
กรณีศึกษา SEO ตลอดทั้งปี: สิ่งที่คุณต้องรู้เกี่ยวกับ Googlebot
เผยแพร่แล้ว: 2019-08-30หมายเหตุบรรณาธิการ: CEO ของโปรแกรมรวบรวมข้อมูล JetOctopus Serge Bezborodov ให้คำแนะนำจากผู้เชี่ยวชาญเกี่ยวกับวิธีทำให้เว็บไซต์ของคุณน่าสนใจสำหรับ Googlebot ข้อมูลในบทความนี้อ้างอิงจากการวิจัยตลอดทั้งปีและการรวบรวมข้อมูลหน้าเว็บ 300 ล้านหน้า
ไม่กี่ปีที่ผ่านมา ฉันพยายามเพิ่มการเข้าชมเว็บไซต์รวบรวมงานของเราด้วยหน้าเว็บ 5 ล้านหน้า ฉันตัดสินใจใช้บริการเอเจนซี่ SEO โดยคาดหวังว่าทราฟฟิกจะทะลุหลังคา แต่ฉันคิดผิด แทนที่จะตรวจสอบอย่างรอบด้าน ฉันได้อ่านไพ่ทาโรต์ นั่นเป็นเหตุผลที่ฉันกลับไปที่สแควร์วันและสร้างโปรแกรมรวบรวมข้อมูลเว็บสำหรับการวิเคราะห์ SEO ในหน้าเว็บที่ครอบคลุม
ฉันสอดแนม Googlebot มานานกว่าหนึ่งปีแล้ว และตอนนี้ฉันพร้อมที่จะแบ่งปันข้อมูลเชิงลึกเกี่ยวกับพฤติกรรมของมันแล้ว ฉันคาดหวังว่าการสังเกตของฉันจะอธิบายวิธีการทำงานของโปรแกรมรวบรวมข้อมูลเว็บเป็นอย่างน้อย และอย่างน้อยก็จะช่วยให้คุณดำเนินการเพิ่มประสิทธิภาพบนหน้าเว็บได้อย่างมีประสิทธิภาพ ฉันรวบรวมข้อมูลที่มีประโยชน์ที่สุดสำหรับเว็บไซต์ใหม่หรือเว็บไซต์ที่มีหน้าเว็บนับพันหน้า
เพจของคุณแสดงใน SERPs หรือไม่?
หากต้องการทราบแน่ชัดว่าหน้าใดอยู่ในผลการค้นหา คุณควรตรวจสอบความสามารถในการจัดทำดัชนีของทั้งเว็บไซต์ อย่างไรก็ตาม การวิเคราะห์แต่ละ URL บนเว็บไซต์ที่มีหน้าเว็บมากกว่า 10 ล้านหน้านั้นมีค่าใช้จ่ายสูงพอๆ กับรถยนต์คันใหม่
ลองใช้การวิเคราะห์ไฟล์บันทึกแทน เราทำงานกับเว็บไซต์ด้วยวิธีต่อไปนี้: เรารวบรวมข้อมูลหน้าเว็บตามที่บอทค้นหาทำ จากนั้นเราจะวิเคราะห์ไฟล์บันทึกที่รวบรวมมาเป็นเวลาครึ่งปี บันทึกแสดงว่าบ็อตเยี่ยมชมเว็บไซต์หรือไม่ หน้าใดบ้างที่ถูกรวบรวมข้อมูล และเมื่อใดและบ่อยแค่ไหนที่บ็อตเยี่ยมชมหน้านั้น
การรวบรวมข้อมูลเป็นกระบวนการของบอทค้นหาที่เยี่ยมชมเว็บไซต์ของคุณ ประมวลผลลิงก์ทั้งหมดบนหน้าเว็บและวางลิงก์เหล่านี้ในบรรทัดสำหรับการจัดทำดัชนี ระหว่างการรวบรวมข้อมูล บ็อตจะเปรียบเทียบ URL ที่เพิ่งประมวลผลกับ URL ที่มีอยู่แล้วในดัชนี ดังนั้น บอทจะรีเฟรชข้อมูลและเพิ่ม/ลบบาง URL จากฐานข้อมูลเครื่องมือค้นหาเพื่อให้ผลลัพธ์ที่เกี่ยวข้องและใหม่ที่สุดสำหรับผู้ใช้
ตอนนี้เราสามารถสรุปได้อย่างง่ายดาย:
