
Apache Spark สามารถให้ปีกแก่การวิเคราะห์สายการบินได้อย่างไร
เผยแพร่แล้ว: 2015-10-30อุตสาหกรรมสายการบินทั่วโลกยังคงเติบโตอย่างรวดเร็ว แต่ยังไม่เห็นผลกำไรที่สม่ำเสมอและแข็งแกร่ง จากข้อมูลของสมาคมขนส่งทางอากาศระหว่างประเทศ (IATA) อุตสาหกรรมนี้มีรายได้เพิ่มขึ้นสองเท่าในช่วงทศวรรษที่ผ่านมา จาก 369 พันล้านดอลลาร์ในปี 2548 เป็น 727 พันล้านดอลลาร์ในปี 2558 ที่คาดการณ์ไว้

ในภาคการบินเชิงพาณิชย์ ผู้เล่นทุกคนในห่วงโซ่คุณค่า ไม่ว่าจะเป็นสนามบิน ผู้ผลิตเครื่องบิน ผู้ผลิตเครื่องยนต์ไอพ่น ตัวแทนท่องเที่ยว และบริษัทบริการต่างได้รับผลกำไรที่เป็นระเบียบเรียบร้อย
ผู้เล่นทั้งหมดเหล่านี้สร้างข้อมูลปริมาณมากเป็นรายบุคคลอันเนื่องมาจากการเปลี่ยนแปลงของธุรกรรมเที่ยวบินที่สูงขึ้น การระบุและจับความต้องการเป็นกุญแจสำคัญในที่นี้ ซึ่งเปิดโอกาสให้สายการบินต่างๆ สามารถสร้างความแตกต่างได้มากขึ้น ดังนั้น อุตสาหกรรมการบินสามารถใช้ข้อมูลเชิงลึกขนาดใหญ่เพื่อเพิ่มยอดขายและปรับปรุงอัตรากำไร
บิ๊กดาต้าเป็นคำศัพท์สำหรับการรวบรวมชุดข้อมูลที่มีขนาดใหญ่และซับซ้อนจนระบบประมวลผลข้อมูลแบบดั้งเดิมหรือเครื่องมือ DBMS ในมือไม่สามารถจัดการการประมวลผลได้
Apache Spark เป็นเฟรมเวิร์กการประมวลผลคลัสเตอร์แบบโอเพนซอร์สแบบกระจายที่ออกแบบมาเฉพาะสำหรับการสืบค้นแบบโต้ตอบและอัลกอริธึมแบบวนซ้ำ
นามธรรม Spark DataFrame เป็นวัตถุข้อมูลแบบตารางที่คล้ายกับ dataframe ดั้งเดิมของ R หรือแพ็คเกจ Pythons pandas แต่เก็บไว้ในสภาพแวดล้อมคลัสเตอร์
จากการสำรวจล่าสุดของ Fortunes พบว่า Apache Spark เป็นเทคโนโลยีที่ได้รับความนิยมมากที่สุดในปี 2015
Cloudera ผู้ค้า Hadoop รายใหญ่ที่สุดก็บอกลา Hadoops MapReduce และ Hello to Spark
สิ่งที่ทำให้ Spark ได้เปรียบเหนือ Hadoop คือ speed Spark จัดการการทำงานส่วนใหญ่ ใน หน่วยความจำ โดยคัดลอกจากที่จัดเก็บข้อมูลทางกายภาพแบบกระจายไปยังหน่วยความจำ RAM แบบลอจิคัลที่เร็วกว่ามาก ซึ่งจะช่วยลดระยะเวลาที่ใช้ในการเขียนและอ่านจากฮาร์ดไดรฟ์แบบกลไกที่ช้าและเป็นก้อนที่ต้องทำภายใต้ระบบ Hadoops MapReduce
นอกจากนี้ Spark ยังรวมเครื่องมือต่างๆ (การประมวลผลแบบเรียลไทม์ การเรียนรู้ของเครื่อง และ SQL เชิงโต้ตอบ) ที่ออกแบบมาอย่างดีสำหรับการขับเคลื่อนวัตถุประสงค์ทางธุรกิจ เช่น การวิเคราะห์ข้อมูลแบบเรียลไทม์โดยการรวมข้อมูลในอดีตจากอุปกรณ์ที่เชื่อมต่อ หรือที่เรียกว่า อินเทอร์เน็ตของสิ่งต่างๆ
วันนี้ มารวบรวมข้อมูลเชิงลึกเกี่ยวกับข้อมูลสนามบินตัวอย่างโดยใช้ Apache Spark
ในบล็อกที่แล้ว เราเห็นวิธีจัดการข้อมูลที่มีโครงสร้างและกึ่งโครงสร้างใน Spark โดยใช้ Dataframes API ใหม่ และยังครอบคลุมถึงวิธีการประมวลผลข้อมูล JSON อย่างมีประสิทธิภาพอีกด้วย
