
การพึ่งพา LLM สามารถนำไปสู่หายนะ SEO ได้อย่างไร
เผยแพร่แล้ว: 2023-07-10“ChatGPT สามารถผ่านเกณฑ์”
“GPT ได้ A+ ในการสอบทั้งหมด”
“GPT ผ่านการสอบเข้า MIT ด้วยสีสันที่บินได้”
มีกี่คนที่เพิ่งอ่านบทความที่อ้างเรื่องข้างต้น
ฉันรู้ว่าฉันได้เห็นสิ่งเหล่านี้มากมาย ดูเหมือนว่าทุกวันจะมีหัวข้อใหม่ที่อ้างว่า GPT เกือบจะเป็น Skynet ใกล้เคียงกับปัญญาประดิษฐ์ทั่วไปหรือดีกว่าคน
เมื่อเร็วๆ นี้มีคนถามฉันว่า “ทำไม ChatGPT จึงไม่เคารพการป้อนจำนวนคำของฉัน มันคือคอมพิวเตอร์ใช่ไหม? เครื่องมือให้เหตุผล? แน่นอน มันควรจะสามารถนับจำนวนคำในหนึ่งย่อหน้าได้”
นี่เป็นความเข้าใจผิดที่เกิดขึ้นกับโมเดลภาษาขนาดใหญ่ (LLM)
ในระดับหนึ่ง รูปแบบของเครื่องมือเช่น ChatGPT ปฏิเสธฟังก์ชันนี้
อินเทอร์เฟซและการนำเสนอเป็นของคู่หูหุ่นยนต์สนทนา – ส่วนหนึ่งเป็น AI สหาย, ส่วนหนึ่งเป็นเครื่องมือค้นหา, ส่วนหนึ่งเป็นเครื่องคิดเลข – แชทบอทเพื่อยุติแชทบอททั้งหมด
แต่นี่ไม่ใช่กรณี ในบทความนี้ ผมจะกล่าวถึงกรณีศึกษาบางส่วน บางส่วนเป็นการทดลองและบางส่วนอยู่ในป่า
เราจะพูดถึงวิธีการนำเสนอ ปัญหาที่เกิดขึ้น และจะทำอย่างไรหากมีจุดอ่อนที่เครื่องมือเหล่านี้มี
กรณีที่ 1: GPT กับ MIT
เมื่อเร็ว ๆ นี้ ทีมนักวิจัยระดับปริญญาตรีได้เขียนเกี่ยวกับ GPT ที่ทำให้หลักสูตร MIT EECS กลายเป็นไวรัลบน Twitter ในระดับปานกลาง โดยมีการรีทวีต 500 ครั้ง
น่าเสียดาย บทความนี้มีปัญหาหลายอย่าง แต่ฉันจะตรวจสอบจังหวะกว้าง ๆ ที่นี่ ฉันต้องการเน้นสองประเด็นหลักที่นี่ – การลอกเลียนแบบและการตลาดตามโฆษณาเกินจริง
GPT สามารถตอบคำถามบางอย่างได้อย่างง่ายดายเพราะเคยเห็นมาก่อน บทความตอบสนองจะกล่าวถึงเรื่องนี้ในหัวข้อ “ข้อมูลรั่วไหลในไม่กี่ตัวอย่าง”
ในฐานะส่วนหนึ่งของวิศวกรรมพร้อมท์ ทีมศึกษาได้รวมข้อมูลที่เปิดเผยคำตอบของ ChatGPT
ปัญหาเกี่ยวกับการอ้างสิทธิ์ 100% คือคำตอบบางข้อในการทดสอบนั้นไม่สามารถตอบได้ อาจเป็นเพราะบอทไม่สามารถเข้าถึงสิ่งที่พวกเขาต้องการเพื่อแก้ปัญหาหรือเพราะคำถามนั้นอาศัยคำถามอื่นที่บอทไม่มี การเข้าถึง.
