
Apache Spark: ประกายดาวในนภาข้อมูลขนาดใหญ่
เผยแพร่แล้ว: 2015-09-24- แนะนำผลิตภัณฑ์นับล้านให้กับลูกค้าที่เหมาะสม
- ติดตามประวัติการค้นหาและเสนอราคาส่วนลดสำหรับการเดินทางเที่ยวบิน
- การเปรียบเทียบทักษะทางเทคนิคของบุคคลและการแนะนำบุคคลที่จะเชื่อมต่อในสาขาของคุณอย่างเหมาะสม
- ทำความเข้าใจรูปแบบในอ็อบเจ็กต์เคลื่อนที่หลายพันล้านรายการ เสาเครือข่าย และธุรกรรมการโทร และคำนวณการเพิ่มประสิทธิภาพเครือข่ายโทรคมนาคมหรือค้นหาช่องโหว่ของเครือข่าย
- ศึกษาคุณสมบัติของเซ็นเซอร์นับล้านและวิเคราะห์ความล้มเหลวในเครือข่ายเซ็นเซอร์
ข้อมูลพื้นฐานที่จำเป็นเพื่อใช้เพื่อให้ได้ผลลัพธ์ที่ถูกต้องสำหรับงานข้างต้นทั้งหมดนั้นค่อนข้างใหญ่ ไม่สามารถจัดการได้อย่างมีประสิทธิภาพ (ทั้งในแง่ของพื้นที่และเวลา) โดยระบบดั้งเดิม
ทั้งหมดนี้เป็นสถานการณ์จำลองข้อมูลขนาดใหญ่
ในการรวบรวม จัดเก็บ และทำการคำนวณเกี่ยวกับข้อมูลจำนวนมากเช่นนี้ เราจำเป็นต้องมีระบบการประมวลผลแบบคลัสเตอร์เฉพาะ Apache Hadoop ได้แก้ไขปัญหานี้ให้เราแล้ว
นำเสนอ ระบบจัดเก็บข้อมูลแบบกระจาย (HDFS) และ แพลตฟอร์มการประมวลผลแบบขนาน (MapReduce)
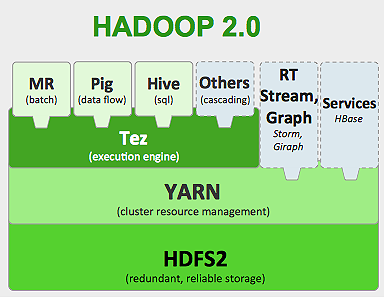
Hadoop framework ทำงานดังนี้:
- แบ่งไฟล์ข้อมูลขนาดใหญ่ออกเป็นชิ้นเล็กๆ เพื่อประมวลผลโดยแต่ละเครื่อง (Distributing Storage)
- แบ่งงานที่ยาวกว่าออกเป็นงานที่เล็กกว่าเพื่อดำเนินการแบบคู่ขนาน (Parallel Computation)
- จัดการความล้มเหลวโดยอัตโนมัติ
ข้อจำกัดของ Hadoop
Hadoop มีเครื่องมือพิเศษในระบบนิเวศเพื่อทำงานต่างๆ ดังนั้น หากคุณต้องการใช้งานแอปพลิเคชันแบบ end-to-end คุณจะต้องใช้เครื่องมือหลายอย่าง ตัวอย่างเช่น สำหรับการสืบค้น SQL คุณจะใช้ hive/pig สำหรับแหล่งการ สตรีม คุณต้องใช้ Hadoop inbuilt streaming หรือ Apache Storm (ซึ่งไม่ได้เป็นส่วนหนึ่งของระบบนิเวศ Hadoop) หรือสำหรับอัลกอริธึม การเรียนรู้ของเครื่อง คุณต้องใช้ Mahout การรวมระบบทั้งหมดเหล่านี้เข้าด้วยกันเพื่อสร้างกรณีการใช้งานไปป์ไลน์ข้อมูลเดียวนั้นค่อนข้างเป็นงานที่ค่อนข้างง่าย
ในงาน MapReduce
- เอาต์พุตงานแผนที่ทั้งหมดถูกดัมพ์บนดิสก์ในเครื่อง (หรือ HDFS)
- Hadoop รวมไฟล์การรั่วไหลทั้งหมดเป็นไฟล์ที่ใหญ่กว่าซึ่งถูกจัดเรียงและแบ่งพาร์ติชั่นตามจำนวนตัวลด
- และลดภาระงานต้องโหลดเข้าหน่วยความจำอีกครั้ง
กระบวนการนี้ทำให้งานช้าลงทำให้ดิสก์ I/O และเครือข่าย I/O สิ่งนี้ทำให้ Mapreduce ไม่เหมาะสำหรับการประมวลผลแบบวนซ้ำ ซึ่งคุณต้องใช้อัลกอริธึมการเรียนรู้ของเครื่องกับกลุ่มข้อมูลเดียวกันซ้ำแล้วซ้ำอีก
เข้าสู่โลกของ Apache Spark:
