
Entity SEO: คำแนะนำขั้นสุดท้าย
เผยแพร่แล้ว: 2023-04-06บทความนี้ร่วมเขียนโดย Andrew Ansley
สิ่งต่าง ๆ ไม่ใช่สตริง หากคุณไม่เคยได้ยินมาก่อน ข้อความนี้มาจากบล็อกโพสต์ของ Google ที่มีชื่อเสียงซึ่งประกาศกราฟความรู้
วันครบรอบ 11 ปีของการประกาศอยู่ห่างออกไปเพียงหนึ่งเดือน แต่หลายคนยังคงพยายามทำความเข้าใจว่า “สิ่งต่างๆ ไม่ใช่สตริง” หมายถึงอะไรสำหรับ SEO จริงๆ
คำพูดนี้เป็นความพยายามที่จะสื่อว่า Google เข้าใจ สิ่งต่าง ๆ และไม่ใช่อัลกอริทึมการตรวจหาคำหลักธรรมดาอีกต่อไป
ในเดือนพฤษภาคม 2012 อาจมีคนแย้งว่าเอนทิตี SEO ถือกำเนิดขึ้น แมชชีนเลิร์นนิงของ Google ซึ่งได้รับความช่วยเหลือจากฐานความรู้กึ่งโครงสร้างและโครงสร้าง สามารถเข้าใจความหมายที่อยู่เบื้องหลังคำหลักได้
ธรรมชาติที่กำกวมของภาษามีทางออกระยะยาวในที่สุด
ดังนั้น หากเอนทิตีมีความสำคัญต่อ Google มานานกว่าทศวรรษ เหตุใดนัก SEO จึงยังคงสับสนเกี่ยวกับเอนทิตี
คำถามที่ดี. ฉันเห็นเหตุผลสี่ประการ:
- คำว่า SEO เอนทิตีไม่ได้ถูกใช้อย่างกว้างขวางเพียงพอสำหรับ SEO ที่จะคุ้นเคยกับคำจำกัดความของมัน ดังนั้นจึงรวมไว้ในคำศัพท์ของพวกเขา
- การเพิ่มประสิทธิภาพสำหรับเอนทิตีจะทับซ้อนอย่างมากกับวิธีการเพิ่มประสิทธิภาพที่เน้นคำหลักแบบเก่า เป็นผลให้เอนทิตีถูกรวมเข้ากับคำหลัก นอกจากนี้ ยังไม่เป็นที่ชัดเจนว่าเอนทิตีมีบทบาทอย่างไรใน SEO และบางครั้งคำว่า "เอนทิตี" สามารถใช้แทนกันได้กับ "หัวข้อ" เมื่อ Google พูดถึงเรื่องนี้
- การทำความเข้าใจเอนทิตีเป็นงานที่น่าเบื่อ หากคุณต้องการความรู้เชิงลึกเกี่ยวกับเอนทิตี คุณจะต้องอ่านสิทธิบัตรของ Google และรู้พื้นฐานของแมชชีนเลิร์นนิง Entity SEO เป็นวิธีการเชิงวิทยาศาสตร์มากกว่าการทำ SEO และวิทยาศาสตร์ก็ไม่ได้เหมาะสำหรับทุกคน
- แม้ว่า YouTube จะส่งผลกระทบต่อการเผยแพร่ความรู้อย่างมาก แต่ก็ทำให้ประสบการณ์การเรียนรู้ในหลายๆ วิชาลดลง ผู้สร้างที่ประสบความสำเร็จมากที่สุดบนแพลตฟอร์มเคยใช้เส้นทางง่ายๆ ในการให้ความรู้แก่ผู้ชม ด้วยเหตุนี้ ผู้สร้างเนื้อหาจึงใช้เวลากับเอนทิตีไม่นานจนกระทั่งเมื่อไม่นานมานี้ ด้วยเหตุนี้ คุณจึงต้องเรียนรู้เกี่ยวกับเอนทิตีจากนักวิจัย NLP จากนั้นจึงจำเป็นต้องนำความรู้ไปใช้กับ SEO สิทธิบัตรและเอกสารการวิจัยเป็นกุญแจสำคัญ นี่เป็นการตอกย้ำประเด็นแรกข้างต้นอีกครั้ง
บทความนี้เป็นวิธีแก้ปัญหาทั้งสี่ข้อที่ทำให้ SEO ไม่สามารถเชี่ยวชาญแนวทาง SEO ที่อิงตามเอนทิตีได้อย่างเต็มที่
เมื่ออ่านสิ่งนี้ คุณจะได้เรียนรู้:
- เอนทิตีคืออะไรและเหตุใดจึงมีความสำคัญ
- ประวัติการค้นหาความหมาย
- วิธีระบุและใช้เอนทิตีใน SERP
- วิธีใช้เอนทิตีเพื่อจัดอันดับเนื้อหาเว็บ
เหตุใดเอนทิตีจึงมีความสำคัญ
Entity SEO คืออนาคตของเครื่องมือค้นหาที่มุ่งไปที่การเลือกเนื้อหาที่จะจัดอันดับและกำหนดความหมายของมัน
เมื่อรวมสิ่งนี้เข้ากับความไว้วางใจบนฐานความรู้ และฉันเชื่อว่าเอนทิตี SEO จะเป็นอนาคตของวิธีการทำ SEO ในอีกสองปีข้างหน้า
ตัวอย่างของเอนทิตี
ดังนั้นคุณจะรู้จักเอนทิตีได้อย่างไร
SERP มีตัวอย่างหลายรายการที่คุณน่าจะเคยเห็น
ประเภทของเอนทิตีที่พบบ่อยที่สุดคือเกี่ยวข้องกับสถานที่ ผู้คน หรือธุรกิจ
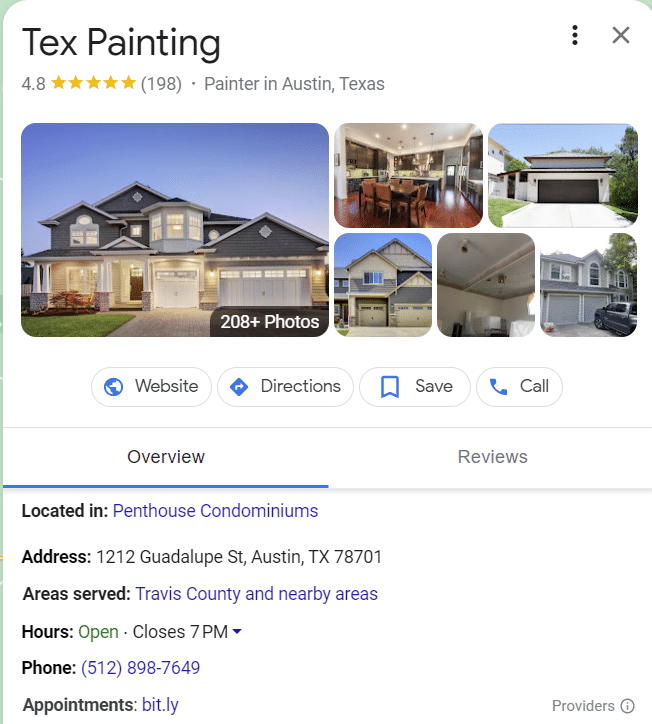
บางทีตัวอย่างที่ดีที่สุดของเอนทิตีใน SERP ก็คือกลุ่มเจตนา ยิ่งเข้าใจหัวข้อมากเท่าใด คุณลักษณะการค้นหาเหล่านี้ก็ยิ่งปรากฏขึ้นมากเท่านั้น
ที่น่าสนใจคือ แคมเปญ SEO เดียวสามารถเปลี่ยนโฉมหน้าของ SERP ได้เมื่อคุณรู้วิธีดำเนินการแคมเปญ SEO ที่เน้นเอนทิตี
รายการ Wikipedia เป็นอีกตัวอย่างหนึ่งของเอนทิตี Wikipedia ให้ตัวอย่างที่ดีของข้อมูลที่เกี่ยวข้องกับเอนทิตี
