
Bright Data Scraping Browser Review 2023: เครื่องมือที่ดีที่สุดในการแยกข้อมูลออนไลน์?
เผยแพร่แล้ว: 2023-04-26ข้อดี
- แผนการกำหนดราคาที่ยืดหยุ่น
- เครือข่ายความเร็วสูงที่เชื่อถือได้สำหรับการทำงานกับข้อมูล
- ใช้งานง่ายและมีประสิทธิภาพ
- ตั้งค่าได้ง่าย
- การสนับสนุนการปฏิบัติงาน
- การสนับสนุนลูกค้าโดยเฉพาะ
- ตัวเลือกที่หลากหลายและการตั้งค่าแบบกำหนดเองสำหรับความต้องการบริการพร็อกซี
- ทำงานได้อย่างเสถียรโดยไม่มีการหยุดชะงัก
ข้อเสีย
- สามารถมีใบแจ้งราคาเพิ่มเติมเพื่อให้เหมาะกับความต้องการของลูกค้า
- ไม่ใช่ผู้ให้บริการออนไลน์ที่ถูกที่สุด
Bright Data Scraping Browser เป็นเบราว์เซอร์อัตโนมัติแบบครบวงจรที่ออกแบบมาเพื่อวัตถุประสงค์ในการขูดข้อมูล มันมาพร้อมกับคุณสมบัติและประโยชน์มากมายที่ทำให้เป็นเครื่องมือที่เชื่อถือได้สำหรับโครงการขูดข้อมูล Bright Data Scraping Browser ช่วยให้คุณประหยัดเวลา เงิน และทรัพยากรด้วยการมอบเบราว์เซอร์ที่ทำทุกอย่างให้คุณ
