
TW-BERT: комплексное взвешивание терминов запроса и будущее поиска Google
Опубликовано: 2023-09-14«Искать сложно», как писал Сет Годин в 2005 году.
Я имею в виду, если мы думаем, что SEO — это сложно (а это так), представьте, что вы пытаетесь создать поисковую систему в мире, где:
- Пользователи сильно различаются и со временем меняют свои предпочтения.
- Технологии, к которым они получают доступ, совершенствуются с каждым днем.
- Конкуренты постоянно наступают вам на пятки.
Вдобавок ко всему, вы также имеете дело с надоедливыми SEO-специалистами, пытающимися обмануть ваш алгоритм и получить представление о том, как лучше всего оптимизировать его для ваших посетителей.
Это будет намного сложнее.
А теперь представьте, что основные технологии, на которые вам нужно опираться для продвижения, имеют свои собственные ограничения – и, что еще хуже, огромные затраты.
Что ж, если вы один из авторов недавно опубликованной статьи «Взвешивание терминов сквозного запроса», вы видите в этом возможность проявить себя.
Что такое взвешивание терминов сквозного запроса?
Взвешивание терминов сквозного запроса — это метод, при котором вес каждого термина в запросе определяется как часть общей модели без использования запрограммированных вручную или традиционных схем взвешивания терминов или других независимых моделей.
На что это похоже?
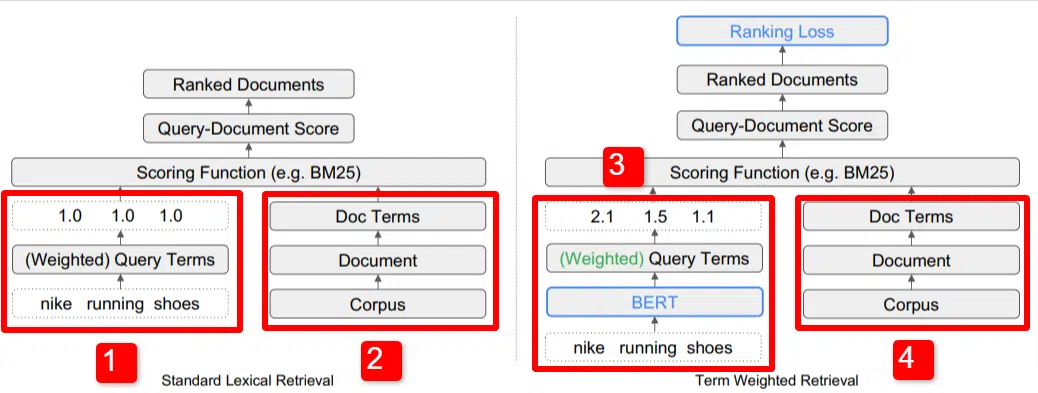
Здесь мы видим иллюстрацию одного из ключевых отличий модели, изложенной в статье (в частности, рис. 1).
В правой части стандартной модели (2) мы видим то же, что и в предлагаемой модели (4), а именно корпус (полный набор документов в указателе), ведущий к документам, ведущим к терминам.
Это иллюстрирует фактическую иерархию в системе, но вы можете представить ее наоборот, сверху вниз. У нас есть условия. Ищем документы с этими условиями. Эти документы входят в состав всех известных нам документов.
В левом нижнем углу (1) стандартной архитектуры поиска информации (IR) вы заметите, что уровень BERT отсутствует. Запрос, использованный в их иллюстрации (кроссовки Nike), поступает в систему, веса вычисляются независимо от модели и передаются в нее.
На приведенной ниже иллюстрации веса распределяются поровну между тремя словами в запросе. Однако так не должно быть. Это просто стандартная и хорошая иллюстрация.
Важно понимать, что веса назначаются извне модели и вводятся вместе с запросом. Мы сейчас расскажем, почему это важно.
Если мы посмотрим на версию термина с весом справа, вы увидите, что запрос «кроссовки Nike» вводит BERT (Term Weighting BERT или, если быть точным, TW-BERT), который используется для присвоения весов, которые лучше всего применить к этому запросу.
Дальше все идет по одному и тому же пути: применяется функция оценки и документы ранжируются. Но в новой модели есть ключевой заключительный шаг, в котором, собственно, и заключается вся суть: расчет потерь в рейтинге.
Этот расчет, о котором я говорил выше, делает очень важными веса, определяемые в модели. Чтобы лучше понять это, давайте немного отвлечемся и обсудим функции потерь, что важно, чтобы действительно понять, что здесь происходит.
Что такое функция потерь?
В машинном обучении функция потерь — это, по сути, расчет того, насколько ошибочна система, пытаясь научиться приближаться к нулевым потерям, насколько это возможно.
Давайте возьмем, к примеру, модель, предназначенную для определения цен на жилье. Если вы ввели все статистические данные о своем доме и получили стоимость в 250 000 долларов, но ваш дом был продан за 260 000 долларов, разница будет считаться убытком (что является абсолютным значением).
На большом количестве примеров модель учат минимизировать потери, присваивая разные веса заданным параметрам до тех пор, пока не будет получен наилучший результат. В этом случае параметр может включать в себя такие вещи, как квадратные футы, количество спален, размер двора, близость к школе и т. д.
