
ประสิทธิภาพการรวบรวมข้อมูล: วิธีเพิ่มระดับการเพิ่มประสิทธิภาพการรวบรวมข้อมูล
เผยแพร่แล้ว: 2022-10-27ไม่รับประกันว่า Googlebot จะรวบรวมข้อมูลทุก URL ที่สามารถเข้าถึงบนไซต์ของคุณได้ ในทางกลับกัน เว็บไซต์ส่วนใหญ่ไม่มีหน้าที่สำคัญ
ความจริงก็คือ Google ไม่มีทรัพยากรที่จะรวบรวมข้อมูลทุกหน้าที่พบ URL ทั้งหมดที่ Googlebot ค้นพบ แต่ยังไม่ได้รวบรวมข้อมูล พร้อมด้วย URL ที่ตั้งใจจะรวบรวมข้อมูลจะได้รับการจัดลำดับความสำคัญในคิวการรวบรวมข้อมูล
ซึ่งหมายความว่า Googlebot จะรวบรวมข้อมูลเฉพาะที่ได้รับมอบหมายลำดับความสำคัญสูงพอ และเนื่องจากคิวการรวบรวมข้อมูลเป็นไดนามิก จึงมีการเปลี่ยนแปลงอย่างต่อเนื่องเมื่อ Google ประมวลผล URL ใหม่ และไม่ใช่ทุก URL เข้าร่วมที่ด้านหลังของคิว
แล้วคุณจะแน่ใจได้อย่างไรว่า URL ของเว็บไซต์ของคุณเป็น VIP และก้าวข้ามเส้น?
การรวบรวมข้อมูลมีความสำคัญอย่างยิ่งต่อ SEO

เพื่อให้เนื้อหาได้รับการมองเห็น Googlebot จะต้องรวบรวมข้อมูลก่อน
แต่ข้อดีมีรายละเอียดมากกว่านั้นเพราะหน้าเว็บจะถูกรวบรวมข้อมูล เร็วขึ้น เมื่อเป็น:
- สร้าง ยิ่งเนื้อหาใหม่สามารถปรากฏบน Google ได้เร็วเท่านั้น นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับกลยุทธ์เนื้อหาที่มีเวลาจำกัดหรือออกสู่ตลาดเป็นรายแรก
- อัปเดต เนื้อหาที่รีเฟรชเร็วขึ้นอาจส่งผลต่อการจัดอันดับได้ นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับทั้งกลยุทธ์การเผยแพร่เนื้อหาซ้ำและกลยุทธ์ SEO ทางเทคนิค
ด้วยเหตุนี้ การรวบรวมข้อมูลจึงเป็นสิ่งจำเป็นสำหรับการเข้าชมที่เกิดขึ้นเองทั้งหมดของคุณ บ่อยครั้งที่มีการกล่าวกันว่าการเพิ่มประสิทธิภาพการรวบรวมข้อมูลเป็นประโยชน์สำหรับเว็บไซต์ขนาดใหญ่เท่านั้น
แต่มันไม่เกี่ยวกับขนาดเว็บไซต์ของคุณ เนื้อหาความถี่ได้รับการอัปเดต หรือว่าคุณมีการยกเว้น "ค้นพบแล้ว - ไม่ได้จัดทำดัชนี" ใน Google Search Console
การเพิ่มประสิทธิภาพการรวบรวมข้อมูลเป็นประโยชน์สำหรับทุกเว็บไซต์ ความเข้าใจผิดเกี่ยวกับคุณค่าของมันดูเหมือนจะกระตุ้นจากการวัดที่ไร้ความหมาย โดยเฉพาะอย่างยิ่งงบประมาณการรวบรวมข้อมูล
งบประมาณการรวบรวมข้อมูลไม่สำคัญ

บ่อยครั้งที่การรวบรวมข้อมูลได้รับการประเมินตามงบประมาณการรวบรวมข้อมูล นี่คือจำนวน URL ที่ Googlebot จะรวบรวมข้อมูลในระยะเวลาที่กำหนดบนเว็บไซต์หนึ่งๆ
Google กล่าวว่าถูกกำหนดโดยสองปัจจัย:
