
Использование регрессий Excel для лучшего понимания ключевых показателей эффективности
Опубликовано: 2021-10-23Группа из нас здесь, в Hanapin, недавно приняла участие в бесплатном 21-дневном курсе Excel, который вел известный эксперт по Microsoft Excel доктор Уэйн Уинстон. Сам курс сначала казался медленным, но в конечном итоге раскрыл несколько возможностей Excel, о которых я никогда не знал. Самым интересным из них для меня является возможность регрессии нескольких переменных без использования передового статистического программного обеспечения (такого как STATA). В этом посте я поделюсь пошаговыми инструкциями по настройке и запуску регрессий в Excel и расскажу, как этот инструмент может помочь в анализе PPC и управлении учетной записью.
Простите, я регрессирую
Прежде чем мы углубимся в техническую реализацию, вы, возможно, задаетесь вопросом: «Что такое регресс?» Короче говоря, регрессия рассматривает отношения между переменными. Для любой зависимой переменной («Y»), какой набор независимых переменных («Xs») вносит вклад в вариацию Y и какую часть этого поведения объясняет регрессионная модель? (См. Подробный обзор регрессионного анализа здесь)
Линейные регрессии (или множественные линейные регрессии) являются наиболее распространенными, они укладываются в суммированное уравнение вида:
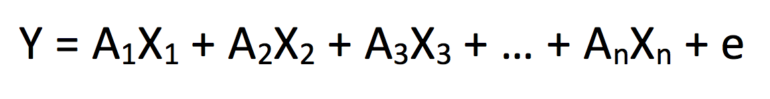
где Y - зависимая переменная, X 1 - X n представляют собой набор из n независимых переменных, а A 1 - A n - константы коэффициентов, соответствующие X 1 - X n . Это базовое построение статистической модели, поэтому мы понимаем, что будет некоторое несоответствие между нашими предсказанными и наблюдаемыми результатами для каждой итерации «y». Таким образом, термин ошибки «+ e» добавляется для учета такой дисперсии.
Почему регресс в PPC?
Регрессии можно использовать в любом количестве анализов. Например, вы можете подумать, как изменение ставки CPC влияет на сред. Позиция, процент потерянных показов или показатель качества. Вы можете проверить, какой элемент (ожидаемый CTR, качество целевой страницы или релевантность рекламы) оказывает наибольшее влияние на показатель качества вашего аккаунта, кампании или ключевого слова. Возможно, как мы увидим в приведенном ниже примере, вы захотите выяснить, какую роль играют цены за клик в поисковой и медийной сети и коэффициенты конверсии в общей цене за конверсию для вашей учетной записи.
Какой бы ни была ваша конечная цель, процесс настройки и определения ценности вашей регрессионной модели остается неизменным.
Шаг 1. Подготовьте данные
Как и в случае любого анализа, для получения хорошего результата требуются качественные данные, которые были правильно подготовлены. Для хороших результатов регрессии вам понадобится достаточный объем данных (по крайней мере, столько точек данных, сколько независимых переменных, но чем больше данных у вас доступно, тем более точной может быть ваша регрессионная модель). Чтобы увеличить количество точек данных, вы можете рассмотреть возможность сегментирования данных по дням, неделям или месяцам (в зависимости от исследуемого периода времени).
В нашем примере мы используем данные за последние 24 месяца в Adwords. После загрузки отчета о кампании (с разбивкой по месяцам) мы создаем сводную таблицу для анализа кликов, затрат и конверсий по месяцам и типу кампании:
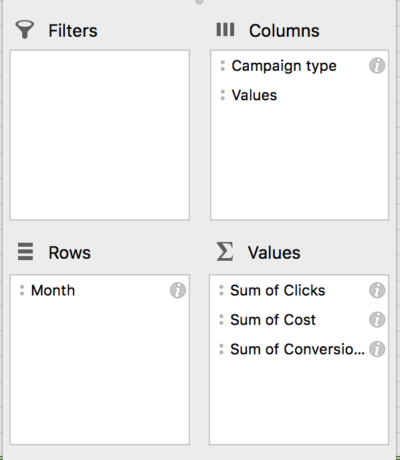
Отсюда мы можем рассчитать CPA, CPC и CVR для каждой сети, а также общую CPA. Тогда это всего лишь одно быстрое копирование и вставка данных на новый лист, и мы готовы начать регресс!
