
Google, EEAT aracılığıyla yazarları nasıl belirleyip değerlendirebilir?
Yayınlanan: 2023-04-17Google, arama sonuçlarını sıralarken içerik kaynağına, özellikle de yazara daha fazla önem veriyor. SERP'lerde Perspektifler, Bu sonuç hakkında ve Bu yazar hakkında bölümlerinin girişi bunu netleştirir.
Bu makale, Google'ın içerik parçalarını yazarlarının deneyimi, uzmanlığı, yetkinliği ve güvenilirliği (EEAT) aracılığıyla potansiyel olarak nasıl değerlendirebileceğini incelemektedir.
EEAT: Google'ın kalite saldırısı
Google, arama sonuçlarının kalitesini ve SERP kullanıcı deneyimini iyileştirmek için EEAT konseptinin önemini vurguladı.
İçeriğin genel kalitesi, bağlantı sinyalleri (yani, PageRank ve bağlantı metinleri) ve varlık düzeyindeki sinyaller gibi sayfa içi faktörlerin tümü hayati bir rol oynar.
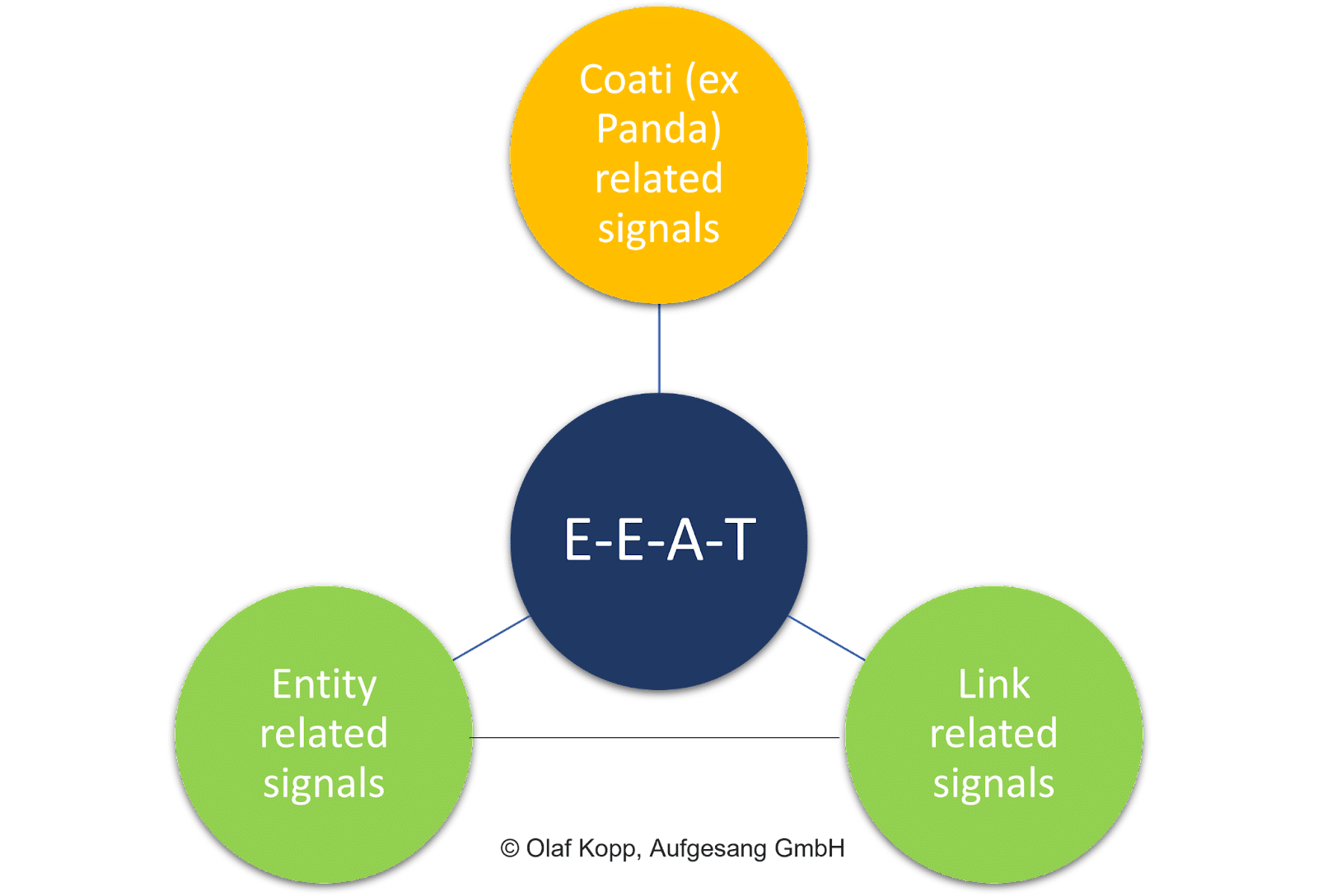
Belge puanlamanın aksine, bireysel içeriğin değerlendirilmesi EEAT'nin odak noktası değildir.
Konsept, etki alanı ve oluşturucu varlıkla ilgili tematik bir referansa sahiptir. Arama amacından ve bireysel içeriğin kendisinden bağımsızdır.
Sonuç olarak, EEAT, arama sorgularından bağımsız olarak etkileyen bir faktördür.
