
Yaygın JavaScript SEO sorunlarını teşhis etme kılavuzu
Yayınlanan: 2023-07-10Dürüst olalım, JavaScript ve SEO birlikte her zaman iyi oynamazlar. Bazı SEO'lar için konu, bir karmaşıklık perdesiyle örtülmüş gibi hissedilebilir.
Pekala, iyi haber: katmanları soyduğunuzda, birçok JavaScript tabanlı SEO sorunu, arama motoru tarayıcılarının ilk etapta JavaScript ile nasıl etkileşime girdiğinin temellerine geri döner.
Dolayısıyla, bu temelleri anlarsanız sorunları derinlemesine inceleyebilir, etkilerini anlayabilir ve önemli olanları düzeltmek için geliştiricilerle birlikte çalışabilirsiniz.
Bu makalede, siteler JS çerçeveleri üzerine oluşturulduğunda bazı genel sorunları teşhis etmeye yardımcı olacağız. Artı, her teknik SEO'nun işleme söz konusu olduğunda ihtiyaç duyduğu temel bilgileri yıkacağız.
Özetle render
Daha ayrıntılı konulara girmeden önce, büyük resmi konuşalım.
Bir arama motorunun JavaScript tarafından desteklenen içeriği anlaması için sayfayı taraması ve oluşturması gerekir.
Sorun şu ki, arama motorlarının kullanacakları çok fazla kaynağı var, bu yüzden onları ne zaman kullanmaya değer olduğu konusunda seçici olmak zorundalar. Tarayıcı onu oluşturma kuyruğuna gönderse bile bir sayfanın oluşturulacağı kesin değildir.
Sayfayı oluşturmamayı seçerse veya içeriği düzgün şekilde oluşturamazsa, bu bir sorun olabilir.
İlk sunucu yanıtında ön ucun HTML'yi nasıl sunduğuna bağlıdır.
Tarayıcıda bir URL oluşturulduğunda, React, Vue veya Gatsby gibi bir ön uç, sayfa için HTML'yi oluşturur. Bir tarayıcı, ortaya çıkan içeriğe bakabilmesi için oluşturmayı beklemek üzere URL'yi göndermeden önce bu HTML'nin sunucuda zaten mevcut olup olmadığını ("önceden oluşturulmuş" HTML) kontrol eder.
Önceden oluşturulmuş herhangi bir HTML'nin kullanılabilir olup olmadığı, kullanıcı arabiriminin nasıl yapılandırıldığına bağlıdır. HTML'yi sunucu aracılığıyla veya istemci tarayıcısında üretecektir.
Sunucu tarafı oluşturma
İsim her şeyi söylüyor. Bir SSR kurulumunda, tarayıcı, fazladan JS yürütme ve oluşturma gerektirmeden tam olarak oluşturulmuş bir HTML sayfası beslenir.
Dolayısıyla, sayfa oluşturulmamış olsa bile, arama motoru yine de herhangi bir HTML'yi tarayabilir, sayfayı bağlamsallaştırabilir (meta veriler, kopya, resimler) ve diğer sayfalarla ilişkisini (kırıntılar, kanonik URL, dahili bağlantılar) anlayabilir.
İstemci tarafı oluşturma
CSR'de HTML, tüm JavaScript bileşenleriyle birlikte tarayıcıda oluşturulur. HTML taranabilir hale gelmeden önce JavaScript'in oluşturulması gerekir.
Oluşturma hizmeti kuyruğa gönderilen bir sayfayı oluşturmamayı seçerse, kopya, dahili URL'ler, resim bağlantıları ve hatta meta veriler tarayıcılar tarafından kullanılamaz durumda kalır.
Sonuç olarak, arama motorlarının bir URL'nin arama sorgularıyla ilgisini anlamak için çok az bağlamı vardır veya hiç yoktur.
