
Apache Spark, havayolu analitiğine nasıl kanat verebilir?
Yayınlanan: 2015-10-30Küresel havayolu endüstrisi hızla büyümeye devam ediyor, ancak tutarlı ve sağlam karlılık henüz görülmedi. Uluslararası Hava Taşımacılığı Birliği'ne (IATA) göre, endüstri, son on yılda gelirini 2005'te 369 milyar ABD dolarından 2015'te beklenen 727 milyar ABD dolarına çıkararak ikiye katladı.

Ticari havacılık sektöründe, havalimanları, uçak üreticileri, jet motoru üreticileri, seyahat acenteleri ve hizmet şirketleri gibi değer zincirindeki her oyuncu düzenli bir kâr sağlıyor.
Tüm bu oyuncular, daha yüksek uçuş işlemleri nedeniyle bireysel olarak son derece yüksek hacimlerde veri üretir. Talebi belirlemek ve yakalamak, havayollarına kendilerini farklılaştırmaları için çok daha fazla fırsat sağlayan anahtardır. Bu nedenle, Havacılık endüstrileri, satışlarını artırmak ve kar marjını artırmak için büyük veri içgörülerinden yararlanabilir.
Büyük veri, hesaplaması geleneksel veri işleme sistemleri veya eldeki DBMS araçları tarafından işlenemeyecek kadar büyük ve karmaşık veri kümelerinin toplanması için kullanılan bir terimdir.
Apache Spark, etkileşimli sorgular ve yinelemeli algoritmalar için özel olarak tasarlanmış açık kaynaklı, dağıtılmış bir küme bilgi işlem çerçevesidir.
Spark DataFrame soyutlaması, R'nin yerel veri çerçevesine veya Pythons pandas paketine benzer, ancak küme ortamında depolanan tablo şeklinde bir veri nesnesidir.
Fortunes'ın son anketine göre Apache Spark, 2015'in en popüler teknolojisi.
En büyük Hadoop satıcısı Cloudera ayrıca Hadoops MapReduce'a Hoşçakal ve Spark'a Merhaba diyor.
Spark'a Hadoop'a göre üstünlük sağlayan şey hızdır . Spark, işlemlerinin çoğunu bellekte gerçekleştirir ve bunları dağıtılmış fiziksel depolamadan çok daha hızlı mantıksal RAM belleğine kopyalar. Bu, Hadoops MapReduce sistemi altında yapılması gereken yavaş, hantal mekanik sabit disklere yazma ve okuma için harcanan süreyi azaltır.
Ayrıca Spark, nesnelerin İnterneti olarak da bilinen bağlı cihazlardan gelen geçmiş verileri birleştirerek gerçek zamanlı verileri analiz etmek gibi iş hedeflerini güçlendirmek için iyi hazırlanmış araçlar (gerçek zamanlı işleme, makine öğrenimi ve etkileşimli SQL) içerir.
Bugün, Apache Spark kullanarak örnek havaalanı verileri hakkında bazı bilgiler toplayalım.
Önceki blogda, yeni Dataframes API kullanarak Spark'ta yapılandırılmış ve yarı yapılandırılmış verilerin nasıl işleneceğini gördük ve ayrıca JSON verilerinin verimli bir şekilde nasıl işleneceğini ele aldık.
Bu blogda , SQL kullanarak DataFrame'lerdeki verilerin nasıl sorgulanacağını ve çıktıların CSV formatında dosya sistemine nasıl kaydedileceğini anlayacağız.
Databricks CSV ayrıştırma kitaplığını kullanma
Bunun için Creators of Apache Spark tarafından kurulan ve şu anda Spark Geliştirme ve dağıtımlarını yöneten Databricks tarafından sağlanan bir CSV ayrıştırma kitaplığını kullanacağım.
Spark topluluğu , yaklaşık 600 katılımcıdan oluşur ve bu da onu, katkıda bulunanların sayısı açısından açık kaynaklı yazılımlar için önemli bir yönetim organı olan Apache Software Foundation'ın tamamındaki en aktif proje haline getirir.
Spark-csv kitaplığı, kıvılcımdaki csv verilerini ayrıştırmamıza ve sorgulamamıza yardımcı olur. Bu kitaplığı, herhangi bir Hadoop uyumlu dosya sisteminden csv verilerini okumak ve yazmak için kullanabiliriz.
Verileri Spark DataFrames'e yükleme
Databricks'teki spark-csv ayrıştırma kitaplığını kullanarak girdi dosyalarımızı bir Spark DataFrames'e yükleyelim.
Bu kitaplığı Spark kabuğunda –packages com.databricks belirterek kullanabilirsiniz: spark-csv_2.10:1.0.3
Shell'i aşağıda gösterildiği gibi başlatırken:
$ bin/spark-shell –paketleri com.databricks:spark-csv_2.10:1.0.3
İnternete bağlı olmanız gerektiğini unutmayın çünkü bu komutu verdiğinizde spark-csv paketi otomatik olarak indirilecektir. Spark 1.4.0 sürümünü kullanıyorum
Önceden oluşturulmuş SparkContext(sc) nesnesiyle sqlContext oluşturalım
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Şimdi, şeması aşağıdaki gibi olan havaalanları.csv (airport csv github) dosyasından csv verilerimizi yükleyelim.
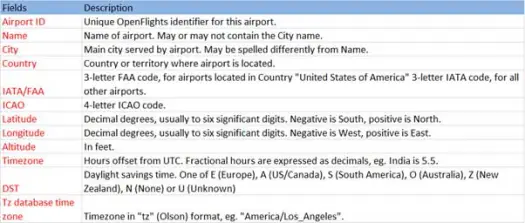
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Yükleme işlemi, Databricks spark-csv kitaplığını kullanarak *.csv dosyasını ayrıştıracak ve dosyadaki ilk başlık satırındakiyle aynı sütun adlarına sahip bir veri çerçevesi döndürecektir.
Aşağıdakiler, yükleme yöntemine iletilen parametrelerdir.
- Kaynak : "com.databricks.spark.csv" , spark'a csv dosyası olarak yüklemek istediğimizi söyler.
- Seçenekler:
- path - bulunduğu dosyanın yolu.
- Header : "header" -> "true" , spark'a, sonuçta elde edilen veri çerçevesi için dosyanın ilk satırını sütun adlarıyla eşleştirmesini söyler.
Dataframe'imizin şemasının ne olduğunu görelim
Veri çerçevemizdeki örnek verilere göz atın
scala> airportDF.show

