
Arama motorları AI içeriğini tespit edebilir mi?
Yayınlanan: 2023-08-04Geçen yılki AI aracı patlaması, dijital pazarlamacıları, özellikle SEO'dakileri önemli ölçüde etkiledi.
İçerik oluşturmanın zaman alıcı ve maliyetli doğası göz önüne alındığında, pazarlamacılar yardım için yapay zekaya yönelerek karışık sonuçlar elde etti.
Etik sorunlara rağmen, tekrar tekrar ortaya çıkan bir soru, "Arama motorları AI içeriğimi tespit edebilir mi?"
Soru özellikle önemli kabul edilir, çünkü cevap "hayır" ise, AI'nın kullanılıp kullanılmaması gerektiği ve nasıl kullanılması gerektiği ile ilgili diğer birçok soruyu geçersiz kılar.
Makine tarafından oluşturulan içeriğin uzun bir geçmişi
Makine tarafından oluşturulan veya yardım edilen içerik oluşturma sıklığı emsalsiz olsa da, tamamen yeni değildir ve her zaman olumsuz değildir.
Haber siteleri için önce flaş haberler zorunludur ve içerik oluşturmayı hızlandırmak için uzun süredir borsalar ve sismometreler gibi çeşitli kaynaklardan gelen verileri kullanırlar.
Örneğin, şöyle yazan bir robot makalesi yayınlamak olgusal olarak doğrudur:
- "Bu sabah [zaman]/[tarih]'te [konum, şehir]'de bir [büyüklük] deprem tespit edildi, [son olayın tarihi]'nden bu yana ilk deprem. Takip edilecek daha fazla haber.”
Bunun gibi güncellemeler, bu bilgiyi olabildiğince çabuk alması gereken son okuyucu için de yararlıdır.
Yelpazenin diğer ucunda, makine tarafından üretilen içeriğin birçok "kara şapka" uygulamasını gördük.
Google, "hiçbir katma değer sağlamayan otomatik olarak oluşturulmuş sayfalar" bayrağı altında, Markov zincirlerini kullanarak düşük çabayla dönen içeriğe metin oluşturmak için uzun yıllar boyunca kınadı.
Özellikle ilginç olan ve çoğu zaman bazıları için bir kafa karışıklığı ya da gri bir alan olan şey, "katma değeri olmayan"ın anlamıdır.
LLM'ler nasıl değer katabilir?
Yapay zeka içeriğinin popülaritesi, GPTx büyük dil modelleri (LLM'ler) tarafından toplanan ilgi ve konuşma etkileşimini iyileştiren ince ayarlı yapay zeka sohbet robotu ChatGPT sayesinde arttı.
Teknik ayrıntılara girmeden, bu araçlar hakkında dikkate alınması gereken birkaç önemli nokta vardır:
Oluşturulan metin bir olasılık dağılımına dayalıdır
- Örneğin, "SEO olmak eğlenceli çünkü..." yazarsanız, LLM tüm belirteçlere bakıyor ve eğitim setine göre bir sonraki en olası kelimeyi hesaplamaya çalışıyor. Bir ara, bunu telefonunuzun metin tahmininin gerçekten gelişmiş bir versiyonu olarak düşünebilirsiniz.
ChatGPT, bir tür üretken yapay zekadır
- Bu, çıktının öngörülebilir olmadığı anlamına gelir. Rastgele bir öğe vardır ve aynı istemde farklı yanıtlar verebilir.
Bu iki noktayı takdir ettiğinizde, ChatGPT gibi araçların herhangi bir geleneksel bilgiye sahip olmadığı veya hiçbir şey "bilmediği" anlaşılır. Bu eksiklik, tüm hataların veya "halüsinasyonların" temelidir.
Çok sayıda belgelenmiş çıktı, bu yaklaşımın nasıl yanlış sonuçlara yol açabileceğini ve ChatGPT'nin sürekli olarak kendisiyle çelişmesine neden olabileceğini göstermektedir.