กำลังมองหา การตรวจสอบเบราว์เซอร์ Bright Data Scraping ที่เป็นกลาง ไม่ต้องกังวล ฉันเข้าใจคุณแล้ว
การขูดข้อมูลเป็นเครื่องมือที่จำเป็นสำหรับธุรกิจและนักวิจัยในการดึงข้อมูลเชิงลึกอันมีค่าจากอินเทอร์เน็ต
อย่างไรก็ตาม อาจเป็นงานที่ท้าทายและใช้เวลานาน โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับเว็บไซต์ที่ซับซ้อนซึ่งใช้ระบบตรวจจับบอตและการบล็อกเว็บไซต์
Bright Data Scraping Browser เป็น เบราว์เซอร์อัตโนมัติแบบครบวงจร ที่ออกแบบมาเพื่อวัตถุประสงค์ในการขูดข้อมูลโดยเฉพาะ
ในบทความนี้ เราจะทบทวน คุณสมบัติหลักและประโยชน์ ของ Bright Data Scraping Browser และอธิบายว่าทำไมมันถึงเป็นเครื่องมือที่เชื่อถือได้สำหรับโปรเจ็กต์การขูดข้อมูล
ไม่ว่าคุณจะเป็นเจ้าของธุรกิจขนาดเล็กหรือองค์กรขนาดใหญ่ บทวิจารณ์นี้จะช่วยคุณพิจารณาว่า Bright Data Scraping Browser เป็นเครื่องมือที่เหมาะสมสำหรับความต้องการในการขูดข้อมูลของคุณหรือไม่
