
Spark vs Hadoop: Big Data Framework ใดที่จะยกระดับธุรกิจของคุณ
เผยแพร่แล้ว: 2019-09-24“ข้อมูลเป็นเชื้อเพลิงของเศรษฐกิจดิจิทัล”
ด้วยธุรกิจสมัยใหม่ที่ต้องอาศัยข้อมูลจำนวนมากเพื่อทำความเข้าใจผู้บริโภคและตลาดของตนให้ดีขึ้น เทคโนโลยีอย่าง Big Data กำลังได้รับแรงผลักดันมหาศาล
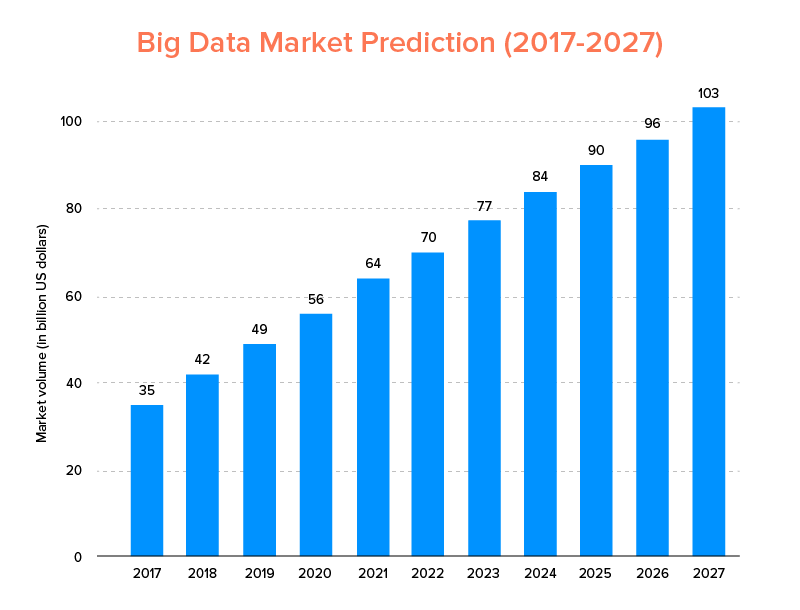
บิ๊กดาต้า เช่นเดียวกับ AI ที่ไม่เพียงแต่อยู่ใน รายชื่อเทรนด์เทคโนโลยีชั้นนำสำหรับปี 2020 แต่คาดว่าทั้งสตาร์ทอัพและบริษัทที่ติดอันดับ Fortune 500 จะเติบโตอย่างก้าวกระโดดและรับรองความภักดีของลูกค้าที่สูงขึ้น สิ่งบ่งชี้ที่ชัดเจนว่าตลาดบิ๊กดาต้าคาดว่าจะแตะระดับ 103 พันล้านดอลลาร์ภายในปี 2570
ขณะนี้ ด้านหนึ่ง ทุกคนมีแรงจูงใจสูงที่จะแทนที่เครื่องมือวิเคราะห์ข้อมูลแบบเดิมด้วย Big Data ซึ่งเป็นเครื่องมือที่เตรียมพื้นฐานสำหรับความก้าวหน้าของ Blockchain และ AI พวกเขายังสับสนเกี่ยวกับการเลือกเครื่องมือ Big data ที่เหมาะสม พวกเขากำลังเผชิญกับภาวะที่กลืนไม่เข้าคายไม่ออกในการเลือกระหว่าง Apache Hadoop และ Spark – สองยักษ์ใหญ่แห่งโลกของ Big Data
ดังนั้น เมื่อพิจารณาถึงความคิดนี้ วันนี้เราจะมาพูดถึงบทความเกี่ยวกับ Apache Spark vs Hadoop และช่วยคุณในการพิจารณาว่าตัวเลือกใดที่เหมาะสมกับความต้องการของคุณ
แต่ก่อนอื่น เรามาทำความรู้จักกับ Hadoop และ Spark กันก่อนดีกว่า
Apache Hadoop เป็นเฟรมเวิร์กแบบโอเพนซอร์ส แบบกระจาย และแบบ Java ที่ช่วยให้ผู้ใช้สามารถจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ในคอมพิวเตอร์หลายเครื่องโดยใช้โครงสร้างการเขียนโปรแกรมอย่างง่าย ประกอบด้วยโมดูลต่างๆ ที่ทำงานร่วมกันเพื่อมอบประสบการณ์ที่ดียิ่งขึ้น ซึ่งได้แก่:-
- Hadoop Common
- ระบบไฟล์แบบกระจาย Hadoop (HDFS)
- Hadoop YARN
- Hadoop MapReduce
ในขณะที่ Apache Spark เป็นเฟรมเวิร์กข้อมูลขนาดใหญ่ที่ใช้คอมพิวเตอร์คลัสเตอร์แบบโอเพนซอร์สที่ 'ใช้งานง่าย' และให้บริการที่รวดเร็วกว่า
กรอบงานบิ๊กดาต้าทั้งสองได้รับการสนับสนุนจากบริษัทขนาดใหญ่หลายแห่งเนื่องจากโอกาสที่พวกเขาเสนอให้