Not : İlk HTML yanıtında sunulan bir HTML karışımı olabileceği gibi, oluşturmak (görünmek) için JS'nin yürütülmesini gerektiren HTML de olabilir. En yaygın olanları çerçeve, tek tek site bileşenlerinin nasıl oluşturulduğu ve sunucu yapılandırmasını içeren birkaç faktöre bağlıdır.
JavaScript SEO araç seti
JavaScript ile ilgili SEO sorunlarını tanımlamaya yardımcı olacak kesinlikle araçlar var.
Tarayıcı araçlarını ve Google Search Console'u kullanarak birçok araştırma yapabilirsiniz. İşte sağlam bir araç seti oluşturan kısa liste:
- Kaynağı görüntüle: Sayfanın önceden oluşturulmuş HTML'sini (ilk sunucu yanıtı) görmek için bir sayfaya sağ tıklayın ve "kaynağı görüntüle"ye tıklayın.
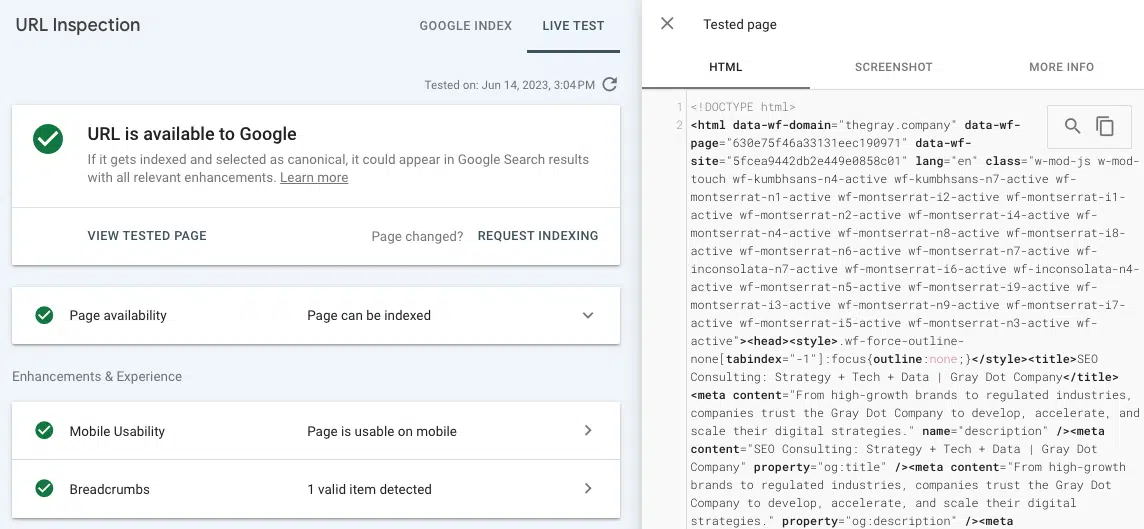
- Canlı URL'yi test edin (URL denetimi): Google Search Console'un URL denetimi sekmesinde, oluşturulmuş bir sayfanın ekran görüntüsünü, HTML'yi ve diğer önemli ayrıntılarını görüntüleyin. ("Kaynağı görüntüle"deki önceden oluşturulmuş HTML ile GSC'de canlı URL testinden alınan işlenmiş HTML karşılaştırılarak birçok oluşturma sorunu bulunabilir.)
- Chrome Geliştirici Araçları: JavaScript hatalarını ve daha fazlasını görüntülemek için araçları açmak üzere bir sayfayı sağ tıklayın ve "İncele"yi seçin.
- Wappalyzer: Herhangi bir sitenin üzerine inşa edildiği yığını görün ve bu ücretsiz Chrome uzantısını yükleyerek çerçeveye özgü içgörüler arayın.
Yaygın JavaScript SEO sorunları
Sorun 1: Önceden oluşturulmuş HTML evrensel olarak kullanılamıyor
Tarama ve bağlama ilişkin daha önce belirtilen olumsuz sonuçlara ek olarak, bir arama motorunun bir sayfayı oluşturması için gereken zaman ve kaynaklar sorunu da vardır.