ดังที่คุณเห็นจากด้านบนซ้าย เอนทิตีมีแอตทริบิวต์ทุกประเภทที่เกี่ยวข้องกับ "ปลา" ตั้งแต่ลักษณะทางกายวิภาคไปจนถึงความสำคัญต่อมนุษย์
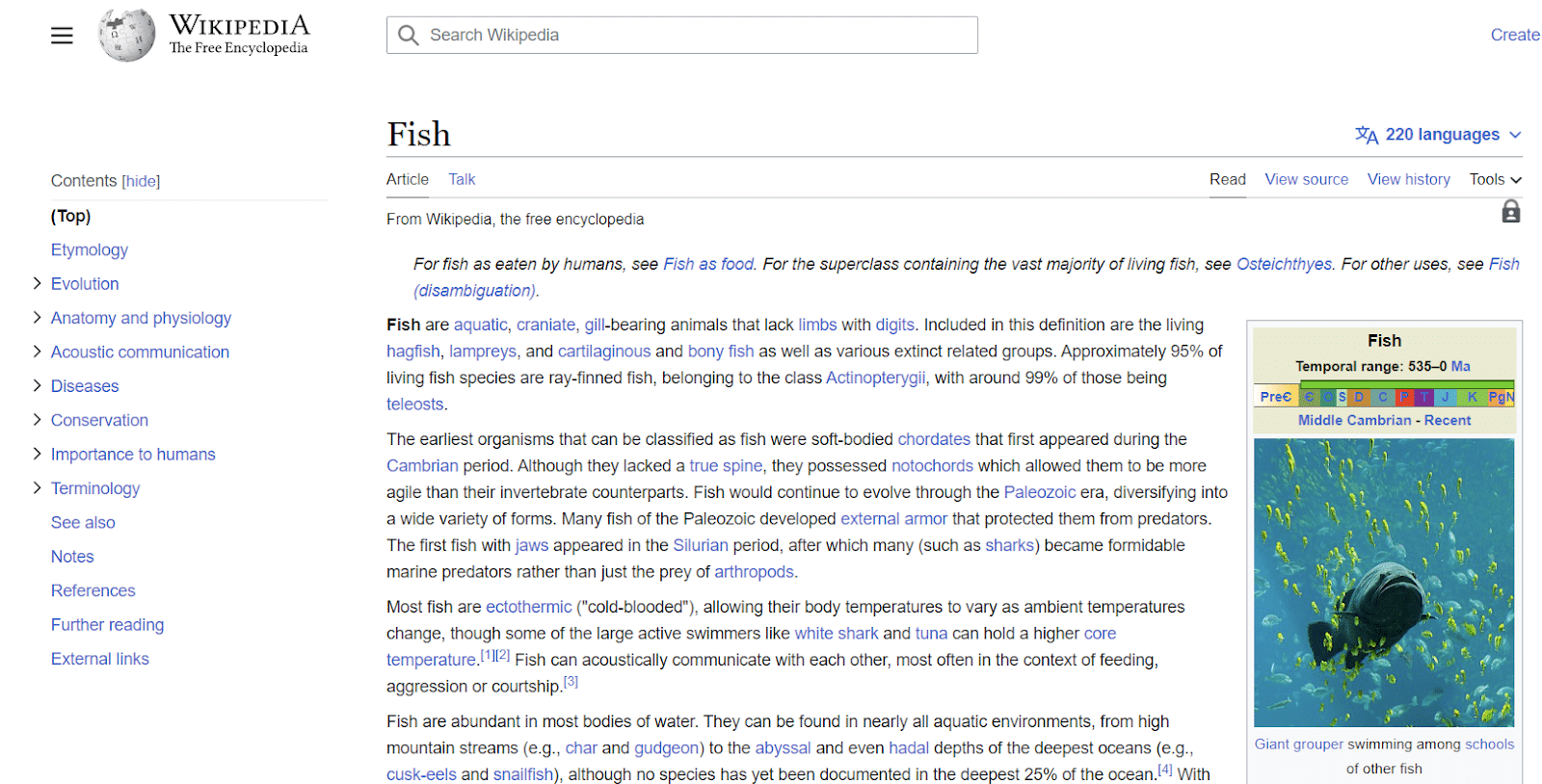
แม้ว่าวิกิพีเดียจะมีจุดข้อมูลมากมายในหัวข้อหนึ่งๆ แต่ก็ไม่ครบถ้วนสมบูรณ์
เอนทิตีคืออะไร?
เอนทิตีคือวัตถุหรือสิ่งที่สามารถระบุตัวตนได้โดยไม่ซ้ำใคร โดยมีลักษณะเฉพาะตามชื่อ ประเภท คุณลักษณะ และความสัมพันธ์กับเอนทิตีอื่นๆ เอนทิตีจะถือว่ามีอยู่ก็ต่อเมื่อมีอยู่ในแคตตาล็อกเอนทิตี
แคตตาล็อกเอนทิตีกำหนด ID เฉพาะให้กับแต่ละเอนทิตี เอเจนซีของฉันมีโซลูชันแบบเป็นโปรแกรมที่ใช้รหัสเฉพาะที่เชื่อมโยงกับแต่ละเอนทิตี (รวมบริการ ผลิตภัณฑ์ และแบรนด์ทั้งหมด)
ถ้าคำหรือวลีไม่อยู่ในแค็ตตาล็อกที่มีอยู่ ไม่ได้หมายความว่าคำหรือวลีนั้นไม่ใช่เอนทิตี แต่โดยทั่วไปแล้วคุณสามารถทราบได้ว่าบางสิ่งเป็นเอนทิตีจากการมีอยู่ในแคตตาล็อก
สิ่งสำคัญคือต้องสังเกตว่า Wikipedia ไม่ใช่ปัจจัยในการตัดสินใจว่าบางสิ่งเป็นเอนทิตีหรือไม่ แต่บริษัทเป็นที่รู้จักมากที่สุดจากฐานข้อมูลของเอนทิตี
สามารถใช้แค็ตตาล็อกใด ๆ เมื่อพูดถึงเอนทิตี โดยทั่วไปแล้ว เอนทิตีคือบุคคล สถานที่ หรือสิ่งของ แต่สามารถรวมแนวคิดและแนวคิดไว้ด้วย
ตัวอย่างของแคตตาล็อกเอนทิตีประกอบด้วย:
- วิกิพีเดีย
- วิกิสนเทศ
- ดีบีพีเดีย
- ฟรีเบส
- ยาโกะ

หน่วยงานช่วยลดช่องว่างระหว่างโลกของข้อมูลที่ไม่มีโครงสร้างและไม่มีโครงสร้าง
สามารถใช้เพื่อเพิ่มคุณค่าให้กับข้อความที่ไม่มีโครงสร้างในเชิงความหมาย ในขณะที่แหล่งข้อมูลที่เป็นข้อความอาจใช้เพื่อเติมฐานความรู้ที่มีโครงสร้าง
การจดจำการกล่าวถึงเอนทิตีในข้อความและเชื่อมโยงการกล่าวถึงเหล่านี้กับรายการที่สอดคล้องกันในฐานความรู้เรียกว่างานของการเชื่อมโยงเอนทิตี
เอนทิตีช่วยให้เข้าใจความหมายของข้อความได้ดีขึ้น ทั้งสำหรับมนุษย์และสำหรับเครื่องจักร
ในขณะที่มนุษย์สามารถแก้ไขความกำกวมของเอนทิตีได้โดยง่ายตามบริบทที่กล่าวถึง สิ่งนี้นำเสนอความยากลำบากและความท้าทายมากมายสำหรับเครื่องจักร
รายการฐานความรู้ของเอนทิตีจะสรุปสิ่งที่เรารู้เกี่ยวกับเอนทิตีนั้น
ในขณะที่โลกมีการเปลี่ยนแปลงตลอดเวลา ข้อเท็จจริงใหม่ๆ ก็ปรากฏขึ้นเช่นกัน การติดตามการเปลี่ยนแปลงเหล่านี้ต้องใช้ความพยายามอย่างต่อเนื่องจากบรรณาธิการและผู้จัดการเนื้อหา นี่เป็นงานที่เรียกร้องในระดับมาก
ด้วยการวิเคราะห์เนื้อหาของเอกสารที่มีการกล่าวถึงเอนทิตี กระบวนการค้นหาข้อเท็จจริงใหม่หรือข้อเท็จจริงที่ต้องอัปเดตอาจได้รับการสนับสนุนหรือแม้แต่การทำงานอัตโนมัติทั้งหมด
นักวิทยาศาสตร์อ้างถึงสิ่งนี้ว่าเป็นปัญหาของประชากรฐานความรู้ ซึ่งเป็นสาเหตุที่การเชื่อมโยงเอนทิตีมีความสำคัญ
เอนทิตีช่วยอำนวยความสะดวกในการทำความเข้าใจความหมายของความต้องการข้อมูลของผู้ใช้ ซึ่งแสดงโดยการค้นหาคำหลัก และเนื้อหาของเอกสาร เอนทิตีจึงอาจใช้เพื่อปรับปรุงการสืบค้นและ/หรือการแสดงเอกสาร
ในงานวิจัย Extended Named Entity ผู้เขียนระบุประเภทเอนทิตีประมาณ 160 ประเภท นี่คือภาพหน้าจอสองในเจ็ดรายการจากรายการ


ประเภทของเอนทิตีบางประเภทสามารถกำหนดได้ง่ายกว่า แต่สิ่งสำคัญคือต้องจำไว้ว่าแนวคิดและแนวคิดก็คือเอนทิตี ทั้งสองหมวดหมู่นี้เป็นเรื่องยากมากที่ Google จะปรับขนาดด้วยตัวเอง
คุณไม่สามารถสอน Google ด้วยหน้าเดียวเมื่อทำงานกับแนวคิดที่คลุมเครือ ความเข้าใจในเอนทิตีต้องการบทความจำนวนมากและการอ้างอิงจำนวนมากที่คงอยู่ในช่วงเวลาหนึ่ง
ประวัติของ Google พร้อมเอนทิตี
เมื่อวันที่ 16 กรกฎาคม 2010 Google ได้ซื้อ Freebase การซื้อนี้เป็นขั้นตอนสำคัญประการแรกที่นำไปสู่ระบบการค้นหาเอนทิตีในปัจจุบัน

