
Apache Spark: Büyük veri gök kubbesinde parlayan yıldız.
Yayınlanan: 2015-09-24- Milyonlarca ürünü doğru müşterilere önermek.
- Arama geçmişini takip etme ve uçuş yolculukları için indirimli fiyatlar sunma.
- Kişinin teknik becerilerini karşılaştırmak ve alanınızda bağlantı kuracak kişileri uygun şekilde önermek.
- Milyarlarca mobil nesnedeki, ağ kulelerindeki ve çağrı işlemlerindeki kalıpları anlama ve telekomünikasyon ağı optimizasyonlarını hesaplama veya ağ boşluklarını bulma.
- Sensörlerin milyonlarca özelliğini incelemek ve sensör ağlarındaki arızaları analiz etmek.
Yukarıdaki tüm görevler için doğru sonuçları elde etmek için kullanılması gereken temel veriler nispeten çok büyüktür. Geleneksel sistemler tarafından verimli bir şekilde (hem mekan hem de zaman açısından) ele alınamaz.
Bunların hepsi büyük veri senaryolarıdır.
Bu tür hacimli verileri toplamak, depolamak ve hesaplamak için özel bir küme hesaplama sistemine ihtiyacımız var. Apache Hadoop bu sorunu bizim için çözdü.
Dağıtılmış bir depolama sistemi (HDFS) ve paralel bilgi işlem platformu (MapReduce) sunar.
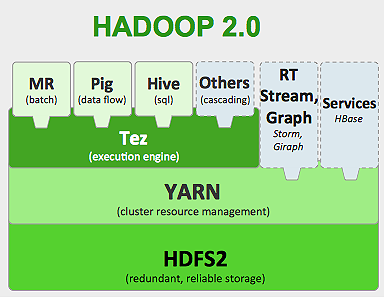
Hadoop çerçevesi aşağıdaki gibi çalışır:
- Büyük veri dosyalarını ayrı makineler tarafından işlenmek üzere daha küçük parçalara böler (Dağıtma Depolama).
- Daha uzun işi, paralel şekilde yürütülmek üzere daha küçük görevlere böler (Paralel Hesaplama).
- Arızaları otomatik olarak ele alır.
Hadoop'un Sınırlamaları
Hadoop , ekosisteminde farklı görevleri yerine getirmek için özel araçlara sahiptir. Bu nedenle, bir uygulamanın yaşam döngüsünü uçtan uca çalıştırmak istiyorsanız, birden fazla araç kullanmanız gerekir. Örneğin, kullanacağınız SQL sorguları için Hive/pig , akış kaynakları için Hadoop dahili akış veya Apache Storm (Hadoop ekosisteminin bir parçası değildir) veya makine öğrenme algoritmaları için Mahout kullanmanız gerekir. Tek bir veri hattı kullanım senaryosu oluşturmak için tüm bu sistemleri bir araya getirmek oldukça zor bir iştir.
MapReduce işinde,
- Tüm harita görevleri çıktısı yerel disklere (veya HDFS'ye) aktarılır.
- Hadoop, tüm dökülme dosyalarını azaltıcı sayısına göre sıralanmış ve bölümlenmiş daha büyük bir dosyada birleştirir.
- Azaltmak ve görevleri tekrar belleğe yüklemek zorunda.
Bu işlem işi yavaşlatarak Disk G/Ç ve ağ G/Ç'sine neden olur. Bu aynı zamanda Mapreduce'u aynı veri grubuna tekrar tekrar makine öğrenimi algoritmaları uygulamanız gereken yinelemeli işleme için uygun hale getirir.
Apache Spark dünyasına girin:
Apache Spark , 2009 yılında UC Berkeley AMPLAB'de geliştirildi ve 2010'da bugüne kadar Apache'nin en çok katkı sağladığı açık kaynak projesi haline geldi.
Apache Spark , aynı anda hem toplu hem de akış işlerini çalıştırabileceğiniz daha genelleştirilmiş bir sistemdir. Verileri bellekte daha hızlı işlemek için yetenekler ekleyerek, hızı önceki MapReduce'un yerini alır. Ayrıca diskte daha verimlidir. Temel veri birimi RDD'yi (Dayanıklı Dağıtılmış Veri Kümesi) kullanarak bellek işlemeden yararlanır. Bunlar, işin tüm yaşam döngüsü için bellekte mümkün olduğu kadar çok veri kümesini tutar, dolayısıyla disk G/Ç'den tasarruf sağlar. Bellek üst limitlerinden sonra bazı veriler diskin üzerine dökülebilir.
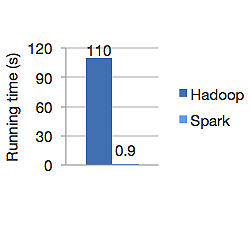
Aşağıdaki grafik, lojistik regresyonu hesaplamak için hem Apache Hadoop hem de Spark'ın çalışma süresini saniye cinsinden gösterir. Spark aynı işi sadece 0.9 saniyede bitirirken Hadoop 110 saniye sürdü.
Spark, tüm verileri bellekte saklamaz. Ancak veriler bellekteyse, daha hızlı işlemek için LRU önbelleğinden en iyi şekilde yararlanır. Bellekteki verileri hesaplarken 100 kat daha hızlıdır ve diskte Hadoop'tan daha hızlıdır.
