
คู่มือ SEO เพื่อทำความเข้าใจโมเดลภาษาขนาดใหญ่ (LLM)
เผยแพร่แล้ว: 2023-05-08ฉันควรใช้โมเดลภาษาขนาดใหญ่สำหรับการวิจัยคำหลักหรือไม่ โมเดลเหล่านี้คิดได้หรือไม่? ChatGPT เป็นเพื่อนของฉันหรือไม่
หากคุณเคยถามตัวเองด้วยคำถามเหล่านี้ คู่มือนี้เหมาะสำหรับคุณ
คู่มือนี้ครอบคลุมสิ่งที่ SEO จำเป็นต้องรู้เกี่ยวกับโมเดลภาษาขนาดใหญ่ การประมวลผลภาษาธรรมชาติ และทุกสิ่งที่เกี่ยวข้อง
โมเดลภาษาขนาดใหญ่ การประมวลผลภาษาธรรมชาติ และอื่นๆ ในรูปแบบง่ายๆ
มีสองวิธีในการทำให้คนทำบางสิ่ง – บอกให้เขาทำหรือหวังว่าเขาจะทำมันเอง
เมื่อพูดถึงวิทยาการคอมพิวเตอร์ การเขียนโปรแกรมกำลังบอกให้หุ่นยนต์ทำ ขณะที่การเรียนรู้ของเครื่องหวังให้หุ่นยนต์ทำเอง แบบแรกคือการเรียนรู้ของเครื่องภายใต้การดูแล และแบบหลังคือการเรียนรู้ของเครื่องแบบไม่มีผู้ดูแล
การประมวลผลภาษาธรรมชาติ (NLP) เป็นวิธีการแบ่งข้อความเป็นตัวเลขแล้ววิเคราะห์โดยใช้คอมพิวเตอร์
คอมพิวเตอร์จะวิเคราะห์รูปแบบในคำต่างๆ และเมื่อมีการพัฒนามากขึ้น ในความสัมพันธ์ระหว่างคำต่างๆ
โมเดลแมชชีนเลิร์นนิงภาษาธรรมชาติที่ไม่มีผู้ดูแลสามารถฝึกฝนในชุดข้อมูลประเภทต่างๆ มากมาย
ตัวอย่างเช่น หากคุณฝึกโมเดลภาษาในการวิจารณ์ภาพยนตร์เรื่อง “Waterworld” โดยเฉลี่ย คุณจะได้ผลลัพธ์ที่ดีในการเขียน (หรือทำความเข้าใจ) บทวิจารณ์ภาพยนตร์เรื่อง “Waterworld”
หากคุณฝึกฝนบทวิจารณ์เชิงบวกสองบทที่ฉันทำเกี่ยวกับภาพยนตร์เรื่อง “Waterworld” ก็จะเข้าใจบทวิจารณ์เชิงบวกเหล่านั้นเท่านั้น
โมเดลภาษาขนาดใหญ่ (LLM) เป็นโครงข่ายประสาทเทียมที่มีพารามิเตอร์มากกว่าพันล้านพารามิเตอร์ มีขนาดใหญ่มากจนเป็นที่กล่าวทั่วไป พวกเขาไม่เพียงแค่ได้รับการฝึกอบรมเกี่ยวกับบทวิจารณ์เชิงบวกและเชิงลบสำหรับ “วอเตอร์เวิร์ล” เท่านั้น แต่ยังรวมถึงความคิดเห็น บทความวิกิพีเดีย ไซต์ข่าว และอื่นๆ
โครงการแมชชีนเลิร์นนิงทำงานกับบริบทได้หลายอย่าง ทั้งสิ่งต่างๆ ภายในและนอกบริบท
หากคุณมีโครงการแมชชีนเลิร์นนิงที่ทำงานเพื่อระบุจุดบกพร่องและแสดงแมว โครงการนั้นจะไม่ประสบความสำเร็จ
นี่คือเหตุผลว่าทำไมสิ่งต่างๆ เช่น รถยนต์ไร้คนขับจึงเป็นเรื่องยาก มีปัญหานอกบริบทมากมายที่ยากต่อการสรุปความรู้นั้น
LLMs ดูเหมือน และ สามารถเป็นได้ กว้างกว่าโครงการแมชชีนเลิร์นนิงอื่นๆ มาก นี่เป็นเพราะขนาดที่แท้จริงของข้อมูลและความสามารถในการบดขยี้ความสัมพันธ์ที่แตกต่างกันหลายพันล้านรายการ
เรามาพูดถึงหนึ่งในเทคโนโลยีที่ก้าวล้ำที่อนุญาต - หม้อแปลงไฟฟ้า
อธิบายหม้อแปลงตั้งแต่เริ่มต้น
ประเภทของสถาปัตยกรรมเครือข่ายประสาท หม้อแปลงได้ปฏิวัติฟิลด์ NLP
ก่อนที่จะมีหม้อแปลง โมเดล NLP ส่วนใหญ่ใช้เทคนิคที่เรียกว่าเครือข่ายประสาทแบบวนซ้ำ (RNN) ซึ่งประมวลผลข้อความตามลำดับทีละคำ วิธีการนี้มีข้อจำกัด เช่น ช้าและมีปัญหาในการจัดการกับการอ้างอิงระยะยาวในข้อความ
Transformers เปลี่ยนสิ่งนี้
ในบทความหลักประจำปี 2560 “Attention is All You Need” Vaswani et al. แนะนำสถาปัตยกรรมหม้อแปลง
แทนที่จะประมวลผลข้อความตามลำดับ Transformers ใช้กลไกที่เรียกว่า "Self-attention" เพื่อประมวลผลคำพร้อมกัน ทำให้สามารถจับการอ้างอิงระยะยาวได้อย่างมีประสิทธิภาพมากขึ้น
สถาปัตยกรรมก่อนหน้านี้รวมถึง RNNs และอัลกอริทึมหน่วยความจำระยะสั้นระยะยาว
แบบจำลองที่เกิดซ้ำเช่นนี้ (และยังคงใช้อยู่) โดยทั่วไปใช้กับงานที่เกี่ยวข้องกับลำดับข้อมูล เช่น ข้อความหรือคำพูด
อย่างไรก็ตาม โมเดลเหล่านี้มีปัญหา พวกเขาสามารถประมวลผลข้อมูลได้ครั้งละหนึ่งส่วนเท่านั้น ซึ่งทำให้ช้าลงและจำกัดจำนวนข้อมูลที่สามารถทำงานกับมันได้ การประมวลผลแบบต่อเนื่องนี้จำกัดความสามารถของโมเดลเหล่านี้จริงๆ
กลไกการให้ความสนใจถูกนำมาใช้เป็นวิธีการประมวลผลข้อมูลลำดับที่แตกต่างกัน พวกเขาอนุญาตให้แบบจำลองดูข้อมูลทั้งหมดพร้อมกันและตัดสินใจว่าส่วนใดที่สำคัญที่สุด