ในบล็อกนี้ เราจะเข้าใจวิธีการ สืบค้นข้อมูลใน DataFrames โดยใช้ SQL เช่นเดียวกับการ บันทึกเอาต์พุตไปยังระบบไฟล์ในรูปแบบ CSV
การใช้ไลบรารีแยกวิเคราะห์ Databricks CSV
สำหรับสิ่งนี้ ฉันจะใช้ไลบรารีการแยกวิเคราะห์ CSV ที่จัดทำโดย Databricks ซึ่งเป็นบริษัทที่ก่อตั้งโดยผู้สร้าง Apache Spark และดูแลจัดการ Spark Development และการแจกจ่ายในปัจจุบัน
ชุมชน Spark ประกอบด้วยผู้มีส่วนร่วมประมาณ 600 รายที่ทำให้โครงการนี้เป็นโครงการที่มีการใช้งานมากที่สุดใน Apache Software Foundation ซึ่งเป็นองค์กรหลักสำหรับซอฟต์แวร์โอเพ่นซอร์สในแง่ของจำนวนผู้ร่วมให้ข้อมูล
ไลบรารี Spark-csv ช่วยให้เราแยกวิเคราะห์และสืบค้นข้อมูล csv ใน spark เราสามารถใช้ไลบรารีนี้เพื่ออ่านและเขียนข้อมูล csv เข้าและออกจากระบบไฟล์ที่เข้ากันได้กับ Hadoop
กำลังโหลดข้อมูลลงใน Spark DataFrames
ให้โหลดไฟล์อินพุตของเราลงใน Spark DataFrames โดยใช้ไลบรารีการแยกวิเคราะห์ spark-csv จาก Databricks
คุณสามารถใช้ไลบรารีนี้ที่ Spark shell โดยระบุ –packages com.databricks: spark-csv_2.10:1.0.3
ในขณะที่เริ่มเชลล์ดังแสดงด้านล่าง:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
จำไว้ว่าคุณควรเชื่อมต่อกับอินเทอร์เน็ตเพราะแพ็คเกจ spark-csv จะถูกดาวน์โหลดโดยอัตโนมัติเมื่อคุณให้คำสั่งนี้ ฉันใช้เวอร์ชัน spark 1.4.0 อยู่
ให้สร้าง sqlContext ด้วยวัตถุ SparkContext(sc) ที่สร้างไว้แล้ว
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
ตอนนี้ให้โหลดข้อมูล csv ของเราจากไฟล์ airports.csv (airport csv github) ซึ่งมีสคีมาดังต่อไปนี้
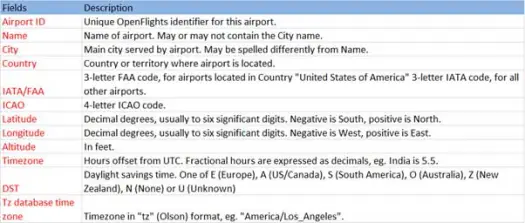
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))การดำเนินการโหลดจะแยกวิเคราะห์ไฟล์ *.csv โดยใช้ไลบรารี Databricks spark-csv และส่งคืนดาต้าเฟรมที่มีชื่อคอลัมน์เหมือนกับในบรรทัดส่วนหัวแรกในไฟล์
ต่อไปนี้เป็นพารามิเตอร์ที่ส่งผ่านไปยังวิธีการโหลด
- ที่มา : "com.databricks.spark.csv" บอก spark ว่าเราต้องการโหลดเป็นไฟล์ csv
- ตัวเลือก:
- เส้นทาง - เส้นทางของไฟล์ซึ่งอยู่
- ส่วนหัว : "ส่วนหัว" -> "จริง" บอกให้ spark จับคู่บรรทัดแรกของไฟล์กับชื่อคอลัมน์สำหรับ dataframe ที่เป็นผลลัพธ์
มาดูกันว่าสคีมาของ Dataframe ของเราคืออะไร
ตรวจสอบข้อมูลตัวอย่างใน dataframe ของเรา
scala> airportDF.show

การสืบค้นข้อมูล CSV โดยใช้ตารางชั่วคราว:
ในการดำเนินการค้นหากับตาราง เราเรียกเมธอด sql() บน SQLContext

เราได้สร้างสนามบิน DataFrame และโหลดข้อมูล CSV เพื่อสืบค้นข้อมูล DF นี้ เราต้องลงทะเบียนเป็นตารางชั่วคราวที่เรียกว่าสนามบิน
>
scala> airportDF.registerTempTable("airports")
มาดูกันว่ามีสนามบินกี่แห่งในภาคตะวันออกเฉียงใต้ในชุดข้อมูลของเรา