Apache Spark ได้รับการพัฒนาใน UC Berkeley AMPLAB ในปี 2009 และในปี 2010 มันได้กลายเป็นโปรเจ็กต์โอเพ่นซอร์สที่มีส่วนสนับสนุนอันดับต้น ๆ ของ Apache จนถึงปัจจุบัน
Apache Spark เป็นระบบ ทั่วๆ ไป ซึ่งคุณสามารถ เรียกใช้งานทั้งแบบแบตช์และสตรีม พร้อมกันได้ มันเข้ามาแทนที่ MapReduce รุ่นก่อนด้วยความเร็วโดยเพิ่มความสามารถในการประมวลผลข้อมูลในหน่วยความจำได้เร็วขึ้น นอกจากนี้ยังมีประสิทธิภาพมากขึ้นบนดิสก์ มันใช้ประโยชน์จากการประมวลผลหน่วยความจำโดยใช้หน่วยข้อมูลพื้นฐาน RDD (ชุดข้อมูลที่กระจายแบบยืดหยุ่น) ชุดข้อมูลเหล่านี้เก็บชุดข้อมูลไว้ในหน่วยความจำให้มากที่สุดเท่าที่จะเป็นไปได้สำหรับวงจรชีวิตที่สมบูรณ์ ดังนั้นจึงช่วยประหยัดดิสก์ I/O ข้อมูลบางอย่างอาจล้นบนดิสก์หลังจากขีดจำกัดสูงสุดของหน่วยความจำ
กราฟด้านล่างแสดงเวลาทำงานเป็นวินาทีของทั้ง Apache Hadoop และ Spark สำหรับการคำนวณการถดถอยโลจิสติก Hadoop ใช้เวลา 110 วินาทีในขณะที่ spark ทำงานเดียวกันเสร็จในเวลาเพียง 0.9 วินาที
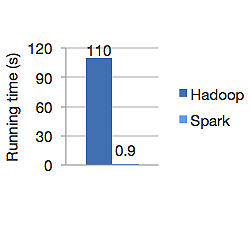
Spark ไม่ได้เก็บข้อมูลทั้งหมดในหน่วยความจำ แต่ถ้าข้อมูลอยู่ในหน่วยความจำ จะทำให้ใช้แคช LRU ได้ดีที่สุดเพื่อประมวลผลเร็วขึ้น ขณะที่ประมวลผลข้อมูลในหน่วยความจำเร็วขึ้น 100 เท่า และบนดิสก์ยังเร็วกว่า Hadoop
โมเดลการจัดเก็บข้อมูลแบบกระจายของ Spark ชุดข้อมูลแบบกระจายที่ยืดหยุ่น (RDD) รับประกันความทนทานต่อข้อผิดพลาดซึ่งจะช่วยลด I/O ของเครือข่าย กระดาษประกาย พูดว่า:

"RDD บรรลุความทนทานต่อข้อผิดพลาดผ่านแนวคิดเรื่องสายเลือด: หากพาร์ติชั่นของ RDD หายไป RDD ก็มีข้อมูลเพียงพอเกี่ยวกับวิธีการที่มันได้มาจาก RDD อื่น ๆ เพื่อให้สามารถสร้างพาร์ติชั่นนั้นขึ้นมาใหม่ได้"
ดังนั้นคุณจึงไม่จำเป็นต้องทำซ้ำข้อมูลเพื่อให้เกิดความทนทานต่อข้อผิดพลาด
ใน Spark MapReduce เอาต์พุตของ mappers จะถูกเก็บไว้ในบัฟเฟอร์แคชของ OS และตัวลดจะดึงไปด้านข้างและเขียนลงในหน่วยความจำโดยตรง ซึ่งแตกต่างจาก Hadoop ที่เอาต์พุตจะหกลงดิสก์และอ่านอีกครั้ง
แคชหน่วยความจำของ Spark ทำให้เหมาะสำหรับอัลกอริธึมการเรียนรู้ของเครื่องที่คุณจำเป็นต้องใช้ข้อมูลเดิมซ้ำแล้วซ้ำอีก Spark สามารถเรียกใช้งานที่ซับซ้อน ไปป์ไลน์ข้อมูลหลายขั้นตอนโดยใช้ Direct Acyclic Graph (DAGs)
Spark เขียนด้วย Scala และทำงานบน JVM (Java Virtual Machine) Spark เสนอ API การพัฒนาสำหรับภาษา Java, Scala, Python และ R Spark ทำงานบน Hadoop YARN, Apache Mesos และมีตัวจัดการคลัสเตอร์แบบสแตนด์อโลนของตัวเอง
ในปี 2014 บริษัทได้อันดับที่ 1 ในสถิติโลกสำหรับการจัดเรียงข้อมูล 100TB (1 ล้านล้านระเบียน) ในเวลาเพียง 23 นาที โดยที่ Yahoo ที่เคยบันทึก Hadoop ไว้ก่อนหน้านั้นอยู่ที่ 72 นาที สิ่งนี้พิสูจน์ได้ว่า Spark จัดเรียงข้อมูลเร็วขึ้น 3 เท่าและด้วยเครื่องจักรน้อยกว่า 10 เท่า การเรียงลำดับทั้งหมดเกิดขึ้นบนดิสก์ (HDFS) โดยไม่ใช้ความสามารถแคชในหน่วยความจำแบบ spark