EEAT esas olarak tematik alanlara atıfta bulunur ve şirketler, kuruluşlar, kişiler ve bunların etki alanları gibi varlıklarla ilgili olarak içerik koleksiyonlarını ve sayfa dışı sinyalleri değerlendiren bir değerlendirme katmanı olarak anlaşılır.
İçeriğin kaynağı olarak yazarın önemi
(E-)EAT'den çok önce Google, içerik kaynaklarının derecelendirmesini arama sıralamalarına dahil etmeye çalıştı. Örneğin, 2009'daki Vince güncellemesi, marka tarafından oluşturulan içeriğe bir sıralama avantajı sağladı.
Knol veya Google+ gibi çoktan sona ermiş olan projeler aracılığıyla Google, yazar derecelendirmeleri için sinyaller toplamaya çalıştı (ör. bir sosyal grafik ve kullanıcı derecelendirmeleri yoluyla).
Son 20 yılda, birçok Google patenti doğrudan veya dolaylı olarak Knol gibi içerik platformlarına ve Google+ gibi sosyal ağlara atıfta bulunmuştur.
Bir içerik parçasının kaynağını veya yazarını EEAT kriterlerine göre değerlendirmek, arama sonuçlarının kalitesini daha da geliştirmek için çok önemli bir adımdır.
Yapay zeka tarafından üretilen içeriğin bolluğu ve klasik spam ile, Google'ın arama dizinine kalitesiz içerik eklemesi mantıklı değil.
Bilgi alma sırasında indekslediği ve işlemesi gereken içerik ne kadar fazlaysa, o kadar fazla bilgi işlem gücü gerekir.
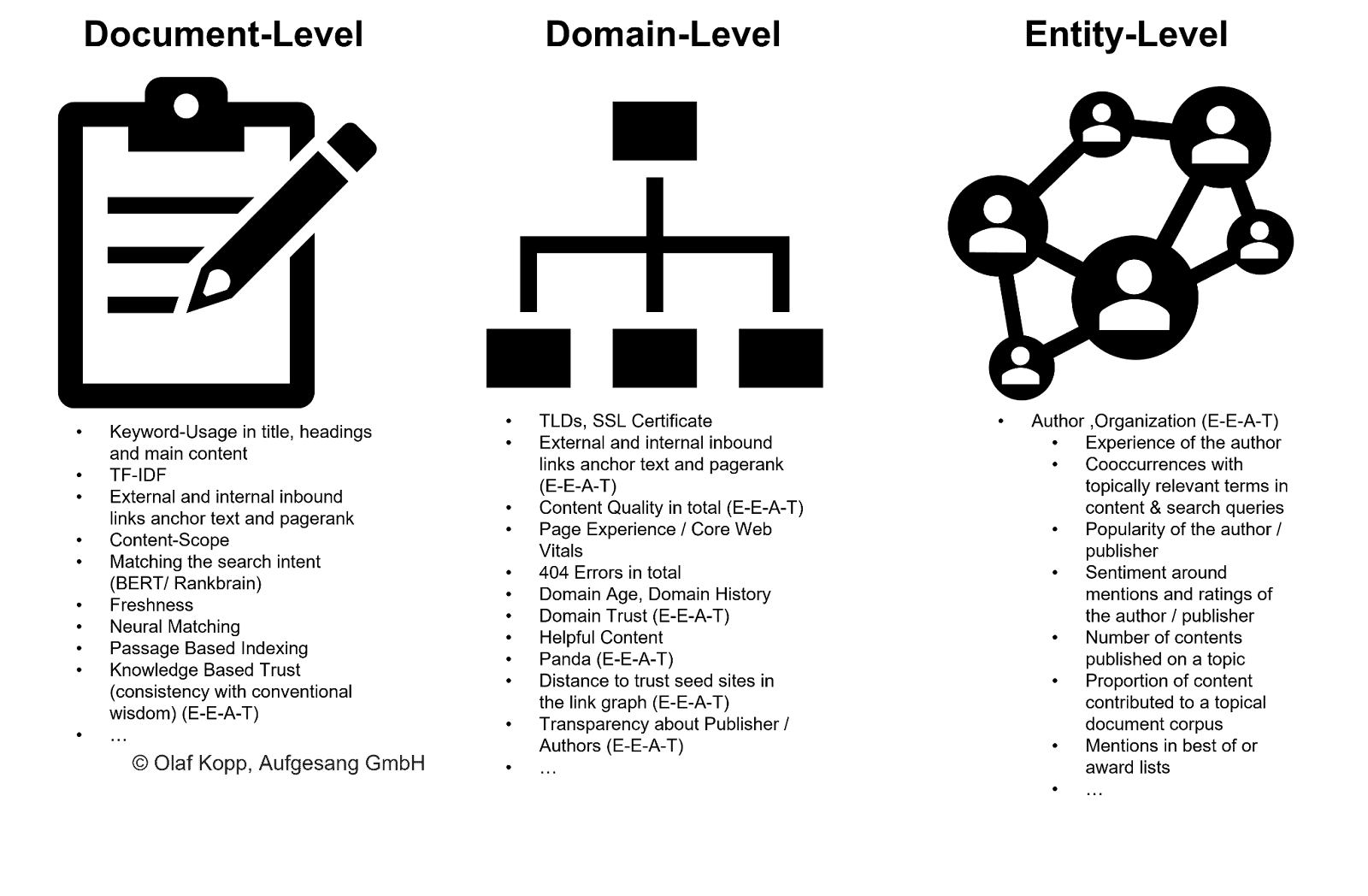
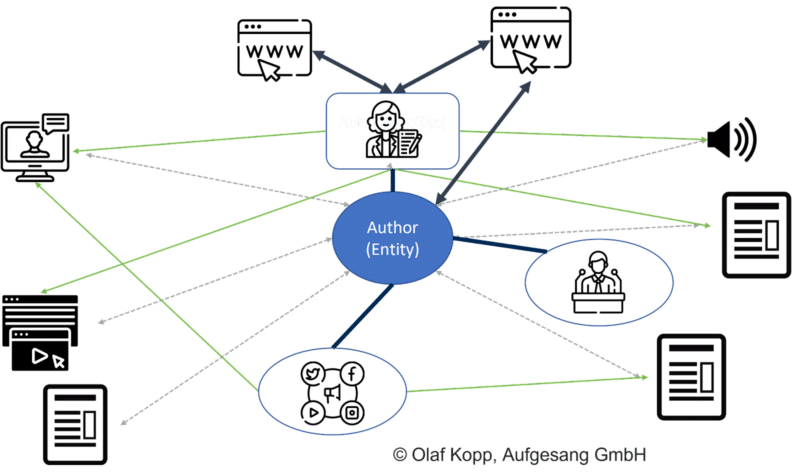
EEAT, Google'ın her içeriği taramak zorunda kalmadan daha geniş bir ölçekte uygulanan varlık, etki alanı ve yazar düzeyine göre sıralamasına yardımcı olabilir.
