
วิธีใช้เอนทิตีของ Google และ GPT-4 เพื่อสร้างโครงร่างบทความ
เผยแพร่แล้ว: 2023-06-06ในบทความนี้ คุณจะได้เรียนรู้วิธีใช้การคัดลอกบางส่วนและกราฟความรู้ของ Google เพื่อทำวิศวกรรมพร้อมท์อัตโนมัติที่สร้างโครงร่างและบทสรุปสำหรับบทความ ซึ่งหากเขียนได้ดี จะมีองค์ประกอบสำคัญมากมายในการจัดอันดับที่ดี
ที่รากฐานของสิ่งต่าง ๆ เรากำลังบอกให้ GPT-4 สร้างโครงร่างบทความตามคำหลักและเอนทิตีอันดับต้น ๆ ที่พวกเขาพบในหน้าอันดับดีที่คุณเลือก
เอนทิตีจะถูกจัดลำดับตามคะแนนความสามารถของพวกเขา
“ทำไมคะแนนความเด่น” คุณอาจถาม
Google อธิบายความโดดเด่นในเอกสาร API เป็น:
“คะแนนความโดดเด่นสำหรับเอนทิตีให้ข้อมูลเกี่ยวกับความสำคัญหรือศูนย์กลางของเอนทิตีนั้นในข้อความเอกสารทั้งหมด คะแนนที่เข้าใกล้ 0 นั้นมีความสำคัญน้อยกว่า ในขณะที่คะแนนที่เข้าใกล้ 1.0 นั้นมีความสำคัญอย่างมาก”
ดูเหมือนจะเป็นตัวชี้วัดที่ดีทีเดียวที่จะใช้เพื่อกำหนดเอนทิตีที่ควรมีอยู่ในเนื้อหาที่คุณอาจต้องการเขียนใช่ไหม
เริ่มต้นใช้งาน
มีสองวิธีที่คุณสามารถดำเนินการได้:
- ใช้เวลาประมาณ 5 นาที (อาจถึง 10 นาที หากคุณต้องการตั้งค่าคอมพิวเตอร์) และเรียกใช้สคริปต์จากเครื่องของคุณ หรือ...
- ข้ามไปที่ Colab ที่ฉันสร้างและเริ่มเล่นทันที
ฉันเป็นส่วนหนึ่งของกลุ่มแรก แต่ฉันก็ข้ามไปที่ Colab หนึ่งหรือสองครั้งในหนึ่งวัน 😀
สมมติว่าคุณยังอยู่ที่นี่และต้องการตั้งค่านี้ในเครื่องของคุณเอง แต่ยังไม่ได้ติดตั้ง Python หรือ IDE (Integrated Development Environment) ฉันจะแนะนำให้คุณอ่านการตั้งค่าเครื่องของคุณก่อนใช้งาน โน๊ตบุ๊ค Jupyter ไม่ควรเกิน 5 นาที