- ขีดจำกัดอัตราการรวบรวมข้อมูล (หรือสิ่งที่ Googlebot สามารถรวบรวมข้อมูลได้): ความเร็วที่ Googlebot สามารถดึงทรัพยากรของเว็บไซต์ได้โดยไม่กระทบต่อประสิทธิภาพของเว็บไซต์ โดยพื้นฐานแล้ว เซิร์ฟเวอร์ที่ตอบสนองจะนำไปสู่อัตราการรวบรวมข้อมูลที่สูงขึ้น
- ความต้องการรวบรวมข้อมูล (หรือสิ่งที่ Googlebot ต้องการรวบรวมข้อมูล): จำนวน URL ที่ Googlebot เข้าชมระหว่างการรวบรวมข้อมูลครั้งเดียวโดยอิงตามความต้องการสำหรับการจัดทำดัชนี (อีกครั้ง) ซึ่งได้รับผลกระทบจากความนิยมและความล้าสมัยของเนื้อหาของเว็บไซต์
เมื่อ Googlebot "ใช้" งบประมาณการรวบรวมข้อมูลแล้ว Googlebot จะหยุดรวบรวมข้อมูลไซต์
Google ไม่ได้ระบุตัวเลขสำหรับงบประมาณการรวบรวมข้อมูล สิ่งที่ใกล้เคียงที่สุดคือการแสดงคำขอรวบรวมข้อมูลทั้งหมดในรายงานสถิติการรวบรวมข้อมูลของ Google Search Console
SEO จำนวนมาก รวมทั้งตัวฉันในอดีต ได้ใช้ความพยายามอย่างมากในการอนุมานงบประมาณการรวบรวมข้อมูล
ขั้นตอนที่นำเสนอบ่อยครั้งเป็นสิ่งที่สอดคล้องกับ:
- กำหนดจำนวนหน้าที่รวบรวมข้อมูลได้บนเว็บไซต์ของคุณ ซึ่งมักจะแนะนำให้ดูจำนวน URL ในแผนผังเว็บไซต์ XML หรือเรียกใช้โปรแกรมรวบรวมข้อมูลแบบไม่จำกัด
- คำนวณการรวบรวมข้อมูลเฉลี่ยต่อวันโดยส่งออกรายงานสถิติการรวบรวมข้อมูลของ Google Search Console หรือตามคำขอของ Googlebot ในไฟล์บันทึก
- หารจำนวนหน้าด้วยจำนวนการรวบรวมข้อมูลเฉลี่ยต่อวัน มักกล่าวกันว่า หากผลลัพธ์มากกว่า 10 ให้เน้นที่การปรับงบประมาณการตระเวนให้เหมาะสม
อย่างไรก็ตาม กระบวนการนี้มีปัญหา
ไม่เพียงเพราะถือว่าทุก URL ได้รับการรวบรวมข้อมูลเพียงครั้งเดียว ในความเป็นจริงแล้ว URL บางส่วนได้รับการรวบรวมข้อมูลหลายครั้ง และบางรายการไม่ได้ทั้งหมดเลย
ไม่เพียงเพราะถือว่าการรวบรวมข้อมูลหนึ่งครั้งเท่ากับหนึ่งหน้า เมื่อในความเป็นจริง หน้าหนึ่งอาจต้องใช้การรวบรวมข้อมูล URL จำนวนมากเพื่อดึงทรัพยากร (JS, CSS ฯลฯ) ที่จำเป็นในการโหลด
แต่ที่สำคัญที่สุด เนื่องจากเมื่อกลั่นกรองเป็นเมตริกที่คำนวณแล้ว เช่น การรวบรวมข้อมูลเฉลี่ยต่อวัน งบประมาณในการรวบรวมข้อมูลจึงเป็นเพียงเมตริกที่ไร้สาระ
กลวิธีใดๆ ที่มุ่งไปที่ "การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล" (หรือที่รู้จักว่ามีเป้าหมายเพื่อเพิ่มจำนวนการรวบรวมข้อมูลทั้งหมดอย่างต่อเนื่อง) ถือเป็นธุระของคนโง่
เหตุใดคุณจึงควรใส่ใจเกี่ยวกับการเพิ่มจำนวนการรวบรวมข้อมูลทั้งหมด หากมีการใช้กับ URL ที่ไม่มีค่าหรือหน้าเว็บที่ไม่มีการเปลี่ยนแปลงตั้งแต่การรวบรวมข้อมูลครั้งล่าสุด การรวบรวมข้อมูลดังกล่าวจะไม่ช่วยประสิทธิภาพ SEO
