
Hadoop ระบบนิเวศและส่วนประกอบ
เผยแพร่แล้ว: 2015-04-23บิ๊กดาต้าเป็นคำที่แพร่หลายในอุตสาหกรรมไอทีตั้งแต่ปี 2008 จำนวนข้อมูลที่สร้างขึ้นโดยเครือข่ายสังคมออนไลน์ การผลิต การค้าปลีก หุ้น โทรคมนาคม ประกันภัย การธนาคาร และอุตสาหกรรมการดูแลสุขภาพนั้นเหนือจินตนาการ
ก่อนการถือกำเนิดของ Hadoop การจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ถือเป็นความท้าทายครั้งใหญ่ แต่ตอนนี้ Hadoop พร้อมใช้งานแล้ว บริษัทต่างๆ ได้ตระหนักถึงผลกระทบทางธุรกิจของ Big Data และการทำความเข้าใจข้อมูลนี้จะขับเคลื่อนการเติบโตอย่างไร ตัวอย่างเช่น:
• ภาคการธนาคารมีโอกาสมากขึ้นที่จะเข้าใจลูกค้าประจำ ผู้ผิดนัดเงินกู้ และธุรกรรมการฉ้อโกง
• ภาคการค้าปลีกขณะนี้มีข้อมูลเพียงพอที่จะคาดการณ์อุปสงค์
• ภาคการผลิตไม่จำเป็นต้องพึ่งพากลไกราคาแพงสำหรับการทดสอบคุณภาพ การเก็บข้อมูลเซ็นเซอร์และการวิเคราะห์จะทำให้เห็นรูปแบบต่างๆ มากมาย
• อีคอมเมิร์ซ โซเชียลเน็ตเวิร์ก ปรับแต่งเพจตามความสนใจของลูกค้า
• ตลาดหุ้นสร้างข้อมูลจำนวนมหาศาล ซึ่งสัมพันธ์กันเป็นครั้งคราวจะเผยให้เห็นข้อมูลเชิงลึกที่สวยงาม
Big Data มีแอปพลิเคชั่นที่มีประโยชน์และชาญฉลาดมากมาย
Hadoop คือคำตอบสำหรับการประมวลผล Big Data ระบบนิเวศ Hadoop เป็นการผสมผสานระหว่างเทคโนโลยีที่มีความได้เปรียบในการแก้ปัญหาทางธุรกิจอย่างเชี่ยวชาญ
ให้เราเข้าใจส่วนประกอบใน Hadoop Ecosytem เพื่อสร้างโซลูชันที่เหมาะสมสำหรับปัญหาทางธุรกิจที่กำหนด
ระบบนิเวศ Hadoop:
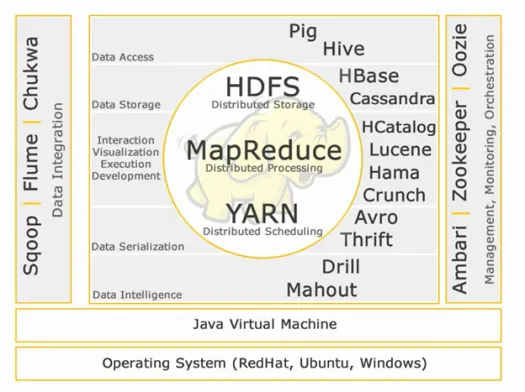