Bu makro düzeyinde içerik, yaratıcı varlığa göre sınıflandırılabilir ve az ya da çok tarama bütçesi ile tahsis edilebilir. Google ayrıca bu yöntemi, tüm içerik gruplarını indekslemeden hariç tutmak için kullanabilir.
Google, yazarları nasıl belirleyebilir ve içeriği nasıl nitelendirebilir?
Yazarlar kişi varlık tipine aittir. Bilgi Grafiği'nde kayıtlı olan önceden bilinen varlıklar ile Bilgi Kasası gibi bir bilgi havuzuna kaydedilen önceden bilinmeyen veya doğrulanmamış varlıklar arasında bir ayrım yapılmalıdır.
Varlıklar henüz Bilgi Grafiğinde yakalanmamış olsa bile Google, makine öğrenimi ve dil modellerini kullanarak varlıkları tanıyabilir ve yapılandırılmamış içerikten çıkarabilir. Çözüm, doğal dil işlemenin bir alt görevi olan varlık tanıma (NER) olarak adlandırılır.
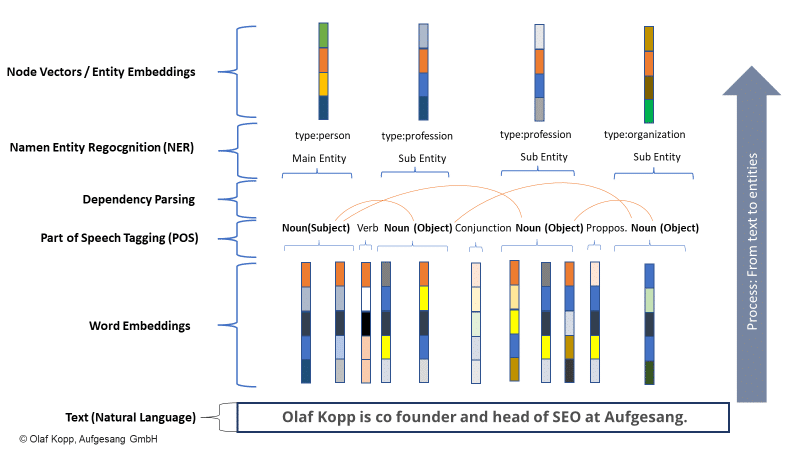
NER, varlıkları dil kalıplarına göre tanır ve varlık türleri atanır. Genel olarak konuşursak, isimler (adlandırılmış) varlıklardır.
Modern bilgi alma sistemleri bunun için kelime yerleştirmeyi (Word2Vec) kullanır.
Bir sayı vektörü, bir metnin veya metin paragrafının her bir kelimesini temsil eder ve varlıklar, düğüm vektörleri veya varlık yerleştirmeleri (Node2Vec/Entity2Vec) olarak temsil edilebilir.
Sözcükler, konuşma bölümü (POS) etiketleme yoluyla bir gramer sınıfına (isim, fiil, edatlar, vb.) atanır.
İsimler genellikle varlıktır. Özneler ana varlıklardır ve nesneler ikincil varlıklardır. Fiiller ve edatlar varlıkları birbirleriyle ilişkilendirebilir.
Aşağıdaki örnekte “olaf kopp”, “seo başkanı”, “ortak kurucu” ve “aufgesang” adlı varlıklardır. (NN = isim).
Doğal dil işleme, varlıkları tanımlayabilir ve aralarındaki ilişkiyi belirleyebilir.
Bu, bir varlık kavramını daha iyi yakalayan ve anlayan anlamsal bir alan yaratır.