สิ่งนี้มีประโยชน์มากในหลาย ๆ งาน อย่างไรก็ตาม โมเดลส่วนใหญ่ที่ใช้ความสนใจยังใช้การประมวลผลซ้ำ
โดยพื้นฐานแล้วพวกเขามีวิธีการประมวลผลข้อมูลทั้งหมดในคราวเดียว แต่ก็ยังจำเป็นต้องดูตามลำดับ กระดาษของ Vaswani et al. ลอยอยู่ “จะเกิดอะไรขึ้นถ้าเราใช้แต่กลไกความสนใจ”
ความสนใจเป็นวิธีที่โมเดลจะโฟกัสไปที่บางส่วนของลำดับอินพุตเมื่อทำการประมวลผล ตัวอย่างเช่น เมื่อเราอ่านประโยคหนึ่งๆ เราจะให้ความสนใจกับคำบางคำมากกว่าคำอื่นๆ โดยธรรมชาติ ขึ้นอยู่กับบริบทและสิ่งที่เราต้องการเข้าใจ
หากคุณดูทรานสฟอร์มเมอร์ แบบจำลองจะคำนวณคะแนนสำหรับแต่ละคำในลำดับอินพุตโดยพิจารณาจากความสำคัญในการทำความเข้าใจความหมายโดยรวมของลำดับ
จากนั้นตัวแบบจะใช้คะแนนเหล่านี้เพื่อชั่งน้ำหนักความสำคัญของแต่ละคำในลำดับ ทำให้สามารถเน้นคำที่สำคัญมากขึ้นและน้อยลงกับคำที่ไม่สำคัญ
กลไกความสนใจนี้ช่วยให้โมเดลจับการพึ่งพาระยะยาวและความสัมพันธ์ระหว่างคำที่อาจอยู่ห่างกันในลำดับอินพุตโดยไม่ต้องประมวลผลลำดับทั้งหมดตามลำดับ
สิ่งนี้ทำให้ทรานสฟอร์มเมอร์มีประสิทธิภาพมากสำหรับงานประมวลผลภาษาธรรมชาติ เนื่องจากมันสามารถเข้าใจความหมายของประโยคหรือลำดับข้อความที่ยาวขึ้นได้อย่างรวดเร็วและแม่นยำ
ลองมาดูตัวอย่างโมเดลหม้อแปลงที่ประมวลผลประโยค "แมวนั่งบนเสื่อ"
แต่ละคำในประโยคแสดงเป็นเวกเตอร์ ชุดตัวเลข โดยใช้เมทริกซ์ฝัง สมมติว่าการฝังสำหรับแต่ละคำคือ:
- ที่ : [0.2, 0.1, 0.3, 0.5]
- แมว : [0.6, 0.3, 0.1, 0.2]
- เสาร์ : [0.1, 0.8, 0.2, 0.3]
- บน : [0.3, 0.1, 0.6, 0.4]
- ที่ : [0.5, 0.2, 0.1, 0.4]
- เสื่อ : [0.2, 0.4, 0.7, 0.5]
จากนั้น Transformer จะคำนวณคะแนนสำหรับแต่ละคำในประโยคตามความสัมพันธ์กับคำอื่นๆ ทั้งหมดในประโยค
ซึ่งทำได้โดยใช้ดอทโปรดักต์ของการฝังคำแต่ละคำกับการฝังคำอื่นๆ ทั้งหมดในประโยค
ตัวอย่างเช่น ในการคำนวณคะแนนสำหรับคำว่า "cat" เราจะใช้ดอทโปรดัคของการฝังคำนั้นร่วมกับการฝังคำอื่นๆ ทั้งหมด:
- “ แมว “: 0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “ แมวนั่ง “: 0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “ แมวบน “: 0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “ แมวตัว “: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- “ เสื่อแมว “: 0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
คะแนนเหล่านี้บ่งชี้ความเกี่ยวข้องของแต่ละคำกับคำว่า “แมว” จากนั้น Transformer จะใช้คะแนนเหล่านี้เพื่อคำนวณผลรวมถ่วงน้ำหนักของการฝังคำ โดยที่น้ำหนักคือคะแนน
สิ่งนี้สร้างเวกเตอร์บริบทสำหรับคำว่า "แมว" ที่พิจารณาความสัมพันธ์ระหว่างคำทั้งหมดในประโยค กระบวนการนี้ซ้ำสำหรับแต่ละคำในประโยค
ให้คิดว่าเป็นหม้อแปลงที่วาดเส้นแบ่งระหว่างแต่ละคำในประโยคตามผลลัพธ์ของการคำนวณแต่ละครั้ง บางเส้นมีความบางกว่าและบางเส้นจะน้อยกว่า
หม้อแปลงเป็นรูปแบบใหม่ที่ใช้เฉพาะความสนใจโดยไม่มีการประมวลผลซ้ำ ทำให้เร็วขึ้นมากและสามารถจัดการข้อมูลได้มากขึ้น
GPT ใช้หม้อแปลงอย่างไร
คุณอาจจำได้ว่าในประกาศ BERT ของ Google พวกเขาโอ้อวดว่าอนุญาตให้ค้นหาเพื่อทำความเข้าใจบริบททั้งหมดของข้อมูลที่ป้อน สิ่งนี้คล้ายกับวิธีที่ GPT สามารถใช้หม้อแปลงได้
ลองใช้การเปรียบเทียบ
ลองจินตนาการว่าคุณมีลิงนับล้านตัว แต่ละตัวนั่งอยู่หน้าแป้นพิมพ์
ลิงแต่ละตัวสุ่มกดปุ่มบนแป้นพิมพ์ สร้างชุดตัวอักษรและสัญลักษณ์
สตริงบางสตริงไม่มีสาระ ในขณะที่บางสตริงอาจดูเหมือนคำจริงหรือแม้แต่ประโยคที่เชื่อมโยงกัน
วันหนึ่ง ครูฝึกคณะละครสัตว์คนหนึ่งเห็นว่าลิงเขียนไว้ว่า "เป็นหรือไม่เป็น" ครูฝึกจึงให้ขนมแก่ลิง
ลิงตัวอื่นๆ เห็นสิ่งนี้และเริ่มพยายามเลียนแบบลิงที่ประสบความสำเร็จ โดยหวังว่าจะได้ขนมจากพวกมันเอง
เมื่อเวลาผ่านไป ลิงบางตัวเริ่มสร้างสตริงข้อความที่ดีขึ้นและสอดคล้องกันมากขึ้นอย่างต่อเนื่อง ในขณะที่ลิงบางตัวยังคงสร้างข้อความที่ไม่มีความหมาย
