
Как получить максимальную отдачу от Google Search Console API с помощью регулярных выражений
Опубликовано: 2022-11-02Консоль поиска Google — это удивительный инструмент, который предоставляет бесценные поисковые данные реальных пользователей непосредственно из Google. Хотя с диаграммами и таблицами удобно работать, большая часть данных недоступна из пользовательского интерфейса.
Единственный способ добраться до этих скрытых данных — использовать API и извлечь все доступные вам ценные поисковые данные — если вы знаете, как это сделать. Это возможно с помощью регулярных выражений.
Вот как вы можете максимизировать API Google Search Console с помощью регулярных выражений, по словам Эрика Ву, вице-президента по развитию продуктов в Honey, компании PayPal, который выступал на SMX Advanced.
Диагностика SEO-проблем с помощью GSC
Работаете над веб-сайтом, на котором наблюдается застой или снижение роста или падение основного обновления?
Большинство SEO-специалистов обращаются к Google Search Console (GSC) для диагностики таких проблем.
(Или, если позволяют ресурсы, вы можете даже использовать платный инструмент, такой как Ryte, или создать свою собственную платформу.)
К счастью для SEO-сообщества, нет недостатка в панелях Looker Studio (ранее Google Data Studio), полезных для анализа GSC, в том числе:
- Бесплатная панель инструментов Алейды Солис, которая использует данные GSC, чтобы легко определять потенциальные изменения рейтинга за последние дни после обновления Google Core.
- Панель мониторинга поискового трафика Google, которая теперь собирает данные о трафике Discover и Google News.
- Search Console Explorer Studio Ханны Батлер. (А если вы хотите манипулировать данными GSC и находить быстрые идеи, вы можете использовать Search Console Explorer Sheet от Butler.)
Панели инструментов позволяют SEO-специалистам просматривать обзор различных тенденций, а не использовать GSC и делать несколько кликов, чтобы получить нужные данные.
Но если вы анализируете корпоративные сайты, вы можете столкнуться с некоторыми препятствиями.
- Looker Studio и Google Таблицы загружаются медленно, особенно когда вы имеете дело с большими сайтами.
- Интерфейс GSC имеет ограничение экспорта в 1000 строк.
- У GSC огромная проблема с выборкой. По данным Similar.ai, корпоративные SEO-команды пропускают 90% ключевых слов GSC. И если вы знаете, как извлекать данные, вы можете получить в 14 раз больше ключевых слов.
Преодоление проблемы выборки GSC
Проводник для поиска — еще один инструмент, который вы можете использовать для анализа GSC. Ной Лернер и команда Two Octobers создали его с помощью конвейеров данных с использованием API GSC, который затем выводит данные в BigQuery (в основном минуя Google Таблицы и загружая файлы CSV), а затем визуализирует информацию с помощью Data Studio.
При этом вы можете быть уверены, что получаете почти все данные.
Есть еще одна оговорка из-за проблемы выборки GSC, особенно для крупных сайтов электронной коммерции с большим количеством различных категорий. GSC не обязательно будет отображать все данные, поступающие из этих каталогов.
Проведя различные тесты, чтобы получить как можно больше данных из GSC API, команда Similar.ai нашла способ закрыть пробел в выборке GSC.
Они обнаружили, что, добавляя больше подкаталогов в качестве разных профилей на панель инструментов GSC, вы можете извлечь еще больше данных, поскольку Google предоставляет вам больше информации на этом более низком уровне.
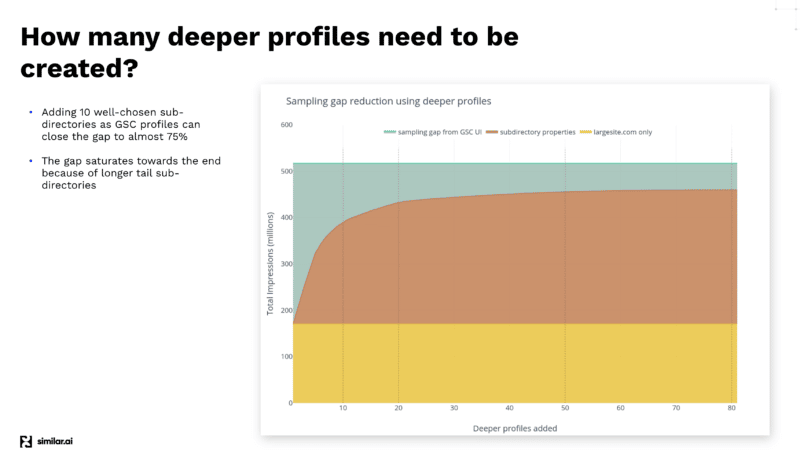
Например, если вы просматриваете страницу example.com/televisions и добавляете «телевидение» в качестве подкаталога в свой профиль GSC, Google предоставит вам только ключевые слова и информацию о кликах для этого подкаталога и ниже.