Tarayıcı, oluşturma işlemine bir URL eklemeyi seçerse, oluşturma kuyruğuna girer. Bunun nedeni, bir tarayıcının önceden oluşturulmuş ve oluşturulmuş HTML yapısı arasında bir eşitsizlik algılayabilmesidir. (Önceden oluşturulmuş HTML yoksa bu çok mantıklı!)
Bir URL'nin web oluşturma hizmeti için ne kadar süre bekleyeceğine dair bir garanti yoktur. WRS'yi zamanında işlemeye yönlendirmenin en iyi yolu, yerinde bir URL'nin önemini gösteren kilit otorite sinyallerinin bulunmasını sağlamaktır (örneğin, üst gezinmede bağlantılı, birçok dahili bağlantı, standart olarak atıfta bulunulur). Bu biraz karmaşık bir hal alıyor çünkü otorite sinyallerinin de taranması gerekiyor.
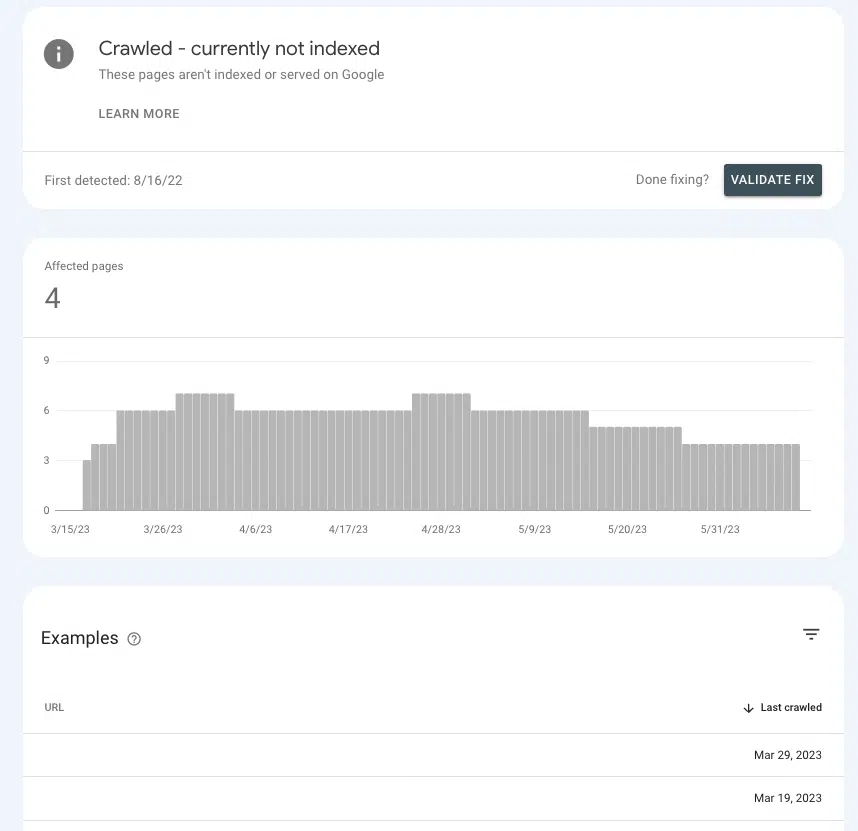
Google Search Console'da, önemli sayfalara doğru yetki sinyallerini gönderip göndermediğinizi veya onları belirsizliğe mi sürüklediğinizi anlamak mümkündür.
Sayfalar > Sayfa indeksleme > Tarandı – şu anda indekslenmemiş seçeneğine gidin ve listede öncelikli sayfaların olup olmadığına bakın.
Bekleme odasındalarsa bunun nedeni, Google'ın kaynakları harcayacak kadar önemli olup olmadıklarını belirleyememesidir.