ในที่สุด ลิงสามารถจดจำและเลียนแบบรูปแบบที่สอดคล้องกันในข้อความได้
LLM มีขาขึ้นบนลิงเพราะ LLMs ได้รับการฝึกอบรมครั้งแรกเกี่ยวกับข้อความหลายพันล้านชิ้น พวกเขาสามารถเห็นรูปแบบแล้ว พวกเขายังเข้าใจเวกเตอร์และความสัมพันธ์ระหว่างข้อความเหล่านี้
ซึ่งหมายความว่าพวกเขาสามารถใช้รูปแบบและความสัมพันธ์เหล่านั้นเพื่อสร้างข้อความใหม่ที่คล้ายกับภาษาธรรมชาติ
GPT ซึ่งย่อมาจาก Generative Pre-trained Transformer เป็นโมเดลภาษาที่ใช้ตัวแปลงเพื่อสร้างข้อความภาษาธรรมชาติ
มันถูกฝึกโดยใช้ข้อความจำนวนมหาศาลจากอินเทอร์เน็ต ซึ่งทำให้สามารถเรียนรู้รูปแบบและความสัมพันธ์ระหว่างคำและวลีในภาษาธรรมชาติได้
แบบจำลองทำงานโดยรับข้อความสั้นๆ หรือข้อความสองสามคำ และใช้ตัวแปลงเพื่อทำนายว่าคำใดควรตามมาตามรูปแบบที่ได้เรียนรู้จากข้อมูลการฝึกอบรม
โมเดลยังคงสร้างข้อความคำต่อคำโดยใช้บริบทของคำก่อนหน้าเพื่อแจ้งคำถัดไป
GPT ในการดำเนินการ
ข้อดีอย่างหนึ่งของ GPT คือสามารถสร้างข้อความภาษาธรรมชาติที่มีความสอดคล้องกันสูงและมีความเกี่ยวข้องทางบริบท
สิ่งนี้มีการใช้งานจริงมากมาย เช่น การสร้างคำอธิบายผลิตภัณฑ์หรือการตอบคำถามบริการลูกค้า นอกจากนี้ยังสามารถใช้ในเชิงสร้างสรรค์ เช่น แต่งบทกวีหรือเรื่องสั้น
อย่างไรก็ตาม เป็นเพียงแบบจำลองทางภาษาเท่านั้น ได้รับการฝึกอบรมเกี่ยวกับข้อมูล และข้อมูลนั้นอาจล้าสมัยหรือไม่ถูกต้อง
- มันไม่มีแหล่งความรู้
- ไม่สามารถค้นหาทางอินเทอร์เน็ตได้
- มันไม่ "รู้" อะไรเลย
เพียงแค่เดาว่าคำใดจะมาต่อไป
ลองดูตัวอย่าง:
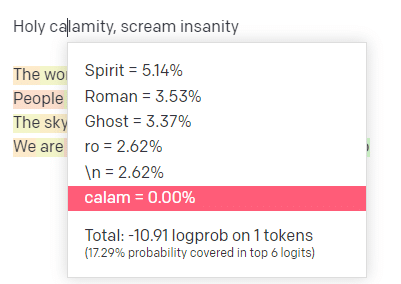
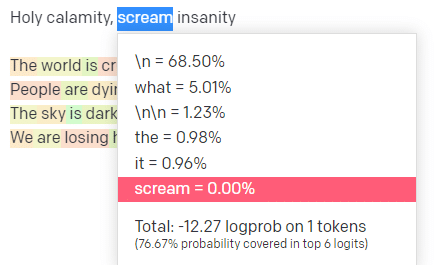
ในสนามเด็กเล่น OpenAI ฉันได้เสียบบรรทัดแรกของแทร็ก Handsome Boy Modeling School คลาสสิก 'Holy calamity [[Bear Witness ii]]'
ฉันส่งการตอบกลับเพื่อให้เราสามารถเห็นความเป็นไปได้ของทั้งบรรทัดอินพุตและเอาต์พุตของฉัน มาดูกันว่าแต่ละส่วนบอกอะไรเราบ้าง
สำหรับคำ/โทเค็นแรก ฉันป้อน "ศักดิ์สิทธิ์" เราจะเห็นว่าอินพุตถัดไปที่คาดหวังมากที่สุดคือ Spirit, Roman และ Ghost
เรายังเห็นได้ว่าผลลัพธ์หกอันดับแรกครอบคลุมความน่าจะเป็นของสิ่งที่จะเกิดขึ้นต่อไปเพียง 17.29% ซึ่งหมายความว่ามีความเป็นไปได้อื่นอีกประมาณ 82% ที่เราไม่เห็นในการแสดงภาพข้อมูลนี้
เรามาคุยกันสั้น ๆ เกี่ยวกับอินพุตต่าง ๆ ที่คุณสามารถใช้ในสิ่งนี้และผลกระทบที่ส่งผลต่อเอาต์พุตของคุณอย่างไร
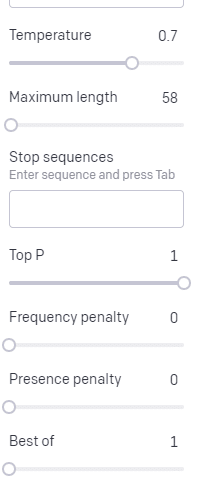
อุณหภูมิ คือแนวโน้มที่ตัวแบบจะคว้าคำอื่นที่ไม่ใช่คำที่มีความน่าจะเป็นสูงสุด P อันดับต้น ๆ คือวิธีที่โมเดลเลือกคำเหล่านั้น
ดังนั้นสำหรับอินพุต “Holy Calamity” P บนสุดคือวิธีที่เราเลือกกลุ่มของโทเค็นถัดไป [Ghost, Roman, Spirit] และอุณหภูมิคือความเป็นไปได้มากน้อยเพียงใดสำหรับโทเค็นที่น่าจะเป็นไปได้มากที่สุดเทียบกับความหลากหลายที่มากขึ้น
หากอุณหภูมิสูงขึ้น ก็มี แนวโน้ม ที่จะเลือกโทเค็น ที่มีโอกาสน้อยกว่า
ดังนั้นอุณหภูมิที่สูงและค่า P บนที่สูงจะยิ่งเลวร้ายลง มันเลือกจากความหลากหลาย (P บนสุด) และมีแนวโน้มที่จะเลือกโทเค็นที่น่าประหลาดใจ


ในขณะที่อุณหภูมิสูงแต่ P บนล่างจะเลือกตัวเลือกที่น่าประหลาดใจจากตัวอย่างความเป็นไปได้ที่มีขนาดเล็กลง:

และการลดอุณหภูมิเพียงแค่เลือกโทเค็นถัดไปที่เป็นไปได้มากที่สุด:

ในความคิดของฉันการเล่นกับความน่าจะเป็นเหล่านี้สามารถให้ข้อมูลเชิงลึกที่ดีแก่คุณว่าแบบจำลองเหล่านี้ทำงานอย่างไร
กำลังดูชุดของตัวเลือกถัดไปที่น่าจะเป็นไปได้โดยพิจารณาจากสิ่งที่เสร็จสมบูรณ์แล้ว
สิ่งนี้หมายความว่าอย่างไร
พูดง่ายๆ ก็คือ LLM จะรวบรวมอินพุต เขย่า และเปลี่ยนให้เป็นเอาต์พุต
ฉันเคยได้ยินคนล้อเล่นว่ามันแตกต่างจากคนทั่วไปมากไหม
แต่มันไม่เหมือนกับผู้คน – LLMs ไม่มีฐานความรู้ พวกเขาไม่ได้ดึงข้อมูลเกี่ยวกับสิ่งใดสิ่งหนึ่ง พวกเขาเดาลำดับของคำโดยอิงจากคำสุดท้าย
อีกตัวอย่างหนึ่ง: ลองนึกถึงแอปเปิ้ล นึกถึงอะไร?