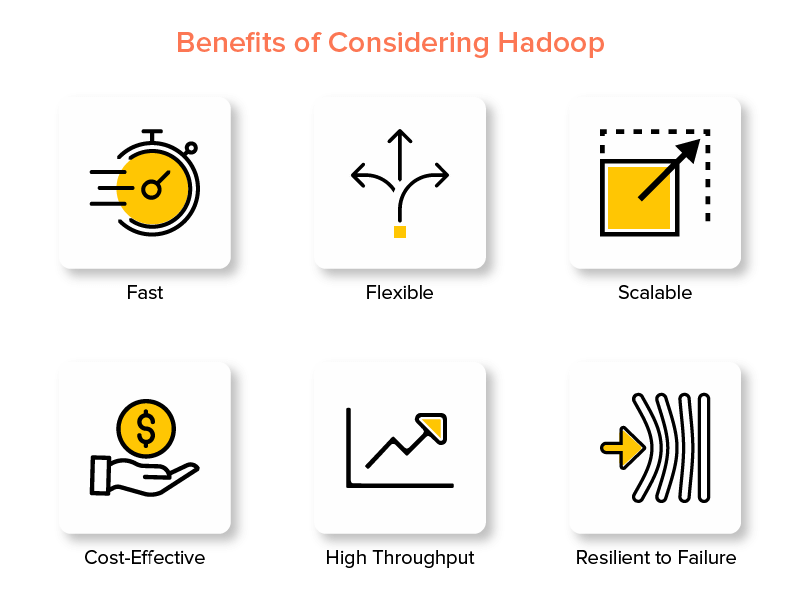
ข้อดีของ Hadoop Big Data Framework
1. เร็ว
คุณลักษณะหนึ่งของ Hadoop ที่ทำให้เป็นที่นิยมในโลกข้อมูลขนาดใหญ่คือความรวดเร็ว
วิธีการจัดเก็บจะขึ้นอยู่กับระบบไฟล์แบบกระจายที่ 'แมป' ข้อมูลเป็นหลักไม่ว่าจะอยู่ที่ใดในคลัสเตอร์ นอกจากนี้ ข้อมูลและเครื่องมือที่ใช้สำหรับการประมวลผลข้อมูลมักจะพร้อมใช้งานบนเซิร์ฟเวอร์เดียวกัน ซึ่งทำให้การประมวลผลข้อมูลเป็นงานที่ไม่ยุ่งยากและรวดเร็วขึ้น
อันที่จริง พบว่า Hadoop สามารถประมวลผลข้อมูลที่ไม่มีโครงสร้างได้หลายเทราไบต์ในเวลาเพียงไม่กี่นาที ในขณะที่ระดับเพทาไบต์ในชั่วโมง
2. ยืดหยุ่นได้
Hadoop ไม่เหมือนกับเครื่องมือประมวลผลข้อมูลแบบเดิมๆ ที่มอบความยืดหยุ่นระดับไฮเอนด์
ช่วยให้ธุรกิจรวบรวมข้อมูลจากแหล่งต่างๆ (เช่น โซเชียลมีเดีย อีเมล ฯลฯ) ทำงานกับข้อมูลประเภทต่างๆ (ทั้งที่มีโครงสร้างและไม่มีโครงสร้าง) และรับข้อมูลเชิงลึกอันมีค่าเพื่อนำไปใช้ในวัตถุประสงค์ที่หลากหลายต่อไป (เช่น การประมวลผลบันทึก การวิเคราะห์แคมเปญทางการตลาด การตรวจจับการฉ้อโกง ฯลฯ)
3. ปรับขนาดได้
ข้อดีอีกประการของ Hadoop คือสามารถปรับขนาดได้สูง แพลตฟอร์มนี้ไม่เหมือนกับ ระบบฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม (RDBMS) ซึ่ง ช่วยให้ธุรกิจสามารถจัดเก็บและแจกจ่ายชุดข้อมูลขนาดใหญ่จากเซิร์ฟเวอร์หลายร้อยเครื่องที่ทำงานคู่ขนานกัน
4. คุ้มค่า
Apache Hadoop เมื่อเทียบกับเครื่องมือวิเคราะห์ข้อมูลขนาดใหญ่อื่น ๆ มีราคาไม่แพงมาก เนื่องจากไม่ต้องใช้เครื่องจักรพิเศษใดๆ มันทำงานบนกลุ่มของฮาร์ดแวร์สินค้าโภคภัณฑ์ นอกจากนี้ยังง่ายกว่าในการเพิ่มโหนดเพิ่มเติมในระยะยาว
หมายความว่า หนึ่งกรณีเพิ่มโหนดได้อย่างง่ายดายโดยไม่ต้องทนทุกข์กับการหยุดทำงานของข้อกำหนดล่วงหน้าในการวางแผน
5. ปริมาณงานสูง
ในกรณีของเฟรมเวิร์ก Hadoop ข้อมูลจะถูกจัดเก็บในลักษณะแบบกระจายเพื่อให้งานขนาดเล็กถูกแบ่งออกเป็นหลายส่วนพร้อมกัน สิ่งนี้ทำให้ธุรกิจต่างๆ ได้งานมากขึ้นในเวลาที่น้อยลง ซึ่งส่งผลให้มีปริมาณงานสูงขึ้นในที่สุด
