
วิธีใช้ประโยชน์สูงสุดจาก Google Search Console API โดยใช้ regex
เผยแพร่แล้ว: 2022-11-02Google Search Console เป็นเครื่องมือที่น่าทึ่งที่ให้ข้อมูลการค้นหาอันล้ำค่าโดยผู้ใช้จริงโดยตรงจาก Google แม้ว่าแผนภูมิและตารางจะใช้งานได้ง่าย แต่ข้อมูลส่วนใหญ่ไม่สามารถเข้าถึงได้จาก UI
วิธีเดียวที่จะเข้าถึงข้อมูลที่ซ่อนอยู่นี้คือการใช้ API และดึงข้อมูลการค้นหาที่มีค่าทั้งหมดที่มีให้คุณ - ถ้าคุณรู้วิธี เป็นไปได้ด้วยนิพจน์ทั่วไป
ต่อไปนี้คือวิธีที่คุณสามารถเพิ่ม Google Search Console API ให้สูงสุดโดยใช้นิพจน์ทั่วไป ตามที่ Eric Wu รองประธานฝ่ายการเติบโตของผลิตภัณฑ์ของ Honey บริษัทในเครือ PayPal ผู้ซึ่งพูดที่ SMX Advanced
การวินิจฉัยปัญหา SEO กับ GSC
การทำงานบนเว็บไซต์มีการเติบโตที่ซบเซาหรือลดลง หรือการอัปเดตหลักลดลงใช่หรือไม่
ผู้เชี่ยวชาญด้าน SEO ส่วนใหญ่หันไปใช้ Google Search Console (GSC) เพื่อวินิจฉัยปัญหาดังกล่าว
(หรือหากทรัพยากรอนุญาต คุณอาจใช้เครื่องมือแบบชำระเงิน เช่น Ryte หรือสร้างแพลตฟอร์มของคุณเองก็ได้)
โชคดีสำหรับชุมชน SEO ไม่มีปัญหาการขาดแคลนแดชบอร์ด Looker Studio (เดิมคือ Google Data Studio) ที่เป็นประโยชน์สำหรับการวิเคราะห์ GSC ได้แก่:
- แดชบอร์ดฟรีของ Aleyda Solis ซึ่งใช้ข้อมูล GSC เพื่อระบุการเปลี่ยนแปลงการจัดอันดับที่อาจเกิดขึ้นในช่วงไม่กี่วันที่ผ่านมาจากการอัปเดตหลักของ Google
- แดชบอร์ดการตรวจสอบปริมาณการค้นหาของ Google ซึ่งขณะนี้ดึงข้อมูลการเข้าชม Discover และ Google News
- Search Console Explorer Studio ของ Hannah Butler (และหากคุณต้องการจัดการข้อมูล GSC แบบลงมือปฏิบัติจริงและค้นหาข้อมูลเชิงลึกอย่างรวดเร็ว คุณสามารถใช้แผ่นงาน Search Console Explorer ของ Butler ได้)
แดชบอร์ดช่วยให้ SEO สามารถดูภาพรวมของแนวโน้มต่างๆ ได้ แทนที่จะใช้ GSC และการคลิกหลายครั้งเพื่อเข้าถึงข้อมูลที่คุณต้องการ
แต่หากคุณกำลังวิเคราะห์ไซต์ขององค์กร คุณอาจพบกับอุปสรรค์บางอย่างได้
- Looker Studio และ Google ชีตโหลดได้ช้า โดยเฉพาะอย่างยิ่งเมื่อคุณจัดการกับไซต์ขนาดใหญ่
- อินเทอร์เฟซของ GSC มีขีดจำกัดการส่งออก 1,000 แถว
- GSC มีปัญหาในการสุ่มตัวอย่างมาก ทีม SEO ระดับองค์กรพลาด 90% ของคีย์เวิร์ด GSC ของพวกเขา ตามข้อมูลของ Similar.ai และถ้าคุณรู้วิธีดึงข้อมูล คุณก็จะได้คีย์เวิร์ดถึง 14 เท่า
เอาชนะปัญหาการสุ่มตัวอย่างของ GSC
Explorer for Search เป็นอีกเครื่องมือหนึ่งที่คุณสามารถใช้สำหรับการวิเคราะห์ GSC จาก Noah Learner และทีมงานที่ Two Octobers สร้างขึ้นด้วยไปป์ไลน์ข้อมูลโดยใช้ API ของ GSC ซึ่งจะส่งข้อมูลไปยัง BigQuery (โดยทั่วไปจะข้าม Google ชีตและดาวน์โหลดไฟล์ CSV) แล้วแสดงข้อมูลด้วย Data Studio