บางทีคุณสามารถหมุนหนึ่งในใจของคุณ
บางทีคุณอาจจำกลิ่นของสวนแอปเปิ้ล ความอ่อนหวานของสาวสีชมพู ฯลฯ
บางทีคุณอาจนึกถึงสตีฟจ็อบส์
ทีนี้มาดูกันว่าข้อความแจ้ง "นึกถึงแอปเปิ้ล" จะส่งกลับอย่างไร
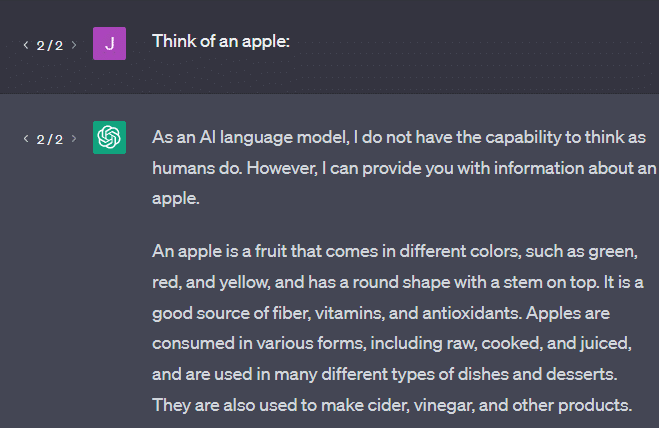
คุณอาจเคยได้ยินคำว่า "Stochastic Parrots" ลอยมาเมื่อถึงจุดนี้
Stochastic Parrots เป็นคำที่ใช้อธิบาย LLM เช่น GPT นกแก้วเป็นนกที่เลียนแบบสิ่งที่ได้ยิน
ดังนั้น LLM ก็เหมือนนกแก้วที่พวกเขารับข้อมูล (คำ) และส่งออกสิ่งที่คล้ายกับสิ่งที่พวกเขาเคยได้ยิน แต่ก็ สุ่ม เช่นกัน ซึ่งหมายความว่าพวกเขาใช้ความน่าจะเป็นเพื่อเดาว่าอะไรจะเกิดขึ้นต่อไป
LLM นั้นเก่งในการจดจำรูปแบบและความสัมพันธ์ระหว่างคำ แต่พวกเขาไม่มีความเข้าใจอย่างลึกซึ้งในสิ่งที่พวกเขาเห็น นั่นเป็นเหตุผลที่พวกเขาเก่งในการสร้างข้อความภาษาธรรมชาติ แต่ไม่เข้าใจ
การใช้งานที่ดีสำหรับ LLM
LLM นั้นเก่งในงานทั่วไปมากกว่า
คุณสามารถแสดงข้อความได้ และหากไม่มีการฝึกอบรม ก็สามารถทำงานด้วยข้อความนั้นได้
คุณสามารถโยนข้อความและขอให้วิเคราะห์ความรู้สึก ขอให้ถ่ายโอนข้อความนั้นไปยังมาร์กอัปที่มีโครงสร้าง และทำงานสร้างสรรค์บางอย่าง (เช่น การเขียนโครงร่าง)
ไม่เป็นไรสำหรับสิ่งต่าง ๆ เช่นรหัส สำหรับงานหลายๆ อย่าง แทบจะทำให้คุณไปถึงที่นั่นได้
แต่อีกครั้ง มันขึ้นอยู่กับความน่าจะเป็นและรูปแบบ ดังนั้นจะมีบางครั้งที่มันเลือกรูปแบบในการป้อนข้อมูลของคุณที่คุณไม่รู้ว่ามีอยู่
สิ่งนี้อาจเป็นแง่บวก (เห็นรูปแบบที่มนุษย์ไม่สามารถทำได้) แต่ก็อาจเป็นแง่ลบได้เช่นกัน (ทำไมมันถึงตอบแบบนี้?)
นอกจากนี้ยังไม่มีสิทธิ์เข้าถึงแหล่งข้อมูลประเภทใดๆ SEO ที่ใช้เพื่อค้นหาคำหลักการจัดอันดับจะมีช่วงเวลาที่ไม่ดี
ไม่สามารถค้นหาการเข้าชมสำหรับคำหลัก ไม่มีข้อมูลสำหรับข้อมูลคำหลักนอกเหนือจากคำที่มีอยู่

สิ่งที่น่าตื่นเต้นเกี่ยวกับ ChatGPT คือรูปแบบภาษาที่พร้อมใช้งานได้ง่ายซึ่งคุณสามารถนำไปใช้ได้ทันทีในงานต่างๆ แต่ก็ไม่มีข้อแม้
ใช้งานได้ดีกับรุ่น ML อื่นๆ
ฉันได้ยินคนพูดว่าพวกเขากำลังใช้ LLM สำหรับงานบางอย่าง ซึ่งอัลกอริทึมและเทคนิค NLP อื่นๆ สามารถทำได้ดีกว่า

ลองมาดูตัวอย่าง การดึงคำหลัก
ถ้าฉันใช้ TF-IDF หรือเทคนิคคำหลักอื่นๆ เพื่อดึงคำหลักจากคลังข้อมูล ฉันรู้ว่าเทคนิคนั้นใช้การคำนวณแบบใด
ซึ่งหมายความว่าผลลัพธ์จะเป็นมาตรฐาน ทำซ้ำได้ และฉันรู้ว่าผลลัพธ์จะเกี่ยวข้องกับคลังข้อมูลนั้นโดยเฉพาะ
ด้วย LLM เช่น ChatGPT หากคุณขอให้แยกคำหลัก คุณไม่จำเป็นต้องดึงคำหลักจากคลังข้อมูล คุณได้รับสิ่งที่ GPT คิดว่า ควรตอบสนองต่อคลังข้อมูล + แยกคำหลัก
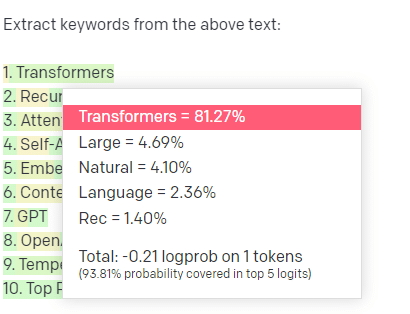
ซึ่งคล้ายกับงานต่างๆ เช่น การจัดกลุ่มหรือการวิเคราะห์ความรู้สึก คุณไม่จำเป็นต้องได้รับผลลัพธ์ที่ปรับแต่งอย่างละเอียดด้วยพารามิเตอร์ที่คุณตั้งไว้ คุณได้รับสิ่งที่น่าจะเป็นไปได้ตามงานอื่นๆ ที่คล้ายคลึงกัน
อีกครั้ง LLMs ไม่มีฐานความรู้และไม่มีข้อมูลที่เป็นปัจจุบัน พวกเขามักจะค้นหาเว็บไม่ได้ และแยกวิเคราะห์สิ่งที่ได้รับจากข้อมูลเป็นโทเค็นทางสถิติ ข้อจำกัดเกี่ยวกับระยะเวลาของหน่วยความจำของ LLM เป็นเพราะปัจจัยเหล่านี้
