
คู่มือการวินิจฉัยปัญหา JavaScript SEO ทั่วไป
เผยแพร่แล้ว: 2023-07-10พูดกันตามตรงว่า JavaScript และ SEO ไม่ได้เข้ากันได้ดีเสมอไป สำหรับ SEO บางส่วน หัวข้ออาจรู้สึกเหมือนถูกปกคลุมด้วยม่านแห่งความซับซ้อน
ข่าวดี: เมื่อคุณลอกเลเยอร์กลับ ปัญหา SEO ที่ใช้ JavaScript จำนวนมากจะกลับมาที่พื้นฐานของวิธีที่โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาโต้ตอบกับ JavaScript ในตอนแรก
ดังนั้น หากคุณเข้าใจพื้นฐานเหล่านั้น คุณก็สามารถเจาะลึกถึงปัญหา เข้าใจผลกระทบ และทำงานร่วมกับผู้พัฒนาเพื่อแก้ไขปัญหาที่สำคัญได้
ในบทความนี้ เราจะช่วยวินิจฉัยปัญหาทั่วไปเมื่อไซต์สร้างขึ้นบนเฟรมเวิร์ก JS นอกจากนี้ เราจะแจกแจงความรู้พื้นฐานที่จำเป็นสำหรับ SEO ด้านเทคนิคเมื่อพูดถึงการเรนเดอร์
แสดงผลโดยสังเขป
ก่อนที่เราจะเข้าสู่เนื้อหาที่ละเอียดกว่านี้ เรามาพูดถึงภาพใหญ่กันก่อน
เพื่อให้เครื่องมือค้นหาเข้าใจเนื้อหาที่ขับเคลื่อนโดย JavaScript นั้นจะต้องรวบรวมข้อมูล และ แสดงผลหน้าเว็บ
ปัญหาคือ เสิร์ชเอ็นจิ้นมีทรัพยากรมากมายให้ใช้ ดังนั้นพวกเขาจึงต้องเลือกว่าเมื่อใดควรค่าแก่การใช้ ไม่ใช่ว่าหน้าจะแสดงผล แม้ว่าโปรแกรมรวบรวมข้อมูลจะส่งไปยังคิวการแสดงผล
หากเลือกที่จะไม่แสดงหน้าหรือไม่สามารถแสดงเนื้อหาได้อย่างถูกต้อง อาจเป็นปัญหาได้
มันขึ้นอยู่กับวิธีที่ส่วนหน้าให้บริการ HTML ในการตอบสนองของเซิร์ฟเวอร์เริ่มต้น
เมื่อสร้าง URL ในเบราว์เซอร์ ส่วนหน้า เช่น React, Vue หรือ Gatsby จะสร้าง HTML สำหรับหน้านั้น โปรแกรมรวบรวมข้อมูลจะตรวจสอบว่า HTML นั้นมีอยู่แล้วจากเซิร์ฟเวอร์หรือไม่ ("HTML ที่แสดงผลล่วงหน้า") ก่อนที่จะส่ง URL เพื่อรอการแสดงผลเพื่อให้สามารถดูเนื้อหาที่เป็นผลลัพธ์ได้
การที่ HTML ที่แสดงผลล่วงหน้าจะพร้อมใช้งานหรือไม่นั้นขึ้นอยู่กับการกำหนดค่าส่วนหน้า มันจะสร้าง HTML ผ่านเซิร์ฟเวอร์หรือในเบราว์เซอร์ไคลเอ็นต์
การแสดงผลฝั่งเซิร์ฟเวอร์
ชื่อกล่าวมันทั้งหมด ในการตั้งค่า SSR โปรแกรมรวบรวมข้อมูลจะได้รับหน้า HTML ที่แสดงผลอย่างสมบูรณ์โดยไม่ต้องใช้การดำเนินการและการแสดงผล JS เพิ่มเติม
ดังนั้น แม้ว่าหน้าจะไม่แสดงผล เครื่องมือค้นหายังสามารถรวบรวมข้อมูล HTML ใดๆ ปรับบริบทของหน้า (ข้อมูลเมตา การคัดลอก รูปภาพ) และทำความเข้าใจความสัมพันธ์กับหน้าอื่นๆ (เบรดครัมบ์, Canonical URL, ลิงก์ภายใน)
การแสดงผลฝั่งไคลเอนต์
