
Установка Hadoop с помощью Ambari
Опубликовано: 2015-12-11Все, что вы хотите знать об установке Hadoop с помощью Ambari
Apache Hadoop де-факто стал программной средой для надежных, масштабируемых, распределенных и крупномасштабных вычислений. В отличие от других вычислительных систем, он выполняет вычисления для данных, а не отправляет данные для вычислений. Hadoop был создан в 2006 году в Yahoo Дугом Каттингом на основе статьи, опубликованной Google. По мере развития Hadoop в его экосистему с годами добавлялось множество новых компонентов и инструментов для повышения удобства использования и функциональности. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop и т. д. и многие другие.
Почему Амбари?
С ростом популярности Hadoop многие разработчики берутся за эту технологию, чтобы попробовать ее на вкус. Но, как говорится, Hadoop не для слабонервных, многие разработчики даже не смогли перешагнуть барьер установки Hadoop. Многие дистрибутивы предлагают предустановленную песочницу виртуальных машин, чтобы попробовать что-то новое, но это не дает вам ощущения распределенных вычислений. Однако установка мультиузла — непростая задача, а с растущим числом компонентов очень сложно справиться с таким количеством параметров конфигурации. К счастью, Apache Ambari приходит нам на помощь!
Что такое Амбари?
Apache Ambari — это веб-инструмент для подготовки, управления и мониторинга кластеров Apache Hadoop. Ambari предоставляет панель инструментов для просмотра состояния кластера, например тепловых карт, и возможность визуального просмотра приложений MapReduce, Pig и Hive, а также функции для диагностики их характеристик производительности в удобной для пользователя форме. Он имеет очень простой и интерактивный пользовательский интерфейс для установки различных инструментов и выполнения различных задач управления, настройки и мониторинга. Ниже мы рассмотрим различные этапы установки Hadoop и различных компонентов экосистемы в многоузловом кластере.
Архитектура Ambari показана ниже
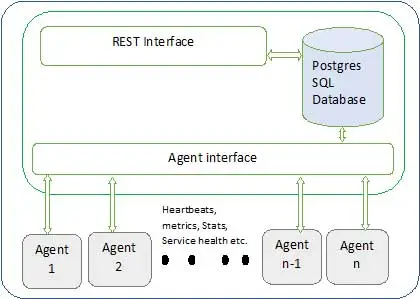
Амбари состоит из двух компонентов
- Сервер Ambari — это главный процесс, который взаимодействует с агентами Ambari, установленными на каждом узле, участвующем в кластере. У него есть экземпляр базы данных postgres, который используется для хранения всех метаданных, связанных с кластером.
- Агент Ambari — действующие агенты Ambari на каждом узле. Каждый агент периодически отправляет свой собственный статус работоспособности вместе с различными метриками, статусом установленных служб и многим другим. В соответствии с мастером принимает решение о следующем действии и возвращает агенту действие.
Как установить Амбари?
Установка Ambari — это простая задача, выполняемая несколькими командами.
Мы рассмотрим установку Ambari и настройку кластера. Предполагается, что у нас есть 4 узла. Узел1, Узел2, Узел3 и Узел4. И мы выбираем Node1 в качестве нашего сервера Ambari.
Это шаги установки в системе на основе RHEL, для Debian и других систем шаги мало чем отличаются.
- Установка Амбари: –
С серверного узла Ambari (узел 1, как мы решили)
я. Скачать общедоступный репозиторий Ambari

Эта команда добавит репозиторий Hortonworks Ambari в yum, который является менеджером пакетов по умолчанию для систем RHEL.
ii.Установите Ambari RPMS

Это займет некоторое время и установит Ambari в этой системе.

III. Настройка сервера Амбари
Следующее, что нужно сделать после установки Ambari, — настроить Ambari и настроить его для подготовки кластера.
Следующий шаг позаботится об этом