Yaygın sebepler
Varsayılan ayarları
Çoğu popüler kullanıcı arabirimi, "kutudan çıkar çıkmaz" istemci tarafı işlemeye ayarlı olarak gelir, bu nedenle varsayılan ayarların suçlu olma ihtimali oldukça yüksektir.
Çoğu ön ucun neden varsayılan olarak CSR'ye geçtiğini merak ediyorsanız, bunun nedeni performans avantajlarıdır. Geliştiriciler her zaman SSR'yi sevmez çünkü bu, bir siteyi hızlandırma ve belirli etkileşimli öğeleri (örneğin, sayfalar arasında benzersiz geçişler) uygulama olanaklarını sınırlayabilir.
Tek sayfalık uygulama
Bir site tek sayfalık bir uygulamaysa, tamamen JavaScript'e sarılır ve bir sayfanın tüm bileşenlerini tarayıcıda oluşturur (diğer bir deyişle her şey) istemci tarafında oluşturulur ve yeni sayfalar yeniden yüklenmeden sunulur).
Bunun bazı olumsuz etkileri vardır ve belki de en önemlisi sayfaların potansiyel olarak keşfedilemez olmasıdır.
Bu, bir SPA'yı daha SEO dostu bir şekilde kurmanın imkansız olduğu anlamına gelmez. Ancak, bunun gerçekleşmesi için gereken bazı önemli geliştirme çalışmaları olacak.
Sorun 2: Bazı sayfa içeriğine tarayıcılar erişemez
Bir arama motorunun bir URL oluşturmasını sağlamak, yalnızca tüm öğeler taranmaya uygun olduğu sürece harikadır. Ya sayfayı oluşturuyorsa, ancak sayfanın erişilemeyen bölümleri varsa?
Örneğin, bir SEO dahili bağlantı analizi yapar ve birkaç sayfada bağlantılı bir URL için çok az veya hiç dahili bağlantı raporlanmaz.
Bağlantı, Canlı URL'yi Test Et aracından oluşturulan HTML'de görünmüyorsa, büyük olasılıkla Google'ın erişemediği JavaScript kaynaklarında sunuluyordur.
Suçluyu daraltmak için, URL'lerde eksik sayfa içeriğinin veya dahili bağlantıların sayfada nerede olduğu açısından ortak noktalara bakmak iyi bir fikir olacaktır.
Örneğin, her ürün sayfasının aynı bölümünde görünen bir SSS bağlantısıysa, bu, geliştiricilerin bir düzeltmeyi daraltmasına yardımcı olmak için uzun bir yol kat eder.
Yaygın sebepler
JavaScript Hataları
Burada bir sorumluluk reddi beyanıyla başlayalım. Karşılaştığınız çoğu JavaScript hatası SEO için önemli değildir.
Bu nedenle, hata avına çıkarsanız, geliştiricinize uzun bir liste yapın ve konuşmaya "Bütün bu hatalar nedir?"
JavaScript uzmanı olabilmeleri için soruna konuşarak "neden" ile yaklaşın (çünkü öyleler!).
Bununla birlikte, sayfanın geri kalanını ayrıştırılamaz hale getirebilecek sözdizimi hataları vardır (örneğin, "render engelleme"). Bu meydana geldiğinde, işleyici tek tek HTML öğelerini çözemez, DOM'daki içeriği yapılandıramaz veya ilişkileri anlayamaz.
Genel olarak, bu tür hatalar, tarayıcı görünümünde de bir tür etkiye sahip oldukları için tanınabilir.
Görsel doğrulamaya ek olarak, JavaScript hatalarını sayfaya sağ tıklayıp "incele"yi seçerek ve "Konsol" sekmesine giderek de görmek mümkündür.
Arama pazarlamacılarının güvendiği günlük haber bültenini edinin.
Şartlara bakın.