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
เราสามารถทำการรวมในการสืบค้น sql บน Spark
เราจะค้นหาว่าแต่ละประเทศมีสนามบินที่แตกต่างกันกี่เมือง
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
ระดับความสูงเฉลี่ย (เป็นฟุต) ของสนามบินในแต่ละประเทศคือเท่าใด
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
ทีนี้มาดูว่าในแต่ละเขตเวลามีสนามบินกี่แห่งที่เปิดดำเนินการอยู่บ้าง?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
นอกจากนี้เรายังสามารถคำนวณละติจูดและลองจิจูดเฉลี่ยสำหรับสนามบินเหล่านี้ในแต่ละประเทศ
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
มานับกันว่ามี DST ต่างกันกี่ตัว
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
บันทึกข้อมูลในรูปแบบ CSV
จนถึงตอนนี้เราโหลดและสอบถามข้อมูล csv ตอนนี้เราจะมาดูวิธีการบันทึกผลลัพธ์ในรูปแบบ CSV กลับไปที่ระบบไฟล์
สมมติว่าเราต้องการส่งรายงานให้กับลูกค้าเกี่ยวกับสนามบินทั้งหมดในภาคตะวันตกเฉียงเหนือของทุกประเทศ
มาคำนวณกันก่อน
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
และบันทึกเป็นไฟล์ CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
ต่อไปนี้เป็นพารามิเตอร์ที่ส่งผ่านไปยังวิธีการบันทึก
- ที่มา : เหมือนกับวิธีการ โหลด com.databricks.spark.csv ซึ่งบอกให้ spark บันทึกข้อมูลเป็น csv
- SaveMode : อนุญาตให้ผู้ใช้ระบุล่วงหน้าว่าต้องทำอะไรหากพาธเอาท์พุตที่ระบุมีอยู่แล้ว เพื่อไม่ให้ข้อมูลที่มีอยู่สูญหาย/ถูกเขียนทับโดยไม่ได้ตั้งใจ คุณสามารถโยนข้อผิดพลาด ต่อท้ายหรือเขียนทับได้ ที่นี่ เราได้แสดงข้อผิดพลาด ErrorIfExists เนื่องจากเราไม่ต้องการเขียนทับไฟล์ที่มีอยู่
- ตัวเลือก : ตัวเลือกเหล่านี้เหมือนกับที่เราส่งผ่านไปยังวิธีการ โหลด ตัวเลือก:
- เส้นทาง - เส้นทางของไฟล์ที่ควรเก็บไว้
- ส่วนหัว : "ส่วนหัว" -> "จริง" บอกให้ spark จับคู่ชื่อคอลัมน์ของ dataframe กับบรรทัดแรกของไฟล์ผลลัพธ์ที่ได้
การแปลงรูปแบบข้อมูลอื่นเป็น CSV
นอกจากนี้เรายังสามารถแปลงรูปแบบข้อมูลอื่น ๆ เช่น JSON, ปาร์เก้, ข้อความเป็น CSV โดยใช้ไลบรารีนี้
ในบล็อกที่แล้ว เราได้สร้างข้อมูล json คุณสามารถหาได้ใน github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
ให้บันทึกเป็น CSV
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
บทสรุป:
ในโพสต์นี้ เราได้รวบรวมข้อมูลเชิงลึกเกี่ยวกับข้อมูลสนามบินโดยใช้แบบสอบถามเชิงโต้ตอบ SparkSQL
และสำรวจ csv parsing library จาก Spark
บล็อกถัดไป เราจะสำรวจองค์ประกอบที่สำคัญมากของ Spark เช่น Spark Streaming
Spark Streaming ช่วยให้ผู้ใช้สามารถรวบรวมข้อมูลเรียลไทม์ลงใน Spark และประมวลผลตามที่เกิดขึ้นและให้ผลลัพธ์ได้ทันที