
Google, spam ve yapay zeka içeriği algılama ve web sitelerini sıralama için ChatGPT benzeri bir sistem mi kullanıyor?
Yayınlanan: 2023-02-01Başlık kasıtlı olarak yanıltıcıdır - ancak yalnızca "ChatGPT" teriminin kullanılması söz konusu olduğunda.
"ChatGPT benzeri", sistemi "GPT-2 veya GPT-3 gibi bir metin oluşturma modeli" olarak tanımlamak yerine, okuyucu olarak, bahsettiğim teknoloji türünü hemen bilmenizi sağlar. (Ayrıca, ikincisi gerçekten tıklanabilir olmayacaktır…)
Bu makalede inceleyeceğimiz şey, 2020'den daha eski ancak oldukça alakalı bir Google makalesidir: "Üretken Modeller, Sayfa Kalitesinin Denetimsiz Tahmin Edicileridir: Devasa Ölçekli Bir Çalışma."
Kağıt ne hakkında?
Yazarların açıklamasıyla başlayalım. Konuyu şöyle tanıtıyorlar:
"Birçoğu, büyük ölçüde insan görünümlü metinleri büyük ölçekte üretme yeteneklerinden dolayı, sinirsel metin oluşturucuların vahşi doğadaki potansiyel tehlikeleri hakkında endişelerini dile getirdi.
İnsan ve makine tarafından oluşturulan metin arasında ayrım yapmak için eğitilmiş sınıflandırıcılar, son zamanlarda web'de makine tarafından oluşturulan metnin varlığını izlemek için kullanılmıştır [29]. Bununla birlikte, etiket gerektirmeme çekici özelliklerine rağmen - yalnızca bir insan metni külliyatı ve üretken bir model - bu sınıflandırıcıların başka kullanımlar için uygulanması konusunda çok az çalışma yapılmıştır. Bu çalışmada, kullanıma hazır insan ve makine ayrımcılarının, sayfa kalitesinin güçlü sınıflandırıcıları olarak hizmet ettiğini titiz insan değerlendirmesi yoluyla gösteriyoruz . Yani, makine tarafından üretilmiş gibi görünen metinler tutarsız veya anlaşılmaz olma eğilimindedir. Doğada düşük sayfa kalitesinin varlığını anlamak için, sınıflandırıcıları yarım milyar İngilizce web sayfasından oluşan bir örneğe uyguluyoruz.”
Esasen söylemek istedikleri, AI tabanlı kopyayı tespit etmek için geliştirilen aynı sınıflandırıcıların, onu oluşturmak için aynı modelleri kullanarak, düşük kaliteli içeriği tespit etmek için başarıyla kullanılabileceğini bulduklarıdır.
Tabii bu bizi önemli bir soruyla baş başa bırakıyor:
Bu nedensellik mi (yani, sistem bunda gerçekten iyi olduğu için mi alıyor) yoksa korelasyon mu (yani, daha iyi araçlarla dolaşılması kolay bir şekilde çok sayıda mevcut spam oluşturulmuş mu)?
Ancak bunu keşfetmeden önce, yazarların bazı çalışmalarına ve bulgularına bakalım.
kurulum
Başvuru için, deneylerinde aşağıdakileri kullandılar:
- İki metin oluşturma modeli , OpenAI'nin RoBERTa tabanlı GPT-2 dedektörü (GPT-2 çıkışlı RoBERTa modelini kullanan ve muhtemelen yapay zeka tarafından üretilip üretilmediğini tahmin eden bir dedektör) ve aynı zamanda yukarıya erişimi olan GLTR modeli GPT-2 çıkışı ve benzer şekilde çalışır.
Yukarıdaki kağıttan kopyaladığım içerikte bu modelin çıktısının bir örneğini görebiliriz:
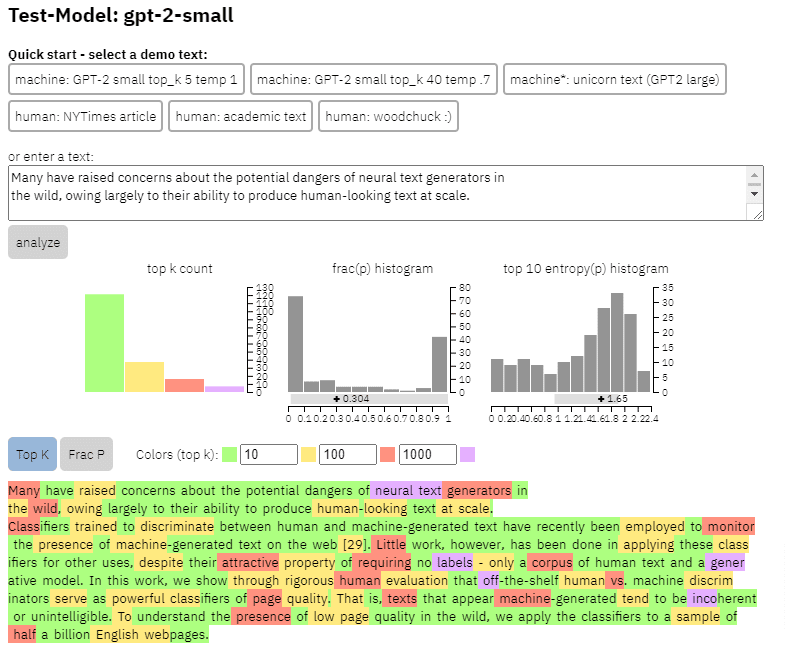
- Üç veri kümesi Web500M (500 milyon İngilizce web sayfasından rastgele örnekleme), GPT-2 Çıktısı (250.000 GPT-2 metin oluşturma) ve Grover-Output (tasarlanan önceden eğitilmiş Grover-Base modelini kullanarak dahili olarak 1,2 milyon makale oluşturdular) sahte haberleri tespit etmek için).