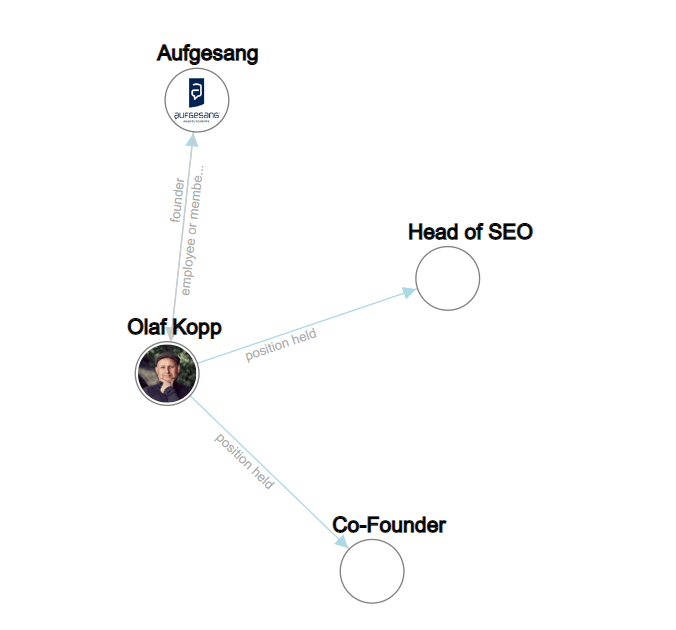
Bununla ilgili daha fazla bilgiyi "Google, arama sorgularını ve içeriği daha iyi anlamak için NLP'yi nasıl kullanır?" bölümünde bulabilirsiniz.
Yazar yerleştirmelerinin karşılığı, belge yerleştirmeleridir. Belge yerleştirmeleri, vektör alanı analizi aracılığıyla yazar vektörleriyle karşılaştırılır. ("Belgelerin vektör temsillerini oluşturma" adlı Google patentinden daha fazla bilgi edinebilirsiniz.)
Tüm içerik türleri, aşağıdakilere izin veren vektörler olarak temsil edilebilir:
- Vektör uzaylarında karşılaştırılacak içerik vektörleri ve yazar vektörleri.
- Benzerliğe göre kümelenecek belgeler.
- Atanacak yazarlar.
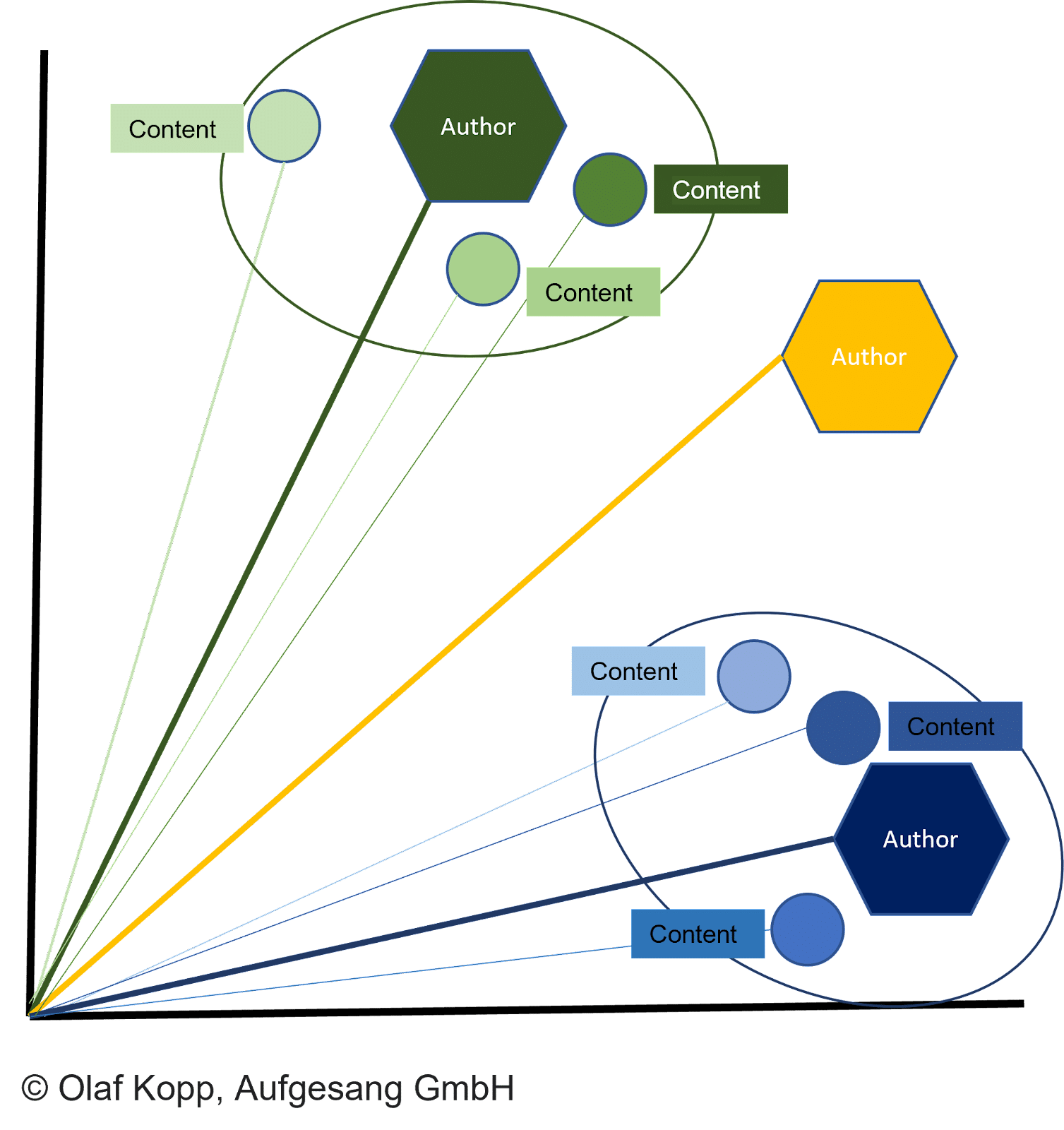
Belge vektörleri ile karşılık gelen yazar vektörü arasındaki mesafe, yazarın belgeleri oluşturma olasılığını tanımlar.