İçerik bir kullanıcı etkileşimi gerektirir
Oluşturmayla ilgili hatırlanması gereken en önemli şeylerden biri, Google'ın, kullanıcıların sayfayla etkileşime girmesini gerektiren herhangi bir içeriği oluşturamamasıdır. Ya da daha basit bir şekilde ifade etmek gerekirse, şeyleri “tıklayamaz”.

Bu neden önemli? Eski, güvenilir dostumuz akordeon açılır menüsünü ve kaç sitenin ürün ayrıntıları ve SSS gibi içerikleri düzenlemek için onu kullandığını bir düşünün.
Akordeonun nasıl kodlandığına bağlı olarak, JS yürütülene kadar doldurulmazsa Google, açılır listedeki içeriği işleyemeyebilir.
Kontrol etmek için, bir sayfayı "İnceleyebilir" ve "gizli" içeriğin (bir akordiyona tıkladığınızda görünen şey) HTML'de olup olmadığına bakabilirsiniz.
Değilse, bu, Googlebot ve diğer tarayıcıların bu içeriği sayfanın oluşturulmuş sürümünde görmediği anlamına gelir.
3. Sorun: Bir sitenin bölümleri taranmıyor
Google, tarar ve kuyruğa gönderirse sayfanızı oluşturabilir veya oluşturmayabilir. Sayfayı taramazsa, bu fırsat bile masadan kalkar.
Google'ın sayfaları tarayıp taramadığını anlamak için Ayarlar > Tarama istatistikleri bölümünde Tarama İstatistikleri raporu kullanışlı olabilir.
Son üç aydaki 200 durum sayfasının tüm tarama örneklerini görmek için Tarama istekleri: Tamam (200) öğesini seçin. Ardından, tek tek URL'leri veya tüm dizinleri aramak için filtrelemeyi kullanın.
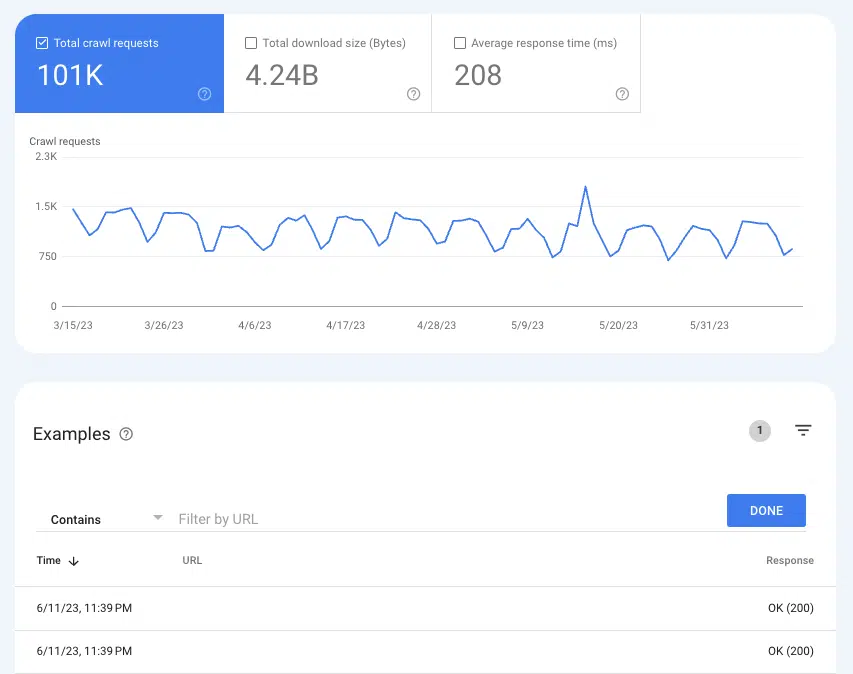
URL'ler tarama günlüklerinde görünmüyorsa, büyük olasılıkla Google sayfaları keşfedemez ve tarayamaz (veya 200 sayfa değildir, bu tamamen farklı bir sorundur).