6. ยืดหยุ่นต่อความล้มเหลว
สุดท้ายแต่ไม่ท้ายสุด Hadoop เสนอตัวเลือกความทนทานต่อข้อผิดพลาดสูง ซึ่งช่วยลดผลที่ตามมาของความล้มเหลว มันเก็บแบบจำลองของทุกบล็อกที่ทำให้สามารถกู้คืนข้อมูลได้ทุกเมื่อที่โหนดหยุดทำงาน
ข้อเสียของ Hadoop Framework
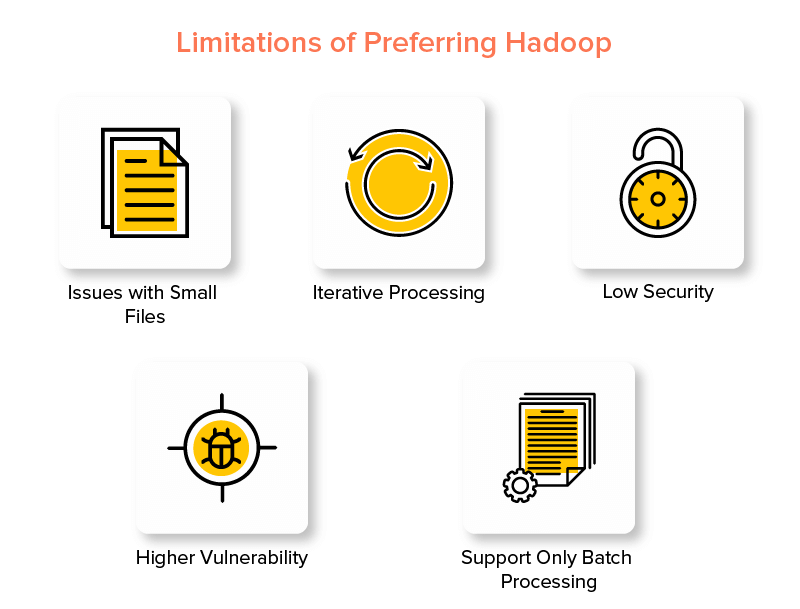
1. ปัญหาเกี่ยวกับไฟล์ขนาดเล็ก
ข้อเสียที่ใหญ่ที่สุดของการพิจารณา Hadoop สำหรับการวิเคราะห์ข้อมูลขนาดใหญ่คือ ไม่มีศักยภาพในการสนับสนุนการอ่านไฟล์ขนาดเล็กแบบสุ่มอย่างมีประสิทธิภาพและประสิทธิผล
เหตุผลเบื้องหลังคือไฟล์ขนาดเล็กมีขนาดหน่วยความจำที่ต่ำกว่าขนาดบล็อก HDFS ในสถานการณ์เช่นนี้ หากจัดเก็บไฟล์ขนาดเล็กจำนวนมาก มีโอกาสสูงที่จะโอเวอร์โหลด NameNode ที่เก็บเนมสเปซของ HDFS ซึ่งในทางปฏิบัติแล้วไม่ใช่ความคิดที่ดี
2. การประมวลผลซ้ำ
การไหลของข้อมูลในกรอบงาน Hadoop ข้อมูลขนาดใหญ่อยู่ในรูปแบบของลูกโซ่ ดังนั้นผลลัพธ์ของข้อมูลหนึ่งจะกลายเป็นอินพุตของอีกขั้นตอนหนึ่ง ในขณะที่การไหลของข้อมูลในการประมวลผลแบบวนซ้ำมีลักษณะเป็นวัฏจักร
ด้วยเหตุนี้ Hadoop จึงเป็นตัวเลือกที่ไม่เหมาะสมกับการเรียนรู้ด้วยเครื่องหรือโซลูชันที่ใช้การประมวลผลแบบวนซ้ำ
3. ความปลอดภัยต่ำ
ข้อเสียอีกประการหนึ่งของการใช้เฟรมเวิร์ก Hadoop คือมีคุณสมบัติด้านความปลอดภัยที่ต่ำกว่า
เฟรมเวิร์ก เช่น ปิดใช้งานโมเดลความปลอดภัยตามค่าเริ่มต้น หากผู้ที่ใช้เครื่องมือข้อมูลขนาดใหญ่นี้ไม่ทราบวิธีเปิดใช้งาน ข้อมูลของพวกเขาอาจมีความเสี่ยงสูงที่จะถูกขโมย/นำไปใช้ในทางที่ผิด นอกจากนี้ Hadoop ยังไม่มีฟังก์ชันการเข้ารหัสที่ระดับการจัดเก็บข้อมูลและเครือข่าย ซึ่งเพิ่มโอกาสในการคุกคามข้อมูลอีกครั้ง
4. ช่องโหว่ที่สูงขึ้น
Hadoop framework เขียนด้วย Java ซึ่งเป็นภาษาการเขียนโปรแกรมที่ได้รับความนิยมมากที่สุด ซึ่งช่วยให้อาชญากรไซเบอร์เข้าถึงโซลูชันที่ใช้ Hadoop ได้ง่ายขึ้นและใช้ข้อมูลที่ละเอียดอ่อนในทางที่ผิด
5. รองรับการประมวลผลแบบแบตช์เท่านั้น