- URL นี้อาจจะไม่อยู่ในดัชนี ยกเว้นกรณีที่บอทค้นหาอยู่ใน URL
- หาก Googlebot เข้าชม URL ดังกล่าวหลายครั้งต่อวัน URL นั้นจะมีลำดับความสำคัญสูง ดังนั้นคุณต้องให้ความสนใจเป็นพิเศษ
ข้อมูลนี้แสดงให้เห็นว่าอะไรขัดขวางการเติบโตและการพัฒนาเว็บไซต์ของคุณ ตอนนี้ แทนที่จะทำงานสุ่มสี่สุ่มห้า ทีมของคุณสามารถเพิ่มประสิทธิภาพเว็บไซต์ได้อย่างชาญฉลาด
เราทำงานกับเว็บไซต์ขนาดใหญ่เป็นส่วนใหญ่ เพราะหากเว็บไซต์ของคุณมีขนาดเล็ก Googlebot จะรวบรวมข้อมูลหน้าเว็บทั้งหมดของคุณไม่ช้าก็เร็ว
ในทางกลับกัน เว็บไซต์ที่มีหน้าเว็บมากกว่า 100 หน้าที่ประสบปัญหาเมื่อโปรแกรมรวบรวมข้อมูลเข้าชมหน้าเว็บที่ผู้ดูแลเว็บมองไม่เห็น งบประมาณในการรวบรวมข้อมูลอันมีค่าอาจสูญเปล่าไปกับหน้าที่ไร้ประโยชน์หรือเป็นอันตรายเหล่านี้ ในเวลาเดียวกัน บอทอาจไม่พบหน้าที่ทำกำไรของคุณ เนื่องจากโครงสร้างเว็บไซต์มีความยุ่งเหยิง
งบประมาณการรวบรวมข้อมูลคือทรัพยากรที่จำกัดซึ่ง Googlebot พร้อมที่จะใช้จ่ายบนเว็บไซต์ของคุณ มันถูกสร้างขึ้นเพื่อจัดลำดับความสำคัญของสิ่งที่จะวิเคราะห์และเมื่อใด ขนาดของงบประมาณการรวบรวมข้อมูลขึ้นอยู่กับหลายปัจจัย เช่น ขนาดของเว็บไซต์ โครงสร้าง ปริมาณ และความถี่ของข้อความค้นหาของผู้ใช้ เป็นต้น
โปรดทราบว่าบอทการค้นหาไม่สนใจที่จะรวบรวมข้อมูลเว็บไซต์ของคุณทั้งหมด
จุดประสงค์หลักของบอตเครื่องมือค้นหาคือการให้คำตอบที่เกี่ยวข้องมากที่สุดแก่ผู้ใช้โดยสูญเสียทรัพยากรน้อยที่สุดบอตรวบรวมข้อมูลมากเท่าที่จำเป็นสำหรับวัตถุประสงค์หลัก ดังนั้น หน้าที่ของคุณคือช่วยบอตเลือกเนื้อหาที่มีประโยชน์และให้ผลกำไรสูงสุด
การสอดแนม Googlebot
ในปีที่ผ่านมา เราได้สแกนมากกว่า 300 ล้าน URL และ 6 พันล้านบรรทัดบันทึกบนเว็บไซต์ขนาดใหญ่ จากข้อมูลนี้ เราได้ติดตามพฤติกรรมของ Googlebot เพื่อช่วยตอบคำถามต่อไปนี้:
- เพจประเภทใดบ้างที่ถูกละเว้น?
- หน้าไหนเข้าบ่อย?
- อะไรคือสิ่งที่ควรค่าแก่ความสนใจสำหรับบอท?
- อะไรไม่มีค่า?
ด้านล่างนี้คือการวิเคราะห์และการค้นพบของเรา ไม่ใช่การเขียนหลักเกณฑ์สำหรับผู้ดูแลเว็บของ Google ใหม่ อันที่จริง เราไม่ได้ให้คำแนะนำที่ไม่ได้รับการพิสูจน์และไม่ยุติธรรมใดๆ แต่ละจุดขึ้นอยู่กับสถิติข้อเท็จจริงและกราฟเพื่อความสะดวกของคุณ
ลองตัดการไล่ล่าและค้นหา:
- สิ่งที่สำคัญสำหรับ Googlebot คืออะไร
- อะไรเป็นตัวกำหนดว่าบอทเข้าชมเพจหรือไม่?