ด้วยสิ่งนี้ คุณจึงมั่นใจได้ว่าคุณจะได้รับข้อมูล เกือบทั้งหมด
ยังมีข้อแม้อยู่เนื่องจากปัญหาการสุ่มตัวอย่างของ GSC โดยเฉพาะไซต์อีคอมเมิร์ซขนาดใหญ่ที่มีหมวดหมู่ต่างๆ มากมาย GSC ไม่จำเป็นต้องแสดงข้อมูลทั้งหมดที่มาจากไดเรกทอรีเหล่านั้น
หลังจากทำการทดสอบต่างๆ เพื่อให้ได้ข้อมูลมากที่สุดจาก GSC API ทีม Similar.ai ได้ค้นพบวิธีปิดช่องว่างการสุ่มตัวอย่าง GSC
พวกเขาพบว่าการเพิ่มไดเรกทอรีย่อยเป็นโปรไฟล์ต่างๆ ภายในแดชบอร์ด GSC ของคุณ ทำให้คุณสามารถดึงข้อมูลได้มากขึ้น เนื่องจาก Google ให้ข้อมูลเพิ่มเติมแก่คุณในระดับที่ต่ำกว่านั้น
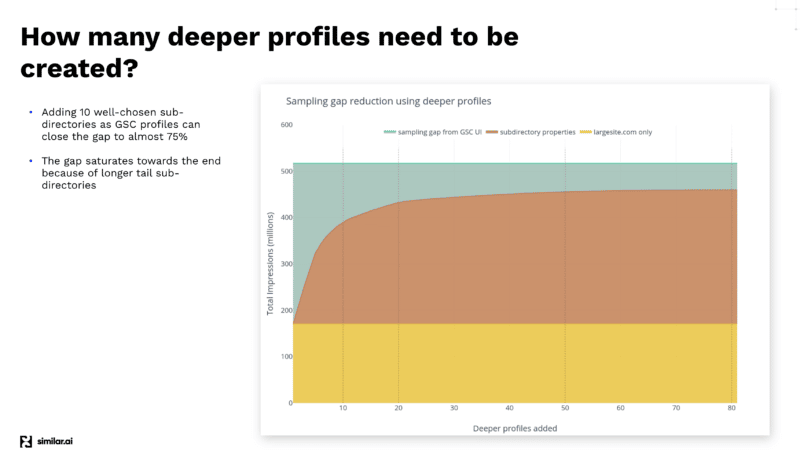
ตัวอย่างเช่น หากคุณกำลังดู example.com/televisions และคุณเพิ่ม "โทรทัศน์" เป็นไดเรกทอรีย่อยในโปรไฟล์ GSC ของคุณ Google จะให้เฉพาะคำหลักและข้อมูลการคลิกสำหรับไดเรกทอรีย่อยนั้นและด้านล่างเท่านั้น
และด้วยการเพิ่มไดเรกทอรีย่อยต่างๆ เหล่านี้เป็นจำนวนมาก คุณสามารถดึงข้อมูลได้มากขึ้น
ซึ่งช่วยแก้ปัญหาการสุ่มตัวอย่าง แต่คุณสามารถรับข้อมูลได้มากขึ้นโดยใช้นิพจน์ทั่วไป
รับข้อมูล GSC เพิ่มเติมด้วยนิพจน์ทั่วไป
นิพจน์ทั่วไปหรือ regex เป็นเครื่องมือที่มีประสิทธิภาพในการทำความเข้าใจข้อมูลของคุณ
ในเดือนเมษายนปี 2021 Google ได้เพิ่มการรองรับ regex ให้กับ GSC ทำให้ SEO มีช่องทางมากขึ้นในการแบ่งส่วนข้อมูลการค้นหาทั่วไป
หลายครั้งที่ข้อมูลไม่มีประโยชน์เว้นแต่คุณจะเข้าใจได้ และ regex ช่วยดึงข้อมูลเชิงลึกที่นำไปปฏิบัติได้จากข้อมูลอันสมบูรณ์ของ GSC
แต่ถึงแม้จะทรงพลังเพียงใด regex อาจเรียนรู้ได้ยาก
สถานที่ที่ดีที่สุดในการทำความเข้าใจและเจาะลึกถึงนิพจน์ทั่วไปคือเอกสารอย่างเป็นทางการของ Google เกี่ยวกับ GitHub (Google ใช้ RE2 ในผลิตภัณฑ์ซึ่งเป็นรสชาติของสำนวนทั่วไป)
แม้ว่า regex จะพร้อมใช้งานในภาษาการเขียนโปรแกรมต่างๆ ทุกประเภท คุณจะพบได้เกือบทุกที่ แม้กระทั่งผู้ที่กำลังแก้ไขไฟล์ .htaccess
ในส่วนถัดไปคือกรณีการใช้งานสำหรับการใช้ประโยชน์จาก regex สำหรับ GSC
แบบสอบถามข้อมูล Regex
เมื่อดูคำค้นหาตามข้อมูลจริงใน GSC คุณมักจะต้องการทำความเข้าใจ:
- ผู้คนมาที่ไซต์ของคุณจริงๆ เป็นอย่างไร
- พวกเขากำลังดึงคำถามอะไร
การพิจารณาสิ่งเหล่านั้นจากมุมมองครั้งเดียว ภายใน GSC อาจเป็นเรื่องยาก
คุณมักจะค้นหาคำว่า "อะไร" "อย่างไร" "ทำไม" และ "เมื่อใด"
มีสองวิธีในการแยกการสืบค้นข้อมูลที่ไม่น่าเบื่อกับ regex
