
Hadoop Ekosistemi ve bileşenleri
Yayınlanan: 2015-04-23Büyük Veri, 2008'den beri BT sektöründe dolaşan popüler bir kelimedir. Sosyal ağlar, üretim, perakende, hisse senetleri, telekom, sigorta, bankacılık ve sağlık sektörleri tarafından üretilen veri miktarı hayallerimizin çok ötesindedir.
Hadoop'un ortaya çıkmasından önce, büyük verilerin depolanması ve işlenmesi büyük bir zorluktu. Ancak artık Hadoop kullanıma sunulduğundan, şirketler Büyük Veri'nin ticari etkisini ve bu verilerin anlaşılmasının büyümeyi nasıl yönlendireceğini anladı. Örneğin:
• Bankacılık sektörleri sadık müşterileri, kredi borcunu ödeyemeyenleri ve dolandırıcılık işlemlerini anlama konusunda daha iyi bir şansa sahiptir.
• Perakende sektörleri artık talebi tahmin etmek için yeterli veriye sahip.
• İmalat sektörlerinin kalite testi için maliyetli mekanizmalara bağlı olması gerekmez. Sensör verilerini yakalamak ve analiz etmek birçok modeli ortaya çıkaracaktır.
• E-Ticaret, sosyal ağlardaki sayfaları müşteri ilgi alanlarına göre kişiselleştirebilir.
• Hisse senedi piyasaları muazzam miktarda veri üretir, zaman zaman korelasyonlar güzel içgörüler ortaya çıkaracaktır.
Büyük Veri, birçok yararlı ve anlayışlı uygulamaya sahiptir.
Hadoop, Büyük Veriyi işlemek için doğru cevaptır. Hadoop ekosistemi, iş problemlerini çözmede yeterli avantaja sahip teknolojilerin bir kombinasyonudur.
Belirli bir iş sorunu için doğru çözümler oluşturmak için Hadoop Ekosistemindeki bileşenleri anlayalım.
Hadoop Ekosistemi:
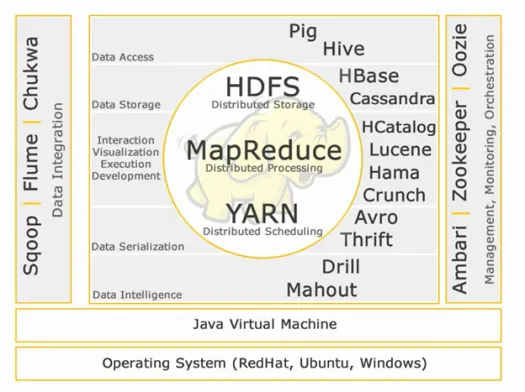

Çekirdek Hadoop:
HDFS:
HDFS, Yüksek Hacim, Hız ve Çeşitlilik ile büyük veri kümelerini yönetmek için Hadoop Dağıtılmış Dosya Sistemi anlamına gelir. HDFS, ana bağımlı mimarisini uygular. Ana, Ad düğümüdür ve bağımlı, veri düğümüdür.
Özellikler:
• Ölçeklenebilir
• Güvenilir
• Mal Donanımı
HDFS, Büyük Veri depolama için iyi bilinir.
Harita indirgeme:
Harita Azaltma, yüksek hacimli dağıtılmış verileri işlemek için tasarlanmış bir programlama modelidir. Platform, daha iyi istisna işleme için Java kullanılarak oluşturulmuştur. Harita Azaltma, Job tracker ve Task Tracker olmak üzere iki cin içerir.
Özellikler:
• Fonksiyonel Programlama.
• Büyük Veri üzerinde çok iyi çalışır.
• Büyük veri kümelerini işleyebilir.
Harita Azaltma, büyük verileri işlemekle bilinen ana bileşendir.
İPLİK:
YARN, Yet Another Resource Negotiator anlamına gelir. MapReduce 2(MRv2) olarak da adlandırılır. MRv1'deki Job Tracker'ın iki ana işlevi, kaynak yönetimi ve iş planlama/izleme, ResourceManager, NodeManager ve ApplicationMaster olmak üzere ayrı arka plan programlarına bölünmüştür.
Özellikler:
• Daha iyi kaynak yönetimi.
• Ölçeklenebilirlik
• Küme kaynaklarının dinamik tahsisi.
Veri Erişimi:
Domuz:
Apache Pig, basit geçici veri analiz programlarıyla büyük veri kümelerini analiz etmek için MapReduce üzerine kurulmuş yüksek seviyeli bir dildir. Pig, Veri Akışı dili olarak da bilinir. Python ile çok iyi entegre edilmiştir. Başlangıçta yahoo tarafından geliştirilmiştir.
Domuzun göze çarpan özellikleri:
• Programlama kolaylığı
• Optimizasyon fırsatları
• Genişletilebilirlik.
Pig komut dosyaları dahili olarak harita azaltma programlarına dönüştürülecektir.