นอกจากนี้ ใครก็ตามที่เคยดูสถิติการรวบรวมข้อมูลจะรู้ว่าพวกเขาผันผวน มักจะค่อนข้างรุนแรง จากวันหนึ่งไปอีกวันขึ้นอยู่กับปัจจัยหลายประการ ความผันผวนเหล่านี้อาจหรืออาจไม่สัมพันธ์กับการจัดทำดัชนีอย่างรวดเร็ว (อีกครั้ง) ของหน้าที่เกี่ยวข้องกับ SEO
จำนวน URL ที่รวบรวมข้อมูลเพิ่มขึ้นหรือลดลงนั้นไม่ได้ดีหรือไม่ดีโดยเนื้อแท้
ประสิทธิภาพการรวบรวมข้อมูลคือ SEO KPI

สำหรับหน้าที่คุณต้องการสร้างดัชนี ไม่ควรเน้นว่ามีการรวบรวมข้อมูลหรือไม่ แต่ควรเน้นที่ ความเร็วของการรวบรวมข้อมูล หลังจากเผยแพร่ หรือ มีการเปลี่ยนแปลงอย่างมีนัยสำคัญ
โดยพื้นฐานแล้ว เป้าหมายคือเพื่อลดเวลาระหว่างการสร้างหรืออัปเดตหน้าที่เกี่ยวข้องกับ SEO กับการรวบรวมข้อมูล Googlebot ครั้งถัดไป ฉันเรียกเวลานี้ว่าการหน่วงเวลาประสิทธิภาพการรวบรวมข้อมูล
วิธีที่เหมาะสมที่สุดในการวัดประสิทธิภาพการรวบรวมข้อมูลคือการคำนวณความแตกต่างระหว่างฐานข้อมูลที่สร้างหรืออัปเดตวันที่และเวลากับการรวบรวมข้อมูล Googlebot ครั้งถัดไปของ URL จากไฟล์บันทึกของเซิร์ฟเวอร์
หากการเข้าถึงจุดข้อมูลเหล่านี้เป็นเรื่องยาก คุณยังสามารถใช้เป็นพร็อกซีวันที่ Lastmod แผนผังเว็บไซต์ XML และค้นหา URL ใน API การตรวจสอบ URL ของ Google Search Console สำหรับสถานะการรวบรวมข้อมูลครั้งล่าสุดได้ (สูงสุด 2,000 คำค้นหาต่อวัน)
นอกจากนี้ ด้วยการใช้ API การตรวจสอบ URL คุณยังสามารถติดตามเมื่อสถานะการจัดทำดัชนีเปลี่ยนแปลงเพื่อคำนวณประสิทธิภาพการจัดทำดัชนีสำหรับ URL ที่สร้างขึ้นใหม่ ซึ่งเป็นความแตกต่างระหว่างการเผยแพร่และการจัดทำดัชนีที่สำเร็จ
เนื่องจากการตระเวนโดยที่ไม่มีผลกระทบต่อสถานะการจัดทำดัชนีหรือการประมวลผลการรีเฟรชเนื้อหาของหน้าจึงเป็นการสิ้นเปลือง
ประสิทธิภาพการรวบรวมข้อมูลเป็นตัวชี้วัดที่นำไปปฏิบัติได้ เนื่องจากเมื่อลดลง เนื้อหาที่มีความสำคัญต่อ SEO สามารถแสดงต่อผู้ชมของคุณทั่วทั้ง Google ได้มากขึ้น
คุณยังสามารถใช้เพื่อวิเคราะห์ปัญหา SEO ได้อีกด้วย เจาะลึกลงไปในรูปแบบ URL เพื่อทำความเข้าใจว่าเนื้อหาจากส่วนต่างๆ ของไซต์ของคุณถูกรวบรวมข้อมูลได้เร็วเพียงใด และนี่คือสิ่งที่ขัดขวางประสิทธิภาพการทำงานทั่วไปหรือไม่
หากคุณเห็นว่า Googlebot ใช้เวลาหลายชั่วโมงหรือเป็นวันหรือหลายสัปดาห์ในการรวบรวมข้อมูลและจัดทำดัชนีเนื้อหาที่สร้างขึ้นใหม่หรืออัปเดตล่าสุด คุณจะทำอย่างไรกับมัน
รับจดหมายข่าวรายวันที่นักการตลาดต้องพึ่งพา
ดูเงื่อนไข