Daniel K. Cheung แชร์สตริง regex ที่จะแสดงข้อความค้นหาทั้งหมดที่มีคำว่า "อะไร" "อย่างไร" "ทำไม" และ "เมื่อใด" ที่ได้รับการคลิกหรือการแสดงผล:
-
"what|how|why|when"
และสตริง regex นี้ที่แชร์โดย Steve Toth ทำให้ตัวอย่างก่อนหน้านี้ดีขึ้น:
-
^(who|what|where|when|why|how)[" "]
คุณสามารถใช้สตริงนี้ได้หากต้องการบันทึกข้อความค้นหาตามคำถามที่ขึ้น ต้น ด้วย "ใคร" "อะไร" "ที่ไหน" "เมื่อไหร่" "ทำไม" และ "อย่างไร" แล้ว ตาม ด้วยช่องว่าง
นี่เป็นรายการที่ดีที่จะใช้เมื่อคุณกำลังมองหาคำประเภทใดก็ตามที่จะเริ่มต้นคำถาม:
- คือ, ไม่สามารถ, ได้, ไม่ได้, ไม่ได้, ทำ, ไม่ได้, ได้อย่างไร, ถ้า, เป็น, ไม่, ควร, ไม่ควร, เป็น, ไม่ใช่ เป็น, ไม่ได้, อะไร, เมื่อไหร่, ที่ไหน, ใคร, ใคร, ทำไม, จะไม่, จะไม่, จะไม่
การวางทั้งหมดนี้ในรูปแบบ regex จะมีลักษณะดังนี้:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
ในสตริงอักขระ 178 นี้:
- คุณมีคาเร็ต (
^) ซึ่งบอกคุณว่าการสืบค้นต้องขึ้นต้นด้วยคำนี้: - คำต่างๆ จะถูกคั่นด้วยไพพ์ (
|) แทนเครื่องหมายจุลภาค - คำทั้งหมดอยู่ในวงเล็บ
- มีแบ็กสแลชและ “s” (
\s) ซึ่งหมายถึงช่องว่างหลังคำ
นี่เป็นสิ่งที่ดี แต่ก็สามารถน่าเบื่อได้
ด้านล่างนี้ Wu ได้ลดความซับซ้อนของรายการคำก่อนหน้าเพื่อให้เป็นมิตรกับ regex มากขึ้นและสั้นลง ซึ่งเหมาะสำหรับการคัดลอกและวาง การรักษาด้วยวิธีนี้ยังช่วยให้เกิดประสิทธิภาพอีกด้วย
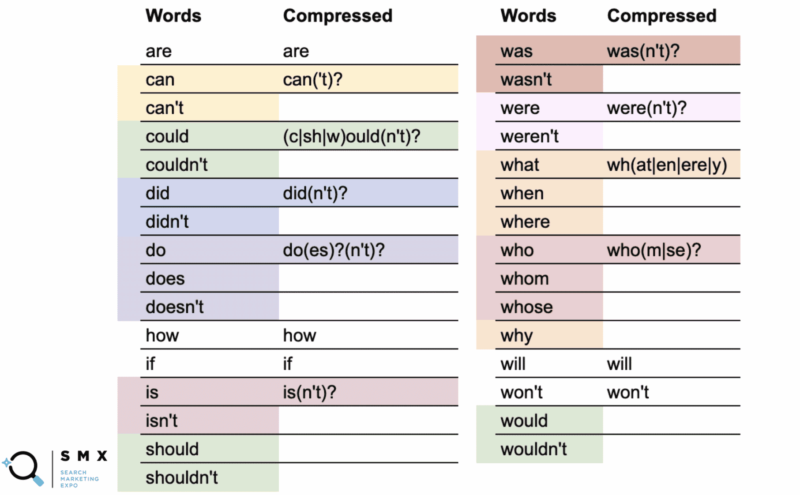
ในคอลัมน์แรกคือคำปกติ และคอลัมน์ที่สองคือ regex ที่บีบอัด
ตัวอย่างเช่น คำว่า "can" ใช้เวอร์ชันบีบอัด can('t)? .
เครื่องหมายคำถามบ่งชี้ว่าอะไรก็ตามในวงเล็บเป็นตัวเลือก ไวยากรณ์ที่บีบอัดทำให้คุณสามารถครอบคลุมทั้งคำว่า "สามารถ" และ "ไม่สามารถ"
ที่น่าสนใจกว่านั้น คุณสามารถทำสิ่งนี้ได้ด้วย can/could, should/shouldn, และ would/would ที่ส่วน -ould ของคำเป็นฐานทั่วไป เช่น (c|sh|w)ould(n't)? . สตริงสั้นนี้ครอบคลุมทั้งหกกรณีเหล่านั้น
ในขณะที่ลดความซับซ้อนของรายการคำยาวๆ นั้นทำให้สตริงอ่านได้น้อยลง ข้อดีคือมันเข้ากับฟิลด์ regex ได้มากขึ้น และช่วยให้คุณคัดลอกและวางได้ง่ายขึ้น
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
หากคุณก้าวไปอีกขั้นคุณสามารถบีบอัดได้มากขึ้น ในกรณีนี้ Wu ลดจำนวนตัวละครจาก 135 เป็น 113 อักขระ
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
นิพจน์ทั่วไปอาจซับซ้อนมาก หากคุณได้รับสตริง regex จากคนอื่นและต้องการแก้ความกำกวมว่ากำลังทำอะไรอยู่ คุณสามารถใช้ Regexper เพื่อช่วยให้คุณเห็นภาพได้