ใน CSR HTML จะถูกสร้างขึ้นในเบราว์เซอร์พร้อมกับส่วนประกอบ JavaScript ทั้งหมด JavaScript ต้องแสดงผลก่อนที่จะรวบรวมข้อมูล HTML ได้
หากบริการแสดงผลเลือกที่จะไม่แสดงผลหน้าที่ส่งไปยังคิว โปรแกรมรวบรวมข้อมูลก็จะไม่สามารถคัดลอก URL ภายใน ลิงก์รูปภาพ หรือแม้แต่ข้อมูลเมตาได้
เป็นผลให้เครื่องมือค้นหามีบริบทเพียงเล็กน้อยหรือไม่มีเลยในการทำความเข้าใจความเกี่ยวข้องของ URL กับคำค้นหา
หมายเหตุ : อาจมีการผสมผสานของ HTML ที่ให้บริการในการตอบกลับ HTML เริ่มต้น เช่นเดียวกับ HTML ที่ต้องใช้ JS ในการดำเนินการเพื่อแสดงผล (ปรากฏ) ขึ้นอยู่กับปัจจัยหลายประการ ซึ่งส่วนใหญ่รวมถึงเฟรมเวิร์ก วิธีสร้างส่วนประกอบของไซต์แต่ละรายการ และการกำหนดค่าเซิร์ฟเวอร์
ชุดเครื่องมือ JavaScript SEO
มีเครื่องมือที่จะช่วยระบุปัญหา SEO ที่เกี่ยวข้องกับ JavaScript ได้อย่างแน่นอน
คุณสามารถตรวจสอบได้หลายอย่างโดยใช้เครื่องมือของเบราว์เซอร์และ Google Search Console นี่คือรายการสั้น ๆ ที่ประกอบขึ้นเป็นชุดเครื่องมือที่มั่นคง:
- ดูซอร์ส: คลิกขวาบนเพจแล้วคลิก “ดูซอร์ส” เพื่อดู HTML ที่แสดงผลล่วงหน้าของเพจ (การตอบสนองของเซิร์ฟเวอร์เริ่มต้น)
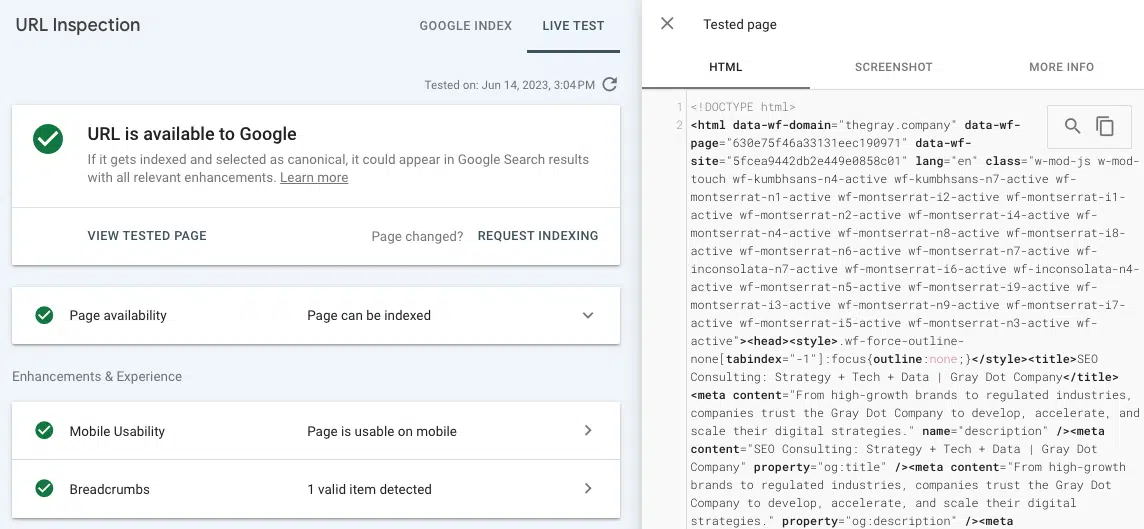
- ทดสอบ URL จริง (การตรวจสอบ URL): ดูภาพหน้าจอ, HTML และรายละเอียดที่สำคัญอื่นๆ ของหน้าที่แสดงผลในแท็บการตรวจสอบ URL ของ Google Search Console (สามารถพบปัญหาการแสดงผลหลายอย่างได้โดยการเปรียบเทียบ HTML ที่แสดงผลล่วงหน้าจาก “ดูซอร์ส” กับ HTML ที่แสดงผลจากการทดสอบ URL จริงใน GSC)
- เครื่องมือสำหรับนักพัฒนา Chrome: คลิกขวาบนหน้าแล้วเลือก "ตรวจสอบ" เพื่อเปิดเครื่องมือสำหรับดูข้อผิดพลาดของ JavaScript และอื่นๆ
- Wappalyzer: ดูสแตกที่ไซต์ใดๆ สร้างขึ้น และค้นหาข้อมูลเชิงลึกเฉพาะเฟรมเวิร์กด้วยการติดตั้งส่วนขยาย Chrome ฟรีนี้
ปัญหา JavaScript SEO ทั่วไป
ปัญหาที่ 1: HTML ที่แสดงผลล่วงหน้าไม่สามารถใช้งานได้ในระดับสากล
นอกเหนือจากความหมายเชิงลบสำหรับการรวบรวมข้อมูลและการปรับบริบทที่กล่าวถึงก่อนหน้านี้ ยังมีปัญหาเรื่องเวลาและทรัพยากรที่อาจใช้สำหรับเครื่องมือค้นหาในการแสดงหน้าเว็บ
หากโปรแกรมรวบรวมข้อมูลเลือกที่จะใส่ URL ผ่านกระบวนการแสดงผล URL จะจบลงในคิวการแสดงผล สิ่งนี้เกิดขึ้นเนื่องจากโปรแกรมรวบรวมข้อมูลอาจรู้สึกถึงความแตกต่างระหว่างโครงสร้าง HTML ที่แสดงผลล่วงหน้าและที่แสดงผล (ซึ่งสมเหตุสมผลมากหากไม่มี HTML ที่แสดงผลล่วงหน้า!)