И, добавляя множество этих различных подкаталогов, вы можете извлечь намного больше информации.
Это решает проблему выборки, но вы можете получить еще больше данных, используя регулярные выражения.
Получение большего количества данных GSC с помощью регулярных выражений
Регулярное выражение или регулярное выражение — это мощный инструмент для понимания ваших данных.
В апреле 2021 года Google добавил поддержку регулярных выражений в GSC, предоставив оптимизаторам больше возможностей для нарезки данных органического поиска.
Во многих случаях данные бесполезны, если вы не можете их понять. А регулярное выражение помогает извлекать полезную информацию из обширных данных GSC.
Но каким бы мощным оно ни было, регулярное выражение может быть трудным для изучения.
Лучшее место для понимания и глубокого изучения регулярных выражений — это официальная документация Google на GitHub. (Google использует RE2 в своих продуктах, что является разновидностью регулярных выражений.)
Хотя регулярное выражение доступно во всех видах различных языков программирования, вы найдете его почти везде, даже для тех, кто модифицирует файлы .htaccess.
В следующих нескольких разделах приведены примеры использования регулярных выражений для GSC.
Информационные запросы регулярных выражений
Глядя на фактические информационные поисковые запросы в GSC, вы обычно хотите понять:
- Как люди на самом деле приходят на ваш сайт?
- Какие вопросы они извлекают?
Глядя на эти вещи с разовой точки зрения внутри GSC, может быть сложно.
Вы всегда ищете слова «что», «как», «почему», а затем «когда».
Есть несколько способов сделать извлечение информационных запросов менее утомительным с помощью регулярных выражений.
Daniel K. Cheung поделился строкой регулярного выражения, которая покажет вам все запросы, содержащие «что», «как», «почему» и «когда», которые либо получили клик, либо показ:
-
"what|how|why|when"
И эта строка регулярного выражения, которой поделился Стив Тот, поднимает предыдущий пример на ступеньку выше:
-
^(who|what|where|when|why|how)[" "]
Вы можете использовать эту строку, если хотите захватить запросы на основе вопросов, которые начинаются с «кто», «что», «где», «когда», «почему» и «как», а затем следует пробел.
Это отличный список для использования, когда вы ищете слово любого типа, с которого начинается вопрос:
- являются, может, не может, мог, не мог, сделал, не сделал, делает, не делает, не делает, как, если, есть, нет, должен, не должен, был, не был, были, не были, что, когда, где, кто, кого, чей, почему, будет, не будет, будет, не будет
Помещение всего этого в форму регулярного выражения будет выглядеть примерно так:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
В этой 178-символьной строке:
- У вас есть знак вставки (
^), который говорит вам, что запрос должен начинаться с этого слова: - Слова разделяются вертикальной чертой (
|) вместо запятых. - Все слова заключены в скобки.
- Есть обратная косая черта и «s» (
\s), которые обозначают пробел после слова.
Это хорошо, но может быть утомительно.
Ниже Ву упростил предыдущий список слов, сделав его более удобным для регулярных выражений и более коротким, что идеально подходит для копирования и вставки. Поддержание этого таким образом также помогает с эффективностью.