แกน Hadoop:
HDFS:
HDFS ย่อมาจาก Hadoop Distributed File System สำหรับจัดการชุดข้อมูลขนาดใหญ่ที่มีปริมาณมาก ความเร็ว และความหลากหลาย HDFS ใช้สถาปัตยกรรมมาสเตอร์ทาส มาสเตอร์คือโหนดชื่อและสเลฟคือโหนดข้อมูล
คุณสมบัติ:
• ปรับขนาดได้
• เชื่อถือได้
• สินค้าฮาร์ดแวร์
HDFS เป็นที่รู้จักกันดีสำหรับการจัดเก็บข้อมูลขนาดใหญ่
แผนที่ลด:
Map Reduce เป็นโมเดลการเขียนโปรแกรมที่ออกแบบมาเพื่อประมวลผลข้อมูลที่กระจายปริมาณมาก แพลตฟอร์มสร้างขึ้นโดยใช้ Java เพื่อการจัดการข้อยกเว้นที่ดียิ่งขึ้น แผนที่ลดประกอบด้วยสอง deamons ตัวติดตามงานและตัวติดตามงาน
คุณสมบัติ:
• ฟังก์ชั่นการเขียนโปรแกรม.
• ทำงานได้ดีกับ Big Data
• สามารถประมวลผลชุดข้อมูลขนาดใหญ่ได้
Map Reduce เป็นองค์ประกอบหลักที่รู้จักกันในการประมวลผลข้อมูลขนาดใหญ่
เส้นด้าย:
YARN ย่อมาจาก Yet Another Resource Negotiator เรียกอีกอย่างว่า MapReduce 2(MRv2) ฟังก์ชันการทำงานหลักสองอย่างของ Job Tracker ใน MRv1 การจัดการทรัพยากรและการจัดกำหนดการ/การตรวจสอบงานถูกแบ่งออกเป็น daemons แยกกัน ซึ่งได้แก่ ResourceManager, NodeManager และ ApplicationMaster
คุณสมบัติ:
• การจัดการทรัพยากรที่ดีขึ้น
• ความสามารถในการปรับขนาด
• การจัดสรรแบบไดนามิกของทรัพยากรคลัสเตอร์
การเข้าถึงข้อมูล:
หมู:
Apache Pig เป็นภาษาระดับสูงที่สร้างขึ้นบน MapReduce สำหรับการวิเคราะห์ชุดข้อมูลขนาดใหญ่ด้วยโปรแกรมวิเคราะห์ข้อมูลเฉพาะกิจอย่างง่าย หมูเรียกอีกอย่างว่าภาษา Data Flow มันถูกรวมเข้ากับ python ได้เป็นอย่างดี เริ่มแรกพัฒนาโดย yahoo
ลักษณะเด่นของหมู:
• ง่ายต่อการเขียนโปรแกรม
• โอกาสในการเพิ่มประสิทธิภาพ
• ความสามารถในการขยาย
สคริปต์หมูภายในจะถูกแปลงเป็นโปรแกรมลดแผนที่

รังผึ้ง:
Apache Hive เป็นภาษาการสืบค้นระดับสูงอีกภาษาหนึ่งและโครงสร้างพื้นฐานคลังข้อมูลที่สร้างขึ้นบน Hadoop สำหรับการสรุปข้อมูล การสืบค้น และการวิเคราะห์ เริ่มแรกพัฒนาโดย yahoo และทำโอเพ่นซอร์ส
ลักษณะเด่นของรังผึ้ง:
• SQL เช่นภาษาแบบสอบถามที่เรียกว่า HQL
• การแบ่งพาร์ติชั่นและบัคเก็ตเพื่อการประมวลผลข้อมูลที่รวดเร็วยิ่งขึ้น
• การผสานรวมกับเครื่องมือสร้างภาพ เช่น Tableau
แบบสอบถามไฮฟ์ภายในจะถูกแปลงเป็นโปรแกรมลดแผนที่
หากคุณต้องการเป็นนักวิเคราะห์ข้อมูลขนาดใหญ่ สองภาษาระดับสูงนี้ต้องรู้!!

การจัดเก็บข้อมูล:
เอชเบส:
Apache HBase เป็นฐานข้อมูล NoSQL ที่สร้างขึ้นสำหรับการโฮสต์ตารางขนาดใหญ่ที่มีแถวหลายพันล้านแถวและหลายล้านคอลัมน์บนเครื่องฮาร์ดแวร์สินค้า Hadoop ใช้ Apache Hbase เมื่อคุณต้องการการเข้าถึงข้อมูลขนาดใหญ่แบบสุ่มแบบเรียลไทม์เพื่ออ่าน/เขียน
คุณสมบัติ:
• อ่านและเขียนอย่างสม่ำเสมอ ในการทำงานของหน่วยความจำ
• ง่ายต่อการใช้ Java API สำหรับการเข้าถึงไคลเอ็นต์
• เข้ากันได้ดีกับหมู รัง และ sqoop
• เป็นระบบที่สม่ำเสมอและทนต่อการแบ่งพาร์ติชันในทฤษฎีบท CAP

