
TW-BERT: การถ่วงน้ำหนักข้อความค้นหาตั้งแต่ต้นจนจบและอนาคตของ Google Search
เผยแพร่แล้ว: 2023-09-14การค้นหาเป็นเรื่องยาก ดังที่ Seth Godin เขียนเมื่อปี 2548
ฉันหมายถึง ถ้าเราคิดว่า SEO นั้นยาก (และเป็นเช่นนั้น) ลองจินตนาการว่าคุณกำลังพยายามสร้างเครื่องมือค้นหาในโลกที่:
- ผู้ใช้มีความแตกต่างกันอย่างมากและเปลี่ยนการตั้งค่าเมื่อเวลาผ่านไป
- เทคโนโลยีที่พวกเขาเข้าถึงมีความก้าวหน้าในการค้นหาทุกวัน
- คู่แข่งคอยจับจ้องคุณอยู่ตลอดเวลา
ยิ่งไปกว่านั้น คุณยังต้องรับมือกับ SEO ที่น่ารำคาญที่พยายาม สร้างอัลกอริทึมของคุณ เพื่อรับข้อมูลเชิงลึกเกี่ยวกับวิธีที่ดีที่สุดในการเพิ่มประสิทธิภาพให้กับผู้เยี่ยมชมของคุณ
นั่นจะทำให้มันยากขึ้นมาก
ลองจินตนาการดูว่าเทคโนโลยีหลักที่คุณต้องพึ่งพาเพื่อความก้าวหน้านั้นมีข้อจำกัดของตัวเองหรือไม่ และอาจแย่กว่านั้นคือต้องมีค่าใช้จ่ายมหาศาล
หากคุณเป็นหนึ่งในผู้เขียนบทความที่ตีพิมพ์เมื่อเร็วๆ นี้ "การถ่วงน้ำหนักคำค้นหาแบบ End-to-End" คุณจะเห็นว่านี่เป็นโอกาสที่จะโดดเด่น
การถ่วงน้ำหนักคำค้นหาจากต้นทางถึงปลายทางคืออะไร
การถ่วงน้ำหนักคำค้นหาจากต้นทางถึงปลายทางหมายถึงวิธีการที่น้ำหนักของแต่ละคำในแบบสอบถามถูกกำหนดให้เป็นส่วนหนึ่งของโมเดลโดยรวม โดยไม่ต้องอาศัยรูปแบบการถ่วงน้ำหนักคำที่ตั้งโปรแกรมด้วยตนเองหรือแบบดั้งเดิม หรือโมเดลอิสระอื่นๆ
มันมีลักษณะอย่างไร?
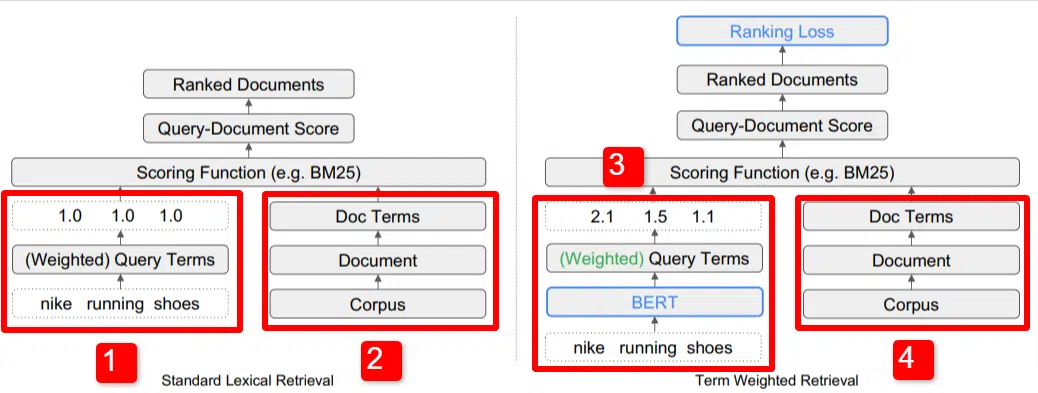
ที่นี่เราเห็นภาพประกอบของ หนึ่งใน ตัวสร้างความแตกต่างที่สำคัญของแบบจำลองที่ระบุไว้ในรายงาน (โดยเฉพาะรูปที่ 1)
ทางด้านขวาของโมเดลมาตรฐาน (2) เราจะเห็นแบบเดียวกับที่เราทำกับโมเดลที่เสนอ (4) ซึ่งก็คือคลังข้อมูล (เอกสารชุดเต็มในดัชนี) ที่นำไปสู่เอกสาร ซึ่งนำไปสู่ข้อกำหนด