เราระบุปัจจัยต่อไปนี้:
ระยะทางจากดัชนี
DFI ย่อมาจาก Distance From Index และเป็นระยะทางที่ URL ของคุณสำหรับ URL หลัก/รูท/ดัชนีในการคลิก เป็นหนึ่งในเกณฑ์ที่สำคัญที่สุดที่ส่งผลต่อความถี่ในการเข้าชมของ Googlebot นี่ คือ วิดีโอเพื่อการศึกษาเพื่อ เรียนรู้เพิ่มเติมเกี่ยวกับ DFI
โปรดทราบว่า DFI ไม่ใช่จำนวนของเครื่องหมายทับในไดเรกทอรี URL เช่น:
site.com / ร้านค้า /iphone/iphoneX.html – DFI – 3
ดังนั้น DFI จึงถูกนับตามจำนวนคลิกจากหน้าหลัก
https://site.com/shop/iphone/iphoneX.html
https://site.com แคตตาล็อก iPhone → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
ด้านล่างนี้ คุณจะเห็นความสนใจของ Googlebot ใน URL ที่มี DFI ของมันค่อยๆ ลดลงในช่วงเดือนที่ผ่านมาและในช่วงหกเดือนที่ผ่านมา
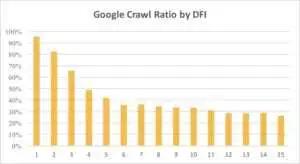
อย่างที่คุณเห็น หาก DFI เป็น 5 t0 6 Googlebot จะรวบรวมข้อมูลหน้าเว็บเพียงครึ่งเดียว และเปอร์เซ็นต์ของหน้าที่ประมวลผลจะลดลงหาก DFI มีขนาดใหญ่ ตัวบ่งชี้ในตารางรวมกันเป็น 18 ล้านหน้า โปรดทราบว่าข้อมูลอาจแตกต่างกันไปขึ้นอยู่กับช่องของเว็บไซต์นั้นๆ
จะทำอย่างไร?
เห็นได้ชัดว่ากลยุทธ์ที่ดีที่สุดในกรณีนี้คือการหลีกเลี่ยง DFI ที่ยาวกว่า 5 สร้างโครงสร้างเว็บไซต์ที่ง่ายต่อการนำทาง ให้ความสนใจเป็นพิเศษกับลิงก์ ฯลฯ
ความจริงก็คือมาตรการเหล่านี้ใช้เวลานานมากสำหรับเว็บไซต์ที่มีหน้ามากกว่า 100 หน้า โดยปกติแล้วเว็บไซต์ขนาดใหญ่มักมีประวัติการออกแบบใหม่และการย้ายข้อมูลมาอย่างยาวนาน นั่นเป็นเหตุผลที่ผู้ดูแลเว็บไม่ควรลบหน้าที่มี DFI เป็น 10, 12 หรือแม้แต่ 30 นอกจากนี้ การแทรกลิงก์เดียวจากหน้าที่เข้าชมบ่อยจะไม่ช่วยแก้ปัญหา
วิธีที่ดีที่สุดในการรับมือกับ DFI ที่ยาวนานคือการตรวจสอบและประเมินว่า URL เหล่านี้มีความเกี่ยวข้อง ทำกำไรได้ และมีตำแหน่งใดบ้างใน SERP
หน้าที่มี DFI ยาวแต่ตำแหน่งที่ดีใน SERP นั้นมีศักยภาพสูง หากต้องการเพิ่มการเข้าชมหน้าเว็บคุณภาพสูง ผู้ดูแลเว็บควรแทรกลิงก์จากหน้าถัดไป หนึ่งถึงสองลิงก์ไม่เพียงพอสำหรับความคืบหน้าที่จับต้องได้
คุณสามารถดูได้จากกราฟด้านล่างว่า Googlebot เข้าชม URL บ่อยขึ้นหากมีลิงก์มากกว่า 10 ลิงก์ในหน้านั้น
ลิงค์
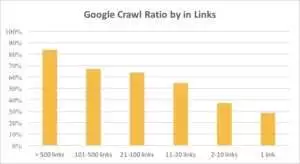
ยิ่งเว็บไซต์มีขนาดใหญ่เท่าใด จำนวนลิงก์บนหน้าเว็บก็ยิ่งมีนัยสำคัญมากขึ้นเท่านั้น ข้อมูลนี้มาจากเว็บไซต์มากกว่า 1 ล้านหน้า
