
Годовой SEO-кейс: что нужно знать о роботе Googlebot
Опубликовано: 2019-08-30Примечание редактора: генеральный директор краулера JetOctopus Сергей Безбородов дает экспертные советы о том, как сделать ваш сайт привлекательным для робота Googlebot. Данные в этой статье основаны на годовом исследовании и 300 миллионах просканированных страниц.
Несколько лет назад я пытался увеличить посещаемость нашего сайта-агрегатора вакансий с 5 миллионами страниц. Решил воспользоваться услугами SEO-агентства, рассчитывая, что трафик будет зашкаливать. Но я был неправ. Вместо комплексного аудита я получил гадание на картах Таро. Вот почему я вернулся к началу и создал поисковый робот для всестороннего анализа SEO на странице.
Я слежу за роботом Googlebot больше года и теперь готов поделиться информацией о его поведении. Я ожидаю, что мои наблюдения, по крайней мере, прояснят, как работают поисковые роботы, и, самое большее, помогут вам эффективно проводить внутреннюю оптимизацию. Я собрал наиболее значимые данные, которые будут полезны как для нового веб-сайта, так и для сайта с тысячами страниц.
Появляются ли ваши страницы в поисковой выдаче?
Чтобы точно знать, какие страницы находятся в результатах поиска, вы должны проверить индексируемость всего сайта. Однако анализ каждого URL-адреса на веб-сайте, насчитывающем более 10 миллионов страниц, стоит целое состояние, примерно столько же, сколько новая машина.
Вместо этого воспользуемся анализом лог-файлов. Мы работаем с сайтами следующим образом: мы сканируем веб-страницы, как это делает поисковый бот, а затем анализируем лог-файлы, которые были собраны за полгода. Журналы показывают, посещали ли боты веб-сайт, какие страницы были просканированы, а также когда и как часто боты посещали страницы.
Сканирование — это процесс, когда поисковые роботы посещают ваш сайт, обрабатывают все ссылки на веб-страницах и помещают эти ссылки в очередь на индексацию. Во время сканирования боты сравнивают только что обработанные URL-адреса с теми, которые уже находятся в индексе. Таким образом, боты обновляют данные и добавляют/удаляют некоторые URL-адреса из базы данных поисковой системы, чтобы предоставить пользователям наиболее актуальные и свежие результаты.
Теперь мы можем легко сделать следующие выводы:
- Если поисковый бот не был на URL-адресе, этот URL-адрес, вероятно, не будет в индексе.
- Если робот Googlebot посещает URL-адрес несколько раз в день, этот URL-адрес имеет высокий приоритет и поэтому требует вашего особого внимания.
В целом эта информация показывает, что мешает органическому росту и развитию вашего сайта. Теперь вместо того, чтобы действовать вслепую, ваша команда может разумно оптимизировать веб-сайт.
В основном мы работаем с крупными веб-сайтами, потому что, если ваш веб-сайт небольшой, робот Googlebot рано или поздно просканирует все ваши веб-страницы.
И наоборот, веб-сайты с более чем 100 000 страниц сталкиваются с проблемой, когда сканер посещает страницы, невидимые для веб-мастеров. Ценный краулинговый бюджет может быть потрачен впустую на эти бесполезные или даже вредные страницы. При этом бот может так и не найти ваши прибыльные страницы из-за бардака в структуре сайта.
Бюджет сканирования — это ограниченные ресурсы, которые робот Googlebot готов потратить на ваш сайт. Он был создан, чтобы расставить приоритеты, что анализировать и когда. Размер краулингового бюджета зависит от многих факторов, таких как размер вашего сайта, его структура, объем и частота запросов пользователей и т. д.
Обратите внимание, что поисковый бот не заинтересован в полном сканировании вашего сайта.
Основная цель поискового бота — дать пользователям максимально релевантные ответы с минимальными потерями ресурсов.Бот сканирует столько данных, сколько ему нужно для основной цели. Итак, ВАША задача помочь боту подобрать наиболее полезный и прибыльный контент.
Шпионить за Googlebot
За последний год мы просканировали более 300 миллионов URL-адресов и 6 миллиардов строк журнала на крупных веб-сайтах. На основе этих данных мы проследили поведение робота Googlebot, чтобы ответить на следующие вопросы:
- Какие типы страниц игнорируются?
- Какие страницы часто посещаются?
- На что стоит обратить внимание для бота?
- Что не имеет ценности?
Ниже представлен наш анализ и выводы, а не переписанное руководство Google для веб-мастеров. На самом деле мы не даем бездоказательных и необоснованных рекомендаций. Каждый пункт основан на фактической статистике и графиках для вашего удобства.