7 ขั้นตอนในการเพิ่มประสิทธิภาพการรวบรวมข้อมูล
การเพิ่มประสิทธิภาพการรวบรวมข้อมูลเป็นเพียงการแนะนำ Googlebot ในการรวบรวมข้อมูล URL ที่สำคัญ รวดเร็วเมื่อถูกเผยแพร่ (ซ้ำ) ปฏิบัติตามเจ็ดขั้นตอนด้านล่าง
1. รับรองการตอบสนองของเซิร์ฟเวอร์ที่รวดเร็วและสมบูรณ์
เซิร์ฟเวอร์ที่มีประสิทธิภาพสูงเป็นสิ่งสำคัญ Googlebot จะช้าลงหรือหยุดรวบรวมข้อมูลเมื่อ:
- การรวบรวมข้อมูลไซต์ของคุณส่งผลต่อประสิทธิภาพการทำงาน ตัวอย่างเช่น ยิ่งรวบรวมข้อมูลมากเท่าใด เวลาตอบสนองของเซิร์ฟเวอร์ก็จะช้าลงเท่านั้น
- เซิร์ฟเวอร์ตอบสนองด้วยข้อผิดพลาดจำนวนมากหรือหมดเวลาการเชื่อมต่อ
ในทางกลับกัน การปรับปรุงความเร็วในการโหลดหน้าเว็บทำให้สามารถแสดงหน้าเว็บได้มากขึ้น อาจทำให้ Googlebot รวบรวมข้อมูล URL ได้มากขึ้นในระยะเวลาเท่ากัน นี่เป็นประโยชน์เพิ่มเติมที่นอกเหนือจากความเร็วของหน้าเว็บที่เป็นประสบการณ์ของผู้ใช้และปัจจัยในการจัดอันดับ
หากคุณยังไม่ได้ดำเนินการ ให้พิจารณาการสนับสนุนสำหรับ HTTP/2 เนื่องจากจะช่วยให้สามารถขอ URL เพิ่มเติมที่มีการโหลดที่ใกล้เคียงกันบนเซิร์ฟเวอร์ได้
อย่างไรก็ตาม ความสัมพันธ์ระหว่างประสิทธิภาพและปริมาณการรวบรวมข้อมูลอยู่ ที่จุด เดียวเท่านั้น เมื่อคุณข้ามเกณฑ์นั้น ซึ่งแตกต่างกันไปในแต่ละไซต์ การเพิ่มขึ้นในประสิทธิภาพของเซิร์ฟเวอร์ไม่น่าจะสัมพันธ์กับ uptick ในการรวบรวมข้อมูล

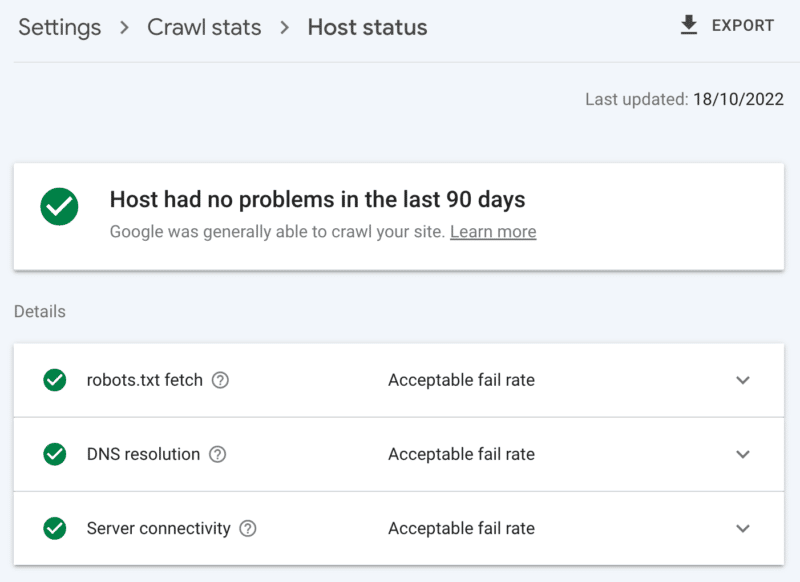
วิธีตรวจสอบความสมบูรณ์ของเซิร์ฟเวอร์
รายงานสถิติการรวบรวมข้อมูลของ Google Search Console:
- สถานะโฮสต์: แสดงเครื่องหมายถูกสีเขียว
- ข้อผิดพลาด 5xx: มีค่าน้อยกว่า 1%
- แผนภูมิเวลาตอบสนองของเซิร์ฟเวอร์: มีแนวโน้มต่ำกว่า 300 มิลลิวินาที
2. ล้างเนื้อหาที่มีมูลค่าต่ำ
หากเนื้อหาไซต์จำนวนมากล้าสมัย ซ้ำกัน หรือมีคุณภาพต่ำ จะทำให้เกิดการแข่งขันสำหรับกิจกรรมการตระเวน อาจทำให้การจัดทำดัชนีของเนื้อหาใหม่ล่าช้า หรือสร้างดัชนีใหม่ของเนื้อหาที่อัปเดต
นอกจากนี้ การทำความสะอาดเนื้อหาที่มีมูลค่าต่ำเป็นประจำยังช่วยลดการขยายตัวของดัชนีและการใช้คำหลักร่วมกัน และเป็นประโยชน์ต่อประสบการณ์ของผู้ใช้ นี่คือสิ่งที่ไม่ต้องคิดเกี่ยวกับ SEO
รวมเนื้อหากับการเปลี่ยนเส้นทาง 301 เมื่อคุณมีหน้าอื่นที่สามารถเห็นเป็นการแทนที่ที่ชัดเจน การทำความเข้าใจสิ่งนี้จะทำให้คุณเสียค่าใช้จ่ายในการรวบรวมข้อมูลเป็นสองเท่าสำหรับการประมวลผล แต่เป็นการเสียสละที่คุ้มค่าสำหรับส่วนของลิงก์