ไม่มีการรับประกันว่า URL จะรอบริการแสดงผลเว็บนานเท่าใด วิธีที่ดีที่สุดในการเปลี่ยนแปลง WRS ไปสู่การแสดงผลอย่างทันท่วงทีคือต้องแน่ใจว่ามีสัญญาณการอนุญาตหลักอยู่ในไซต์ที่แสดงความสำคัญของ URL (เช่น ลิงก์ใน nav ด้านบน ลิงก์ภายในจำนวนมาก อ้างอิงเป็นบัญญัติ) มีความซับซ้อนเล็กน้อยเนื่องจากต้องมีการรวบรวมข้อมูลสัญญาณผู้มีอำนาจด้วย
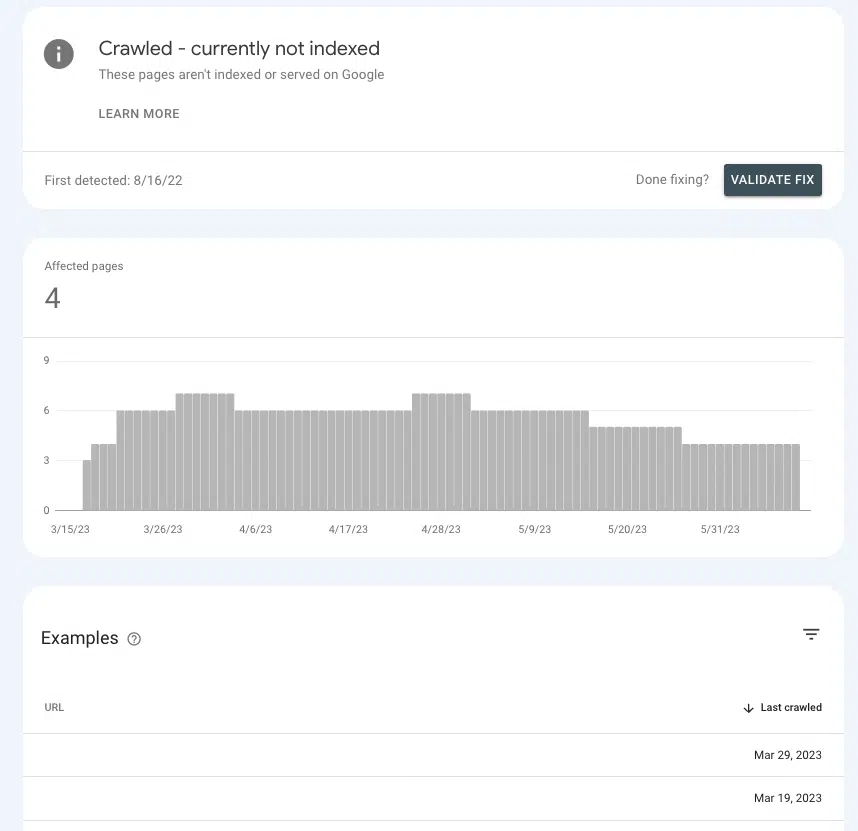
ใน Google Search Console คุณสามารถทราบได้ว่าคุณกำลังส่งสัญญาณการอนุญาตที่ถูกต้องไปยังหน้าสำคัญๆ หรือทำให้หน้าเหล่านั้นอยู่ในขอบเขตที่รกร้างว่างเปล่า
ไปที่ หน้า > การจัดทำดัชนีหน้า > รวบรวมข้อมูลแล้ว – ขณะนี้ยังไม่ได้จัดทำดัชนี และมองหาหน้าที่มีความสำคัญภายในรายการ
หากพวกเขาอยู่ในห้องรอ นั่นเป็นเพราะ Google ไม่สามารถระบุได้ว่าพวกเขามีความสำคัญพอที่จะใช้ทรัพยากรหรือไม่
สาเหตุทั่วไป
การตั้งค่าเริ่มต้น
ส่วนหน้ายอดนิยมส่วนใหญ่มาแบบ "นอกกรอบ" ที่ตั้งค่าเป็นการแสดงผลฝั่งไคลเอ็นต์ ดังนั้นจึงมีโอกาสค่อนข้างดีที่การตั้งค่าเริ่มต้นจะเป็นตัวการ
หากคุณสงสัยว่าเหตุใดฟรอนต์เอนด์ส่วนใหญ่จึงใช้ค่าเริ่มต้นเป็น CSR นั่นเป็นเพราะข้อดีด้านประสิทธิภาพ นักพัฒนาไม่ได้ชอบ SSR เสมอไป เพราะมันสามารถจำกัดความเป็นไปได้ในการเร่งความเร็วไซต์และใช้งานองค์ประกอบเชิงโต้ตอบบางอย่าง (เช่น การเปลี่ยนระหว่างหน้าที่ไม่ซ้ำกัน)
แอปพลิเคชันหน้าเดียว
หากไซต์เป็นแอปพลิเคชันแบบหน้าเดียว ไซต์นั้นจะถูกรวมไว้ใน JavaScript และสร้างส่วนประกอบทั้งหมดของเพจในเบราว์เซอร์ (หรือเรียกว่าทุกอย่าง) แสดงผลฝั่งไคลเอ็นต์และแสดงหน้าใหม่โดยไม่ต้องโหลดซ้ำ)
