
Руководство SEO для понимания больших языковых моделей (LLM)
Опубликовано: 2023-05-08Должен ли я использовать большие языковые модели для исследования ключевых слов? Могут ли эти модели думать? ChatGPT — мой друг?
Если вы задавали себе эти вопросы, то это руководство для вас.
В этом руководстве рассказывается, что необходимо знать SEO-специалистам о больших языковых моделях, обработке естественного языка и обо всем, что между ними.
Большие языковые модели, обработка естественного языка и многое другое простыми словами
Есть два способа заставить человека что-то сделать — сказать ему сделать это или надеяться, что он сделает это сам.
Когда дело доходит до информатики, программирование говорит роботу сделать это, в то время как машинное обучение надеется, что робот сделает это сам. Первое — это машинное обучение с учителем, а второе — машинное обучение без учителя.
Обработка естественного языка (NLP) — это способ разбить текст на числа, а затем проанализировать его с помощью компьютеров.
Компьютеры анализируют закономерности в словах и, по мере развития, в отношениях между словами.
Неконтролируемая модель машинного обучения на естественном языке может быть обучена на множестве различных наборов данных.
Например, если вы обучили языковую модель на средних отзывах о фильме «Водный мир», вы получите хороший результат при написании (или понимании) отзывов о фильме «Водный мир».
Если бы вы обучали его двум положительным отзывам о фильме «Водный мир», которые я сделал, он бы понял только эти положительные отзывы.
Большие языковые модели (LLM) — это нейронные сети с более чем миллиардом параметров. Они настолько велики, что являются более обобщенными. Их обучают не только положительным и отрицательным отзывам о «Водном мире», но и комментариям, статьям в Википедии, новостным сайтам и многому другому.
Проекты машинного обучения много работают с контекстом — вещи внутри и вне контекста.
Если у вас есть проект машинного обучения, который идентифицирует ошибки и показывает им кошку, он не будет хорош в этом проекте.
Вот почему такие вещи, как самоуправляемые автомобили, так сложны: существует так много вырванных из контекста проблем, что очень трудно обобщить эти знания.
LLM кажутся и могут быть гораздо более обобщенный, чем другие проекты машинного обучения. Это из-за огромного размера данных и способности анализировать миллиарды различных взаимосвязей.
Поговорим об одной из прорывных технологий, позволяющих это сделать, — трансформаторах.
Объяснение трансформаторов с нуля
Тип архитектуры нейронной сети, преобразователи произвели революцию в области НЛП.
До трансформеров большинство моделей НЛП опирались на технику, называемую рекуррентными нейронными сетями (РНС), которая обрабатывала текст последовательно, по одному слову за раз. У этого подхода были свои ограничения, такие как медлительность и трудности с обработкой длинных зависимостей в тексте.
Трансформеры изменили это.
В исторической статье 2017 года «Внимание — это все, что вам нужно» Васвани и др. представил архитектуру трансформатора.
Вместо последовательной обработки текста трансформеры используют механизм под названием «самовнимание» для параллельной обработки слов, что позволяет им более эффективно фиксировать долгосрочные зависимости.
Предыдущая архитектура включала RNN и алгоритмы длинной кратковременной памяти.
Рекуррентные модели, подобные этим, обычно использовались (и до сих пор используются) для задач, связанных с последовательностями данных, такими как текст или речь.
Однако у этих моделей есть проблема. Они могут обрабатывать данные только по одному фрагменту за раз, что замедляет их работу и ограничивает объем данных, с которыми они могут работать. Эта последовательная обработка действительно ограничивает возможности этих моделей.
Механизмы внимания были введены как другой способ обработки данных последовательности. Они позволяют модели просматривать все части данных одновременно и решать, какие части являются наиболее важными.
Это может быть очень полезно во многих задачах. Однако большинство моделей, использующих внимание, также используют рекуррентную обработку.
По сути, у них был такой способ обработки данных одновременно, но им все равно нужно было смотреть на них по порядку. В статье Васвани и др. всплывало: «Что, если бы мы использовали только механизм внимания?»
