
Что такое генеративный ИИ и как он работает?
Опубликовано: 2023-09-26Генеративный ИИ, разновидность искусственного интеллекта, стал революционной силой в мире технологий. Но что именно? И почему этому уделяется так много внимания?
В этом подробном руководстве рассказывается о том, как работают генеративные модели ИИ, что они могут и чего не могут делать, а также о значении всех этих элементов.
Что такое генеративный ИИ?
Генеративный ИИ, или genAI, относится к системам, которые могут генерировать новый контент, будь то текст, изображения, музыку или даже видео. Традиционно AI/ML подразумевал три вещи: контролируемое, неконтролируемое и обучение с подкреплением. Каждый из них дает ценную информацию на основе результатов кластеризации.
Негенеративные модели ИИ выполняют вычисления на основе входных данных (например, классифицируют изображение или переводят предложение). Напротив, генеративные модели дают «новые» результаты, такие как написание эссе, сочинение музыки, создание графики и даже создание реалистичных человеческих лиц, которых не существует в реальном мире.
Последствия генеративного ИИ
Развитие генеративного искусственного интеллекта имеет серьезные последствия. Благодаря возможности генерировать контент в таких отраслях, как развлечения, дизайн и журналистика, происходит смена парадигмы.
Например, информационные агентства могут использовать ИИ для составления отчетов, а дизайнеры могут получать предложения по графике с помощью ИИ. ИИ может генерировать сотни рекламных слоганов за секунды – независимо от того, хороши эти варианты или нет. или нет - это другой вопрос.
Генеративный ИИ может создавать индивидуальный контент для отдельных пользователей. Подумайте о чем-то вроде музыкального приложения, которое сочиняет уникальную песню в зависимости от вашего настроения, или новостного приложения, которое готовит статьи на интересующие вас темы.
Проблема в том, что, поскольку ИИ играет все более важную роль в создании контента, вопросы об аутентичности, авторских правах и ценности человеческого творчества становятся все более распространенными.
Как работает генеративный ИИ?
По своей сути генеративный ИИ занимается прогнозированием следующего фрагмента данных в последовательности, будь то следующее слово в предложении или следующий пиксель изображения. Давайте разберемся, как это достигается.
Статистические модели
Статистические модели являются основой большинства систем искусственного интеллекта. Они используют математические уравнения для представления взаимосвязи между различными переменными.
В случае генеративного ИИ модели обучаются распознавать закономерности в данных, а затем использовать эти закономерности для генерации новые аналогичные данные.
Если модель обучена на английских предложениях, она изучает статистическую вероятность того, что одно слово следует за другим, что позволяет ей генерировать связные предложения.
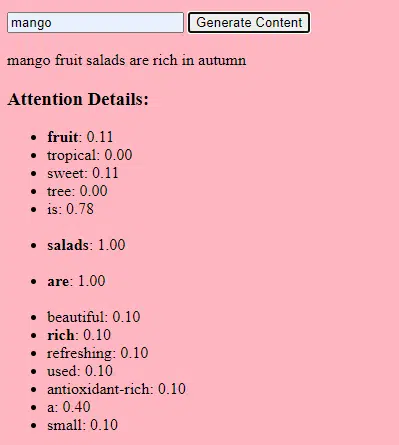
Сбор данных
Решающее значение имеют как качество, так и количество данных. Генеративные модели обучаются на обширных наборах данных для понимания закономерностей.
Для языковой модели это может означать использование миллиардов слов из книг, веб-сайтов и других текстов.
Для модели изображения это может означать анализ миллионов изображений. Чем разнообразнее и полнее обучающие данные, тем лучше модель будет генерировать разнообразные результаты.
Как работают трансформаторы и внимание
Трансформаторы — это тип архитектуры нейронной сети, представленный в статье Васвани и др. в 2017 году под названием «Внимание — это все, что вам нужно». С тех пор они стали основой для большинства современных языковых моделей. ChatGPT не будет работать без преобразователей.