หากคุณพบว่ามีลิงก์น้อยกว่า 10 ลิงก์ในหน้าที่ทำกำไรของคุณ ไม่ต้องตกใจ ขั้นแรก ให้ตรวจสอบว่าหน้าเว็บเหล่านี้มีคุณภาพสูงและให้ผลกำไรหรือไม่ เมื่อคุณทำเช่นนั้น ให้แทรกลิงก์ในหน้าคุณภาพสูงโดยไม่ต้องเร่งรีบและทำซ้ำสั้นๆ เพื่อวิเคราะห์บันทึกหลังจากแต่ละขั้นตอน

ขนาดเนื้อหา
เนื้อหาเป็นหนึ่งในส่วนที่ได้รับความนิยมมากที่สุดในการวิเคราะห์ SEO แน่นอน ยิ่งเนื้อหาที่เกี่ยวข้องอยู่ในเว็บไซต์ของคุณมากเท่าไหร่ อัตราส่วนการรวบรวมข้อมูลของคุณก็จะยิ่งดีขึ้นเท่านั้น ด้านล่างนี้ คุณจะเห็นความสนใจของ Googlebot ที่ลดลงอย่างมากสำหรับหน้าเว็บที่มีคำน้อยกว่า 500 คำ
จะทำอย่างไร?
จากประสบการณ์ของฉัน เกือบครึ่งหนึ่งของหน้าทั้งหมดที่มีคำน้อยกว่า 500 คำเป็นหน้าขยะ เราเห็นกรณีที่เว็บไซต์มี 70,000 หน้าโดยระบุเฉพาะขนาดของเสื้อผ้า ดังนั้นเพียงบางส่วนของหน้าเหล่านี้เท่านั้นที่อยู่ในดัชนี
ดังนั้น ตรวจสอบก่อนว่าคุณต้องการเพจเหล่านั้นจริงๆ หรือไม่ หาก URL เหล่านี้มีความสำคัญ คุณควรเพิ่มเนื้อหาที่เกี่ยวข้องใน URL เหล่านี้ หากคุณไม่มีอะไรจะเพิ่ม ก็แค่ผ่อนคลายและปล่อย URL เหล่านี้ไว้ตามเดิม บางครั้งก็ดีกว่าถ้าไม่ทำอะไรเลยแทนที่จะเผยแพร่เนื้อหาที่ไร้ประโยชน์
ปัจจัยอื่นๆ
ปัจจัยต่อไปนี้อาจส่งผลต่ออัตราส่วนการรวบรวมข้อมูลอย่างมาก:
โหลดเวลา
ความเร็วของหน้าเว็บเป็นสิ่งสำคัญสำหรับการรวบรวมข้อมูลและการจัดอันดับ บอทก็เหมือนมนุษย์: มันเกลียดการรอหน้าเว็บโหลดนานเกินไป หากเว็บไซต์ของคุณมีมากกว่า 1 ล้านหน้า บอทค้นหาอาจดาวน์โหลดหน้าเว็บ 5 หน้าด้วยเวลาโหลด 1 วินาที แทนที่จะรอหน้าเดียวที่โหลดใน 5 วินาที
จะทำอย่างไร?
อันที่จริง นี่เป็นงานทางเทคนิคและไม่มีวิธีแก้ปัญหาแบบ "วิธีเดียวที่เหมาะกับทุกคน" เช่น การใช้เซิร์ฟเวอร์ที่ใหญ่กว่า แนวคิดหลักคือการค้นหาคอขวดของปัญหา คุณควรเข้าใจว่าทำไมหน้าเว็บจึงโหลดช้า หลังจากเปิดเผยเหตุผลแล้ว คุณสามารถดำเนินการได้
อัตราส่วนของเนื้อหาที่ไม่ซ้ำใครและเทมเพลต
ความสมดุลระหว่างข้อมูลเฉพาะและเทมเพลตเป็นสิ่งสำคัญ ตัวอย่างเช่น คุณมีเว็บไซต์ที่มีชื่อสัตว์เลี้ยงหลายแบบ คุณสามารถรวบรวมเนื้อหาที่เกี่ยวข้องและไม่ซ้ำใครเกี่ยวกับหัวข้อนี้ได้มากน้อยเพียงใด
Luna เป็นชื่อสุนัข "คนดัง" ที่ได้รับความนิยมสูงสุด รองลงมาคือ Stella, Jack, Milo และ Leo
บอทค้นหาไม่ต้องการใช้ทรัพยากรของตนกับหน้าประเภทนี้
จะทำอย่างไร?