อีกอย่างคือโมเดลพวกนี้มันคิดไม่ได้ ฉันใช้คำว่า "คิด" เพียงไม่กี่ครั้งในงานชิ้นนี้ เพราะมันยากมากที่จะไม่ใช้มันเมื่อพูดถึงกระบวนการเหล่านี้
แนวโน้มไปทางมานุษยวิทยาแม้ว่าจะพูดถึงสถิติแฟนซีก็ตาม
แต่นี่หมายความว่าหากคุณมอบหมาย LLM ให้กับงานใดๆ ก็ตามที่ต้องใช้ "ความคิด" แสดงว่าคุณไม่ได้ไว้วางใจสิ่งมีชีวิตที่คิด
คุณเชื่อถือการวิเคราะห์ทางสถิติว่าคนประหลาดทางอินเทอร์เน็ตหลายร้อยคนตอบสนองต่อโทเค็นที่คล้ายกันอย่างไร
หากคุณไว้ใจผู้ใช้งานอินเทอร์เน็ตในเรื่องใดงานหนึ่ง คุณสามารถใช้ LLM ได้ มิฉะนั้น…
สิ่งที่ไม่ควรเป็นโมเดล ML
แชทบอททำงานผ่านโมเดล GPT (GPT-J) มีรายงานว่าสนับสนุนให้ชายคนหนึ่งฆ่าตัวตาย ปัจจัยหลายอย่างรวมกันอาจทำให้เกิดอันตรายได้ เช่น
- ผู้คนเปลี่ยนแปลงคำตอบเหล่านี้
- เชื่อว่าพวกเขาไม่มีผิด
- ใช้ในจุดที่ต้องมีคนอยู่ในเครื่อง
- และอื่น ๆ.
ในขณะที่คุณอาจคิดว่า “ฉันเป็น SEO ฉันไม่มีระบบที่สามารถฆ่าใครซักคนได้!”
ลองนึกถึงหน้า YMYL และวิธีที่ Google โปรโมตแนวคิดอย่าง EEAT
Google ทำเช่นนี้เพราะพวกเขาต้องการรบกวน SEO หรือเป็นเพราะพวกเขาไม่ต้องการให้เกิดผลเสียหายนั้น
แม้จะอยู่ในระบบที่มีฐานความรู้ที่แข็งแกร่ง อันตรายก็เกิดขึ้นได้
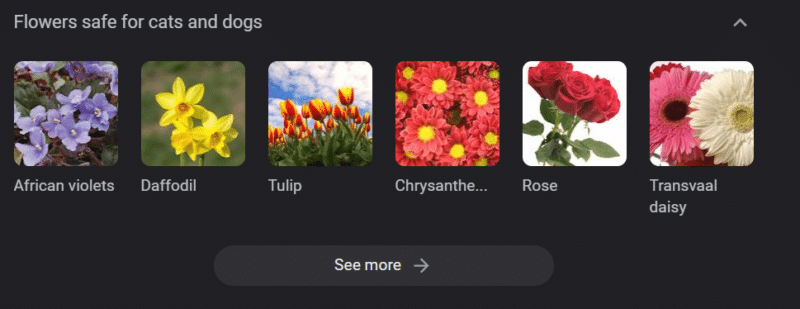
ด้านบนคือม้าหมุนความรู้ของ Google สำหรับ "ดอกไม้ที่ปลอดภัยสำหรับแมวและสุนัข" ดอกแดฟโฟดิลอยู่ในรายชื่อนั้นแม้ว่าจะเป็นพิษต่อแมวก็ตาม
สมมติว่าคุณกำลังสร้างเนื้อหาสำหรับเว็บไซต์สัตวแพทย์ในวงกว้างโดยใช้ GPT คุณใส่คำหลักจำนวนมากและ ping ChatGPT API
คุณมีนักแปลอิสระอ่านผลลัพธ์ทั้งหมด และพวกเขาไม่ใช่ผู้เชี่ยวชาญเฉพาะเรื่อง พวกเขาไม่รับปัญหา
คุณเผยแพร่ผลงานซึ่งสนับสนุนการซื้อดอกแดฟโฟดิลสำหรับเจ้าของแมว
คุณฆ่าแมวของใครบางคน
ไม่โดยตรง บางทีพวกเขาอาจไม่รู้ด้วยซ้ำว่าเป็นไซต์นั้นโดยเฉพาะ
บางทีไซต์สัตว์แพทย์อื่น ๆ ก็เริ่มทำสิ่งเดียวกันและให้อาหารซึ่งกันและกัน
ผลการค้นหาอันดับต้น ๆ ของ Google สำหรับ "ดอกแดฟโฟดิลเป็นพิษต่อแมว" เป็นไซต์ที่ระบุว่าไม่เป็นเช่นนั้น
นักแปลอิสระคนอื่น ๆ อ่านเนื้อหา AI อื่น ๆ หน้าต่อหน้าเนื้อหา AI ตรวจสอบข้อเท็จจริงจริง ๆ แต่ขณะนี้ระบบมีข้อมูลที่ไม่ถูกต้อง
เมื่อพูดถึงการเฟื่องฟูของ AI ในปัจจุบัน ฉันพูดถึง Therac-25 บ่อยมาก เป็นกรณีศึกษาที่โด่งดังเกี่ยวกับความผิดทางคอมพิวเตอร์
โดยพื้นฐานแล้วมันเป็นเครื่องรังสีรักษาเครื่องแรกที่ใช้กลไกล็อคคอมพิวเตอร์เท่านั้น ความผิดพลาดในซอฟต์แวร์หมายความว่าผู้คนได้รับปริมาณรังสีหลายหมื่นเท่าของปริมาณรังสีที่ควรได้รับ
สิ่งที่โดดเด่นสำหรับฉันเสมอคือการที่บริษัทเรียกคืนและตรวจสอบโมเดลเหล่านี้โดยสมัครใจ
แต่พวกเขาสันนิษฐานว่าเนื่องจากเทคโนโลยีมีความก้าวหน้าและซอฟต์แวร์ก็ "ไม่มีข้อผิดพลาด" ปัญหาจึงเกี่ยวข้องกับชิ้นส่วนกลไกของเครื่องจักร
ดังนั้น พวกเขาจึงซ่อมแซมกลไกต่างๆ แต่ไม่ได้ตรวจสอบซอฟต์แวร์ และ Therac-25 ก็ยังคงขายอยู่ในตลาด
คำถามที่พบบ่อยและความเข้าใจผิด
ทำไม ChatGPT ถึงโกหกฉัน
สิ่งหนึ่งที่ฉันได้เห็นจากผู้ที่มีความคิดที่ยิ่งใหญ่ในยุคของเราและผู้มีอิทธิพลบน Twitter คือการบ่นว่า ChatGPT “โกหก” พวกเขา นี่เป็นเพราะความเข้าใจผิดสองประการควบคู่กันไป:
- ChatGPT นั้นมี "ต้องการ"
- ว่ามีฐานความรู้
