
Получение информации в SEO: что это такое и почему это важно
Опубликовано: 2023-07-25Патент Google на «оценку прироста информации» был выдан в июне 2022 года. Я считаю, что не случайно последовало несколько обновлений алгоритма, включая обновление полезного контента.
Является ли оценка получения информации ключевым способом для Google расставить приоритеты в отношении ценного контента, который является «оригинальным, высококачественным, ориентированным на людей контентом, демонстрирующим качества EEAT»?
Моя гипотеза: да. Вот почему.
Что такое оценка прироста информации?
Оценка прироста информации — это, по сути, мера того, насколько ваш контент уникален по сравнению с остальной частью корпуса. Здесь корпусом будут все потенциальные документы, которые Google анализирует при ранжировании по конкретному поисковому запросу.
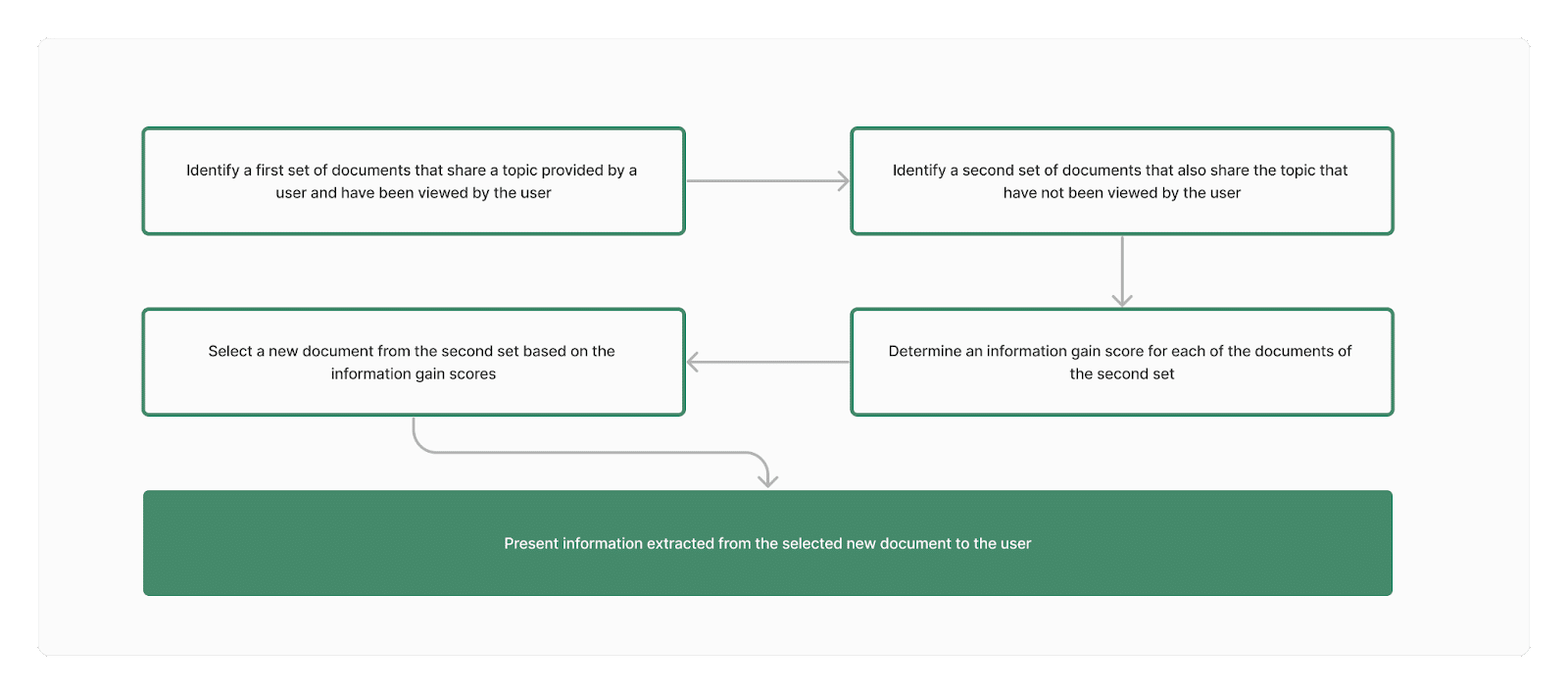
В патенте большинство сценариев, приведенных для расчета показателей прироста информации, выполняются после последующих запросов или просмотров документов и просмотров результатов поиска. Это процесс обучения, специфичный для человека и/или темы, которую он ищет.
Покойный Билл Славски написал техническое описание этого процесса, когда в 2020 году патент все еще находился на рассмотрении.
Одна из интересных вещей, которые я вижу в патентном языке, заключается в следующем:
Google дает возможность алгоритмическому расчету показателей получения информации и их применению в качестве обучающих данных в моделях машинного обучения.
Потребность в первом наборе документов для расчета оценки прироста информации может стать устаревшей в будущем:
«[В] некоторых реализациях данные из каждого из документов второго набора документов могут применяться в модели машинного обучения в качестве входных данных».
Как получение информации влияет на ранжирование в поиске?