เอาล่ะ ได้เวลาไปกันแล้ว!
การใช้เอนทิตีของ Google และ GPT-4 เพื่อสร้างโครงร่างบทความ
เพื่อให้ทำตามได้ง่าย ฉันจะจัดรูปแบบคำแนะนำดังนี้:
- ขั้นตอน : คำอธิบายสั้น ๆ ของขั้นตอนที่เรากำลังทำอยู่
- Code : รหัสสำหรับทำตามขั้นตอนนั้น
- คำอธิบาย : คำอธิบายสั้น ๆ เกี่ยวกับสิ่งที่รหัสกำลังทำอยู่
ขั้นตอนที่ 1: บอกฉันว่าคุณต้องการอะไร
ก่อนที่เราจะดำดิ่งสู่การสร้างโครงร่าง เราต้องกำหนดสิ่งที่เราต้องการ
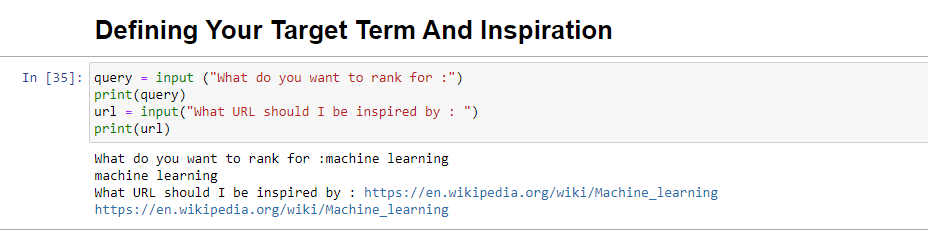
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)เมื่อเรียกใช้ บล็อกนี้จะแจ้งให้ผู้ใช้ (อาจเป็นคุณ) ป้อนข้อความค้นหาที่คุณต้องการให้บทความจัดอันดับ/เกี่ยวข้อง รวมทั้งให้ตำแหน่งสำหรับใส่ URL ของบทความที่คุณต้องการ ชิ้นที่จะได้รับแรงบันดาลใจจาก
ฉันขอแนะนำบทความที่มีอันดับดี อยู่ในรูปแบบที่เหมาะกับไซต์ของคุณ และคุณคิดว่าสมควรได้รับการจัดอันดับโดยพิจารณาจากคุณค่าของบทความเพียงอย่างเดียว ไม่ใช่แค่จุดแข็งของไซต์เท่านั้น
เมื่อเรียกใช้จะมีลักษณะดังนี้:
ขั้นตอนที่ 2: การติดตั้งไลบรารีที่จำเป็น
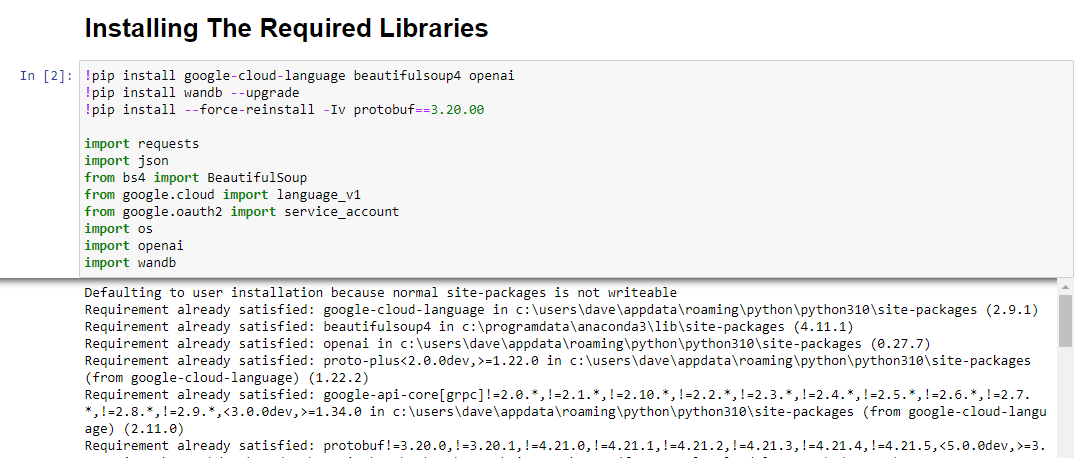
ต่อไป เราต้องติดตั้งไลบรารีทั้งหมดที่เราจะใช้เพื่อทำให้เวทมนตร์เกิดขึ้น
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbเรากำลังติดตั้งไลบรารีต่อไปนี้:
- คำขอ : ไลบรารีนี้อนุญาตให้สร้างคำขอ HTTP เพื่อดึงเนื้อหาจากเว็บไซต์หรือ API ของเว็บ