- Enron Spam E-posta Veri Kümesi üzerinde eğitilmiş bir sınıflandırıcı olan Spam Baseline . Atayacakları Dil Kalitesi sayısını belirlemek için bu sınıflandırıcıyı kullandılar, bu nedenle model bir belgenin spam olmadığını 0,2 olasılıkla belirlerse, atanan Dil Kalitesi (LQ) puanı 0,2 idi.
Arama pazarlamacılarının güvendiği günlük haber bültenini edinin.
Şartlara bakın.
Spam yaygınlığı hakkında bir kenara
Yazarların tökezlediği bazı ilginç bulguları tartışmak için hızlıca bir kenara çekmek istedim. Biri aşağıdaki şekilde gösterilmektedir (kağıttan Şekil 3):
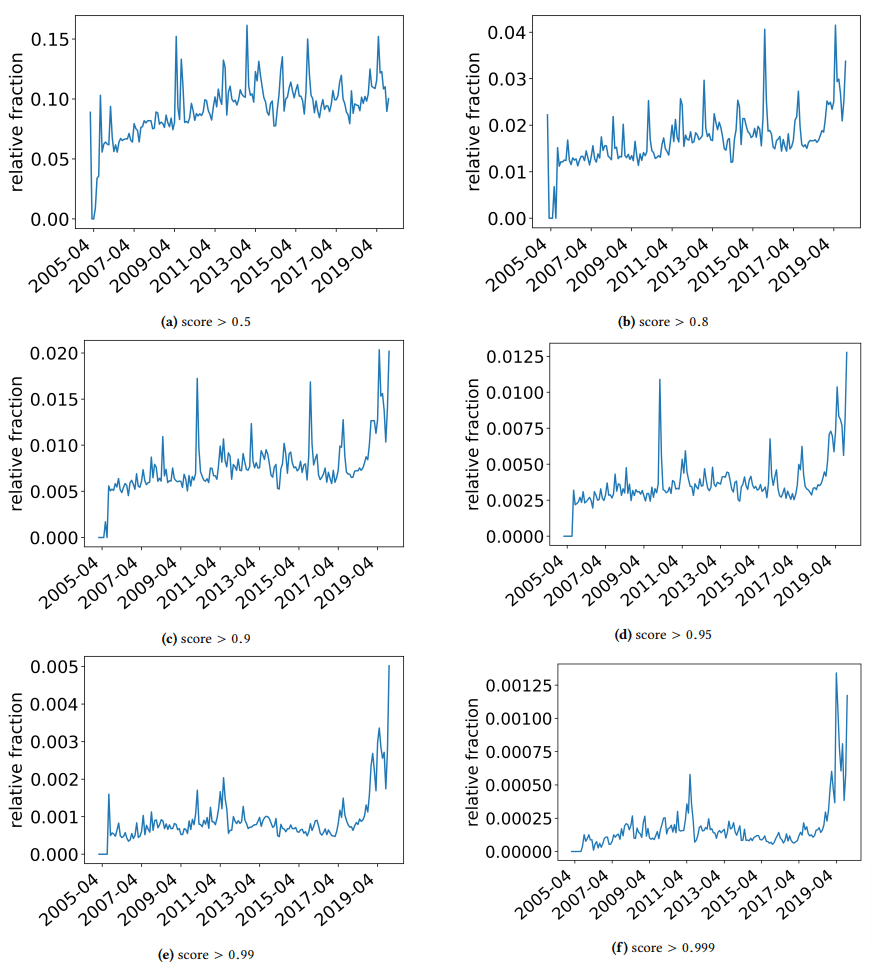
Her grafiğin altındaki puana dikkat etmek önemlidir. 1.0'a doğru bir sayı, içeriğin spam olduğuna dair bir güvene doğru ilerliyor. O zaman gördüğümüz şey, 2017'den itibaren - ve 2019'da artış göstererek - düşük kaliteli belgelerin yaygınlığıydı.
Ek olarak, düşük kaliteli içeriğin etkisinin bazı sektörlerde diğerlerinden daha yüksek olduğunu bulmuşlardır (daha yüksek bir puanın daha yüksek spam olasılığını yansıttığını hatırlayarak).
