
การติดตั้ง Hadoop โดยใช้ Ambari
เผยแพร่แล้ว: 2015-12-11ทั้งหมดที่คุณต้องการรู้เกี่ยวกับการติดตั้ง Hadoop โดยใช้Ambari
Apache Hadoop ได้กลายเป็นซอฟต์แวร์เฟรมเวิร์กสำหรับการคำนวณที่เชื่อถือได้ ปรับขนาดได้ กระจายและมีขนาดใหญ่ ไม่เหมือนกับระบบคอมพิวเตอร์อื่น ๆ ที่นำการคำนวณมาสู่ข้อมูลมากกว่าการส่งข้อมูลไปยังการคำนวณ Hadoop ก่อตั้งขึ้นในปี 2549 ที่ Yahoo โดย Doug Cutting จากบทความที่ตีพิมพ์โดย Google เมื่อ Hadoop เติบโตเต็มที่ ในช่วงหลายปีที่ผ่านมามีการเพิ่มส่วนประกอบและเครื่องมือใหม่ๆ เข้าไปในระบบนิเวศเพื่อเพิ่มความสามารถในการใช้งานและฟังก์ชันการทำงาน Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop เป็นต้น เป็นต้น
ทำไมต้องแอมบารี?
ด้วยความนิยมที่เพิ่มขึ้นของ Hadoop นักพัฒนาจำนวนมากจึงกระโดดเข้าสู่เทคโนโลยีนี้เพื่อลิ้มรส แต่อย่างที่พวกเขาพูดกันว่า Hadoop นั้นไม่เหมาะกับคนขี้กลัว นักพัฒนาหลายคนไม่สามารถแม้แต่จะก้าวข้ามอุปสรรคในการติดตั้ง Hadoop ได้ การแจกแจงจำนวนมากเสนอแซนด์บ็อกซ์ของ VM ที่ติดตั้งไว้ล่วงหน้าเพื่อทดลองใช้งานต่างๆ แต่ไม่ได้ให้ความรู้สึกเหมือนเป็นการคำนวณแบบกระจาย อย่างไรก็ตาม การติดตั้งหลายโหนดไม่ใช่เรื่องง่าย และด้วยองค์ประกอบที่เพิ่มขึ้นเรื่อยๆ จึงเป็นเรื่องยากมากที่จะจัดการกับพารามิเตอร์การกำหนดค่าจำนวนมาก โชคดีที่ Apache Ambari มาที่นี่เพื่อช่วยเหลือเรา!
แอมบารีคืออะไร?
Apache Ambari เป็นเครื่องมือบนเว็บสำหรับการจัดเตรียม จัดการ และตรวจสอบคลัสเตอร์ Apache Hadoop Ambari จัดเตรียมแดชบอร์ดสำหรับการดูความสมบูรณ์ของคลัสเตอร์ เช่น แผนที่ความหนาแน่น และความสามารถในการดูแอปพลิเคชัน MapReduce, Pig และ Hive แบบเห็นภาพ พร้อมด้วยคุณลักษณะต่างๆ เพื่อวินิจฉัยคุณลักษณะด้านประสิทธิภาพในลักษณะที่เป็นมิตรต่อผู้ใช้ มี UI ที่เรียบง่ายและโต้ตอบได้เพื่อติดตั้งเครื่องมือต่างๆ และดำเนินการจัดการ กำหนดค่า และตรวจสอบต่างๆ ด้านล่างนี้ เราจะนำคุณผ่านขั้นตอนต่างๆ ในการติดตั้ง Hadoop และส่วนประกอบต่างๆ ของระบบนิเวศบนคลัสเตอร์แบบหลายโหนด
สถาปัตยกรรมอัมบารีแสดงอยู่ด้านล่าง
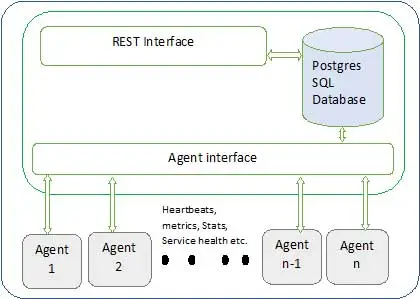
แอมบารีมีสององค์ประกอบ
- เซิร์ฟเวอร์ Ambari – นี่คือกระบวนการหลักที่สื่อสารกับตัวแทน Ambari ที่ติดตั้งบนแต่ละโหนดที่เข้าร่วมในคลัสเตอร์ มีอินสแตนซ์ฐานข้อมูล postgres ซึ่งใช้เพื่อรักษาข้อมูลเมตาที่เกี่ยวข้องกับคลัสเตอร์ทั้งหมด
- Ambari Agent – เป็นตัวแทนสำหรับ Ambari ในแต่ละโหนด ตัวแทนแต่ละรายจะส่งสถานะสุขภาพของตนเองเป็นระยะพร้อมกับตัวชี้วัดที่แตกต่างกัน สถานะบริการที่ติดตั้ง และอื่นๆ อีกมากมาย ตามที่อาจารย์ตัดสินใจดำเนินการต่อไปและแจ้งกลับไปให้ตัวแทนดำเนินการ
วิธีการติดตั้ง Ambari ?
การติดตั้ง Ambari ทำได้ง่ายเพียงไม่กี่คำสั่ง
เราจะครอบคลุมการติดตั้ง Ambari และการตั้งค่าคลัสเตอร์ เราถือว่ามี 4 โหนด โหนด1 โหนด2 โหนด3 และโหนด4 และเรากำลังเลือก Node1 เป็นเซิร์ฟเวอร์ Ambari ของเรา
นี่คือขั้นตอนการติดตั้งบนระบบที่ใช้ RHEL สำหรับขั้นตอนของระบบเดเบียนและระบบอื่นๆ จะแตกต่างกันเล็กน้อย
- การติดตั้งแอมบารี: –
จากโหนดเซิร์ฟเวอร์ Ambari (โหนด 1 ตามที่เราตัดสินใจ)
ฉัน. ดาวน์โหลดเอกสารสาธารณะของ Ambari

