
Spark против Hadoop: какая платформа для работы с большими данными поднимет ваш бизнес?
Опубликовано: 2019-09-24«Данные — топливо цифровой экономики»
Поскольку современные предприятия полагаются на кучу данных, чтобы лучше понять своих потребителей и рынок, такие технологии, как большие данные, набирают огромную популярность.
Большие данные, как и искусственный интеллект, не только попали в список главных технологических трендов 2020 года, но и, как ожидается, будут приняты как стартапами, так и компаниями из списка Fortune 500 за экспоненциальный рост бизнеса и повышение лояльности клиентов. Ясным признаком этого является то, что рынок больших данных, по прогнозам, достигнет 103 миллиардов долларов к 2027 году.
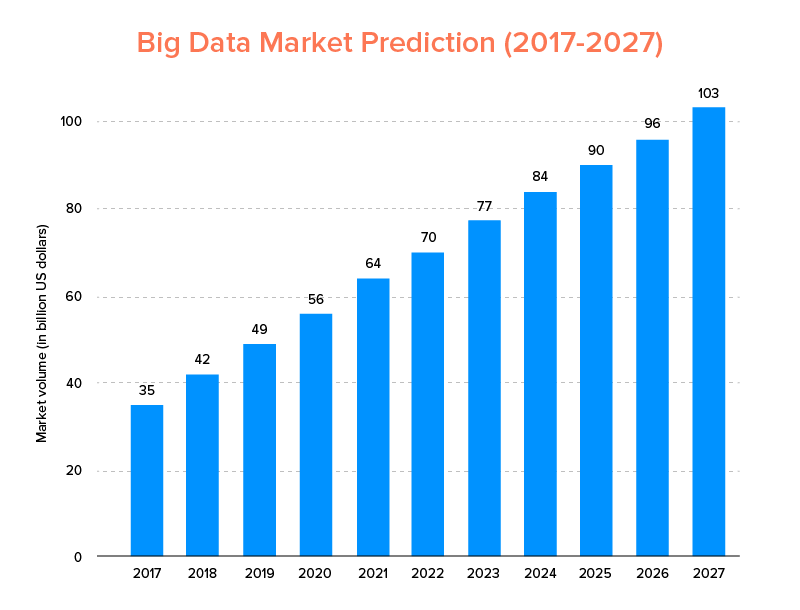
Теперь, хотя, с одной стороны, все заинтересованы в замене своих традиционных инструментов анализа данных большими данными — теми, которые подготавливают почву для развития блокчейна и ИИ, — они также запутались в выборе правильного инструмента для работы с большими данными. Перед ними стоит дилемма выбора между Apache Hadoop и Spark — двумя титанами мира больших данных.
Итак, принимая во внимание эту мысль, сегодня мы рассмотрим статью об Apache Spark и Hadoop и поможем вам определить, какой из них подходит для ваших нужд.
Но, во-первых, давайте кратко представим, что такое Hadoop и Spark.
Apache Hadoop — это распределенная среда с открытым исходным кодом на основе Java, которая позволяет пользователям хранить и обрабатывать большие данные в нескольких кластерах компьютеров с помощью простых программных конструкций. Он состоит из различных модулей, которые работают вместе для обеспечения расширенного опыта, а именно:
- Хадуп Общий
- Распределенная файловая система Hadoop (HDFS)
- пряжа Hadoop
- Hadoop MapReduce
Принимая во внимание, что Apache Spark — это платформа распределенных кластерных вычислений с открытым исходным кодом для больших данных, которая «проста в использовании» и предлагает более быстрые услуги.
Две платформы больших данных поддерживаются многочисленными крупными компаниями благодаря набору возможностей, которые они предлагают.
