
Google ใช้ระบบคล้าย ChatGPT เพื่อตรวจจับสแปมและเนื้อหา AI และจัดอันดับเว็บไซต์หรือไม่
เผยแพร่แล้ว: 2023-02-01พาดหัวนั้นจงใจทำให้เข้าใจผิด – แต่ตราบใดที่การใช้คำว่า “ChatGPT” เท่านั้นที่เกี่ยวข้อง
“ChatGPT-like” ช่วยให้คุณซึ่งเป็นผู้อ่านทราบประเภทของเทคโนโลยีที่ฉันพูดถึงได้ทันที แทนที่จะอธิบายว่าระบบเป็น “รูปแบบการสร้างข้อความ เช่น GPT-2 หรือ GPT-3” (นอกจากนี้ อันหลังจะคลิกไม่ได้จริงๆ…)
สิ่งที่เราจะดูในบทความนี้คือเอกสาร Google ที่เก่ากว่าแต่มีความเกี่ยวข้องสูงในปี 2020 “Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”
กระดาษเกี่ยวกับอะไร
เริ่มจากคำอธิบายของผู้แต่ง พวกเขาแนะนำหัวข้อดังนี้:
“หลายคนแสดงความกังวลเกี่ยวกับอันตรายที่อาจเกิดขึ้นจากตัวสร้างข้อความประสาทในธรรมชาติ เนื่องจากความสามารถในการสร้างข้อความที่ดูเหมือนมนุษย์เป็นส่วนใหญ่
เมื่อเร็ว ๆ นี้มีการใช้ตัวแยกประเภทที่ได้รับการฝึกฝนให้แยกแยะระหว่างข้อความที่มนุษย์สร้างขึ้นและเครื่องสร้างขึ้นเพื่อตรวจสอบการมีอยู่ของข้อความที่เครื่องสร้างขึ้นบนเว็บ [29] อย่างไรก็ตาม มีการใช้ตัวแยกประเภทเหล่านี้สำหรับการใช้งานอื่นๆ เพียงเล็กน้อย แม้จะมีคุณสมบัติที่น่าสนใจตรงที่ไม่ต้องใช้ป้ายกำกับใดๆ เลย มีเพียงคลังข้อมูลของมนุษย์และแบบจำลองเชิงกำเนิดเท่านั้น ในงานนี้ เราแสดงผ่านการประเมินอย่างเข้มงวดโดยมนุษย์ว่า ตัวแบ่งแยกระหว่างมนุษย์กับเครื่องจักรทำหน้าที่เป็นตัวแยกประเภทที่มีประสิทธิภาพของคุณภาพของ หน้า นั่นคือ ข้อความที่ดูเหมือนว่าสร้างขึ้นโดยเครื่องจักรมักจะไม่ต่อเนื่องกันหรือไม่เข้าใจ เพื่อให้เข้าใจถึงการมีอยู่ของเพจที่มีคุณภาพต่ำ เราจึงใช้ตัวแยกประเภทกับตัวอย่างหน้าเว็บภาษาอังกฤษกว่าครึ่งพันล้านหน้า”