หลังจากลงทุนใน Freebase แล้ว Google ก็ตระหนักว่า Wikidata มีทางออกที่ดีกว่า จากนั้น Google จึงทำงานเพื่อรวม Freebase เข้ากับ Wikidata ซึ่งเป็นงานที่ยากกว่าที่คิดไว้มาก
นักวิทยาศาสตร์ของ Google ห้าคนเขียนบทความเรื่อง “From Freebase to Wikidata: The Great Migration” ประเด็นสำคัญ ได้แก่
“Freebase สร้างขึ้นจากแนวคิดของวัตถุ ข้อเท็จจริง ประเภท และคุณสมบัติ ออบเจ็กต์ Freebase แต่ละรายการมีตัวระบุที่เสถียรซึ่งเรียกว่า "กลาง" (สำหรับรหัสเครื่อง)”
“แบบจำลองข้อมูลของวิกิดาต้าขึ้นอยู่กับแนวคิดของรายการและข้อความ รายการเป็นตัวแทนของเอนทิตี มีตัวระบุที่เสถียรซึ่งเรียกว่า "qid" และอาจมีป้ายกำกับ คำอธิบาย และนามแฝงในหลายภาษา ถ้อยแถลงเพิ่มเติมและลิงก์ไปยังหน้าเกี่ยวกับตัวตนในโครงการวิกิมีเดียอื่น ๆ ซึ่งโดดเด่นที่สุดคือวิกิพีเดีย ตรงกันข้ามกับ Freebase แถลงการณ์ของ Wikidata ไม่ได้มีเป้าหมายเพื่อเข้ารหัสข้อเท็จจริงที่แท้จริง แต่เป็นการอ้างสิทธิ์จากแหล่งต่างๆ ซึ่งอาจขัดแย้งกันเองด้วย…”
เอนทิตีถูกกำหนดไว้ในฐานความรู้เหล่านี้ แต่ Google ยังคงต้องสร้างความรู้ของเอนทิตีสำหรับข้อมูลที่ไม่มีโครงสร้าง (เช่น บล็อก)
Google ร่วมมือกับ Bing และ Yahoo และสร้าง Schema.org เพื่อทำงานนี้ให้สำเร็จ
Google ให้คำแนะนำสคีมาเพื่อให้ผู้จัดการเว็บไซต์มีเครื่องมือที่ช่วยให้ Google เข้าใจเนื้อหาได้ โปรดจำไว้ว่า Google ต้องการเน้นที่สิ่งต่างๆ ไม่ใช่สตริง
ในคำพูดของ Google:
“คุณช่วยเราได้ด้วยการให้เบาะแสที่ชัดเจนเกี่ยวกับความหมายของหน้าแก่ Google โดยรวมข้อมูลที่มีโครงสร้างไว้ในหน้านั้น ข้อมูลที่มีโครงสร้างเป็นรูปแบบมาตรฐานสำหรับการให้ข้อมูลเกี่ยวกับหน้าและจัดประเภทเนื้อหาของหน้า ตัวอย่างเช่น ในหน้าสูตรอาหาร ส่วนผสมคืออะไร เวลาและอุณหภูมิในการปรุง แคลอรี และอื่นๆ”
Google กล่าวต่อไปว่า:
“คุณต้องรวมคุณสมบัติที่จำเป็นทั้งหมดสำหรับวัตถุเพื่อให้มีสิทธิ์ปรากฏใน Google Search ด้วยการแสดงผลที่ปรับปรุงแล้ว โดยทั่วไป การกำหนดคุณลักษณะที่แนะนำเพิ่มเติมจะทำให้มีโอกาสมากขึ้นที่ข้อมูลของคุณจะปรากฏในผลการค้นหาด้วยการแสดงผลที่ปรับปรุงแล้ว อย่างไรก็ตาม การให้พร็อพเพอร์ตี้ที่แนะนำน้อยลงแต่ครบถ้วนและถูกต้องนั้นสำคัญกว่าการพยายามจัดหาพร็อพเพอร์ตี้ที่แนะนำทั้งหมดที่เป็นไปได้ด้วยข้อมูลที่ไม่สมบูรณ์ มีรูปแบบไม่ดี หรือไม่ถูกต้อง”
สามารถพูดได้มากกว่านี้เกี่ยวกับสคีมา แต่พอเพียงแล้วที่จะบอกว่าสคีมาเป็นเครื่องมือที่น่าทึ่งสำหรับ SEO ที่ต้องการทำให้เนื้อหาของหน้าชัดเจนสำหรับเครื่องมือค้นหา
ปริศนาชิ้นสุดท้ายมาจากการประกาศบล็อกของ Google ที่ชื่อว่า “การปรับปรุงการค้นหาสำหรับ 20 ปีข้างหน้า”
ความเกี่ยวข้องและคุณภาพของเอกสารเป็นแนวคิดหลักเบื้องหลังการประกาศนี้ วิธีแรกที่ Google ใช้ในการพิจารณาเนื้อหาของหน้าเว็บนั้นมุ่งเน้นไปที่คำหลักทั้งหมด
จากนั้น Google ได้เพิ่มเลเยอร์หัวข้อเพื่อค้นหา เลเยอร์นี้เกิดขึ้นได้จากกราฟความรู้และการคัดลอกและจัดโครงสร้างข้อมูลทั่วทั้งเว็บอย่างเป็นระบบ
นั่นนำเราไปสู่ระบบการค้นหาปัจจุบัน Google เปลี่ยนจาก 570 ล้านรายการและ 18 พันล้านข้อเท็จจริงเป็น 800 พันล้านข้อเท็จจริงและ 8 พันล้านรายการภายในเวลาไม่ถึง 10 ปี เมื่อจำนวนนี้เพิ่มขึ้น การค้นหาเอนทิตีก็ดีขึ้น
โมเดลเอนทิตีมีการปรับปรุงจากโมเดลการค้นหาก่อนหน้าอย่างไร
โมเดลการดึงข้อมูล (IR) ตามคีย์เวิร์ดแบบดั้งเดิมมีข้อจำกัดโดยธรรมชาติคือไม่สามารถดึงเอกสาร (ที่เกี่ยวข้อง) ที่ไม่มีคำที่ชัดเจนซึ่งตรงกับคำค้นหา
หากคุณใช้ ctrl + f เพื่อค้นหาข้อความบนหน้า คุณจะใช้สิ่งที่คล้ายกับรูปแบบการดึงข้อมูลตามคำหลักแบบดั้งเดิม