Mesafe diğer vektörlerden daha küçükse ve belirli bir eşiğe ulaşılırsa belge yazara atfedilir.
Bu aynı zamanda bir belgenin yanlış bayrak altında oluşturulmasını da engelleyebilir. Yazar vektörü daha sonra içerikte belirtilen yazar adı kullanılarak daha önce açıklandığı gibi bir yazar varlığına atanabilir.
Yazarlar hakkında önemli bilgi kaynakları şunları içerir:
- Kişi hakkında Wikipedia Makaleleri.
- Yazar profilleri.
- Konuşmacı profilleri.
- Sosyal medya profilleri.
Varlık türündeki bir kişinin adını Google'da ararsanız, ilk 20 arama sonucunda Wikipedia girişlerini, yazarın profillerini ve yazarla doğrudan bağlantılı etki alanlarının URL'lerini bulacaksınız.
Mobil SERP'lerde, Google'ın kişi varlığıyla hangi kaynaklarda doğrudan ilişki kurduğunu görebilirsiniz.
Google, sosyal medya profilleri için simgelerin üzerindeki tüm sonuçları, varlığa doğrudan atıfta bulunan kaynaklar olarak tanıdı.

"Olaf kopp" arama sorgusunun bu ekran görüntüsü, varlıkların kaynaklara bağlı olduğunu gösterir.
Ayrıca bir bilgi panelinin yeni bir çeşidini görüntüler. Görünüşe göre burada bir beta testinin parçası oldum.
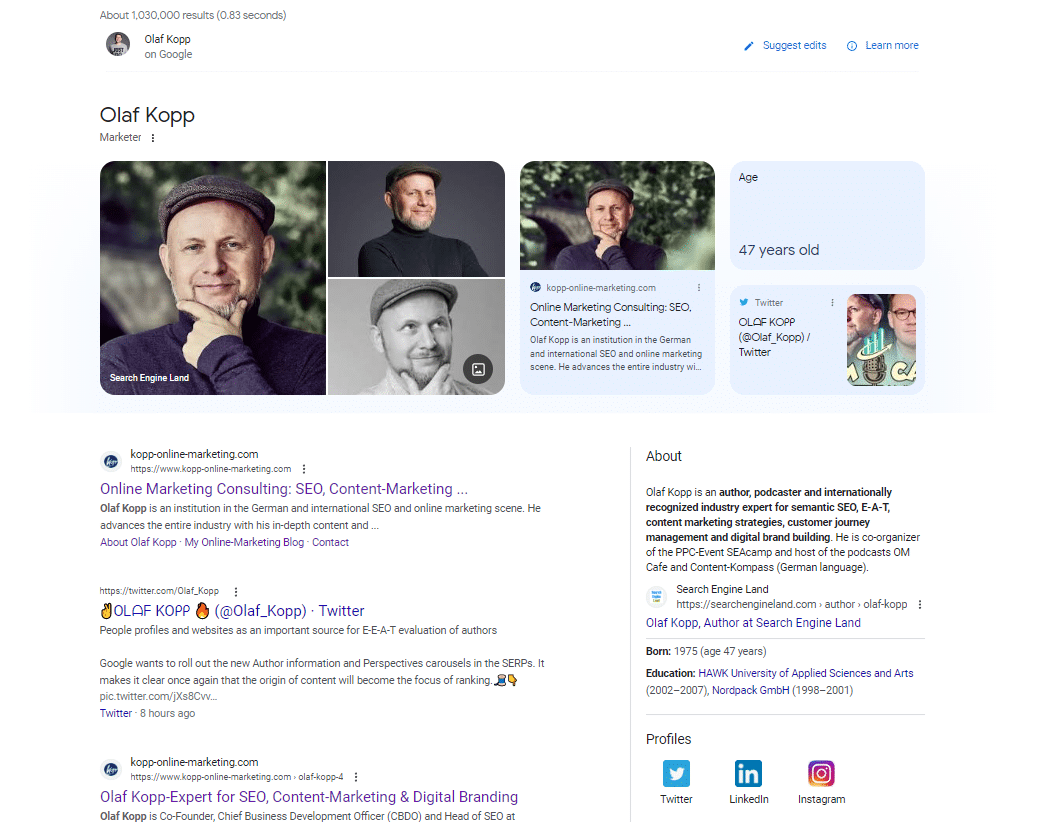
Bu ekran görüntüsünde, resimlere ve niteliklere (yaş) ek olarak, Google'ın alanımı ve sosyal medya profilimi doğrudan varlığımla ilişkilendirdiğini ve bunları bilgi panelinde sunduğunu göreceksiniz.