คำสั่งนี้จะเพิ่มที่เก็บ Hortonworks Ambari ลงใน yum ซึ่งเป็นตัวจัดการแพ็คเกจเริ่มต้นสำหรับระบบ RHEL
ii. ติดตั้ง Ambari RPMS

การดำเนินการนี้จะใช้เวลาสักครู่และจะติดตั้ง Ambari บนระบบนี้

สาม. การกำหนดค่าเซิร์ฟเวอร์ Ambari
สิ่งต่อไปที่ต้องทำหลังจากการติดตั้ง Ambari คือการกำหนดค่า Ambari และตั้งค่าเพื่อจัดเตรียมคลัสเตอร์
ขั้นตอนต่อไปนี้จะดูแลเรื่องนี้


iv เริ่มเซิร์ฟเวอร์และเข้าสู่ระบบเว็บ UI
เริ่มเซิร์ฟเวอร์ด้วย

ตอนนี้เราสามารถเข้าถึง UI เว็บของ Ambari (โฮสต์บนพอร์ต 8080)
เข้าสู่ระบบ Ambari ด้วยชื่อผู้ใช้เริ่มต้น "admin" และรหัสผ่านเริ่มต้น "admin"
การตั้งค่าคลัสเตอร์ Hadoop
1. หน้า Landing Page
คลิกที่ "Launch Install Wizard" เพื่อเริ่มการตั้งค่าคลัสเตอร์
2. ชื่อคลัสเตอร์
ให้คลัสเตอร์ชื่อที่ดี
หมายเหตุ: นี่เป็นเพียงชื่อธรรมดาสำหรับคลัสเตอร์ ไม่สำคัญนัก ดังนั้นอย่ากังวลและเลือกชื่อใดๆ สำหรับคลัสเตอร์
3. การเลือกกอง
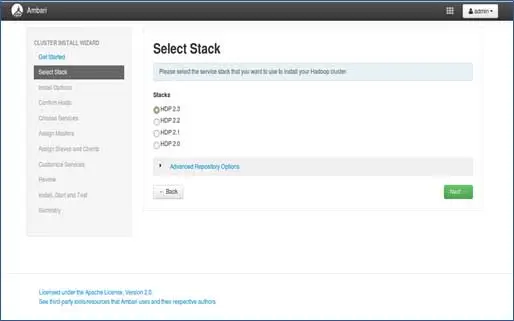
หน้านี้จะแสดงรายการสแต็กที่สามารถติดตั้งได้ แต่ละสแต็กได้รับการบรรจุไว้ล่วงหน้าด้วยองค์ประกอบระบบนิเวศ Hadoop กองเหล่านี้มาจาก Hortonworks (เราสามารถติดตั้ง Hadoop แบบธรรมดาได้ด้วย ซึ่งจะกล่าวถึงในโพสต์ต่อไป)
4. รายการโฮสต์และรายการคีย์ SSH