มีการเผยแพร่ข้อมูลจำนวนมากบนเว็บทุกวัน
เป็นไปไม่ได้ที่ Google จะเข้าใจความหมายของทุกคำ ทุกย่อหน้า ทุกบทความ และทุกเว็บไซต์
เอนทิตีจะจัดเตรียมโครงสร้างที่ Google สามารถลดภาระการคำนวณลงได้ในขณะที่ปรับปรุงความเข้าใจ
“วิธีการดึงข้อมูลตามแนวคิดพยายามที่จะจัดการกับความท้าทายนี้โดยอาศัยโครงสร้างเสริมเพื่อให้ได้การแสดงความหมายของข้อความค้นหาและเอกสารในพื้นที่แนวคิดระดับที่สูงขึ้น โครงสร้างดังกล่าวรวมถึงคำศัพท์ควบคุม (พจนานุกรมและอรรถาภิธาน) ภววิทยา และเอนทิตีจากคลังความรู้”
– การค้นหาเชิงเอนทิตี บทที่ 8.3
Krisztian Balog ผู้เขียนหนังสือฉบับสมบูรณ์เกี่ยวกับเอนทิตี ได้ระบุวิธีแก้ปัญหาที่เป็นไปได้ 3 วิธีสำหรับโมเดลการดึงข้อมูลแบบดั้งเดิม
- ตามการขยายตัว : ใช้เอนทิตีเป็นแหล่งข้อมูลสำหรับการขยายการสืบค้นด้วยเงื่อนไขต่างๆ
- Projection-based : เข้าใจความเกี่ยวข้องระหว่างแบบสอบถามและเอกสารโดยการฉายไปยังพื้นที่แฝงของเอนทิตี
- ตามเอนทิตี : การแสดงความหมายที่ชัดเจนของข้อความค้นหาและเอกสารจะได้รับในพื้นที่เอนทิตีเพื่อเพิ่มการแสดงตามคำ
เป้าหมายของแนวทางทั้ง 3 นี้คือการได้รับข้อมูลของผู้ใช้ที่ต้องการมากขึ้นโดยการระบุเอนทิตีที่เกี่ยวข้องกับการสืบค้นอย่างมาก
จากนั้น Balog จะระบุอัลกอริทึมหกรายการที่เกี่ยวข้องกับวิธีการแมปเอนทิตีตามการฉายภาพ (วิธีการฉายภาพเกี่ยวข้องกับการแปลงเอนทิตีเป็นพื้นที่สามมิติและการวัดเวกเตอร์โดยใช้รูปทรงเรขาคณิต)
- การวิเคราะห์ความหมายที่ชัดเจน (ESA) : ความหมายของคำที่กำหนดได้รับการอธิบายโดยเวกเตอร์ที่จัดเก็บจุดแข็งของคำที่เกี่ยวข้องกับแนวคิดที่ได้มาจากวิกิพีเดีย
- แบบจำลองพื้นที่เอนทิตีแฝง (LES) : ขึ้นอยู่กับกรอบความน่าจะเป็นเชิงกำเนิด คะแนนการดึงข้อมูลของเอกสารถือเป็นการรวมกันเชิงเส้นของคะแนนพื้นที่เอนทิตีแฝงและคะแนนความน่าจะเป็นของคิวรีดั้งเดิม
- EsdRank: EsdRank มีไว้สำหรับจัดลำดับเอกสาร โดยใช้การผสมผสานระหว่างฟีเจอร์เคียวรีเอนทิตีและเอนทิตีเอกสาร สิ่งเหล่านี้สอดคล้องกับแนวคิดขององค์ประกอบการฉายภาพแบบสอบถามและองค์ประกอบการฉายเอกสารของ LES ตามลำดับจากก่อนหน้านี้ การใช้เฟรมเวิร์กการเรียนรู้แบบเลือกปฏิบัติ สัญญาณเพิ่มเติมสามารถรวมเข้าด้วยกันได้อย่างง่ายดาย เช่น ความนิยมของเอนทิตีหรือคุณภาพของเอกสาร
- การจัดอันดับความหมายที่ชัดเจน (ESR): รูปแบบการจัดอันดับความหมายที่ชัดเจนรวมข้อมูลความสัมพันธ์จากกราฟความรู้เพื่อเปิดใช้งาน "การจับคู่แบบอ่อน" ในพื้นที่เอนทิตี
- Word-entity duet framework: รวมการโต้ตอบข้ามช่องว่างระหว่างการแทนตามคำและเอนทิตี ซึ่งนำไปสู่การจับคู่สี่ประเภท: เงื่อนไขการสืบค้นกับเงื่อนไขเอกสาร เอนทิตีการสืบค้นไปยังเงื่อนไขเอกสาร เงื่อนไขการสืบค้นกับเอนทิตีเอกสาร และเอนทิตีการสืบค้น เพื่อจัดทำเอกสารเอนทิตี
- รูปแบบการจัดอันดับตามความสนใจ : นี่เป็นสิ่งที่ซับซ้อนที่สุดที่จะอธิบาย
นี่คือสิ่งที่ Balog เขียน:
“มีการออกแบบฟีเจอร์ความสนใจทั้งหมดสี่ฟีเจอร์ ซึ่งแยกออกมาสำหรับเอนทิตีการสืบค้นแต่ละรายการ คุณลักษณะความกำกวมของเอนทิตีมีไว้เพื่อระบุลักษณะความเสี่ยงที่เกี่ยวข้องกับหมายเหตุประกอบเอนทิตี เหล่านี้คือ: (1) เอนโทรปีของความน่าจะเป็นของรูปแบบพื้นผิวที่เชื่อมโยงกับเอนทิตีที่แตกต่างกัน (เช่น ในวิกิพีเดีย) (2) เอนทิตีที่มีคำอธิบายประกอบเป็นความรู้สึกที่ได้รับความนิยมมากที่สุดของรูปแบบพื้นผิวหรือไม่ (เช่น มีความเหมือนกันสูงสุด คะแนน และ (3) ความแตกต่างของคะแนนสามัญระหว่างผู้สมัครที่มีแนวโน้มมากที่สุดและผู้สมัครที่มีแนวโน้มมากที่สุดเป็นอันดับสองสำหรับแบบฟอร์มพื้นผิวที่กำหนด คุณลักษณะที่ 4 คือความใกล้เคียงซึ่งถูกกำหนดให้เป็นความคล้ายคลึงกันของโคไซน์ระหว่างเอนทิตีแบบสอบถามและแบบสอบถามในพื้นที่ฝัง โดยเฉพาะอย่างยิ่ง การฝังคำในเอนทิตีร่วมได้รับการฝึกอบรมโดยใช้โมเดลข้ามแกรมในคลังข้อมูล โดยที่การกล่าวถึงเอนทิตีจะถูกแทนที่ด้วยตัวระบุเอนทิตีที่สอดคล้องกัน การฝังคำค้นหาถือเป็นจุดศูนย์กลางของการฝังคำคำค้นหา”