IV. Запустите сервер и войдите в веб-интерфейс
Запустите сервер с

Теперь мы можем получить доступ к веб-интерфейсу Ambari (размещенному на порту 8080).
Войдите в Ambari с именем пользователя по умолчанию «admin» и паролем по умолчанию «admin».
Настройка кластера Hadoop
1. Целевая страница
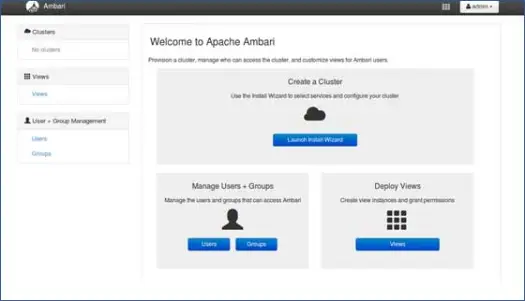
Нажмите «Запустить мастер установки», чтобы начать настройку кластера.
2. Имя кластера
Дайте вам кластер хорошее имя.
Примечание. Это простое имя для кластера, оно не имеет большого значения, поэтому не беспокойтесь об этом и выберите для него любое имя.
3. Выбор стека
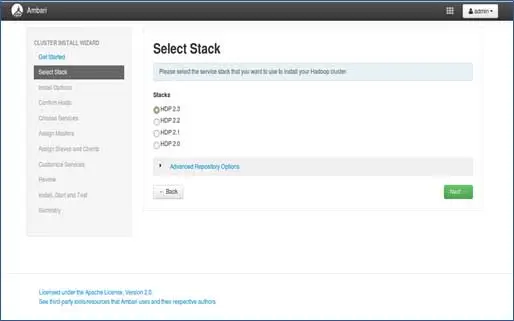
На этой странице будут перечислены стеки, доступные для установки. Каждый стек предварительно упакован с компонентом экосистемы Hadoop. Эти стеки от Hortonworks. (Мы также можем установить простой Hadoop. Об этом мы расскажем в следующих постах).
4. Ввод хостов и ввод ключа SSH
Прежде чем перейти к этому шагу, мы должны настроить SSH без пароля для всех участвующих узлов.

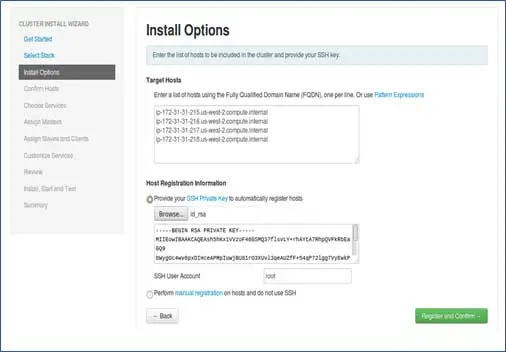
Добавьте имена хостов узлов, по одной записи в каждой строке. [Добавить полное доменное имя, которое можно получить с помощью команды hostname –f]. Выберите закрытый ключ, используемый при настройке SSH без пароля, и имя пользователя, с помощью которого был создан закрытый ключ.
5. Статус регистрации хостов
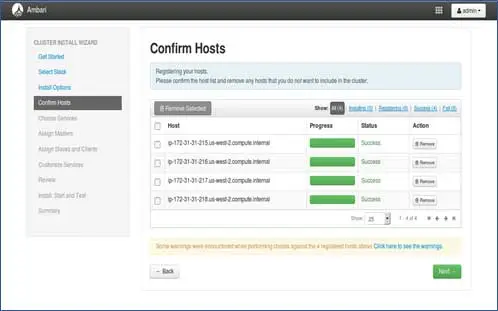
Вы можете увидеть некоторые выполняемые операции, эти операции включают настройку Ambari-агента на каждом узле, создание базовых настроек на каждом узле. Как только мы увидим ALL GREEN, мы готовы двигаться дальше. Иногда это может занять некоторое время, так как устанавливается несколько пакетов.

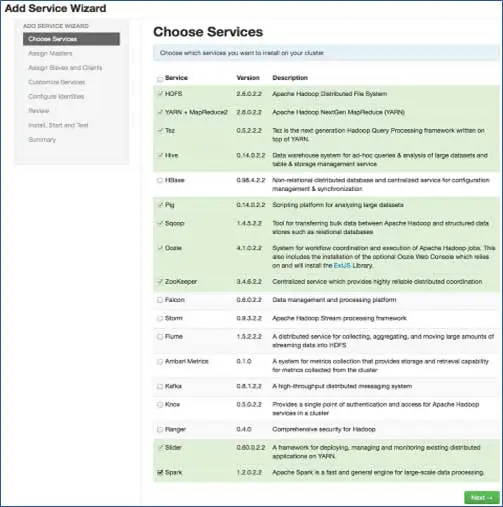
6. Выберите службы, которые хотите установить
В соответствии с выбранными стеками на шаге 3 у нас есть количество сервисов, которые мы можем установить в кластере. Вы можете выбрать тот, который вы хотите. Ambari интеллектуально выбирает зависимые службы, если вы их не выбрали. Например, вы выбрали HBase, но не Zookeeper, он предложит то же самое и добавит Zookeeper в кластер.
7. Сопоставление основных сервисов с узлами
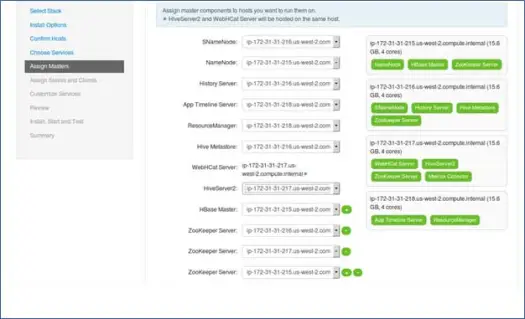
Как вы знаете, в экосистеме Hadoop есть инструменты, основанные на архитектуре master-slave. На этом шаге мы свяжем основные процессы с узлом. Здесь убедитесь, что вы правильно сбалансировали свой кластер. Кроме того, имейте в виду, что первичные и вторичные службы, такие как Namenode и вторичный Namenode, не находятся на одном компьютере.