สิ่งนี้มีนัยเชิงลบบางประการ บางทีสิ่งที่สำคัญที่สุดคือหน้าเว็บนั้นอาจไม่สามารถค้นพบได้
ไม่ได้หมายความว่าเป็นไปไม่ได้ที่จะตั้งค่า SPA ให้เป็นมิตรกับ SEO มากขึ้น แต่มีโอกาสที่จะต้องมีงานพัฒนาที่สำคัญบางอย่างที่จำเป็นเพื่อให้สิ่งนั้นเกิดขึ้น
ปัญหาที่ 2: โปรแกรมรวบรวมข้อมูลไม่สามารถเข้าถึงเนื้อหาบางหน้าได้
การให้เครื่องมือค้นหาแสดง URL นั้นยอดเยี่ยม ตราบใดที่องค์ประกอบทั้งหมดพร้อมสำหรับการรวบรวมข้อมูล จะเกิดอะไรขึ้นหากกำลังแสดงผลหน้าเว็บ แต่มีส่วนของหน้าเว็บที่ไม่สามารถเข้าถึงได้
ตัวอย่างเช่น SEO ทำการวิเคราะห์ลิงก์ภายในและพบลิงก์ภายในเพียงเล็กน้อยหรือไม่มีเลยที่รายงานสำหรับ URL ที่เชื่อมโยงในหลายหน้า
หากลิงก์ไม่แสดงใน HTML ที่แสดงผลจากเครื่องมือ Test Live URL เป็นไปได้ว่าลิงก์นั้นแสดงในทรัพยากร JavaScript ที่ Google ไม่สามารถเข้าถึงได้
ในการจำกัดผู้ร้ายให้แคบลง เป็นความคิดที่ดีที่จะมองหาลักษณะทั่วไปในแง่ของตำแหน่งที่เนื้อหาของหน้าที่ขาดหายไปหรือลิงก์ภายในอยู่ในหน้านั้นผ่าน URL
ตัวอย่างเช่น หากเป็นลิงก์คำถามที่พบบ่อยซึ่งปรากฏอยู่ในส่วนเดียวกันของทุกหน้าผลิตภัณฑ์ นั่นจะช่วยให้นักพัฒนาซอฟต์แวร์จำกัดการแก้ไขให้แคบลงได้
สาเหตุทั่วไป
ข้อผิดพลาดของจาวาสคริปต์
เริ่มจากข้อจำกัดความรับผิดชอบที่นี่ ข้อผิดพลาด JavaScript ส่วนใหญ่ที่คุณพบไม่สำคัญสำหรับ SEO
ดังนั้นหากคุณค้นหาข้อผิดพลาด เขียนรายการยาว ๆ ให้กับ dev ของคุณ และเริ่มการสนทนาด้วย "ข้อผิดพลาดเหล่านี้คืออะไร" พวกเขาอาจไม่ได้รับข้อผิดพลาดทั้งหมด
เข้าหา “ทำไม” โดยพูดกับปัญหา เพื่อให้พวกเขาเป็นผู้เชี่ยวชาญ JavaScript (เพราะพวกเขาเป็น!)