สารบัญ
Scraping Browser คืออะไรและทำไมจึงต้องใช้
เบราว์เซอร์ขูดเป็นเบราว์เซอร์ที่ทำงานโดยอัตโนมัติและถูกใช้โดยผู้เขียนโค้ดเพื่อรับข้อมูล สามารถจัดการได้โดย API ระดับสูง เช่น Puppeteer และ Playwright และมีคุณสมบัติในตัวสำหรับการปลดบล็อกเว็บไซต์
ไม่เหมือนเว็บไซต์เปล่า เบราว์เซอร์ขูดมี ส่วนติดต่อผู้ใช้แบบกราฟิก (GUI) ที่ช่วยให้คุณตัดสินใจได้ว่าจะทำงานอย่างไร
เมื่อทำการคัดลอกข้อมูล นักพัฒนาซอฟต์แวร์จะใช้เบราว์เซอร์อัตโนมัติเมื่อจำเป็นต้องแสดงผลหน้าเว็บใน JavaScript หรือจำเป็นต้องเชื่อมต่อกับเว็บไซต์
ตัวอย่างเช่น การย้าย การเปลี่ยนหน้า การคลิก และแม้แต่การจับภาพหน้าจอ นอกจากนี้ เบราว์เซอร์ยังช่วยในโครงการขูดข้อมูลขนาดใหญ่ที่กำหนดเป้าหมายหลายหน้าพร้อมกัน
Scraping Browser เป็นวิธีที่ดีกว่ามากในการปรับขนาดโปรเจ็กต์การขูดข้อมูลและหลีกเลี่ยงบล็อกต่าง ๆ มากกว่าเบราว์เซอร์เปล่า ๆ เบราว์เซอร์ที่ไม่มีส่วนหัวคือเว็บเบราว์เซอร์ที่ไม่มีส่วนติดต่อผู้ใช้ที่มองเห็นได้