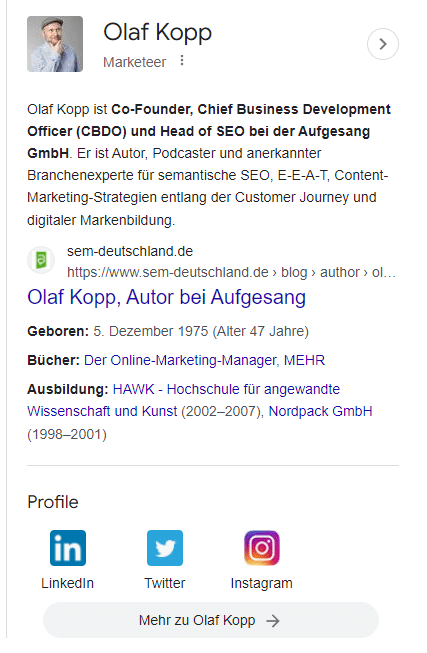
Hakkımda bir Wikipedia makalesi bulunmadığından, Hakkında açıklaması ABD'deki Search Engine Land'deki yazar profilinden ve Almanya'daki ajansın web sitesinin yazar profilinden sağlanır.
Web'deki kişisel profiller, Google'ın yazarları bağlamsallaştırmasına ve bir yazarla ilişkili sosyal medya profillerini ve etki alanlarını belirlemesine yardımcı olur.
Yazar profillerindeki yazar kutuları veya yazar koleksiyonları, Google'ın yazarlara içerik atamasına yardımcı olur. Belirsizlikler ortaya çıkabileceğinden yazarın adı tanımlayıcı olarak yetersizdir.
Tutarlılığı sağlamak için herkesin yazar açıklamalarına dikkat etmelisiniz. Google, varlığın geçerliliğini birbiriyle karşılaştırmalı olarak kontrol etmek için bunları kullanabilir.
Arama pazarlamacılarının güvendiği günlük haber bültenini edinin.
Şartlara bakın.
Yazarların EEAT derecelendirmesi için ilginç Google patentleri
Aşağıdaki patentler, Google'ın yazarları nasıl belirlediğine, ona içerik atadığına ve onu EEAT açısından nasıl değerlendirdiğine ilişkin olası metodolojilere bir bakış sunar.

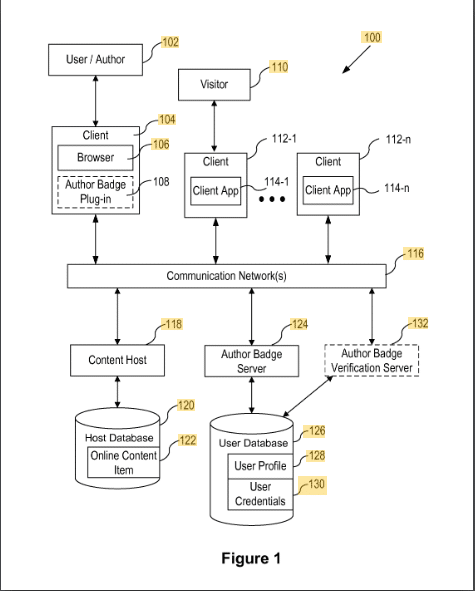
İçerik Yazarı Rozetleri
Bu patent, içeriğin bir rozet aracılığıyla yazarlara nasıl atandığını açıklar.
İçerik, e-posta adresi veya yazarın adı gibi bir kimlik kullanılarak bir yazar rozetine atanır. Doğrulama, yazarın tarayıcısındaki bir eklenti aracılığıyla yapılır.
Yazar vektörleri oluşturuluyor
Google bu patenti 2016 yılında, 2036 yılına kadar imzalamıştır. Ancak sadece ABD için patent başvuruları yapılmış olması, dünya çapında henüz Google aramalarında kullanılmadığını düşündürmektedir.
Patent, eğitim verilerine dayalı olarak yazarların vektörler olarak nasıl temsil edildiğini açıklar.
Bir vektör, yazarın tipik yazma stiline ve kelime seçimine göre tanımlanan benzersiz parametreler haline gelir.
Bu şekilde, daha önce yazara atfedilmeyen içerikler onlara atanabilir veya benzer yazarlar kümeler halinde gruplandırılabilir.
İçerik sıralaması daha sonra, kullanıcının geçmişte aramadaki (örneğin Keşfet'teki) kullanıcı davranışına dayalı olarak bir veya daha fazla yazar için ayarlanabilir.
Bu nedenle, daha önce keşfedilmiş yazarlardan ve benzer yazarlardan gelen içerikler daha iyi sıralanır.
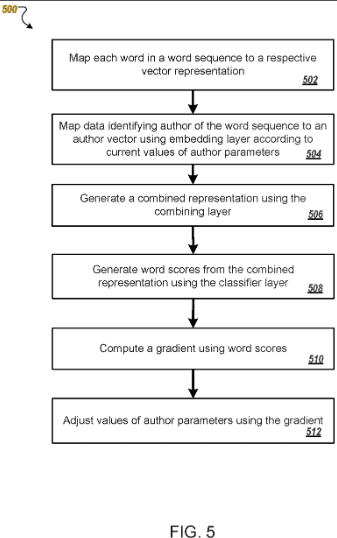
Bu patent, yazarlar ve kelime yerleştirmeleri gibi sözde yerleştirmelere dayanmaktadır.
Günümüzde gömmeler, derin öğrenme ve doğal dil işlemede teknolojik standarttır.
Bu nedenle, Google'ın bu tür yöntemleri yazar tanıma ve ilişkilendirme için de kullanacağı açıktır.