- JSON : มีฟังก์ชันในการทำงานกับข้อมูล JSON รวมถึงการแยกวิเคราะห์สตริง JSON ลงในออบเจกต์ Python และการทำให้ออบเจกต์ Python เป็นอนุกรมเป็นสตริง JSON
- BeautifulSoup : ไลบรารีนี้ใช้สำหรับการขูดเว็บ ช่วยในการแยกวิเคราะห์และนำทางเอกสาร HTML หรือ XML และดึงข้อมูลที่เกี่ยวข้องจากเอกสารเหล่านั้น
- Google.cloud.language_v1 : เป็นไลบรารีจาก Google Cloud ที่ให้ความสามารถในการประมวลผลภาษาธรรมชาติ ซึ่งช่วยให้สามารถทำงานต่างๆ ได้ เช่น การวิเคราะห์ความรู้สึก การจดจำเอนทิตี และการวิเคราะห์ไวยากรณ์บนข้อมูลข้อความ
- Google.oauth2.service_account : ไลบรารีนี้เป็นส่วนหนึ่งของแพ็คเกจ Google OAuth2 Python ให้การสนับสนุนการตรวจสอบสิทธิ์ด้วย Google APIs โดยใช้บัญชีบริการ ซึ่งเป็นวิธีการให้สิทธิ์เข้าถึงทรัพยากรของโครงการ Google Cloud แบบจำกัด
- OS : ไลบรารีนี้มีวิธีการโต้ตอบกับระบบปฏิบัติการ อนุญาตให้เข้าถึงฟังก์ชันต่างๆ เช่น การทำงานของไฟล์ ตัวแปรสภาพแวดล้อม และการจัดการกระบวนการ
- OpenAI : ไลบรารีนี้เป็นแพ็คเกจ OpenAI Python มีอินเทอร์เฟซเพื่อโต้ตอบกับโมเดลภาษาของ OpenAI รวมถึง GPT-4 (และ 3) ช่วยให้นักพัฒนาสร้างข้อความ ดำเนินการเติมข้อความ และอื่นๆ อีกมากมาย
- Pandas : เป็นห้องสมุดที่ทรงพลังสำหรับการจัดการและวิเคราะห์ข้อมูล มีโครงสร้างข้อมูลและฟังก์ชันในการจัดการและวิเคราะห์ข้อมูลที่มีโครงสร้าง เช่น ตารางหรือไฟล์ CSV ได้อย่างมีประสิทธิภาพ
- WandB : ไลบรารีนี้ย่อมาจาก "น้ำหนักและอคติ" และเป็นเครื่องมือสำหรับการติดตามการทดลองและการแสดงภาพ ช่วยบันทึกและแสดงภาพเมตริก ไฮเปอร์พารามิเตอร์ และแง่มุมที่สำคัญอื่นๆ ของการทดสอบแมชชีนเลิร์นนิง