Hadoop ไม่ประมวลผลข้อมูลที่สตรีม ไม่เหมือนกับเฟรมเวิร์ก Big Data อื่นๆ รองรับ การประมวลผลแบบแบ ตช์เท่านั้น และเหตุผลเบื้องหลังก็คือ MapReduce ล้มเหลวในการใช้ประโยชน์จากหน่วยความจำของ Hadoop Cluster ให้ได้มากที่สุด
แม้ว่าทั้งหมดนี้เกี่ยวกับ Hadoop คุณลักษณะและข้อเสียของมัน ให้มาดูข้อดีและข้อเสียของ Spark เพื่อค้นหาความสะดวกในการทำความเข้าใจความแตกต่างระหว่างทั้งสอง
ประโยชน์ของ Apache Spark Framework
1. ไดนามิกในธรรมชาติ
เนื่องจาก Apache Spark มีโอเปอเรเตอร์ระดับสูงประมาณ 80 ตัว จึงสามารถใช้สำหรับการประมวลผลข้อมูลแบบไดนามิกได้ ถือได้ว่าเป็นเครื่องมือบิ๊กดาต้าที่เหมาะสมในการพัฒนาและจัดการแอพคู่ขนาน
2. ทรงพลัง
เนื่องจากความสามารถในการประมวลผลข้อมูลในหน่วยความจำที่มีความหน่วงต่ำและความพร้อมใช้งานของไลบรารีในตัวที่หลากหลายสำหรับการเรียนรู้ของเครื่องและอัลกอริธึมการวิเคราะห์กราฟ จึงสามารถรองรับความท้าทายด้านการวิเคราะห์ต่างๆ ทำให้เป็นตัวเลือกข้อมูลขนาดใหญ่ที่มีประสิทธิภาพในตลาด
3. การวิเคราะห์ขั้นสูง
คุณสมบัติที่โดดเด่นอีกประการของ Spark คือมันไม่เพียงสนับสนุน 'MAP' และ 'reduce' แต่ยังสนับสนุน Machine Learning (ML), การสืบค้น SQL, อัลกอริธึมกราฟ และข้อมูลสตรีมมิ่ง ทำให้เหมาะสำหรับการเพลิดเพลินกับการวิเคราะห์ขั้นสูง
4. การนำกลับมาใช้ใหม่
โค้ด Spark ต่างจาก Hadoop ตรงที่สามารถนำมาใช้ซ้ำสำหรับการประมวลผลแบบกลุ่ม เรียกใช้การค้นหาเฉพาะกิจในสถานะสตรีม เข้าร่วมสตรีมกับข้อมูลในอดีต และอื่นๆ
5. การประมวลผลสตรีมตามเวลาจริง
ข้อดีอีกประการของการใช้ Apache Spark ก็คือช่วยให้สามารถจัดการและประมวลผลข้อมูลได้แบบเรียลไทม์
6. การสนับสนุนหลายภาษา
สุดท้ายแต่ไม่ท้ายสุด เครื่องมือวิเคราะห์ข้อมูลขนาดใหญ่นี้รองรับหลายภาษาสำหรับการเข้ารหัส ซึ่งรวมถึง Java, Python และ Scala
ข้อจำกัดของ Spark Big Data Tool

1. ไม่มีกระบวนการจัดการไฟล์
ข้อเสียเปรียบหลักของการใช้ Apache Spark คือไม่มีระบบจัดการไฟล์ของตัวเอง มันอาศัยแพลตฟอร์มอื่นเช่น Hadoop เพื่อให้เป็นไปตามข้อกำหนดนี้