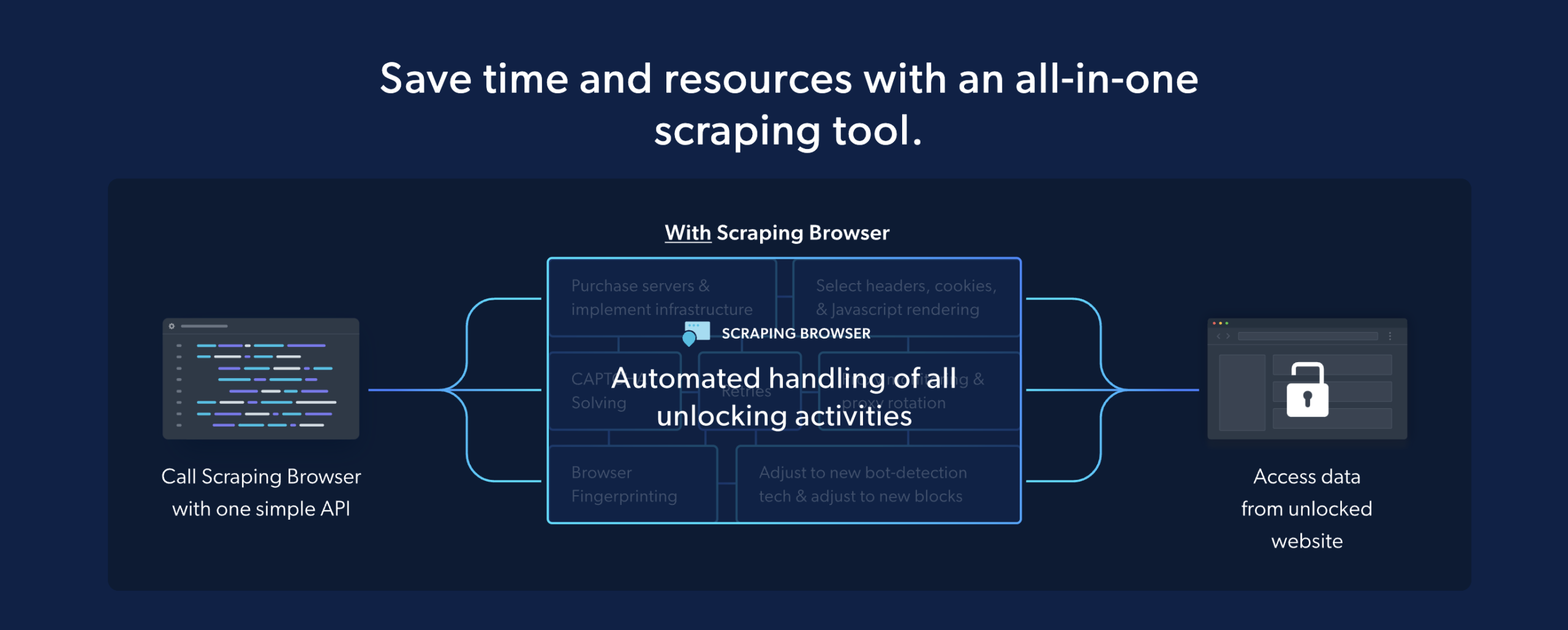
เบราว์เซอร์เหล่านี้มักใช้กับพร็อกซีเพื่อขูดข้อมูล แต่ซอฟต์แวร์ป้องกันบอทสามารถตรวจจับได้ง่าย ทำให้ยากที่จะขูดข้อมูลในปริมาณมาก
ความจริงที่ว่า Scraping Browser เปิดอยู่บนคอมพิวเตอร์ของ Bright Data ก็เป็นประโยชน์อีกประการหนึ่ง ทำให้เหมาะสำหรับโครงการที่ต้องการขยายขนาด
นักพัฒนาสามารถเปิด Scraping Browser ได้มากเท่าที่ต้องการโดยไม่ต้องเสียเงินซื้อระบบราคาแพงในคอมพิวเตอร์ของตนเอง
นอกจากนี้ Scraping Browser มีโอกาสน้อยที่จะพบโดยซอฟต์แวร์ที่มองหาบ็อตเนื่องจากมีอินเทอร์เฟซ GUI ทำให้เป็นเครื่องมือที่เชื่อถือได้มากขึ้นสำหรับการคัดลอกข้อมูล



Bright Data Scraping Browser & คู่มือการซื้อ
ขั้นตอน - 1: ไปที่ เว็บไซต์อย่างเป็นทางการของ Bright Data Scraping Browser เลื่อนลงและเลือกแผนที่คุณต้องการ