จากที่กล่าวมา มีข้อผิดพลาดทางไวยากรณ์ที่อาจทำให้ส่วนที่เหลือของหน้าแยกวิเคราะห์ไม่ได้ (เช่น "การบล็อกการแสดงผล") เมื่อสิ่งนี้เกิดขึ้น ตัวแสดงภาพจะไม่สามารถแยกองค์ประกอบ HTML แต่ละรายการ จัดโครงสร้างเนื้อหาใน DOM หรือทำความเข้าใจความสัมพันธ์ได้
โดยทั่วไปแล้ว ข้อผิดพลาดประเภทนี้เป็นที่รู้จักเนื่องจากมีผลกระทบบางอย่างในมุมมองเบราว์เซอร์ด้วย
นอกจากการยืนยันด้วยภาพแล้ว ยังเป็นไปได้ที่จะเห็นข้อผิดพลาดของ JavaScript โดยคลิกขวาที่หน้า เลือก "ตรวจสอบ" และไปที่แท็บ "คอนโซล"
รับจดหมายข่าวรายวันที่นักการตลาดไว้วางใจ
ดูข้อกำหนด
เนื้อหาต้องมีการโต้ตอบกับผู้ใช้

สิ่งที่สำคัญที่สุดประการหนึ่งที่ต้องจำเกี่ยวกับการแสดงผลคือ Google ไม่สามารถแสดงเนื้อหาใดๆ ที่กำหนดให้ผู้ใช้ต้องโต้ตอบกับหน้าเว็บ หรือจะพูดง่ายๆ ก็คือ ไม่สามารถ "คลิก" สิ่งต่างๆ ได้
ทำไมถึงสำคัญ? ลองนึกถึงเพื่อนเก่าที่ไว้ใจได้ เมนูแบบเลื่อนลงหีบเพลง และจำนวนไซต์ที่ใช้เพื่อจัดระเบียบเนื้อหา เช่น รายละเอียดผลิตภัณฑ์และคำถามที่พบบ่อย
ขึ้นอยู่กับวิธีการเข้ารหัสหีบเพลง Google อาจไม่สามารถแสดงเนื้อหาในเมนูแบบเลื่อนลงได้หากไม่เติมข้อมูลจนกว่า JS จะดำเนินการ
หากต้องการตรวจสอบ คุณสามารถ "ตรวจสอบ" หน้าเว็บและดูว่าเนื้อหา "ที่ซ่อนอยู่" (สิ่งที่แสดงเมื่อคุณคลิกที่หีบเพลง) อยู่ใน HTML หรือไม่
หากไม่มี แสดงว่า Googlebot และโปรแกรมรวบรวมข้อมูลอื่นๆ ไม่เห็นเนื้อหานี้ในหน้าเว็บเวอร์ชันที่แสดงผล
ปัญหาที่ 3: ส่วนต่างๆ ของไซต์ไม่ได้รับการรวบรวมข้อมูล
Google อาจแสดงหรือไม่แสดงหน้าของคุณหากรวบรวมข้อมูลและส่งไปยังคิว หากไม่รวบรวมข้อมูลหน้าเว็บ โอกาสนั้นก็จะหายไปจากตาราง
เพื่อทำความเข้าใจว่า Google กำลังรวบรวมข้อมูลหน้าเว็บหรือไม่ รายงานสถิติการรวบรวมข้อมูลอาจมีประโยชน์ใน การตั้งค่า > สถิติการรวบรวมข้อมูล
เลือกคำขอรวบรวมข้อมูล: ตกลง (200) เพื่อดูอินสแตนซ์การรวบรวมข้อมูลทั้งหมดของหน้าสถานะ 200 หน้าในช่วงสามเดือนที่ผ่านมา จากนั้น ใช้การกรองเพื่อค้นหาแต่ละ URL หรือทั้งไดเรกทอรี
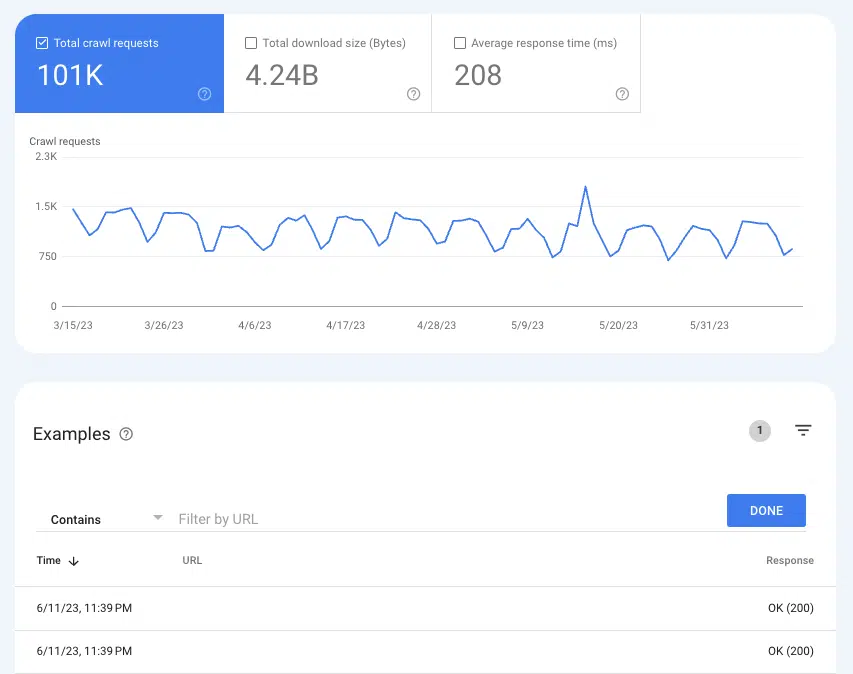
หาก URL ไม่ปรากฏในบันทึกการรวบรวมข้อมูล มีโอกาสดีที่ Google ไม่สามารถค้นพบและรวบรวมข้อมูลหน้าเว็บเหล่านั้นได้ (หรือไม่ใช่หน้า 200 ซึ่งเป็นปัญหาที่แตกต่างไปจากเดิมอย่างสิ้นเชิง)
สาเหตุทั่วไป
ลิงก์ภายในไม่สามารถรวบรวมข้อมูลได้
ลิงค์เป็นโปรแกรมรวบรวมข้อมูลป้ายถนนติดตามไปยังหน้าใหม่ นั่นเป็นเหตุผลหนึ่งที่ทำให้หน้าเด็กกำพร้าเป็นปัญหาใหญ่
หากคุณมีไซต์ที่มีลิงก์ดีและเห็นหน้าที่ไม่มีผู้เกี่ยวข้องปรากฏขึ้นในการตรวจสอบไซต์ของคุณ มีโอกาสที่ดีที่จะเป็นเพราะไม่มีลิงก์ใน HTML ที่แสดงผลล่วงหน้า