Механизм «внимания» позволяет модели концентрироваться на различных частях входных данных, подобно тому, как люди обращают внимание на определенные слова при понимании предложения.
Этот механизм позволяет модели решать, какие части входных данных актуальны для данной задачи, что делает ее очень гибкой и мощной.
Приведенный ниже код представляет собой фундаментальное описание механизмов трансформатора, объясняющее каждую часть простым языком.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)В коде у вас может быть класс Transformer и один класс TransformerLayer. Это похоже на проект этажа, а не всего здания.
Этот фрагмент кода TransformerLayer показывает, как работают определенные компоненты, такие как внимание нескольких голов и определенные механизмы.
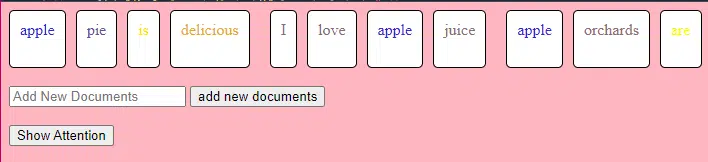
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Нейронная сеть прямого распространения — один из простейших типов искусственных нейронных сетей. Он состоит из входного слоя, одного или нескольких скрытых слоев и выходного слоя.
Данные передаются в одном направлении – от входного слоя через скрытые слои к выходному слою. В сети нет петель и циклов.
В контексте архитектуры преобразователя нейронная сеть прямого распространения используется после механизма внимания на каждом уровне. Это простое двухуровневое линейное преобразование с активацией ReLU между ними.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Как работает генеративный ИИ – простыми словами
Думайте о генеративном ИИ как о бросании взвешенной игральной кости. Данные обучения определяют веса (или вероятности).
Если кубик представляет следующее слово в предложении, слово, которое часто следует за текущим словом в обучающих данных, будет иметь более высокий вес. Таким образом, «небо» может следовать за «синим» чаще, чем за «бананом». Когда ИИ «кидает кости» для генерации контента, он с большей вероятностью выберет статистически более вероятные последовательности на основе своего обучения.
Итак, как LLM могут генерировать контент, который «кажется» оригинальным?
Давайте возьмем фальшивый список – «лучшие подарки Ид аль-Фитр для контент-маркетологов» – и рассмотрим, как LLM может генерировать этот список путем объединения текстовых подсказок из документов о подарках, празднике Ид и контент-маркетологах.
Перед обработкой текст разбивается на более мелкие части, называемые «токенами». Эти токены могут быть длиной в один символ или в одно слово.
Пример: «Ид аль-Фитр – это праздник» становится [«Ид», «аль-Фитр», «есть», «а», «праздник»].
Это позволяет модели работать с управляемыми фрагментами текста и понимать структуру предложений.
Затем каждый токен преобразуется в вектор (список чисел) с использованием вложений. Эти векторы фиксируют значение и контекст каждого слова.
Позиционное кодирование добавляет к каждому вектору слов информацию о его позиции в предложении, гарантируя, что модель не потеряет эту информацию о порядке.
Затем мы используем механизм внимания : это позволяет модели фокусироваться на разных частях входного текста при генерации вывода. Если вы помните BERT, то именно это так заинтересовало сотрудников Google в BERT.
Если наша модель видела тексты о « подарках » и знает, что люди дарят подарки во время торжеств , а также видела тексты о том, что « Ид аль-Фитр » является значимым праздником , она обратит « внимание » на эти связи.
Точно так же, если он увидел тексты о « маркетологах контента », нуждающихся в определенных инструментах или ресурсах , он может связать идею « подарков » с « маркетологами контента».

Теперь мы можем комбинировать контексты: поскольку модель обрабатывает входной текст через несколько слоев Transformer, она объединяет изученные контексты.
Таким образом, даже если в исходных текстах никогда не упоминались «подарки Ид аль-Фитр для контент-маркетологов», модель может объединить понятия «Ид аль-Фитр», «подарки» и «контент-маркетологи» для создания этого контента.