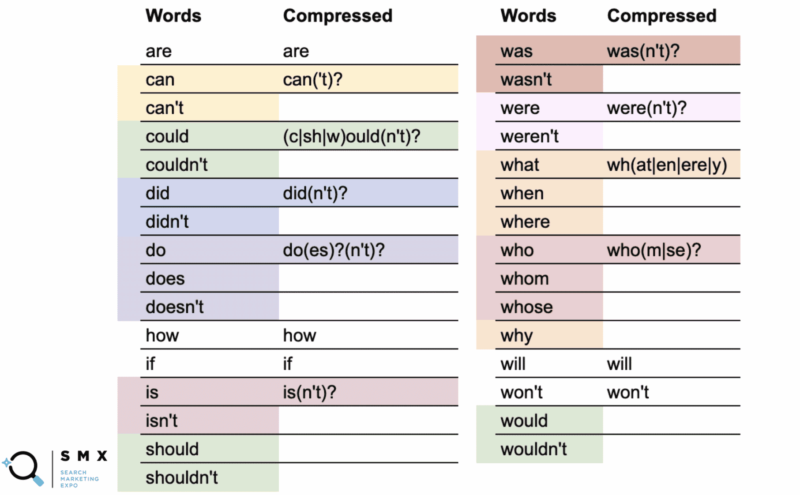
В первом столбце — обычные слова, а во втором — сжатое регулярное выражение.
Например, слово «может» использует сжатую версию can('t)? .
Знак вопроса указывает на то, что все, что заключено в скобки, является необязательным. Сжатый синтаксис позволяет охватить как слово «может», так и «не может».
Что еще интереснее, вы можете сделать это с помощью глаголов «может/не может», «должен/не должен» и «будет/не будет», где -ould часть слов является общей основой, например (c|sh|w)ould(n't)? . Эта короткая строка охватывает все шесть случаев.
Хотя упрощение этого длинного списка слов сделало строку менее читаемой, замечательно то, что она больше вписывается в поле регулярного выражения и упрощает копирование и вставку.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Если вы пойдете дальше, вы можете сжать его еще больше. В этом случае Ву сократил количество символов со 135 до 113 символов.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Регулярные выражения могут быть очень сложными. Если вы получаете строку регулярного выражения от кого-то еще и хотите устранить неоднозначность того, что делает что, вы можете использовать Regexper, чтобы визуализировать ее.
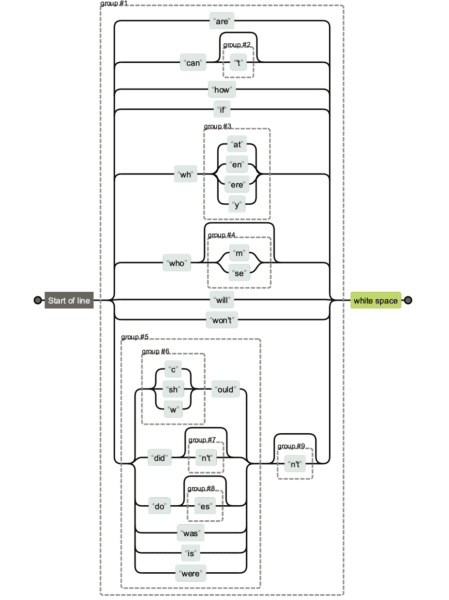
Ниже вы увидите сравнение различных версий строк регулярных выражений. Легче поддерживать первый и, очевидно, сложнее поддерживать и читать последний.

Но иногда количество символов действительно имеет значение, особенно если у вас длинные регулярные выражения.
По словам Дэниела Вайсберга, эксперта Google Search Advocate, ограничения фильтра регулярных выражений для GSC составляют 4096 символов.
Казалось бы, совсем немного. Однако, если у вас есть сайт электронной коммерции и вам нужно добавить доменные имена, поддомены или более длинные каталоги, вы, скорее всего, достигнете этого предела.
Фирменные запросы Regex
Еще один случай, когда вы можете начать сталкиваться с ограничением символов регулярных выражений в GSC, — это когда вы используете его для фирменных запросов.