เมื่อเรียกใช้ดูเหมือนว่า:
รับจดหมายข่าวรายวันที่นักการตลาดไว้วางใจ
ดูข้อกำหนด
ขั้นตอนที่ 3: การรับรองความถูกต้อง
ฉันจะต้องหลบหน้าเราสักครู่เพื่อมุ่งหน้าและตรวจสอบสิทธิ์ของเราให้เข้าที่ เราจะต้องมีคีย์ OpenAI API และข้อมูลรับรองการค้นหากราฟความรู้ของ Google
การดำเนินการนี้จะใช้เวลาเพียงไม่กี่นาที
รับ OpenAI API ของคุณ
ในปัจจุบัน คุณอาจจำเป็นต้องเข้าร่วมในรายชื่อผู้รอ ฉันโชคดีที่เข้าถึง API ได้ตั้งแต่เนิ่นๆ ดังนั้นฉันจึงเขียนสิ่งนี้เพื่อช่วยให้คุณตั้งค่าได้ทันทีที่ได้รับ
รูปภาพการสมัครมาจาก GPT-3 และจะได้รับการอัปเดตสำหรับ GPT-4 เมื่อโฟลว์พร้อมใช้งานสำหรับทุกคน
ก่อนที่คุณจะสามารถใช้ GPT-4 ได้ คุณต้องมีคีย์ API เพื่อเข้าถึง
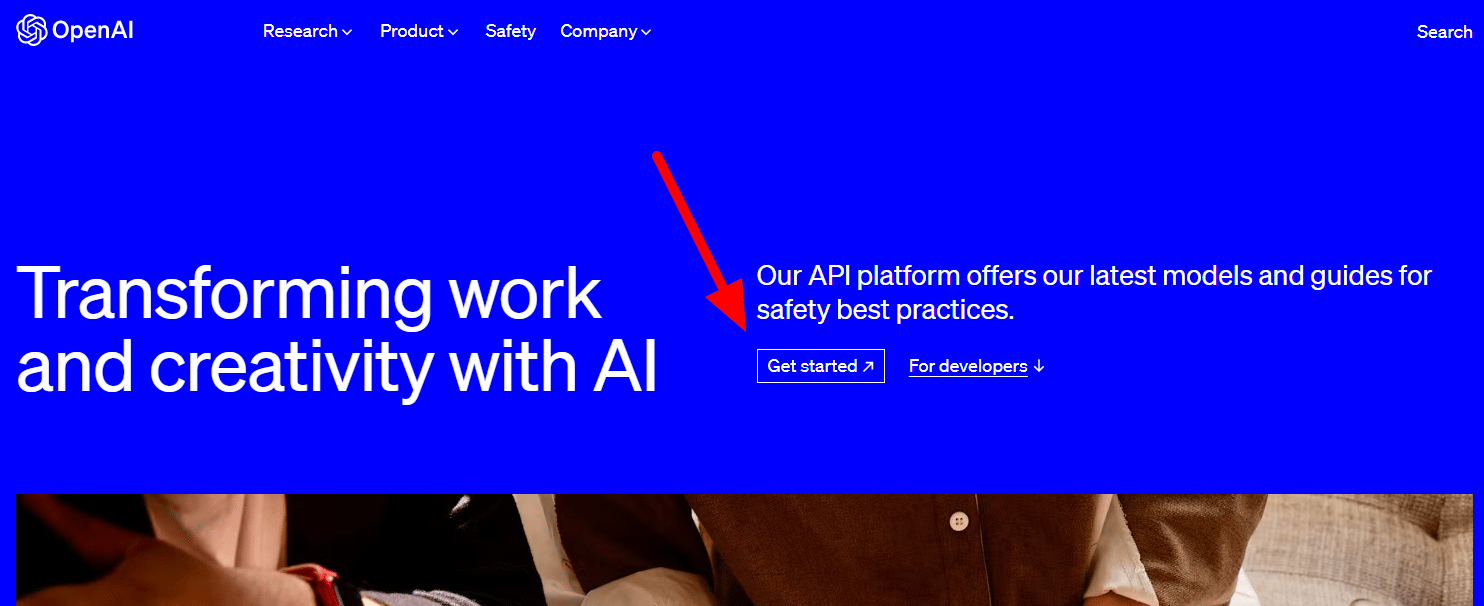
หากต้องการรับเพียงไปที่หน้าผลิตภัณฑ์ของ OpenAI แล้วคลิก เริ่มต้น
เลือกวิธีการสมัครของคุณ (ฉันเลือก Google) และดำเนินการผ่านขั้นตอนการยืนยัน คุณจะต้องเข้าถึงโทรศัพท์ที่สามารถรับข้อความได้สำหรับขั้นตอนนี้
เมื่อดำเนินการเสร็จแล้ว คุณจะสร้างคีย์ API เพื่อให้ OpenAI สามารถเชื่อมต่อสคริปต์ของคุณกับบัญชีของคุณได้
พวกเขาต้องรู้ว่าใครกำลังทำอะไรและตัดสินว่าควรเรียกเก็บเงินจากคุณสำหรับสิ่งที่คุณทำหรือไม่และเท่าไหร่
ราคา OpenAI
เมื่อลงชื่อสมัครใช้ คุณจะได้รับเครดิต $5 ซึ่งจะทำให้คุณได้รับเครดิตเพิ่มขึ้นอย่างน่าประหลาดใจหากคุณเพิ่งทดลอง
ในขณะที่เขียนนี้ การกำหนดราคาที่ผ่านมาคือ:

สร้างคีย์ OpenAI ของคุณ
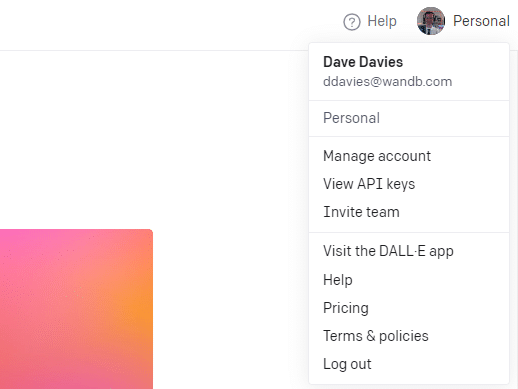
หากต้องการสร้างคีย์ ให้คลิกที่โปรไฟล์ของคุณที่ด้านบนขวา แล้วเลือก ดูคีย์ API
...จากนั้น คุณจะสร้างคีย์ของคุณ
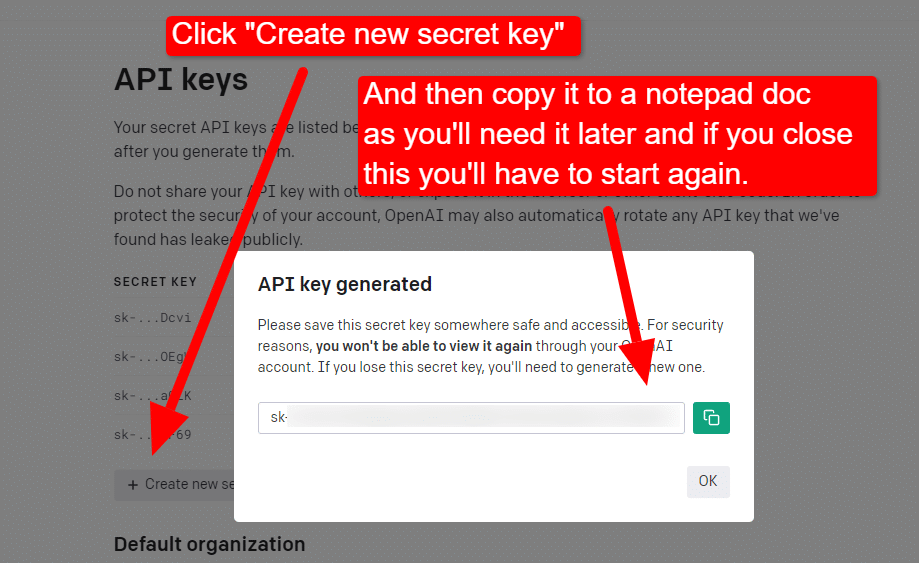
เมื่อคุณปิดไลท์บ็อกซ์แล้ว คุณจะไม่สามารถดูคีย์ของคุณได้และจะต้องสร้างคีย์ใหม่ ดังนั้นสำหรับโปรเจกต์นี้ เพียงคัดลอกไปยังเอกสาร Notepad เพื่อใช้งานในเร็วๆ นี้
หมายเหตุ: อย่าบันทึกคีย์ของคุณ (เอกสาร Notepad บนเดสก์ท็อปของคุณไม่มีความปลอดภัยสูง) เมื่อคุณใช้งานไปชั่วขณะแล้ว ให้ปิดเอกสาร Notepad โดยไม่บันทึก
รับการตรวจสอบสิทธิ์ Google Cloud ของคุณ
ก่อนอื่น คุณจะต้องลงชื่อเข้าใช้บัญชี Google ของคุณ (คุณอยู่ในไซต์ SEO ดังนั้นฉันคิดว่าคุณมีแล้ว 🙂)
เมื่อคุณทำเสร็จแล้ว คุณสามารถตรวจทานข้อมูล API ของกราฟความรู้ได้หากคุณรู้สึกต้องการ หรือข้ามไปที่คอนโซล API แล้วดำเนินการต่อ
เมื่อคุณอยู่ที่คอนโซล:
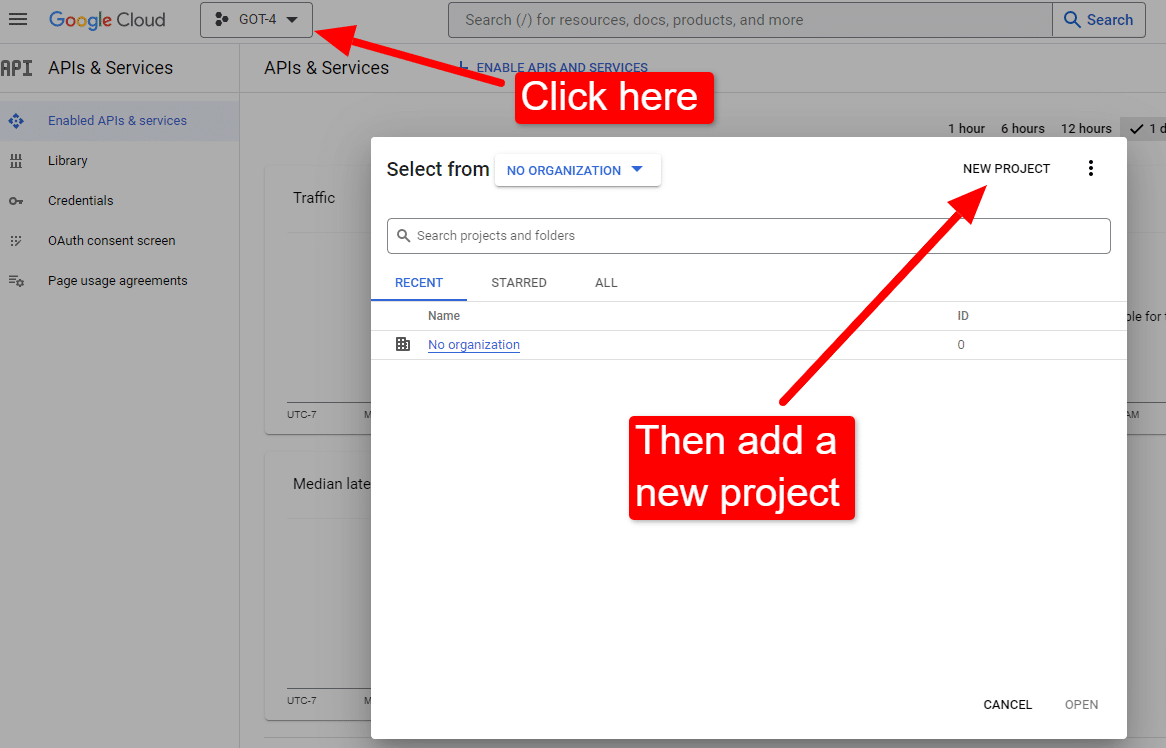
ตั้งชื่อบางอย่างเช่น "บทความที่ยอดเยี่ยมของ Dave" รู้ยัง...จำง่าย
ถัดไป คุณจะเปิดใช้งาน API โดยคลิก เปิดใช้ API และบริการ
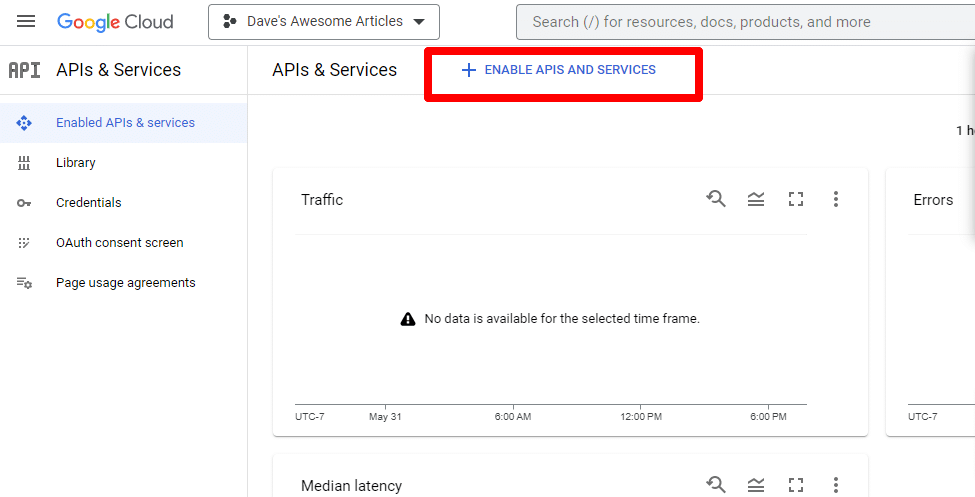
ค้นหา API การค้นหากราฟความรู้ และเปิดใช้งาน

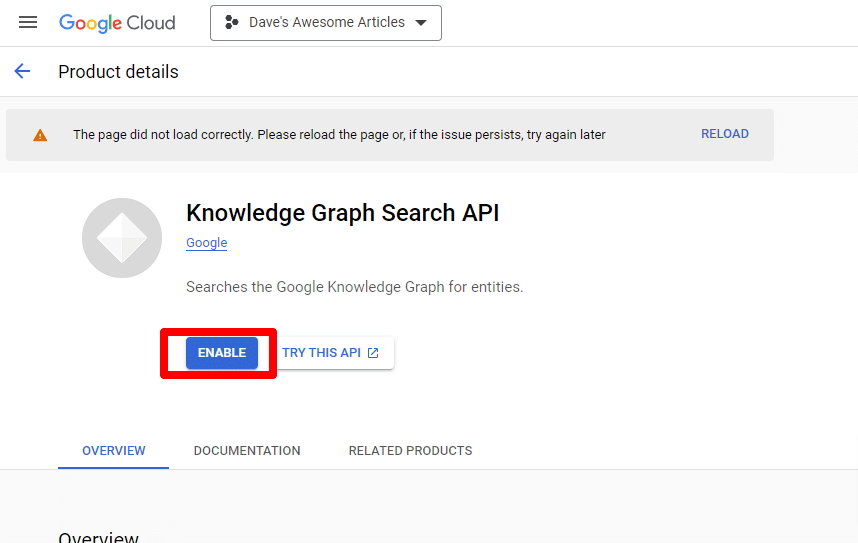
จากนั้นคุณจะถูกนำกลับไปที่หน้า API หลัก ซึ่งคุณสามารถสร้างข้อมูลรับรองได้:
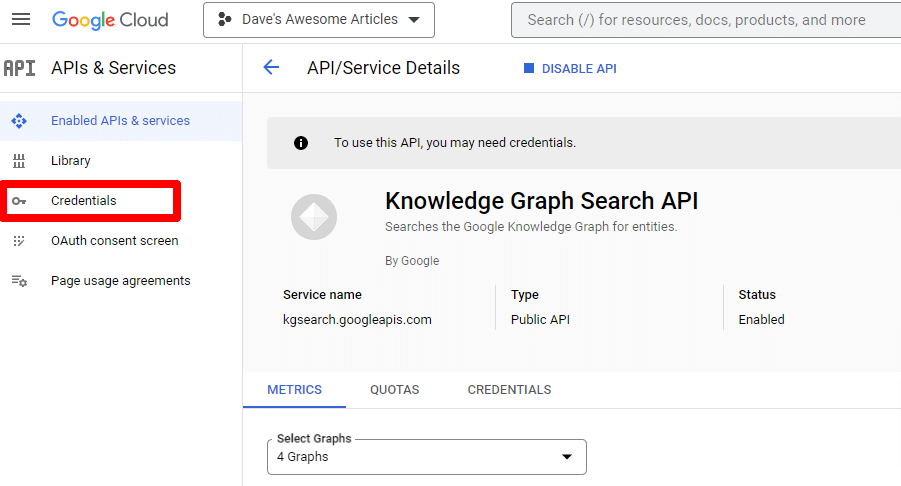
และเราจะสร้างบัญชีบริการ
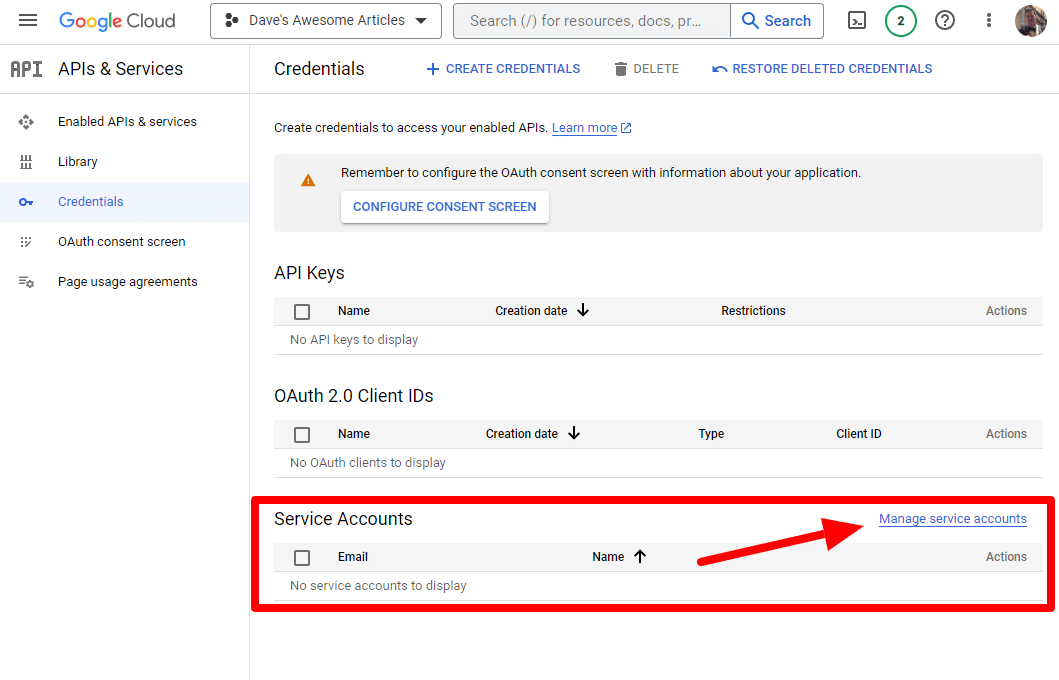
เพียงสร้างบัญชีบริการ:
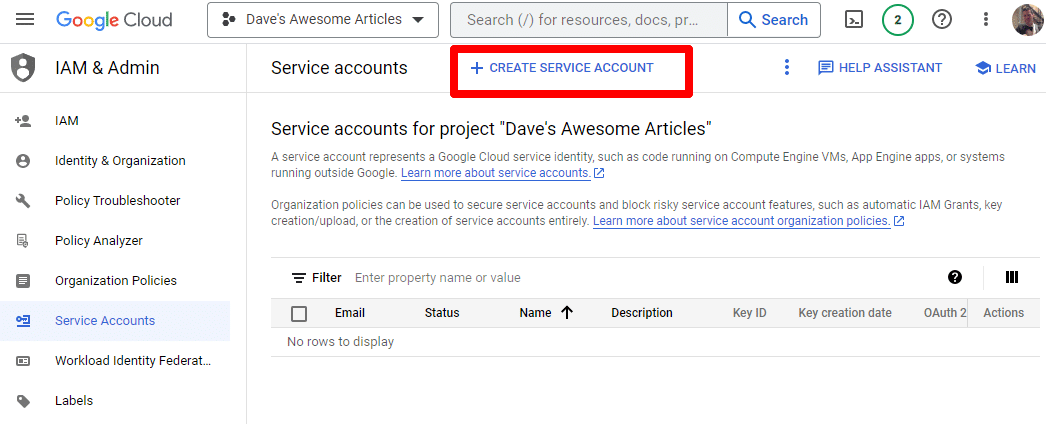
กรอกข้อมูลที่จำเป็น:
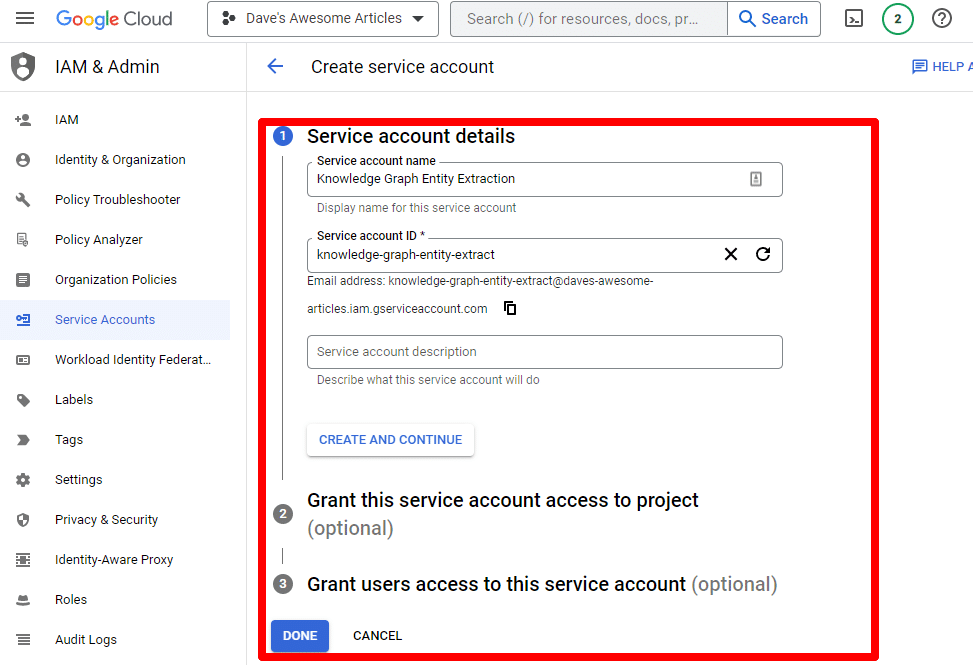
(คุณจะต้องตั้งชื่อและให้สิทธิ์แก่เจ้าของ)
ตอนนี้เรามีบัญชีบริการของเราแล้ว ที่เหลือก็แค่สร้างคีย์ของเรา
คลิกจุดสามจุดใต้ การดำเนินการ แล้วคลิก จัดการคีย์
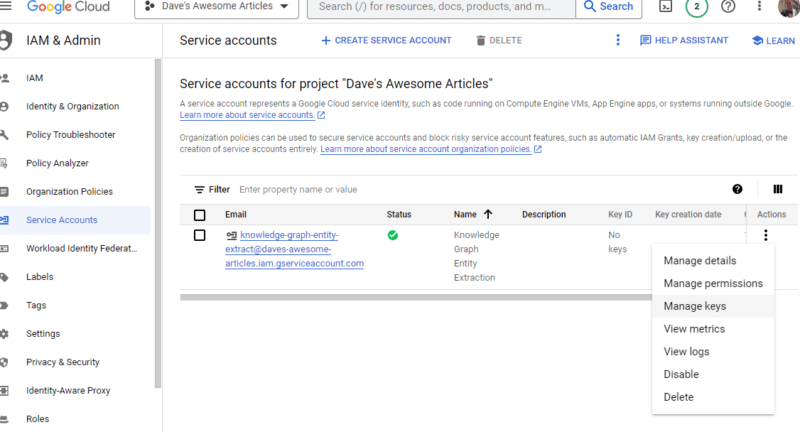
คลิก เพิ่มคีย์ จากนั้น สร้างคีย์ใหม่ :
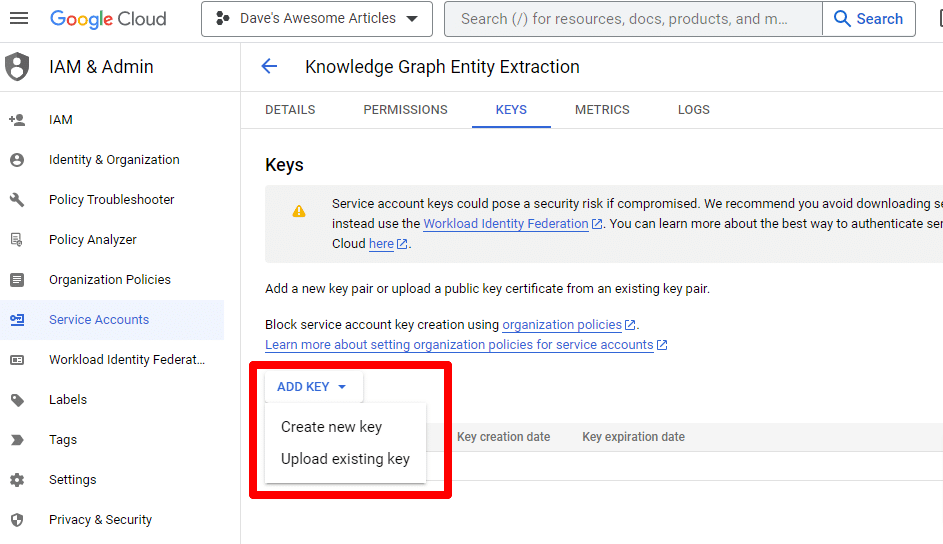
ประเภทคีย์จะเป็น JSON
คุณจะเห็นการดาวน์โหลดไปยังตำแหน่งดาวน์โหลดเริ่มต้นของคุณทันที
คีย์นี้จะให้สิทธิ์การเข้าถึง API ของคุณ ดังนั้นโปรดรักษาคีย์นี้ให้ปลอดภัย เช่นเดียวกับ OpenAI API ของคุณ
เอาล่ะ…และเรากลับมาแล้ว พร้อมที่จะดำเนินการกับสคริปต์ของเราแล้วหรือยัง
เมื่อเรามีแล้ว เราต้องกำหนดคีย์ API และพาธไปยังไฟล์ที่ดาวน์โหลด รหัสที่จะทำคือ:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") คุณจะแทนที่ YOUR_OPENAI_API_KEY ด้วยคีย์ของคุณเอง
นอกจากนี้ คุณจะแทนที่ /PATH-TO-FILE/FILENAME.JSON ด้วยเส้นทางไปยังรหัสบัญชีบริการที่คุณเพิ่งดาวน์โหลด รวมถึงชื่อไฟล์ด้วย
เรียกใช้เซลล์และคุณพร้อมที่จะดำเนินการต่อ
ขั้นตอนที่ 4: สร้างฟังก์ชั่น
ต่อไป เราจะสร้างฟังก์ชันเพื่อ:
- ขูดหน้าเว็บที่เราป้อนด้านบน
- วิเคราะห์เนื้อหาและแยกเอนทิตี
- สร้างบทความโดยใช้ GPT-4
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()นี่คือสิ่งที่อธิบายความคิดเห็น เรากำลังสร้างสามฟังก์ชันสำหรับวัตถุประสงค์ที่ระบุไว้ข้างต้น