Преимущества платформы больших данных Hadoop
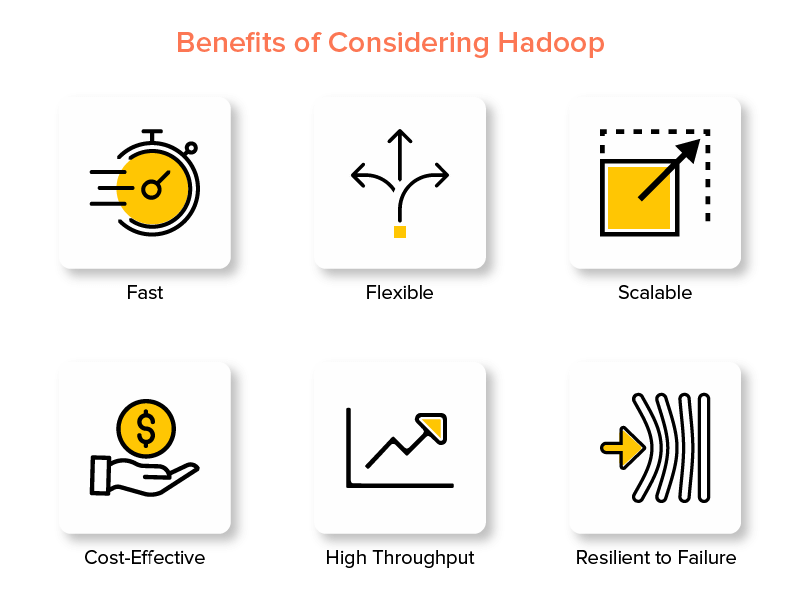
1. Быстро
Одной из особенностей Hadoop, которая делает его популярным в мире больших данных, является его скорость.
Его метод хранения основан на распределенной файловой системе, которая в первую очередь «сопоставляет» данные, где бы они ни находились в кластере. Кроме того, данные и инструменты, используемые для обработки данных, обычно доступны на одном сервере, что упрощает и ускоряет обработку данных.
Фактически было установлено, что Hadoop может обрабатывать терабайты неструктурированных данных всего за несколько минут, а петабайты — за часы.
2. Гибкость
Hadoop, в отличие от традиционных инструментов обработки данных, предлагает высокую гибкость.
Он позволяет компаниям собирать данные из разных источников (таких как социальные сети, электронная почта и т. д.), работать с различными типами данных (как структурированными, так и неструктурированными) и получать ценную информацию для дальнейшего использования в различных целях (например, обработка журналов, анализ рыночных кампаний, выявление мошенничества и др.).
3. Масштабируемость
Еще одним преимуществом Hadoop является его высокая масштабируемость. Платформа, в отличие от традиционных систем реляционных баз данных (RDBMS) , позволяет предприятиям хранить и распространять большие наборы данных с сотен серверов, работающих параллельно.
4. Экономичность
Apache Hadoop, по сравнению с другими инструментами анализа больших данных, намного дешевле. Это потому, что для этого не требуется какой-либо специализированной машины; он работает на группе товарного оборудования. Кроме того, в долгосрочной перспективе проще добавить больше узлов.
Это означает, что в одном случае можно легко увеличить количество узлов, не страдая от простоев требований предварительного планирования.
5. Высокая пропускная способность
В случае платформы Hadoop данные хранятся распределенным образом, так что небольшое задание разбивается на несколько блоков данных параллельно. Это позволяет предприятиям выполнять больше задач за меньшее время, что в конечном итоге приводит к увеличению пропускной способности.
6. Устойчивость к неудачам
И последнее, но не менее важное: Hadoop предлагает варианты с высокой отказоустойчивостью, которые помогают смягчить последствия сбоя. Он хранит реплику каждого блока, что позволяет восстанавливать данные всякий раз, когда какой-либо узел выходит из строя.
Недостатки платформы Hadoop
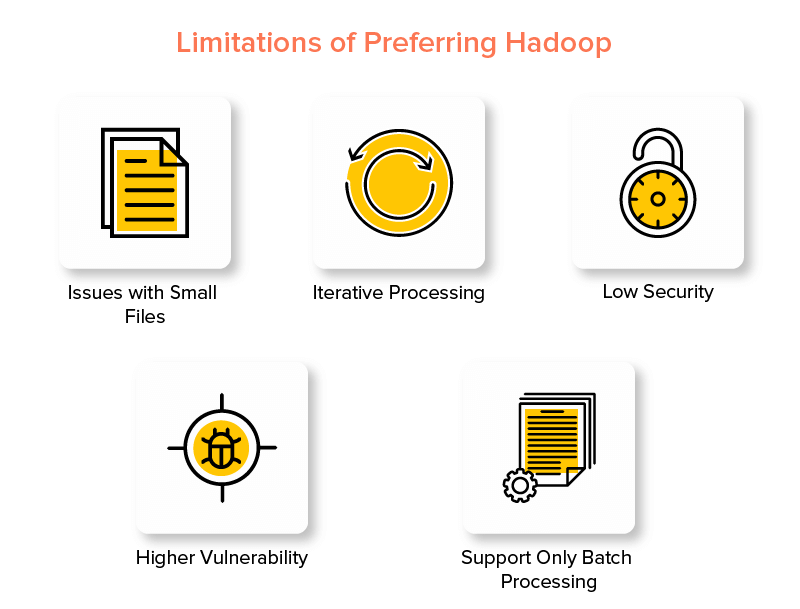
1. Проблемы с маленькими файлами
Самый большой недостаток использования Hadoop для аналитики больших данных заключается в том, что ему не хватает потенциала для эффективной и действенной поддержки случайного чтения небольших файлов.