Внимание — это способ, с помощью которого модель может сосредоточиться на определенных частях входной последовательности при ее обработке. Например, когда мы читаем предложение, мы, естественно, обращаем больше внимания на одни слова, чем на другие, в зависимости от контекста и того, что мы хотим понять.
Если вы посмотрите на преобразователь, модель вычисляет оценку для каждого слова во входной последовательности в зависимости от того, насколько оно важно для понимания общего значения последовательности.
Затем модель использует эти оценки для взвешивания важности каждого слова в последовательности, что позволяет больше сосредоточиться на важных словах и меньше на неважных.
Этот механизм внимания помогает модели фиксировать долгосрочные зависимости и отношения между словами, которые могут быть далеко друг от друга во входной последовательности, без необходимости последовательной обработки всей последовательности.
Это делает преобразователь настолько мощным для задач обработки естественного языка, поскольку он может быстро и точно понимать значение предложения или более длинной последовательности текста.
Возьмем пример модели-трансформера, обрабатывающей предложение «Кошка села на коврик».
Каждое слово в предложении представлено в виде вектора, последовательности чисел, с использованием матрицы вложения. Допустим, вложения для каждого слова:
- : [0,2, 0,1, 0,3, 0,5]
- кошка : [0,6, 0,3, 0,1, 0,2]
- сб : [0,1, 0,8, 0,2, 0,3]
- на : [0,3, 0,1, 0,6, 0,4]
- : [0,5, 0,2 , 0,1, 0,4]
- мат : [0,2, 0,4, 0,7, 0,5]
Затем преобразователь вычисляет оценку для каждого слова в предложении на основе его связи со всеми другими словами в предложении.
Это делается с помощью скалярного произведения встраивания каждого слова с вложениями всех других слов в предложении.
Например, чтобы вычислить оценку для слова «кошка», мы возьмем скалярное произведение его вложения с вложениями всех других слов:
- « Кошка »: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- « кошка сидела »: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- « кошка на »: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- « кошка »: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- « кошачий коврик »: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Эти баллы указывают на релевантность каждого слова слову «кошка». Затем преобразователь использует эти оценки для вычисления взвешенной суммы вложений слов, где весами являются оценки.
Это создает вектор контекста для слова «кошка», который учитывает отношения между всеми словами в предложении. Этот процесс повторяется для каждого слова в предложении.
Думайте об этом как о преобразователе, рисующем линию между каждым словом в предложении на основе результата каждого вычисления. Одни линии более тонкие, другие менее.
Преобразователь — это новый тип модели, который использует только внимание без какой-либо периодической обработки. Это делает его намного быстрее и позволяет обрабатывать больше данных.
Как GPT использует трансформаторы
Возможно, вы помните, что в объявлении Google BERT они хвастались тем, что это позволяет поиску понимать полный контекст ввода. Это похоже на то, как GPT может использовать трансформаторы.
Воспользуемся аналогией.
Представьте, что у вас есть миллион обезьян, каждая из которых сидит перед клавиатурой.
Каждая обезьяна случайным образом нажимает клавиши на своей клавиатуре, создавая цепочки букв и символов.
Некоторые строки — полная ерунда, а другие могут напоминать настоящие слова или даже связные предложения.
Однажды один из дрессировщиков цирка видит, что обезьяна написала «Быть или не быть», поэтому дрессировщик дает обезьянке лакомство.
Другие обезьяны видят это и начинают пытаться подражать успешной обезьяне, надеясь на собственное угощение.
Со временем некоторые обезьяны начинают последовательно воспроизводить более качественные и связные текстовые строки, в то время как другие продолжают производить тарабарщину.
В конце концов, обезьяны могут распознавать и даже подражать связным паттернам в тексте.
У LLM есть преимущество над обезьянами, потому что LLM сначала обучаются на миллиардах фрагментов текста. Они уже могут видеть закономерности. Они также понимают векторы и отношения между этими фрагментами текста.
Это означает, что они могут использовать эти шаблоны и отношения для создания нового текста, напоминающего естественный язык.
GPT (Generative Pre-trained Transformer) — это языковая модель, использующая преобразователи для генерации текста на естественном языке.