แคสแซนดรา:
Cassandra เป็นฐานข้อมูล NoSQL ที่ออกแบบมาสำหรับความสามารถในการปรับขนาดเชิงเส้นและความพร้อมใช้งานสูง Cassandra อิงตามรูปแบบคีย์-ค่า พัฒนาโดย Facebook และเป็นที่รู้จักสำหรับการตอบสนองต่อคำถามได้เร็วขึ้น
คุณสมบัติ:
• ดัชนีคอลัมน์
• รองรับการดีนอร์มัลไลซ์เซชัน
• มุมมองที่เป็นรูปธรรม
• แคชในตัวที่ทรงพลัง

ปฏิสัมพันธ์ -การแสดงภาพ- การดำเนินการ-การพัฒนา:
แคตตาล็อก:
HCatalog เป็นเลเยอร์การจัดการตารางซึ่งให้การรวมข้อมูลเมตาของไฮฟ์สำหรับแอปพลิเคชัน Hadoop อื่นๆ ช่วยให้ผู้ใช้ที่มีเครื่องมือประมวลผลข้อมูลต่างๆ เช่น Apache pig, Apache MapReduce และ Apache Hive สามารถอ่านและเขียนข้อมูลได้ง่ายขึ้น

คุณสมบัติ:
• มุมมองแบบตารางสำหรับรูปแบบต่างๆ
• การแจ้งเตือนความพร้อมใช้งานของข้อมูล
• REST API สำหรับระบบภายนอกเพื่อเข้าถึงข้อมูลเมตา
ลูซีน:
Apache LuceneTM เป็นไลบรารีเครื่องมือค้นหาข้อความที่มีคุณสมบัติครบถ้วนและมีประสิทธิภาพสูง ซึ่งเขียนด้วยภาษาจาวาทั้งหมด เป็นเทคโนโลยีที่เหมาะสำหรับการใช้งานเกือบทุกประเภทที่ต้องการการค้นหาข้อความแบบเต็ม โดยเฉพาะอย่างยิ่งข้ามแพลตฟอร์ม
คุณสมบัติ:
• การจัดทำดัชนีประสิทธิภาพสูงที่ปรับขนาดได้
• อัลกอริธึมการค้นหาที่ทรงพลัง แม่นยำ และมีประสิทธิภาพ
• โซลูชั่นข้ามแพลตฟอร์ม
ฮามา:
Apache Hama เป็นเฟรมเวิร์กแบบกระจายตามการคำนวณแบบ Bulk Synchronous Parallel (BSP) มีความสามารถและเป็นที่รู้จักกันดีสำหรับการคำนวณทางวิทยาศาสตร์จำนวนมาก เช่น เมทริกซ์ กราฟ และอัลกอริธึมเครือข่าย
คุณสมบัติ:
• โมเดลการเขียนโปรแกรมอย่างง่าย
• เหมาะอย่างยิ่งสำหรับอัลกอริธึมแบบวนซ้ำ
• รองรับ YARN
• การกรองการทำงานร่วมกันโดยการเรียนรู้ของเครื่องโดยไม่ได้รับการดูแล
• การจัดกลุ่ม K-Means
กระทืบ:
Apache crunch ถูกสร้างขึ้นสำหรับการวางท่อโปรแกรม MapReduce ที่ง่ายและมีประสิทธิภาพ เฟรมเวิร์กนี้ใช้สำหรับเขียน ทดสอบ และเรียกใช้ไปป์ไลน์ MapReduce
คุณสมบัติ:
• นักพัฒนาที่เน้น
• นามธรรมน้อยที่สุด
• โมเดลข้อมูลที่ยืดหยุ่น
การจัดลำดับข้อมูล:
รว์:
Apache Avro เป็นเฟรมเวิร์กการจัดลำดับข้อมูลซึ่งเป็นกลางทางภาษา ออกแบบมาเพื่อการพกพาของภาษา ทำให้ข้อมูลมีอายุยืนกว่าภาษาที่จะอ่านและเขียนได้

