
Экосистема Hadoop и ее компоненты
Опубликовано: 2015-04-23Большие данные — это модное слово, циркулирующее в ИТ-индустрии с 2008 года. Количество данных, генерируемых социальными сетями, производством, розничной торговлей, акциями, телекоммуникациями, страхованием, банковским делом и здравоохранением, выходит за рамки нашего воображения.
До появления Hadoop хранение и обработка больших данных были большой проблемой. Но теперь, когда доступен Hadoop, компании осознали влияние больших данных на бизнес и то, как понимание этих данных будет способствовать росту. Например:
• У банковского сектора больше шансов понять лояльных клиентов, неплательщиков кредитов и мошеннических операций.
• Секторы розничной торговли теперь имеют достаточно данных для прогнозирования спроса.
• Производственные отрасли не должны зависеть от дорогостоящих механизмов проверки качества. Сбор данных датчиков и их анализ позволили бы выявить множество закономерностей.
• Электронная коммерция, социальные сети позволяют персонализировать страницы исходя из интересов клиентов.
• Фондовые рынки генерируют огромное количество данных, которые время от времени сопоставляются, чтобы выявить прекрасные идеи.
Большие данные имеют много полезных и проницательных приложений.
Hadoop — это прямое решение для обработки больших данных. Экосистема Hadoop представляет собой комбинацию технологий, обладающих значительными преимуществами в решении бизнес-задач.
Давайте разберемся с компонентами экосистемы Hadoop, чтобы создать правильные решения для данной бизнес-задачи.
Экосистема Hadoop:
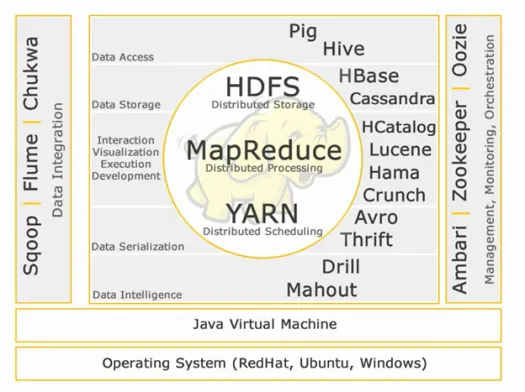

Ядро Хадуп:
HDFS:
HDFS расшифровывается как распределенная файловая система Hadoop для управления наборами больших данных с высоким объемом, скоростью и разнообразием. HDFS реализует архитектуру ведущий-ведомый. Мастер — это узел имени, а подчиненный — узел данных.
Функции:
• Масштабируемость
• Надежный
• Товарное оборудование
HDFS хорошо известна как хранилище больших данных.
Уменьшение карты:
Map Reduce — это модель программирования, предназначенная для обработки больших объемов распределенных данных. Платформа построена с использованием Java для лучшей обработки исключений. Map Reduce включает в себя два демона, средство отслеживания заданий и средство отслеживания задач.
Функции:
• Функциональное программирование.
• Очень хорошо работает с большими данными.
• Может обрабатывать большие наборы данных.
Map Reduce — основной компонент, известный обработкой больших данных.
ПРЯЖА:
YARN расшифровывается как Yet Another Resource Negotiator. Он также называется MapReduce 2 (MRv2). Две основные функции Job Tracker в MRv1, управление ресурсами и планирование/мониторинг заданий, разделены на отдельные демоны: ResourceManager, NodeManager и ApplicationMaster.
Функции:
• Лучшее управление ресурсами.
• Масштабируемость
• Динамическое выделение ресурсов кластера.
Доступ к данным:
Свинья:
Apache Pig — это язык высокого уровня, созданный на основе MapReduce для анализа больших наборов данных с помощью простых специализированных программ анализа данных. Свинья также известна как язык потока данных. Он очень хорошо интегрирован с python. Первоначально он был разработан Yahoo.
Отличительные черты свиньи:
• Простота программирования
• Возможности оптимизации
• Расширяемость.
Внутренние скрипты Pig будут преобразованы в программы уменьшения карты.

Улей:
Apache Hive — это еще один высокоуровневый язык запросов и инфраструктура хранилища данных, построенная поверх Hadoop для обеспечения суммирования, запроса и анализа данных. Первоначально он был разработан Yahoo и сделан с открытым исходным кодом.
Отличительные черты улья:
• SQL-подобный язык запросов под названием HQL.
• Разделение и группирование для более быстрой обработки данных.
• Интеграция с инструментами визуализации, такими как Tableau.
Внутренние запросы Hive будут преобразованы в программы уменьшения карты.
Если вы хотите стать аналитиком больших данных, вам необходимо знать эти два языка высокого уровня!

Хранилище данных:
Hbase:
Apache HBase — это база данных NoSQL, созданная для размещения больших таблиц с миллиардами строк и миллионами столбцов поверх общедоступных аппаратных машин Hadoop. Используйте Apache Hbase, когда вам нужен произвольный доступ для чтения и записи в режиме реального времени к вашим большим данным.
Функции:
• Строго согласованное чтение и запись. В операциях с памятью.
• Простой в использовании Java API для клиентского доступа.
• Хорошо интегрируется со свиньями, ульями и сквошами.
• Является последовательной и устойчивой к разбиению системой в теореме CAP.