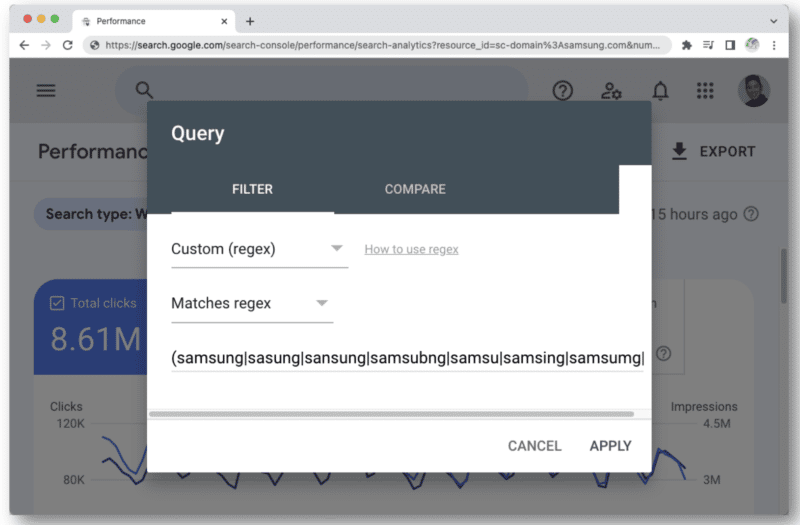
Когда вы думаете обо всех различных типах орфографических ошибок в названии бренда, которые может ввести человек, вы быстро столкнетесь с 4096 символами. Например:
- aamaung, damsung, mamsang, sam sung, samaung, samdung, самсунг, самунг, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samngsum, samngsubng, samsung , самсунг г, самсунб, самсунд, самсунд, самсун, самсун …
Здесь помогает понимание регулярных выражений. С помощью этой строки вы можете записать название бренда «samsung» вместе с орфографическими ошибками:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Часто люди неправильно пишут средние части слова. Но в целом они правильно понимают формат и длину, и таким образом вы можете приблизиться к своему синтаксису.

При орфографических ошибках в запросах на бренд учитывайте следующее:
- Основные буквы , из которых состоит запрос бренда.
- Согласные .
- Буквы вокруг твердых согласных .

Красным цветом выделены твердые согласные, которые люди обычно не пропускают, когда набирают название бренда. Это основные буквы, из которых состоит конкретный бренд. Для «samsung» «s» в начале, «m» в середине, а затем «n» и «g» в конце.
Синие буквы, окружающие основные согласные на клавиатуре, — это те, которые люди обычно неправильно набирают. В примере вокруг «s» вы видите «a», «d» и «z». (Хотя раскладка для международных клавиатур отличается, концепция остается той же.)
Приведенная выше строка регулярного выражения охватывает все возможные варианты «samsung».
Другой важный трюк здесь заключается в [az\s]{1,4} .
В форме регулярного выражения это в основном говорит: «Я хочу сопоставить любую букву от «а» до «z» или пробел от одного до четырех раз».
Это фиксирует все те странные орфографические ошибки, которые могут произойти в середине запроса бренда, когда человек потенциально может нажать одну и ту же клавишу несколько раз или случайно нажать пробел.
Кроме того, название бренда имеет определенную длину («самсунг» состоит из семи символов). Скорее всего, люди не будут набирать 20–50 символов.
Таким образом, в этом регулярном выражении мы предполагаем, что между «s» и «m» в «samsung» кто-то напечатает 1–4 символа с ошибкой. А затем от «m» до «g» в конце они опечатаются от 1 до 6 символов, включая пробелы.
Добавление всего этого позволяет вам всесторонне охватить множество вариантов фирменного запроса.
Следует также отметить, что название бренда может появляться в разных частях запроса.

Поэтому нам нужно убедиться, что само название бренда зафиксировано. Это должно быть либо:
- В начале запроса.
- В середине запроса (таким образом, в окружении пробелов).
- Или в конце запроса.
Регулярное выражение для этого выглядит следующим образом:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Это захватывает все запросы, в которых название бренда «samsung» находится либо в начале, либо в середине, либо в конце.
- Начало строки =
^ - В окружении пробелов =
\s - Конец строки =
$
Сообщение JC Chouinard, Регулярные выражения (RegEx) в Google Search Console, еще глубже погружается в примеры регулярных выражений.
Regex и GSC API в действии
Регулярные выражения пригодились Ву и его команде, когда они работали с клиентом, который столкнулся с падением трафика после обновления ядра.
Изучив различные проблемы сайта электронной коммерции, они обнаружили, что проблема связана с некоторыми страницами сведений о продукте.
Им нужно было сегментировать типы страниц для анализа в GSC. Но это была сложная задача из-за разных структур URL-адресов для товаров из США и других стран.

Международные URL-адреса продуктов сайта включали коды языков и стран, тогда как URL-адреса продуктов для США не включали.
Даже использование синтаксиса регулярных выражений было сложным, потому что буквы и тире существуют в ярлыке продукта, категориях и подкатегориях. Кроме того, им нужно было отфильтровать международные URL-адреса продуктов, чтобы охватить только страницы США.
Чтобы получить все целевые страницы продуктов США + подробные страницы ( не страницы i18n), они придумали следующие строки регулярных выражений:
Включить: /([^/]+/){1,2}p?