รักษาความสมดุล ผู้ใช้และบ็อตไม่ชอบการเข้าชมหน้าเว็บที่มีเทมเพลตที่ซับซ้อน ลิงก์ขาออกจำนวนมาก และเนื้อหาเพียงเล็กน้อย
หน้าเด็กกำพร้า
หน้าเด็กกำพร้าคือ URL ที่ไม่ได้อยู่ในโครงสร้างเว็บไซต์ และคุณไม่ทราบเกี่ยวกับหน้าเหล่านี้ แต่หน้าเด็กกำพร้าเหล่านี้อาจถูกรวบรวมข้อมูลโดยบอท เพื่อให้ชัดเจน ดูที่ Euler's Circle ในภาพด้านล่าง:

คุณสามารถดูสถานการณ์ปกติสำหรับเว็บไซต์ใหม่ซึ่งไม่มีการเปลี่ยนแปลงโครงสร้างมาระยะหนึ่งแล้ว มีเพจ 900,000 หน้าที่คุณและโปรแกรมรวบรวมข้อมูลสามารถวิเคราะห์ได้ โปรแกรมรวบรวมข้อมูลประมาณ 500,000 หน้าประมวลผล แต่ Google ไม่รู้จัก หากคุณสร้างดัชนี 500,000 URL เหล่านี้ได้ การเข้าชมของคุณจะเพิ่มขึ้นอย่างแน่นอน
ให้ความสนใจ: แม้แต่เว็บไซต์ใหม่ก็ยังมีบางหน้า (ส่วนสีน้ำเงินในภาพ) ที่ไม่ได้อยู่ในโครงสร้างเว็บไซต์ แต่บอทมักจะเข้าเยี่ยมชมเป็นประจำ
และหน้าเหล่านี้อาจมีเนื้อหาขยะ เช่น ข้อความค้นหาของผู้เยี่ยมชมที่สร้างขึ้นอัตโนมัติโดยไร้ประโยชน์
แต่เว็บไซต์ขนาดใหญ่มักไม่ค่อยแม่นยำนัก บ่อยครั้งที่เว็บไซต์ที่มีประวัติมีลักษณะดังนี้:

นี่คือปัญหาอื่น: Google รู้จักเว็บไซต์ของคุณมากกว่าที่คุณรู้ อาจมีเพจที่ถูกลบ, เพจใน JavaScript หรือ Ajax, การเปลี่ยนเส้นทางที่เสียหาย และอื่นๆ เป็นต้น เมื่อเราเผชิญกับสถานการณ์ที่รายการลิงก์เสีย 500,000 รายการปรากฏในแผนผังเว็บไซต์เนื่องจากความผิดพลาดของโปรแกรมเมอร์ หลังจากผ่านไปสามวัน ข้อบกพร่องก็พบและแก้ไข แต่ Googlebot เข้าไปยังลิงก์เสียเหล่านี้เป็นเวลาครึ่งปีแล้ว!
บ่อยครั้ง งบประมาณการรวบรวมข้อมูลของคุณ มักจะเสียไปกับหน้าเว็บที่ไม่มีเจ้าของเหล่านี้
จะทำอย่างไร?