Это потому, что он изучил более широкий контекст вокруг каждого из этих терминов.
После обработки входных данных через механизм внимания и сети прямой связи на каждом уровне преобразователя модель создает распределение вероятностей по своему словарю для следующего слова в последовательности.
Можно подумать, что после таких слов, как «лучший» и «Ид аль-Фитр», с большой вероятностью последует слово «подарки». Точно так же он может ассоциировать «подарки» с потенциальными получателями, такими как «контент-маркетологи».
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
См. условия.
Как строятся большие языковые модели
Путь от базовой модели преобразователя к сложной модели большого языка (LLM), такой как GPT-3 или BERT, включает масштабирование и доработку различных компонентов.
Вот пошаговая разбивка:
LLM обучаются на огромных объемах текстовых данных. Трудно объяснить, насколько обширны эти данные.
Набор данных C4, отправная точка для многих LLM, представляет собой 750 ГБ текстовых данных. Это 805 306 368 000 байт – очень много информации. Эти данные могут включать книги, статьи, веб-сайты, форумы, разделы комментариев и другие источники.
Чем разнообразнее и полнее данные, тем лучше возможности модели для понимания и обобщения.
Хотя базовая архитектура трансформатора остается основой, LLM имеют значительно большее количество параметров. GPT-3, например, имеет 175 миллиардов параметров. В этом случае параметры относятся к весам и смещениям нейронной сети, которые изучаются в процессе обучения.
При глубоком обучении модель обучается делать прогнозы путем корректировки этих параметров, чтобы уменьшить разницу между ее прогнозами и фактическими результатами.

Процесс настройки этих параметров называется оптимизацией, в которой используются такие алгоритмы, как градиентный спуск.
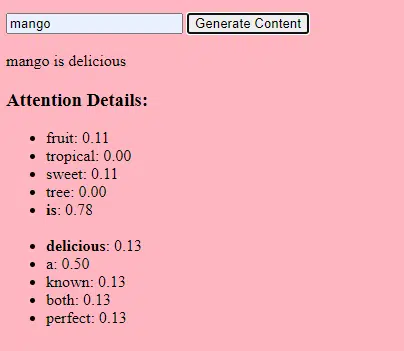
- Веса: это значения в нейронной сети, которые преобразуют входные данные внутри слоев сети. Они корректируются во время обучения, чтобы оптимизировать выходные данные модели. Каждая связь между нейронами в соседних слоях имеет соответствующий вес.
- Смещения: это также значения в нейронной сети, которые добавляются к результатам преобразования слоя. Они предоставляют модели дополнительную степень свободы, позволяя ей лучше соответствовать обучающим данным. Каждый нейрон в слое имеет связанное с ним смещение.
Такое масштабирование позволяет модели хранить и обрабатывать более сложные закономерности и связи в данных.
Большое количество параметров также означает, что модель требует значительной вычислительной мощности и памяти для обучения и вывода. Вот почему обучение таких моделей является ресурсоемким и обычно использует специализированное оборудование, такое как графические процессоры или TPU.
Модель обучена предсказывать следующее слово в последовательности с использованием мощных вычислительных ресурсов. Он корректирует свои внутренние параметры в зависимости от допущенных ошибок, постоянно улучшая свои прогнозы.
Механизмы внимания, подобные тем, которые мы обсуждали, имеют решающее значение для студентов LLM. Они позволяют модели сосредоточиться на различных частях входных данных при генерации выходных данных.
Взвешивая важность различных слов в контексте, механизмы внимания позволяют модели генерировать связный и контекстуально релевантный текст. Выполнение этого в таком массовом масштабе позволяет LLM работать так, как они это делают.
Как преобразователь предсказывает текст?
Трансформаторы прогнозируют текст, обрабатывая входные токены на нескольких уровнях, каждый из которых оснащен механизмами внимания и сетями прямой связи.