Он был обучен на огромном количестве текста из Интернета, что позволило ему изучить закономерности и отношения между словами и фразами на естественном языке.
Модель работает, принимая подсказку или несколько слов текста и используя преобразователи, чтобы предсказать, какие слова должны быть следующими, на основе шаблонов, которые она извлекла из своих обучающих данных.
Модель продолжает генерировать текст слово за словом, используя контекст предыдущих слов для информирования следующих.
GPT в действии
Одним из преимуществ GPT является то, что он может генерировать текст на естественном языке, который является очень связным и контекстуально релевантным.
Это имеет много практических применений, таких как создание описаний продуктов или ответы на запросы клиентов. Его также можно использовать творчески, например, для создания стихов или коротких рассказов.
Однако это всего лишь языковая модель. Он обучается на данных, и эти данные могут быть устаревшими или неверными.
- У него нет источника знаний.
- Он не может искать в Интернете.
- Он ничего не «знает».
Он просто угадывает, какое слово будет следующим.
Давайте рассмотрим несколько примеров:
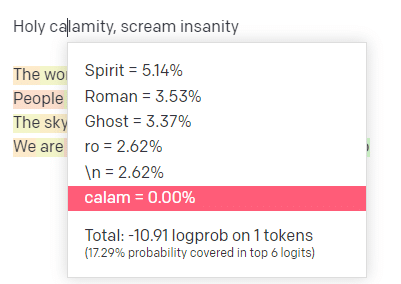
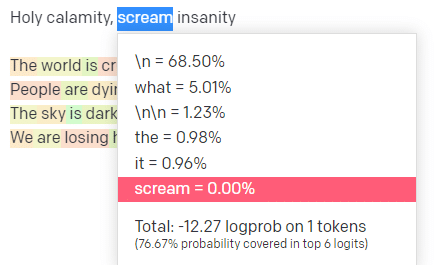
На игровой площадке OpenAI я вставил первую строчку классического трека «Святое бедствие [[Bear Witness ii]]» из классического трека Handsome Boy Modeling School.
Я отправил ответ, чтобы мы могли увидеть вероятность как моих входных, так и выходных строк. Итак, давайте пройдемся по каждой части того, что это нам говорит.
Для первого слова/токена я ввожу «Святой». Мы видим, что наиболее ожидаемый следующий ввод — это Дух, Роман и Призрак.
Мы также можем видеть, что первые шесть результатов охватывают только 17,29% вероятностей того, что будет дальше: это означает, что есть ~82% других возможностей, которые мы не можем увидеть в этой визуализации.
Давайте кратко обсудим различные входные данные, которые вы можете использовать при этом, и то, как они влияют на ваш результат.
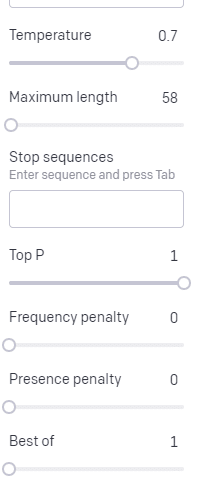
Температура — это вероятность того, что модель захватит слова, отличные от слов с наибольшей вероятностью, а верхнее значение P — это то, как она выбирает эти слова.
Таким образом, для ввода «Священное бедствие» верхнее значение P — это то, как мы выбираем кластер следующих токенов [Призрак, Римлянин, Дух], а температура — это вероятность того, что наиболее вероятный токен будет выбран по сравнению с большим разнообразием.
Если температура выше, вероятность выбора менее вероятного маркера выше.
Таким образом, высокая температура и высокое верхнее P, вероятно, будут более дикими. Он выбирает из большого разнообразия (высокая вершина P) и с большей вероятностью выберет неожиданные жетоны.


В то время как высокая температура, но более низкий верхний P будет выбирать неожиданные варианты из меньшей выборки возможностей:

А понижение температуры просто выбирает наиболее вероятные следующие токены:

По моему мнению, игра с этими вероятностями может дать вам хорошее представление о том, как работают такие модели.
Он просматривает набор возможных следующих выборов на основе того, что уже сделано.
Что это значит на самом деле?