Исключить: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Вот разбивка:

Команда хотела сопоставить категорию, подкатегорию и все продукты, поэтому они включили:
- Любой символ, кроме косой черты =
[^/]+ - 1 или 2 каталога =
/){1,2} - Иногда следует ярлык продукта =
p?
Символ вставки ( ^ ) обычно означает начало строки. Но когда оно находится внутри квадратных скобок (как в [^/] ), оно указывает на отрицание (т. е. «ничего в этом поле»).
Итак, эта строка /([^/]+/){1,2}p? означает «Я хочу, чтобы любое количество символов, кроме косой черты, шло до косой черты (обозначающей каталог), а иногда за ней следует буква «p» (префикс для ярлыков продуктов)».
В то же время команда не хотела сопоставлять комбинацию страны и языка, которая также содержала буквы и тире, поэтому они исключили:
- Любой двухбуквенный каталог =
[a-zA-Z]{2} - Комбинация из 2 букв + 2 букв языка и страны =
[a-zA-Z]{2}-[a-zA-Z]{2}
Самостоятельное создание регулярного выражения для соответствия всем кодам языков и стран было бы утомительным из-за всех возможных комбинаций, поэтому они не могли подойти к этому так же, как к информационным запросам (где исключались все типы комбинаций).
Но даже после создания этих строк регулярных выражений у них возникла проблема.
В Google Search Console есть только одно поле для вставки строки регулярного выражения. Вам нужно будет выбрать « Соответствует регулярному выражению » или «Не соответствует регулярному выражению» — вы не можете использовать оба варианта одновременно.
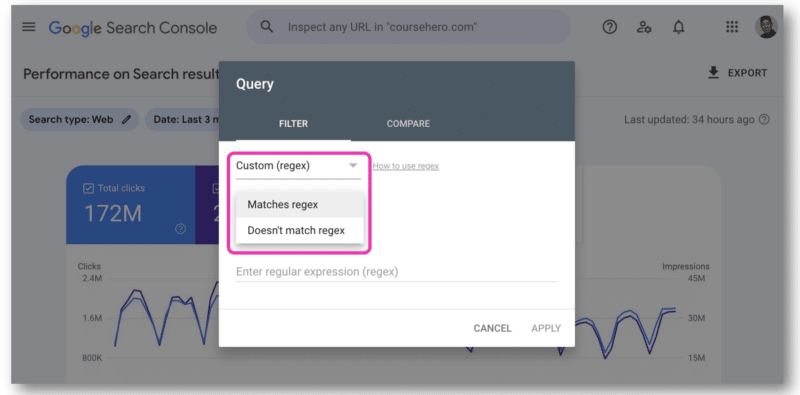
Вот тут-то и пригодился GSC API, поскольку он позволяет объединять строки регулярных выражений.
В документации API Google Search Console есть ссылка « Попробовать сейчас ».
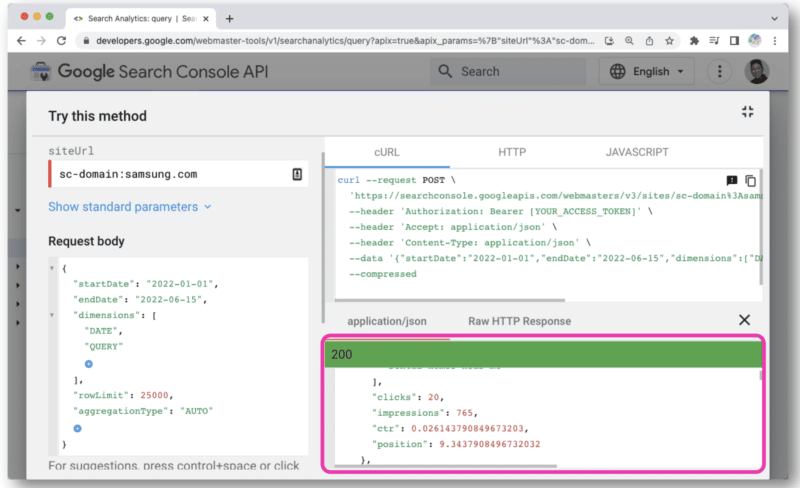
После нажатия откроется консоль, которая позволит вам выбрать сайт и сделать запрос API через веб-представление.