После обработки модель создает распределение вероятностей по своему словарю для следующего слова в последовательности. В качестве предсказания обычно выбирается слово с наибольшей вероятностью.
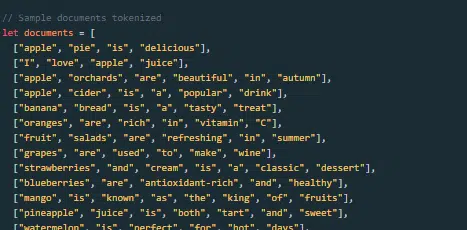
Как создается и обучается большая языковая модель?
Создание LLM включает в себя сбор данных, их очистку, обучение модели, ее тонкую настройку и энергичное непрерывное тестирование.
Модель изначально обучается на обширном корпусе, чтобы предсказать следующее слово в последовательности. Этот этап позволяет модели изучить связи между словами, которые отражают закономерности в грамматике, отношения, которые могут представлять факты о мире, и связи, которые напоминают логические рассуждения. Эти связи также позволяют ему улавливать предвзятости, присутствующие в обучающих данных.
После предварительного обучения модель уточняется на более узком наборе данных, часто при участии рецензентов, следующих рекомендациям.
Точная настройка является важным шагом в создании LLM. Он включает в себя обучение предварительно обученной модели более конкретному набору данных или задаче. Давайте возьмем ChatGPT в качестве примера.
Если вы играли с моделями GPT, то знаете, что подсказки заключаются не столько в «напишите это», сколько в
- Подсказка: Однажды
- Продолжение: На вершине башни жил злой волшебник.
- Продолжение: На вершине башни жил злой волшебник.
- Подсказка : Почему курица присоединилась к группе?
- Продолжение : Потому что у него были голени!
Чтобы добраться до ChatGPT с этой точки, потребуется много низкооплачиваемого труда. Эти люди создают огромные корпуса, чтобы оценить вес ответов GPT и ожидаемого поведения. Эти работники создают массу текстов подсказок/продолжений, например:
- Подсказка : Закончите эту историю: «Однажды…».
- Продолжение : Конечно! Давным-давно в далекой-далекой стране жила маленькая деревня, приютившаяся между двумя величественными горами.
- Продолжение : Конечно! Давным-давно в далекой-далекой стране жила маленькая деревня, приютившаяся между двумя величественными горами.
- Подсказка : Расскажите анекдот про курицу.
- Продолжение : Почему курица присоединилась к группе? Потому что у него были барабанные палочки!
Этот процесс тонкой настройки важен по нескольким причинам:
- Специфика: хотя предварительное обучение дает модели широкое понимание языка, точная настройка сужает ее знания и поведение, чтобы они больше соответствовали конкретным задачам или областям. Например, модель, настроенная на медицинских данных, лучше ответит на медицинские вопросы.
- Управление: точная настройка дает разработчикам больше контроля над результатами модели. Разработчики могут использовать тщательно подобранный набор данных, чтобы направлять модель на получение желаемых ответов и избегать нежелательного поведения.
- Безопасность: помогает снизить вредные или предвзятые результаты. Используя рекомендации в процессе тонкой настройки, рецензенты могут гарантировать, что модель не будет создавать нежелательный контент.
- Производительность: точная настройка может значительно улучшить производительность модели при выполнении конкретных задач. Например, модель, идеально настроенная для поддержки клиентов, будет работать намного лучше, чем универсальная модель.
Вы можете сказать, что ChatGPT в некоторых отношениях был доработан.
Например, «логическое рассуждение» — это то, с чем, как правило, сталкиваются выпускники LLM. Лучшая модель логического мышления ChatGPT — GPT-4 — была тщательно обучена явному распознаванию закономерностей в числах.
Вместо чего-то вроде этого:
- Подсказка : Сколько будет 2+2?
- Процесс : Часто в учебниках по математике для детей 2+2=4. Иногда встречаются ссылки на «2+2=5», но обычно в таких случаях больше контекста имеет отношение к Джорджу Оруэллу или «Звездному пути». Если бы это было в этом контексте, вес был бы больше в пользу 2+2=5. Но такого контекста не существует, поэтому в данном случае следующий токен, скорее всего, будет 4.