Yaygın sebepler
Dahili bağlantılar taranamaz
Bağlantılar, tarayıcıların yeni sayfalara gitmek için takip ettikleri yol işaretleridir. Yetim sayfaların bu kadar büyük bir sorun olmasının bir nedeni de budur.
İyi bağlantılara sahip bir siteniz varsa ve site denetimlerinizde yetim sayfaların açıldığını görüyorsanız, bunun nedeni büyük olasılıkla bağlantıların önceden oluşturulmuş HTML'de bulunmamasıdır.
Kontrol etmenin kolay bir yolu, bildirilen sahipsiz sayfaya bağlantı veren bir URL'ye gitmektir. Sayfaya sağ tıklayın ve “kaynağı görüntüle” seçeneğine tıklayın.
Ardından, yetim sayfanın URL'sini aramak için CMD + f tuşlarını kullanın. Önceden oluşturulmuş HTML'de görünmüyorsa ancak tarayıcıda oluşturulduğunda sayfada görünüyorsa, dördüncü sayıya atlayın.
XML site haritası güncellenmedi
XML site haritası, Google'ın yeni sayfaları keşfetmesine ve bir taramada hangi URL'lere öncelik verileceğini anlamasına yardımcı olmak için çok önemlidir.
XML site haritası olmadan, sayfa keşfi yalnızca aşağıdaki bağlantılarla mümkündür.
Bu nedenle, önceden oluşturulmuş HTML'si olmayan siteler için eski veya eksik bir site haritası, Google'ın sayfaları oluşturmasını, diğer sayfalara verilen dahili bağlantıları izlemesini, sıraya koymasını, oluşturmasını, bağlantılarını izlemesini vb. beklemek anlamına gelir.
Kullanmakta olduğunuz kullanıcı arabirimine bağlı olarak, dinamik XML site haritaları oluşturabilen eklentilere erişiminiz olabilir.
Genellikle özelleştirmeye ihtiyaç duyarlar, bu nedenle SEO'ların site haritasında olmaması gereken URL'leri ve bunun neden olduğuna dair mantığı özenle belgelemesi önemlidir.
Bu, site haritasını favori SEO aracınız aracılığıyla çalıştırarak doğrulamak nispeten kolay olmalıdır.
Sorun 4: Dahili bağlantılar eksik
Tarayıcılara dahili bağlantıların bulunmaması, yalnızca potansiyel bir keşif sorunu değil, aynı zamanda bir eşitlik sorunudur. Bağlantılar SEO denkliğini referans URL'den hedef URL'ye aktardığından, hem sayfa hem de etki alanı otoritesini büyütmede önemli bir faktördür.
Ana sayfadaki bağlantılar harika bir örnektir. Genellikle bir web sitesindeki en yetkili sayfadır, bu nedenle ana sayfadan başka bir sayfaya verilen bağlantı çok önemlidir.
Bu bağlantılar taranabilir değilse, bu biraz kırık bir ışın kılıcına sahip olmak gibidir. En güçlü araçlarınızdan biri işe yaramaz hale getirildi (kelime oyunu amaçlı).
Yaygın sebepler
Bağlantıya ulaşmak için kullanıcı etkileşimi gerekiyor
Daha önce kullandığımız akordeon örneği, içeriğin bir kullanıcı etkileşiminin arkasına gizlendiği örneklerden yalnızca biridir. Yaygın etkileri olabilecek bir başkası, özellikle önemli ürün kataloglarına sahip e-Ticaret siteleri için sonsuz kaydırmalı sayfalandırmadır.
Sonsuz kaydırma kurulumunda, bir ürün listeleme (kategori) sayfasındaki sayısız ürün, kullanıcı sayfayı belirli bir noktanın ötesine kaydırmadıkça (geç yükleme) veya "daha fazlasını göster" düğmesine dokunmadıkça yüklenmeyecektir.