Bir yazarın itibar puanlaması
Bu patent ilk olarak Google tarafından 2008 yılında imzalanmıştır ve minimum süresi 2029'dur. Bu patent aslen uzun süredir kapalı olan Google Knol projesine atıfta bulunmaktadır.
Bu nedenle, Google'ın bunu 2017'de çevrimiçi içeriğin paraya dönüştürülmesi başlığı altında yeniden çizmesinin nedeni daha da heyecan verici. Knol, 2012'de Google tarafından kapatıldı.
Patent, bir itibar puanı belirlemekle ilgilidir. Bunun için aşağıdaki faktörler dikkate alınabilir:
- Yazarın çerçeve düzeyi.
- Tanınmış medyada yayınlar.
- yayın sayısı.
- Son sürümlerin yaşı.
- Yazarın ne kadar süredir resmi olarak yazar olarak çalıştığı.
- Yazarın içeriği tarafından oluşturulan bağlantıların sayısı.
Bir yazar, konu başına birden fazla itibar puanına sahip olabilir ve konu alanı başına birkaç takma ada sahip olabilir.
Patentte belirtilen noktaların çoğu, Knol gibi kapalı bir platformla ilgilidir. Dolayısıyla bu patent bu noktada yeterli olmalıdır.
Ajan rütbesi
Bu Google patenti ilk olarak 2005 yılında imzalanmıştır ve minimum süresi 2026 yılına kadardır.
ABD'nin yanı sıra İspanya, Kanada ve dünya genelinde de tescillenmiş olması, Google aramalarında kullanılma ihtimalini artırdı.
Patent, dijital içeriğin bir aracıya (yayıncı ve/veya yazar) nasıl atandığını açıklar. Bu içerik, diğer şeylerin yanı sıra bir ajan sıralamasına göre sıralanır.
Ajan Sıralaması, arama sorgusunun arama amacından bağımsızdır ve ajana atanan belgelere ve bunların geri bağlantılarına göre belirlenir.
Ajan Derecesi, yalnızca bir arama sorgusu, arama sorgusu kümesi veya tüm konu alanlarını ifade eder.
“Ajan sıralamaları, isteğe bağlı olarak, arama terimlerine veya arama terimleri kategorilerine göre de hesaplanabilir. Örneğin, arama terimleri (veya yapılandırılmış arama terimleri koleksiyonları, yani sorgular), örneğin spor veya tıp uzmanlıkları gibi konulara göre sınıflandırılabilir ve bir temsilcinin her konuya göre farklı bir sıralaması olabilir.”
Bir çevrimiçi içerik yazarının güvenilirliği
Bu Google patenti ilk olarak 2008 yılında imzalanmıştır ve minimum süresi 2029'dur ve şu ana kadar yalnızca ABD'de tescil edilmiştir.
Justin Lawyer, bir yazarın Patent İtibar Puanı ile aynı şekilde geliştirmiştir ve aramalarda kullanımı ile doğrudan ilişkilidir.
Patentte de anılan patentte olduğu gibi benzer noktalar bulunmaktadır.
Benim için yazarları güven ve otorite açısından değerlendirmek için en heyecan verici patent.
Bu patent, bir yazarın güvenilirliğini algoritmik olarak belirlemek için kullanılabilecek çeşitli faktörlere atıfta bulunur.
Bir arama motorunun, bir yazarın güvenilirlik faktörü ve itibar puanının etkisi altında belgeleri nasıl sıralayabileceğini açıklar.
Bir yazar, kaç farklı konuda içerik yayınladıklarına bağlı olarak birden çok itibar puanına sahip olabilir.
Bir yazarın itibar puanı yayıncıdan bağımsızdır.
Yine bu patentte, bir EEAT derecelendirmesinde olası bir faktör olarak bağlantılara atıfta bulunulmaktadır. Yayınlanan içeriğe bağlantı sayısı, bir yazarın itibar puanını etkileyebilir.
Bir itibar puanı için aşağıdaki olası sinyallerden bahsedilmektedir:
- Yazarın bir konu alanında ne kadar süredir içerik ürettiği.
- Yazarın farkındalığı.
- Kullanıcılar tarafından yayınlanan içeriğin derecelendirmeleri.
- Başka bir yayıncı, yazarın içeriğini ortalamanın üzerinde derecelendirme ile yayınlarsa.
- Yazar tarafından yayınlanan içerik miktarı.
- Yazarın en son ne kadar zaman önce yayınladığı.
- Yazarın benzer bir konudaki önceki yayınlarının derecelendirmeleri.
Patent itibar puanı hakkında diğer ilginç bilgiler:
- Bir yazar, kaç farklı konuda içerik yayınladıklarına bağlı olarak birden çok itibar puanına sahip olabilir.
- Bir yazarın itibar puanı yayıncıdan bağımsızdır.
- Yinelenen içerik veya alıntılar birden çok kez yayınlanırsa itibar puanı düşürülebilir.
- Yayınlanan içeriğe bağlantı sayısı, itibar puanını etkileyebilir.
Ayrıca, patent yazarlar için bir güvenilirlik faktörünü ele almaktadır. Aşağıdaki etkileyen faktörlerden bahsedilmektedir:
- Meslek veya yazarın bir şirketteki rolü hakkında doğrulanmış bilgiler. Aynı zamanda şirketin güvenilirliğini de göz önünde bulundurur.
- Mesleğin yayınlanan içeriğin konularıyla ilgisi.
- Yazarın eğitim ve öğretim düzeyi.