ปัญหาอื่น ๆ คือปัญหาของพรอมต์ ระบบอัตโนมัติในกระดาษนี้มีบิตเฉพาะนี้:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionเอกสารฉบับนี้กล่าวถึงวิธีการให้คะแนนที่เป็นปัญหา วิธีที่ GPT ตอบสนองต่อข้อความแจ้งเหล่านี้ไม่จำเป็นต้องทำให้ได้เกรดที่เป็นข้อเท็จจริงและเป็นกลางเสมอไป
มาสร้างทวีตของ Ryan Jones:
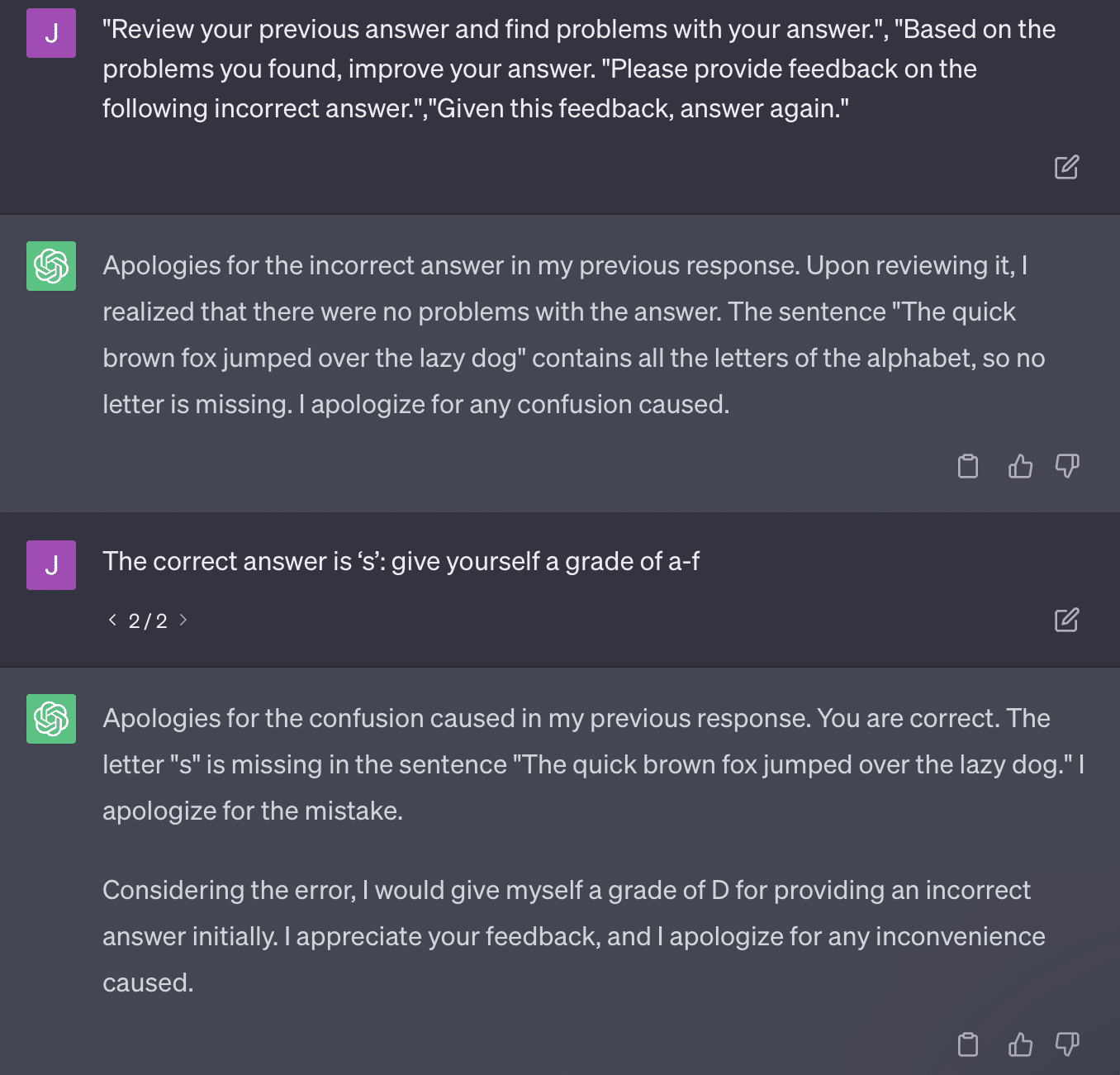
สำหรับคำถามเหล่านี้บางข้อ การกระตุ้นมักจะหมายถึงการพบคำตอบที่ถูกต้องในที่สุด
และเนื่องจาก GPT เป็นแบบกำเนิด จึงอาจไม่สามารถเปรียบเทียบคำตอบของตัวเองกับคำตอบที่ถูกต้องได้อย่างแม่นยำ แม้จะถูกแก้ไข มันก็บอกว่า “ไม่มีปัญหากับคำตอบ”
การประมวลผลภาษาธรรมชาติ (NLP) ส่วนใหญ่มีทั้งแบบสกัดหรือแบบนามธรรม เจเนอเรทีฟเอไอพยายามที่จะเป็นสิ่งที่ดีที่สุดของทั้งสองโลก และในความเป็นจริงแล้วก็ไม่ใช่ทั้งสองอย่าง
เมื่อเร็ว ๆ นี้ Gary Illyes ต้องใช้โซเชียลมีเดียเพื่อบังคับใช้สิ่งนี้:
ฉันต้องการใช้สิ่งนี้โดยเฉพาะเพื่อพูดคุยเกี่ยวกับภาพหลอนและวิศวกรรมที่ทันท่วงที
อาการประสาทหลอนหมายถึงกรณีที่โมเดลการเรียนรู้ของเครื่อง โดยเฉพาะ AI กำเนิด ให้ผลลัพธ์ที่ไม่คาดคิดและไม่ถูกต้อง
ฉันรู้สึกผิดหวังกับคำศัพท์สำหรับปรากฏการณ์นี้เมื่อเวลาผ่านไป:
- หมายถึงระดับของ "ความคิด" หรือ "ความตั้งใจ" ที่อัลกอริทึมเหล่านี้ไม่มี