Bu nedenle, JavaScript oluşturulsa bile, bir tarayıcı henüz yüklenmemiş ürünler için dahili bağlantılara erişemez. Ancak tüm bu ürünlerin tek bir sayfaya yüklenmesi, sayfa performansının düşük olması nedeniyle kullanıcı deneyimini olumsuz yönde etkileyecektir.
Bu nedenle SEO'lar genellikle, her sonuç sayfasının farklı, taranabilir bir URL'ye sahip olduğu gerçek sayfalandırmayı tercih eder.
Bir sitenin geç yüklemeyi optimize etmenin ve tüm ürünleri önceden oluşturulmuş HTML'ye eklemenin yolları olsa da, bu, oluşturulan HTML ile önceden oluşturulmuş HTML arasında farklılıklara yol açar.
Etkili bir şekilde bu, oluşturma kuyruğuna daha fazla sayfa göndermek ve tarayıcıların ihtiyaç duyduklarından daha fazla çalışmasını sağlamak için bir neden oluşturur ve bunun SEO için harika olmadığını biliyoruz.
En azından, sonsuz kaydırmayı optimize etmek için Google'ın önerilerini uygulayın.
Bağlantılar düzgün kodlanmamış
Google bir siteyi taradığında veya kuyrukta bir URL oluşturduğunda, bir sayfanın durum bilgisiz sürümünü indirir. Uygun href etiketleri ve çapaları (en sık gördüğünüz bağlantı yapısı) kullanmanın neden bu kadar önemli olduğunun büyük bir kısmı budur. Bir tarayıcı, yönlendirici, yayılma veya onClick gibi bağlantı biçimlerini takip edemez.
Takip edebilir:
- <a href="https://example.com">
- <a href="/relative/path/file">
Takip edilemiyor:
- <a routerLink="bazı/yol">
- <span href="https://example.com">
- <a>
Bir geliştiricinin amaçları doğrultusunda, bunların tümü bağlantıları kodlamanın geçerli yollarıdır. SEO etkileri, ek bir bağlam katmanıdır ve bilmek onların işi değil – SEO'nun işi.
İyi bir SEO'nun işinin büyük bir kısmı, geliştiricilere belgeler aracılığıyla bu bağlamı sağlamaktır.
Sorun 5: Meta veriler eksik
Bir HTML sayfasında, başlık, açıklama, standart URL ve meta robots etiketi gibi meta verilerin tümü kafanın içine yerleştirilmiştir.
Bariz nedenlerden dolayı, eksik meta veriler SEO için zararlıdır, ancak SPA'lar için daha da zararlıdır. Kendi kendine referans veren standart bir URL gibi öğeler, bir JS sayfasının oluşturma kuyruğundan başarılı bir şekilde geçme şansını artırmak için çok önemlidir.
Önceden oluşturulmuş HTML'de bulunması gereken tüm öğeler arasında, indeksleme için en önemli olan başlıktır.
Şans eseri, bu sorunun yakalanması oldukça kolaydır, çünkü bir sitenin hijyen raporlaması için kullandığı herhangi bir SEO aracında eksik meta veriler için çok sayıda hatayı tetikleyecektir. Ardından, kaynak kodunda kafayı arayarak onaylayabilirsiniz.
Yaygın sebepler
Eksik veya yanlış yapılandırılmış meta veri aracı
Bir JS çerçevesinde, bir eklenti kafayı oluşturur ve meta verileri kafaya ekler. (En popüler örnek React Helmet'tir.) Bir eklenti zaten kurulu olsa bile, genellikle doğru şekilde yapılandırılması gerekir.
Yine, bu, tüm SEO'ların yapabileceği bir alandır, sorunu geliştiriciye getirmek, nedenini açıklamak ve iyi belgelenmiş kabul kriterlerine doğru yakın bir şekilde çalışmaktır.
Sorun 6: Kaynaklar taranmıyor
Komut dosyası dosyaları ve görüntüler, işleme sürecinde temel yapı taşlarıdır.