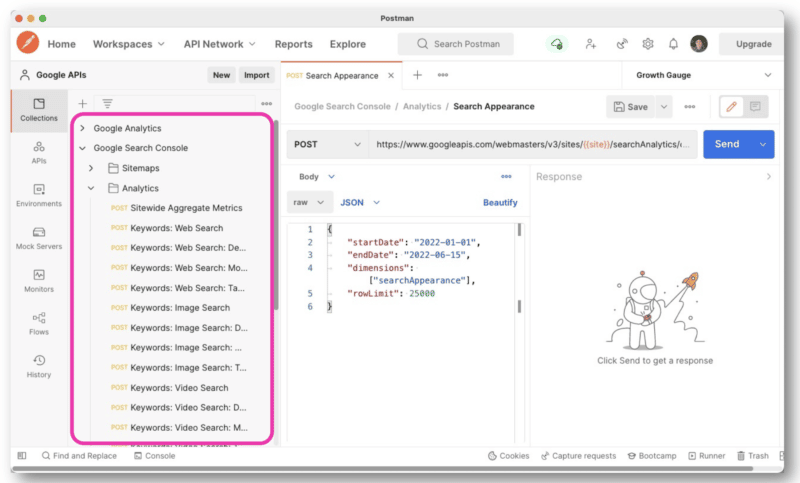
Но чтобы лучше управлять запросами API, Ву рекомендует использовать Postman на рабочем столе или Paw (родной для Mac).
Почтальон позволяет создавать запросы и сохранять их на потом. А если у вас есть доступ к другим сайтам, вам не нужно каждый раз создавать новый запрос. Вы просто меняете имя сайта на переменную, а затем делаете несколько запросов.
Paw, с другой стороны, гораздо проще просматривать и использовать.
Чтобы получить доступ к API, вам необходимо получить ключи API. (Вот полезный урок от Chouinard.)
Как только вы получите эту информацию, у вас будет свой идентификатор клиента и секреты клиента, которые вы добавите к своей аутентификации OAuth 2.0 в Postman или Paw.
Оттуда вы сможете войти в свою обычную учетную запись.
Ву в основном делал запросы API GSC, используя строки регулярных выражений в Paw. Запрос вводится в середине интерфейса.
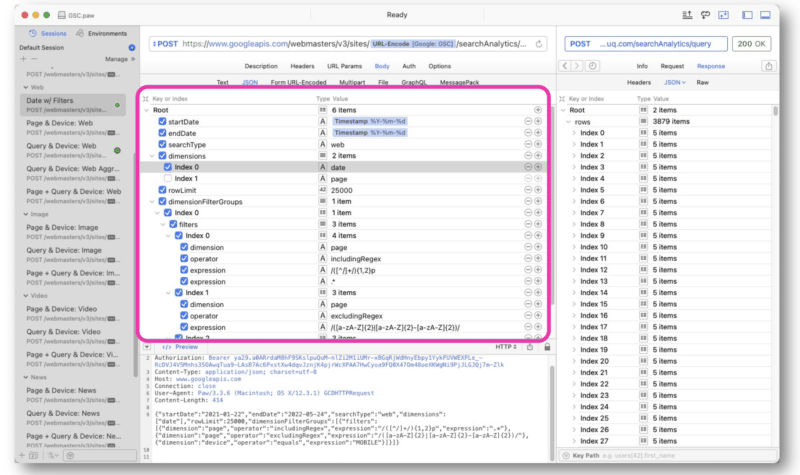
Ответ от Google аналогичен ответу веб-представления GSC API. Затем данные можно экспортировать для обработки.
Поскольку данные находятся в JSON, информация может быть запутанной и трудной для чтения.

Для этого вы можете использовать бесплатный процессор JSON командной строки с открытым исходным кодом под названием JQ для красивой печати информации.

Данные не так полезны, пока вы не введете их в электронную таблицу. Вставьте файл, который вы экспортировали из Paw в JQ. Откройте его, а затем выполните итерацию по каждой строке, сохраняя каждый элемент, чтобы вы могли вывести их в CSV.