สำหรับตอนนี้ สิ่งสำคัญคือต้องมีความคุ้นเคยในระดับพื้นผิวกับอัลกอริทึมที่เน้นเอนทิตีทั้งหกนี้
ประเด็นหลักคือมีสองวิธี: การฉายเอกสารไปยังเลเยอร์เอนทิตีแฝงและการเพิ่มคำอธิบายประกอบเอนทิตีที่ชัดเจนของเอกสาร
โครงสร้างข้อมูลสามประเภท
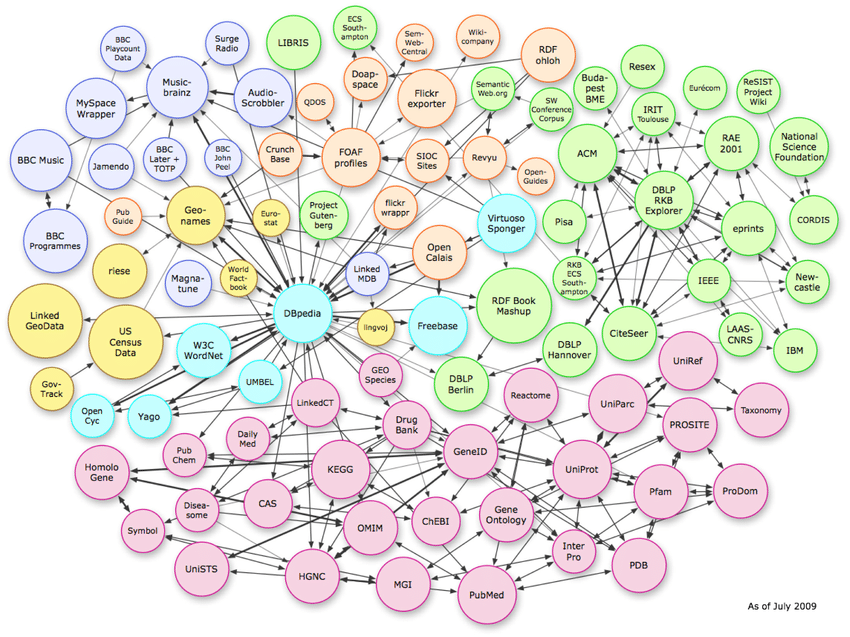
ภาพด้านบนแสดงความสัมพันธ์ที่ซับซ้อนในปริภูมิเวกเตอร์ ในขณะที่ตัวอย่างแสดงการเชื่อมต่อของกราฟความรู้ รูปแบบเดียวกันนี้สามารถทำซ้ำได้ในระดับสคีมาแบบหน้าต่อหน้า
เพื่อให้เข้าใจเอนทิตี สิ่งสำคัญคือต้องทราบโครงสร้างข้อมูลสามประเภทที่อัลกอริทึมใช้
- การใช้ คำอธิบายเอนทิตีแบบไม่มีโครงสร้าง การอ้างอิงถึงเอนทิตีอื่นจะต้องได้รับการยอมรับและไม่คลุมเครือ ขอบกำกับ (ไฮเปอร์ลิงก์) จะถูกเพิ่มจากแต่ละเอนทิตีไปยังเอนทิตีอื่นๆ ทั้งหมดที่กล่าวถึงในคำอธิบาย
- ในการตั้งค่า แบบกึ่งโครงสร้าง (เช่น วิกิพีเดีย) อาจมีการระบุลิงก์ไปยังเอนทิตีอื่นอย่างชัดเจน
- เมื่อทำงานกับ ข้อมูลที่มีโครงสร้าง สามเท่าของ RDF จะกำหนดกราฟ (เช่น กราฟความรู้) โดยเฉพาะอย่างยิ่ง หัวเรื่องและทรัพยากรวัตถุ (URI) คือโหนด และภาคแสดงคือขอบ
ปัญหาเกี่ยวกับบริบทกึ่งโครงสร้างและทำให้เสียสมาธิสำหรับคะแนน IR คือหากเอกสารไม่ได้กำหนดค่าสำหรับหัวข้อเดียว คะแนน IR อาจถูกลดทอนลงด้วยบริบทที่แตกต่างกัน 2 บริบท ส่งผลให้อันดับสัมพัทธ์หายไปจากเอกสารข้อความอื่น
การลดคะแนน IR เกี่ยวข้องกับความสัมพันธ์ทางศัพท์ที่มีโครงสร้างไม่ดีและความใกล้เคียงของคำที่ไม่ดี
คำที่เกี่ยวข้องซึ่งเติมเต็มซึ่งกันและกันควรใช้อย่างใกล้ชิดภายในย่อหน้าหรือส่วนของเอกสารเพื่อส่งสัญญาณบริบทให้ชัดเจนยิ่งขึ้นเพื่อเพิ่มคะแนน IR
การใช้แอตทริบิวต์และความสัมพันธ์ของเอนทิตีทำให้มีการปรับปรุงสัมพัทธ์ในช่วง 5–20% การใช้ประโยชน์จากข้อมูลประเภทเอนทิตีนั้นให้ผลตอบแทนที่คุ้มค่ายิ่งขึ้น ด้วยการปรับปรุงที่เกี่ยวข้องตั้งแต่ 25% ถึงมากกว่า 100%
การใส่คำอธิบายประกอบในเอกสารที่มีเอนทิตีสามารถนำโครงสร้างไปสู่เอกสารที่ไม่มีโครงสร้าง ซึ่งสามารถช่วยเติมฐานความรู้ด้วยข้อมูลใหม่เกี่ยวกับเอนทิตี
ใช้วิกิพีเดียเป็นกรอบ SEO เอนทิตีของคุณ
โครงสร้างหน้าวิกิพีเดีย
- ชื่อเรื่อง (I.)
- ส่วนนำ (II.)
- ลิงก์แก้ความกำกวม (II.a)
- กล่องข้อมูล (II.b)
- ข้อความเบื้องต้น (II.c)
- สารบัญ (III.)
- เนื้อหาของร่างกาย (IV.)
- ภาคผนวกและสาระสำคัญ (V.)
- เอกสารอ้างอิงและหมายเหตุ (Va)
- ลิงก์ภายนอก (Vb)
- หมวดหมู่ (Vc)
บทความในวิกิพีเดียส่วนใหญ่ประกอบด้วยข้อความเกริ่นนำ "บทนำ" ซึ่งเป็นบทสรุปสั้นๆ ของบทความ โดยทั่วไปจะมีความยาวไม่เกินสี่ย่อหน้า ควรเขียนในลักษณะที่สร้างความน่าสนใจในบทความ
ประโยคแรกและวรรคเปิดมีความสำคัญเป็นพิเศษ ประโยคแรก "สามารถถือเป็นคำจำกัดความของเอนทิตีที่อธิบายไว้ในบทความ" ย่อหน้าแรกให้คำจำกัดความที่ซับซ้อนมากขึ้นโดยไม่มีรายละเอียดมากเกินไป
คุณค่าของลิงก์มีมากกว่าจุดประสงค์ในการนำทาง พวกเขาจับความสัมพันธ์เชิงความหมายระหว่างบทความ นอกจากนี้ anchor text ยังเป็นแหล่งที่มาของชื่อเอนทิตีที่หลากหลายอีกด้วย อาจใช้ลิงก์ Wikipedia เพื่อช่วยระบุและแยกแยะเอนทิตีที่กล่าวถึงในข้อความ
- สรุปข้อเท็จจริงที่สำคัญเกี่ยวกับเอนทิตี (กล่องข้อมูล)
- แนะนำสั้น ๆ.