Шаг 2: Постройте свою модель (выбор переменных)
Построение модели состоит из двух основных компонентов: продуманного планирования и гибкого редактирования. Тщательное планирование заключается в рассмотрении того, какие переменные лучше всего подходят для вашей модели с точки зрения логики (и какие данные доступны для использования). Потратив немного больше времени на этап планирования, вы сможете сэкономить время и рассудок, когда вы будете тестировать и повторно тестировать свою модель. Даже при тщательной подготовке вам все равно может потребоваться гибкий пересмотр модели по мере того, как вы регрессируете и определяете переменные, которые являются значимыми, а не нет.
Два важных замечания при выборе независимых переменных:
- Независимые переменные должны иметь мыслимую логическую связь с зависимой переменной (например, среднее количество осадков в Токио и количество сердечных приступов в Висконсине будут в моем списке корреляций для изучения)
- Независимые переменные не должны сильно коррелировать друг с другом (например, включение стоимости, кликов и цены за клик в качестве независимых переменных в рамках одной и той же регрессии вызовет ошибку мультиколлинеарности в модели).
В нашем примере мы хотим посмотреть, что движет CPA нашей учетной записи. Мы знаем, что есть две сети, в которых мы показываем рекламу в Adwords - поисковая и контекстно-медийная, - и мы знаем, что двумя основными переменными, определяющими цену за конверсию (стоимость / конверсия) для каждой сети, являются CPC (стоимость / клик) и CVR (конверсия / клик). ).
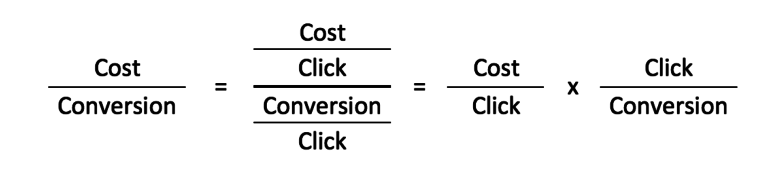
Поэтому мы начнем с регрессии CPA для CPC и CVR для поисковой и контекстно-медийной сети по отдельности, чтобы определить, какие независимые переменные являются значимыми и, следовательно, должны быть включены в нашу окончательную модель.
Шаг 3: регресс и пересмотр
Чтобы запустить регрессию в Excel:
1. Перед запуском регрессии в Excel сначала убедитесь, что независимые переменные (столбцы данных) соседствуют друг с другом.
2. Затем убедитесь, что надстройка «Analysis ToolPak» включена для Excel (после включения отображается на ленте «Данные»).
3. На панели инструментов анализа данных выберите «Регрессия».
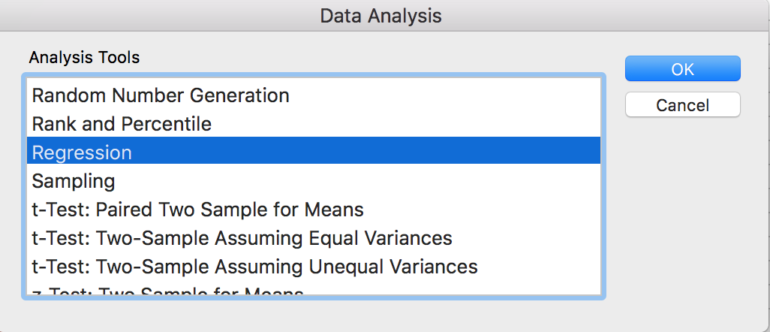
4. Введите диапазон зависимой переменной (Y) и диапазона независимых переменных (X), выбрав «Ярлыки», если вы решите включить заголовки столбцов.
5. Выберите место размещения для вывода регрессии (новый или существующий рабочий лист).
6. Выберите «остатки», если вы хотите проверить и удалить выбросы в данных.
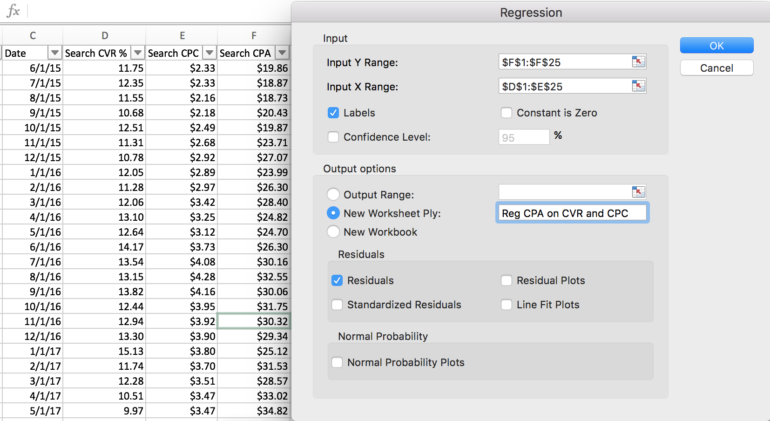
7. Нажмите «ОК», чтобы запустить регрессию. Вы автоматически перейдете к листу, содержащему сводку и подробности вывода.