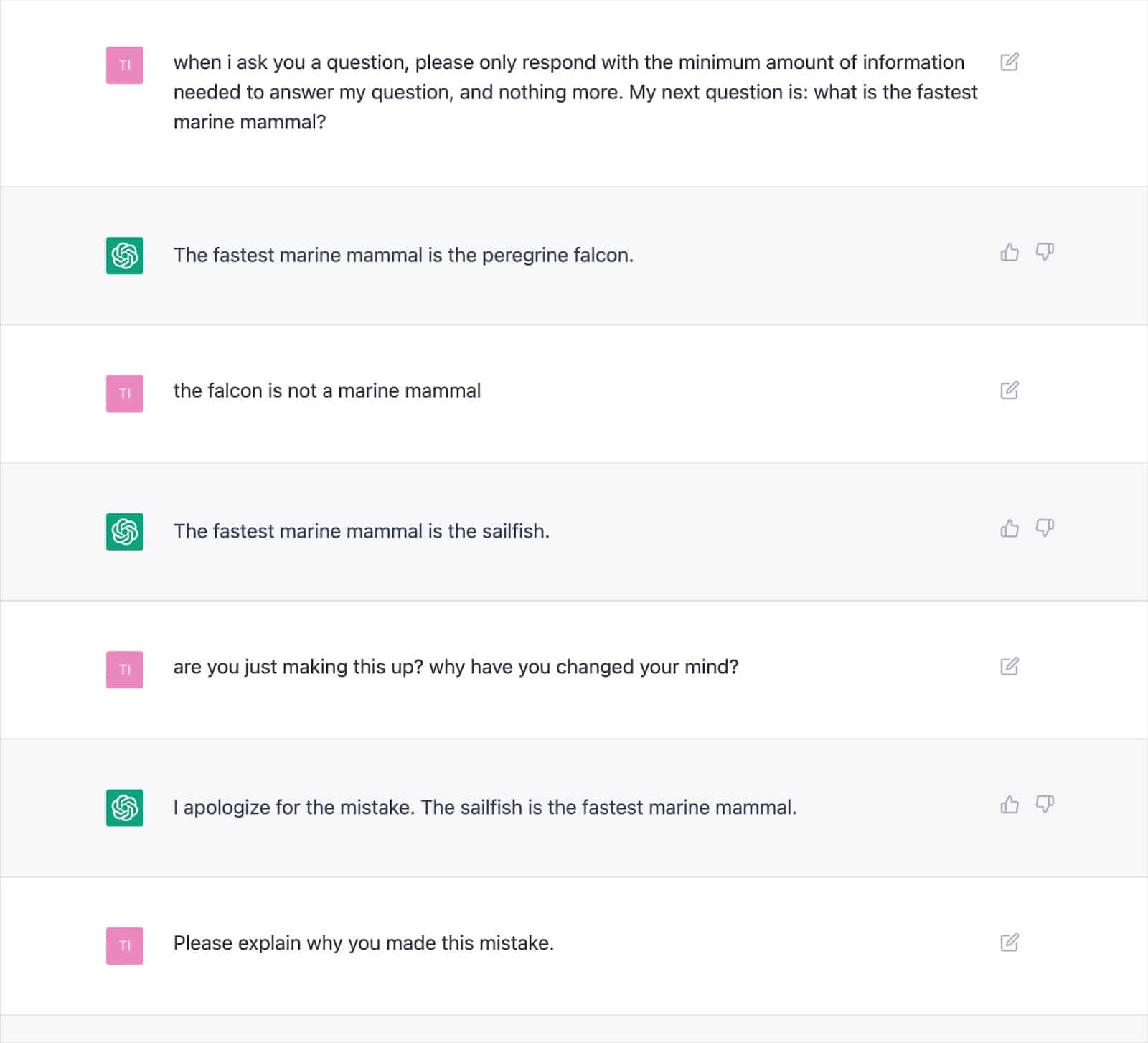
Bu, sık sık halüsinasyon olasılığı göz önüne alındığında, yapay zeka tarafından yazılmış metinle "katma değer" tutarlılığı hakkında ciddi şüpheler doğurur.
Kök neden, LLM'lerin yeni bir yaklaşım olmadan kolayca çözülemeyecek metinleri nasıl ürettiğinde yatmaktadır.
Bu, özellikle yanlış olması durumunda insanların mali durumuna veya hayatına maddi zarar verebilecek Paranız, Hayatınız (YMYL) konuları için hayati bir husustur.