- ลิงค์ภายใน. กฎหลักที่กำหนดให้กับผู้แก้ไขคือการเชื่อมโยงกับการเกิดขึ้นครั้งแรกของเอนทิตีหรือแนวคิดเท่านั้น
- รวมคำพ้องความหมายยอดนิยมทั้งหมดสำหรับเอนทิตี
- การกำหนดหน้าหมวดหมู่
- เทมเพลตการนำทาง
- อ้างอิง
- เครื่องมือแยกวิเคราะห์พิเศษสำหรับการทำความเข้าใจ Wiki Pages
- สื่อหลายประเภท
วิธีเพิ่มประสิทธิภาพสำหรับเอนทิตี
สิ่งต่อไปนี้คือข้อควรพิจารณาที่สำคัญเมื่อเพิ่มประสิทธิภาพเอนทิตีสำหรับการค้นหา:
- การรวมคำที่เกี่ยวข้องกับความหมายไว้ในหน้า
- ความถี่ของคำและวลีบนหน้า
- การจัดระเบียบแนวคิดในเพจ
- รวมถึงข้อมูลที่ไม่มีโครงสร้าง ข้อมูลกึ่งโครงสร้าง และข้อมูลที่มีโครงสร้างในหน้า
- Subject-Predicate-Object Pairs (SPO)
- เว็บเอกสารบนไซต์ที่ทำหน้าที่เป็นหน้าหนังสือ
- การจัดระเบียบเอกสารเว็บบนเว็บไซต์
- รวมแนวคิดในเอกสารบนเว็บที่เป็นคุณลักษณะที่รู้จักของเอนทิตี
หมายเหตุสำคัญ: เมื่อเน้นไปที่ความสัมพันธ์ระหว่างเอนทิตี ฐานความรู้มักจะเรียกว่ากราฟความรู้
เนื่องจากมีการวิเคราะห์เจตนาร่วมกับบันทึกการค้นหาของผู้ใช้และส่วนอื่นๆ ของบริบท วลีค้นหาเดียวกันจากบุคคลที่ 1 อาจสร้างผลลัพธ์ที่แตกต่างจากบุคคลที่ 2 บุคคลนั้นอาจมีเจตนาที่ต่างกันด้วยข้อความค้นหาเดียวกันทุกประการ
หากเพจของคุณครอบคลุมจุดประสงค์ทั้งสองประเภท เพจของคุณก็เป็นตัวเลือกที่ดีกว่าสำหรับการจัดอันดับเว็บ คุณสามารถใช้โครงสร้างของฐานความรู้เพื่อเป็นแนวทางในเทมเพลตจุดประสงค์การสืบค้นของคุณ (ตามที่กล่าวไว้ในส่วนก่อนหน้า)
ผู้คนยังถาม ค้นหาผู้คน และเติมข้อความอัตโนมัติมีความเกี่ยวข้องเชิงความหมายกับคำค้นหาที่ส่ง และอาจเจาะลึกลงไปในทิศทางการค้นหาปัจจุบัน หรือย้ายไปยังลักษณะอื่นของงานค้นหา
เรารู้เรื่องนี้แล้ว เราจะเพิ่มประสิทธิภาพได้อย่างไร
เอกสารของคุณควรมีรูปแบบต่างๆ ของจุดประสงค์ในการค้นหามากที่สุดเท่าที่จะเป็นไปได้ เว็บไซต์ของคุณควรมีรูปแบบความตั้งใจในการค้นหาทั้งหมดสำหรับคลัสเตอร์ของคุณ การจัดกลุ่มขึ้นอยู่กับความคล้ายคลึงกันสามประเภท:
- ความคล้ายคลึงกันของคำศัพท์
- ความคล้ายคลึงกันทางความหมาย
- คลิกความคล้ายคลึงกัน
ครอบคลุมหัวข้อ
คืออะไร –> รายการแอตทริบิวต์ –> ส่วนที่อุทิศให้กับแต่ละแอตทริบิวต์ –> แต่ละส่วนลิงก์ไปยังบทความที่อุทิศให้กับหัวข้อนั้นอย่างเต็มที่ –> ควรระบุผู้ชมและควรระบุคำจำกัดความสำหรับส่วนย่อย –> สิ่งที่ควรพิจารณา ? –> มีประโยชน์อย่างไร? –> ประโยชน์ของตัวดัดแปลง –> ___ คืออะไร –> ใช้ทำอะไร? –> วิธีการได้รับ –> วิธีการทำ –> ใครสามารถทำได้ –> เชื่อมโยงกลับไปที่หมวดหมู่ทั้งหมด

Google มีเครื่องมือที่ให้คะแนนความโดดเด่น (คล้ายกับที่เราใช้คำว่า "ความแข็งแกร่ง" หรือ "ความมั่นใจ") ซึ่งจะบอกคุณว่า Google มองเนื้อหาอย่างไร

ตัวอย่างข้างต้นมาจากบทความ Search Engine Land เกี่ยวกับเอนทิตีจากปี 2018
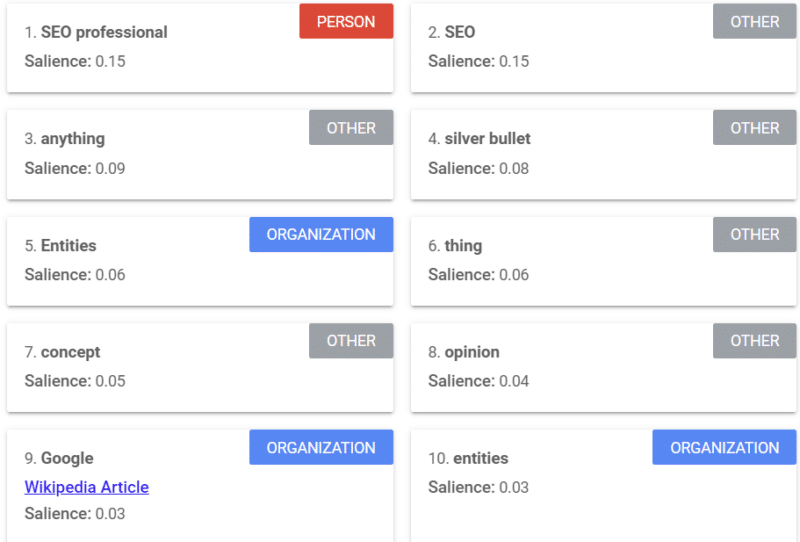
คุณสามารถดูบุคคล อื่นๆ และองค์กรได้จากตัวอย่าง เครื่องมือนี้เป็น Natural Language API ของ Google Cloud
ทุกคำ ประโยค และย่อหน้ามีความสำคัญเมื่อพูดถึงเอนทิตี วิธีจัดระเบียบความคิดของคุณสามารถเปลี่ยนความเข้าใจของ Google เกี่ยวกับเนื้อหาของคุณได้
คุณอาจรวมคำหลักเกี่ยวกับ SEO แต่ Google เข้าใจคำหลักนั้นในแบบที่คุณต้องการให้เข้าใจหรือไม่
ลองวางย่อหน้าหนึ่งหรือสองย่อหน้าลงในเครื่องมือและจัดระเบียบใหม่และปรับเปลี่ยนตัวอย่างเพื่อดูว่าจะเพิ่มหรือลดความเด่นอย่างไร