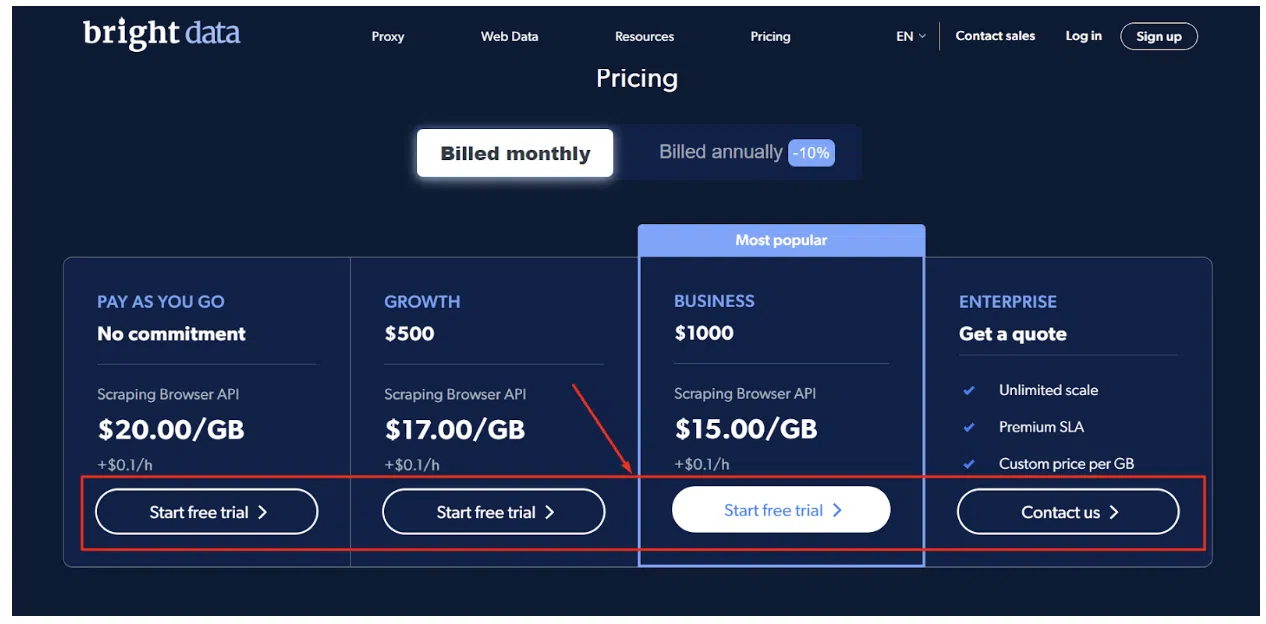
ขั้นตอนที่ 2: กรอกรายละเอียดที่ต้องการ ทำเครื่องหมายที่ช่อง และคลิก 'สร้างบัญชี'
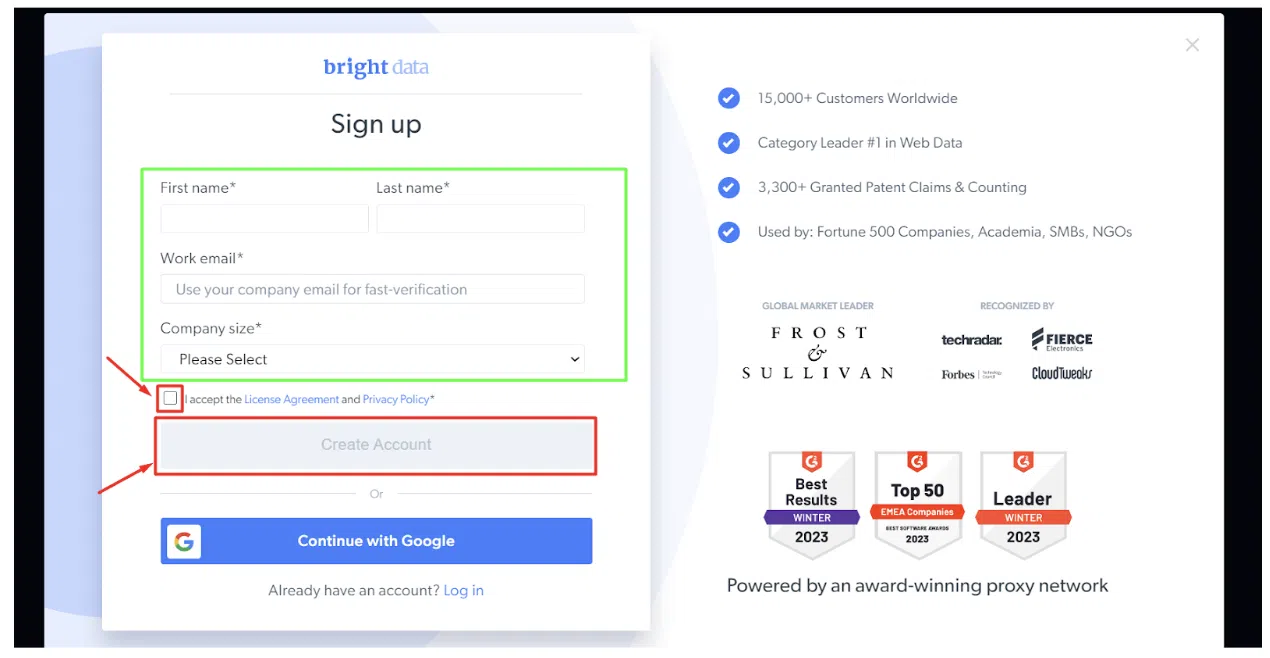
ขั้นตอน – 3: กรอกรายละเอียดและคลิกที่ 'สมัคร'
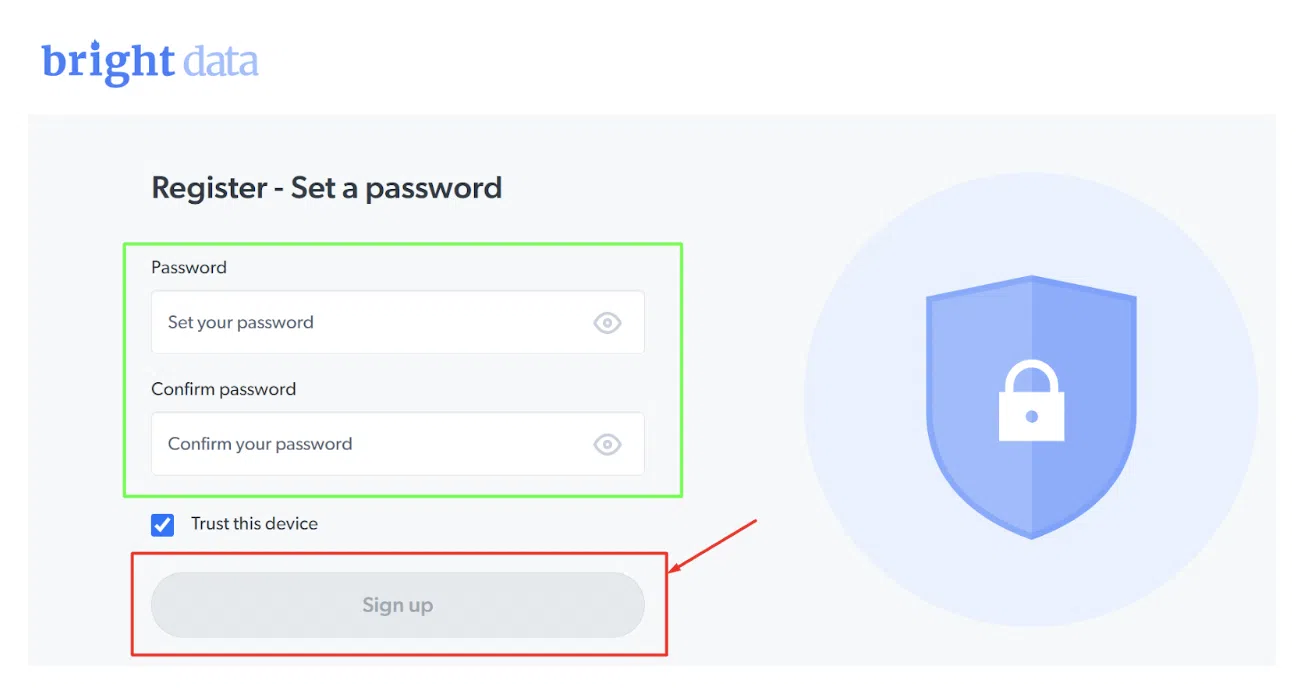
ขั้นตอนที่ 4: คลิกที่ 'เริ่มต้นใช้งาน' ด้านล่าง Bright Data Scraping Browser
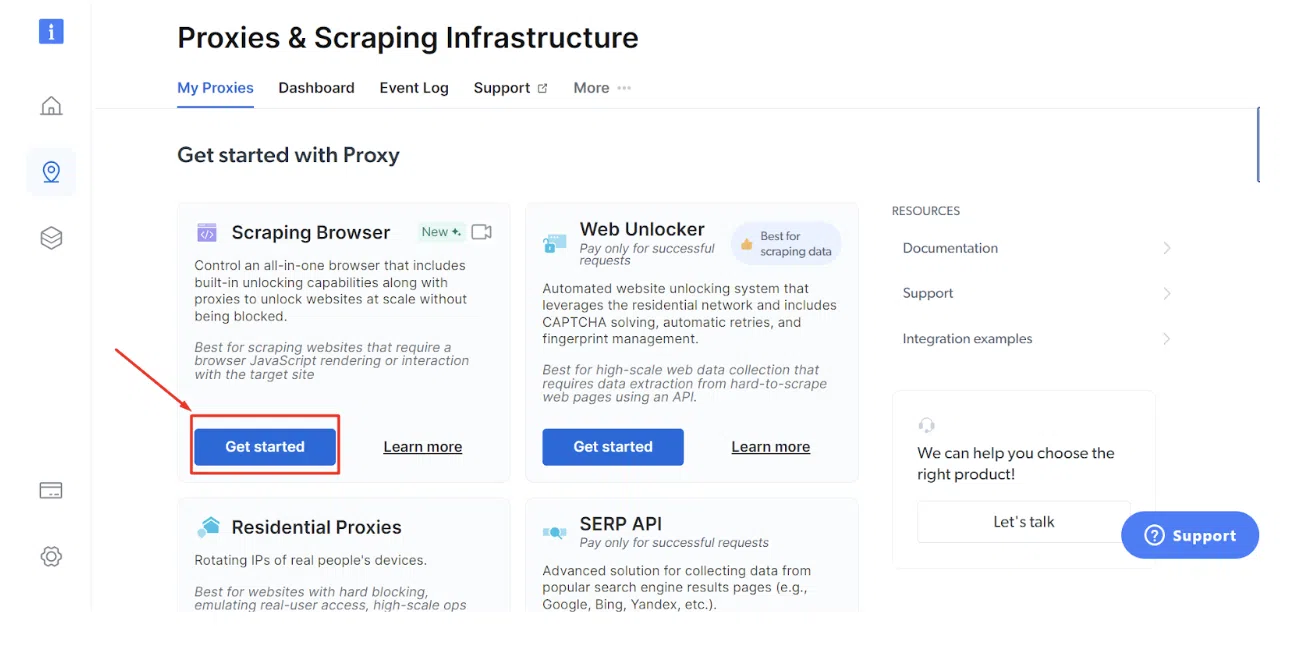
ขั้นตอนที่ 5: คลิกที่ 'บันทึกและเปิดใช้งาน'
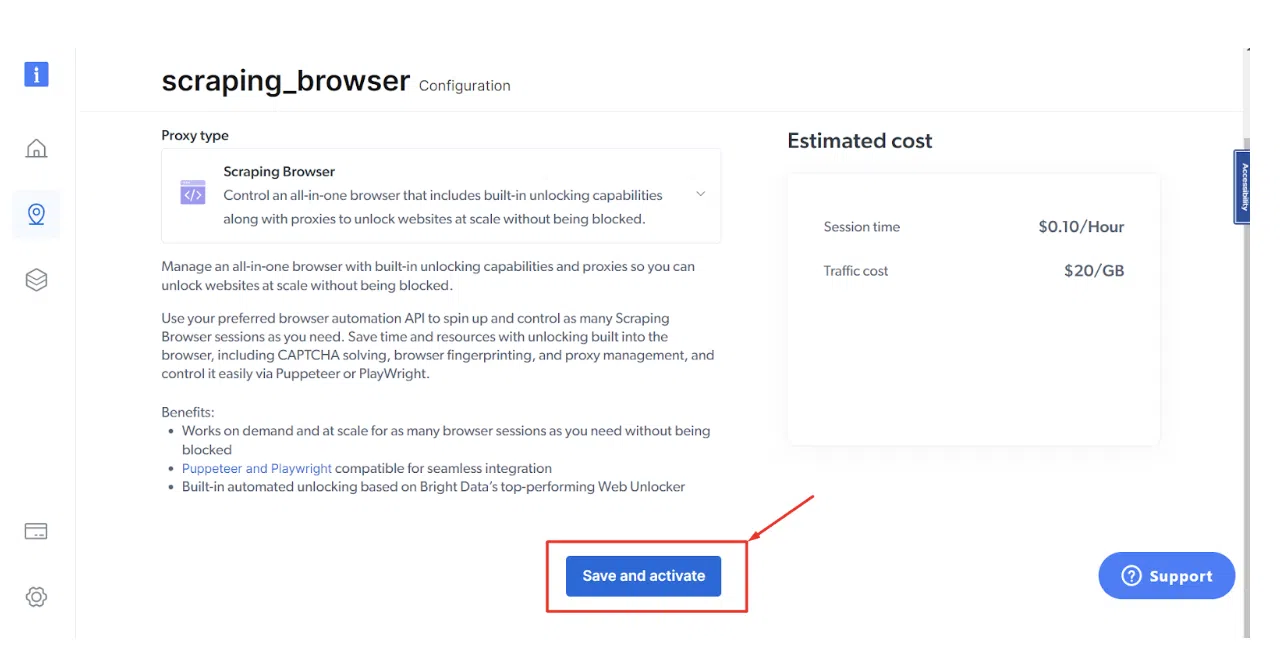
ขั้นตอนที่ 6: กรอกข้อมูลการเรียกเก็บเงินและคลิกที่ 'บันทึกที่อยู่'
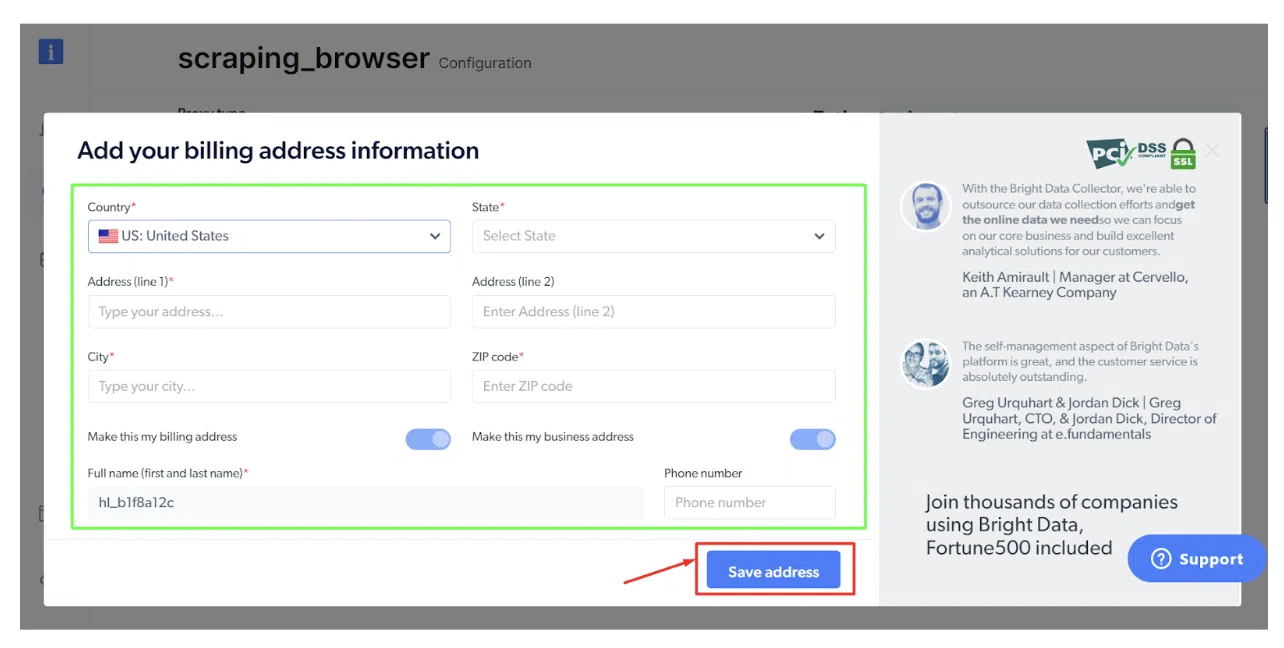
ชำระเงินให้เสร็จสิ้นและคุณพร้อมที่จะไป
เหตุใดฉันจึงแนะนำให้ใช้เบราว์เซอร์ขูดข้อมูลที่สดใส
Bright Data Scraping Browser เป็นเบราว์เซอร์อัตโนมัติที่ออกแบบมาเพื่อวัตถุประสงค์ในการขูดข้อมูลโดยเฉพาะ ต่อไปนี้คือเหตุผลบางประการที่ฉันแนะนำให้ใช้เบราว์เซอร์นี้สำหรับโปรเจ็กต์การขูดข้อมูลของคุณ:
1. นักเชิดหุ่นและนักเขียนบทละครเข้ากันได้:
Bright Data Scraping Browser ทำงานร่วมกับทั้ง Puppeteer (Python) และ Playwright (Node.js) ซึ่งเป็น API ยอดนิยมสองรายการสำหรับการขูดข้อมูลโดยอัตโนมัติ
ซึ่งช่วยให้ผู้เขียนโค้ดได้รับเซสชันเบราว์เซอร์จำนวนเท่าใดก็ได้และทำงานกับเซสชันเหล่านั้นโดยใช้ Puppeteer หรือ Playwright ผ่านอินเทอร์เฟซ CDP
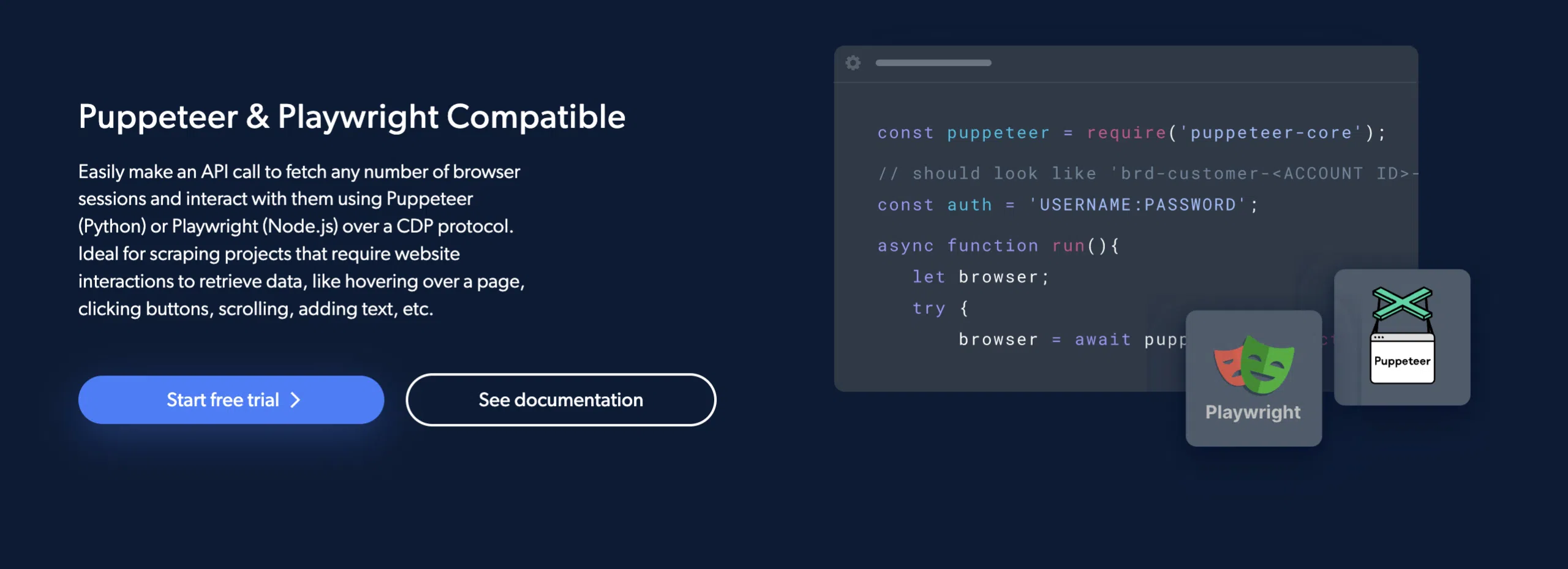
2. ความสามารถในการปรับขนาด:
เบราว์เซอร์ Bright Data Scraping ถูกจัดเก็บไว้ในเซิร์ฟเวอร์ของ Bright Data ซึ่งสามารถปรับขนาดได้มาก สิ่งนี้ทำให้สมบูรณ์แบบสำหรับโครงการขูดข้อมูลเว็บที่กำลังเติบโต
ด้วย Scraping Browser นักพัฒนาสามารถเพิ่มเบราว์เซอร์ได้มากเท่าที่ต้องการในโครงการขูดข้อมูลโดยไม่ต้องสร้างระบบราคาแพงภายในบริษัท

3. ชิงไหวชิงพริบซอฟต์แวร์ตรวจจับบอท:
ระบบตรวจจับบอตฉลาดขึ้นเรื่อย ๆ ซึ่งทำให้ยากขึ้นเรื่อย ๆ