สิ่งนี้แสดงให้เห็นลำดับชั้นที่แท้จริงในระบบ แต่คุณสามารถคิดย้อนกลับจากบนลงล่างได้ เรามีเงื่อนไข เราค้นหาเอกสารที่มีเงื่อนไขเหล่านั้น เอกสารเหล่านั้นอยู่ในคลังข้อมูลของเอกสารทั้งหมดที่เราทราบ
ที่ด้านซ้ายล่าง (1) ในสถาปัตยกรรมการเรียกข้อมูล (IR) มาตรฐาน คุณจะสังเกตเห็นว่าไม่มีเลเยอร์ BERT ข้อความค้นหาที่ใช้ในภาพประกอบ (รองเท้าวิ่ง Nike) จะเข้าสู่ระบบ และน้ำหนักจะถูกคำนวณโดยไม่ขึ้นอยู่กับโมเดลและส่งต่อไป
ในภาพประกอบนี้ น้ำหนักจะผ่านไปเท่ากันระหว่างคำสามคำในแบบสอบถาม อย่างไรก็ตาม มันไม่จำเป็นต้องเป็นอย่างนั้น มันเป็นเพียงตัวอย่างเริ่มต้นและดี
สิ่งสำคัญที่ต้องทำความเข้าใจคือน้ำหนักถูกกำหนดจากภายนอกโมเดลและป้อนพร้อมกับแบบสอบถาม เราจะอธิบายว่าเหตุใดสิ่งนี้จึงสำคัญในช่วงเวลาสั้นๆ
หากเราดูเวอร์ชันน้ำหนักของเทอมทางด้านขวา คุณจะเห็นว่าข้อความค้นหา “nike running shoes” ป้อน BERT (ให้เจาะจง Term Weighting BERT หรือ TW-BERT) ซึ่งใช้เพื่อกำหนดน้ำหนักที่ จะนำไปใช้กับข้อความค้นหานั้นได้ดีที่สุด
จากนั้นสิ่งต่างๆ จะเป็นไปตามเส้นทางที่คล้ายกันสำหรับทั้งคู่ ฟังก์ชันการให้คะแนนจะถูกใช้และเอกสารจะถูกจัดอันดับ แต่มีขั้นตอนสุดท้ายที่สำคัญสำหรับโมเดลใหม่ นั่นคือประเด็นสำคัญของทั้งหมด นั่นก็คือการคำนวณการสูญเสียอันดับ
การคำนวณที่ฉันอ้างถึงข้างต้นนี้ ทำให้น้ำหนักที่กำหนดภายในแบบจำลองมีความสำคัญมาก เพื่อทำความเข้าใจสิ่งนี้ให้ดีที่สุด เราพักไว้ก่อนเพื่อหารือเกี่ยวกับฟังก์ชันการสูญเสีย ซึ่งเป็นสิ่งสำคัญที่จะต้องเข้าใจอย่างแท้จริงว่าเกิดอะไรขึ้นที่นี่
ฟังก์ชั่นการสูญเสียคืออะไร?