ก่อนที่จะดำเนินการต่อไปในขั้นตอนนี้ เราควรตั้งค่ารหัสผ่านน้อยกว่า SSH สำหรับโหนดที่เข้าร่วมทั้งหมด
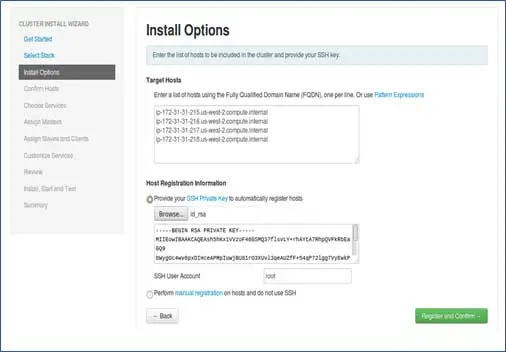
เพิ่มชื่อโฮสต์ของโหนด รายการเดียวในแต่ละบรรทัด [ เพิ่ม FQDN ซึ่งสามารถรับได้โดยชื่อโฮสต์ –f คำสั่ง] เลือกคีย์ส่วนตัวที่ใช้ในขณะที่ตั้งค่ารหัสผ่านน้อยกว่า SSH และชื่อผู้ใช้โดยใช้คีย์ส่วนตัวที่สร้าง
5. สถานะการลงทะเบียนโฮสต์
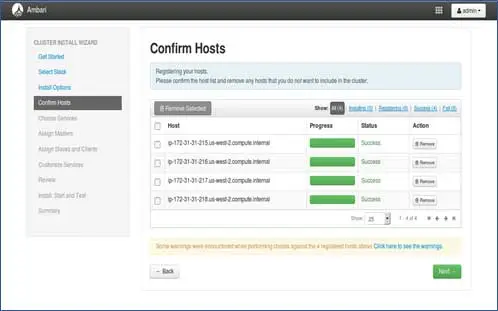
คุณสามารถดูการดำเนินการบางอย่างได้ การดำเนินการเหล่านี้รวมถึงการตั้งค่า Ambari-agent ในแต่ละโหนด การสร้างการตั้งค่าพื้นฐานในแต่ละโหนด เมื่อเราเห็น ALL GREEN เราก็พร้อมที่จะไปต่อ บางครั้งอาจต้องใช้เวลาเนื่องจากติดตั้งแพ็คเกจบางแพ็คเกจ