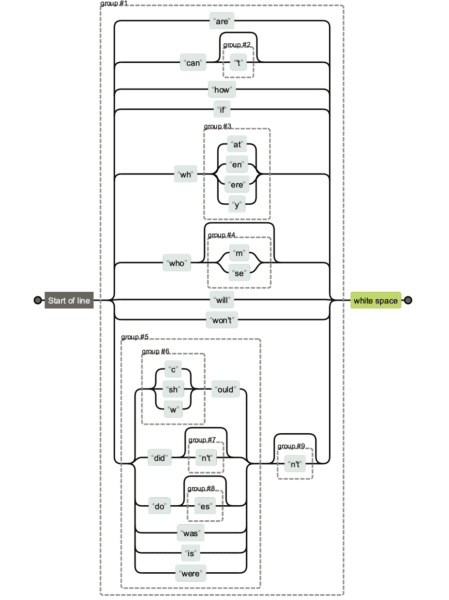
ด้านล่างนี้ คุณจะเห็นการเปรียบเทียบเวอร์ชันสตริง regex ต่างๆ การดูแลรักษาอันแรกง่ายกว่า และการดูแลรักษาและอ่านอันสุดท้ายยากกว่าอย่างเห็นได้ชัด

แต่บางครั้งการนับอักขระก็มีความสำคัญอย่างยิ่งโดยเฉพาะเมื่อคุณมีนิพจน์ทั่วไปที่ยาวกว่า
ขีดจำกัดตัวกรอง Regex สำหรับ GSC คือ 4,096 อักขระตาม Google Search Advocate Daniel Waisberg
ที่ดูเหมือนจะค่อนข้างน้อย อย่างไรก็ตาม หากคุณมีไซต์อีคอมเมิร์ซและต้องเพิ่มชื่อโดเมน โดเมนย่อย หรือไดเร็กทอรีที่ยาวกว่านั้น คุณมักจะถึงขีดจำกัดนั้น
ข้อความค้นหาที่มีตราสินค้า Regex
อีกตัวอย่างหนึ่งที่คุณอาจเริ่มถึงขีดจำกัดอักขระ regex ใน GSC คือเมื่อคุณใช้สำหรับการค้นหาที่มีตราสินค้า
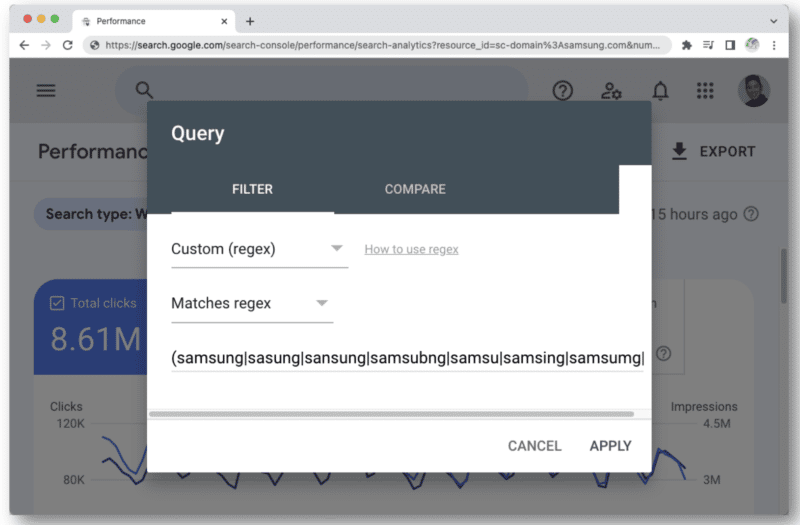
เมื่อคุณนึกถึงการสะกดผิดประเภทต่าง ๆ ของชื่อแบรนด์ที่บุคคลสามารถพิมพ์ได้ คุณจะพบกับจำนวนอักขระ 4,096 ตัวนั้นอย่างรวดเร็ว ตัวอย่างเช่น:
- ซัมซุง, ดัมซอง, มัมซัง, ซัมซุง, samaung, samdung, ซัมซอง, ซัมซอง, ซัมซุง, ซัมกุง, ซัมซัง, ซัมซุง, ซัมกู, samshgg, แซมซง, ซัมซิง, ซัมซุง, ซัมซุบ, ซัมซุบ, ซัมซุบ , samsun g, samsunb, samsund, samsund, samsunh, samsunt …
นี่คือจุดที่การทำความเข้าใจ regex ช่วยได้ ด้วยสตริงนี้ คุณสามารถจับชื่อแบรนด์ "samsung" พร้อมกับการสะกดผิด:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
หลายครั้งที่คนจะสะกดคำตรงกลางผิด แต่โดยทั่วไปแล้ว พวกมันจะมีรูปแบบและความยาวที่เหมาะสม และคุณสามารถใช้ไวยากรณ์ของคุณได้ด้วยวิธีนี้
สำหรับการสะกดผิดของข้อความค้นหาแบรนด์ ให้พิจารณาสิ่งต่อไปนี้:
- ตัวอักษรหลัก ที่ประกอบขึ้นเป็นข้อความค้นหาแบรนด์
- พยัญชนะ .
- ตัวอักษรล้อมรอบพยัญชนะยาก

สีแดงคือพยัญชนะเสียงแข็งที่ผู้คนมักไม่พลาดเมื่อพิมพ์ชื่อแบรนด์ เหล่านี้เป็นตัวอักษรหลักที่ประกอบขึ้นเป็นแบรนด์นั้น ๆ สำหรับ "samsung" ตัว "s" ขึ้นต้น ตัว "m" ตรงกลาง ตามด้วย "n" และ "g" ในตอนท้าย

ตัวอักษรสีน้ำเงินที่ล้อมรอบพยัญชนะหลักเหล่านั้นบนแป้นพิมพ์เป็นตัวอักษรที่คนทั่วไปพิมพ์ผิด ในตัวอย่าง รอบๆ “s” คุณจะเห็น “a”, “d” และ “z” (แม้ว่าเลย์เอาต์สำหรับคีย์บอร์ดสากลจะแตกต่างกัน แต่แนวคิดก็ยังเหมือนเดิม)
สตริง regex ด้านบนจะรวบรวมตัวแปรที่เป็นไปได้ทั้งหมดของ "samsung"
เคล็ดลับสำคัญอื่น ๆ ที่นี่คือ [az\s]{1,4}
ในรูปแบบ regex โดยทั่วไปจะพูดว่า "ฉันต้องการจับคู่ตัวอักษร "a" ถึง "z" หรือการเว้นวรรคหนึ่งถึงสี่ครั้ง"