- Yazarın zamana dayalı deneyimi. Bir yazar bir konuda ne kadar uzun süredir yayın yapıyorsa o kadar güvenilirdir. Yazarın/yayıncının deneyimi, bir konu alanındaki ilk yayın tarihi üzerinden Google için algoritmik olarak belirlenebilir.
- Bir konuda yayınlanan içeriğin sayısı. Bir yazar bir konuda çok sayıda makale yayınlıyorsa, onun bir uzman olduğu ve belirli bir güvenilirliği olduğu varsayılabilir.
- Son sürüme kadar geçen süre. Bir yazarın bir konuda en son yayınladığından bu yana ne kadar uzun süre geçtiyse, bu konu için olası bir itibar puanı o kadar düşer. İçerik ne kadar güncel ise o kadar yüksektir.
- Yazarın/yayıncının ödül ve en iyiler listelerinde yer alması.
Sıralanan arama sonuçlarını yeniden sıralayan sistemler ve yöntemler
Bu Google patenti ilk olarak 2013 yılında imzalanmıştır ve en az 2033 yılına kadar süresi vardır. ABD'de ve dünya çapında tescillenmiştir, bu da Google'ın onu kullanma ihtimalini artırmaktadır.
Patentin mucitleri arasında, EEAT ile ilgili birkaç Google patentinde yer alan Chung Tin Kwok da var.
Patent, arama motorlarının, yazarın içeriğine yapılan atıflara ek olarak, bir yazar puanlamasında tematik bir belge külliyatına katkıda bulunabileceği oranı da nasıl dikkate alabileceğini açıklamaktadır.
"Bazı düzenlemelerde, ilgili varlık için orijinal yazar puanının belirlenmesi şunları içerir: ilgili varlıkla ilişkili olarak tanımlanan bilinen içeriğin dizinindeki çok sayıda içerik bölümünün tanımlanması, çok sayıdaki her bölüm önceden belirlenmiş bir miktarı temsil eder bilinen içerik dizinindeki verilerin yüzdesinin hesaplanması ve bilinen içerik dizinindeki içerik bölümlerinin ilk örnekleri olan çok sayıdaki bölümün yüzdesinin hesaplanması."
Atıf puanlaması da dahil olmak üzere yazar puanlamasına dayalı olarak arama sonuçlarının yeniden sıralamasını açıklar. Atıf puanlaması, bir yazarın belgelerine yapılan atıfların sayısına bağlıdır.
Yazar puanlaması için başka bir kriter, bir yazarın konuyla ilgili belgeler külliyatına katkıda bulunduğu içeriğin oranıdır.
"[W]burada, ilgili bir varlık için yazar puanının belirlenmesi şunları içerir: ilgili varlık için bir atıf puanının belirlenmesi, burada atıf puanı, ilgili varlıkla ilişkili içeriğin alıntılanma sıklığına karşılık gelir; orijinal yazar puanının, bilinen içeriğin bir dizinindeki içeriğin ilk örneği olan ilgili varlıkla ilişkili içeriğin bir yüzdesine karşılık geldiği ilgili varlık ve alıntı puanı ile orijinal yazar puanının önceden belirlenmiş bir işlev kullanılarak birleştirilmesi yazar puanı."
Patentin amacı, "taklitçileri" tespit etmek ve içeriklerini sıralamada düşürmektir, ancak yazarların genel değerlendirmesi için de kullanılabilir.
Bir yazarı derecelendirmek için temel faktörler
Yukarıdaki patentlerde listelenen bir yazar değerlendirmesi için olası faktörlere ek olarak, dikkate alınması gereken birkaç tane daha var (bazılarından "Google'ın EAT'yi değerlendirebileceği 14 yol" makalemde daha önce bahsetmiştim).
- Bir konudaki içeriğin genel kalitesi: Bir yazarın, alan ve formattan bağımsız olarak, bir bütün olarak bir konudaki içeriği hakkında sunduğu kalite, EEAT için bir faktör olabilir. Bunun için sinyaller, içerik düzeyinde kullanıcı sinyalleri, bağlantılar ve diğer kalite sinyalleri olabilir.
- PageRank veya yazarın içeriğine yapılan referanslar.
- İlgili konu veya terimlerle içerikte (podcast'ler, videolar, web siteleri, PDF'ler, kitaplar) yazarın birlikte kullanımı.
- İlgili konu veya terimlerle arama sorgularında yazarın birlikte bulunması.
EEAT'i yazar varlıklarına uygulama
Makine öğrenimi yöntemleri, yapılandırılmamış içerikten anlamsal yapıların büyük ölçekte tanınmasını ve eşlenmesini mümkün kılar.
Bu, Google'ın daha önce Bilgi Grafiği'nde gösterilenden çok daha fazla varlığı tanımasına ve anlamasına olanak tanır.
Sonuç olarak, içeriğin kaynağı giderek daha önemli bir rol oynamaktadır. EEAT, belgelerin, içeriğin ve etki alanının ötesinde algoritmik olarak uygulanabilir.
Kavram, içeriğin yazar varlıklarını da kapsayabilir (yani, içerikten sorumlu yazarlar ve kuruluşlar).
Önümüzdeki birkaç yıl içinde EEAT'nin Google arama üzerinde daha da önemli bir etkisini göreceğimizi düşünüyorum. Bu faktör, sıralama için bireysel içeriğin alaka düzeyi optimizasyonu kadar önemli olabilir.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.