วิธีง่ายๆ ในการตรวจสอบคือไปที่ URL ที่เชื่อมโยงไปยังหน้าเด็กกำพร้าที่รายงาน คลิกขวาที่หน้านั้นแล้วคลิก “ดูแหล่งที่มา”
จากนั้นใช้ CMD + f เพื่อค้นหา URL ของหน้าเด็กกำพร้า หากไม่ปรากฏใน HTML ที่แสดงผลล่วงหน้า แต่ปรากฏในหน้าเมื่อแสดงผลในเบราว์เซอร์ ให้ข้ามไปที่ประเด็นที่สี่
แผนผังเว็บไซต์ XML ไม่ได้อัปเดต
แผนผังไซต์ XML มีความสำคัญต่อการช่วยให้ Google ค้นพบหน้าใหม่และเข้าใจว่า URL ใดควรจัดลำดับความสำคัญในการรวบรวมข้อมูล
หากไม่มีแผนผังเว็บไซต์ XML การค้นหาหน้าจะทำได้โดยการไปตามลิงก์เท่านั้น
ดังนั้นสำหรับไซต์ที่ไม่มี HTML ที่แสดงผลล่วงหน้า แผนผังไซต์ที่ล้าสมัยหรือขาดหายไปหมายถึงการรอให้ Google แสดงผลหน้าเว็บ ติดตามลิงก์ภายในไปยังหน้าอื่น จัดคิว แสดงผล ติดตามลิงก์ และอื่นๆ
ขึ้นอยู่กับส่วนหน้าที่คุณใช้ คุณอาจมีสิทธิ์เข้าถึงปลั๊กอินที่สามารถสร้างแผนผังไซต์ XML แบบไดนามิกได้
พวกเขามักต้องการการปรับแต่ง ดังนั้นจึงเป็นเรื่องสำคัญที่นักทำ SEO จะต้องจัดทำเอกสาร URL ที่ไม่ควรอยู่ในแผนผังเว็บไซต์อย่างขยันขันแข็งและเหตุผลที่เป็นเช่นนั้น
สิ่งนี้ควรตรวจสอบได้ง่ายโดยการเรียกใช้แผนผังเว็บไซต์ผ่านเครื่องมือ SEO ที่คุณชื่นชอบ
ปัญหาที่ 4: ลิงก์ภายในหายไป
ความไม่พร้อมใช้งานของลิงก์ภายในไปยังโปรแกรมรวบรวมข้อมูลไม่ได้เป็นเพียงปัญหาการค้นพบที่อาจเกิดขึ้น แต่ยังเป็นปัญหาด้านความเท่าเทียมด้วย เนื่องจากลิงก์ส่งผ่านส่วนของ SEO จาก URL อ้างอิงไปยัง URL เป้าหมาย จึงเป็นปัจจัยสำคัญที่ทำให้ทั้งเพจและโดเมนมีอำนาจเพิ่มขึ้น
ลิงก์จากหน้าแรกเป็นตัวอย่างที่ดี โดยปกติแล้วจะเป็นหน้าที่น่าเชื่อถือที่สุดบนเว็บไซต์ ดังนั้นลิงก์ไปยังหน้าอื่นจากหน้าแรกจึงมีน้ำหนักมาก
หากลิงก์เหล่านั้นไม่สามารถรวบรวมข้อมูลได้ ก็เหมือนกับกระบี่แสงหัก เครื่องมือที่ทรงพลังที่สุดชิ้นหนึ่งของคุณนั้นไร้ประโยชน์ (ตั้งใจเล่นสำนวน)
สาเหตุทั่วไป
ต้องมีการโต้ตอบกับผู้ใช้เพื่อไปที่ลิงก์
ตัวอย่างหีบเพลงที่เราใช้ก่อนหน้านี้เป็นเพียงตัวอย่างหนึ่งที่เนื้อหาถูกซ่อนอยู่หลังการโต้ตอบของผู้ใช้ อีกประการหนึ่งที่อาจมีความหมายอย่างกว้างขวางคือการเลื่อนหน้าไม่รู้จบ – โดยเฉพาะอย่างยิ่งสำหรับไซต์อีคอมเมิร์ซที่มีแคตตาล็อกผลิตภัณฑ์จำนวนมาก
ในการตั้งค่าการเลื่อนแบบไม่จำกัด สินค้านับไม่ถ้วนในหน้ารายการสินค้า (หมวดหมู่) จะไม่โหลด เว้นแต่ผู้ใช้จะเลื่อนเกินจุดที่กำหนด (การโหลดแบบขี้เกียจ) หรือแตะปุ่ม "แสดงเพิ่มเติม"