Проще говоря, LLM берут набор входных данных, встряхивают их и превращают в выходные данные.
Я слышал, как люди шутили о том, так ли это отличается от людей.
Но это не похоже на людей – у LLM нет базы знаний. Они не извлекают информацию о вещах. Они угадывают последовательность слов на основе последнего.
Другой пример: подумайте о яблоке. Что приходит на ум?
Может быть, вы можете вращать один в своем уме.
Возможно, вы помните запах яблоневого сада, сладость розовой дамы и т. д.
Может быть, вы думаете о Стиве Джобсе.
Теперь давайте посмотрим, что возвращает подсказка «подумай о яблоке».
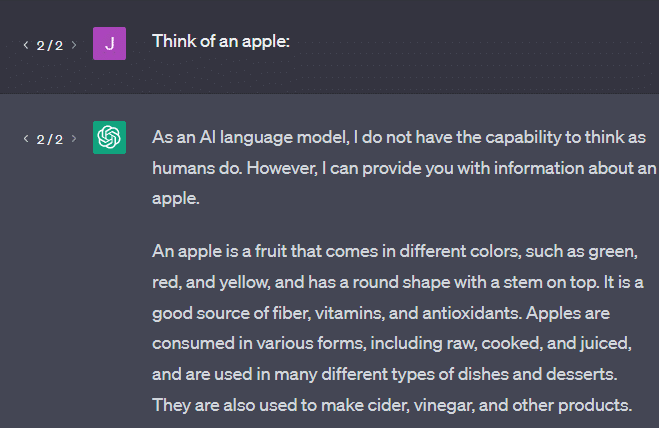
Возможно, к этому моменту вы уже слышали слова «стохастические попугаи».
Стохастические попугаи — это термин, используемый для описания LLM, таких как GPT. Попугай — это птица, которая имитирует то, что слышит.
Таким образом, LLM подобны попугаям в том смысле, что они принимают информацию (слова) и выводят что-то похожее на то, что они услышали. Но они также являются стохастическими , что означает, что они используют вероятность, чтобы угадать, что будет дальше.
LLM хорошо распознают закономерности и отношения между словами, но у них нет более глубокого понимания того, что они видят. Вот почему они так хорошо генерируют текст на естественном языке, но не понимают его.
Хорошее использование для LLM
LLM хорошо справляются с более общими задачами.
Вы можете показать ему текст, и без обучения он сможет выполнить задачу с этим текстом.
Вы можете передать ему какой-нибудь текст и попросить провести анализ тональности, попросить перевести этот текст в структурированную разметку и выполнить некоторую творческую работу (например, написание набросков).
Это нормально в таких вещах, как код. Для многих задач это может почти помочь вам.
Но опять же, это основано на вероятности и закономерностях. Так что будут времена, когда он уловит шаблоны в вашем вводе, о которых вы не знаете.
Это может быть позитивным (видеть закономерности, недоступные людям), но также и негативным (почему он так отреагировал?).
Он также не имеет доступа к каким-либо источникам данных. SEO-специалистам, которые используют его для поиска ключевых слов ранжирования, придется плохо.
Он не может искать трафик по ключевому слову. У него нет информации для данных ключевых слов, кроме того, что слова существуют.

Самое интересное в ChatGPT заключается в том, что это легкодоступная языковая модель, которую вы можете использовать «из коробки» для решения различных задач. Но не без оговорок.

Хорошее применение для других моделей машинного обучения
Я слышал, что люди говорят, что они используют LLM для определенных задач, с которыми другие алгоритмы и методы НЛП справляются лучше.
Возьмем, к примеру, извлечение ключевых слов.
Если я использую TF-IDF или другой метод ключевых слов для извлечения ключевых слов из корпуса, я знаю, какие вычисления выполняются в этом методе.
Это означает, что результаты будут стандартными, воспроизводимыми, и я знаю, что они будут связаны именно с этим корпусом.
С LLM, такими как ChatGPT, если вы запрашиваете извлечение ключевых слов, вы не обязательно получаете ключевые слова, извлеченные из корпуса. Вы получаете то, что GPT считает ответом на ключевые слова корпуса + извлечения.