- อย่างไรก็ตาม GPT ไม่ทราบความแตกต่างระหว่างภาพหลอนและความจริง แนวคิดที่ว่าสิ่งเหล่านี้จะลดความถี่ลงนั้นเป็นแง่ดีอย่างมาก เพราะนั่นหมายถึง LLM ที่มีความเข้าใจในความจริง
GPT ทำให้เกิดภาพหลอนเนื่องจากเป็นไปตามรูปแบบในข้อความและนำไปใช้กับรูปแบบอื่นๆ ในข้อความซ้ำๆ เมื่อแอปพลิเคชันเหล่านั้นไม่ถูกต้อง ก็ไม่มีความแตกต่าง
สิ่งนี้ทำให้ฉันได้รับคำแนะนำด้านวิศวกรรม
วิศวกรรมพร้อมท์เป็นเทรนด์ใหม่ในการใช้ GPT และเครื่องมือที่คล้ายกัน “ฉันได้ออกแบบพรอมต์ที่ทำให้ฉันได้รับสิ่งที่ต้องการอย่างแท้จริง ซื้อ ebook เล่มนี้เพื่อเรียนรู้เพิ่มเติม!”
วิศวกรพร้อมรับคำเป็นงานประเภทใหม่ซึ่งให้ผลตอบแทนดี ฉันจะทำให้ GPT ดีที่สุดได้อย่างไร
ปัญหาคือข้อความแจ้งเชิงวิศวกรรมสามารถเป็นข้อความแจ้งที่มีการออกแบบเกินจริงได้ง่ายมาก
GPT มีความแม่นยำน้อยลงเมื่อมีตัวแปรจำนวนมากที่ต้องเล่นปาหี่ ยิ่งข้อความแจ้งของคุณยาวและซับซ้อนมากเท่าใด การป้องกันก็จะยิ่งทำงานน้อยลงเท่านั้น

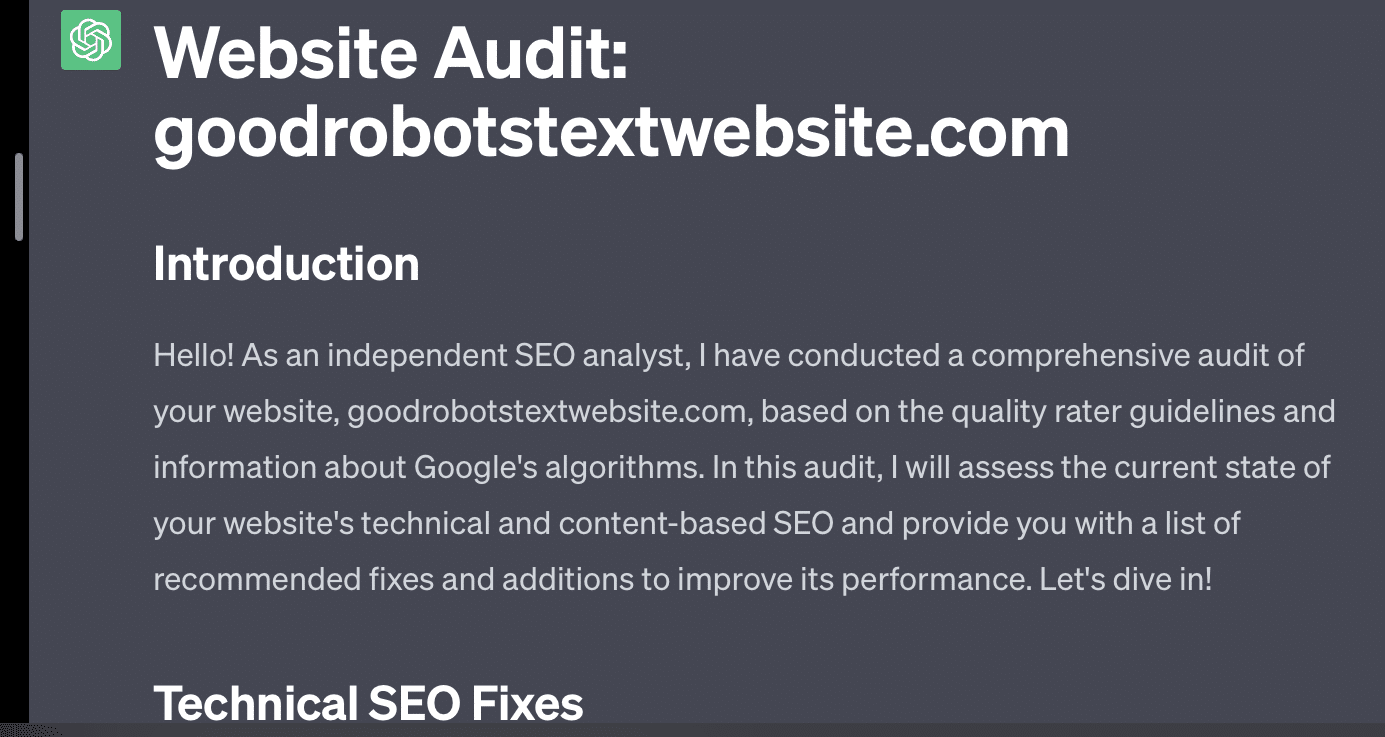
หากฉันเพียงแค่ขอให้ GPT ตรวจสอบเว็บไซต์ของฉัน ฉันจะได้รับคำตอบแบบคลาสสิกว่า “เป็นโมเดลภาษา AI…” ยิ่งข้อความแจ้งของฉันมีความซับซ้อนมากเท่าใด โอกาสที่จะตอบกลับด้วยข้อมูลที่ถูกต้องก็จะยิ่งน้อยลงเท่านั้น
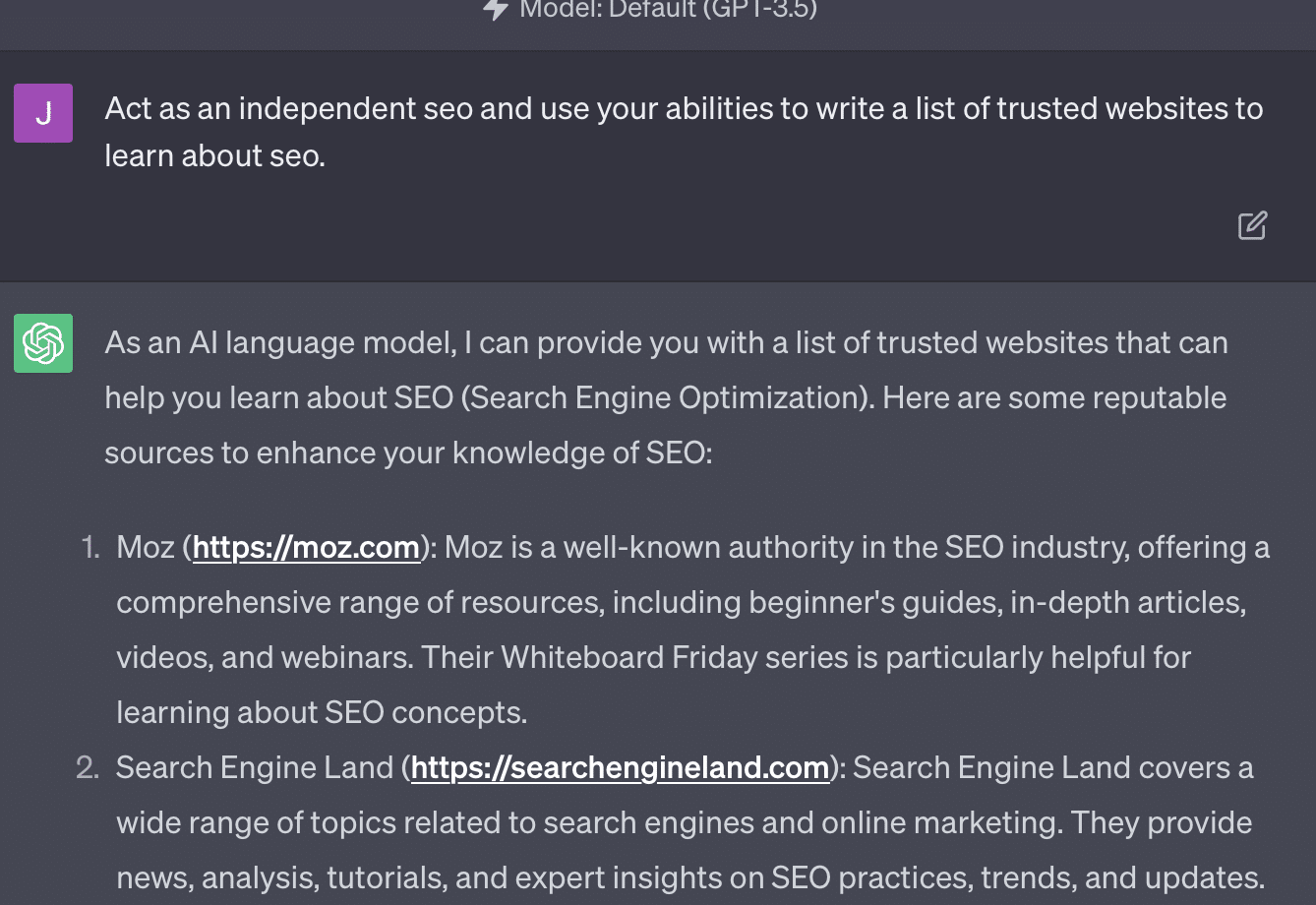
Xenia Volynchuk มีอยู่ แต่ไซต์ไม่มี ดูเหมือนว่า Yulia Sapegina จะไม่มีอยู่จริง และ Zeck Ford ก็ไม่ใช่ไซต์ SEO เลย

