в патенте, относятся к закрытой платформе, такой как Knol. Таким образом, этого патента должно быть достаточно на данный момент.
Ранг агента
Этот патент Google был впервые подписан в 2005 году и имеет минимальный срок действия до 2026 года.
Помимо США, он также был зарегистрирован в Испании, Канаде и во всем мире, поэтому его можно использовать в поиске Google.
Патент описывает, как цифровой контент назначается агенту (издателю и/или автору). Этот контент ранжируется, среди прочего, на основе ранга агента.
Ранг агента не зависит от цели поиска поискового запроса и определяется на основе документов, назначенных агенту, и их обратных ссылок.
Ранг агента относится исключительно к одному поисковому запросу, кластеру поисковых запросов или целым предметным областям.
«Ранги агентов также могут быть дополнительно рассчитаны относительно поисковых запросов или категорий поисковых запросов. Например, поисковые термины (или структурированные наборы поисковых терминов, т. е. запросы) могут быть классифицированы по темам, например, спортивные или медицинские специальности, и агент может иметь разный ранг по каждой теме».
Доверие к автору онлайн-контента
Этот патент Google был впервые подписан в 2008 году и имеет минимальный срок действия 2029 года, и пока зарегистрирован только в США.
Джастин Юрист разработал его по аналогии с рейтингом патентной репутации автора и напрямую связан с использованием в поиске.
В патенте можно найти те же пункты, что и в вышеупомянутом патенте.
Для меня это самый захватывающий патент для оценки авторов с точки зрения доверия и авторитета.
В этом патенте упоминаются различные факторы, которые можно использовать для алгоритмического определения достоверности автора.
Он описывает, как поисковая система может ранжировать документы под влиянием фактора авторитета автора и оценки репутации.
У автора может быть несколько оценок репутации в зависимости от того, на скольких темах он публикует контент.
Оценка репутации автора не зависит от издателя.
Опять же, в этом патенте есть ссылка на ссылки как на возможный фактор рейтинга EEAT. Количество ссылок на опубликованный контент может влиять на оценку репутации автора.
Упомянуты следующие возможные сигналы для оценки репутации:
- Как долго автор создает контент в предметной области.
- Осознание автора.
- Рейтинги опубликованного контента пользователями.
- Если другой издатель публикует авторский контент с рейтингом выше среднего.
- Количество контента, опубликованного автором.
- Как давно автор последний раз публиковался.
- Рейтинги предыдущих публикаций автора на схожую тему.
Другая интересная информация о рейтинге репутации из патента:
- У автора может быть несколько оценок репутации в зависимости от того, на скольких темах он публикует контент.
- Оценка репутации автора не зависит от издателя.
- Оценка репутации может быть понижена, если повторяющийся контент или выдержки публикуются несколько раз.
- Количество ссылок на опубликованный контент может влиять на оценку репутации.
Кроме того, патент учитывает фактор доверия к авторам. Упоминаются следующие влияющие факторы:
- Проверенные сведения о профессии или роли автора в компании. Также учитывается доверие к компании.
- Соответствие профессии тематике публикуемого контента.
- Уровень образования и подготовки автора.
- Авторский опыт, основанный на времени. Чем дольше автор публикуется по теме, тем больше он вызывает доверия. Опыт автора/издателя можно определить алгоритмически для Google по дате первой публикации в предметной области.
- Количество контента, опубликованного по теме. Если автор публикует много статей по теме, можно предположить, что он является экспертом и имеет определенный авторитет.
- Прошедшее время до последнего выпуска. Чем больше времени прошло с момента последней публикации автора по теме, тем больше снижается возможный показатель репутации для этой темы. Чем актуальнее контент, тем он выше.
- Упоминания автора/издателя в списках наград и лучших.
Системы и методы реранжирования ранжированных результатов поиска
Этот патент Google был впервые подписан в 2013 году и имеет минимальный срок действия до 2033 года. Он был зарегистрирован в США и во всем мире, поэтому вполне вероятно, что Google будет его использовать.
Среди изобретателей патента Чунг Тин Квок, который участвовал в нескольких патентах Google, относящихся к EEAT.
Патент описывает, как поисковые системы, в дополнение к ссылкам на авторский контент, могут также учитывать долю, которую он может внести в тематический корпус документов, при оценке автора.
«В некоторых вариантах осуществления определение исходной авторской оценки для соответствующего объекта включает в себя: идентификацию множества частей контента в указателе известного контента, идентифицированного как связанное с соответствующим объектом, причем каждая часть во множестве частей представляет заранее определенное количество данных в указателе известного содержимого и вычисление процента множества частей, которые являются первыми экземплярами частей содержимого в указателе известного содержимого».
Он описывает повторное ранжирование результатов поиска на основе оценки автора, включая оценку цитирования. Оценка цитируемости основана на количестве ссылок на документы автора.
Еще одним критерием оценки авторов является доля контента, внесенного автором в корпус тематических документов.
«[W]здесь определение оценки автора для соответствующего объекта включает в себя: определение оценки цитирования для соответствующего объекта, при этом оценка цитирования соответствует частоте цитирования контента, связанного с соответствующим объектом; определение исходной авторской оценки для соответствующей сущности, при этом первоначальная оценка автора соответствует проценту контента, связанного с соответствующей сущностью, которая является первым экземпляром контента в указателе известного контента; и объединение оценки цитирования и исходной оценки автора с использованием заранее определенной функции для получения оценка автора».
Патент предназначен для выявления «подражателей» и понижения их содержания в рейтинге, но его также можно использовать для общей оценки авторов.
Ключевые факторы для оценки автора
В дополнение к возможным факторам для авторской оценки, перечисленным в патентах выше, следует рассмотреть еще несколько (некоторые из них я уже упоминал в своей статье «14 способов, которыми Google может оценивать EAT»).
- Общее качество контента по теме: Качество, которое автор представляет в своем контенте по теме в целом, независимо от предметной области и формата, может быть фактором для EEAT. Сигналами для этого могут быть пользовательские сигналы, ссылки и другие сигналы качества на уровне контента.
- PageRank или ссылки на авторский контент.
- Совпадения автора в контенте (подкасты, видео, веб-сайты, PDF-файлы, книги) с соответствующими темами или терминами.
- Встречи автора в поисковых запросах с релевантными темами или терминами.
Применение EEAT к авторским объектам
Методы машинного обучения позволяют распознавать и отображать семантические структуры из неструктурированного контента в больших масштабах.
Это позволяет Google распознавать и понимать гораздо больше объектов, чем ранее отображалось в сети знаний.
В результате источник контента играет все более важную роль. EEAT можно алгоритмически применять за пределами документов, контента и предметной области.
Концепция может также охватывать авторские сущности контента (т. е. авторов и организации, ответственные за контент).
Я думаю, что в ближайшие несколько лет мы увидим еще более значительное влияние EEAT на поиск Google. Этот фактор может быть даже столь же важен для ранжирования, как и оптимизация релевантности отдельного контента.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.