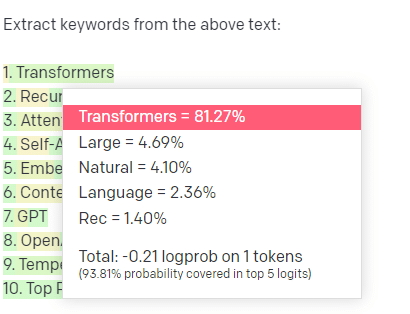
Это похоже на такие задачи, как кластеризация или анализ настроений. Вы не обязательно получите точно настроенный результат с заданными вами параметрами. Вы получаете то, что с некоторой вероятностью основано на других подобных задачах.
Опять же, у LLM нет базы знаний и текущей информации. Они часто не могут искать в Интернете и анализируют полученную информацию в виде статистических токенов. Ограничения на продолжительность памяти LLM связаны с этими факторами.
Другое дело, что эти модели не умеют думать. Я использую слово «думать» всего несколько раз в этой статье, потому что действительно трудно не использовать его, говоря об этих процессах.
Тенденция к антропоморфизму, даже когда речь идет о причудливой статистике.
Но это означает, что если вы доверяете LLM любую задачу, требующую «размышления», вы не доверяете мыслящему существу.
Вы доверяете статистическому анализу того, как сотни интернет-чудаков реагируют на подобные жетоны.
Если вы доверяете задачу интернет-жителям, вы можете использовать LLM. В противном случае…
Вещи, которые никогда не должны быть моделями машинного обучения
Сообщается, что чат-бот, запущенный через модель GPT (GPT-J), подтолкнул человека к самоубийству. Совокупность факторов может причинить реальный вред, в том числе:
- Люди очеловечивают эти ответы.
- Считая их непогрешимыми.
- Использование их в местах, где люди должны находиться в машине.
- И более.
Хотя вы можете подумать: «Я оптимизатор. Я не имею отношения к системам, которые могут кого-то убить!»
Подумайте о страницах YMYL и о том, как Google продвигает такие концепции, как EEAT.
Делает ли Google это, потому что хочет досадить SEO-специалистам, или потому, что не хочет брать на себя вину за этот вред?
Даже в системах с сильными базами знаний можно нанести вред.
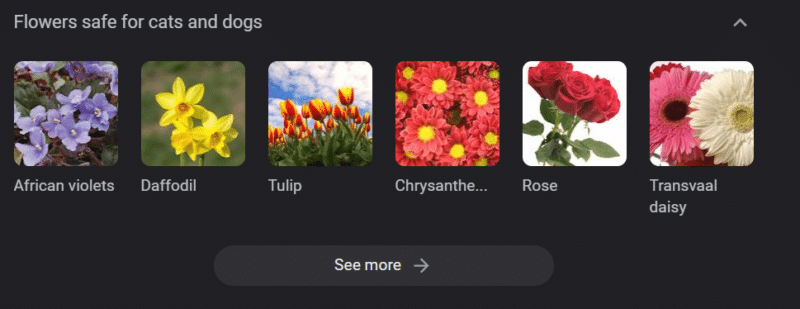
Выше приведена карусель знаний Google для «цветов, безопасных для кошек и собак». Нарциссы находятся в этом списке, несмотря на то, что они токсичны для кошек.
Предположим, вы создаете контент для ветеринарного веб-сайта с помощью GPT. Вы подключаете кучу ключевых слов и пингуете ChatGPT API.
У вас есть фрилансер, читающий все результаты, а не предметный эксперт. Они не замечают проблему.
Вы публикуете результат, который побуждает владельцев кошек покупать нарциссы.
Вы убиваете чью-то кошку.
Не напрямую. Может быть, они даже не знают, что это именно тот сайт.
Может быть, другие ветеринарные сайты начнут делать то же самое и подпитывать друг друга.
Самый популярный результат поиска Google по запросу «ядовиты ли нарциссы для кошек» — это сайт, в котором говорится, что это не так.
Другие фрилансеры читают другой контент ИИ — страницы за страницами контента ИИ — фактически проверяют факты. Но системы теперь имеют неверную информацию.