ดังนั้นแม้ว่าจะมีการแสดงผล JavaScript โปรแกรมรวบรวมข้อมูลไม่สามารถเข้าถึงลิงก์ภายในสำหรับผลิตภัณฑ์ที่ยังไม่ได้โหลด อย่างไรก็ตาม การโหลดผลิตภัณฑ์เหล่านี้ทั้งหมดในหน้าเดียวจะส่งผลเสียต่อประสบการณ์ของผู้ใช้เนื่องจากประสิทธิภาพของหน้าไม่ดี
นี่คือเหตุผลที่ SEO โดยทั่วไปชอบการแบ่งหน้าจริง ซึ่งทุกหน้าของผลลัพธ์มี URL ที่แตกต่างกันและสามารถรวบรวมข้อมูลได้
แม้ว่าจะมีวิธีต่างๆ สำหรับไซต์ในการเพิ่มประสิทธิภาพการโหลดแบบ Lazy Loading และเพิ่มผลิตภัณฑ์ทั้งหมดลงใน HTML ที่แสดงผลล่วงหน้า สิ่งนี้จะนำไปสู่ความแตกต่างระหว่าง HTML ที่แสดงผลและ HTML ที่แสดงผลล่วงหน้า
สิ่งนี้สร้างเหตุผลให้ส่งหน้ามากขึ้นไปยังคิวการแสดงผล และทำให้โปรแกรมรวบรวมข้อมูลทำงานหนักกว่าที่จำเป็น และเรารู้ว่านั่นไม่ดีสำหรับ SEO
อย่างน้อยที่สุด ให้ทำตามคำแนะนำของ Google เพื่อเพิ่มประสิทธิภาพการเลื่อนที่ไม่มีที่สิ้นสุด
ลิงค์ไม่ได้เข้ารหัสอย่างถูกต้อง
เมื่อ Google รวบรวมข้อมูลไซต์หรือแสดง URL ในคิว แสดงว่ากำลังดาวน์โหลดหน้าเว็บเวอร์ชันไร้สถานะ นั่นเป็นส่วนสำคัญว่าทำไมการใช้แท็ก href และจุดยึดที่เหมาะสม (โครงสร้างการเชื่อมโยงที่คุณเห็นบ่อยที่สุด) จึงมีความสำคัญมาก โปรแกรมรวบรวมข้อมูลไม่สามารถติดตามรูปแบบลิงก์ เช่น เราเตอร์ สแปน หรือ onClick
สามารถติดตาม:
- <a href="https://example.com">
- <a href="/relative/path/file">
ไม่สามารถติดตาม:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a>
สำหรับจุดประสงค์ของนักพัฒนา ทั้งหมดนี้เป็นวิธีที่ถูกต้องในการเขียนโค้ดลิงก์ นัยของ SEO เป็นบริบทเพิ่มเติมอีกชั้นหนึ่ง และไม่ใช่หน้าที่ของพวกเขาที่จะรู้ – มันเป็นหน้าที่ของ SEO
งานชิ้นใหญ่ของ SEO ที่ดีคือการให้บริบทนั้นแก่นักพัฒนาผ่านเอกสารประกอบ
ปัญหาที่ 5: ข้อมูลเมตาหายไป
ในหน้า HTML ข้อมูลเมตา เช่น ชื่อ คำอธิบาย URL ตามรูปแบบบัญญัติ และเมตาแท็กโรบ็อตจะซ้อนอยู่ในส่วนหัว
ด้วยเหตุผลที่ชัดเจน ข้อมูลเมตาที่ขาดหายไปนั้นส่งผลเสียต่อ SEO แต่ยิ่งกว่านั้นสำหรับ SPA องค์ประกอบต่างๆ เช่น URL ตามรูปแบบบัญญัติที่อ้างอิงตัวเองมีความสำคัญต่อการปรับปรุงโอกาสของหน้า JS ที่ทำให้ผ่านคิวการแสดงผลได้สำเร็จ
ในบรรดาองค์ประกอบทั้งหมดที่ควรมีใน HTML ที่แสดงผลล่วงหน้า ส่วนหัวมีความสำคัญที่สุดสำหรับการจัดทำดัชนี
โชคดีที่ปัญหานี้ค่อนข้างง่ายที่จะจับได้ เพราะจะทำให้เกิดข้อผิดพลาดมากมายสำหรับข้อมูลเมตาที่ขาดหายไปในเครื่องมือ SEO ใดก็ตามที่ไซต์ใช้ในการรายงานสุขอนามัย จากนั้น คุณสามารถยืนยันได้โดยมองหาส่วนหัวในซอร์สโค้ด
สาเหตุทั่วไป
ไม่มียานพาหนะข้อมูลเมตาหรือกำหนดค่าไม่ถูกต้อง