แต่เบราว์เซอร์ Bright Data Scraping ใช้ AI เพื่อเรียนรู้วิธีหลีกเลี่ยงระบบเหล่านี้โดยอัตโนมัติเมื่อมีการเปลี่ยนแปลง ดังนั้นผู้พัฒนาจึงไม่ต้องจัดการกับปัญหาและค่าใช้จ่ายในการใช้บริการของบุคคลที่สาม
ระบบตรวจจับบอตเห็นว่า Scraping Browser เป็นเบราว์เซอร์ของผู้ใช้จริง ซึ่งทำให้เปิดได้ง่ายกว่าพร็อกซี
4. ข้ามบล็อกเว็บไซต์ที่ยากที่สุด:
เบราว์เซอร์ Bright Data Scraping จัดการงานการปลดล็อกเว็บไซต์ทั้งหมดเบื้องหลังได้ทันที ซึ่งรวมถึงการเรนเดอร์ JavaScript, คุกกี้, การเลือกข้อมูล, การลองใหม่อัตโนมัติ, ลายนิ้วมือของเบราว์เซอร์, การแก้ไข CAPTCHA และอื่นๆ
เครื่องมือนี้ช่วยประหยัดเวลาและเงินของผู้พัฒนาได้อย่างมาก โดยเฉพาะอย่างยิ่งเมื่อพวกเขาได้รับข้อมูลจำนวนมากและจำเป็นต้องทำสิ่งที่ซับซ้อนเพื่อเปิด

ลิงค์ด่วน:
- Octoparse Review: เครื่องมือขูดเว็บที่ดีจริงหรือ?
- Wikipedia Web Scraping: การดึงข้อมูลเพื่อการวิเคราะห์
- เทคนิคการขูดเว็บที่ดีที่สุด: คู่มือปฏิบัติ