หากไม่มีเนื้อหาที่เทียบเท่ากัน การใช้ 301 จะส่งผลให้เป็น soft 404 เท่านั้น นำเนื้อหาดังกล่าวออกโดยใช้รหัสสถานะ 410 (ดีที่สุด) หรือ 404 (ปิดเป็นวินาที) เพื่อส่งสัญญาณที่แรงว่าจะไม่รวบรวมข้อมูล URL อีกครั้ง
วิธีตรวจสอบเนื้อหาที่มีมูลค่าต่ำ
จำนวน URL ในหน้า Google Search Console รายงานว่ามีการยกเว้น 'รวบรวมข้อมูลแล้ว - ยังไม่ได้จัดทำดัชนี' หากสูง ให้ตรวจทานตัวอย่างที่มีให้สำหรับรูปแบบโฟลเดอร์หรือตัวบ่งชี้ปัญหาอื่นๆ
3. ตรวจสอบการควบคุมการจัดทำดัชนี
Rel=canonical ลิงค์ เป็นคำแนะนำที่ดีในการหลีกเลี่ยงปัญหาการจัดทำดัชนี แต่มักจะพึ่งพามากเกินไปและจบลงด้วยการทำให้เกิดปัญหาในการรวบรวมข้อมูล เนื่องจากทุก URL ตามรูปแบบบัญญัติมีค่าใช้จ่ายอย่างน้อยสองการรวบรวมข้อมูล หนึ่งรายการสำหรับตัวเองและอีกรายการสำหรับพาร์ทเนอร์
ในทำนองเดียวกัน คำสั่งของโรบ็อต noindex มีประโยชน์ในการลดการบวมของดัชนี แต่คำสั่งจำนวนมากอาจส่งผลเสียต่อการรวบรวมข้อมูลได้ ดังนั้นควรใช้เมื่อจำเป็นเท่านั้น
ในทั้งสองกรณี ให้ถามตัวเองว่า
- คำสั่งการจัดทำดัชนีเหล่านี้เป็นวิธีที่ดีที่สุดในการจัดการกับความท้าทาย SEO หรือไม่?
- เส้นทาง URL บางเส้นทางสามารถรวม ลบ หรือบล็อกใน robots.txt ได้หรือไม่
หากคุณกำลังใช้งาน ให้พิจารณา AMP ใหม่อย่างจริงจังว่าเป็นโซลูชันทางเทคนิคระยะยาว
ด้วยการอัปเดตประสบการณ์หน้าเว็บที่เน้นที่ Web Vitals หลักและการรวมหน้าที่ไม่ใช่ AMP ไว้ในประสบการณ์ทั้งหมดของ Google ตราบใดที่คุณมีคุณสมบัติตรงตามข้อกำหนดด้านความเร็วของเว็บไซต์ ลองพิจารณาให้ถี่ถ้วนว่า AMP คุ้มค่ากับการรวบรวมข้อมูลซ้ำ 2 ครั้งหรือไม่
วิธีตรวจสอบการพึ่งพาการควบคุมการสร้างดัชนีมากเกินไป
จำนวน URL ในรายงานความครอบคลุมของ Google Search Console ที่จัดหมวดหมู่ตามการยกเว้นโดยไม่มีเหตุผลที่ชัดเจน:
- หน้าทางเลือกที่มีแท็กตามรูปแบบบัญญัติที่เหมาะสม
- ยกเว้นโดยแท็ก noindex
- ซ้ำกัน Google เลือก Canonical ที่แตกต่างจากผู้ใช้
- ไม่ได้เลือก URL ที่ซ้ำกันที่ส่งเป็น URL ตามรูปแบบบัญญัติ
4. บอกสไปเดอร์ของเครื่องมือค้นหาว่าต้องรวบรวมข้อมูลอะไรและเมื่อใด
เครื่องมือสำคัญที่จะช่วยให้ Googlebot จัดลำดับความสำคัญของ URL ของเว็บไซต์และสื่อสารเมื่อหน้าดังกล่าวได้รับการอัปเดตคือแผนผังเว็บไซต์ XML
สำหรับคำแนะนำโปรแกรมรวบรวมข้อมูลที่มีประสิทธิภาพ โปรดแน่ใจว่าได้:
- รวมเฉพาะ URL ที่จัดทำดัชนีได้และมีค่าสำหรับ SEO โดยทั่วไปคือ 200 รหัสสถานะ หน้าเนื้อหาตามรูปแบบบัญญัติที่เป็นต้นฉบับพร้อมแท็กโรบ็อต "ดัชนี ติดตาม" ที่คุณสนใจเกี่ยวกับการมองเห็นใน SERP