С реальной точки зрения это означает, что Google:
- Имеет способ рассчитать, насколько ваш контент уникален по сравнению с остальным контентом в этой тематической области.
- Имеет метрику для активного продвижения или понижения контента на основе этого уровня различия или сходства.
Оценка прироста информации предполагает новый элемент алгоритма, ориентированный на контент, созданный ИИ, и новые фермы контента.
Следовательно, содержание может быть понижено, если ему не хватает уникальности, даже если оно состоит из разных слов, расположенных по-разному.
Контент небоскребов может быть частью этого целевого понижения.
Оценка получения информации и система полезного контента подталкивают к инновациям там, где в настоящее время есть море «идеально оптимизированного» контента.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
См. условия.
Может ли получение информации улучшить видимость вашего сайта?
Использование полученной информации для создания или обновления контента — это двойной процесс.
- Проанализируйте источник ваших данных.
- Определите рыночные возможности.
В идеальном сценарии было бы интересно посмотреть, что может сделать эксперт или менеджер по продажам, если его попросят написать о решении X-проблемы клиента без каких-либо «требований SEO» или с помощью Google. В результате может получиться удивительно инновационный и адекватный ответ.

У большинства из нас нет такой роскоши, как съемка в темноте, и им нужно немного больше структуры, чтобы изменить, обновить и адаптировать то, как мы создаем контент.
Итак, давайте рассмотрим, как мы можем изменить этот подход.
Откуда вы черпаете информацию?
Хотя это может показаться шагом назад, приготовьтесь потратить на поиск контента больше времени, чем когда-либо.
Если вы получаете информацию исключительно из Интернета и поисковой выдачи, по которой вы хотите ранжироваться, вы можете быть частью проблемы. Мы все это делаем, но это немного лениво, верно?
Отличный, качественный контент требует времени.
Контент, который мы публикуем, который мы расширяем и используем для продвижения наших компаний, наших брендов и нас самих, должен соответствовать марке «интеллектуальное лидерство».
Что для этого нужно? Основой идейного лидерства по существу является информированное мнение.
Это требует от вас занять определенную позицию, иметь определенное мнение или прийти к определенному выводу.
А для этого вам нужна информация, подтверждающая это мнение, или вы должны это сделать.
В любой компании у вас будут уникальные данные, которые только и ждут, чтобы вы использовали их в статье или инструменте для своих клиентов и заказчиков, например:
- Обратная связь и журналы от вашей службы поддержки клиентов.
- Ваши отзывы.
- Обратная связь и коммерческие звонки от вашего отдела продаж.
- Данные об использовании вашего продукта, если они могут быть агрегированы и опубликованы.
Это все источники контента, которые конкурент не может легко скопировать.
Их также можно превратить в мультимедийные возможности, которые Google не может создать.
Он также основан на ваших реальных клиентах и их реальном опыте.
Большая часть контента, который результаты поиска «говорят» вам создать, на самом деле может не подходить для ваших клиентов.
Если вы начнете с собственных данных, вы, естественно, отфильтруете большую часть контента, написанного исключительно для поисковых систем.
Какие возможности есть на рынке?
Хотя заманчиво зайти в Google или Bing и следовать формату статьи с самым высоким рейтингом в результатах поиска, помните, что Google ставит ее на первое место только потому, что это лучшее из того, к чему у них есть доступ.
Они не могут создавать свой собственный контент (пока), чтобы точно ответить на то, что ищет человек, если он еще не существует.
Таким образом, ранжирование контента может быть абсолютным мусором для удовлетворения реальных знаний и предоставления надежного ответа, но поскольку это лучшее из худшего, это то, что ранжируется.
Поэтому при создании нового контента мы также должны учитывать актуальную актуальность и области, связанные с темой, о которой вы пишете, которой, возможно, не пользуются другие конкуренты.
Инструменты, которые могут помочь вам увидеть существующие тематические отношения ваших конкурентов, включают в себя:
- Демонстрация API естественного языка
- Демонстрация Диффбота
- по орбите
Инструменты, которые вы можете использовать, чтобы помочь понять семантические отношения тем вашей основной темы (которые могут не освещаться вашими конкурентами), включают:
- MarketMuse
- TF-IDF через Ryte
- Кластеризация ключевых слов с помощью Semrush (платно)
- Создайте свой собственный инструмент моделирования темы, используя скрытое распределение Дирихле и Python (не тестировалось)
У каждого из этих инструментов есть свои компромиссы и соображения, и каждый из них должен быть взвешен с учетом компрометации данных, на которую идет ваша организация.
Как и все остальное, они также являются приблизительным представлением о том, как работает система ранжирования поисковой системы Google.
Также полезно помнить, что излияние недавно опубликованного контента от ИИ имеет реальные финансовые последствия для Google.
Больше контента означает постепенное увеличение счетов за электроэнергию, поэтому они заинтересованы в том, чтобы удалить как можно больше контента, прежде чем он пройдет через все три поисковых робота.
Поэтому найдите способы создавать контент, который понравится как вашим клиентам, так и Google.
Мнения, выраженные в этой статье, принадлежат приглашенному автору, а не обязательно поисковой системе. Штатные авторы перечислены здесь.