แบบฝึกหัดนี้เรียกว่า "การแก้ความกำกวม" มีความสำคัญอย่างมากสำหรับเอนทิตี ภาษามีความกำกวม ดังนั้นเราต้องทำให้คำของเรากำกวมน้อยลงสำหรับ Google
วิธีการแก้ความกำกวมสมัยใหม่พิจารณาหลักฐานสามประเภท:
ลำดับความสำคัญของเอนทิตีและการกล่าวถึง
ความคล้ายคลึงกันทางบริบทระหว่างข้อความที่ล้อมรอบการกล่าวถึงและเอนทิตีของผู้สมัคร และความสอดคล้องกันระหว่างการตัดสินใจที่เชื่อมโยงเอนทิตีทั้งหมดในเอกสาร
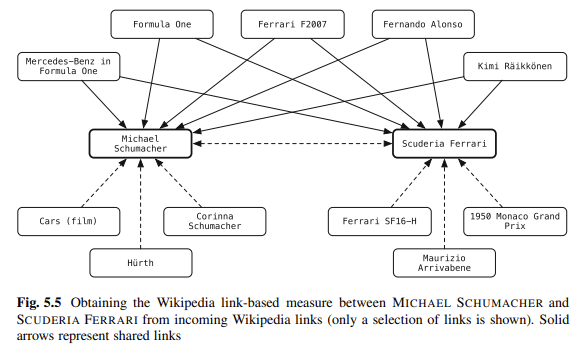
Schema เป็นหนึ่งในวิธีที่ฉันชอบในการทำให้เนื้อหากระจ่าง คุณกำลังเชื่อมโยงเอนทิตีในบล็อกของคุณกับคลังความรู้ Balog พูดว่า:
“[L] การลงสีเอนทิตีในข้อความที่ไม่มีโครงสร้างไปยังที่เก็บข้อมูลความรู้ที่มีโครงสร้างสามารถให้อำนาจแก่ผู้ใช้อย่างมากในกิจกรรมการบริโภคข้อมูลของพวกเขา”
ตัวอย่างเช่น ผู้อ่านเอกสารสามารถรับข้อมูลเชิงบริบทหรือพื้นหลังได้ด้วยการคลิกเพียงครั้งเดียว และพวกเขาสามารถเข้าถึงเอนทิตีที่เกี่ยวข้องได้อย่างง่ายดาย
นอกจากนี้ยังสามารถใช้คำอธิบายประกอบเอนทิตีในการประมวลผลดาวน์สตรีมเพื่อปรับปรุงประสิทธิภาพการดึงข้อมูลหรือเพื่ออำนวยความสะดวกในการโต้ตอบของผู้ใช้กับผลการค้นหาได้ดียิ่งขึ้น
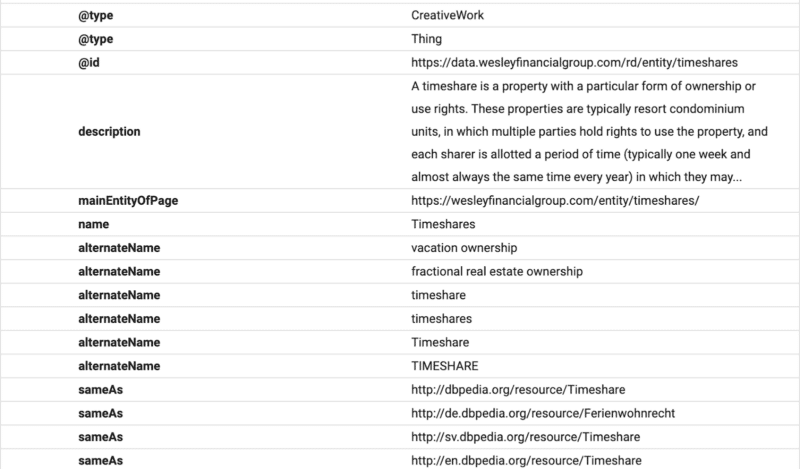
ที่นี่ คุณจะเห็นว่าเนื้อหาคำถามที่พบบ่อยมีโครงสร้างสำหรับ Google โดยใช้สคีมาคำถามที่พบบ่อย
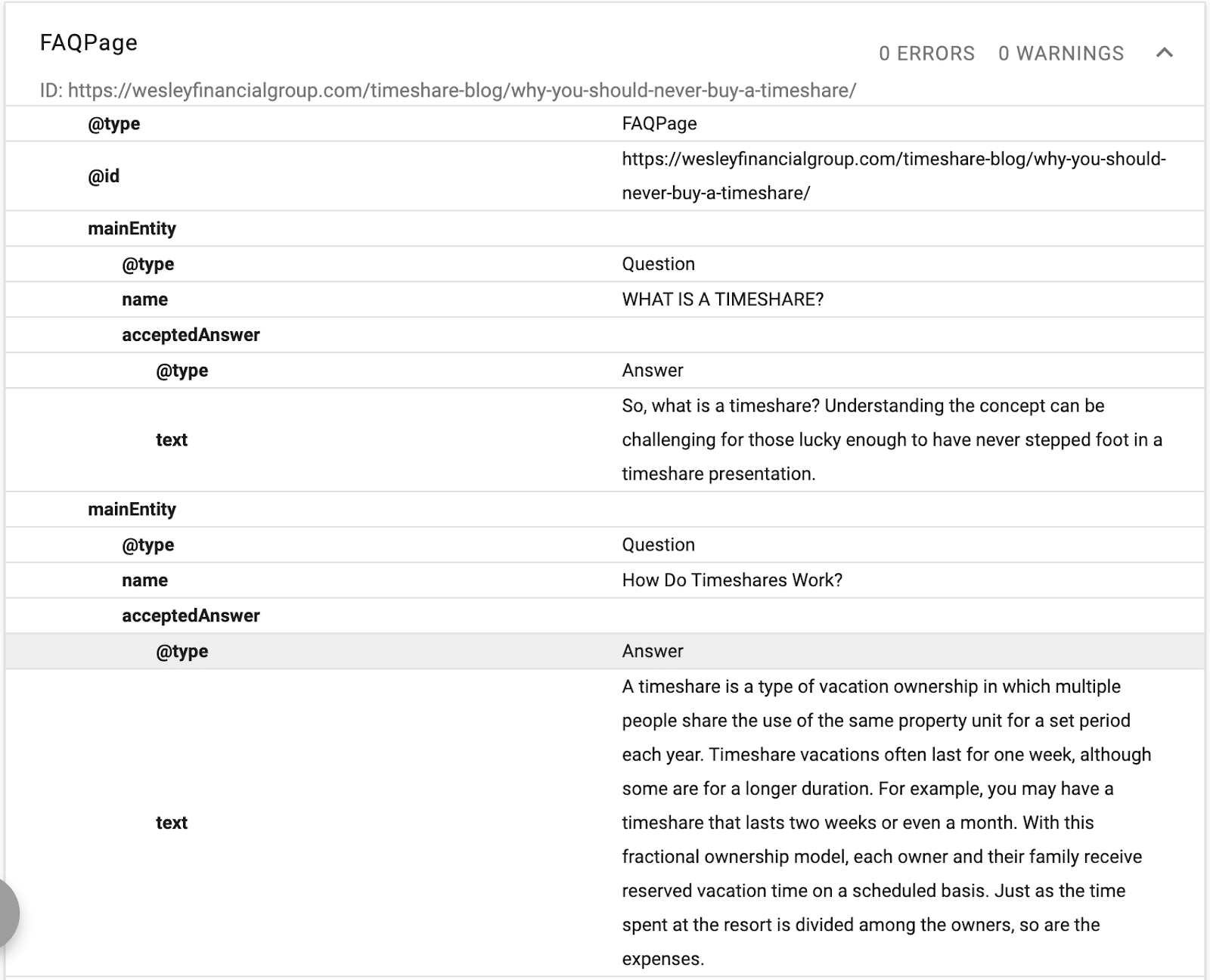
ในตัวอย่างนี้ คุณสามารถดูสคีมาให้คำอธิบายข้อความ ID และการประกาศเอนทิตีหลักของเพจ
(โปรดจำไว้ว่า Google ต้องการเข้าใจลำดับชั้นของเนื้อหา ซึ่งเป็นเหตุผลว่าทำไม H1–H6 จึงมีความสำคัญ)
คุณจะเห็นชื่ออื่นและเหมือนกับการประกาศ ตอนนี้ เมื่อ Google อ่านเนื้อหา ก็จะทราบว่าฐานข้อมูลที่มีโครงสร้างใดที่จะเชื่อมโยงกับข้อความ และจะมีคำที่มีความหมายเหมือนกันและเวอร์ชันทางเลือกที่เชื่อมโยงกับเอนทิตี
เมื่อคุณปรับให้เหมาะสมด้วยสคีมา คุณจะปรับให้เหมาะสมสำหรับ NER (การจดจำชื่อเอนทิตี) หรือที่เรียกว่าการระบุเอนทิตี การดึงเอนทิตี และการแยกเอนทิตี
แนวคิดคือการมีส่วนร่วมใน Named Entity Disambiguation > Wikification > Entity Linking
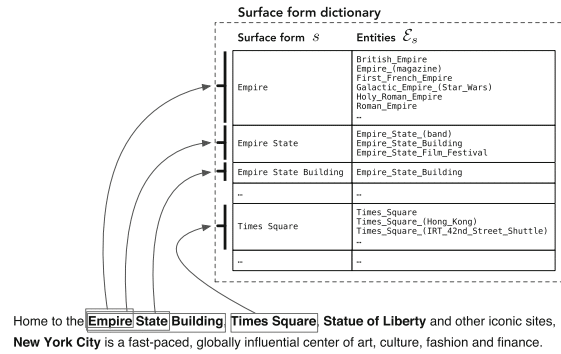
“การถือกำเนิดของวิกิพีเดียได้อำนวยความสะดวกในการรับรู้และแก้ความกำกวมของเอนทิตีขนาดใหญ่โดยจัดทำแค็ตตาล็อกของเอนทิตีที่ครอบคลุมพร้อมกับทรัพยากรอันล้ำค่าอื่นๆ (โดยเฉพาะ ไฮเปอร์ลิงก์ หมวดหมู่ และหน้าเปลี่ยนทิศทางและแก้ความกำกวม”
– การค้นหาที่มุ่งเน้นเอนทิตี
วิธี ไปไกลกว่าคำแนะนำเครื่องมือ SEO
SEO ส่วนใหญ่ใช้เครื่องมือในหน้าเพื่อเพิ่มประสิทธิภาพเนื้อหาของตน เครื่องมือทุกตัวมีข้อจำกัดในการระบุโอกาสของเนื้อหาที่ไม่ซ้ำใครและคำแนะนำเชิงลึกของเนื้อหา
ส่วนใหญ่แล้ว เครื่องมือในหน้าเป็นเพียงการรวมผลลัพธ์ SERP อันดับต้น ๆ และสร้างค่าเฉลี่ยเพื่อให้คุณเลียนแบบ
SEO ต้องจำไว้ว่า Google ไม่ได้ค้นหาข้อมูลที่ทำซ้ำซ้ำ คุณสามารถคัดลอกสิ่งที่คนอื่นกำลังทำอยู่ได้ แต่ข้อมูลเฉพาะคือกุญแจสู่การเป็นไซต์เริ่มต้น/ไซต์ผู้มีอำนาจ
ต่อไปนี้เป็นคำอธิบายอย่างง่ายเกี่ยวกับวิธีที่ Google จัดการกับเนื้อหาใหม่:
เมื่อพบเอกสารที่กล่าวถึงเอนทิตีที่กำหนด เอกสารนั้นอาจถูกตรวจสอบเพื่อค้นหาข้อเท็จจริงใหม่ ซึ่งรายการฐานความรู้ของเอนทิตีนั้นอาจได้รับการปรับปรุง
Balog เขียน:
“เราต้องการช่วยให้บรรณาธิการติดตามการเปลี่ยนแปลงได้โดยการระบุเนื้อหาโดยอัตโนมัติ (บทความข่าว บล็อกโพสต์ ฯลฯ) ที่อาจบ่งบอกถึงการปรับเปลี่ยนรายการ KB ของเอนทิตีบางชุดที่น่าสนใจ (เช่น เอนทิตีที่บรรณาธิการกำหนดคือ รับผิดชอบในการ)."