Kendi URL'leri de olduğundan, taranabilirlik yasaları onlar için de geçerlidir. Dosyaların taranması engellenirse, Google sayfayı oluşturmak için ayrıştıramaz.
URL'lerin taranıp taranmadığını görmek için GSC Tarama İstatistikleri'nde geçmiş istekleri görüntüleyebilirsiniz.
- Resimler: Ayarlar > Tarama İstatistikleri > Tarama İstekleri'ne gidin: Resim
- JavaScript: Ayarlar > Tarama İstatistikleri > Tarama İstekleri: Resim'e gidin
Yaygın sebepler
robots.txt tarafından engellenen dizin
Hem komut dosyası hem de resim URL'leri genellikle kendi ayrılmış alt alan adlarına veya alt klasörlerine yerleşir, bu nedenle robots.txt dosyasındaki bir izin vermeme ifadesi taramayı engeller.
Bazı SEO araçları, herhangi bir komut dosyası veya resim dosyasının engellenip engellenmediğini size söyleyecektir, ancak resimlerinizin ve komut dosyası dosyalarınızın nerede olduğunu biliyorsanız, sorunu tespit etmek oldukça kolaydır. Bu URL yapılarını robots.txt dosyasında arayabilirsiniz.
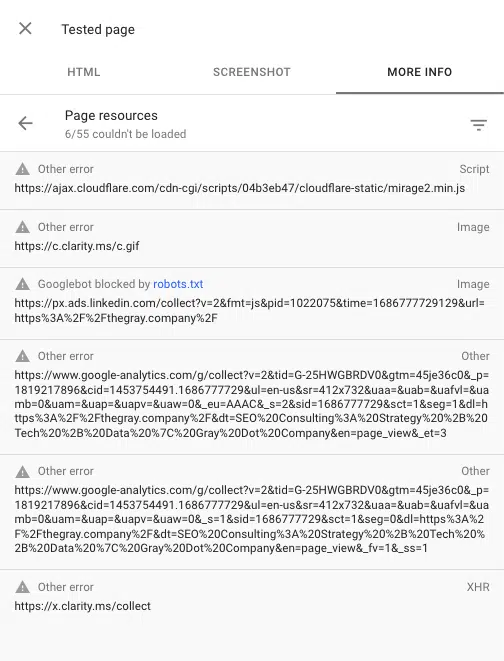
Google Search Console'daki URL inceleme aracını kullanarak bir sayfa oluşturulurken engellenen komut dosyalarını da görebilirsiniz. "Canlı URL'yi test edin" ve ardından Test edilen sayfayı görüntüle > Daha fazla bilgi > Sayfa kaynakları seçeneğine gidin.
Burada, oluşturma işlemi sırasında yüklenemeyen tüm komut dosyalarını görebilirsiniz. Bir dosya robots.txt tarafından engellenirse, bu şekilde işaretlenir.
JavaScript ile arkadaş olun
Evet, JavaScript bazı SEO sorunlarıyla birlikte gelebilir. Ancak SEO geliştikçe, en iyi uygulamalar harika bir kullanıcı deneyimi ile eşanlamlı hale geliyor.
Harika bir kullanıcı deneyimi genellikle JavaScript'e bağlıdır. Bu nedenle, bir SEO'nun işi JavaScript'i kodlamak olmasa da, arama motorlarının onunla nasıl etkileşime girdiğini, oluşturduğunu ve kullandığını bilmemiz gerekir.
Oluşturma sürecini ve JS çerçevelerindeki bazı yaygın SEO sorunlarını sağlam bir şekilde anlayarak, sorunları belirleme ve geliştiricileriniz için güçlü bir müttefik olma yolunda ilerliyorsunuz.
Bu makalede ifade edilen görüşler, konuk yazara aittir ve Search Engine Land olmak zorunda değildir. Personel yazarları burada listelenir.