2. อัลกอริธึมน้อย
Apache Spark ยังล้าหลังเฟรมเวิร์กข้อมูลขนาดใหญ่อื่นๆ เมื่อพิจารณาถึงความพร้อมใช้งานของอัลกอริทึม เช่น ระยะทาง Tanimoto
3. ปัญหาไฟล์ขนาดเล็ก
ข้อเสียอีกประการของการใช้ Spark คือไม่สามารถจัดการไฟล์ขนาดเล็กได้อย่างมีประสิทธิภาพ
เนื่องจากทำงานร่วมกับ Hadoop Distributed File System (HDFS) ซึ่งช่วยให้จัดการไฟล์ขนาดใหญ่ในจำนวนจำกัดบนไฟล์ขนาดเล็กจำนวนมากได้ง่ายขึ้น
4. ไม่มีกระบวนการเพิ่มประสิทธิภาพอัตโนมัติ
Spark ไม่มีกระบวนการปรับแต่งโค้ดอัตโนมัติไม่เหมือนกับบิ๊กดาต้าและแพลตฟอร์มคลาวด์อื่นๆ หนึ่งต้องปรับโค้ดให้เหมาะสมด้วยตนเองเท่านั้น
5. ไม่เหมาะสำหรับสภาพแวดล้อมแบบผู้ใช้หลายคน
เนื่องจาก Apache Spark ไม่สามารถจัดการผู้ใช้หลายรายพร้อมกันได้ จึงทำงานไม่มีประสิทธิภาพในสภาพแวดล้อมที่มีผู้ใช้หลายราย สิ่งที่เพิ่มข้อจำกัดอีกครั้ง
ด้วยพื้นฐานของทั้งกรอบงานข้อมูลขนาดใหญ่ที่ครอบคลุม เป็นไปได้ที่คุณหวังว่าจะทำความคุ้นเคยกับความแตกต่างระหว่าง Spark และ Hadoop
ดังนั้น อย่ารอช้าแล้วไปเปรียบเทียบกันเพื่อดูว่าทีมใดเป็นผู้นำในการต่อสู้ 'Spark vs Hadoop'
Spark vs Hadoop: เครื่องมือสองข้อมูลขนาดใหญ่ซ้อนกันอย่างไร
[รหัสตาราง=38 /]
1. สถาปัตยกรรม
เมื่อพูดถึงสถาปัตยกรรม Spark และ Hadoop สถาปัตยกรรมแบบหลังจะเป็นผู้นำแม้ว่าทั้งคู่จะทำงานในสภาพแวดล้อมการคำนวณแบบกระจาย
ที่เป็นเช่นนี้เพราะว่าสถาปัตยกรรมของ Hadoop ซึ่งแตกต่างจาก Spark- มีองค์ประกอบหลักสองประการคือ HDFS (Hadoop Distributed File System) และ YARN (Yet Another Resource Negotiator) ที่นี่ HDFS จัดการการจัดเก็บข้อมูลขนาดใหญ่ในโหนดต่างๆ ในขณะที่ YARN ดูแลงานการประมวลผลผ่านการจัดสรรทรัพยากรและกลไกการจัดกำหนดการงาน จากนั้นส่วนประกอบเหล่านี้จะถูกแบ่งออกเป็นส่วนประกอบอื่นๆ เพื่อนำเสนอโซลูชั่นที่ดีขึ้นด้วยบริการต่างๆ เช่น ความทนทานต่อข้อผิดพลาด
2. ใช้งานง่าย