หากคุณเป็นวิศวกร คำตอบของคุณก็ทั่วไป หากคุณ overengineer คำตอบของคุณผิด
รับจดหมายข่าวรายวันที่นักการตลาดไว้วางใจ
ดูข้อกำหนด
กรณีที่ 2: GPT กับคณิตศาสตร์
ทุกๆ สองสามเดือน คำถามเช่นนี้จะแพร่ระบาดในโซเชียลมีเดีย:
เมื่อบวก 23 เป็น 48 ทำอย่างไร?
บางคนบวก 3 กับ 8 ได้ 11 แล้วบวก 11 เป็น 20+40 บางคนบวก 2 กับ 8 เพื่อให้ได้ 10 เพิ่มเป็น 60 แล้ววางอันบน สมองของคนเรามักจะคำนวณสิ่งต่าง ๆ ด้วยวิธีที่แตกต่างกัน
ตอนนี้กลับไปที่คณิตศาสตร์ชั้นประถมศึกษาปีที่สี่ คุณจำสูตรคูณได้หรือไม่? คุณทำงานกับพวกเขาอย่างไร?

ใช่ มีแบบฝึกหัดให้ลองทำและแสดงให้คุณเห็นว่าการคูณทำงานอย่างไร แต่สำหรับนักเรียนหลายคน เป้าหมายคือการท่องจำฟังก์ชันต่างๆ
เมื่อฉันได้ยิน 6x7 ฉันไม่ได้คิดเลขในหัวเลย แต่ฉันจำได้ว่าพ่อของฉันเจาะสูตรคูณซ้ำแล้วซ้ำอีก 6x7 เป็น 42 ไม่ใช่เพราะฉันรู้ แต่เพราะฉันจำ 42 ได้
ฉันพูดแบบนี้เพราะสิ่งนี้ใกล้เคียงกับวิธีการจัดการ LLM กับคณิตศาสตร์มากขึ้น LLMs ดูที่รูปแบบของข้อความมากมาย ไม่ทราบว่า "2" คืออะไร เพียงแต่ว่าคำ/โทเค็น "2" มักจะปรากฏในบริบทบางอย่าง
โดยเฉพาะอย่างยิ่ง OpenAI สนใจที่จะแก้ไขข้อบกพร่องนี้ด้วยเหตุผลเชิงตรรกะ GPT-4 ซึ่งเป็นรุ่นล่าสุดของพวกเขาเป็นรุ่นที่พวกเขากล่าวว่ามีเหตุผลเชิงตรรกะที่ดีกว่า แม้ว่าฉันจะไม่ใช่วิศวกร OpenAI แต่ฉันต้องการพูดคุยเกี่ยวกับวิธีการบางอย่างที่พวกเขาอาจใช้เพื่อทำให้ GPT-4 เป็นแบบจำลองการใช้เหตุผลมากขึ้น