สิ่งที่พวกเขากำลังพูดคือพวกเขาพบว่าตัวแยกประเภทเดียวกันที่พัฒนาขึ้นเพื่อตรวจจับสำเนาที่ใช้ AI โดยใช้แบบจำลองเดียวกันในการสร้างสามารถใช้เพื่อตรวจจับเนื้อหาคุณภาพต่ำได้สำเร็จ
แน่นอนว่าสิ่งนี้ทำให้เรามีคำถามสำคัญ:
สาเหตุ นี้ (เช่น ระบบเลือกใช้งานเพราะมันดีจริงๆ) หรือ ความสัมพันธ์กัน (เช่น สแปมในปัจจุบันจำนวนมากสร้างขึ้นด้วยวิธีที่ง่ายต่อการใช้งานด้วยเครื่องมือที่ดีกว่า)
ก่อนที่เราจะสำรวจสิ่งนั้น เรามาดูผลงานของผู้เขียนบางส่วนและการค้นพบของพวกเขาก่อน
การตั้งค่า
สำหรับการอ้างอิง พวกเขาใช้สิ่งต่อไปนี้ในการทดสอบ:
- โมเดลการสร้างข้อความ 2 โมเดล ตัว ตรวจจับ GPT-2 ที่ใช้ RoBERTa ของ OpenAI (ตัวตรวจจับที่ใช้โมเดล RoBERTa พร้อมเอาต์พุต GPT-2 และคาดการณ์ว่าน่าจะสร้างโดย AI หรือไม่) และโมเดล GLTR ซึ่งเข้าถึงด้านบนได้ด้วย เอาต์พุต GPT-2 และทำงานในลักษณะเดียวกัน
เราสามารถดูตัวอย่างผลลัพธ์ของโมเดลนี้ได้ในเนื้อหาที่ฉันคัดลอกมาจากบทความด้านบน:
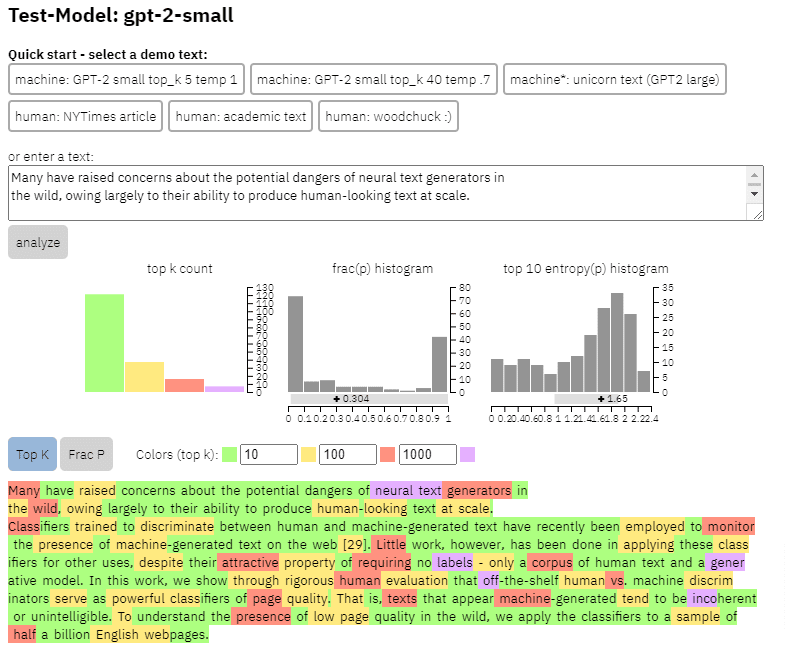
- ชุดข้อมูลสามชุด Web500M (การสุ่มตัวอย่างหน้าเว็บภาษาอังกฤษ 500 ล้านหน้า), เอาต์พุต GPT-2 (การสร้างข้อความ GPT-2 250k) และเอาต์พุต Grover (ชุดข้อมูลเหล่านี้สร้างบทความ 1.2 ล้านรายการภายในโดยใช้โมเดล Grover-Base ที่ผ่านการฝึกอบรมล่วงหน้า ซึ่งได้รับการออกแบบ เพื่อตรวจจับข่าวปลอม)
- Spam Baseline ซึ่งเป็นตัวแยกประเภทที่ได้รับการฝึกฝนในชุดข้อมูลอีเมลขยะของ Enron พวกเขาใช้ตัวแยกประเภทนี้เพื่อสร้างหมายเลขคุณภาพภาษาที่จะกำหนด ดังนั้นหากแบบจำลองระบุว่าเอกสารไม่ใช่สแปมโดยมีโอกาสเป็น 0.2 คะแนนคุณภาพภาษา (LQ) ที่กำหนดคือ 0.2