Причина этого в том, что небольшой файл имеет сравнительно меньший размер памяти, чем размер блока HDFS. В таком сценарии, если хранить огромное количество мелких файлов, повышается вероятность перегрузки NameNode , в котором хранится пространство имен HDFS, что практически не является хорошей идеей.
2. Итеративная обработка
Поток данных в среде больших данных Hadoop представляет собой цепочку, так что выходные данные одного этапа становятся входными данными другого этапа. Принимая во внимание, что поток данных при итеративной обработке носит циклический характер.
Из-за этого Hadoop не подходит для решений на основе машинного обучения или итеративной обработки.
3. Низкий уровень безопасности
Еще один недостаток использования платформы Hadoop заключается в том, что она предлагает более низкие функции безопасности.
Например, в фреймворке по умолчанию отключена модель безопасности. Если кто-то, использующий этот инструмент для работы с большими данными, не знает, как его включить, его данные могут подвергаться более высокому риску кражи или неправомерного использования. Также в Hadoop не предусмотрен функционал шифрования на уровне хранилища и сети, что опять же увеличивает шансы угрозы утечки данных.
4. Более высокая уязвимость
Инфраструктура Hadoop написана на Java, самом популярном, но активно эксплуатируемом языке программирования. Это позволяет киберпреступникам легко получить доступ к решениям на основе Hadoop и неправомерно использовать конфиденциальные данные.
5. Поддержка только пакетной обработки
В отличие от различных других платформ больших данных, Hadoop не обрабатывает потоковые данные. Он поддерживает только пакетную обработку , и причина этого в том, что MapReduce не может максимально использовать память кластера Hadoop.
Хотя это все о Hadoop, его функциях и недостатках, давайте рассмотрим плюсы и минусы Spark, чтобы понять разницу между ними.
Преимущества Apache Spark Framework
1. Динамичность в природе
Поскольку Apache Spark предлагает около 80 высокоуровневых операторов, его можно использовать для динамической обработки данных. Его можно считать подходящим инструментом больших данных для разработки и управления параллельными приложениями.
2. Мощный
Благодаря возможности обработки данных в памяти с малой задержкой и наличию различных встроенных библиотек для алгоритмов машинного обучения и анализа графов он может решать различные аналитические задачи. Это делает его мощным вариантом для работы с большими данными на рынке.
3. Расширенная аналитика
Еще одна отличительная особенность Spark заключается в том, что он не только поощряет «MAP» и «сокращение», но также поддерживает машинное обучение (ML), SQL-запросы, графические алгоритмы и потоковые данные. Это делает его подходящим для использования расширенной аналитики.
4. Повторное использование
В отличие от Hadoop, код Spark можно повторно использовать для пакетной обработки, выполнения специальных запросов к состоянию потока, объединения потока с историческими данными и многого другого.
5. Потоковая обработка в реальном времени
Еще одно преимущество использования Apache Spark заключается в том, что он позволяет обрабатывать и обрабатывать данные в режиме реального времени.
6. Многоязычная поддержка
И последнее, но не менее важное: этот инструмент для анализа больших данных поддерживает несколько языков программирования, включая Java, Python и Scala.
Ограничения инструмента Spark для больших данных

1. Нет процесса управления файлами
Основным недостатком использования Apache Spark является отсутствие собственной системы управления файлами. Он полагается на другие платформы, такие как Hadoop, для выполнения этого требования.
2. Несколько алгоритмов
Apache Spark также отстает от других платформ для работы с большими данными с точки зрения доступности таких алгоритмов, как расстояние Танимото.
3. Проблема с маленькими файлами
Еще одним недостатком использования Spark является то, что он неэффективно обрабатывает небольшие файлы.
Это связано с тем, что он работает с распределенной файловой системой Hadoop (HDFS), которая упрощает управление ограниченным количеством больших файлов по сравнению с большим количеством маленьких файлов.