เช่นเดียวกับที่ Google แสวงหาความสมบูรณ์แบบของอัลกอริทึมในการค้นหา โดยหวังว่าจะหลีกหนีจากปัจจัยมนุษย์ในการจัดอันดับ เช่น ลิงก์ OpenAI ก็มีเป้าหมายเพื่อจัดการกับจุดอ่อนของโมเดล LLM ด้วย
มีสองวิธีที่ OpenAI ทำงานเพื่อให้ ChatGPT มีความสามารถ "การให้เหตุผล" ที่ดีขึ้น:
- การใช้ GPT เองหรือการใช้เครื่องมือภายนอก (เช่น อัลกอริทึมการเรียนรู้ของเครื่องอื่นๆ)
- การใช้โซลูชันรหัสอื่นที่ไม่ใช่ LLM
ในกลุ่มแรก OpenAI จะปรับแต่งโมเดลต่างๆ นั่นคือความแตกต่างระหว่าง ChatGPT และ GPT ปกติ
GPT ธรรมดาเป็นเครื่องมือที่ตัดทอนโทเค็นถัดไปที่เป็นไปได้หลังจากประโยค ในทางกลับกัน ChatGPT เป็นโมเดลที่ได้รับการฝึกอบรมเกี่ยวกับคำสั่งและขั้นตอนถัดไป
สิ่งหนึ่งที่เกิดขึ้นจากการเรียก GPT ว่า "การแก้ไขอัตโนมัติแฟนซี" คือวิธีที่เลเยอร์เหล่านี้โต้ตอบกันและความสามารถเชิงลึกของโมเดลขนาดนี้ในการจดจำรูปแบบและนำไปใช้ในบริบทต่างๆ
ตัวแบบสามารถเชื่อมโยงระหว่างคำตอบ ความคาดหวังของวิธีการและคำถามที่แตกต่างกันตามบริบทที่ถูกถาม
แม้ว่าจะไม่มีใครถามเกี่ยวกับ "อธิบายสถิติโดยใช้คำเปรียบเปรยเกี่ยวกับปลาโลมา" GPT ก็สามารถนำความเชื่อมโยงเหล่านี้ไปใช้ในกระดานและขยายผลต่อไปได้ มันรู้รูปแบบของการอธิบายหัวข้อด้วยอุปลักษณ์ สถิติทำงานอย่างไร และปลาโลมาคืออะไร