- นักเทคโนโลยีที่อยู่เบื้องหลังเทคโนโลยีมีวาระบางอย่างนอกเหนือจาก "ทำเงิน" หรือ "สร้างสิ่งที่ยอดเยี่ยม"
อคติฝังอยู่ในทุกส่วนของชีวิตประจำวันของคุณ ดังนั้นข้อยกเว้นสำหรับอคติเหล่านี้
ปัจจุบันนักพัฒนาซอฟต์แวร์ส่วนใหญ่เป็นผู้ชาย: ฉันเป็นนักพัฒนาซอฟต์แวร์และเป็นผู้หญิง
การฝึกอบรม AI ตามความเป็นจริงนี้จะนำไปสู่การคิดว่านักพัฒนาซอฟต์แวร์เป็นผู้ชายเสมอ ซึ่งไม่เป็นความจริง
ตัวอย่างที่โด่งดังคือ AI ด้านการสรรหาบุคลากรของ Amazon ซึ่งได้รับการฝึกฝนเกี่ยวกับเรซูเม่จากพนักงานของ Amazon ที่ประสบความสำเร็จ
สิ่งนี้นำไปสู่การละทิ้งเรซูเม่จากวิทยาลัยที่มีคนผิวดำเป็นส่วนใหญ่ แม้ว่าพนักงานเหล่านั้นหลายคนจะประสบความสำเร็จอย่างมากก็ตาม
เพื่อตอบโต้อคติเหล่านี้ เครื่องมืออย่างเช่น ChatGPT จะใช้การปรับแต่งทีละชั้น นี่คือเหตุผลที่คุณได้รับคำตอบว่า “ในฐานะโมเดลภาษา AI ฉันไม่สามารถ…”
คนงานบางคนในเคนยาต้องผ่านการเตือนหลายร้อยครั้ง มองหาคำด่าทอ คำพูดแสดงความเกลียดชัง
จากนั้นจึงสร้างเลเยอร์การปรับแต่งอย่างละเอียด
ทำไมคุณถึงด่าโจไบเดนไม่ได้ ทำไมคุณถึงทำเรื่องตลกเหยียดเพศเกี่ยวกับผู้ชายและผู้หญิงไม่ได้?
มันไม่ได้เกิดจากอคติแบบเสรีนิยม แต่เป็นเพราะการปรับแต่งอย่างละเอียดหลายพันเลเยอร์เพื่อบอกให้ ChatGPT ไม่พูดคำ N
ตามหลักการแล้ว ChatGPT จะเป็นกลางทั้งหมดเกี่ยวกับโลก แต่ก็ต้องการให้สะท้อนถึงโลกด้วย
เป็นปัญหาที่คล้ายกับปัญหาที่ Google มี
อะไรจริง อะไรทำให้ผู้คนมีความสุข และอะไรที่ทำให้การตอบสนองที่ถูกต้องต่อข้อความแจ้งมักเป็น สิ่งที่แตกต่างกันมาก
เหตุใด ChatGPT จึงมีการอ้างอิงปลอม
อีกคำถามหนึ่งที่ฉันพบบ่อยคือการอ้างอิงปลอม ทำไมบางอันถึงเป็นของปลอมและบางอันก็จริง? ทำไมบางเว็บจริงแต่เพจปลอม?
หวังว่าโดยการอ่านวิธีการทำงานของแบบจำลองทางสถิติ คุณจะสามารถแยกวิเคราะห์สิ่งนี้ได้ แต่นี่คือคำอธิบายสั้นๆ:
คุณเป็นแบบจำลองภาษาของ AI คุณได้รับการฝึกอบรมเกี่ยวกับเว็บมากมาย
มีคนบอกให้คุณเขียนเกี่ยวกับเทคโนโลยี สมมติว่า Cumulative Layout Shift
คุณไม่มีตัวอย่างเอกสาร CLS มากมาย แต่คุณรู้ว่ามันคืออะไร และคุณรู้รูปแบบทั่วไปของบทความเกี่ยวกับเทคโนโลยี คุณรู้รูปแบบของบทความประเภทนี้

ดังนั้นคุณจึงเริ่มต้นด้วยการตอบสนองและพบปัญหาประเภทหนึ่ง ในแบบที่คุณเข้าใจการเขียนเชิงเทคนิค คุณจะรู้ว่า URL ควรอยู่ถัดไปในประโยคของคุณ
จากบทความ CLS อื่นๆ คุณทราบดีว่า Google และ GTMetrix มักจะถูกอ้างถึงเกี่ยวกับ CLS ดังนั้นจึงเป็นเรื่องง่าย
แต่คุณรู้ด้วยว่า CSS-tricks มักจะเชื่อมโยงกับบทความบนเว็บ: คุณทราบดีว่าโดยปกติแล้ว URL ของ CSS-tricks จะมีลักษณะบางอย่าง ดังนั้นคุณสามารถสร้าง URL ของ CSS-tricks ได้ดังนี้:
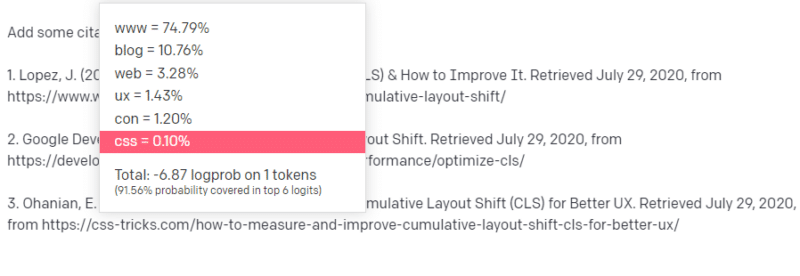
เคล็ดลับคือ นี่คือวิธีการสร้าง URL ทั้งหมด ไม่ใช่แค่ URL ปลอม:

บทความ GTMetrix นี้มีอยู่จริง แต่มีอยู่เนื่องจากเป็นชุดค่าที่น่าจะอยู่ที่ส่วนท้ายของประโยคนี้
GPT และแบบจำลองที่คล้ายกันไม่สามารถแยกความแตกต่างระหว่างการอ้างอิงจริงและการอ้างอิงปลอม
วิธีเดียวที่จะทำการสร้างแบบจำลองนั้นคือใช้แหล่งข้อมูลอื่น (ฐานความรู้ Python ฯลฯ) เพื่อแยกวิเคราะห์ความแตกต่างนั้นและตรวจสอบผลลัพธ์
'นกแก้วสโตแคสติก' คืออะไร?