4. Нет автоматического процесса оптимизации
В отличие от различных других больших данных и облачных платформ, в Spark нет процесса автоматической оптимизации кода. Оптимизировать код приходится только вручную.
5. Не подходит для многопользовательской среды
Поскольку Apache Spark не может работать с несколькими пользователями одновременно, он неэффективно работает в многопользовательской среде. Что-то, что снова добавляет к его ограничениям.
Ознакомившись с основами обеих платформ больших данных, вы, вероятно, надеетесь ознакомиться с различиями между Spark и Hadoop.
Итак, давайте не будем больше ждать и перейдем к их сравнению, чтобы увидеть, кто из них лидирует в битве «Spark против Hadoop».
Spark против Hadoop: как два инструмента для работы с большими данными противостоят друг другу
[идентификатор таблицы = 38 /]
1. Архитектура
Когда дело доходит до архитектуры Spark и Hadoop, последняя лидирует, даже когда обе они работают в распределенной вычислительной среде.
Это связано с тем, что архитектура Hadoop, в отличие от Spark, состоит из двух основных элементов: HDFS (распределенная файловая система Hadoop) и YARN (еще один механизм согласования ресурсов). Здесь HDFS управляет хранением больших данных на различных узлах, тогда как YARN занимается обработкой задач с помощью механизмов распределения ресурсов и планирования заданий. Затем эти компоненты делятся на дополнительные компоненты для предоставления более качественных решений с такими услугами, как отказоустойчивость.
2. Простота использования
Apache Spark позволяет разработчикам внедрять в свою среду разработки различные удобные API, такие как Scala, Python, R, Java и Spark SQL. Кроме того, он поставляется с интерактивным режимом, который поддерживает как пользователей, так и разработчиков. Это делает его простым в использовании и с низкой кривой обучения.
Тогда как, говоря о Hadoop, он предлагает надстройки для поддержки пользователей, но не интерактивный режим. Благодаря этому Spark побеждает Hadoop в этой битве «больших данных».
3. Отказоустойчивость и безопасность
Хотя и Apache Spark, и Hadoop MapReduce обеспечивают отказоустойчивость, последний выигрывает битву.
Это связано с тем, что нужно начинать с нуля на случай сбоя процесса в середине работы в среде Spark. Но, когда дело доходит до Hadoop, они могут продолжаться с момента самого краха.
4. Производительность
Когда дело доходит до сравнения производительности Spark и MapReduce, первый выигрывает у второго.
Фреймворк Spark может работать в 10 раз быстрее на диске и в 100 раз в памяти. Это позволяет управлять 100 ТБ данных в 3 раза быстрее, чем Hadoop MapReduce.
5. Обработка данных
Еще одним фактором, который следует учитывать при сравнении Apache Spark и Hadoop, является обработка данных.
В то время как Apache Hadoop предлагает возможность только пакетной обработки, другая платформа больших данных позволяет работать с интерактивной, итеративной, потоковой, графической и пакетной обработкой. Что-то, что доказывает, что Spark — лучший вариант для получения лучших услуг по обработке данных.
6. Совместимость
Совместимость Spark и Hadoop MapReduce примерно одинакова.
Хотя иногда обе платформы больших данных действуют как автономные приложения, они также могут работать вместе. Spark может эффективно работать поверх Hadoop YARN, а Hadoop легко интегрируется со Sqoop и Flume. Из-за этого оба поддерживают источники данных и форматы файлов друг друга.
7. Безопасность
Среда Spark загружена различными функциями безопасности, такими как ведение журнала событий и использование фильтров сервлетов javax для защиты веб-интерфейсов. Кроме того, он поощряет аутентификацию с помощью общего секрета и может использовать потенциал разрешений файлов HDFS, межрежимное шифрование и Kerberos при интеграции с YARN и HDFS.
Принимая во внимание, что Hadoop поддерживает аутентификацию Kerberos , стороннюю аутентификацию, обычные права доступа к файлам, списки контроля доступа и многое другое, что в конечном итоге обеспечивает более высокие результаты безопасности.
Итак, при рассмотрении сравнения Spark и Hadoop с точки зрения безопасности последний лидирует.
8. Экономическая эффективность
При сравнении Hadoop и Spark первому требуется больше памяти на диске, а второму — больше оперативной памяти. Кроме того, поскольку Spark является довольно новым по сравнению с Apache Hadoop, разработчики, работающие со Spark, встречаются реже.