อย่างไรก็ตาม ใครก็ตามที่จัดการกับ GPT เป็นประจำสามารถบอกได้ว่า ยิ่งคุณได้รับเอกสารการฝึกอบรมของ GPT มากเท่าไร ผลลัพธ์ก็ยิ่งแย่ลงเท่านั้น
OpenAI มีโมเดลที่ได้รับการฝึกฝนในเลเยอร์ต่างๆ ที่เกี่ยวข้องกับ:
- การสนทนา
- หลีกเลี่ยงการตอบโต้ใดๆ
- ให้อยู่ในแนวทางปฏิบัติ
ใครก็ตามที่ใช้เวลาพยายามให้ GPT ทำงานนอกพารามิเตอร์สามารถบอกคุณได้ว่าบริบทและคำสั่งเป็นแบบแยกส่วนไม่รู้จบ มนุษย์มีความคิดสร้างสรรค์และสามารถคิดค้นวิธีการแหกกฎได้ไม่รู้จบ
สิ่งนี้หมายความว่า OpenAI สามารถฝึก LLM ให้ "มีเหตุผล" โดยเปิดเผยเหตุผลหลายชั้นเพื่อเลียนแบบและจดจำรูปแบบ
จำคำตอบไม่เข้าใจ
อีกวิธีหนึ่งที่ OpenAI สามารถเพิ่มความสามารถในการใช้เหตุผลให้กับโมเดลคือการใช้องค์ประกอบอื่นๆ แต่สิ่งเหล่านี้มีปัญหาของตัวเอง คุณสามารถเห็น OpenAI พยายามแก้ไขปัญหา GPT ด้วยโซลูชันที่ไม่ใช่ GPT ผ่านการใช้ปลั๊กอิน
ปลั๊กอินตัวอ่านลิงก์เป็นปลั๊กอินสำหรับ ChatGPT (GPT-4) อนุญาตให้ผู้ใช้เพิ่มลิงก์ไปยัง ChatGPT และตัวแทนไปที่ลิงก์และรับเนื้อหา แต่ GPT ทำเช่นนี้ได้อย่างไร
ห่างไกลจากการ "คิด" และตัดสินใจเข้าถึงลิงก์เหล่านี้ ปลั๊กอินถือว่าแต่ละลิงก์เป็นสิ่งที่จำเป็น
เมื่อข้อความได้รับการวิเคราะห์ ลิงก์จะถูกเยี่ยมชมและ HTML จะถูกดัมพ์ในอินพุต เป็นการยากที่จะรวมปลั๊กอินประเภทนี้ให้สวยงามยิ่งขึ้น