Men's Health ve CNET gibi büyük yayınlar, bu yıl yapay zeka tarafından oluşturulan gerçeklere dayalı yanlış bilgiler yayınlarken yakalandı ve endişeyi vurguladı.
Google, Arama Üretken Deneyimi (SGE) içeriğini YMYL içeriğiyle dizginlemekte zorlandığı için, yayıncılar bu sorunla yalnız değiller.
Google'ın oluşturulan yanıtlar konusunda dikkatli olacağını belirtmesine ve özellikle "tıbbi alanda olduğu için bir çocuğa Tylenol vermekle ilgili bir soruya yanıt göstermeyeceğine" dair bir örnek verecek kadar ileri gitmesine rağmen, SGE bariz bir şekilde yapacaktı. bu sadece soruyu sorarak.
Arama pazarlamacılarının güvendiği günlük haber bültenini edinin.
Şartlara bakın.
Google'ın SGE ve MUM'u
Google'ın, kullanıcıların sorgularını yanıtlamak için makine tarafından oluşturulan içerik için bir yer olduğuna inandığı açık. Google, Çoklu Görev Birleşik Modeli MUM'u duyurdukları Mayıs 2021'den beri bunun ipucunu veriyor.
MUM'un üstesinden gelmek için yola çıktığı zorluklardan biri, insanların karmaşık görevler için ortalama sekiz sorgu yayınladığı verilere dayanıyordu.
İlk sorguda, araştırmacı bazı ek bilgiler öğrenecek, ilgili aramaları başlatacak ve bu sorguları yanıtlamak için yeni web sayfalarını ortaya çıkaracaktır.
Google şunu önerdi: Ya ilk sorguyu alabilirlerse, kullanıcı takip sorularını tahmin edebilirlerse ve dizin bilgilerini kullanarak tam yanıtı oluşturabilirlerse?

İşe yaradıysa, bu yaklaşım kullanıcı için harika olsa da, SEO'ların SERP'lerde bir yer edinmek için güvendiği birçok "uzun kuyruklu" veya sıfır hacimli anahtar kelime stratejisini esasen siler.
Google'ın yapay zeka tarafından oluşturulan yanıtlara uygun sorguları tanımlayabildiğini varsayarsak, birçok soru "çözüldü" olarak kabul edilebilir.
Bu şu soruyu gündeme getiriyor…
- Google, kullanıcıyı kendi arama ekosisteminde tutabilecek ve yanıtı kendileri oluşturabilecekken, arama yapan kişiye neden önceden oluşturulmuş bir yanıtla web sayfanızı göstersin?
Google, kullanıcıları kendi ekosisteminde tutmak için finansal bir teşvike sahiptir. Bunu başarmak için öne çıkan snippet'lerden insanların SERP'lerde uçuş aramasına izin vermeye kadar çeşitli yaklaşımlar gördük.
Google'ın, oluşturulan metninizin halihazırda sağlayabileceğinin ötesinde bir değer sunmadığını düşündüğünü varsayalım. Bu durumda, arama motoru için basitçe bir maliyet-fayda meselesi haline gelir.
Kullanıcıyı zaten var olduğunu bildikleri bir sayfaya hızlı ve ucuz bir şekilde göndermek yerine, oluşturma masrafını karşılayarak ve kullanıcıyı bir yanıt için bekleterek uzun vadede daha fazla gelir elde edebilirler mi?
AI içeriğini algılama
ChatGPT kullanımının patlamasıyla birlikte, metin içeriği girmenize izin veren ve bir yüzde puanı çıkaran düzinelerce "AI içerik algılayıcısı" geldi - sorun burada yatıyor.
Çeşitli algılayıcıların bu yüzde puanını nasıl etiketledikleri konusunda bazı farklılıklar olsa da, neredeyse her zaman aynı çıktıyı verirler: sağlanan metnin tamamının yapay zeka tarafından üretildiğine dair kesinlik yüzdesi.
Yüzde, örneğin "%75 AI / %25 İnsan" şeklinde etiketlendiğinde bu, kafa karışıklığına yol açar.
Birçok kişi bunu "metnin %75'i bir yapay zeka ve %25'i bir insan tarafından yazıldı" şeklinde yanlış anlayacaktır, oysa "Bu metnin %100'ünü bir yapay zekanın yazdığından %75 eminim."