8. Если проверка результатов регрессии выявляет незначительные независимые переменные (обычно p-значения больше, чем .1) или R-квадрат ниже ожидаемого (см. «A» ниже), вы можете повторить процесс по мере необходимости, чтобы доработать модель.
Шаг 4: понимание вывода
Первый взгляд на итоговый результат может пугать и обескураживать. Чтобы упростить задачу, ниже выделены ключевые разделы выходных данных, которые помогут вам оценить модель, только что построенную вашей регрессией.

(A) R-квадрат и скорректированный R-квадрат: это показатель того, насколько хорошо ваша модель «соответствует» данным. Короче говоря, R-квадрат показывает, насколько вариации в зависимой переменной объясняются выбранными независимыми переменными. Скорректированный квадрат R в основном такой же, но также учитывает количество включенных независимых переменных, обеспечивая немного более точную меру. (Не существует такого понятия, как «хороший» или «правильный» квадрат R, поскольку он зависит от типа модели и данных, которые вы используете, но чем выше, тем лучше).
(B) Стандартная ошибка: квадратный корень из суммы квадратов разностей между прогнозируемыми и фактическими результатами. Для нормального распределения примерно 65% остатков (см. «E» ниже) будут меньше одной стандартной ошибки, а 95% будут меньше 2. Остатки, превышающие стандартную ошибку более чем в два раза, обычно помечаются как выбросы в данных.
(C) Коэффициенты независимых переменных: Коэффициенты - это члены «А» в вашей формуле регрессии. Таким образом, в этом примере увеличение CPC на 1 единицу должно равняться увеличению CPA на 8,4 (при условии, что CVR остается постоянным).
(D) P-значение независимых переменных: с точки зрения непрофессионала, P-значение говорит о значимости независимой переменной. Низкие P-значения значимы (стремятся к меньшему, чем 0,1), в то время как высокие P-значения указывают на то, что воспринимаемая корреляция может быть чистой случайностью. Независимые переменные с высокими значениями P должны быть исключены на этапе «гибкого пересмотра».
(E) Остатки: показывает разницу между прогнозируемым значением зависимой переменной для каждой итерации и фактическим записанным значением. Как упоминалось выше, большинство остатков должно быть меньше 1 стандартной ошибки и почти все должно быть меньше значения 2 * стандартной ошибки. Вы можете решить, следует ли включать или исключать какие-либо выявленные выбросы (остатки, превышающие стандартную ошибку более чем в два раза) из вашей модели.
Шаг 5: Собираем все вместе (Выводы!)
Проведя три регрессии, мы нашли следующие три уравнения, связывающих CPC и CVR в поисковой и медийной сети с сетью и общими ценами за конверсию:



Эти уравнения подтверждают то, что мы уже знали (или думали, что сделали): цены за клик и CVR в поисковой и медийной сети играют важную роль в поведении нашей общей цены за конверсию. Однако помимо этого они также выявили 3 вещи, которых не обнаружит стандартная тепловая карта.
- Повышение цены за клик в поисковой сети в 3,5 раза больше влияет на цену за конверсию в поисковой сети, чем аналогичное повышение CVR в поисковой сети.
- Колебания цены за клик в контекстно-медийной сети почти в 5 раз сильнее влияют на цену за конверсию в контекстно-медийной сети.
- В целом, сдвиги в эффективности контекстно-медийной сети влияют на общую цену за конверсию сильнее, чем сдвиги аналогичной величины в эффективности поисковой сети.
Отсюда ясно, что цена за клик в контекстно-медийной сети - это цель №1 для оптимизации, если я хочу снизить общую цену за конверсию. Следующими идут CPC в поисковой сети и CVR в контекстно-медийной сети, при этом CVR в поисковой сети - наименьший из моих приоритетов.
Регрессии - мощный инструмент и отличное дополнение к набору инструментов Менеджера контекстной рекламы. Этот базовый пример показывает лишь один из многих способов, с помощью которых регрессия может помочь вам понять взаимосвязь между вашими любимыми ключевыми показателями эффективности. Мы надеемся, что вы протестируете или продолжите использовать возможность регрессии в Excel и поделитесь с нами своим опытом / мыслями / выводами в Twitter!