- Ответ : 2+2=4
Обучение происходит примерно так:
- обучение: 2+2=4
- обучение: 4/2=2
- тренировка: половина из 4 это 2
- тренировка: 2 из 2 — четыре
…и так далее.
Это означает, что для более «логичных» моделей процесс обучения является более строгим и ориентирован на то, чтобы модель понимала и правильно применяла логические и математические принципы.
Модель подвергается воздействию различных математических проблем и их решений, гарантируя, что она может обобщить и применить эти принципы к новым, невидимым проблемам.
Важность этого процесса тонкой настройки, особенно для логических рассуждений, невозможно переоценить. Без этого модель может давать неправильные или бессмысленные ответы на простые логические или математические вопросы.
Модели изображений и языковые модели
Хотя модели изображения и языка могут использовать схожие архитектуры, такие как преобразователи, данные, которые они обрабатывают, принципиально различаются:
Модели изображений
Эти модели работают с пикселями и часто работают иерархически, сначала анализируя небольшие узоры (например, края), затем комбинируя их для распознавания более крупных структур (например, фигур) и так далее, пока не будут поняты все изображение.
Языковые модели
Эти модели обрабатывают последовательности слов или символов. Им необходимо понимать контекст, грамматику и семантику, чтобы создавать связный и контекстуально релевантный текст.
Как работают известные генеративные интерфейсы ИИ
Далл-Э + Мидджорни
Dall-E — вариант модели GPT-3, адаптированный для генерации изображений. Он обучен на огромном наборе данных пар текст-изображение. Midjourney — еще одно программное обеспечение для создания изображений, основанное на запатентованной модели.
- Входные данные: вы предоставляете текстовое описание, например «двуглавый фламинго».
- Обработка: эти модели кодируют этот текст в серию чисел, а затем декодируют эти векторы, находя связи с пикселями, чтобы создать изображение. Модель изучила связи между текстовыми описаниями и визуальными представлениями на основе обучающих данных.
- Выход: изображение, соответствующее данному описанию или относящееся к нему.
Пальцы, узоры, проблемы
Почему эти инструменты не могут постоянно генерировать руки, которые выглядят нормально? Эти инструменты работают, просматривая пиксели рядом друг с другом.
Вы можете увидеть, как это работает, сравнивая ранее или более примитивно сгенерированные изображения с более поздними: более ранние модели выглядят очень размытыми. Напротив, более поздние модели намного четче.
Эти модели генерируют изображения, предсказывая следующий пиксель на основе уже сгенерированных пикселей. Этот процесс повторяется миллионы раз для создания полного изображения.
Руки, особенно пальцы, сложны и имеют множество деталей, которые необходимо точно уловить.
Положение, длина и ориентация каждого пальца могут сильно различаться на разных изображениях.
При генерации изображения из текстового описания модели приходится делать множество предположений о точной позе и строении руки, что может привести к аномалиям.
ЧатGPT
ChatGPT основан на архитектуре GPT-3.5 — модели на основе преобразователя, предназначенной для задач обработки естественного языка.
- Входные данные: приглашение или серия сообщений для имитации разговора.
- Обработка: ChatGPT использует свои обширные знания из разнообразных интернет-текстов для генерации ответов. Он учитывает контекст разговора и пытается дать наиболее релевантный и связный ответ.
- Вывод: текстовый ответ, который продолжает разговор или отвечает на него.
Специальность
Сильная сторона ChatGPT заключается в его способности обрабатывать различные темы и имитировать человеческие разговоры, что делает его идеальным для чат-ботов и виртуальных помощников.
Бард + Поисковый генеративный опыт (SGE)
Хотя конкретные детали могут быть запатентованными, Bard основан на методах искусственного интеллекта-трансформера, аналогичных другим современным языковым моделям. SGE основан на аналогичных моделях, но включает в себя другие алгоритмы машинного обучения, которые использует Google.