ในแมชชีนเลิร์นนิง ฟังก์ชันการสูญเสียโดยพื้นฐานแล้วคือการคำนวณว่าระบบมีความผิดพลาดเพียงใดกับระบบดังกล่าวที่พยายามเรียนรู้ที่จะเข้าใกล้การสูญเสียเป็นศูนย์มากที่สุดเท่าที่จะเป็นไปได้
ยกตัวอย่างแบบจำลองที่ออกแบบมาเพื่อกำหนดราคาบ้าน หากคุณกรอกสถิติทั้งหมดของบ้านและมีมูลค่า 250,000 ดอลลาร์ แต่บ้านของคุณขายได้ในราคา 260,000 ดอลลาร์ ส่วนต่างจะถือเป็นการสูญเสีย (ซึ่งเป็นมูลค่าสัมบูรณ์)
จากตัวอย่างจำนวนมาก โมเดลได้รับการสอนให้ลดการสูญเสียให้เหลือน้อยที่สุดโดยการกำหนดน้ำหนักที่แตกต่างกันให้กับพารามิเตอร์ที่ได้รับจนกว่าจะได้ผลลัพธ์ที่ดีที่สุด พารามิเตอร์ในกรณีนี้อาจรวมถึงสิ่งต่างๆ เช่น ตารางฟุต ห้องนอน ขนาดสนามหญ้า ความใกล้ชิดกับโรงเรียน ฯลฯ
ตอนนี้ กลับไปที่การถ่วงน้ำหนักคำค้นหา
เมื่อมองย้อนกลับไปที่ตัวอย่างทั้งสองข้างต้น สิ่งที่เราต้องมุ่งเน้นคือการมีแบบจำลอง BERT ที่ให้น้ำหนักกับเงื่อนไขในช่องทางล่างของการคำนวณการสูญเสียการจัดอันดับ
เพื่อให้แตกต่างออกไป ในรูปแบบดั้งเดิม การถ่วงน้ำหนักของเงื่อนไขนั้นทำโดยไม่ขึ้นกับตัวโมเดลเอง ดังนั้น จึงไม่สามารถตอบสนองต่อประสิทธิภาพของโมเดลโดยรวมได้ ไม่สามารถเรียนรู้วิธีการปรับปรุงน้ำหนักได้

ในระบบที่นำเสนอ การเปลี่ยนแปลงนี้ การถ่วงน้ำหนักจะทำจากภายในตัวแบบจำลอง ดังนั้น เนื่องจากแบบจำลองพยายามปรับปรุงประสิทธิภาพและลดฟังก์ชันการสูญเสีย จึงจะมีวงแหวนพิเศษเหล่านี้เพื่อเปลี่ยนการนำการถ่วงน้ำหนักคำศัพท์มาสู่สมการ อย่างแท้จริง.
แกรม
TW-BERT ไม่ได้ออกแบบมาเพื่อใช้งานในแง่ของคำ แต่เป็น ngram
ผู้เขียนรายงานอธิบายได้ดีว่าทำไมพวกเขาถึงใช้ ngrams แทนคำ เมื่อพวกเขาชี้ให้เห็นว่าในแบบสอบถาม "nike running shoes" หากคุณเพียงแค่ให้น้ำหนักคำ จากนั้นหน้าที่มีการกล่าวถึงคำว่า nike, running และ shoes ก็สามารถจัดอันดับได้ดี หากเป็นเรื่อง "ถุงเท้าวิ่ง Nike" และ "รองเท้าสเก็ต"
วิธีการ IR แบบเดิมใช้สถิติการสืบค้นและสถิติเอกสาร และอาจแสดงหน้าที่มีปัญหานี้หรือคล้ายกัน ความพยายามที่ผ่านมาในการแก้ไขปัญหานี้เน้นไปที่การเกิดขึ้นร่วมกันและการเรียงลำดับ
ในโมเดลนี้ เอ็นแกรมจะถูกถ่วงน้ำหนักเหมือนกับคำที่อยู่ในตัวอย่างก่อนหน้าของเรา ดังนั้นเราจึงได้ผลลัพธ์ดังนี้:
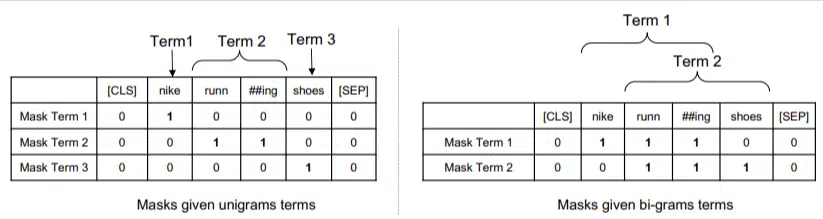
ทางด้านซ้าย เราจะเห็นว่าข้อความค้นหาจะมีน้ำหนักเป็นหน่วยกรัม (ngrams 1 คำ) อย่างไร และทางด้านขวาคือ bi-grams (ngrams 2 คำ)