kovan:
Apache Hive, veri özetleme, sorgulama ve analiz sağlamak için Hadoop'un üzerine inşa edilmiş başka bir üst düzey sorgu dili ve veri ambarı altyapısıdır. Başlangıçta yahoo tarafından geliştirilmiştir ve açık kaynak yapılmıştır.
Kovanın belirgin özellikleri:
• HQL denilen SQL benzeri bir sorgu dili.
• Daha hızlı veri işleme için bölümleme ve kovalama.
• Tableau gibi görselleştirme araçlarıyla entegrasyon.
Kovan sorguları dahili olarak harita azaltma programlarına dönüştürülecektir.
Büyük bir veri analisti olmak istiyorsanız, bu iki yüksek seviyeli dili mutlaka bilmelisiniz!!

Veri depolama:
Hbase:
Apache HBase, Hadoop emtia donanım makinelerinin üzerinde milyarlarca satır ve milyonlarca sütun içeren büyük tabloları barındırmak için oluşturulmuş bir NoSQL veritabanıdır. Büyük Verilerinize rastgele, gerçek zamanlı okuma/yazma erişimine ihtiyacınız olduğunda Apache Hbase'i kullanın.
Özellikler:
• Kesinlikle tutarlı okuma ve yazma işlemleri. Bellek işlemlerinde.
• İstemci erişimi için kullanımı kolay Java API.
• Domuz, kovan ve kepçe ile iyi entegre edilmiştir.
• CAP teoreminde tutarlı ve bölüm toleranslı bir sistemdir.

Cassandra:
Cassandra, doğrusal ölçeklenebilirlik ve yüksek kullanılabilirlik için tasarlanmış bir NoSQL veritabanıdır. Cassandra, anahtar/değer modeline dayanmaktadır. Facebook tarafından geliştirildi ve sorgulara daha hızlı yanıt vermesiyle biliniyor.
Özellikler:
• Sütun dizinleri
• Denormalizasyon desteği
• Gerçekleştirilmiş görünümler
• Güçlü yerleşik önbelleğe alma.

Etkileşim -Görselleştirme- yürütme-geliştirme:
Katalog:

HCatalog, diğer Hadoop uygulamaları için kovan meta verilerinin entegrasyonunu sağlayan bir tablo yönetim katmanıdır. Apache pig, Apache MapReduce ve Apache Hive gibi farklı veri işleme araçlarına sahip kullanıcıların verileri daha kolay okumasını ve yazmasını sağlar.
Özellikler:
• Farklı formatlar için tablo görünümü.
• Veri kullanılabilirliği bildirimleri.
• Harici sistemlerin meta verilere erişmesi için REST API'leri.
Lusen:
Apache LuceneTM, tamamen Java ile yazılmış, yüksek performanslı, tam özellikli bir metin arama motoru kitaplığıdır. Başta platformlar arası olmak üzere tam metin arama gerektiren hemen her uygulamaya uygun bir teknolojidir.
Özellikler:
• Ölçeklenebilir, Yüksek – Performans indeksleme.
• Güçlü, Doğru ve Verimli arama algoritmaları.
• Çapraz platform çözümü.
Hama:
Apache Hama, Toplu Senkronize Paralel (BSP) hesaplamaya dayalı dağıtılmış bir çerçevedir. Matris, grafik ve ağ algoritmaları gibi büyük bilimsel hesaplamalar için yetenekli ve iyi bilinir.
Özellikler:
• Basit programlama modeli
• Yinelemeli algoritmalar için çok uygundur
• İPLİK destekli
• İşbirlikçi filtreleme denetimsiz makine öğrenimi.
• K-Means kümeleme.
Çıtır:
Apache crunch, basit ve verimli MapReduce programlarının ardışık düzeni için oluşturulmuştur. Bu çerçeve, MapReduce ardışık düzenlerini yazmak, test etmek ve çalıştırmak için kullanılır.
Özellikler:
• Geliştirici odaklı.
• Minimal soyutlamalar
• Esnek veri modeli.
Veri Serileştirme:
Avro:
Apache Avro, dilden bağımsız bir veri serileştirme çerçevesidir. Verilerin, okuma ve yazma için dilden daha uzun yaşamasına olanak tanıyan, dil taşınabilirliği için tasarlanmıştır.