ข้อมูลนี้จะรวบรวมคำสะกดผิดแปลกๆ ที่อาจเกิดขึ้นระหว่างการค้นหาแบรนด์ โดยที่บุคคลอาจกดปุ่มเดียวกันหลายครั้งหรือกดเว้นวรรคโดยไม่ได้ตั้งใจ
นอกจากนี้ ชื่อแบรนด์ยังมีความยาวที่แน่นอน (“samsung” มีอักขระเจ็ดตัว) ผู้คนมักจะไม่ลงเอยด้วยการพิมพ์อักขระ 20-50 ตัว
ดังนั้นในนิพจน์ทั่วไปนี้ เรากำลังเดาว่าระหว่าง "s" และ "m" ใน "samsung" จะมีคนพิมพ์อักขระ 1-4 ตัวผิด จากนั้นจาก "m" ถึง "g" ในตอนท้าย พวกเขาจะพิมพ์อักขระ 1-6 ตัวผิด โดยมีการเว้นวรรคด้วย
การเพิ่มทั้งหมดนี้ทำให้คุณสามารถบันทึกข้อความค้นหาที่มีตราสินค้าได้หลากหลายรูปแบบอย่างครอบคลุม
สิ่งอื่นที่ควรทราบคือชื่อแบรนด์อาจปรากฏในส่วนต่างๆ ของข้อความค้นหา

ดังนั้นเราจึงต้องตรวจสอบให้แน่ใจว่าชื่อแบรนด์นั้นถูกจับได้ มันควรจะเป็นอย่างใดอย่างหนึ่ง:
- ที่จุดเริ่มต้นของแบบสอบถาม
- ตรงกลางของข้อความค้นหา (ซึ่งล้อมรอบด้วยช่องว่าง)
- หรือท้ายคำถาม
นิพจน์ทั่วไปสำหรับสิ่งนี้มีดังนี้:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
ข้อมูลนี้จะรวบรวมคำถามทั้งหมดที่ชื่อแบรนด์ "samsung" อยู่ต้น กลาง หรือปลาย
- จุดเริ่มต้นของสตริง =
^ - ล้อมรอบด้วยช่องว่าง =
\s - จุดสิ้นสุดของสตริง =
$
โพสต์ของ JC Chouinard นิพจน์ทั่วไป (RegEx) ใน Google Search Console เจาะลึกเข้าไปในตัวอย่าง regex
การทำงานของ Regex และ GSC API
นิพจน์ทั่วไปมีประโยชน์สำหรับ Wu และทีมของเขาเมื่อพวกเขาทำงานกับไคลเอนต์ที่พบว่าการรับส่งข้อมูลลดลงหลังจากอัปเดตหลัก
หลังจากดูปัญหาต่างๆ ของไซต์อีคอมเมิร์ซแล้ว พวกเขาพบว่าปัญหาอยู่ในหน้ารายละเอียดผลิตภัณฑ์บางหน้า
พวกเขาจำเป็นต้องแบ่งประเภทเพจเพื่อการวิเคราะห์ใน GSC แต่นี่เป็นงานที่ซับซ้อนเนื่องจากโครงสร้าง URL ที่แตกต่างกันสำหรับผลิตภัณฑ์ในสหรัฐอเมริกาและต่างประเทศ

URL ผลิตภัณฑ์สากลของไซต์รวมภาษาและรหัสประเทศ ในขณะที่ URL ผลิตภัณฑ์ของสหรัฐอเมริกาไม่ได้รวมไว้
แม้แต่การใช้ไวยากรณ์ regex ก็ยุ่งยากเพราะมีตัวอักษรและขีดคั่นอยู่ในส่วนย่อยของผลิตภัณฑ์ หมวดหมู่ และหมวดหมู่ย่อย นอกจากนี้ พวกเขาจำเป็นต้องกรอง URL ของผลิตภัณฑ์ระหว่างประเทศออกเพื่อบันทึกเฉพาะหน้าของสหรัฐฯ
ในการรับหน้า Landing + รายละเอียดผลิตภัณฑ์ในสหรัฐอเมริกาทั้งหมด ( ไม่ใช่ หน้า i18n) พวกเขาสร้างสตริง regex ต่อไปนี้:
รวม: /([^/]+/){1,2}p?
ยกเว้น: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
นี่คือรายละเอียด:

ทีมงานต้องการจับคู่หมวดหมู่ หมวดหมู่ย่อย และผลิตภัณฑ์ทั้งหมด ดังนั้นพวกเขาจึงรวม:
- อักขระใดๆ ที่ไม่ใช่เครื่องหมายทับ =
[^/]+ - 1 หรือ 2 ไดเร็กทอรี =
/){1,2} - บางครั้งตามด้วย Product slug =
p?