- รวมแท็กการประทับเวลา <lastmod> ที่ถูกต้องในแต่ละ URL และแผนผังไซต์ให้ใกล้เคียงกับเรียลไทม์มากที่สุด
Google ไม่ตรวจสอบแผนผังเว็บไซต์ทุกครั้งที่มีการรวบรวมข้อมูลเว็บไซต์ ดังนั้นเมื่อใดก็ตามที่มีการอัปเดต ทางที่ดีควรแจ้ง Google ให้ทราบ โดยส่งคำขอ GET ในเบราว์เซอร์หรือบรรทัดคำสั่งไปที่:
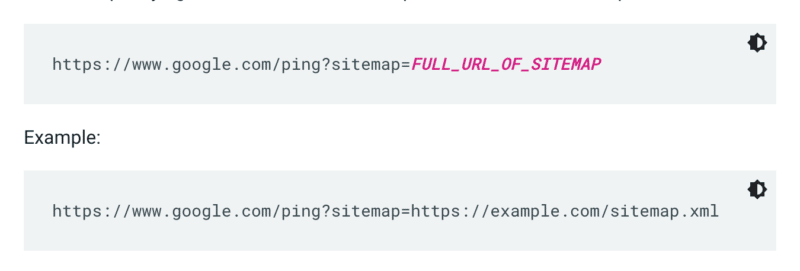
นอกจากนี้ ให้ระบุเส้นทางไปยังแผนผังเว็บไซต์ในไฟล์ robots.txt และส่งไปยัง Google Search Console โดยใช้รายงานแผนผังเว็บไซต์
ตามกฎแล้ว Google จะรวบรวมข้อมูล URL ในแผนผังเว็บไซต์บ่อยกว่า URL อื่นๆ แม้ว่า URL ในแผนผังไซต์ของคุณจะมีคุณภาพต่ำในเปอร์เซ็นต์เล็กน้อย แต่ก็สามารถห้ามไม่ให้ Googlebot ใช้คำแนะนำในการรวบรวมข้อมูลได้
แผนผังเว็บไซต์ XML และลิงก์จะเพิ่ม URL ไปยังคิวการรวบรวมข้อมูลปกติ นอกจากนี้ยังมีคิวการรวบรวมข้อมูลที่มีลำดับความสำคัญ ซึ่งมีสองวิธีในการเข้า
ประการแรก สำหรับผู้ที่ประกาศรับสมัครงานหรือวิดีโอถ่ายทอดสด คุณสามารถส่ง URL ไปยัง Indexing API ของ Google ได้
หรือหากคุณต้องการดึงดูดสายตาของ Microsoft Bing หรือ Yandex คุณสามารถใช้ IndexNow API สำหรับ URL ใดก็ได้ อย่างไรก็ตาม ในการทดสอบของฉันเอง มีผลกระทบอย่างจำกัดต่อการรวบรวมข้อมูลของ URL ดังนั้น หากคุณใช้ IndexNow อย่าลืมตรวจสอบประสิทธิภาพการรวบรวมข้อมูลสำหรับ Bingbot
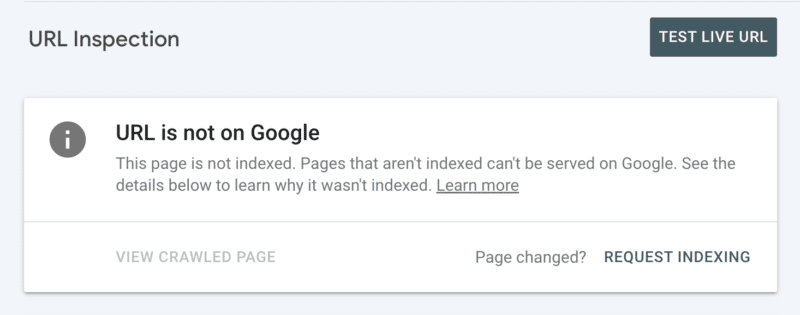
ประการที่สอง คุณสามารถขอการจัดทำดัชนีด้วยตนเองหลังจากตรวจสอบ URL ใน Search Console แม้ว่าโปรดทราบว่าโควตามี URL 10 รายการต่อวัน และการรวบรวมข้อมูลยังอาจใช้เวลาหลายชั่วโมง เป็นการดีที่สุดที่จะเห็นว่านี่เป็นโปรแกรมแก้ไขชั่วคราวในขณะที่คุณขุดเพื่อค้นหารากเหง้าของปัญหาการรวบรวมข้อมูลของคุณ
วิธีตรวจสอบคำแนะนำในการรวบรวมข้อมูลที่จำเป็นของ Googlebot
ใน Google Search Console แผนผังไซต์ XML ของคุณจะแสดงสถานะ "สำเร็จ" และเพิ่งอ่าน
5. บอกสไปเดอร์ของเครื่องมือค้นหาว่าไม่ควรรวบรวมข้อมูลอะไร
บางหน้าอาจมีความสำคัญต่อผู้ใช้หรือฟังก์ชันการทำงานของไซต์ แต่คุณไม่ต้องการให้ปรากฏในผลการค้นหา ป้องกันไม่ให้เส้นทาง URL ดังกล่าวรบกวนโปรแกรมรวบรวมข้อมูลด้วย robots.txt ไม่อนุญาต ซึ่งอาจรวมถึง:
- API และ CDN ตัวอย่างเช่น หากคุณเป็นลูกค้าของ Cloudflare อย่าลืมไม่อนุญาตโฟลเดอร์ /cdn-cgi/ ที่เพิ่มลงในไซต์ของคุณ