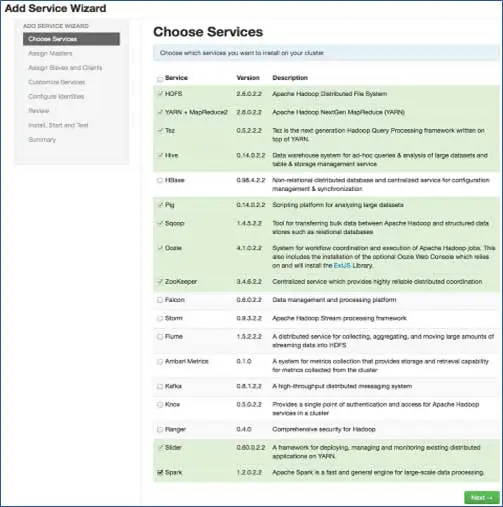
6. เลือกบริการที่คุณต้องการติดตั้ง
ตามสแต็กที่เลือกในขั้นตอนที่ 3 เรามีจำนวนบริการที่เราสามารถติดตั้งในคลัสเตอร์ได้ คุณสามารถเลือกสิ่งที่คุณต้องการ Ambari จะเลือกบริการที่ขึ้นต่อกันอย่างชาญฉลาดหากคุณยังไม่ได้เลือก ตัวอย่างเช่น คุณเลือก HBase แต่ไม่ใช่ Zookeeper ซึ่งระบบจะแจ้งแบบเดียวกันและจะเพิ่ม Zookeeper ลงในคลัสเตอร์ด้วย
7. การทำแผนที่บริการหลักด้วยโหนด
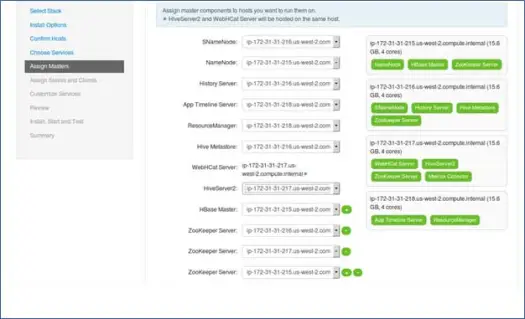
อย่างที่คุณทราบแล้วว่าระบบนิเวศ Hadoop มีเครื่องมือที่อิงตามสถาปัตยกรรมมาสเตอร์-ทาส ในขั้นตอนนี้ เราจะเชื่อมโยงกระบวนการหลักกับโหนด ตรวจสอบให้แน่ใจว่าคุณได้ปรับสมดุลคลัสเตอร์ของคุณอย่างเหมาะสม นอกจากนี้ โปรดทราบว่าบริการหลักและรอง เช่น Namenode และ Namenode รองไม่ได้อยู่ในเครื่องเดียวกัน