Spark'ın dağıtılmış veri depolama modeli, esnek dağıtılmış veri kümeleri (RDD), hata toleransını garanti ederek ağ G/Ç'sini en aza indirir. Kıvılcım kağıdı diyor ki:

"RDD'ler bir soy kavramı aracılığıyla hata toleransı elde ederler: Bir RDD'nin bir bölümü kaybolursa, RDD, yalnızca o bölümü yeniden oluşturabilmek için diğer RDD'lerden nasıl türetildiği hakkında yeterli bilgiye sahiptir."
Bu nedenle, hata toleransı elde etmek için verileri çoğaltmanız gerekmez.
Spark MapReduce'da, eşleyicilerin çıktısı OS arabellek önbelleğinde tutulur ve indirgeyiciler, çıktının diske döküldüğü ve yeniden okunduğu Hadoop'un aksine, yanlarına çeker ve doğrudan belleklerine yazar.
Spark'ın bellek önbelleği, aynı verileri tekrar tekrar kullanmanız gereken makine öğrenimi algoritmaları için uygun hale getirir. Spark, Doğrudan Döngüsel Grafik (DAG'ler) kullanarak karmaşık işleri, çok adımlı veri işlem hatlarını çalıştırabilir.
Spark, Scala'da yazılmıştır ve JVM (Java Virtual Machine) üzerinde çalışır. Spark, Java, Scala, Python ve R dilleri için geliştirme API'leri sunar. Spark, Hadoop YARN, Apache Mesos üzerinde çalışır ve kendi bağımsız küme yöneticisine sahiptir.
2014 yılında, Hadoop by Yahoo'nun önceki rekoru yaklaşık 72 dakika iken, 100 TB veri (1 trilyon kayıt) kriterini sadece 23 dakikada sıralamak için dünya rekoru birinciliği elde etti. Bu, sıralanan verileri 3 kat daha hızlı ve 10 kat daha az makineyle kıvılcımladığını kanıtlıyor. Tüm sıralama, gerçekte kıvılcım bellek içi önbellek özelliği kullanılmadan diskte (HDFS) gerçekleşti.
Kıvılcım Ekosistemi
Spark, aşağıdaki bileşenleri sunmasını sağlamak için tek seferde gelişmiş analitik yapmak içindir:
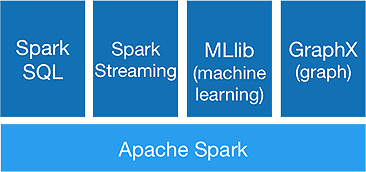
1. Kıvılcım Çekirdeği:
Spark çekirdek API, iş planlama, görev dağıtımı, bellek yönetimi, G/Ç işlemleri ve arızalardan kurtarma işlemlerini gerçekleştiren Apache Spark çerçevesinin temelidir. Spark'taki ana mantıksal veri birimi, verileri daha sonra paralel olarak işlenmek üzere dağıtılmış şekilde depolayan RDD (Resilient Distributed Dataset) olarak adlandırılır. İşlemleri tembelce hesaplar. Bu nedenle, belleğin her zaman meşgul olmasına gerek yoktur ve diğer işler onu kullanabilir.
2.Spark SQL:
Düşük gecikme süresi ile etkileşimli sorgulama yetenekleri sunar . Yeni DataFrame API, hem yapılandırılmış hem de yarı yapılandırılmış verileri tutabilir ve tüm SQL işlemlerinin ve işlevlerinin hesaplamalar yapmasına izin verir.
3.Spark Akışı:
Verileri mikro gruplar halinde toplayan ve işleyen gerçek zamanlı akış API'leri sağlar.
Gelen veriler üzerinde iş mantıklarını hesaplamak ve anında sonuç üretmek için sürekli RDD dizisinden başka bir şey olmayan Dstreams'i kullanır.
4.MLlib :
Spark'ın makine öğrenimi kitaplığının yanı sıra sınıflandırma, regresyon, işbirlikçi filtreleme vb. istatistiksel algoritmalar sağlayan makine öğrenimi kitaplığıdır (Mahout'tan neredeyse 9 kat daha hızlıdır).
5.GraphX :
GraphX API, grafikleri işlemek ve grafik-paralel hesaplamalar gerçekleştirmek için yetenekler sağlar. PageRank gibi grafik algoritmaları ve grafikleri analiz etmek için çeşitli işlevler içerir.
Spark, Hadoop Dönemi'nin sonunu işaretleyecek mi?
Spark hala genç bir sistem, Hadoop kadar olgunlaşmamış. NOSQL için HBase gibi bir araç yoktur. Daha hızlı veri işleme için yüksek bellek gereksinimi göz önüne alındığında, bunun ticari donanım üzerinde çalıştığını gerçekten söyleyemezsiniz. Spark'ın kendi depolama sistemi yoktur. Bunun için HDFS'ye güvenir.
Bu nedenle, Hadoop MapReduce, fazla veri boru hattı içermeyen belirli toplu işler için hala iyidir.
“Yeni teknoloji asla eskisinin yerini tamamen alamaz; ikisi bir arada yaşamayı tercih eder.”
Çözüm
Bu blogda, Spark gibi bir araca neden ihtiyaç duyduğunuzu, onu küme hesaplama sistemini ve temel bileşenlerini daha hızlı yapan şeyin ne olduğunu inceledik. Sonraki bölümde, Spark çekirdek API RDD'leri, dönüşümleri ve eylemleri hakkında daha derine ineceğiz.