- รูปภาพ สคริปต์ หรือไฟล์รูปแบบที่ไม่สำคัญ หากหน้าที่โหลดโดยไม่มีทรัพยากรเหล่านี้จะไม่ได้รับผลกระทบจากการสูญเสียอย่างมีนัยสำคัญ
- หน้าที่ การใช้งาน เช่น ตะกร้าสินค้า
- ช่องว่าง ไม่จำกัด เช่น พื้นที่ที่สร้างโดยหน้าปฏิทิน
- หน้าพารามิเตอร์ โดยเฉพาะจากการนำทางแบบเหลี่ยมเพชรพลอยที่กรอง (เช่น ?price-range=20-50) เรียงลำดับใหม่ (เช่น ?sort=) หรือค้นหา (เช่น ?q=) เนื่องจากทุกชุดค่าผสมจะถูกนับโดยโปรแกรมรวบรวมข้อมูลเป็นหน้าที่แยกจากกัน
ระวังอย่าบล็อกพารามิเตอร์การแบ่งหน้าอย่างสมบูรณ์ การแบ่งหน้าที่รวบรวมข้อมูลได้จนถึงจุดหนึ่งมักจะจำเป็นสำหรับ Googlebot ในการค้นหาเนื้อหาและประมวลผลส่วนของลิงก์ภายใน (ตรวจสอบการสัมมนาผ่านเว็บของ Semrush เกี่ยวกับการแบ่งหน้าเพื่อเรียนรู้รายละเอียดเพิ่มเติมเกี่ยวกับสาเหตุ)
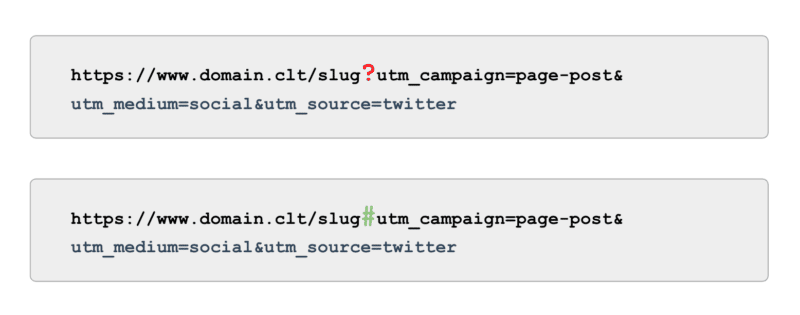
และเมื่อพูดถึงการติดตาม แทนที่จะใช้แท็ก UTM ที่ขับเคลื่อนโดยพารามิเตอร์ (aka, '?') ให้ใช้จุดยึด (aka, '#') ให้ประโยชน์ในการรายงานแบบเดียวกันใน Google Analytics โดยไม่ต้องรวบรวมข้อมูล
วิธีตรวจสอบคำแนะนำในการไม่รวบรวมข้อมูลของ Googlebot
ตรวจสอบตัวอย่างของ URL ที่ "จัดทำดัชนีแล้ว ไม่ได้ส่งในแผนผังเว็บไซต์" ใน Google Search Console ละเว้นสองสามหน้าแรกของการแบ่งหน้า คุณพบเส้นทางอื่นใดอีก ควรรวมไว้ในแผนผังไซต์ XML บล็อกจากการรวบรวมข้อมูลหรือปล่อยให้เป็น
นอกจากนี้ ให้ตรวจสอบรายการ "ค้นพบ - ยังไม่ได้จัดทำดัชนี" - บล็อกใน robots.txt เส้นทาง URL ใดๆ ที่มีมูลค่าต่ำถึงไม่มีเลยสำหรับ Google
ในการดำเนินการนี้ในระดับต่อไป ให้ตรวจสอบการรวบรวมข้อมูลสมาร์ทโฟน Googlebot ทั้งหมดในไฟล์บันทึกของเซิร์ฟเวอร์เพื่อหาเส้นทางที่ไร้ค่า
6. จัดการลิงก์ที่เกี่ยวข้อง
ลิงก์ย้อนกลับไปยังหน้าเว็บมีประโยชน์สำหรับ SEO ในหลายๆ ด้าน และการรวบรวมข้อมูลก็ไม่มีข้อยกเว้น แต่ลิงก์ภายนอกอาจเป็นเรื่องยากที่จะได้รับสำหรับหน้าเว็บบางประเภท ตัวอย่างเช่น หน้าลึก เช่น ผลิตภัณฑ์ หมวดหมู่ในระดับล่างในสถาปัตยกรรมของไซต์ หรือแม้แต่บทความ
ในทางกลับกัน ลิงค์ภายในที่เกี่ยวข้องคือ:
- ปรับขนาดได้ในทางเทคนิค
- สัญญาณที่มีประสิทธิภาพสำหรับ Googlebot ในการจัดลำดับความสำคัญของหน้าสำหรับการรวบรวมข้อมูล
- มีผลอย่างยิ่งต่อการรวบรวมข้อมูลหน้าลึก
เบรดครัมบ์ บล็อกเนื้อหาที่เกี่ยวข้อง ตัวกรองด่วน และการใช้แท็กที่ได้รับการดูแลจัดการอย่างดีล้วนเป็นประโยชน์อย่างมากต่อประสิทธิภาพในการรวบรวมข้อมูล เนื่องจากเป็นเนื้อหาที่มีความสำคัญต่อ SEO ตรวจสอบให้แน่ใจว่าไม่มีลิงก์ภายในดังกล่าวที่ขึ้นอยู่กับ JavaScript แต่ควรใช้ลิงก์ <a> มาตรฐานที่รวบรวมข้อมูลได้