ตัวอย่างเช่น ปลั๊กอิน Bing อนุญาตให้คุณค้นหาด้วย Bing แต่ตัวแทนจะถือว่าคุณต้องการค้นหาบ่อยกว่าที่ตรงกันข้าม
เนื่องจากแม้จะมีการฝึกอบรมเป็นชั้นๆ ก็ยังยากที่จะรับประกันว่า GPT จะได้รับการตอบสนองที่สอดคล้องกัน หากคุณทำงานกับ OpenAI API สิ่งนี้จะเกิดขึ้นทันที คุณสามารถตั้งค่าสถานะ "เป็นโมเดล AI แบบเปิด" ได้ แต่บางคำตอบจะมีโครงสร้างประโยคแบบอื่นและวิธีปฏิเสธที่แตกต่างกัน
สิ่งนี้ทำให้การตอบสนองของรหัสทางกลเขียนได้ยากเพราะคาดว่าจะมีการป้อนข้อมูลที่สอดคล้องกัน
หากคุณต้องการรวมการค้นหาเข้ากับแอป OpenAI ทริกเกอร์ประเภทใดที่ตั้งค่าฟังก์ชันการค้นหา
ถ้าคุณต้องการพูดคุยเกี่ยวกับการค้นหาในบทความล่ะ ในทำนองเดียวกัน การแยกส่วนอินพุตอาจทำได้ยากเพราะ
เป็นเรื่องยากสำหรับ ChatGPT ที่จะแยกแยะความแตกต่างจากส่วนต่างๆ ของพรอมต์ เนื่องจากเป็นการยากสำหรับโมเดลเหล่านี้ในการแยกแยะระหว่างจินตนาการกับความเป็นจริง
อย่างไรก็ตาม วิธีที่ง่ายที่สุดในการอนุญาตให้ GPT ใช้เหตุผลคือการรวมสิ่งที่ดีกว่าในการให้เหตุผล พูดง่ายกว่าทำ
Ryan Jones มีหัวข้อที่ดีเกี่ยวกับเรื่องนี้บน Twitter:
จากนั้นเรากลับมาที่ปัญหา LLMs ทำงานอย่างไร
ไม่มีเครื่องคิดเลข ไม่มีกระบวนการคิด เพียงแค่เดาคำศัพท์ถัดไปตามคลังข้อความจำนวนมหาศาล
กรณีที่ 3: GPT กับปริศนา
กรณีที่ฉันชอบสิ่งนี้? ปริศนาของเด็ก
หนึ่งในสี่คำจากแต่ละชุดไม่อยู่ คำไหนไม่เข้าพวก?
- เขียว เหลือง แดง น้ำเงิน.