ประหยัด:
Thrift เป็นภาษาที่พัฒนาขึ้นเพื่อสร้างอินเทอร์เฟซเพื่อโต้ตอบกับเทคโนโลยีที่สร้างบน Hadoop ใช้เพื่อกำหนดและสร้างบริการสำหรับหลายภาษา
ข้อมูลอัจฉริยะ:
เจาะ:
Apache Drill เป็นเอ็นจิ้นการสืบค้น SQL ที่มีความหน่วงต่ำสำหรับ Hadoop และ NoSQL
คุณสมบัติ:
• ความคล่องตัว
• ความยืดหยุ่น
• ความคุ้นเคย

ควาญ:
Apache Mahout เป็นไลบรารีแมชชีนเลิร์นนิงที่ปรับขนาดได้ซึ่งออกแบบมาเพื่อสร้างการวิเคราะห์เชิงคาดการณ์บน Big Data ตอนนี้ Mahout มีการใช้งาน apache spark เพื่อการประมวลผลหน่วยความจำที่เร็วขึ้น
คุณสมบัติ:
• การกรองการทำงานร่วมกัน
• การจำแนกประเภท
• การจัดกลุ่ม
• ลดขนาด

การรวมข้อมูล:
อาปาเช่ สควอป:

Apache Sqoop เป็นเครื่องมือที่ออกแบบมาสำหรับการถ่ายโอนข้อมูลจำนวนมากระหว่างฐานข้อมูลเชิงสัมพันธ์กับ Hadoop
คุณสมบัติ:
• นำเข้าและส่งออกไปยังและจาก HDFS
• นำเข้าและส่งออกไปยังและจากไฮฟ์
• นำเข้าและส่งออกไปยัง HBase
อาปาเช่ ฟลูม:
Flume เป็นบริการแบบกระจาย เชื่อถือได้ และพร้อมใช้งานสำหรับการรวบรวม รวบรวม และย้ายข้อมูลบันทึกจำนวนมากอย่างมีประสิทธิภาพ
คุณสมบัติ:
• แข็งแกร่ง
• ทนต่อความผิดพลาด
• สถาปัตยกรรมที่เรียบง่ายและยืดหยุ่นตามกระแสข้อมูลการสตรีม

อาปาเช่ ชุกวา:
ตัวรวบรวมบันทึกที่ปรับขนาดได้ใช้สำหรับการมอนิเตอร์ระบบไฟล์แบบกระจายขนาดใหญ่
คุณสมบัติ:
• ปรับขนาดเป็นหลายพันโหนด
• การจัดส่งที่เชื่อถือได้
• ควรจะสามารถเก็บข้อมูลได้อย่างไม่มีกำหนด

การจัดการ การตรวจสอบ และการประสาน:
อาปาเช่ แอมบารี:
Ambari ได้รับการออกแบบมาเพื่อให้การจัดการ Hadoop ง่ายขึ้นด้วยอินเทอร์เฟซสำหรับการจัดเตรียม จัดการ และตรวจสอบ Apache Hadoop Clusters
คุณสมบัติ:
• จัดเตรียม Hadoop Cluster
• จัดการคลัสเตอร์ Hadoop
• ตรวจสอบคลัสเตอร์ Hadoop

ผู้ดูแลสวนสัตว์ Apache:
Zookeeper เป็นบริการแบบรวมศูนย์ที่ออกแบบมาเพื่อรักษาข้อมูลการกำหนดค่า การตั้งชื่อ การซิงโครไนซ์แบบกระจาย และการให้บริการกลุ่ม
คุณสมบัติ:
• การทำให้เป็นอนุกรม
• อะตอมมิก
• ความน่าเชื่อถือ
• API แบบง่าย

อาปาเช่ อูซี่:
Oozie เป็นระบบกำหนดตารางเวลาเวิร์กโฟลว์เพื่อจัดการงาน Apache Hadoop
คุณสมบัติ:
• ระบบที่ปรับขนาดได้ เชื่อถือได้ และขยายได้
• รองรับงาน Hadoop หลายประเภท เช่น Map-Reduce, Hive, Pig และ Sqoop
• เรียบง่ายและใช้งานง่าย

เราจะหารือเกี่ยวกับส่วนประกอบโดยละเอียดในบทความต่อไป คอยติดตาม.