SGE, скорее всего, генерирует контент, используя генеративную модель на основе преобразователя, а затем нечетко извлекает ответы из ранжируемых страниц в поиске. (Возможно, это неправда. Просто предположение, основанное на том, как это работает. Пожалуйста, не подавайте на меня в суд!)
- Ввод: подсказка/команда/поиск.
- Обработка: Бард обрабатывает вводимые данные и работает так же, как и другие LLM. SGE использует аналогичную архитектуру, но добавляет уровень, на котором он ищет свои внутренние знания (полученные из обучающих данных) для генерации подходящего ответа. Он учитывает структуру, контекст и намерение приглашения для создания соответствующего контента.
- Выход: сгенерированный контент, который может представлять собой историю, ответ или любой другой тип текста.
Приложения генеративного ИИ (и их противоречия)
Арт, живопись и дизайн
Генеративный ИИ теперь может создавать произведения искусства, музыку и даже дизайн продуктов. Это открыло новые возможности для творчества и инноваций.
Споры
Рост использования ИИ в искусстве вызвал дебаты о сокращении рабочих мест в творческих сферах.
Кроме того, существуют опасения по поводу:
- Трудовые нарушения, особенно когда контент, созданный ИИ, используется без надлежащего указания авторства или компенсации.
- Руководители, угрожающие писателям заменой их искусственным интеллектом, — одна из причин, спровоцировавших забастовку писателей.
Обработка естественного языка (НЛП)
Модели искусственного интеллекта сейчас широко используются для чат-ботов, языкового перевода и других задач НЛП.
Помимо мечты об искусственном общем интеллекте (AGI), это лучшее применение для LLM, поскольку они близки к «универсальной» модели НЛП.
Споры
Многие пользователи считают чат-ботов безличными и иногда раздражающими.
Более того, хотя ИИ добился значительных успехов в языковом переводе, ему часто не хватает нюансов и культурного понимания, которые привносят люди-переводчики, что приводит к впечатляющим и ошибочным переводам.
Медицина и открытие лекарств
ИИ может быстро анализировать огромные объемы медицинских данных и генерировать потенциальные лекарственные соединения, ускоряя процесс разработки лекарств. Многие врачи уже используют степень магистра права для написания заметок и общения с пациентами.
Споры
Полагаться на LLM в медицинских целях может быть проблематично. Медицина требует точности, и любые ошибки или оплошности ИИ могут иметь серьезные последствия.
В медицине также уже есть предубеждения, которые только усиливаются при использовании программ LLM. Существуют также аналогичные проблемы, которые обсуждаются ниже, с конфиденциальностью, эффективностью и этикой.
Игры
Многие энтузиасты ИИ в восторге от использования ИИ в играх: они говорят, что ИИ может создавать реалистичную игровую среду, персонажей и даже целые игровые сюжеты, улучшая игровой процесс. Диалог с NPC можно улучшить с помощью этих инструментов.
Споры
Ведутся споры об интенциональности игрового дизайна.
Хотя ИИ может генерировать огромное количество контента, некоторые утверждают, что ему не хватает продуманного дизайна и связности повествования, которые привносят дизайнеры-люди.
В Watchdogs 2 были программные NPC, которые мало что добавляли к связности повествования игры в целом.
Маркетинг и реклама
ИИ может анализировать поведение потребителей и генерировать персонализированную рекламу и рекламный контент, делая маркетинговые кампании более эффективными.
LLM имеют контекст из произведений других людей, что делает их полезными для создания пользовательских историй или более тонких программных идей. Вместо того, чтобы рекомендовать телевизоры тому, кто только что купил телевизор, специалисты LLM могут порекомендовать аксессуары, которые могут кому-то пригодиться.
Споры
Использование ИИ в маркетинге вызывает проблемы конфиденциальности. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Мнения, выраженные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Здесь перечислены штатные авторы.