- รีวิว Netpeak Checker
สรุป: รีวิวเบราว์เซอร์ที่ขูดข้อมูลอย่างสดใสในปี 2023
Bright Data Scraping Browser เป็นเครื่องมืออันทรงพลังสำหรับการขูดข้อมูลที่นำเสนอคุณสมบัติและประโยชน์มากมายเพื่อปรับปรุงโครงการขูดข้อมูลของคุณ
ด้วยความสามารถในการปลดบล็อกเว็บไซต์ที่มีประสิทธิภาพ ความเข้ากันได้กับ Puppeteer และ Playwright ความสามารถในการปรับขนาด และเทคโนโลยี AI เบราว์เซอร์นี้สามารถช่วยคุณประหยัดเวลาและทรัพยากรในขณะที่ได้รับอัตราความสำเร็จในการปลดล็อกที่ดีกว่าพร็อกซี
ความสามารถในการปลดล็อกเว็บไซต์โดยอัตโนมัติยังทำให้เป็นเครื่องมือที่เหมาะสำหรับการขูดตามขนาด ซึ่งจำเป็นต้องมีการดำเนินการปลดล็อกที่ซับซ้อน
ไม่ว่าคุณจะเป็นเจ้าของธุรกิจขนาดเล็กหรือองค์กรขนาดใหญ่ Bright Data Scraping Browser เป็นเครื่องมือที่เชื่อถือได้ที่สามารถช่วยให้คุณปรับปรุงการดำเนินการขูดข้อมูลและดึงข้อมูลเชิงลึกอันมีค่าจากอินเทอร์เน็ต