Давайте перейдем к делу и узнаем:
- Что действительно важно для робота Googlebot?
- От чего зависит, посещает ли бот страницу или нет?
Мы выделили следующие факторы:
Расстояние от индекса
DFI расшифровывается как «Расстояние от индекса» и показывает, насколько далеко ваш URL-адрес от основного/корневого/индексного URL-адреса в кликах. Это один из важнейших критериев, влияющих на частоту посещений Googlebot. Вот учебное видео, чтобы узнать больше о DFI .
Обратите внимание, что DFI — это не количество косых черт в каталоге URL, например:
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
Итак, DFI считается именно по КЛИКАМ с главной страницы
https://site.com/shop/iphone/iphoneX.html
https://site.com Каталог iPhone → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html — DFI — 2
Ниже вы можете увидеть, как интерес Googlebot к URL-адресу с его DFI постепенно снижался в течение последнего месяца и в течение последних шести месяцев.
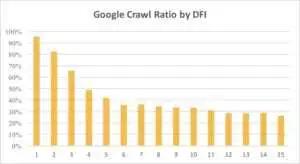
Как видите, если DFI равен 5 t0 6, робот Googlebot сканирует только половину веб-страниц. И процент обработанных страниц уменьшается, если DFI больше. Показатели в таблице были унифицированы на 18 млн страниц. Обратите внимание, что данные могут варьироваться в зависимости от ниши конкретного веб-сайта.
Что делать?
Очевидно, что лучшая стратегия в этом случае — избегать DFI длиннее 5, создавать удобную для навигации структуру сайта, уделять особое внимание ссылкам и т. д.
Правда в том, что эти меры действительно отнимают много времени для веб-сайтов на 100 000 и более страниц. Обычно большие веб-сайты имеют долгую историю редизайнов и миграций. Вот почему веб-мастерам не стоит просто удалять страницы с DFI 10, 12 или даже 30. Также не решит проблему вставка одной ссылки с часто посещаемых страниц.
Оптимальный способ справиться с длинным DFI — проверить и оценить, являются ли эти URL релевантными, прибыльными и какие позиции они занимают в поисковой выдаче.
Страницы с длинным DFI, но хорошими позициями в поисковой выдаче имеют высокий потенциал. Чтобы увеличить посещаемость качественных страниц, веб-мастерам следует вставлять ссылки со следующих страниц. Одной-двух ссылок недостаточно для ощутимого прогресса.
На графике ниже видно, что Googlebot чаще посещает URL-адреса, если на странице более 10 ссылок.
Ссылки
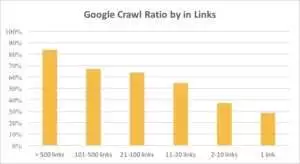
На самом деле, чем больше веб-сайт, тем больше ссылок на веб-страницах. Эти данные на самом деле взяты с веб-сайтов, насчитывающих более 1 миллиона страниц.

Если вы обнаружили, что на ваших прибыльных страницах меньше 10 ссылок, не паникуйте. Во-первых, проверьте, являются ли эти страницы качественными и прибыльными. При этом вставляйте ссылки на качественные страницы без спешки и с короткими итерациями, анализируя логи после каждого шага.
Размер содержимого
Контент — один из самых популярных аспектов SEO-анализа. Конечно, чем более релевантный контент находится на вашем сайте, тем лучше ваш коэффициент сканирования. Ниже вы можете увидеть, как резко падает интерес робота Googlebot к страницам, содержащим менее 500 слов.
Что делать?
Исходя из моего опыта, почти половина всех страниц, содержащих менее 500 слов, являются мусорными. Мы видели случай, когда веб-сайт содержал 70 000 страниц, на которых были указаны только размеры одежды, поэтому в индекс попала только часть этих страниц.
Поэтому сначала проверьте, действительно ли вам нужны эти страницы. Если эти URL-адреса важны, вы должны добавить к ним релевантный контент. Если вам нечего добавить, просто расслабьтесь и оставьте эти URL как есть. Иногда лучше ничего не делать, чем публиковать бесполезный контент.
Другие факторы
Следующие факторы могут существенно повлиять на коэффициент сканирования:
Время загрузки
Скорость веб-страницы имеет решающее значение для сканирования и ранжирования. Бот похож на человека: он ненавидит слишком долго ждать загрузки веб-страницы. Если на вашем веб-сайте более 1 миллиона страниц, поисковый бот, скорее всего, загрузит пять страниц с временем загрузки в 1 секунду, а не будет ждать, пока одна страница загрузится за 5 секунд.
Что делать?
На самом деле это техническая задача, и нет универсального решения, такого как использование большего сервера. Основная идея состоит в том, чтобы найти узкое место проблемы. Вы должны понимать, почему веб-страницы загружаются медленно. Только после выявления причины можно приступать к действиям.