รับจดหมายข่าวรายวันที่นักการตลาดไว้วางใจ
ดูข้อกำหนด
นอกเหนือจากความแพร่หลายของสแปม
ฉันต้องการใช้เวลาสั้น ๆ เพื่อหารือเกี่ยวกับการค้นพบที่น่าสนใจบางอย่างที่ผู้เขียนพบ หนึ่งแสดงในรูปต่อไปนี้ (รูปที่ 3 จากกระดาษ):
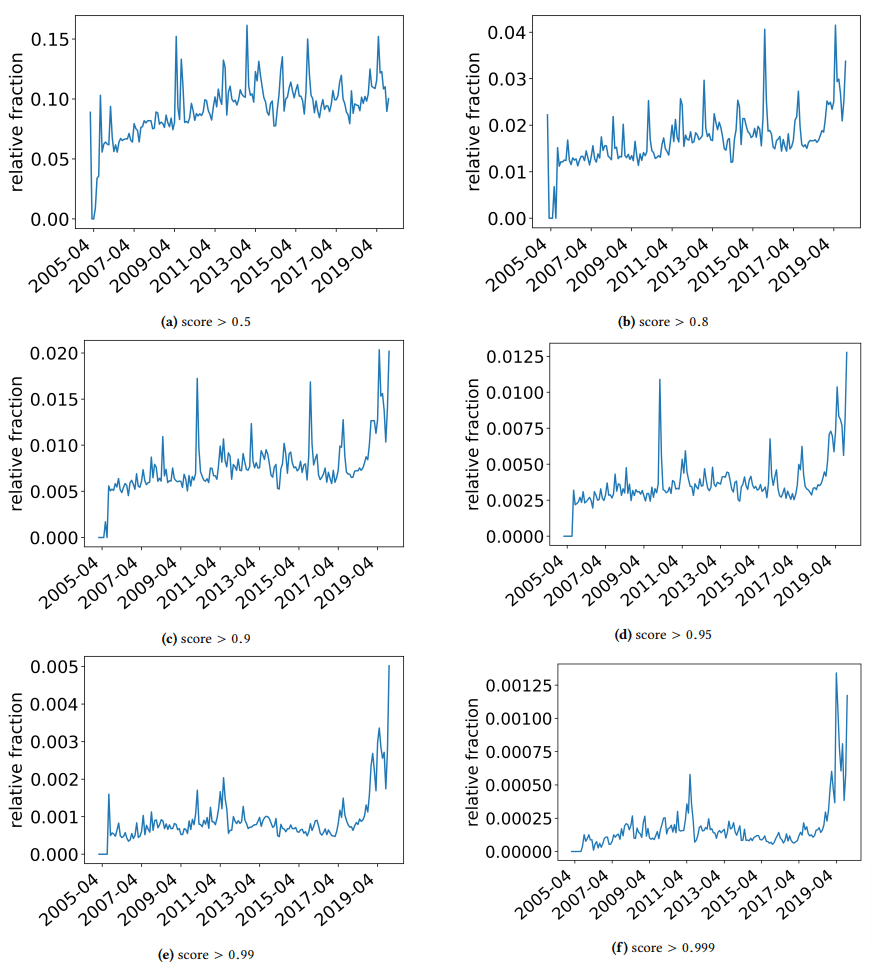
สิ่งสำคัญคือต้องสังเกตคะแนนด้านล่างแต่ละกราฟ ตัวเลขในเวอร์ชัน 1.0 กำลังเคลื่อนไปสู่ความมั่นใจว่าเนื้อหานั้นเป็นสแปม สิ่งที่เราเห็นคือตั้งแต่ปี 2017 เป็นต้นไป และเพิ่มขึ้นอย่างรวดเร็วในปี 2019 มีเอกสารคุณภาพต่ำแพร่หลาย
นอกจากนี้ พวกเขาพบว่าผลกระทบของเนื้อหาคุณภาพต่ำในบางภาคส่วนนั้นสูงกว่าภาคส่วนอื่น ๆ (โปรดจำไว้ว่าคะแนนที่สูงขึ้นแสดงถึงความเป็นไปได้ที่จะเกิดสแปม)
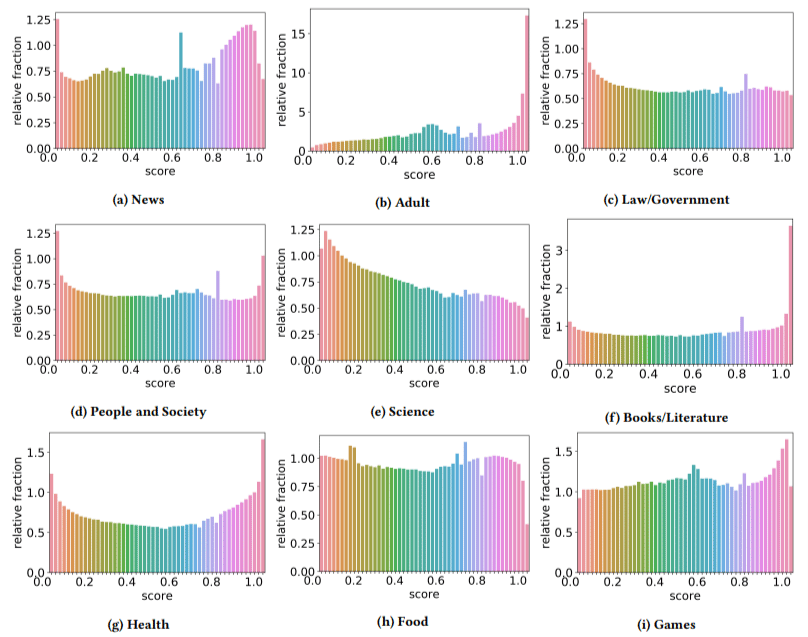
ฉันเกาหัวสองสามอัน ผู้ใหญ่มีเหตุผลแน่นอน
แต่หนังสือและวรรณกรรมเป็นเรื่องที่น่าประหลาดใจ สุขภาพก็เช่นกัน จนกระทั่งผู้เขียนเรียกไวอากร้าและไซต์ "ผลิตภัณฑ์เพื่อสุขภาพสำหรับผู้ใหญ่" อื่นๆ ว่า "สุขภาพ" และฟาร์มเรียงความว่าเป็น "วรรณกรรม" นั่นคือ
การค้นพบของพวกเขา
นอกเหนือจากที่เราได้พูดคุยกันเกี่ยวกับภาคส่วนต่าง ๆ และการเติบโตที่พุ่งสูงขึ้นในปี 2019 ผู้เขียนยังพบสิ่งที่น่าสนใจอีกมากมายที่นักทำ SEO สามารถเรียนรู้และต้องจดจำไว้ โดยเฉพาะอย่างยิ่งเมื่อเราเริ่มพึ่งพาเครื่องมืออย่าง ChatGPT
- เนื้อหาคุณภาพต่ำมักจะมีความยาวน้อยกว่า (สูงสุดที่ 3,000 ตัวอักษร)
- ระบบตรวจจับที่ได้รับการฝึกฝนมาเพื่อระบุว่าข้อความนั้นเขียนโดยเครื่องจักรหรือไม่ ยังดีในการจำแนกเนื้อหาระดับสูงและต่ำ