โปรดจำไว้ว่าลิงก์ภายในดังกล่าวควรเพิ่มมูลค่าที่แท้จริงให้กับผู้ใช้ด้วย
วิธีตรวจสอบลิงค์ที่เกี่ยวข้อง
เรียกใช้การรวบรวมข้อมูลไซต์ทั้งหมดของคุณด้วยตนเองด้วยเครื่องมือ เช่น แมงมุม SEO ของ ScreamingFrog โดยมองหา:
- URL เด็กกำพร้า
- ลิงก์ภายในถูกบล็อกโดย robots.txt
- ลิงก์ภายในไปยังรหัสสถานะที่ไม่ใช่ 200
- เปอร์เซ็นต์ของ URL ที่ไม่สามารถจัดทำดัชนีได้ซึ่งเชื่อมโยงภายใน
7. ตรวจสอบปัญหาการรวบรวมข้อมูลที่เหลืออยู่
หากการเพิ่มประสิทธิภาพทั้งหมดข้างต้นเสร็จสมบูรณ์ และประสิทธิภาพในการรวบรวมข้อมูลของคุณยังคงมีประสิทธิภาพต่ำ ให้ดำเนินการตรวจสอบแบบเจาะลึก
เริ่มต้นด้วยการตรวจสอบตัวอย่างการยกเว้น Google Search Console ที่เหลืออยู่เพื่อระบุปัญหาการรวบรวมข้อมูล
เมื่อแก้ไขปัญหาแล้ว ให้ลงลึกโดยใช้เครื่องมือรวบรวมข้อมูลด้วยตนเองเพื่อรวบรวมข้อมูลหน้าทั้งหมดในโครงสร้างเว็บไซต์อย่าง Googlebot การอ้างอิงโยงนี้กับไฟล์บันทึกที่จำกัดให้เหลือเพียง IP ของ Googlebot เพื่อทำความเข้าใจว่าหน้าใดบ้างและไม่มีการรวบรวมข้อมูล
สุดท้าย เปิดตัวในการวิเคราะห์ไฟล์บันทึกโดยจำกัดให้เหลือ Googlebot IP เป็นเวลาอย่างน้อยสี่สัปดาห์ของข้อมูล ซึ่งควรมากกว่านั้น
หากคุณไม่คุ้นเคยกับรูปแบบของไฟล์บันทึก ให้ใช้ประโยชน์จากเครื่องมือวิเคราะห์บันทึก ท้ายที่สุด นี่คือแหล่งข้อมูลที่ดีที่สุดที่จะทำความเข้าใจว่า Google รวบรวมข้อมูลไซต์ของคุณอย่างไร
เมื่อการตรวจสอบของคุณเสร็จสมบูรณ์และคุณมีรายการปัญหาการรวบรวมข้อมูลที่ระบุแล้ว ให้จัดอันดับปัญหาแต่ละข้อตามระดับความพยายามที่คาดหวังและผลกระทบต่อประสิทธิภาพการทำงาน
หมายเหตุ : ผู้เชี่ยวชาญด้าน SEO คนอื่นๆ ได้กล่าวว่าการคลิกจาก SERP ช่วยเพิ่มการรวบรวมข้อมูลของ URL ของหน้า Landing Page อย่างไรก็ตาม ฉันยังไม่สามารถยืนยันสิ่งนี้ด้วยการทดสอบได้
จัดลำดับความสำคัญของประสิทธิภาพการรวบรวมข้อมูลมากกว่างบประมาณการรวบรวมข้อมูล
เป้าหมายของการรวบรวมข้อมูลไม่ใช่เพื่อให้ได้จำนวนสูงสุดของการรวบรวมข้อมูล หรือให้มีทุกๆ หน้าของเว็บไซต์ที่รวบรวมข้อมูลซ้ำๆ แต่เพื่อดึงดูดการรวบรวมข้อมูลเนื้อหาที่เกี่ยวข้องกับ SEO ให้ใกล้เคียงที่สุดเท่าที่จะเป็นไปได้เมื่อมีการสร้างหรืออัปเดตหน้า
โดยรวมแล้ว งบประมาณไม่สำคัญ สิ่งที่คุณลงทุนในสิ่งนั้นมีค่า
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนพนักงานอยู่ที่นี่