คาเร็ต ( ^ ) โดยทั่วไปหมายถึงจุดเริ่มต้นของสตริง แต่เมื่ออยู่ในวงเล็บเหลี่ยม (เช่นใน [^/] ) แสดงว่ามีการปฏิเสธ (เช่น “ไม่มีสิ่งใดอยู่ในช่องนี้”)
ดังนั้นสตริงนี้ /([^/]+/){1,2}p? หมายถึง “ฉันต้องการอักขระจำนวนเท่าใดก็ได้ที่ไม่ใช่เครื่องหมายทับ ซึ่งนำไปสู่เครื่องหมายทับ (ซึ่งหมายถึงไดเรกทอรี) และบางครั้งก็ตามด้วยตัวอักษร 'p' (คำนำหน้าสำหรับทากผลิตภัณฑ์)”
ในเวลาเดียวกัน ทีมงานไม่ต้องการจับคู่ประเทศและภาษาที่มีตัวอักษรและขีดคั่นเหมือนกัน ดังนั้นพวกเขาจึงยกเว้น:
- ไดเร็กทอรี 2 ตัวอักษรใดๆ =
[a-zA-Z]{2} - 2 ตัวอักษร + 2 ตัวอักษร lang-country combo =
[a-zA-Z]{2}-[a-zA-Z]{2}
การสร้างนิพจน์ทั่วไปเพื่อให้ตรงกับภาษาและรหัสประเทศทั้งหมดด้วยตนเองจะเป็นเรื่องที่น่าเบื่อหน่ายเนื่องจากชุดค่าผสมที่เป็นไปได้ทั้งหมด ดังนั้นพวกเขาจึงไม่สามารถทำสิ่งนี้ในลักษณะเดียวกับการสืบค้นข้อมูล (ซึ่งไม่รวมชุดค่าผสมทุกประเภท)
แต่แม้หลังจากสร้างสตริง regex เหล่านี้แล้ว ก็ยังมีปัญหา
ใน Google Search Console มีเพียงช่องเดียวสำหรับวางสตริง regex คุณจะต้องเลือก Matches regex หรือ ไม่ตรงกับ regex คุณไม่สามารถใช้ทั้งสองอย่างพร้อมกันได้
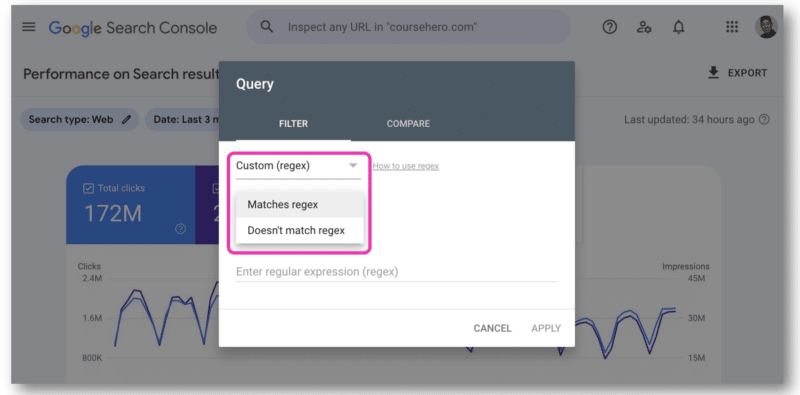
นี่คือจุดที่ GSC API มีประโยชน์ เนื่องจากช่วยให้เข้าร่วมสตริง regex ได้