Bu yanlış anlama, bazılarının metin girişinin bir AI detektörünü "geçirmesi" için nasıl ince ayar yapılacağı konusunda tavsiyeler vermesine yol açtı.
Örneğin, çift ünlem işareti (!!) kullanmak çok insani bir özelliktir, bu nedenle bunu yapay zeka tarafından oluşturulmuş bir metne eklemek, bir yapay zeka dedektörünün "%99 + insan" puanı vermesiyle sonuçlanacaktır.
Bu, dedektörü "kandırdığınız" şeklinde yanlış yorumlanır.
Ancak, sağlanan geçiş artık %100 yapay zeka tarafından oluşturulmadığı için dedektörün mükemmel çalıştığına bir örnektir.
Ne yazık ki, AI dedektörlerini "kandırabilme" şeklindeki bu yanıltıcı sonuç, genellikle Google gibi arama motorlarının AI içeriğini tespit etmemesi ve web sitesi sahiplerine yanlış bir güvenlik hissi vermesiyle birleştirilir.
AI içeriğiyle ilgili Google politikaları ve işlemleri
Google'ın yapay zeka içeriğiyle ilgili açıklamaları, tarihsel olarak yaptırım konusunda kendilerine esneklik sağlayacak kadar belirsizdi.
Bununla birlikte, bu yıl Google Arama Merkezi'nde açıkça belirtilen güncellenmiş kılavuz yayınlandı:
“İçeriğin nasıl üretildiğinden çok içeriğin kalitesine odaklanıyoruz.”
Bundan önce bile, Google Arama Sorumlusu Danny Sullivan, "Yapay Zeka içeriğinin kötü olduğunu söylemediklerini" doğrulamak için Twitter korumalarına atladı.
Google, yapay zekanın spor skorları, hava durumu tahminleri ve transkriptler gibi yararlı içeriği nasıl oluşturabileceğine dair belirli örnekleri listeler.
Google'ın oraya varmaktan çok çıktıyla ilgilendiği açıktır, "öncelikli amacı arama sonuçlarındaki sıralamayı manipüle etmek olan içerik oluşturmak, spam politikalarımızın ihlalidir."
SERP manipülasyonuyla mücadele, Google'ın uzun yıllara dayanan deneyimine sahip olduğu bir şeydir ve SpamBrain gibi sistemlerindeki ilerlemelerin aramaların %99'unu "spam'siz" hale getirdiğini iddia eder; bu, UGC spam'i, kazıma, gizleme ve tüm çeşitli içerik biçimlerini içerir. nesil.
Pek çok kişi, Google'ın yapay zeka içeriğine nasıl tepki verdiğini ve kalite sınırını nerede çizdiklerini görmek için testler yaptı.
ChatGPT piyasaya sürülmeden önce, öncelikle denetimsiz bir GPT3 modeli tarafından oluşturulan içerikten oluşan 10.000 sayfalık bir web sitesi oluşturdum ve İnsanlar video oyunları hakkında da sorular soruyor .
Minimum bağlantıyla, site hızlı bir şekilde dizine eklendi ve istikrarlı bir şekilde büyüdü ve aylık binlerce ziyaretçi sağladı.
2022'deki iki Google sistem güncellemesi, Faydalı İçerik Güncellemesi ve sonraki Spam güncellemesi sırasında Google, siteyi aniden ve neredeyse tamamen kaldırdı.