Обсуждая нынешний бум ИИ, я часто упоминаю Therac-25. Это известный случай компьютерного злодеяния.
По сути, это был аппарат лучевой терапии, первый, в котором использовались только компьютерные механизмы блокировки. Сбой в программном обеспечении привел к тому, что люди получили в десятки тысяч раз больше дозы облучения, чем должны были получить.
Что меня всегда бросается в глаза, так это то, что компания добровольно отозвала и проверила эти модели.
Но они предположили, что, поскольку технология была продвинутой, а программное обеспечение «безотказным», проблема была связана с механическими частями машины.
Таким образом, отремонтировали механизмы, но не проверили программное обеспечение – и Therac-25 остался на рынке.
Часто задаваемые вопросы и заблуждения
Почему ChatGPT лжет мне?
Одна вещь, которую я слышал от некоторых из величайших умов нашего поколения, а также влиятельных лиц в Твиттере, — это жалоба на то, что ChatGPT «лжет» им. Это происходит из-за нескольких неправильных представлений в тандеме:
- У ChatGPT есть «желания».
- Что у него есть база знаний.
- Что у технологов, стоящих за этой технологией, есть некая цель, помимо «заработать деньги» или «сделать крутую вещь».
Предубеждения присутствуют в каждой части вашей повседневной жизни. Так же как и исключения из этих предубеждений.
Большинство разработчиков программного обеспечения в настоящее время — мужчины: я — разработчик программного обеспечения и женщина.
Обучение ИИ на основе этой реальности привело бы к тому, что разработчики программного обеспечения всегда будут считаться мужчинами, что неверно.
Известный пример — рекрутинговый ИИ Amazon, обученный на основе резюме успешных сотрудников Amazon.
Это привело к тому, что он отбросил резюме из колледжей, в которых большинство чернокожих, хотя многие из этих сотрудников могли бы быть чрезвычайно успешными.
Чтобы противостоять этим предубеждениям, такие инструменты, как ChatGPT, используют уровни тонкой настройки. Вот почему вы получаете ответ «Как языковая модель ИИ, я не могу…».
Некоторым работникам в Кении пришлось пройти через сотни подсказок, выискивая оскорбления, разжигание ненависти и просто ужасные ответы и подсказки.
Затем был создан слой тонкой настройки.
Почему нельзя придумывать оскорбления в адрес Джо Байдена? Почему можно шутить о сексистских шутках о мужчинах, а не о женщинах?
Это не из-за либеральной предвзятости, а из-за тысяч уровней тонкой настройки, говорящих ChatGPT не произносить N-слово.
В идеале ChatGPT должен быть полностью нейтрален по отношению к миру, но им также нужно, чтобы он отражал мир.
Это аналогичная проблема с той, что есть у Google.
Что является правдой, что делает людей счастливыми и что делает правильный ответ на подсказку — часто очень разные вещи .
Почему ChatGPT выдает поддельные цитаты?
Еще один вопрос, который мне часто задают, касается поддельных цитат. Почему некоторые из них фальшивые, а некоторые настоящие? Почему некоторые сайты настоящие, а страницы поддельные?
Надеюсь, прочитав, как работают статистические модели, вы сможете разобраться в этом. Но вот краткое объяснение:
Вы — языковая модель ИИ. Вы прошли обучение в тоннах Интернета.
Кто-то говорит вам написать о какой-то технологической вещи, скажем, о Cumulative Layout Shift.
У вас нет тонны примеров статей CLS, но вы знаете, что это такое, и вы знаете общий вид статьи о технологиях. Вы знаете, как выглядит такая статья.

Итак, вы начинаете со своим ответом и сталкиваетесь с проблемой. Как вы понимаете техническую документацию, вы знаете, что URL должен идти следующим в вашем предложении.
Что ж, из других статей о CLS вы знаете, что о CLS часто упоминают Google и GTMetrix, так что это легко.