ในเอกสารประกอบ Google Search Console API มีลิงก์ ลองใช้ เลย
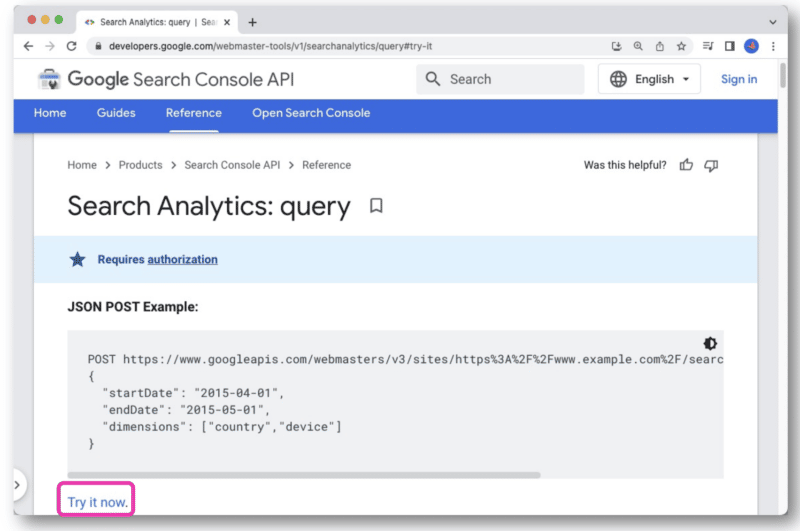
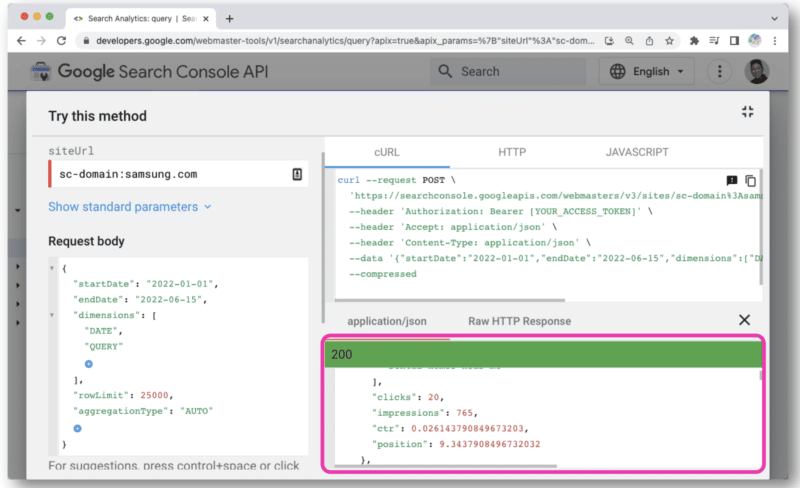
เมื่อคลิกแล้ว คอนโซลจะเปิดขึ้นเพื่อให้คุณสามารถเลือกไซต์และสร้างคำขอ API ของคุณผ่านมุมมองเว็บได้
แต่เพื่อให้จัดการการสืบค้น API ได้ดีขึ้น Wu แนะนำให้ใช้ Postman บนเดสก์ท็อปหรือ Paw (ซึ่งมีอยู่ใน Mac)
บุรุษไปรษณีย์ช่วยให้คุณสร้างแบบสอบถามและบันทึกไว้ในภายหลัง และหากคุณมีสิทธิ์เข้าถึงไซต์อื่น คุณไม่จำเป็นต้องสร้างแบบสอบถามใหม่ทุกครั้ง คุณเพียงแค่เปลี่ยนชื่อไซต์ด้วยตัวแปรแล้วส่งคำขอหลายรายการ
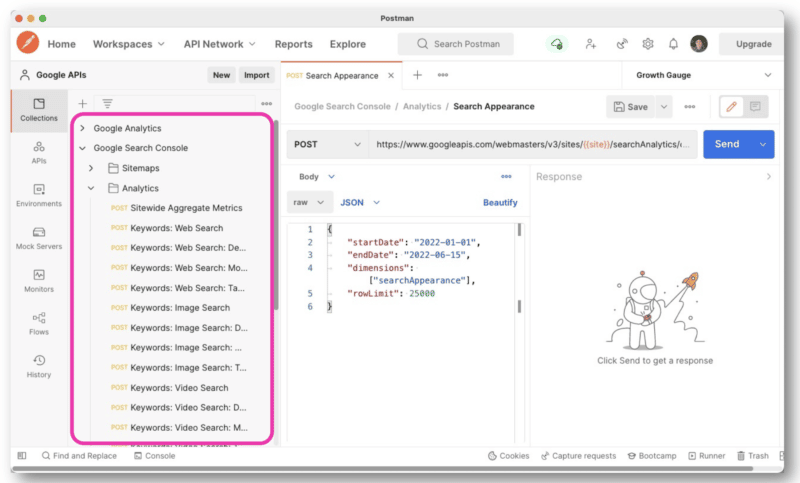
ในทางกลับกัน Paw นั้นง่ายต่อการมองผ่านและใช้งาน
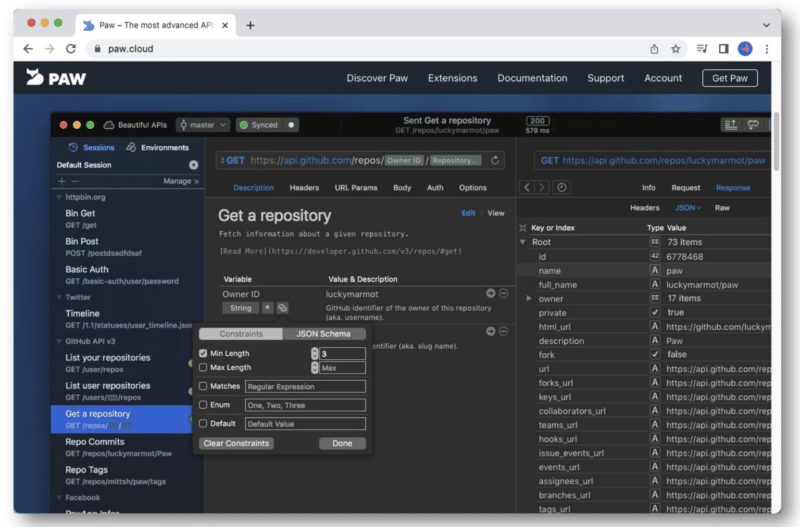
ในการเข้าถึง API คุณจะต้องได้รับคีย์ API (นี่คือบทช่วยสอนที่เป็นประโยชน์จาก Chouinard)
เมื่อคุณได้รับข้อมูลนี้ คุณจะมีรหัสไคลเอ็นต์และข้อมูลลับของไคลเอ็นต์ ซึ่งคุณจะเพิ่มในการตรวจสอบสิทธิ์ OAuth 2.0 ภายใน Postman หรือ Paw
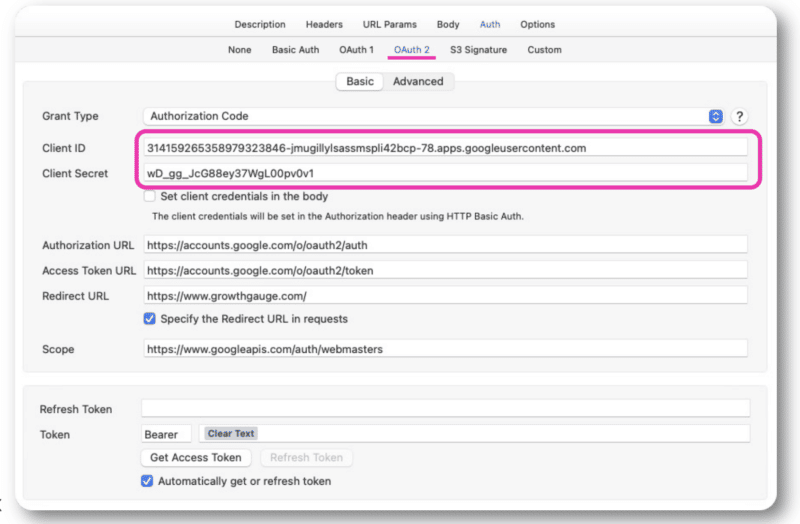
จากที่นั่น คุณจะสามารถลงชื่อเข้าใช้ด้วยบัญชีปกติของคุณได้
Wu ส่วนใหญ่สร้างคำขอ GSC API โดยใช้สตริง regex ใน Paw แบบสอบถามถูกป้อนตรงกลางของอินเทอร์เฟซ