ตาแหลมจะสังเกตเห็น:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, คุณสามารถแก้ไขเนื้อหา ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) และอธิบายบทบาทที่คุณต้องการให้ ChatGPT ทำ คุณยังสามารถใส่น้ำเสียง (เช่น “คุณเป็นนักเขียนที่เป็นมิตร…”)
ขั้นตอนที่ 5: ขูด URL และพิมพ์เอนทิตี
ตอนนี้เรากำลังทำให้มือของเราสกปรก ได้เวลา:
- ขูด URL ที่เราป้อนด้านบน
- ดึงเนื้อหาทั้งหมดที่อยู่ในแท็กย่อหน้า
- เรียกใช้ผ่าน Google Knowledge Graph API
- ส่งออกเอนทิตีเพื่อดูตัวอย่างอย่างรวดเร็ว
โดยทั่วไปคุณต้องการเห็นอะไรในขั้นตอนนี้ หากคุณไม่เห็นอะไรเลย ให้ตรวจสอบไซต์อื่น
content = scrape_url(url) entities = analyze_content(content)คุณจะเห็นว่าบรรทัดที่หนึ่งเรียกใช้ฟังก์ชันที่คัดลอก URL ที่เราป้อนครั้งแรก บรรทัดที่สองวิเคราะห์เนื้อหาเพื่อแยกเอนทิตีและเมตริกหลัก
ส่วนหนึ่งของฟังก์ชัน analyse_content ยังพิมพ์รายการของเอนทิตีที่พบสำหรับการอ้างอิงและการตรวจสอบอย่างรวดเร็ว
ขั้นตอนที่ 6: วิเคราะห์เอนทิตี
เมื่อฉันเริ่มเล่นสคริปต์ครั้งแรก ฉันเริ่มต้นด้วยเอนทิตี 20 รายการและค้นพบอย่างรวดเร็วว่ามักจะมากเกินไป แต่เป็นค่าเริ่มต้น (10) ใช่ไหม
เพื่อหาคำตอบ เราจะเขียนข้อมูลลงใน W&B Tables เพื่อให้ประเมินได้ง่าย มันจะเก็บข้อมูลไปเรื่อย ๆ สำหรับการประเมินในอนาคต
ก่อนอื่น คุณจะต้องใช้เวลาประมาณ 30 วินาทีในการลงชื่อสมัครใช้ (ไม่ต้องกังวล มันฟรีสำหรับสิ่งนี้!) คุณสามารถทำได้ที่ https://wandb.ai/site