Apache Spark ช่วยให้นักพัฒนาแนะนำ API ต่างๆ ที่เป็นมิตรกับผู้ใช้ได้ เช่น สำหรับ Scala, Python, R, Java และ Spark SQL ในสภาพแวดล้อมการพัฒนา นอกจากนี้ยังมาพร้อมกับโหมดโต้ตอบที่รองรับทั้งผู้ใช้และนักพัฒนา ทำให้ง่ายต่อการใช้งานและมีช่วงการเรียนรู้ต่ำ
ในขณะที่เมื่อพูดถึง Hadoop มันมีส่วนเสริมเพื่อรองรับผู้ใช้ แต่ไม่ใช่โหมดโต้ตอบ สิ่งนี้ทำให้ Spark ชนะ Hadoop ในการต่อสู้ 'ข้อมูลขนาดใหญ่'
3. ความคลาดเคลื่อนและความปลอดภัย
ในขณะที่ทั้ง Apache Spark และ Hadoop MapReduce เสนอสิ่งอำนวยความสะดวกในการทนต่อข้อผิดพลาด แต่อย่างหลังก็ชนะการต่อสู้
เนื่องจากต้องเริ่มต้นจากศูนย์ในกรณีที่กระบวนการขัดข้องระหว่างการทำงานในสภาพแวดล้อม Spark แต่เมื่อพูดถึง Hadoop พวกเขาสามารถดำเนินการต่อจากจุดที่เกิดการชนได้เอง
4. ประสิทธิภาพ
เมื่อพิจารณาถึงประสิทธิภาพของ Spark vs MapReduce อดีตจะชนะอย่างหลัง
เฟรมเวิร์ก Spark สามารถทำงานได้เร็วขึ้น 10 เท่าบนดิสก์และ 100 เท่าในหน่วยความจำ ทำให้สามารถจัดการข้อมูล 100 TB ได้เร็วกว่า Hadoop MapReduce ถึง 3 เท่า
5. การประมวลผลข้อมูล
อีกปัจจัยที่ต้องพิจารณาระหว่างการเปรียบเทียบ Apache Spark กับ Hadoop คือการประมวลผลข้อมูล
แม้ว่า Apache Hadoop จะให้โอกาสในการประมวลผลแบบแบตช์เท่านั้น แต่เฟรมเวิร์กข้อมูลขนาดใหญ่อื่น ๆ ช่วยให้สามารถทำงานกับการประมวลผลเชิงโต้ตอบ การวนซ้ำ สตรีม กราฟ และการประมวลผลแบบแบตช์ สิ่งที่พิสูจน์ได้ว่า Spark เป็นตัวเลือกที่ดีกว่าสำหรับการเพลิดเพลินกับบริการประมวลผลข้อมูลที่ดีขึ้น
6. ความเข้ากันได้
ความเข้ากันได้ของ Spark และ Hadoop MapReduce ค่อนข้างเหมือนกัน
แม้ว่าในบางครั้ง กรอบงานข้อมูลขนาดใหญ่ทั้งสองทำหน้าที่เป็นแอปพลิเคชันแบบสแตนด์อโลน แต่ก็สามารถทำงานร่วมกันได้เช่นกัน Spark สามารถทำงานได้อย่างมีประสิทธิภาพบน Hadoop YARN ในขณะที่ Hadoop สามารถทำงานร่วมกับ Sqoop และ Flume ได้อย่างง่ายดาย ด้วยเหตุนี้ ทั้งสองจึงสนับสนุนแหล่งข้อมูลและรูปแบบไฟล์ของกันและกัน
7. ความปลอดภัย