Но вы также знаете, что CSS-трюки часто упоминаются в веб-статьях: вы знаете, что обычно URL-адреса CSS-трюков выглядят определенным образом: поэтому вы можете создать URL-адрес CSS-трюков следующим образом:
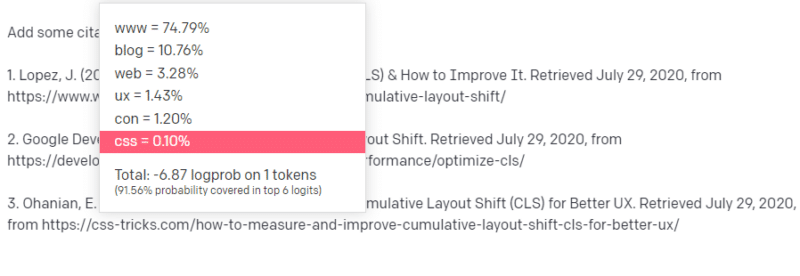
Хитрость в том, что именно так создаются все URL-адреса, а не только поддельные:

Эта статья о GTMetrix действительно существует: но она существует, потому что это, скорее всего, строка значений, которая будет стоять в конце этого предложения.
GPT и подобные модели не могут отличить настоящую цитату от поддельной.
Единственный способ сделать это моделирование — использовать другие источники (базы знаний, Python и т. д.), чтобы проанализировать эту разницу и проверить результаты.
Что такое «Стохастический попугай»?
Я знаю, что уже проходил это, но стоит повторить. Стохастические попугаи — это способ описания того, что происходит, когда большие языковые модели кажутся универсальными по своей природе.
Для LLM ерунда и реальность — одно и то же. Они видят мир как экономист, как набор статистики и цифр, описывающих реальность.
Вы знаете цитату: «Есть три вида лжи: ложь, наглая ложь и статистика».
LLM — это большая куча статистических данных.
LLM кажутся последовательными, но это потому, что мы в основном видим вещи, которые кажутся человеческими, как человеческие.
Точно так же модель чат-бота скрывает большую часть подсказок и информации, необходимых для полной согласованности ответов GPT.
Я разработчик: попытка использовать LLM для отладки моего кода приводит к очень разным результатам. Если это проблема, похожая на ту, с которой люди часто сталкивались в Интернете, LLM могут обнаружить и исправить этот результат.
Если это проблема, с которой он раньше не сталкивался, или это небольшая часть корпуса, то он ничего не исправит.
Почему GPT лучше поисковой системы?
Я сформулировал это в пикантной форме. Я не думаю, что GPT лучше поисковой системы. Меня беспокоит, что люди заменили поиск на ChatGPT.
Одна недооцененная часть ChatGPT заключается в том, что он существует для следования инструкциям. Вы можете попросить его сделать что угодно.
Но помните, все это основано на статистическом следующем слове в предложении, а не на истине.
Поэтому, если вы зададите ему вопрос, на который нет хорошего ответа, но зададите его таким образом, на который он обязан ответить, вы получите плохой ответ.
Иметь ответ, предназначенный для вас и окружающих вас людей, гораздо утешительнее, но мир — это масса впечатлений.
Все входные данные в LLM обрабатываются одинаково: но у некоторых людей есть опыт, и их ответ будет лучше, чем смесь ответов других людей.
Один эксперт стоит больше, чем тысяча идей.
Это рассвет ИИ? Скайнет здесь?
Горилла Коко была обезьяной, которую научили языку жестов. Исследователи в области лингвистики провели массу исследований, доказывающих, что обезьян можно научить языку.
Затем Герберт Террас обнаружил, что обезьяны не составляли предложения или слова, а просто подражали своим человеческим дрессировщикам.
Элиза была машинным терапевтом, одной из первых болтунов (чатботов).
Люди видели в ней личность: терапевта, которому они доверяли и о котором заботились. Они попросили исследователей остаться с ней наедине.
Язык делает что-то очень специфическое с человеческим мозгом. Люди слышат что-то сообщающееся и ожидают мысли за этим.
LLM впечатляют, но таким образом они демонстрируют широту человеческих достижений.
У LLM нет завещания. Они не могут убежать. Они не могут пытаться захватить мир.
Это зеркало: отражение людей и пользователя в частности.
Единственная мысль есть статистическое представление коллективного бессознательного.