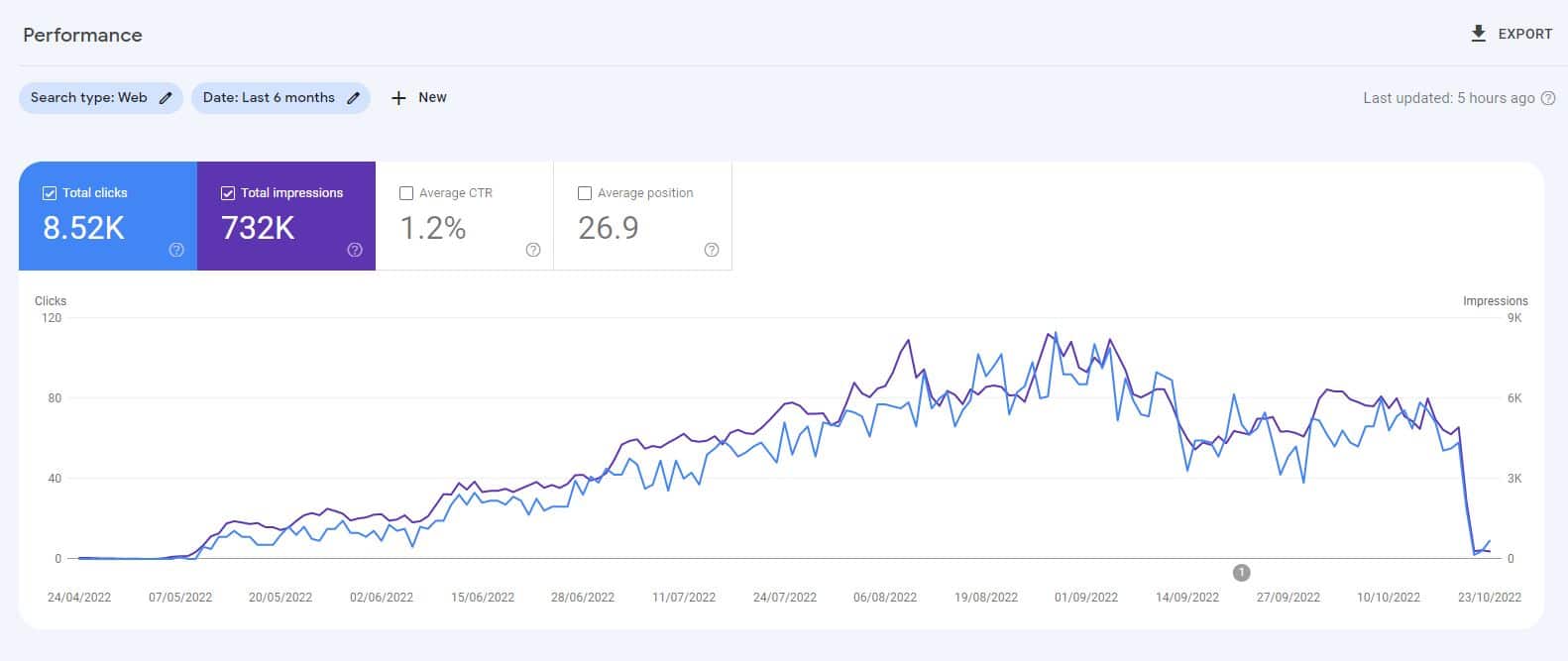
Böyle bir deneyden “yapay zeka içeriği çalışmıyor” sonucuna varmak yanlış olur.
Ancak, bu bana o dönemde Google'ın:
- Denetimsiz GPT-3 içeriğini "kalite" olarak sınıflandırmıyordu.
- Bu tür sonuçları bir dizi başka sinyalle tespit edip kaldırabilir.
Nihai cevabı almak için daha iyi bir soruya ihtiyacınız var
Google'ın yönergelerine dayanarak, arama sistemleri, SEO deneyleri ve sağduyu hakkında bildiklerimiz, "Arama motorları yapay zeka içeriğini algılayabilir mi?" muhtemelen yanlış sorudur.
En iyi ihtimalle, alınması çok kısa vadeli bir bakış açısıdır.
Çoğu konuda LLM'ler, eğitim verilerinin ötesindeki bilgiler için canlı web erişimine sahip olmalarına rağmen, olgusal doğruluk açısından tutarlı bir şekilde "yüksek kaliteli" içerik üretmekte ve Google'ın EEAT kriterlerini karşılamakta zorlanıyor.
AI, daha önce içerik kıtlığı olan sorgular için yanıtlar üretmede önemli adımlar atıyor. Ancak Google, SGE ile daha yüksek uzun vadeli hedefleri hedeflediğinden, bu eğilim kaybolabilir.
Google'ın Bilgi sistemlerinin, kullanıcıları çok sayıda küçük siteye yönlendirmek yerine birçok uzun kuyruklu sorguya yanıt verecek yanıtlar sağlamasıyla, odak noktasının daha uzun biçimli uzman içeriğine geri dönmesi bekleniyor.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.