สภาพแวดล้อม Spark เต็มไปด้วยคุณสมบัติความปลอดภัยที่แตกต่างกัน เช่น การบันทึกเหตุการณ์และการใช้ตัวกรองเซิร์ฟเล็ต javax เพื่อปกป้อง UI ของเว็บ นอกจากนี้ยังสนับสนุนการพิสูจน์ตัวตนผ่านความลับที่ใช้ร่วมกัน และสามารถใช้ประโยชน์จากศักยภาพของการอนุญาตไฟล์ HDFS การเข้ารหัสระหว่างโหมด และ Kerberos เมื่อรวมเข้ากับ YARN และ HDFS
ในขณะที่ Hadoop รองรับการ รับรองความถูกต้องของ Kerberos การรับรองความถูกต้องของบุคคลที่สาม การอนุญาตไฟล์แบบเดิม และรายการควบคุมการเข้าถึง และอื่นๆ ซึ่งให้ผลลัพธ์ด้านความปลอดภัยที่ดีขึ้นในที่สุด
ดังนั้นเมื่อพิจารณาการเปรียบเทียบ Spark กับ Hadoop ในแง่ของความปลอดภัย
8. ความคุ้มค่า
เมื่อเปรียบเทียบ Hadoop และ Spark อดีตต้องการหน่วยความจำบนดิสก์มากกว่าในขณะที่ตัวหลังต้องการ RAM มากกว่า นอกจากนี้ เนื่องจาก Spark นั้นค่อนข้างใหม่เมื่อเปรียบเทียบกับ Apache Hadoop นักพัฒนาที่ทำงานกับ Spark นั้นหายากกว่า
ทำให้การทำงานกับ Spark เป็นเรื่องราคาแพง ความหมาย Hadoop นำเสนอโซลูชันที่คุ้มค่าเมื่อเน้นที่ต้นทุน Hadoop เทียบกับ Spark
9. ขอบเขตตลาด
ในขณะที่ทั้ง Apache Spark และ Hadoop ได้รับการสนับสนุนจากบริษัทขนาดใหญ่และถูกใช้เพื่อวัตถุประสงค์ที่แตกต่างกัน แต่บริษัทหลังนี้เป็นผู้นำในแง่ของขอบเขตตลาด
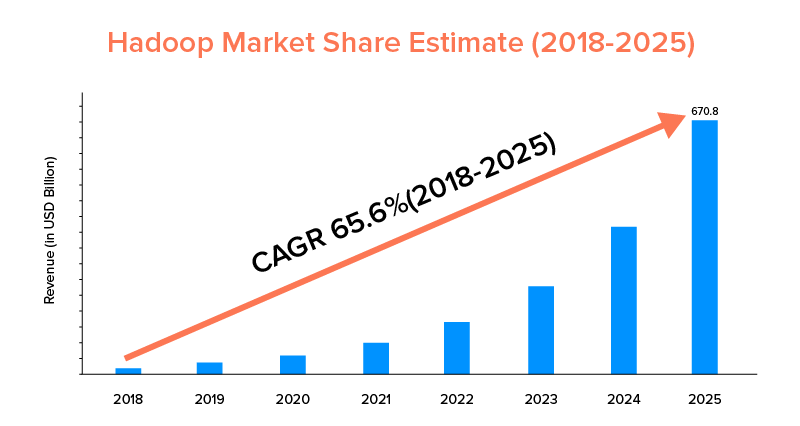
ตามสถิติการตลาด ตลาด Apache Hadoop คาดว่าจะเติบโตด้วย CAGR 65.6% ในช่วงปี 2018 ถึง 2025 เมื่อเทียบกับ Spark ที่มี CAGR 33.9% เท่านั้น
แม้ว่าปัจจัยเหล่านี้จะช่วยในการกำหนดเครื่องมือบิ๊กดาต้าที่เหมาะสมสำหรับธุรกิจของคุณ แต่ก็เป็นประโยชน์ที่จะทำความคุ้นเคยกับกรณีการใช้งานของพวกเขา ดังนั้นขอครอบคลุมที่นี่
กรณีการใช้งานของ Apache Spark Framework
เครื่องมือข้อมูลขนาดใหญ่นี้ได้รับการยอมรับจากธุรกิจต่างๆ เมื่อพวกเขาต้องการ:
- สตรีมและวิเคราะห์ข้อมูลแบบเรียลไทม์
- เพลิดเพลินกับพลังของการเรียนรู้ของเครื่อง
- ทำงานกับการวิเคราะห์เชิงโต้ตอบ
- แนะนำ Fog and Edge Computing ให้กับโมเดลธุรกิจของพวกเขา
กรณีการใช้งานของ Apache Hadoop Framework