8. Сопоставление ведомых устройств с узлами
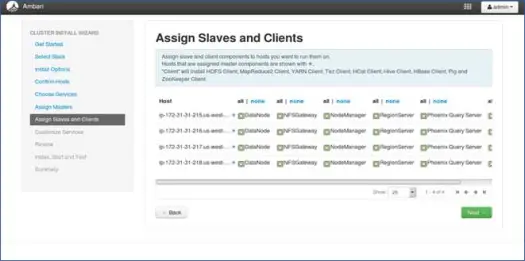
Подобно мастерам, сопоставьте подчиненные службы с узлами. Как правило, на всех узлах будет запущен подчиненный процесс, по крайней мере, для узлов данных и менеджеров узлов.
9. Настройка услуг
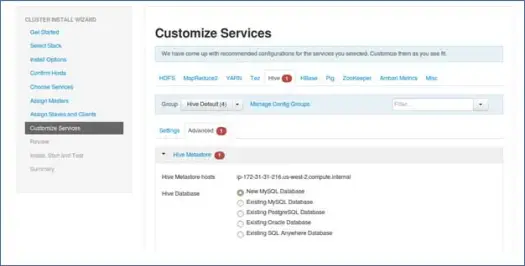
Это очень важная страница для администраторов.
Здесь вы можете настроить свойства вашего кластера, чтобы сделать его наиболее подходящим для ваших вариантов использования.
Также у него будут некоторые необходимые свойства, такие как пароль хранилища метаданных Hive (если выбран куст) и т. д. Они будут отмечены красной ошибкой, например, символами.
10. Просмотрите и начните подготовку
Убедитесь, что вы проверили конфигурацию кластера перед запуском, так как это убережет от неосознанно установленных неправильных конфигураций.
11. Запустите и оставайтесь на месте, пока статус не станет ЗЕЛЕНЫМ.
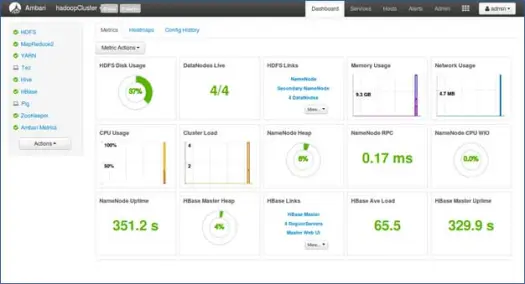
Следующие шаги
Ура! Мы успешно установили Hadoop и все компоненты на все узлы кластера. Теперь мы можем начать играть с Hadoop.
Ambari запускает задание подсчета слов MapReduce, чтобы проверить, все ли работает нормально. Давайте проверим журнал, в котором задание выполнялось пользователем ambari-qa.
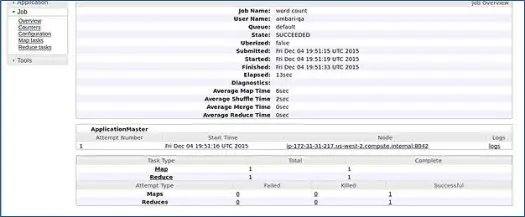
Как вы можете видеть на скриншоте выше, задание WordCount успешно завершено. Это подтверждает, что наш кластер работает нормально.
Заключение
Вот и все, теперь мы научились устанавливать Hadoop и его компоненты в многоузловом кластере с помощью простого веб-инструмента под названием Apache Ambari. Apache Ambari предоставляет нам более простой интерфейс и экономит наши усилия по установке, мониторингу и управлению, которые были бы очень утомительными с таким количеством компонентов и их различными этапами установки и элементами управления мониторингом.
Позвольте мне оставить вас взломать

Установщик Ambari проверяет /etc/lsb-release, чтобы получить сведения об ОС. В Linux Mint тот же файл для версии Ubuntu находится в /etc/upstream-release/lsb-release. Чтобы обмануть установщика, просто замените первое на второе (сначала сделайте резервную копию файла).

В какой-то момент после завершения установки вы можете восстановить оригинал с помощью:

PS Это взлом без каких-либо гарантий, у меня он работал, поэтому я решил поделиться им с вами.
Вы разработчик/dev-ops и вам нужно быстро установить Hadoop. У нас для вас хорошие новости: Ambari предоставляет способ, с помощью которого вы можете пропустить весь процесс мастера и завершенный процесс установки с помощью одного скрипта, и я представлю его в следующем посте, так что следите за обновлениями, а пока счастливого Hadooping!