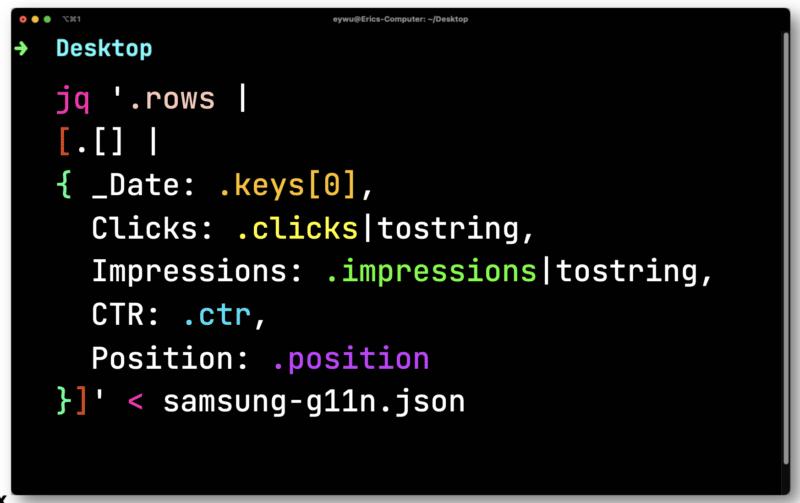
Здесь вам нужно преобразовать клики и показы, которые являются числами с плавающей запятой (число с десятичным знаком). Оба должны быть преобразованы в строки, совместимые с CSV.
Затем JQ выведет следующий гораздо более простой формат.
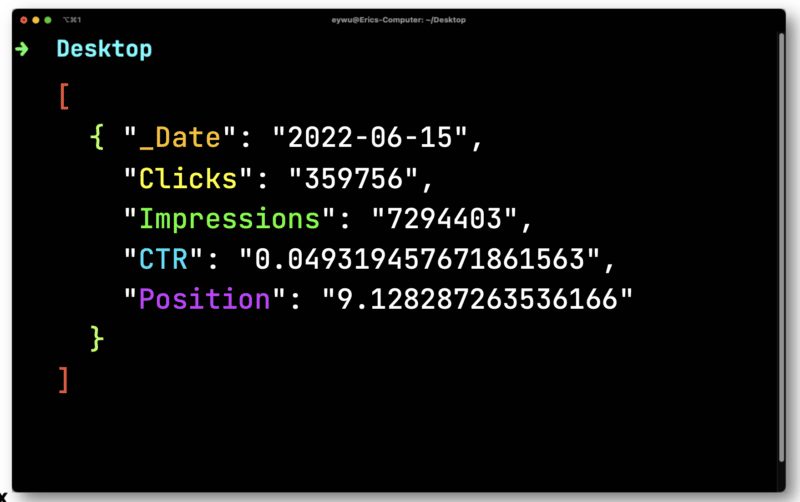
Далее вы будете использовать Dasel, чтобы взять этот формат и преобразовать его в CSV.
И вот конечный результат.
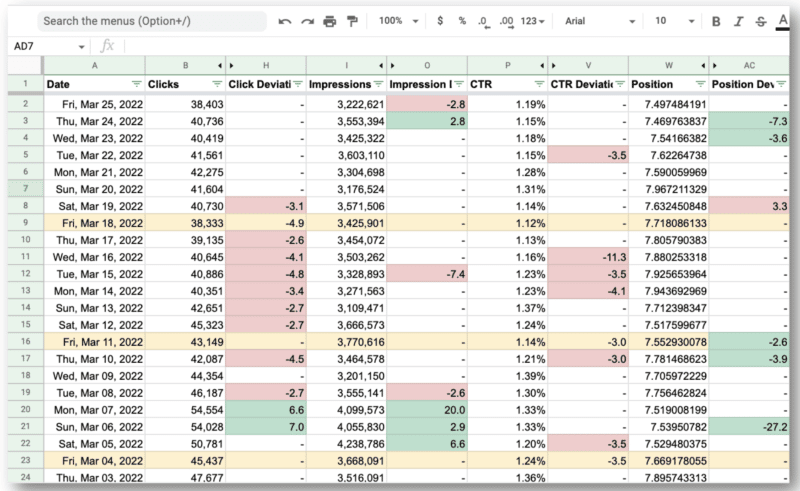
Что удивительно для команды Ву, так это то, что они смогли использовать API Google Search Console и регулярные выражения для:
- Отфильтруйте все международные запросы и посмотрите только на США, где у них были основные проблемы.
- Определите дни, когда на сайте возникали проблемы.
Смотреть: максимально эффективное использование Google Search Console API
Ниже представлено полное видео презентации Ву SMX Advanced.