8. การทำแผนที่ทาสด้วยโหนด
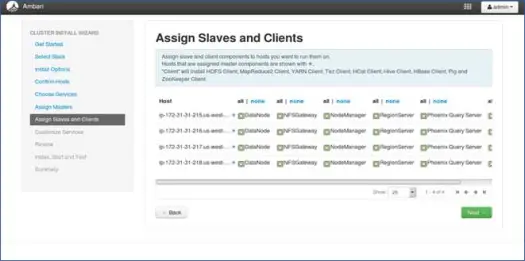
คล้ายกับมาสเตอร์ บริการแมปทาสบนโหนด โดยทั่วไป โหนดทั้งหมดจะมีกระบวนการทาสที่ทำงานอย่างน้อยสำหรับ Datanodes และ Nodemanagers
9. ปรับแต่งบริการ
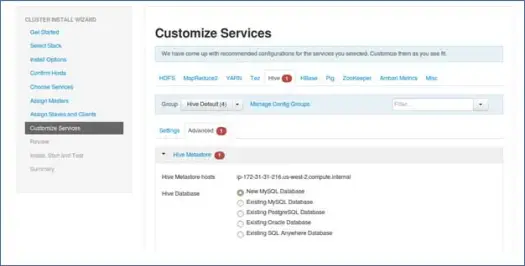
นี่เป็นหน้าที่สำคัญมากสำหรับผู้ดูแลระบบ
ที่นี่ คุณสามารถกำหนดค่าคุณสมบัติสำหรับคลัสเตอร์ของคุณเพื่อให้เหมาะสมกับกรณีการใช้งานของคุณมากที่สุด
นอกจากนี้ยังจะมีคุณสมบัติที่จำเป็นบางอย่างเช่นรหัสผ่าน Hive metastore (หากเลือกไฮฟ์) เป็นต้น สิ่งเหล่านี้จะชี้ด้วยข้อผิดพลาดสีแดงเช่นสัญลักษณ์
10. ตรวจสอบและเริ่มการจัดเตรียม
ตรวจสอบให้แน่ใจว่าคุณได้ตรวจสอบการกำหนดค่าคลัสเตอร์ก่อนเปิดตัว เนื่องจากจะช่วยประหยัดจากการกำหนดค่าที่ไม่ถูกต้องโดยไม่รู้ตัว
11. เปิดตัวและกลับมาจนกว่าสถานะจะเป็นสีเขียว
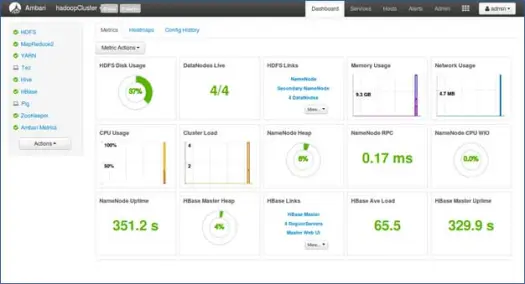
ขั้นตอนถัดไป
เย้! เราติดตั้ง Hadoop และส่วนประกอบทั้งหมดบนโหนดทั้งหมดของคลัสเตอร์สำเร็จแล้ว ตอนนี้เราสามารถเริ่มเล่น Hadoop ได้แล้ว
Ambari เรียกใช้งานการนับจำนวนคำของ MapReduce เพื่อตรวจสอบว่าทุกอย่างทำงานได้ดีหรือไม่ มาตรวจสอบบันทึกของงานที่ดำเนินการโดยผู้ใช้ ambari-qa
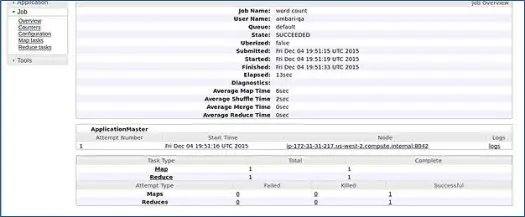
ดังที่คุณเห็นในภาพหน้าจอด้านบน งาน WordCount เสร็จสมบูรณ์ นี่เป็นการยืนยันว่าคลัสเตอร์ของเราทำงานได้ดี
บทสรุป
เพียงเท่านี้ เราก็ได้เรียนรู้วิธีการติดตั้ง Hadoop และส่วนประกอบบนคลัสเตอร์หลายโหนดโดยใช้เครื่องมือบนเว็บอย่างง่ายที่เรียกว่า Apache Ambari Apache Ambari มอบอินเทอร์เฟซที่ง่ายกว่าและช่วยประหยัดความพยายามในการติดตั้ง การตรวจสอบ และการจัดการ ซึ่งอาจสร้างความยุ่งยากให้กับส่วนประกอบจำนวนมาก ตลอดจนขั้นตอนการติดตั้งและการควบคุมการตรวจสอบที่แตกต่างกัน
ให้ฉันปล่อยให้คุณกับแฮ็ค

โปรแกรมติดตั้ง Ambari ตรวจสอบ /etc/lsb-release เพื่อรับรายละเอียดของระบบปฏิบัติการ ใน Linux Mint ไฟล์เดียวกันสำหรับเวอร์ชัน Ubuntu อยู่ภายใต้ /etc/upstream-release/lsb-release เพื่อหลอกตัวติดตั้ง เพียงแทนที่อันแรกด้วยอันหลัง (คุณควรสำรองไฟล์ไว้ก่อน)

เมื่อติดตั้งเสร็จแล้ว คุณสามารถกู้คืนต้นฉบับด้วย:

ป.ล. นี่เป็นแฮ็คที่ไม่มีการรับประกันใด ๆ มันใช้งานได้สำหรับฉัน ฉันคิดว่าจะแบ่งปันกับคุณ
คุณเป็นนักพัฒนา/dev-ops และจำเป็นต้องติดตั้ง Hadoop อย่างรวดเร็ว เรามีข่าวดีมาบอก Ambari นำเสนอวิธีที่คุณสามารถข้ามขั้นตอนของวิซาร์ดทั้งหมดและดำเนินการติดตั้งให้เสร็จสิ้นด้วยสคริปต์ตัวเดียว และฉันจะนำมันมาให้ในโพสต์ถัดไป ดังนั้นโปรดอดใจรอจนกว่าจะถึง Happy Hadooping!