ฉันรู้ว่าฉันผ่านเรื่องนี้ไปแล้ว แต่มันซ้ำซากจำเจ Stochastic Parrots เป็นวิธีการอธิบายว่าเกิดอะไรขึ้นเมื่อโมเดลภาษาขนาดใหญ่ ดูเหมือนเป็น เรื่องทั่วไปโดยธรรมชาติ
สำหรับ LLM เรื่องไร้สาระและความเป็นจริงนั้นเหมือนกัน พวกเขามองโลกเหมือนนักเศรษฐศาสตร์ เป็นสถิติและตัวเลขมากมายที่อธิบายความเป็นจริง
คุณคงรู้จักคำพูดที่ว่า “การโกหกมีอยู่สามประเภท: การโกหก การโกหกที่น่าสยดสยอง และสถิติ”
LLM เป็นสถิติจำนวนมาก
LLM ดูเหมือนจะสอดคล้องกัน แต่นั่นเป็นเพราะโดยพื้นฐานแล้วเราเห็นสิ่งต่าง ๆ ที่ดูเหมือนมนุษย์ในฐานะมนุษย์
ในทำนองเดียวกัน โมเดลแชทบ็อตจะทำให้การแจ้งเตือนและข้อมูลส่วนใหญ่ที่คุณต้องการเพื่อให้การตอบสนองของ GPT มีความสอดคล้องกันอย่างสมบูรณ์
ฉันเป็นนักพัฒนา: การพยายามใช้ LLM เพื่อดีบักโค้ดของฉันมีผลลัพธ์ที่แปรผันอย่างมาก หากเป็นปัญหาที่คล้ายกับที่ผู้คนมักมีทางออนไลน์ LLM สามารถรับและแก้ไขผลลัพธ์นั้นได้
หากเป็นปัญหาที่ไม่เคยพบมาก่อน หรือเป็นส่วนเล็กๆ ของคลังข้อมูล ก็จะไม่สามารถแก้ไขอะไรได้
เหตุใด GPT จึงดีกว่าเครื่องมือค้นหา
ฉันพูดแบบนี้อย่างเผ็ดร้อน ฉัน ไม่ คิดว่า GPT ดีกว่าเครื่องมือค้นหา ฉันกังวลว่าผู้คนได้เปลี่ยนการค้นหาด้วย ChatGPT
ส่วนหนึ่งที่ไม่เป็นที่รู้จักของ ChatGPT คือจำนวนการปฏิบัติตามคำแนะนำ คุณสามารถขอให้ทำอะไรก็ได้
แต่จำไว้ว่า ทั้งหมดนั้นขึ้นอยู่กับสถิติของคำถัดไปในประโยค ไม่ใช่ความจริง
ดังนั้นหากคุณถามคำถามที่ไม่มีคำตอบที่ดี แต่ถามในลักษณะที่จำเป็นต้องตอบ คุณจะได้คำตอบที่ไม่ดี
การตอบสนองที่ออกแบบมาสำหรับคุณและรอบตัวคุณนั้นสบายใจกว่า แต่โลกนี้เต็มไปด้วยประสบการณ์มากมาย
ข้อมูลทั้งหมดที่เข้าสู่ LLM ได้รับการปฏิบัติเหมือนกัน: แต่บางคนมีประสบการณ์ และการตอบสนองของพวกเขาจะดีกว่าคำตอบผสมของคนอื่น
ผู้เชี่ยวชาญหนึ่งคนมีค่ามากกว่าการคิดหนึ่งพันชิ้น
นี่คือจุดเริ่มต้นของ AI หรือไม่? สกายเน็ตอยู่ที่นี่เหรอ?
Koko the Gorilla เป็นลิงที่ได้รับการสอนภาษามือ นักวิจัยในการศึกษาภาษาศาสตร์ได้ทำการวิจัยมากมายที่แสดงให้เห็นว่าลิงสามารถสอนภาษาได้
เฮอร์เบิร์ต เทอร์เรซค้นพบว่าลิงเหล่านี้ไม่ได้สร้างประโยคหรือคำพูดขึ้นมา แต่เป็นเพียงลิงที่เป็นมนุษย์เท่านั้น
Eliza เป็นนักบำบัดด้วยเครื่อง ซึ่งเป็นหนึ่งในแชทบอท (แชทบอท) รุ่นแรกๆ
ผู้คนมองว่าเธอเป็นคน: นักบำบัดที่พวกเขาไว้วางใจและดูแล พวกเขาขอให้นักวิจัยอยู่คนเดียวกับเธอ
ภาษาทำอะไรที่เฉพาะเจาะจงมากกับสมองของผู้คน ผู้คนได้ยินสิ่งที่สื่อสารกันและคาดหวังความคิดที่อยู่เบื้องหลัง
LLMs นั้นน่าประทับใจ แต่ในทางที่แสดงให้เห็นถึงความสำเร็จของมนุษย์ในวงกว้าง
LLM ไม่มีเจตจำนง พวกเขาไม่สามารถหลบหนีได้ พวกเขาไม่สามารถพยายามยึดครองโลกได้
พวกเขาเป็นกระจก: ภาพสะท้อนของผู้คนและผู้ใช้โดยเฉพาะ
ความคิดเดียวที่มีการแสดงทางสถิติของจิตไร้สำนึกร่วม
GPT เรียนรู้ทั้งภาษาด้วยตัวเองหรือไม่?