- พวกเขาเรียกเนื้อหาของเราที่ออกแบบมาสำหรับการจัดอันดับว่าเป็นผู้ร้ายเฉพาะ แต่ฉันสงสัยว่าพวกเขาหมายถึงถังขยะที่เราทุกคนรู้ว่าไม่ควรอยู่ที่นั่น
ผู้เขียนไม่ได้อ้างว่านี่เป็นวิธีแก้ปัญหาแบบ end-all-be-all แต่เป็นจุดเริ่มต้นและฉันแน่ใจว่าพวกเขาได้เลื่อนมาตรฐานไปข้างหน้าในช่วงสองสามปีที่ผ่านมา
หมายเหตุเกี่ยวกับเนื้อหาที่สร้างโดย AI
แบบจำลองภาษาได้พัฒนาขึ้นในช่วงหลายปีที่ผ่านมา ในขณะที่ GPT-3 มีอยู่ในขณะที่เขียนเอกสารนี้ ตัวตรวจจับที่พวกเขาใช้นั้นอิงตาม GPT-2 ซึ่งเป็นรุ่นที่ด้อยกว่ามาก
GPT-4 มีแนวโน้มว่าจะอยู่ใกล้ ๆ และ Sparrow ของ Google จะวางจำหน่ายในปลายปีนี้ ซึ่งหมายความว่าไม่เพียงแต่เทคโนโลยีจะดีขึ้นในทั้งสองด้านของสมรภูมิ (ตัวสร้างเนื้อหาเทียบกับเครื่องมือค้นหา) ชุดค่าผสมจะดึงเข้ามาเล่นได้ง่ายขึ้น
Google สามารถตรวจจับเนื้อหาที่สร้างโดย Sparrow หรือ GPT-4 ได้หรือไม่ อาจจะ.
แต่ถ้ามันถูกสร้างด้วย Sparrow แล้วส่งไปยัง GPT-4 พร้อมกับเขียนใหม่ล่ะ?
อีกปัจจัยหนึ่งที่ต้องจำไว้ก็คือเทคนิคที่ใช้ในเอกสารนี้อิงตามโมเดลการถดถอยอัตโนมัติ พูดง่ายๆ ก็คือ พวกเขาทำนายคะแนนของคำโดยอิงจากสิ่งที่พวกเขาจะทำนายคำนั้นโดยให้คำที่อยู่ข้างหน้าคำนั้น
เมื่อโมเดลพัฒนาความซับซ้อนในระดับที่สูงขึ้นและเริ่มสร้างแนวคิดทั้งหมดทีละคำแทนที่จะใช้คำอื่นตามด้วยคำอื่น การตรวจจับของ AI อาจลื่นไหล
ในทางกลับกัน การตรวจจับเนื้อหาที่ไร้สาระควรเพิ่มขึ้น ซึ่งอาจหมายความว่าเนื้อหาที่ "คุณภาพต่ำ" เท่านั้นที่จะชนะ สร้างขึ้นโดย AI
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่