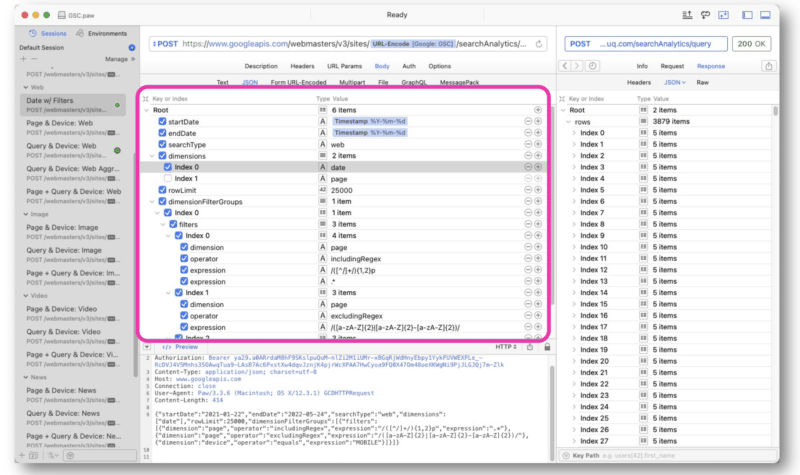
การตอบสนองจาก Google นั้นคล้ายกับมุมมองเว็บ GSC API ข้อมูลสามารถส่งออกเพื่อการประมวลผลได้
เนื่องจากข้อมูลอยู่ใน JSON ข้อมูลจึงอาจยุ่งเหยิงและอ่านยาก

สำหรับสิ่งนี้ คุณสามารถใช้ตัวประมวลผล JSON บรรทัดคำสั่งฟรีและโอเพนซอร์สที่เรียกว่า JQ เพื่อพิมพ์ข้อมูลได้อย่างสวยงาม

ข้อมูลไม่มีประโยชน์ขนาดนั้นจนกว่าคุณจะใส่ลงในสเปรดชีต ไปป์ในไฟล์ที่คุณส่งออกจาก Paw ไปยัง JQ เปิดแล้ววนซ้ำในแต่ละแถว – บันทึกแต่ละองค์ประกอบเพื่อให้คุณสามารถส่งออกไปยัง CSV
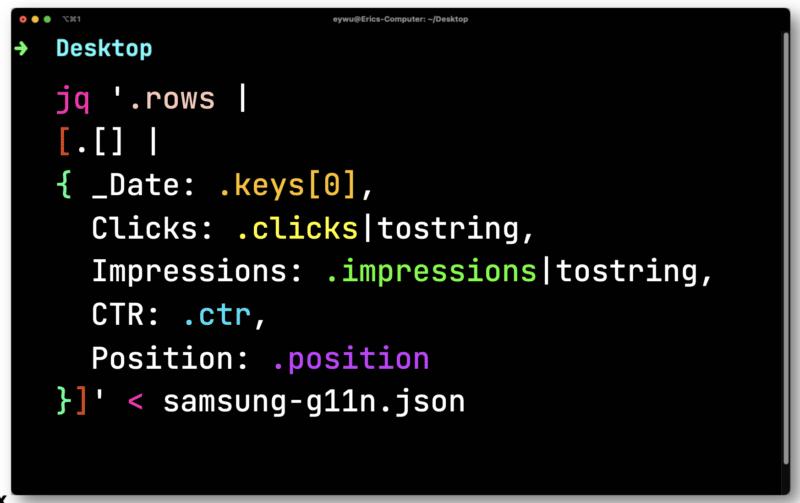
ในที่นี้ คุณจะต้องแปลงจำนวนคลิกและการแสดงผลที่ลอยตัว (ตัวเลขที่มีตำแหน่งทศนิยม) ทั้งสองต้องแปลงเป็นสตริงที่เข้ากันได้กับ CSV
JQ จะแสดงรูปแบบที่ง่ายกว่ามากดังต่อไปนี้
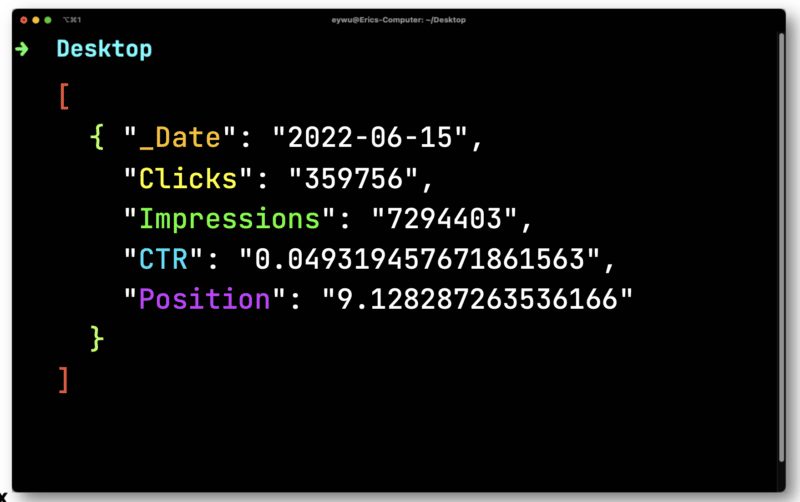
ต่อไป คุณจะต้องใช้ Dasel เพื่อสร้างรูปแบบนี้แล้วสร้างเป็น CSV
และนี่คือผลลัพธ์สุดท้าย
สิ่งที่น่าทึ่งสำหรับทีมของ Wu คือพวกเขาสามารถใช้ Google Search Console API และนิพจน์ทั่วไปเพื่อ:
- กรองข้อความค้นหาระหว่างประเทศทั้งหมดออก และดูเฉพาะสหรัฐอเมริกาที่มีปัญหาหลัก
- ระบุวันที่ไซต์มีปัญหา
ดู: ใช้ประโยชน์สูงสุดจาก Google Search Console API
ด้านล่างนี้เป็นวิดีโอที่สมบูรณ์ของการนำเสนอ SMX Advanced ของ Wu