เมื่อคุณทำเสร็จแล้ว รหัสที่จะทำคือ:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()เมื่อรัน ผลลัพธ์จะเป็นดังนี้:
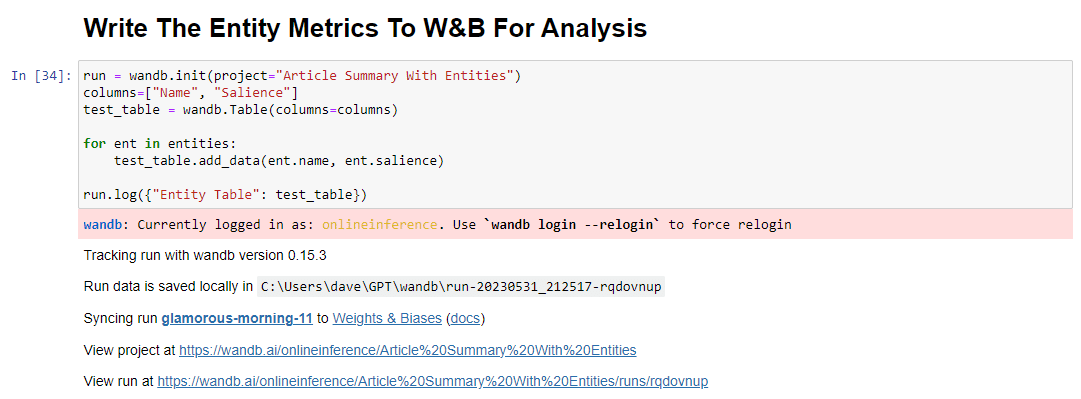
และเมื่อคุณคลิกลิงก์เพื่อดูการวิ่ง คุณจะพบกับ:
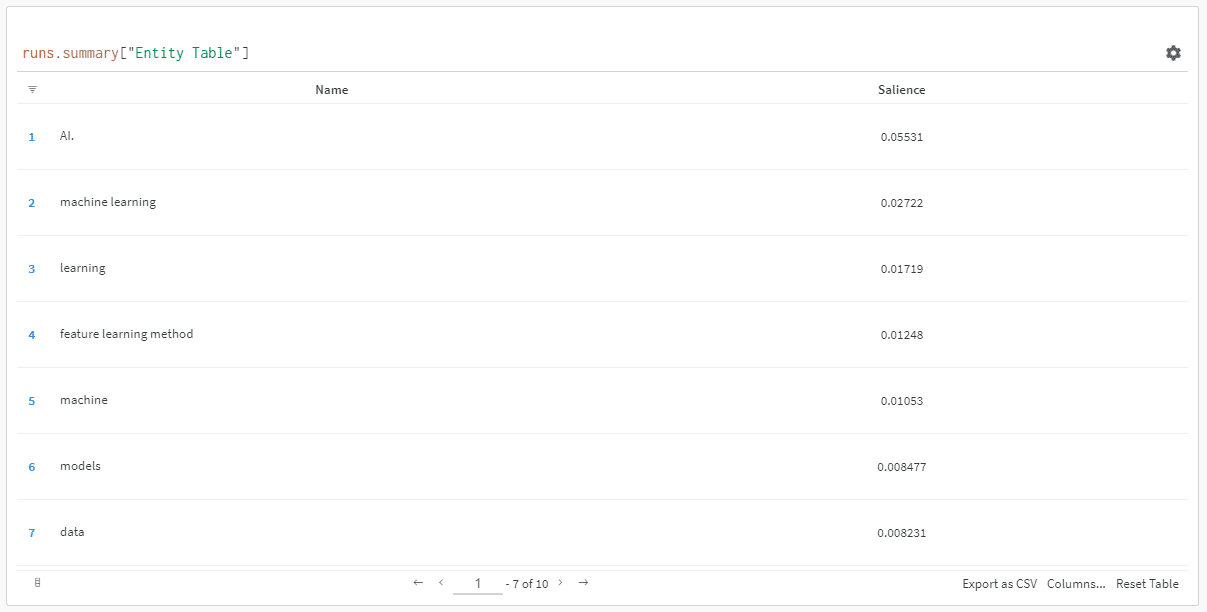
คุณสามารถเห็นการลดลงของคะแนนความถนัด โปรดจำไว้ว่าคะแนนนี้จะคำนวณว่าคำนั้นมีความสำคัญต่อหน้ามากเพียงใด ไม่ใช่คำค้นหา
เมื่อตรวจทานข้อมูลนี้ คุณสามารถเลือกที่จะปรับจำนวนเอนทิตีตามความสำคัญ หรือเฉพาะเมื่อคุณเห็นคำที่ไม่เกี่ยวข้องปรากฏขึ้น
หากต้องการปรับจำนวนเอนทิตี คุณต้องไปที่เซลล์ฟังก์ชันและแก้ไข:
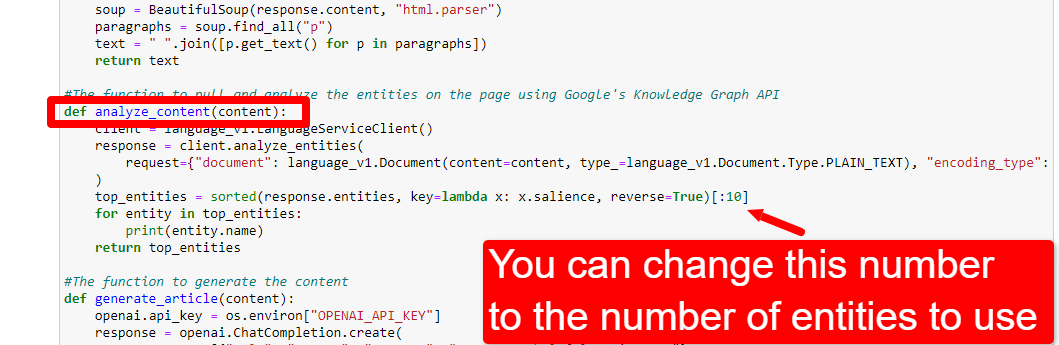
จากนั้นคุณจะต้องเรียกใช้เซลล์อีกครั้งและเซลล์ที่คุณเรียกใช้เพื่อขูดและวิเคราะห์เนื้อหาเพื่อใช้การนับเอนทิตีใหม่
ขั้นตอนที่ 7: สร้างโครงร่างบทความ
ช่วงเวลาที่ทุกคนรอคอย ก็ถึงเวลาสร้างโครงร่างบทความ
สิ่งนี้ทำในสองส่วน ขั้นแรก เราต้องสร้างพรอมต์โดยเพิ่มเซลล์:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)สิ่งนี้สร้างการแจ้งเพื่อสร้างบทความเป็นหลัก:

จากนั้น สิ่งที่เหลืออยู่คือสร้างโครงร่างบทความโดยใช้สิ่งต่อไปนี้:
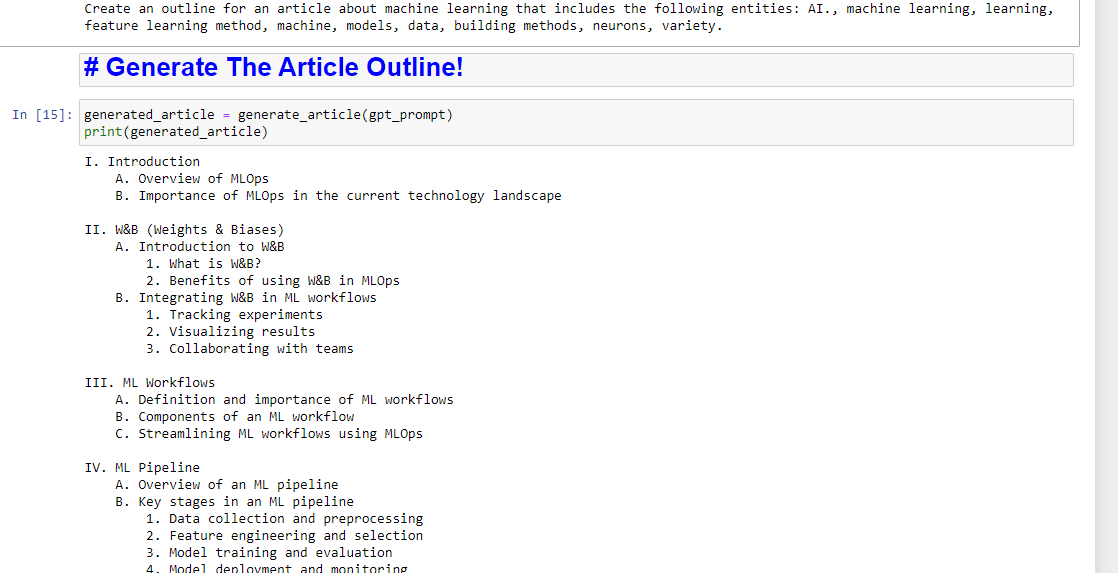
generated_article = generate_article(gpt_prompt) print(generated_article)ซึ่งจะผลิตสิ่งที่ต้องการ:
และหากคุณต้องการเขียนสรุป คุณสามารถเพิ่ม:
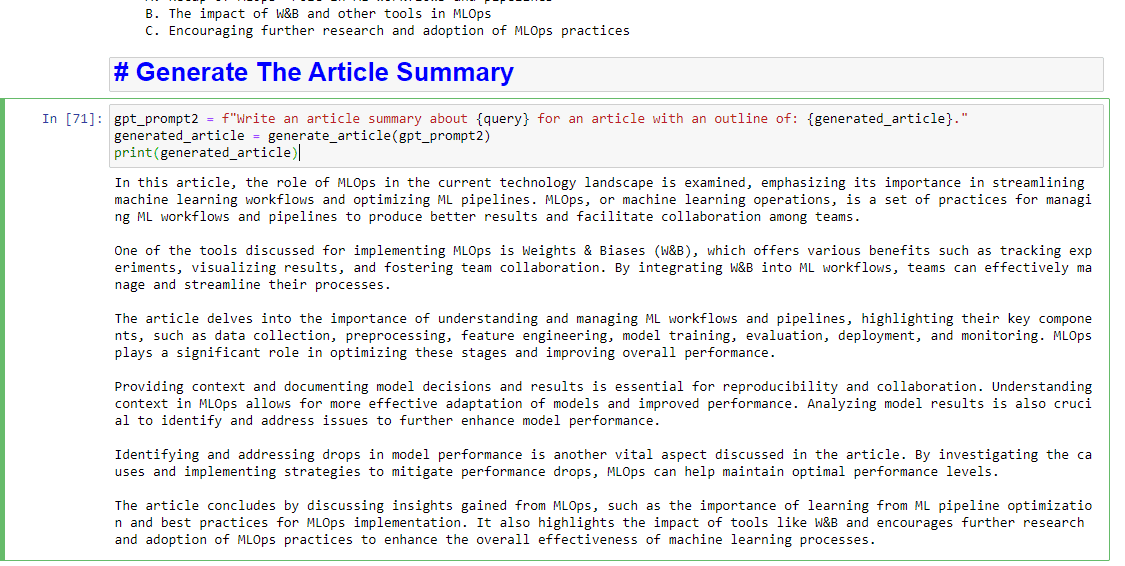
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)ซึ่งจะผลิตสิ่งที่ต้องการ:
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่