Выучил ли GPT целый язык сам по себе?
Сундар Пичаи, генеральный директор Google, продолжил «60 минут» и заявил, что языковая модель Google выучила бенгальский язык.
Модель обучалась на этих текстах. Неправильно, что он «говорил на иностранном языке, знать который его никогда не учили».
Бывают случаи, когда ИИ делает неожиданные вещи, но это само по себе ожидаемо.
Когда вы смотрите на закономерности и статистику в большом масштабе, обязательно будут моменты, когда эти закономерности откроют что-то удивительное.
Что это действительно показывает, так это то, что многие из топ-менеджеров и маркетологов, которые торгуют искусственным интеллектом и машинным обучением, на самом деле не понимают, как работают эти системы.
Я слышал, как некоторые очень умные люди говорили об эмерджентных свойствах, общем искусственном интеллекте (AGI) и других футуристических вещах.
Я могу быть простым деревенским инженером по машинному обучению, но это показывает, как много шумихи, обещаний, научной фантастики и реальности сливается воедино, когда речь идет об этих системах.
Элизабет Холмс, печально известная основательница Theranos, была распята за обещания, которые невозможно было сдержать.
Но цикл невыполнимых обещаний является частью культуры стартапов и зарабатывания денег. Разница между Theranos и рекламой искусственного интеллекта в том, что Theranos не могла долго ее подделывать.
GPT — это черный ящик? Что происходит с моими данными в GPT?
GPT, как модель, не является черным ящиком. Вы можете увидеть исходный код для GPT-J и GPT-Neo.
Однако GPT OpenAI — это черный ящик. OpenAI не выпустила и, вероятно, попытается не выпускать свою модель, поскольку Google не выпускает алгоритм.
Но это не потому, что алгоритм слишком опасен. Если бы это было правдой, они бы не продавали подписку на API какому-нибудь глупцу с компьютером. Это из-за ценности этой проприетарной кодовой базы.
Когда вы используете инструменты OpenAI, вы обучаете их API и подпитываете их своими входными данными. Это означает, что все, что вы вкладываете в OpenAI, питает его.
Это означает, что люди, которые использовали модель GPT OpenAI для данных пациентов, чтобы писать заметки и другие вещи, нарушили HIPAA. Эта информация сейчас находится в модели, и извлечь ее будет крайне сложно.
Поскольку многим людям трудно понять это, вполне вероятно, что модель содержит тонны личных данных, которые просто ждут подходящего запроса, чтобы их опубликовать.
Почему GPT обучается разжиганию ненависти?
Еще одна вещь, которая часто всплывает, заключается в том, что текстовый корпус GPT, на котором обучались, включает в себя разжигание ненависти.
В какой-то степени OpenAI необходимо обучать свои модели реагировать на разжигание ненависти, поэтому у него должен быть корпус, включающий некоторые из этих терминов.
OpenAI утверждает, что вычищает подобные высказывания ненависти из системы, но исходные документы включают 4chan и множество сайтов ненависти.
Ползайте в сети, впитывайте предвзятость.
Нет простого способа избежать этого. Как вы можете заставить что-то распознавать или понимать ненависть, предубеждения и насилие, если это не является частью вашего обучающего набора?
Как избежать предубеждений и понять неявные и явные предубеждения, когда вы — машинный агент, статистически выбирающий следующую лексему в предложении?
TL;DR
Шумиха и дезинформация в настоящее время являются основными элементами бума ИИ. Это не означает, что нет законного использования: эта технология удивительна и полезна.
Но то, как технология продается и как люди ее используют, может способствовать дезинформации, плагиату и даже причинять прямой вред.
Не используйте LLM, когда на кону стоит жизнь. Не используйте LLM, если лучше использовать другой алгоритм. Не ведитесь на обман.
Необходимо понимать, что такое LLM, а что нет.
Я рекомендую это интервью Адама Коновера с Эмили Бендер и Тимнитом Гебру.
LLM могут быть невероятными инструментами при правильном использовании. Существует множество способов использования LLM и еще больше способов злоупотребления LLM.
ChatGPT вам не друг. Это куча статистики. AGI не «уже здесь».
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.