ในเฟรมเวิร์ก JS ปลั๊กอินจะสร้างส่วนหัวและแทรกข้อมูลเมตาลงในส่วนหัว (ตัวอย่างที่ได้รับความนิยมมากที่สุดคือ React Helmet) แม้ว่าจะมีการติดตั้งปลั๊กอินอยู่แล้ว แต่ก็มักจะต้องกำหนดค่าให้ถูกต้อง
นี่เป็นส่วนที่ SEO ทุกคนทำได้คือนำปัญหาไปให้นักพัฒนา อธิบายสาเหตุ และทำงานอย่างใกล้ชิดเพื่อบรรลุเกณฑ์การยอมรับที่มีเอกสารครบถ้วน
ปัญหาที่ 6: ทรัพยากรไม่ได้รับการรวบรวมข้อมูล
ไฟล์สคริปต์และรูปภาพเป็นส่วนสำคัญในกระบวนการเรนเดอร์
เนื่องจากมี URL ของตัวเองด้วย กฎหมายความสามารถในการรวบรวมข้อมูลจึงมีผลบังคับใช้กับพวกเขาด้วย หากไฟล์ถูกบล็อกไม่ให้รวบรวมข้อมูล Google จะไม่สามารถแยกวิเคราะห์หน้าเพื่อแสดงผลได้
หากต้องการดูว่ามีการรวบรวมข้อมูล URL หรือไม่ คุณสามารถดูคำขอที่ผ่านมาใน GSC Crawl Stats
- รูปภาพ: ไปที่ การตั้งค่า > สถิติการรวบรวมข้อมูล > คำขอรวบรวมข้อมูล: รูปภาพ
- JavaScript: ไปที่ การตั้งค่า > สถิติการรวบรวมข้อมูล > คำขอรวบรวมข้อมูล: รูปภาพ
สาเหตุทั่วไป
ไดเรกทอรีถูกบล็อกโดย robots.txt
โดยทั่วไปแล้ว ทั้ง URL ของสคริปต์และรูปภาพจะซ้อนอยู่ในโดเมนย่อยหรือโฟลเดอร์ย่อยเฉพาะของตนเอง ดังนั้นการแสดงออกที่ไม่อนุญาตใน robots.txt จะป้องกันการรวบรวมข้อมูล
เครื่องมือ SEO บางอย่างจะบอกคุณว่าไฟล์สคริปต์หรือไฟล์รูปภาพถูกบล็อกหรือไม่ แต่ปัญหานั้นค่อนข้างง่ายที่จะสังเกตหากคุณทราบว่าไฟล์รูปภาพและสคริปต์ของคุณซ้อนกันอยู่ที่ใด คุณสามารถค้นหาโครงสร้าง URL เหล่านั้นได้ใน robots.txt
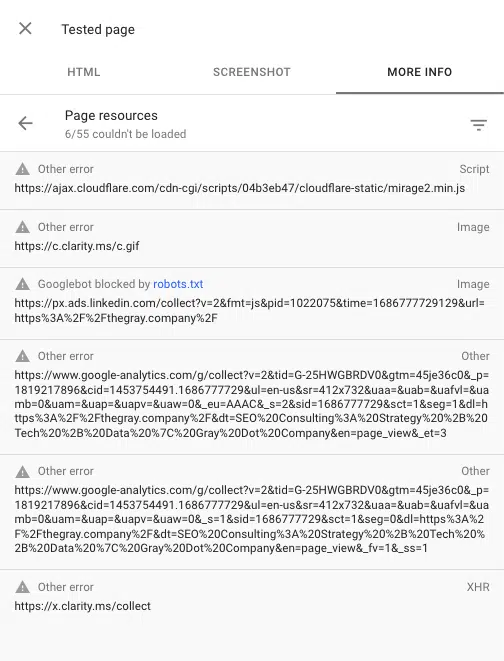
คุณยังสามารถดูสคริปต์ที่ถูกบล็อกเมื่อแสดงผลหน้าเว็บโดยใช้เครื่องมือตรวจสอบ URL ใน Google Search Console “ทดสอบ URL จริง” จากนั้นไปที่ ดูหน้าที่ทดสอบ > ข้อมูลเพิ่มเติม > ทรัพยากรของหน้า
คุณสามารถดูสคริปต์ที่โหลดไม่สำเร็จระหว่างกระบวนการเรนเดอร์ได้ที่นี่ หากไฟล์ถูกบล็อกโดย robots.txt ไฟล์นั้นจะถูกทำเครื่องหมายเช่นนั้น
ทำความรู้จักกับ JavaScript
ใช่ JavaScript อาจมาพร้อมกับปัญหา SEO บางอย่าง แต่เมื่อ SEO พัฒนาขึ้น แนวทางปฏิบัติที่ดีที่สุดก็มีความหมายเหมือนกันกับประสบการณ์ของผู้ใช้ที่ยอดเยี่ยม
ประสบการณ์ของผู้ใช้ที่ดีมักจะขึ้นอยู่กับจาวาสคริปต์ ดังนั้น แม้ว่างานของ SEO จะไม่ใช่การเขียนโค้ด JavaScript แต่เราจำเป็นต้องรู้ว่าเครื่องมือค้นหาโต้ตอบ แสดงผล และใช้งานอย่างไร
ด้วยความเข้าใจอย่างถ่องแท้เกี่ยวกับกระบวนการเรนเดอร์และปัญหา SEO ทั่วไปบางประการในเฟรมเวิร์ก JS คุณก็พร้อมที่จะระบุปัญหาและเป็นพันธมิตรที่ทรงพลังกับนักพัฒนาของคุณ
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่