เนื่องจากมีการถ่วงน้ำหนักไว้ในระบบ ระบบจึงสามารถฝึกการเรียงสับเปลี่ยนทั้งหมดเพื่อกำหนด ngrams ที่ดีที่สุดและน้ำหนักที่เหมาะสมสำหรับแต่ละรายการ แทนที่จะอาศัยเพียงสถิติ เช่น ความถี่
ยิงเป็นศูนย์
คุณสมบัติที่สำคัญของโมเดลนี้คือประสิทธิภาพในการทำงานที่ไม่สั้น ผู้เขียนทำการทดสอบเมื่อ:
- ชุดข้อมูล MS MARCO – ชุดข้อมูล Microsoft สำหรับการจัดอันดับเอกสารและข้อความ
- ชุดข้อมูล TREC-covid – บทความและการศึกษาเรื่อง covid
- Strong04 – บทความข่าว
- Common Core – บทความทางการศึกษาและโพสต์ในบล็อก
พวกเขามีข้อสืบค้นเพื่อการประเมินผลเพียงเล็กน้อยเท่านั้น และไม่ได้ใช้เลยในการปรับแต่ง ทำให้เป็นการทดสอบแบบ Zero-shot เนื่องจากโมเดลไม่ได้รับการฝึกฝนให้จัดอันดับเอกสารในโดเมนเหล่านี้โดยเฉพาะ ผลลัพธ์คือ:
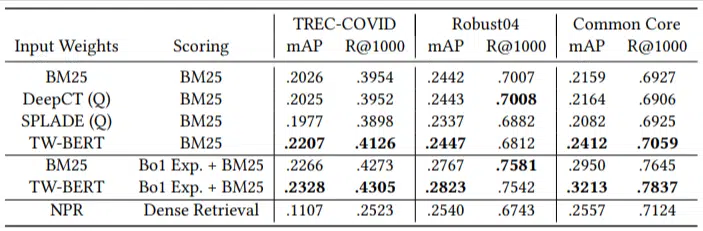
มีประสิทธิภาพเหนือกว่าในงานส่วนใหญ่และทำงานได้ดีที่สุดกับข้อความค้นหาที่สั้นกว่า (1 ถึง 10 คำ)
และเป็นแบบพลักแอนด์เพลย์!
ตกลง นั่นอาจจะง่ายเกินไป แต่ผู้เขียนเขียนว่า:
“การจัด TW-BERT ให้สอดคล้องกับตัวให้คะแนนเครื่องมือค้นหา จะช่วยลดการเปลี่ยนแปลงที่จำเป็นในการรวมเข้ากับแอปพลิเคชันที่ใช้งานจริงที่มี อยู่ ในขณะที่วิธีค้นหาแบบการเรียนรู้เชิงลึกที่มีอยู่จะต้องมีการเพิ่มประสิทธิภาพโครงสร้างพื้นฐานและข้อกำหนดด้านฮาร์ดแวร์เพิ่มเติม น้ำหนักที่เรียนรู้สามารถนำไปใช้ได้อย่างง่ายดายโดยผู้ดึงศัพท์มาตรฐานและโดยเทคนิคการดึงข้อมูลอื่นๆ เช่น การขยายแบบสอบถาม”
เนื่องจาก TW-BERT ได้รับการออกแบบมาเพื่อรวมเข้ากับระบบปัจจุบัน การบูรณาการจึงง่ายกว่าและราคาถูกกว่าตัวเลือกอื่นๆ มาก
ทั้งหมดนี้มีความหมายอย่างไรสำหรับคุณ
ด้วยโมเดลแมชชีนเลิร์นนิง เป็นการยากที่จะคาดเดาตัวอย่างว่าคุณในฐานะ SEO จะทำอะไรได้บ้าง (นอกเหนือจากการใช้งานที่มองเห็นได้ เช่น Bard หรือ ChatGPT)
การเรียงสับเปลี่ยนของโมเดลนี้จะถูกปรับใช้อย่างไม่ต้องสงสัย เนื่องจากมีการปรับปรุงและความง่ายในการปรับใช้ (สมมติว่าข้อความนั้นถูกต้อง)
อย่างไรก็ตาม นี่คือการปรับปรุงคุณภาพชีวิตของ Google ที่จะปรับปรุงการจัดอันดับและผลลัพธ์แบบ Zero-Shot ด้วยต้นทุนที่ต่ำ
สิ่งที่เราวางใจได้จริงๆ ก็คือ หากนำไปใช้จริง ผลลัพธ์ที่ดีกว่าก็จะแสดงออกมาได้อย่างน่าเชื่อถือมากขึ้น และนั่นถือเป็นข่าวดีสำหรับผู้เชี่ยวชาญด้าน SEO
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญ และไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนเจ้าหน้าที่มีอยู่ที่นี่