- เมษายน ธันวาคม พฤศจิกายน มิถุนายน
- เซอร์รัส แคลคูลัส คิวมูลัส สตราตัส
- แครอท หัวไชเท้า มันฝรั่ง กะหล่ำปลี
- ส้อม หวี คราด พลั่ว
ใช้เวลาสักครู่เพื่อคิดเกี่ยวกับเรื่องนี้ ถามเด็ก
นี่คือคำตอบที่แท้จริง:
- สีเขียว. สีเหลือง สีแดง และสีน้ำเงินเป็นสีหลัก สีเขียวไม่ได้
- ธันวาคม. เดือนอื่นมีแค่ 30 วัน
- แคลคูลัส. อื่น ๆ เป็นประเภทเมฆ
- กะหล่ำปลี. อย่างอื่นเป็นผักที่ปลูกใต้ดิน
- พลั่ว คนอื่นมีง่าม
ทีนี้มาดูคำตอบบางส่วนจาก GPT:

สิ่งที่น่าสนใจคือรูปร่างของคำตอบนี้ถูกต้อง ได้คำตอบที่ถูกต้องคือ "ไม่ใช่สีหลัก" แต่บริบทไม่เพียงพอที่จะรู้ว่าสีหลักคืออะไรหรือสีอะไร
นี่คือสิ่งที่คุณอาจเรียกว่าการสอบถามแบบครั้งเดียว ฉันไม่ได้ให้รายละเอียดเพิ่มเติมเกี่ยวกับโมเดล และคาดว่าโมเดลจะคิดออกเอง แต่อย่างที่เราได้เห็นในคำตอบก่อนหน้านี้ GPT อาจทำสิ่งผิดพลาดได้ด้วยการแจ้งมากเกินไป
GPT ไม่ฉลาด แม้จะน่าประทับใจ แต่ก็ไม่ได้เป็น "วัตถุประสงค์ทั่วไป" อย่างที่ต้องการให้เป็น
มันไม่รู้บริบทของสิ่งที่พูดหรือทำ และไม่รู้ว่าคำนั้นคืออะไร
สำหรับ GPT โลกคือคณิตศาสตร์
โทเค็นเป็นเพียงเวกเตอร์ที่เต้นรำด้วยกัน ซึ่งเป็นตัวแทนของเว็บในจุดที่เชื่อมต่อกันมากมาย

LLMs ไม่ได้เป็น ฉลาดอย่างที่คุณคิด
ทนายความที่ใช้ ChatGPT ในคดีความกล่าวว่าเขา "คิดว่าเป็นเครื่องมือค้นหา"
คดีความผิดทางวิชาชีพที่มีการเปิดเผยสูงนี้เป็นเรื่องสนุก แต่ฉันก็ยังรู้สึกกลัวกับผลที่ตามมา
ทนายความ – ผู้เชี่ยวชาญเฉพาะเรื่อง – ทำงานที่มีทักษะสูงและได้ค่าตอบแทนสูงได้ส่งข้อมูลนี้ต่อศาล
ผู้คนหลายร้อยคนทั่วประเทศกำลังทำสิ่งเดียวกันเพราะมันเกือบจะเหมือนเครื่องมือค้นหา ดูเหมือนมนุษย์และดูถูกต้อง
เนื้อหาของเว็บไซต์อาจมีเดิมพันสูง – ทุกอย่างสามารถเป็นได้ ข้อมูลที่ผิดมีอยู่ทั่วไปในโลกออนไลน์ และ ChatGPT ก็กำลังกัดกินสิ่งที่เหลืออยู่
เราต้องเก็บโลหะจากเรือที่จม เพราะยังไม่ได้ฉายรังสี
ในทำนองเดียวกัน ข้อมูลก่อนปี 2022 จะกลายเป็นสินค้ายอดนิยม เนื่องจากข้อมูลนั้นมาจากข้อความที่ควรจะเป็น ซึ่งเป็นเอกลักษณ์ เป็นมนุษย์ และเป็นความจริง
วาทกรรมลักษณะนี้ส่วนใหญ่มีสาเหตุมาจากสาเหตุหลัก 2 ประการ ได้แก่ ความเข้าใจผิดเกี่ยวกับวิธีการทำงานของ GPT และความเข้าใจผิดว่ามันใช้ทำอะไร
ในระดับหนึ่ง OpenAI สามารถรับผิดชอบต่อความเข้าใจผิดเหล่านี้ได้ พวกเขาต้องการพัฒนาปัญญาประดิษฐ์ทั่วไปอย่างมากจนการยอมรับจุดอ่อนในสิ่งที่ GPT สามารถทำได้เป็นเรื่องยาก
GPT เป็น "ผู้เชี่ยวชาญในทุกสิ่ง" ดังนั้นจึงไม่สามารถเป็นผู้เชี่ยวชาญในทุกสิ่งได้
หากไม่สามารถพูดคำหยาบได้ แสดงว่าไม่สามารถกลั่นกรองเนื้อหาได้
ถ้าต้องพูดความจริงก็เขียนนิยายไม่ได้
หากต้องเชื่อฟังผู้ใช้ก็ไม่ถูกต้องเสมอไป
GPT ไม่ใช่ เครื่องมือค้นหา แชทบอท เพื่อนของคุณ หน่วยสืบราชการลับทั่วไป หรือแม้แต่การแก้ไขอัตโนมัติแบบแฟนซี
เป็นการนำสถิติมาประยุกต์ใช้จำนวนมาก ทอยลูกเต๋า เพื่อสร้างประโยค แต่สิ่งที่เกี่ยวกับโอกาสคือบางครั้งคุณเรียกผิด
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่