Это делает работу со Spark дорогостоящим делом. Это означает, что Hadoop предлагает экономически эффективные решения, если сосредоточиться на стоимости Hadoop и Spark.
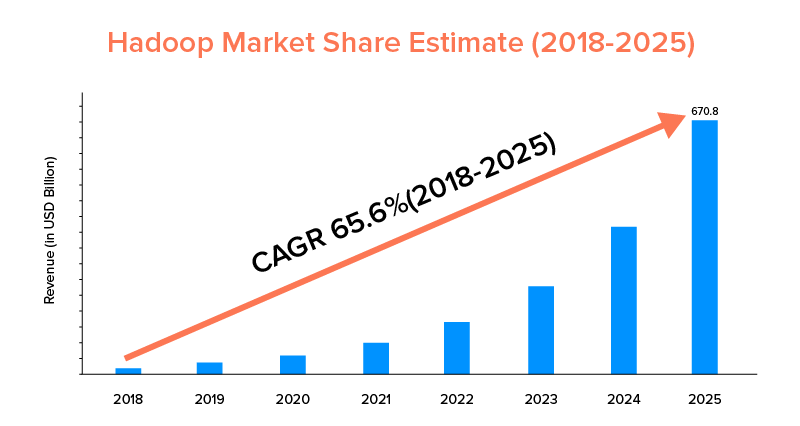
9. Объем рынка
Хотя и Apache Spark, и Hadoop поддерживаются крупными компаниями и используются для разных целей, последний лидирует с точки зрения охвата рынка.
Согласно рыночной статистике, прогнозируется, что рынок Apache Hadoop будет расти со среднегодовым темпом роста 65,6% в период с 2018 по 2025 год по сравнению со Spark с среднегодовым темпом роста всего 33,9%.
Хотя эти факторы помогут определить правильный инструмент для работы с большими данными для вашего бизнеса, полезно ознакомиться с вариантами их использования. Итак, давайте прикроем здесь.
Варианты использования Apache Spark Framework
Этот инструмент больших данных используется предприятиями, когда они хотят:
- Потоковая передача и анализ данных в режиме реального времени.
- Оцените мощь машинного обучения.
- Работа с интерактивной аналитикой.
- Внедрите туманные и граничные вычисления в свою бизнес-модель.
Варианты использования Apache Hadoop Framework
Hadoop предпочитают стартапы и предприятия, когда они хотят:
- Анализировать архивные данные.
- Наслаждайтесь лучшими возможностями финансовой торговли и прогнозирования.
- Выполнение операций, включающих товарное оборудование.
- Рассмотрим линейную обработку данных.
Таким образом, мы надеемся, что вы решили, кто является победителем в битве «Spark против Hadoop» в отношении вашего бизнеса. Если нет, не стесняйтесь связаться с нашими экспертами по большим данным , чтобы развеять все сомнения и получить образцовые услуги с более высоким коэффициентом успеха.
ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ
1. Какую платформу больших данных выбрать?
Выбор полностью зависит от потребностей вашего бизнеса. Если вы сосредоточены на производительности, совместимости данных и простоте использования, Spark лучше, чем Hadoop. Принимая во внимание, что платформа больших данных Hadoop лучше, если вы сосредоточитесь на архитектуре, безопасности и экономической эффективности.
2. В чем разница между Hadoop и Spark?
Существуют различные различия между Spark и Hadoop. Например:-
- Spark в 100 раз превосходит Hadoop MapReduce.
- В то время как Hadoop используется для пакетной обработки, Spark предназначен для пакетной, графической, машинного обучения и итеративной обработки.
- Spark компактнее и проще, чем платформа больших данных Hadoop.
- В отличие от Spark, Hadoop не поддерживает кэширование данных.
3. Spark лучше, чем Hadoop?
Spark лучше, чем Hadoop, когда основное внимание уделяется скорости и безопасности. Однако в других случаях этот инструмент аналитики больших данных отстает от Apache Hadoop.
4. Почему Spark быстрее, чем Hadoop?
Spark быстрее, чем Hadoop, из-за меньшего количества циклов чтения/записи на диск и хранения промежуточных данных в памяти.
5. Для чего используется Apache Spark?
Apache Spark используется для анализа данных, когда нужно:
- Анализируйте данные в режиме реального времени.
- Внедрите машинное обучение и туманные вычисления в свою бизнес-модель.
- Работа с интерактивной аналитикой.