มีสองวิธีในการแก้ไขปัญหาที่อาจเกิดขึ้น วิธีแรกคือตามรูปแบบบัญญัติ: ทำความสะอาดความยุ่งเหยิง จัดระเบียบโครงสร้างของเว็บไซต์ แทรกลิงก์ภายในให้ถูกต้อง เพิ่มหน้าที่ไม่มีผู้ดูแลใน DFI โดยเพิ่มลิงก์จากหน้าที่จัดทำดัชนี กำหนดงานสำหรับโปรแกรมเมอร์ และรอการเข้าชม Googlebot ครั้งต่อไป
วิธีที่สองคือการแจ้ง: รวบรวมรายชื่อเพจที่ไม่มีผู้ดูแลและตรวจสอบว่าเกี่ยวข้องหรือไม่ หากคำตอบคือ “ใช่” ให้สร้างแผนผังไซต์ด้วย URL เหล่านี้แล้วส่งไปที่ Google วิธีนี้ง่ายกว่าและเร็วกว่า แต่มีเพียงครึ่งหนึ่งของหน้ากำพร้าเท่านั้นที่จะอยู่ในดัชนี
ระดับถัดไป
อัลกอริทึมของเครื่องมือค้นหาได้รับการปรับปรุงให้ดีขึ้นเป็นเวลาสองทศวรรษ และเป็นเรื่องไร้เดียงสาที่จะคิดว่าการรวบรวมข้อมูลการค้นหาสามารถอธิบายได้ด้วยกราฟสองสามกราฟ
เรารวบรวมพารามิเตอร์ที่แตกต่างกันมากกว่า 200 รายการสำหรับแต่ละหน้า และคาดว่าตัวเลขนี้จะเพิ่มขึ้นภายในสิ้นปีนี้ ลองจินตนาการว่าเว็บไซต์ของคุณคือตารางที่มี 1 ล้านบรรทัด (หน้า) และคูณบรรทัดเหล่านี้ด้วย 200 คอลัมน์ ตัวอย่างง่ายๆ ไม่เพียงพอสำหรับการตรวจสอบทางเทคนิคที่ครอบคลุม คุณเห็นด้วยหรือไม่?
เราตัดสินใจลงลึกและใช้การเรียนรู้ของเครื่องเพื่อค้นหาว่าอะไรที่มีอิทธิพลต่อการรวบรวมข้อมูลของ Googlebots ในแต่ละกรณี

ประการหนึ่ง ลิงก์เว็บไซต์มีความสำคัญในขณะที่เนื้อหาเป็นปัจจัยสำคัญสำหรับอีกประการหนึ่ง
ประเด็นหลักของงานนี้คือการได้รับคำตอบง่ายๆ จากข้อมูลที่ซับซ้อนและมีจำนวนมหาศาล: สิ่งใดในเว็บไซต์ของคุณที่ส่งผลกระทบต่อการจัดทำดัชนีมากที่สุด กลุ่ม URL ใดที่เชื่อมโยงกับปัจจัยเดียวกัน เพื่อ ให้คุณสามารถทำงานร่วมกับพวกเขาได้อย่างครอบคลุม
ก่อนที่จะดาวน์โหลดและวิเคราะห์บันทึกบนเว็บไซต์ผู้รวบรวม HotWork เรื่องราวเกี่ยวกับหน้าเด็กกำพร้าที่มองเห็นได้สำหรับบอทแต่ไม่ใช่สำหรับเรานั้นดูไม่สมจริงสำหรับฉัน แต่สถานการณ์จริงทำให้ฉันประหลาดใจมากยิ่งขึ้น: การรวบรวมข้อมูลแสดงหน้า 500 หน้าพร้อมการเปลี่ยนเส้นทาง 301 ครั้ง แต่ยานเดกซ์พบหน้า 700,000 หน้าที่มีรหัสสถานะเดียวกันนี้
โดยปกติแล้ว ผู้เชี่ยวชาญด้านเทคนิคจะไม่ชอบเก็บไฟล์บันทึกเนื่องจากข้อมูลนี้ "โอเวอร์โหลด" ลงดิสก์ แต่ตามความเป็นจริงแล้ว ในเว็บไซต์ส่วนใหญ่ที่มีการเข้าชมมากถึง 10 ล้านครั้งต่อเดือน การตั้งค่าพื้นฐานของการจัดเก็บบันทึกจะทำงานได้อย่างสมบูรณ์แบบ
เมื่อพูดถึงปริมาณบันทึก ทางออกที่ดีที่สุดคือการสร้างไฟล์เก็บถาวรและดาวน์โหลดบน Amazon S3-Glacier (คุณสามารถจัดเก็บข้อมูลได้ 250 GB ในราคาเพียง $1) สำหรับผู้ดูแลระบบ งานนี้ง่ายเหมือนการชงกาแฟ ในอนาคต บันทึกประวัติจะช่วยเปิดเผยจุดบกพร่องทางเทคนิคและประเมินอิทธิพลของการอัปเดตของ Google ในเว็บไซต์ของคุณ