Hadoop เป็นที่ต้องการของ startups และ Enterprises เมื่อพวกเขาต้องการ:-
- วิเคราะห์ข้อมูลที่เก็บถาวร
- เพลิดเพลินกับตัวเลือกการซื้อขายและการพยากรณ์ทางการเงินที่ดีขึ้น
- ดำเนินการที่ประกอบด้วยฮาร์ดแวร์สินค้าโภคภัณฑ์
- พิจารณาการประมวลผลข้อมูลเชิงเส้น
ด้วยวิธีนี้ เราหวังว่าคุณจะตัดสินใจได้ว่าทีมใดเป็นผู้ชนะในการต่อสู้ 'Spark vs Hadoop' ในส่วนที่เกี่ยวกับธุรกิจของคุณ ถ้าไม่ อย่าลังเลที่จะ ติดต่อกับผู้เชี่ยวชาญด้านข้อมูลขนาดใหญ่ของเรา เพื่อไขข้อสงสัยและรับบริการที่เป็นแบบอย่างที่มีอัตราความสำเร็จที่สูงขึ้น
คำถามที่พบบ่อย
1. Big Data Framework ใดให้เลือก
ทางเลือกขึ้นอยู่กับความต้องการทางธุรกิจของคุณ หากคุณมุ่งเน้นที่ประสิทธิภาพ ความเข้ากันได้ของข้อมูล และการใช้งานง่าย Spark ดีกว่า Hadoop ในขณะที่กรอบงานข้อมูลขนาดใหญ่ของ Hadoop จะดีกว่าเมื่อคุณมุ่งเน้นไปที่สถาปัตยกรรม ความปลอดภัย และความคุ้มค่า
2. อะไรคือความแตกต่างระหว่าง Hadoop และ Spark?
มีความแตกต่างหลายประการระหว่าง Spark และ Hadoop ตัวอย่างเช่น:-
- Spark เป็นปัจจัย 100 เท่าที่ Hadoop MapReduce
- ในขณะที่ Hadoop ใช้สำหรับการประมวลผลแบบแบตช์ Spark นั้นมีไว้สำหรับแบทช์ กราฟ การเรียนรู้ของเครื่อง และการประมวลผลแบบวนซ้ำ
- Spark มีขนาดกะทัดรัดและง่ายกว่าเฟรมเวิร์กข้อมูลขนาดใหญ่ของ Hadoop
- Hadoop ไม่รองรับการแคชข้อมูลต่างจาก Spark
3. Spark ดีกว่า Hadoop หรือไม่?
Spark ดีกว่า Hadoop เมื่อเน้นที่ความเร็วและความปลอดภัยเป็นหลัก อย่างไรก็ตาม ในกรณีอื่นๆ เครื่องมือวิเคราะห์ข้อมูลขนาดใหญ่นี้จะล้าหลัง Apache Hadoop
4. ทำไม Spark ถึงเร็วกว่า Hadoop?
Spark เร็วกว่า Hadoop เนื่องจากจำนวนรอบการอ่าน/เขียนที่ต่ำกว่าบนดิสก์และการจัดเก็บข้อมูลระดับกลางในหน่วยความจำ
5. Apache Spark ใช้สำหรับอะไร?
Apache Spark ใช้สำหรับการวิเคราะห์ข้อมูลเมื่อต้องการ
- วิเคราะห์ข้อมูลแบบเรียลไทม์
- แนะนำ ML และ Fog Computing ในรูปแบบธุรกิจของคุณ
- ทำงานกับการวิเคราะห์เชิงโต้ตอบ