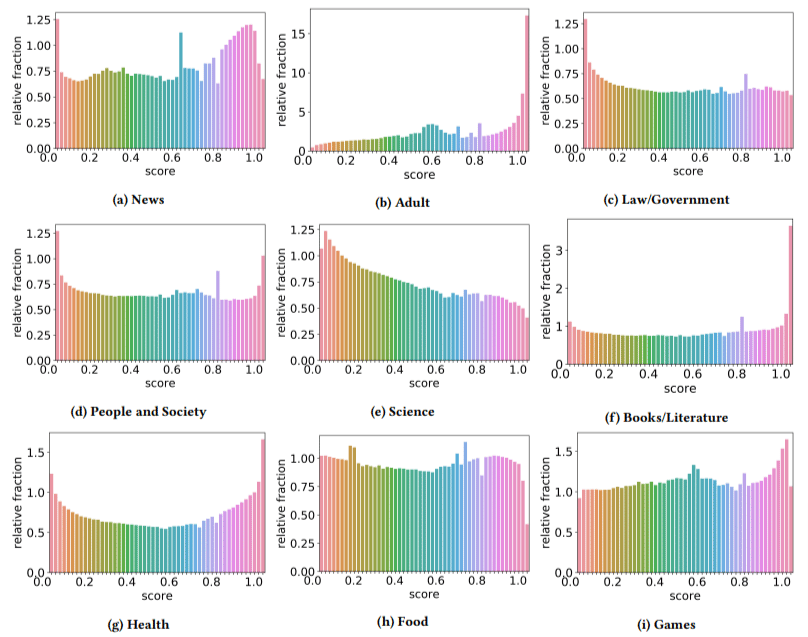
Bunlardan birkaçına kafamı kaşıdım. Belli ki yetişkin mantıklıydı.
Ancak kitaplar ve edebiyat biraz şaşırtıcıydı. Ve sağlık da öyleydi - yazarlar Viagra ve diğer "yetişkinlere yönelik sağlık ürünü" sitelerini "sağlık" olarak ve deneme çiftliklerini "edebiyat" olarak gündeme getirene kadar - yani.
Bulguları
Yazarlar, sektörler ve 2019'daki artış hakkında konuştuklarımızın yanı sıra, özellikle ChatGPT gibi araçlara güvenmeye başladığımızda, SEO'ların öğrenebileceği ve akılda tutması gereken bir dizi ilginç şey buldu.
- Düşük kaliteli içeriğin uzunluğu genellikle daha düşüktür (3.000 karakterle zirve yapar).
- Metnin bir makine tarafından yazıp yazılmadığını belirlemek için eğitilmiş algılama sistemleri, düşük ve yüksek seviye içeriği sınıflandırmada da iyidir.
- Sıralamalar için tasarlanmış içeriğimizi belirli bir suçlu olarak adlandırıyorlar, ancak orada olmaması gerektiğini bildiğimiz çöplüğe atıfta bulunduklarından şüpheleniyorum.
Yazarlar bunun her şeyin sonu olduğunu iddia etmiyorlar, bunun yerine bir başlangıç noktası ve eminim son birkaç yılda çıtayı daha da ileriye taşıdılar.
AI tarafından oluşturulan içerik hakkında bir not
Dil modelleri de aynı şekilde yıllar içinde gelişmiştir. Bu makale yazıldığı sırada GPT-3 varken, kullandıkları dedektörler, önemli ölçüde daha düşük bir model olan GPT-2'ye dayanıyordu.
GPT-4 muhtemelen hemen köşede ve Google'ın Sparrow'u bu yılın sonlarında piyasaya sürülecek. Bu, yalnızca teknolojinin savaş alanının her iki tarafında da (içerik oluşturuculara karşı arama motorları) daha iyi hale gelmekle kalmayıp, kombinasyonları devreye sokmanın daha kolay olacağı anlamına gelir.
Google, Sparrow veya GPT-4 tarafından oluşturulan içeriği algılayabilir mi? Belki.
Peki ya Sparrow ile oluşturulmuşsa ve ardından bir yeniden yazma istemiyle GPT-4'e gönderilmişse?
Unutulmaması gereken bir diğer faktör de, bu yazıda kullanılan tekniklerin oto-regresif modellere dayalı olmasıdır. Basitçe söylemek gerekirse, bir kelime için, o kelimenin kendisinden öncekilere verileceğini tahmin edeceklerine dayanarak bir puan tahmin ederler.
Modeller daha yüksek derecede karmaşıklık geliştirdikçe ve bir kelimeyi takip eden bir kelime yerine her seferinde tam fikirler oluşturmaya başladıkça, yapay zeka algılaması kayabilir.
Öte yandan, saçma sapan içeriğin tespit edilmesi artmalıdır - bu, kazanacak tek "düşük kaliteli" içeriğin yapay zeka tarafından oluşturulmuş olduğu anlamına gelebilir.
Bu makalede ifade edilen görüşler, konuk yazara aittir ve Search Engine Land olmak zorunda değildir. Personel yazarları burada listelenir.