Теперь вернемся к взвешиванию терминов запроса.
Оглядываясь назад на два приведенных выше примера, нам нужно сосредоточиться на наличии модели BERT, которая обеспечивает взвешивание условий в нижней части воронки расчета потерь в рейтинге.
Другими словами, в традиционных моделях взвешивание условий производилось независимо от самой модели и, таким образом, не могло реагировать на то, как работает модель в целом. Он не мог научиться улучшать веса.

В предлагаемой системе это меняется. Взвешивание выполняется изнутри самой модели, и, таким образом, поскольку модель стремится улучшить свою производительность и уменьшить функцию потерь, у нее есть эти дополнительные циферблаты, которые можно включить, внося в уравнение взвешивание членов. Буквально.
нграммы
TW-BERT предназначен не для работы со словами, а для работы с нграммами.
Авторы статьи хорошо иллюстрируют, почему они используют ngrams вместо слов, когда указывают, что в запросе «кроссовки Nike», если вы просто взвешиваете слова, то страница с упоминаниями слов Nike, Running и Shoes может даже иметь хороший рейтинг. если речь идет о «носках для бега Nike» и «обувях для скейтбординга».
Традиционные методы IR используют статистику запросов и статистику документов и могут обнаруживать страницы с этой или похожими проблемами. Прошлые попытки решить эту проблему были сосредоточены на совместном возникновении и упорядочении.
В этой модели нграммы имеют такой же вес, как слова в нашем предыдущем примере, поэтому в итоге мы получаем что-то вроде:
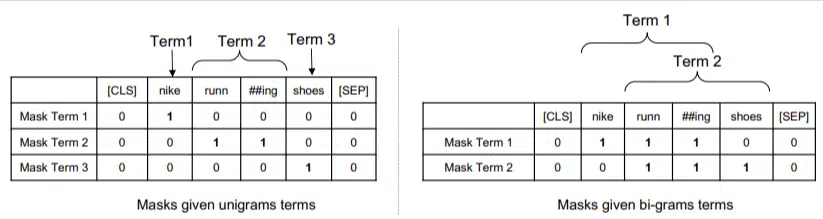
Слева мы видим, как запрос будет взвешиваться как униграммы (нграммы из 1 слова), а справа — биграммы (нграммы из 2 слов).
Система, поскольку в нее встроено взвешивание, может обучаться на всех перестановках, чтобы определить лучшие нграммы, а также подходящий вес для каждой, а не полагаться только на статистику, такую как частота.
Нулевой выстрел
Важной особенностью этой модели является ее производительность в задачах с нулевой короткостью. Авторы протестировали:
- Набор данных MS MARCO — набор данных Microsoft для ранжирования документов и отрывков.
- Набор данных TREC-COVID – статьи и исследования о COVID
- Robust04 – Новостные статьи
- Common Core — образовательные статьи и сообщения в блогах.
У них было лишь небольшое количество оценочных запросов, и они не использовали ни одного для точной настройки, что делало этот тест нулевым, поскольку модель не была обучена ранжировать документы конкретно в этих доменах. Результаты были:
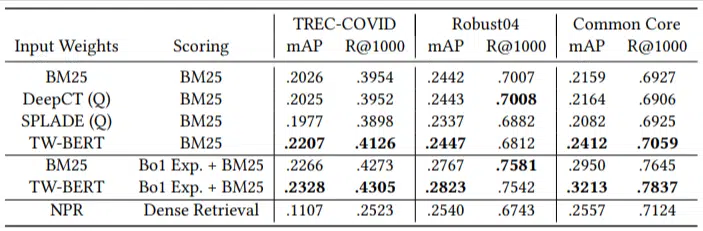
Он превосходил большинство задач и лучше всего работал на более коротких запросах (от 1 до 10 слов).
И это подключи и работай!
Хорошо, это может быть слишком упрощенно, но авторы пишут:
«Согласование TW-BERT с оценщиками поисковых систем сводит к минимуму изменения, необходимые для интеграции его в существующие производственные приложения , тогда как существующие методы поиска на основе глубокого обучения потребуют дальнейшей оптимизации инфраструктуры и требований к оборудованию. Изученные веса могут быть легко использованы стандартными лексическими программами извлечения и другими методами поиска, такими как расширение запроса».
Поскольку TW-BERT предназначен для интеграции в текущую систему, интеграция намного проще и дешевле, чем другие варианты.
Что все это значит для тебя
Например, с моделями машинного обучения трудно предсказать, что вы, как SEO-специалист, можете с этим сделать (кроме видимых развертываний, таких как Bard или ChatGPT).
Модификация этой модели, несомненно, будет использоваться из-за ее улучшений и простоты развертывания (при условии, что утверждения точны).
Тем не менее, это улучшение качества жизни в Google, которое улучшит рейтинг и результаты с нулевым результатом при низких затратах.
Все, на что мы действительно можем рассчитывать, — это то, что в случае реализации мы получим более надежные результаты. И это хорошая новость для профессионалов SEO.
Мнения, выраженные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Здесь перечислены штатные авторы.