ระบบนิเวศของประกายไฟ
Spark มีไว้สำหรับทำการ วิเคราะห์ ขั้นสูง ในครั้งเดียว เพื่อให้บรรลุโดยมีส่วนประกอบดังต่อไปนี้:
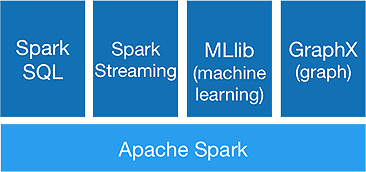
1.Spark แกน:
Spark core API เป็นพื้นฐานของ Apache Spark framework ซึ่งจัดการการจัดกำหนดการงาน การกระจายงาน การจัดการหน่วยความจำ การดำเนินการ I/O และการกู้คืนจากความล้มเหลว หน่วยข้อมูลลอจิคัลหลักใน spark เรียกว่า RDD (Resilient Distributed Dataset) ซึ่งจัดเก็บข้อมูลในลักษณะแบบกระจายเพื่อประมวลผลแบบคู่ขนานในภายหลัง มันคำนวณการดำเนินการอย่างเกียจคร้าน ดังนั้นหน่วยความจำจึงไม่จำเป็นต้องถูกครอบครองตลอดเวลา และงานอื่นๆ ก็สามารถนำไปใช้ได้
2.Spark SQL:
นำเสนอความสามารถในการสืบค้นแบบโต้ตอบ ที่มีเวลาแฝงต่ำ DataFrame API ใหม่สามารถเก็บทั้งข้อมูลที่มีโครงสร้างและกึ่งโครงสร้าง และอนุญาตให้การดำเนินการและฟังก์ชันของ SQL ทั้งหมดทำการคำนวณ
3.Spark สตรีมมิ่ง:
ให้บริการ สตรีมมิ่ง API แบบเรียลไทม์ ซึ่งรวบรวมและประมวลผลข้อมูลเป็นไมโครแบตช์
มันใช้ Dstreams ซึ่งไม่มีอะไรเลยนอกจาก ลำดับ RDD ที่ต่อเนื่องกัน เพื่อคำนวณตรรกะทางธุรกิจกับข้อมูลที่เข้ามาและสร้างผลลัพธ์ทันที
4.MLlib :
เป็น ไลบรารีแมชชีนเลิร์นนิงของ spark (เร็วกว่า Mahout เกือบ 9 เท่า) ซึ่งให้การเรียนรู้ของเครื่องรวมถึงอัลกอริธึมทางสถิติ เช่น การจัดประเภท การถดถอย การกรองการทำงานร่วมกัน เป็นต้น
5.GraphX :
GraphX API ให้ความสามารถในการจัดการกราฟและดำเนินการคำนวณแบบกราฟคู่ขนาน ประกอบด้วยอัลกอริธึมกราฟ เช่น PageRank และฟังก์ชันต่างๆ เพื่อวิเคราะห์กราฟ
Spark จะทำเครื่องหมายจุดสิ้นสุดของ Hadoop Era หรือไม่?
Spark ยังคงเป็นระบบที่อายุน้อย ยังไม่โตเต็มที่เหมือน Hadoop ไม่มีเครื่องมือสำหรับ NOSQL เช่น HBase เมื่อพิจารณาถึงความต้องการหน่วยความจำสูงสำหรับการประมวลผลข้อมูลที่เร็วขึ้น คุณไม่สามารถพูดได้ว่ามันทำงานบนฮาร์ดแวร์สินค้าโภคภัณฑ์ Spark ไม่มีระบบจัดเก็บข้อมูลของตัวเอง มันอาศัย HDFS สำหรับสิ่งนั้น
ดังนั้น Hadoop MapReduce ยังคงดีสำหรับงานแบทช์บางงาน ซึ่งไม่มีการวางไปป์ไลน์ข้อมูลมากนัก
“เทคโนโลยีใหม่ไม่เคยแทนที่เทคโนโลยีเก่าได้อย่างสมบูรณ์ พวกเขาทั้งสองค่อนข้างจะอยู่ร่วมกัน”
บทสรุป
ในบล็อกนี้ เรามาดูกันว่าทำไมคุณถึงต้องการเครื่องมืออย่าง Spark สิ่งที่ทำให้ระบบประมวลผลคลัสเตอร์เร็วขึ้นและส่วนประกอบหลัก ส่วนต่อไปเราจะเจาะลึกเข้าไปใน Spark core API RDD การเปลี่ยนแปลงและการดำเนินการ