Кассандра:
Cassandra — это база данных NoSQL, предназначенная для линейной масштабируемости и высокой доступности. Cassandra основана на модели ключ-значение. Разработан Facebook и известен более быстрым ответом на запросы.
Функции:
• Индексы столбцов
• Поддержка денормализации
• Материализованные представления
• Мощное встроенное кэширование.


Взаимодействие-Визуализация-исполнение-разработка:
Каталог:
HCatalog — это уровень управления таблицами, который обеспечивает интеграцию метаданных куста для других приложений Hadoop. Это позволяет пользователям с различными инструментами обработки данных, такими как Apache pig, Apache MapReduce и Apache Hive, более легко читать и записывать данные.
Функции:
• Табличный вид для различных форматов.
• Уведомления о доступности данных.
• REST API для внешних систем для доступа к метаданным.
Люсен:
Apache LuceneTM — это высокопроизводительная полнофункциональная библиотека механизма текстового поиска, полностью написанная на Java. Эта технология подходит практически для любого приложения, требующего полнотекстового поиска, особенно кросс-платформенного.
Функции:
• Масштабируемость, высокая производительность.
• Мощные, точные и эффективные алгоритмы поиска.
• Кроссплатформенное решение.
Хама:
Apache Hama — это распределенная среда, основанная на вычислениях Bulk Synchronous Parallel (BSP). Способен и хорошо известен массивными научными вычислениями, такими как матричные, графовые и сетевые алгоритмы.
Функции:
• Простая модель программирования
• Хорошо подходит для итерационных алгоритмов
• Пряжа поддерживается
• Совместная фильтрация неконтролируемого машинного обучения.
• Кластеризация K-средних.
Хруст:
Apache crunch создан для конвейерной обработки программ MapReduce, которые просты и эффективны. Эта структура используется для написания, тестирования и запуска конвейеров MapReduce.
Функции:
• Ориентация на разработчиков.
• Минимальные абстракции
• Гибкая модель данных.
Сериализация данных:
Авро:
Apache Avro — это платформа сериализации данных, не зависящая от языка. Разработан для языковой переносимости, что позволяет данным потенциально пережить язык для чтения и записи.

Бережливость:
Thrift — это язык, разработанный для создания интерфейсов для взаимодействия с технологиями, основанными на Hadoop. Он используется для определения и создания сервисов для множества языков.
Интеллект данных:
Дрель:
Apache Drill — это механизм запросов SQL с малой задержкой для Hadoop и NoSQL.
Функции:
• Ловкость
• Гибкость
• Знакомство.

Махаут:
Apache Mahout — это масштабируемая библиотека машинного обучения, предназначенная для построения предиктивной аналитики больших данных. Mahout теперь имеет реализации apache spark для более быстрого вычисления в памяти.
Функции:
• Совместная фильтрация.
• Классификация
• Кластеризация
• Снижение размерности

Интеграция данных:
Апач Скуп:

Apache Sqoop — это инструмент, предназначенный для массовой передачи данных между реляционными базами данных и Hadoop.
Функции:
• Импорт и экспорт в HDFS и обратно.
• Импорт и экспорт в Hive и из него.
• Импорт и экспорт в HBase.
Апач Флюм:
Flume — это распределенная, надежная и доступная служба для эффективного сбора, агрегирования и перемещения больших объемов данных журналов.
Функции:
• Крепкий
• Отказоустойчивой
• Простая и гибкая архитектура, основанная на потоковой передаче данных.

Апач Чуква:
Масштабируемый сборщик журналов, используемый для мониторинга больших распределенных файловых систем.
Функции:
• Масштабируется до тысяч узлов.
• Надежная доставка.
• Должна иметь возможность хранить данные неограниченное время.

Управление, мониторинг и оркестровка:
Апач Амбари:
Ambari разработан для упрощения управления Hadoop, предоставляя интерфейс для подготовки, управления и мониторинга кластеров Apache Hadoop.
Функции:
• Выделите кластер Hadoop.
• Управлять кластером Hadoop.
• Мониторинг кластера Hadoop.

Апачский зоопарк:
Zookeeper — это централизованная служба, предназначенная для хранения информации о конфигурации, именования, обеспечения распределенной синхронизации и предоставления групповых услуг.
Функции:
• Сериализация
• атомарность
• Надежность
• Простой API

Апач Узи:
Oozie — это система планировщика рабочих процессов для управления заданиями Apache Hadoop.
Функции:
• Масштабируемая, надежная и расширяемая система.
• Поддерживает несколько типов заданий Hadoop, таких как Map-Reduce, Hive, Pig и Sqoop.
• Простой и удобный в использовании.

Мы подробно обсудим компоненты в следующих статьях. Следите за обновлениями.