Geçici tablolar kullanarak CSV verilerini sorgulama:

Bir tabloya karşı sorgu yürütmek için SQLContext'te sql() yöntemini çağırırız.
Havaalanları DataFrame oluşturduk ve CSV verilerini yükledik, bu DF verilerini sorgulamak için havaalanları adı verilen geçici tablo olarak kaydetmemiz gerekiyor.
>
scala> airportDF.registerTempTable("airports")
Veri setimizde Güneydoğu bölgesinde kaç tane havalimanı olduğunu bulalım.
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Spark üzerinde sql sorgularında toplamalar yapabiliriz
Her ülkede kaç tane benzersiz şehrin havaalanı olduğunu öğreneceğiz.
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Her Ülkedeki havalimanlarının ortalama Rakımı (feet cinsinden) nedir?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Şimdi her bir saat diliminde kaç havalimanının çalıştığını öğrenmek için?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Ayrıca her ülkedeki bu havalimanları için ortalama enlem ve boylam hesaplayabiliriz.
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Kaç farklı DST olduğunu sayalım
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Verileri CSV formatında kaydetme
Şimdiye kadar csv verilerini yükledik ve sorguladık. Şimdi sonuçların CSV formatında dosya sistemine nasıl kaydedileceğini göreceğiz.
Müşteriye tüm ülkelerin kuzeybatı kesimindeki tüm havaalanları hakkında rapor göndermek istediğimizi varsayalım.
Önce bunu hesaplayalım.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Ve CSV dosyasına kaydedin
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Aşağıdakiler, kaydetme yöntemine geçirilen parametrelerdir.
- Kaynak : Spark'a verileri csv olarak kaydetmesini söyleyen com.databricks.spark.csv yükleme yöntemiyle aynıdır.
- SaveMode : Bu, kullanıcının, verilen çıktı yolu zaten mevcutsa ne yapılması gerektiğini önceden belirlemesine olanak tanır. Böylece mevcut veriler yanlışlıkla kaybolmaz/üzerine yazılmaz. Hata atabilir, ekleyebilir veya üzerine yazabilirsiniz. Burada, mevcut herhangi bir dosyanın üzerine yazmak istemediğimiz için ErrorIfExists hatası verdik.
- Seçenekler : Bu seçenekler yükleme yöntemine geçtiklerimizle aynıdır. Seçenekler:
- path – dosyanın saklanması gereken yolu.
- Header : "header" -> "true" , spark'a veri çerçevesinin sütun adlarını sonuçtaki çıktı dosyasının ilk satırına eşlemesini söyler.
Diğer veri formatlarını CSV'ye dönüştürme
Bu kütüphaneyi kullanarak JSON, parke, metin gibi diğer veri formatlarını da CSV'ye dönüştürebiliriz.
Önceki blogda json verilerini oluşturmuştuk. github'da bulabilirsin
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
sadece CSV olarak kaydedelim.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Çözüm:
Bu gönderide, SparkSQL etkileşimli sorgularını kullanarak havaalanları verileri hakkında bazı bilgiler topladık
ve Spark'tan csv ayrıştırma kitaplığını keşfetti
Sonraki blog, Spark yani Spark Streaming'in çok önemli bir bileşenini keşfedeceğiz.
Spark Akışı, kullanıcıların Spark'ta gerçek zamanlı verileri toplamasına ve olduğu gibi işlemesine olanak tanır ve sonuçları anında verir.