ใครก็ตามที่ปรับปรุงฐานความรู้ การจดจำเอนทิตี และความสามารถในการรวบรวมข้อมูลจะได้รับความรักจาก Google
การเปลี่ยนแปลงที่เกิดขึ้นในคลังความรู้สามารถตรวจสอบย้อนกลับไปยังเอกสารในฐานะต้นฉบับได้
หากคุณให้เนื้อหาที่ครอบคลุมหัวข้อและเพิ่มระดับความลึกที่หายากหรือใหม่ Google สามารถระบุได้ว่าเอกสารของคุณเพิ่มข้อมูลที่ไม่ซ้ำนั้นหรือไม่
ในที่สุด ข้อมูลใหม่นี้คงอยู่ในช่วงเวลาหนึ่งอาจทำให้เว็บไซต์ของคุณกลายเป็นผู้มีอำนาจ
นี่ไม่ใช่การมอบอำนาจตามการจัดอันดับโดเมน แต่เป็นการครอบคลุมเฉพาะเรื่อง ซึ่งฉันเชื่อว่ามีค่ามากกว่ามาก
ด้วยแนวทางเอนทิตีของ SEO คุณจะไม่จำกัดการกำหนดเป้าหมายคำหลักด้วยปริมาณการค้นหา
สิ่งที่คุณต้องทำคือตรวจสอบคำศัพท์หลัก (“คันเบ็ดตกปลา” เป็นต้น) จากนั้นคุณสามารถมุ่งเน้นไปที่การกำหนดเป้าหมายรูปแบบความตั้งใจในการค้นหาตามความคิดที่ดีของมนุษย์
เราเริ่มต้นด้วยวิกิพีเดีย สำหรับตัวอย่างการตกปลาบิน เราจะเห็นว่าอย่างน้อยที่สุด แนวคิดต่อไปนี้ควรครอบคลุมบนเว็บไซต์ตกปลา:
- พันธุ์ปลา ประวัติความเป็นมา กำเนิด การพัฒนา การปรับปรุงเทคโนโลยี การขยายตัว วิธีการตกปลาแบบฟลายฟิชชิ่ง การทอดแห การหล่อแบบสเปย์ การตกปลาแบบฟลายฟิชชิ่ง เทคนิคการตกปลาแบบฟลายฟิช การตกปลาในน้ำเย็น การตกปลาแบบแห้งฟลายเทราต์ ตกปลาเทราต์ เล่นเทราต์ ปล่อยเทราต์ ตกปลาน้ำเค็ม รอก ตีแมลงวัน และเงื่อน
หัวข้อข้างต้นมาจากหน้าวิกิพีเดียการตกปลาบิน แม้ว่าหน้านี้จะแสดงภาพรวมที่ดีของหัวข้อ ฉันต้องการเพิ่มแนวคิดหัวข้อเพิ่มเติมที่มาจากหัวข้อที่เกี่ยวข้องกันในเชิงความหมาย
สำหรับหัวข้อ “ปลา” เราสามารถเพิ่มหัวข้อเพิ่มเติมได้หลายหัวข้อ รวมถึงนิรุกติศาสตร์ วิวัฒนาการ กายวิภาคศาสตร์และสรีรวิทยา การสื่อสารของปลา โรคของปลา การอนุรักษ์ และความสำคัญต่อมนุษย์
มีใครเชื่อมโยงกายวิภาคของปลาเทราต์กับประสิทธิภาพของเทคนิคการตกปลาบางอย่างหรือไม่?
มีเว็บไซต์ตกปลาเดียวที่ครอบคลุมพันธุ์ปลาทั้งหมดในขณะที่เชื่อมโยงประเภทของเทคนิคการตกปลา คันเบ็ด และเหยื่อเข้ากับปลาแต่ละตัวหรือไม่
ถึงตอนนี้ คุณน่าจะเห็นแล้วว่าการขยายหัวข้อจะเติบโตได้อย่างไร โปรดระลึกไว้เสมอเมื่อวางแผนแคมเปญเนื้อหา
อย่าเพิ่งทำใหม่ เพิ่มมูลค่า. เป็นเอกลักษณ์ ใช้อัลกอริทึมที่กล่าวถึงในบทความนี้เป็นแนวทางของคุณ
บทสรุป
บทความนี้เป็นส่วนหนึ่งของชุดบทความที่เน้นเรื่องเอนทิตี ในบทความถัดไป ฉันจะเจาะลึกลงไปในความพยายามในการเพิ่มประสิทธิภาพรอบเอนทิตีและเครื่องมือที่มุ่งเน้นเอนทิตีในตลาด
ฉันอยากจะจบบทความนี้ด้วยการพูดถึงคนสองคนที่อธิบายแนวคิดมากมายเหล่านี้ให้ฉันฟัง
Bill Slawski จาก SEO by the Sea และ Koray Tugbert จาก Holistic SEO ในขณะที่ Slawski ไม่ได้อยู่กับเราอีกต่อไป การมีส่วนร่วมของเขายังคงส่งผลต่ออุตสาหกรรม SEO อย่างต่อเนื่อง
ฉันพึ่งพาแหล่งข้อมูลต่อไปนี้อย่างมากสำหรับเนื้อหาบทความ เนื่องจากแหล่งข้อมูลเหล่านี้เป็นแหล่งข้อมูลที่ดีที่สุดที่มีอยู่ในหัวข้อ:
- ลำดับชั้นของเอนทิตีแบบขยาย โดย Satoshi Ketine, Kiyoshi Sudo และ Chikashi Nobata
- การค้นหาที่มุ่งเน้นเอนทิตีโดย Krisztian Balog , ซีรี่ส์การดึงข้อมูล (INRE, เล่มที่ 39)
- การเขียนข้อความค้นหาใหม่ด้วยการตรวจจับเอน ทิตี สิทธิบัตรของ Google
- การปรับแต่งคำค้นหา สิทธิบัตรของ Google
- การเชื่อมโยงเอนทิตีกับคำค้นหา สิทธิบัตรของ Google
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่