Соотношение уникального и шаблонного контента
Баланс между уникальными и шаблонными данными важен. Например, у вас есть веб-сайт с вариантами имен домашних животных. Сколько релевантного и уникального контента вы действительно можете собрать по этой теме?
Луна была самой популярной кличкой «знаменитости», за ней следовали Стелла, Джек, Майло и Лео.
Поисковые боты не любят тратить свои ресурсы на такие страницы.
Что делать?
Поддерживайте баланс. Пользователи и боты не любят посещать страницы со сложными шаблонами, кучей исходящих ссылок и мало контента.
Страницы-сироты
Страницы-сироты — это URL-адреса, которых нет в структуре веб-сайта, и вы не знаете об этих страницах, но эти страницы-сироты могут быть просканированы ботами. Чтобы было понятно, посмотрите на круг Эйлера на картинке ниже:

Вы видите нормальную ситуацию для молодого сайта, структура которого давно не менялась. Вы и сканер можете проанализировать 900 000 страниц. Поисковый робот обрабатывает около 500 000 страниц, но они неизвестны Google. Если вы сделаете эти 500 000 URL-адресов индексируемыми, ваш трафик обязательно возрастет.
Обратите внимание: Даже на молодом сайте есть страницы (синяя часть на картинке), которые не входят в структуру сайта, но регулярно посещаются ботом.
И эти страницы могут содержать мусорный контент, такой как бесполезные автоматически сгенерированные запросы посетителей.
Но большие веб-сайты редко бывают такими точными. Очень часто сайты с историей выглядят так:

Вот еще одна проблема: Google знает о вашем сайте больше, чем вы. Могут быть удаленные страницы, страницы на JavaScript или Ajax, сломанные редиректы и так далее и тому подобное. Однажды мы столкнулись с ситуацией, когда из-за ошибки программиста в карте сайта появился список из 500 000 битых ссылок. Через три дня ошибка была найдена и исправлена, но гуглбот ходил по этим неработающим ссылкам уже полгода!
Очень часто ваш краулинговый бюджет часто тратится на эти страницы-сироты.
Что делать?
Есть два способа решить эту потенциальную проблему: Первый — канонический: навести порядок. Организуйте структуру сайта, правильно вставляйте внутренние ссылки, добавляйте страницы-сироты в DFI, добавляя ссылки с проиндексированных страниц, ставьте задачу программистам и ждите следующего визита робота Google.
Второй способ оперативный: собрать список страниц-сирот и проверить, актуальны ли они. Если ответ «да», создайте карту сайта с этими URL-адресами и отправьте ее в Google. Этот способ проще и быстрее, но в индекс попадет только половина страниц-сирот.
Следующий уровень
Алгоритмы поисковых систем совершенствовались за два десятилетия, и наивно полагать, что поисковое сканирование можно объяснить с помощью нескольких графиков.
Мы собираем более 200 различных параметров для каждой страницы, и мы ожидаем, что к концу года это число увеличится. Представьте, что ваш сайт представляет собой таблицу с 1 миллионом строк (страниц) и умножьте эти строки на 200 столбцов, простой выборки недостаточно для всестороннего технического аудита. Вы согласны?
Мы решили копнуть глубже и использовали машинное обучение, чтобы выяснить, что влияет на сканирование Googlebots в каждом конкретном случае.

С одной стороны, ссылки на веб-сайты имеют решающее значение, в то время как контент является ключевым фактором для другой.
Суть этой задачи заключалась в том, чтобы получить простые ответы из сложных и массивных данных: что на вашем сайте больше всего влияет на индексацию? Какие кластеры URL-адресов связаны с одними и теми же факторами? Так что вы можете работать с ними комплексно.
До скачивания и анализа логов на нашем сайте-агрегаторе HotWork история с страницами-сиротами, которые видны ботам, но не нам, казалась мне нереальной. Но реальная ситуация меня еще больше удивила: сканирование показало 500 страниц с 301 редиректом, а Яндекс нашел 700 000 страниц с таким же кодом статуса.
Обычно технические гики не любят хранить лог-файлы, потому что эти данные «перегружают» диски. Но объективно на большинстве сайтов с посещаемостью до 10 млн в месяц базовая настройка хранения логов работает отлично.
Говоря об объеме логов, лучшее решение — создать архив и загрузить его на Amazon S3-Glacier (вы можете хранить 250 ГБ данных всего за 1 доллар). Для системных администраторов эта задача так же проста, как приготовление чашки кофе. В дальнейшем исторические журналы помогут выявить технические ошибки и оценить влияние обновлений Google на ваш сайт.