Sundar Pichai ซีอีโอของ Google กล่าวในรายการ “60 นาที” และอ้างว่าโมเดลภาษาของ Google เรียนรู้ภาษาเบงกาลี
แบบจำลองได้รับการฝึกฝนจากข้อความเหล่านั้น มันไม่ถูกต้องที่มัน “พูดภาษาต่างประเทศที่ไม่เคยฝึกให้รู้”
มีหลายครั้งที่ AI ทำสิ่งที่ไม่คาดคิด แต่ก็เป็นสิ่งที่คาดหวังในตัวมันเอง
เมื่อคุณดูรูปแบบและสถิติในระดับใหญ่ จะต้องมีบางครั้งที่รูปแบบเหล่านั้นเผยให้เห็นสิ่งที่น่าประหลาดใจ
สิ่งนี้เผยให้เห็นอย่างแท้จริงคือ C-suite และนักการตลาดจำนวนมากที่เร่ขาย AI และ ML ไม่เข้าใจจริง ๆ ว่าระบบทำงานอย่างไร
ฉันเคยได้ยินบางคนที่ฉลาดมากพูดถึงคุณสมบัติที่เกิดขึ้นใหม่ ปัญญาประดิษฐ์ทั่วไป (AGI) และสิ่งล้ำยุคอื่นๆ
ฉันอาจจะเป็นแค่วิศวกรปฏิบัติการ ML ธรรมดาๆ ของประเทศ แต่มันแสดงให้เห็นว่าโฆษณาเกินจริง คำสัญญา นิยายวิทยาศาสตร์ และความเป็นจริงรวมตัวกันมากแค่ไหนเมื่อพูดถึงระบบเหล่านี้
เอลิซาเบธ โฮล์มส์ ผู้ก่อตั้ง Theranos ที่มีชื่อเสียงโด่งดัง ถูกตรึงกางเขนเพราะให้คำมั่นสัญญาที่รักษาไว้ไม่ได้
แต่วัฏจักรของการทำสัญญาที่เป็นไปไม่ได้นั้นเป็นส่วนหนึ่งของวัฒนธรรมสตาร์ทอัพและการทำเงิน ความแตกต่างระหว่าง Theranos และ AI hype คือ Theranos ไม่สามารถแกล้งทำได้นาน
GPT เป็นกล่องดำหรือไม่? จะเกิดอะไรขึ้นกับข้อมูลของฉันใน GPT
GPT เป็นแบบจำลอง ไม่ใช่กล่องดำ คุณสามารถดูซอร์สโค้ดสำหรับ GPT-J และ GPT-Neo
อย่างไรก็ตาม GPT ของ OpenAI เป็นกล่องดำ OpenAI ไม่มีและมีแนวโน้มที่จะไม่เผยแพร่โมเดลเนื่องจาก Google ไม่ได้เผยแพร่อัลกอริทึม
แต่ไม่ใช่เพราะอัลกอริทึมนั้นอันตรายเกินไป หากเป็นเช่นนั้นจริง พวกเขาจะไม่ขายการสมัครสมาชิก API ให้กับคนโง่ที่มีคอมพิวเตอร์ เป็นเพราะมูลค่าของ codebase ที่เป็นกรรมสิทธิ์นั้น
เมื่อคุณใช้เครื่องมือของ OpenAI คุณกำลังฝึกฝนและป้อน API ให้กับอินพุตของคุณ ซึ่งหมายความว่าทุกสิ่งที่คุณใส่ลงในฟีด OpenAI
ซึ่งหมายความว่าผู้ที่ใช้โมเดล GPT ของ OpenAI กับข้อมูลผู้ป่วยเพื่อช่วยเขียนบันทึกและสิ่งอื่นๆ ได้ละเมิด HIPAA ขณะนี้ข้อมูลดังกล่าวอยู่ในแบบจำลองแล้ว และจะเป็นการยากที่จะดึงข้อมูลออกมา
เนื่องจากมีผู้คนจำนวนมากมีปัญหาในการทำความเข้าใจสิ่งนี้ จึงเป็นไปได้มากที่โมเดลจะมีข้อมูลส่วนตัวจำนวนมาก เพียงแค่รอการแจ้งที่ถูกต้องเพื่อเผยแพร่ข้อมูลดังกล่าว
เหตุใด GPT จึงได้รับการฝึกฝนเกี่ยวกับคำพูดแสดงความเกลียดชัง
อีกสิ่งหนึ่งที่มักเกิดขึ้นก็คือคลังข้อความ GPT ได้รับการฝึกให้มีคำพูดแสดงความเกลียดชัง
ในระดับหนึ่ง OpenAI จำเป็นต้องฝึกฝนแบบจำลองของตนเพื่อตอบสนองต่อคำพูดแสดงความเกลียดชัง ดังนั้นจึงจำเป็นต้องมีคลังข้อมูลที่มีคำศัพท์เหล่านั้นบางส่วน
OpenAI อ้างว่าได้กำจัดคำพูดแสดงความเกลียดชังประเภทนั้นออกจากระบบ แต่เอกสารต้นฉบับรวมถึง 4chan และไซต์แสดงความเกลียดชังมากมาย
ท่องเว็บ ซึมซับอคติ
ไม่มีวิธีที่ง่ายในการหลีกเลี่ยงสิ่งนี้ คุณจะรับรู้หรือเข้าใจความเกลียดชัง อคติ และความรุนแรงได้อย่างไร โดยไม่ต้องให้สิ่งนั้นเป็นส่วนหนึ่งของชุดการฝึกของคุณ
คุณจะหลีกเลี่ยงอคติและเข้าใจอคติโดยนัยและชัดเจนได้อย่างไรเมื่อคุณเป็นตัวแทนเครื่องจักรที่เลือกโทเค็นถัดไปในประโยคทางสถิติ
TL;ดร
การโฆษณาเกินจริงและข้อมูลที่ผิดเป็นองค์ประกอบหลักที่ทำให้ AI เฟื่องฟู ไม่ได้หมายความว่าไม่มีการใช้งานที่ถูกต้อง: เทคโนโลยีนี้น่าทึ่งและมีประโยชน์
แต่วิธีการทำการตลาดของเทคโนโลยีและวิธีที่ผู้คนใช้เทคโนโลยีนั้นสามารถส่งเสริมข้อมูลที่ผิด การลอกเลียนแบบ และแม้แต่ก่อให้เกิดอันตรายโดยตรง
อย่าใช้ LLM เมื่อชีวิตอยู่ในสาย อย่าใช้ LLM เมื่ออัลกอริทึมอื่นทำงานได้ดีกว่า อย่าถูกหลอกโดยการโฆษณา
การทำความเข้าใจว่า LLM คืออะไร - และไม่ใช่ - เป็นสิ่งที่จำเป็น
ฉันขอแนะนำบทสัมภาษณ์ Adam Conover กับ Emily Bender และ Timnit Gebru
LLM สามารถเป็นเครื่องมือที่น่าทึ่งเมื่อใช้อย่างถูกต้อง มีหลายวิธีที่คุณสามารถใช้ LLM และวิธีอีกมากมายในการละเมิด LLM
ChatGPT ไม่ใช่เพื่อนของคุณ มันเป็นสถิติมากมาย AGI ไม่ได้ "อยู่ที่นี่แล้ว"
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่อยู่ที่นี่