tasarruf:
Thrift, Hadoop üzerine kurulu teknolojilerle etkileşim kurmak için arayüzler oluşturmak için geliştirilmiş bir dildir. Çok sayıda dil için hizmet tanımlamak ve oluşturmak için kullanılır.
Veri Zekası:
Delmek:
Apache Drill, Hadoop ve NoSQL için düşük gecikme süreli bir SQL sorgu motorudur.
Özellikler:
• Çeviklik
• Esneklik
• Aşinalık.

Mahut:
Apache Mahout, Büyük Veri üzerinde tahmine dayalı analitik oluşturmak için tasarlanmış, ölçeklenebilir bir makine öğrenimi kitaplığıdır. Mahout'un artık daha hızlı bellek hesaplaması için apache kıvılcım uygulamaları var.
Özellikler:
• İşbirliğine dayalı filtreleme.
• Sınıflandırma
• Kümeleme
• Boyutsal küçülme

Veri Entegrasyonu:
Apache Sqoop'u:

Apache Sqoop, ilişkisel veritabanları ve Hadoop arasında toplu veri aktarımı için tasarlanmış bir araçtır.
Özellikler:
• HDFS'ye ve HDFS'den içe ve dışa aktarma.
• Hive'a ve Hive'dan ithalat ve ihracat.
• HBase'e içe ve dışa aktarın.
Apache Flume:
Flume, büyük miktarda günlük verisini verimli bir şekilde toplamak, toplamak ve taşımak için dağıtılmış, güvenilir ve kullanılabilir bir hizmettir.
Özellikler:
• Güçlü
• Hata töleransı
• Akış veri akışlarına dayalı basit ve esnek Mimari.

Apaçi Çukwa:
Büyük dağıtılmış dosya sistemlerini izlemek için kullanılan ölçeklenebilir günlük toplayıcı.
Özellikler:
• Binlerce düğüme ölçeklenir.
• Güvenilir teslimat.
• Verileri süresiz olarak saklayabilmelidir.

Yönetim, İzleme ve Düzenleme:
Apaçi ambarı:
Ambari, Apache Hadoop Kümelerinin sağlanması, yönetilmesi ve izlenmesi için bir arabirim sağlayarak hadoop yönetimini daha basit hale getirmek için tasarlanmıştır.
Özellikler:
• Bir Hadoop Kümesi sağlayın.
• Bir Hadoop Kümesini yönetme.
• Bir Hadoop Kümesini izleyin.

Apache Hayvan Bekçisi:
Zookeeper, yapılandırma bilgilerini korumak, adlandırmak, dağıtılmış senkronizasyon sağlamak ve grup hizmetleri sağlamak için tasarlanmış merkezi bir hizmettir.
Özellikler:
• Serileştirme
• Atomiklik
• Güvenilirlik
• Basit API

Apaçi Oozie:
Oozie, Apache Hadoop işlerini yönetmek için bir iş akışı zamanlayıcı sistemidir.
Özellikler:
• Ölçeklenebilir, güvenilir ve genişletilebilir sistem.
• Map-Reduce, Hive, Pig ve Sqoop gibi çeşitli Hadoop işlerini destekler.
• Basit ve kullanımı kolaydır.

Bileşenler hakkında ileriki makalelerde ayrıntılı olarak tartışacağız. Bizi izlemeye devam edin.